


循环神经网络(数据思维赛-安全文本信息抽取)
训练集有四列数据:

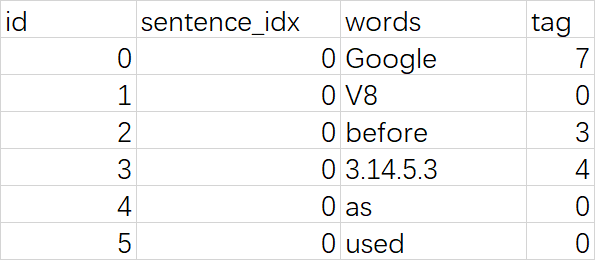
id为序号,sentence_idx为语句的序号,words为从一条语句中解析出的单词,tag为每个word对应的tag标签。
test集给出前三列数据,求每一个word对应的tag数据。
使用循环神经网络算法:

1 import pandas as pd 2 from sklearn.model_selection import train_test_split 3 from keras.preprocessing.text import Tokenizer 4 from keras.preprocessing.sequence import pad_sequences 5 from keras.models import Sequential 6 from keras.layers import Embedding, Dense, Flatten 7 from tensorflow.keras.utils import to_categorical 8 9 # 加载训练数据 10 train_data = pd.read_csv('train.csv',converters={i: str for i in range(0, 100)}) 11 12 # 创建词汇表和标签表 13 tokenizer = Tokenizer() 14 tokenizer.fit_on_texts(train_data['words']) 15 word_vocab_size = len(tokenizer.word_index) + 1 16 tag_vocab = sorted(list(set(train_data['tag'].values))) 17 18 tag2idx = {t: i for i, t in enumerate(tag_vocab)} 19 20 # 将句子和标签转换为序列 21 X = tokenizer.texts_to_sequences(train_data['words']) 22 y = [tag2idx[tag] for tag in train_data['tag']] 23 sentence_idx = train_data['sentence_idx'].values 24 25 # 对序列进行填充 26 max_len = max(len(sentence) for sentence in X) 27 X_pad = pad_sequences(X, maxlen=max_len) 28 29 # 将标签转换为 one-hot 编码 30 y_onehot = to_categorical(y) 31 32 # 划分训练集和验证集 33 X_train, X_val, y_train, y_val, sentence_idx_train, sentence_idx_val = train_test_split( 34 X_pad, y_onehot, sentence_idx, test_size=0.2, random_state=42) 35 36 # 构建神经网络模型 37 model = Sequential() 38 model.add(Embedding(word_vocab_size, 100, input_length=max_len)) 39 model.add(Flatten()) 40 model.add(Dense(128, activation='relu')) 41 model.add(Dense(len(tag_vocab), activation='softmax')) 42 43 model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) 44 45 # 训练模型 46 model.fit(X_train, y_train, validation_data=(X_val, y_val), epochs=10, batch_size=32) 47 48 # 加载测试数据 49 test_data = pd.read_csv('test.csv',converters={i: str for i in range(0, 100)}) 50 51 # 将测试数据转换为序列并填充 52 X_test = tokenizer.texts_to_sequences(test_data['words']) 53 X_test_pad = pad_sequences(X_test, maxlen=max_len) 54 55 # 使用训练好的模型进行预测 56 predictions = model.predict_classes(X_test_pad) 57 58 # 将预测结果保存到result.csv中 59 result_df = pd.DataFrame({'id': test_data['id'], 'sentence_idx': test_data['sentence_idx'], 60 'words': test_data['words'], 'tag': [tag_vocab[prediction] for prediction in predictions]}) 61 result_df.to_csv('result.csv', index=False)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix