

JAVA复习
JavaSE_第1章 Java概述
1、Java语言跨平台原理
Java程序运行在Java虚拟机JVM上,不同的操作系统有不同的JVM,而Java程序可以在任意JVM上运行,所以Java程序可以不考虑系统,只要找到JVM即可运行,从而通过JVM实现跨平台。
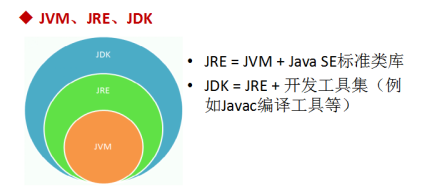
2、JVM、JRE、JDK的关系
- JVM(Java Virtual Machine ):Java虚拟机,是运行所有Java程序的假想计算机,是Java程序的运行环境之一,也是Java 最具吸引力的特性之一。我们编写的Java代码,都运行在JVM 之上。
- **JRE ** (Java Runtime Environment) :是Java程序的运行时环境,包含
JVM和运行时所需要的核心类库。 - JDK (Java Development's Kit):是Java程序开发工具包,包含
JRE和开发人员使用的工具。
3、JDK的安装
-
安装步骤:
-
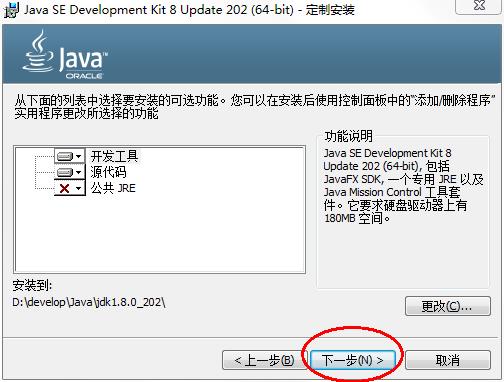
双击
jdk-8u202-windows-x64.exe文件,并单击下一步,如图所示:
-
取消独立JRE的安装,单击
公共JRE前的下拉列表,选择此功能将不可用如图所示: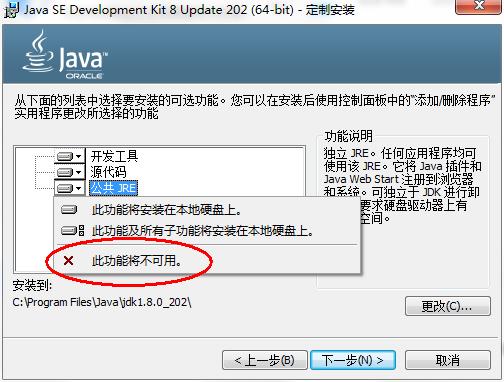
-
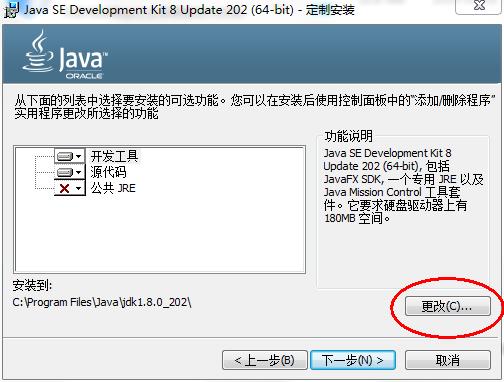
修改安装路径,单击更改,如图所示:
-
将安装路径修改为
D:\develop\Java\jdk1.8.0_202\,并单击确定,如图所示: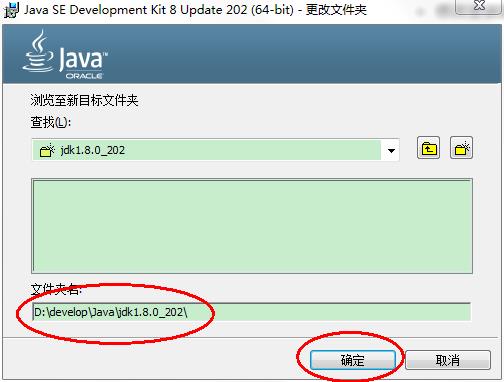
-
单击下一步,如图所示:
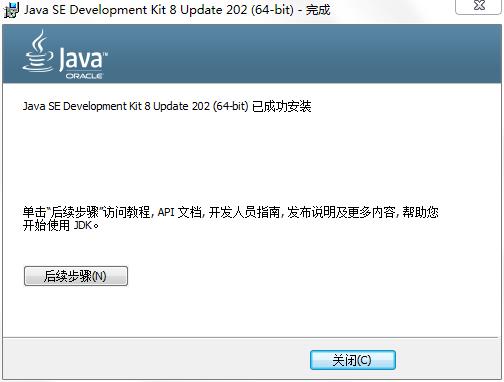
-
稍后几秒,安装完成,如图所示:
-
目录结构,如图所示:

-
4、配置环境变量
方案一:只配置path
-
步骤:
-
打开桌面上的计算机,进入后在左侧找到
计算机,单击鼠标右键,选择属性,如图所示:
-
选择
高级系统设置,如图所示: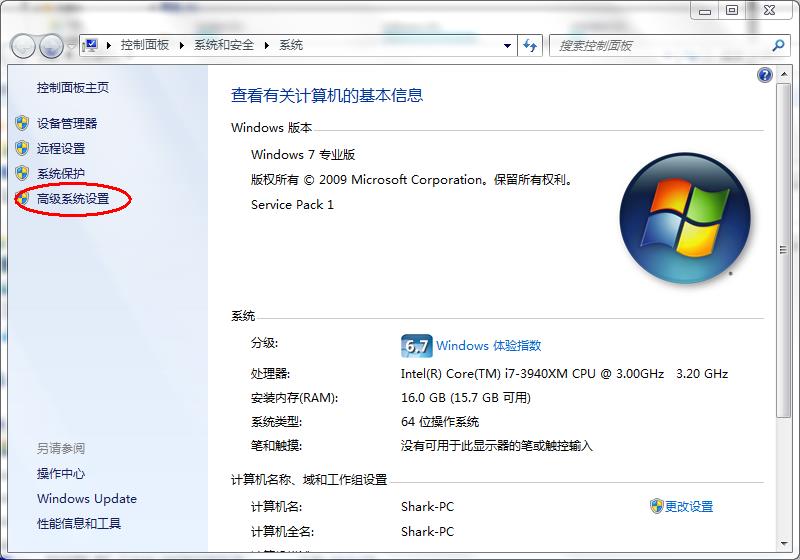
-
在
高级选项卡,单击环境变量,如图所示: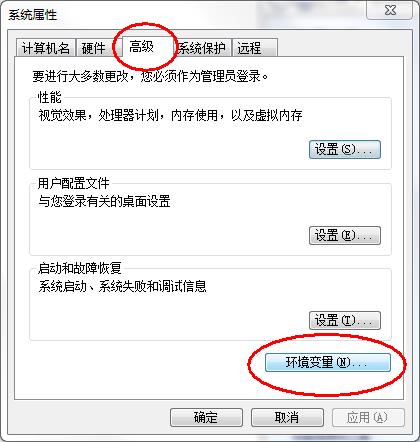
-
在
系统变量中,选中Path环境变量,双击或者点击编辑,如图所示: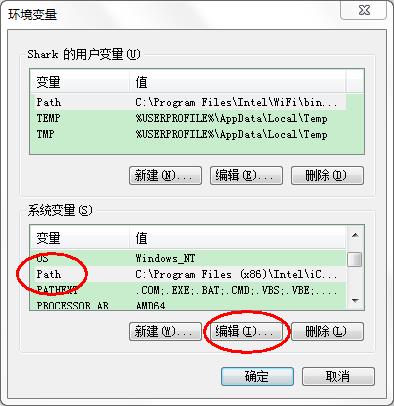
-
在变量值的最前面,键入
D:\develop\Java\jdk1.8.0_202\bin;分号必须要写,而且还要是英文符号。如图所示: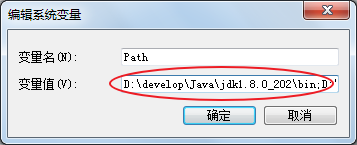
-
环境变量配置完成,重新开启DOS命令行,在任意目录下输入
javac命令,运行成功。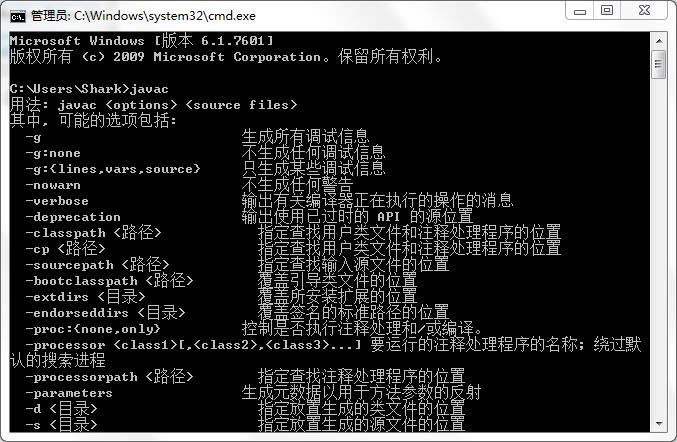
-
方案二:配置JAVA_HOME+path
-
步骤:
-
打开桌面上的计算机,进入后在左侧找到
计算机,单击鼠标右键,选择属性,如图所示: -
选择
高级系统设置,如图所示: -
在
高级选项卡,单击环境变量,如图所示: -
在
系统变量中,单击新建,创建新的环境变量,如图所示:
-
变量名输入
JAVA_HOME,变量值输入D:\develop\Java\jdk1.8.0_202,并单击确定,如图所示: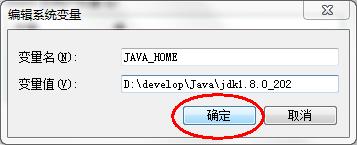
-
选中
Path环境变量,双击或者点击编辑,如图所示: -
在变量值的最前面,键入
%JAVA_HOME%\bin;分号必须要写,而且还要是英文符号。如图所示: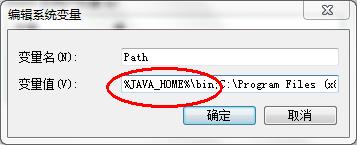
-
环境变量配置完成,重新开启DOS命令行,在任意目录下输入
javac命令,运行成功。
-
5、程序开发步骤说明
JDK安装完毕,可以开发我们第一个Java程序了。
Java程序开发三步骤:编写、编译、运行。
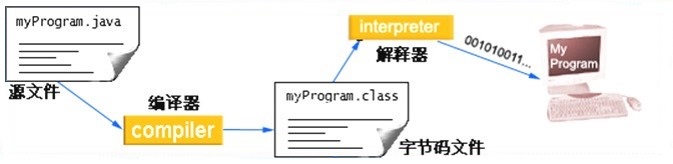
JavaSE_第2章 Java基础语法
1 注释(annotation)
-
注释:就是对代码的解释和说明。其目的是让人们能够更加轻松地了解代码。为代码添加注释,是十分必须要的,它不影响程序的编译和运行。
-
Java中有
单行注释、多行注释和文档注释-
单行注释以
//开头,以换行结束,格式如下:// 注释内容 -
多行注释以
/*开头,以*/结束,格式如下:/* 注释内容 */ -
文档注释以
/**开头,以*/结束,Java特有的注释,结合/** 注释内容 */
-
2 关键字(keyword)
关键字:是指在程序中,Java已经定义好的单词,具有特殊含义。
- HelloWorld案例中,出现的关键字有
public、class、static、void等,这些单词已经被Java定义好 - 关键字的特点:全部都是
小写字母。 - 关键字比较多,不需要死记硬背,学到哪里记到哪里即可。

关键字一共50个,其中const和goto是保留字。
true,false,null看起来像关键字,但从技术角度,它们是特殊的布尔值和空值。
3 标识符( identifier)
简单的说,凡是程序员自己命名的部分都可以称为标识符。
即给类、变量、方法、包等命名的字符序列,称为标识符。
1、标识符的命名规则(必须遵守的硬性规则)
(1)Java的标识符只能使用26个英文字母大小写,0-9的数字,下划线_,美元符号$
(2)不能使用Java的关键字(包含保留字)和特殊值
(3)数字不能开头
(4)不能包含空格
(5)严格区分大小写
2、标识符的命名规范(建议遵守的软性规则,否则容易被鄙视和淘汰)
(1)见名知意
(2)类名、接口名等:每个单词的首字母都大写,形式:XxxYyyZzz,
例如:HelloWorld,String,System等
(3)变量、方法名等:从第二个单词开始首字母大写,其余字母小写,形式:xxxYyyZzz,
例如:age,name,bookName,main
(4)包名等:每一个单词都小写,单词之间使用点.分割,形式:xxx.yyy.zzz,
例如:java.lang
(5)常量名等:每一个单词都大写,单词之间使用下划线_分割,形式:XXX_YYY_ZZZ,
例如:MAX_VALUE,PI
4 变量(variable)
1 变量的概念
变量:在程序执行的过程中,其值可以发生改变的量
变量的作用:用来存储数据,代表内存的一块存储区域,这块内存中的值是可以改变的。
2 变量的声明
数据类型 变量名;
例如:
//存储一个整数类型的年龄
int age;
//存储一个小数类型的体重
double weight;
//存储一个单字符类型的性别
char gender;
//存储一个布尔类型的婚姻状态
boolean marry;
//存储一个字符串类型的姓名
String name;
//声明多个同类型的变量
int a,b,c; //表示a,b,c三个变量都是int类型。
3 变量的赋值
int age = 18;
double weight = 44.4;
boolean marry = true;
String word = "hello world";
long类型:如果赋值的常量整数超过int范围,那么需要在数字后面加L。
float类型:如果赋值为常量小数,那么需要在小数后面加F。
char类型:使用单引号''
String类型:使用双引号""
可以使用其他变量或者表达式给变量赋值
int m = 1;
int n = m;
int x = 1;
int y = 2;
int z = 2 * x + y;
4 变量的三要素
1、数据类型
- 变量的数据类型决定了在内存中开辟多大空间
- 变量的数据类型也决定了该变量可以存什么值
2、变量名
- 见名知意非常重要
3、值
- 基本数据类型的变量:存储数据值
- 引用数据类型的变量:存储地址值,即对象的首地址。例如:String类型的变量存储的是字符串对象的首地址(关于对象后面章节再详细讲解)
5 Java的基本数据类型的存储范围
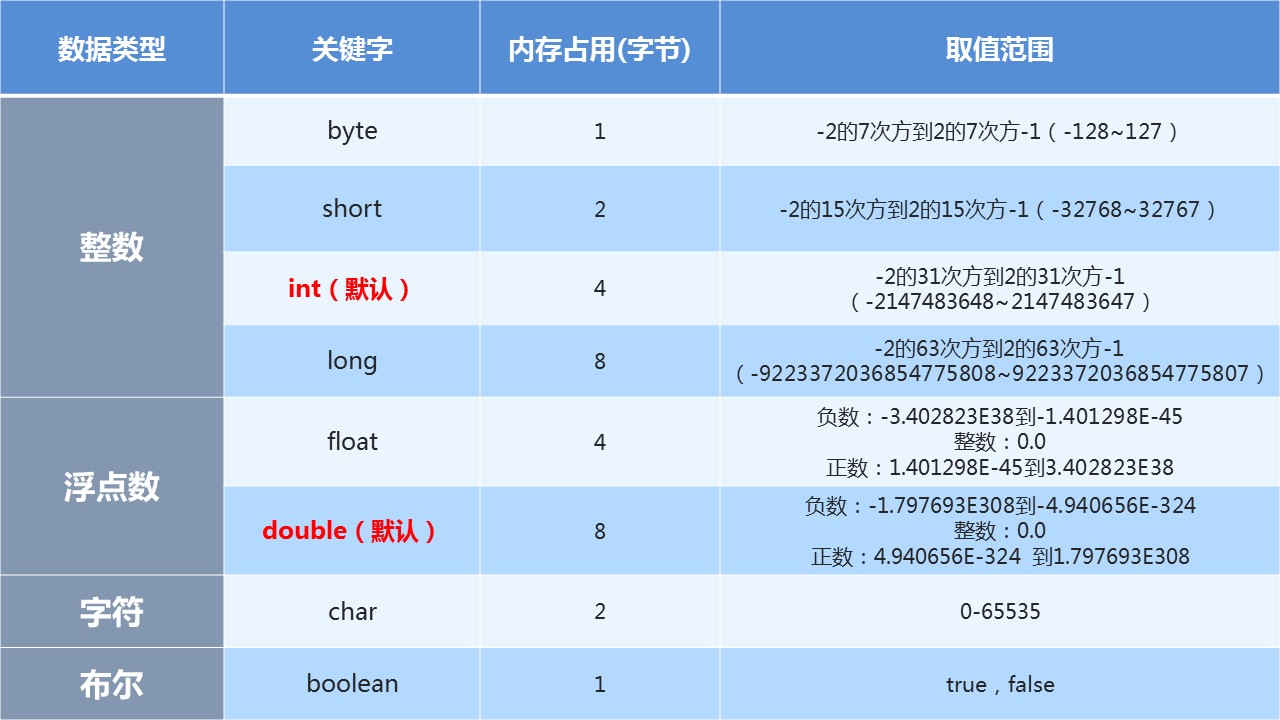
float:单精度浮点型,占内存:4个字节,精度:科学记数法的小数点后6~7位
double:双精度浮点型,占内存:8个字节,精度:科学记数法的小数点后15~16位
6 原码、反码、补码与符号位概念
计算机数据的存储使用二进制补码形式存储,并且最高位是符号位,最高位1是负数,最高位0是正数。
规定:正数的补码与反码、原码一样,称为三码合一;
负数的补码与反码、原码不一样:
负数的原码:把十进制转为二进制,然后最高位设置为1
负数的反码:在原码的基础上,最高位不变,其余位取反(0变1,1变0)
负数的补码:反码+1
例如:byte类型(1个字节,8位)
25 ==> 原码 0001 1001 ==> 反码 0001 1001 -->补码 0001 1001
-25 ==>原码 1001 1001 ==> 反码1110 0110 ==>补码 1110 0111
整数:
正数:25 00000000 00000000 000000000 00011001(原码)
正数:25 00000000 00000000 000000000 00011001(反码)
正数:25 00000000 00000000 000000000 00011001(补码)
负数:-25 10000000 00000000 000000000 00011001(原码)
负数:-25 11111111 11111111 111111111 11100110(反码)
负数:-25 11111111 11111111 111111111 11100111(补码)
7 Java程序中如何表示和处理单个字符
(1)使用单引号将单个字符引起来:例如:'A','0','尚'
char c = '尚';//使用单引号
String s = '尚';//错误的,哪怕是一个字符,也要使用双引号
char kongChar = '';//错误,单引号中有且只能有一个字符
String kongStr = "";//可以,双引号中可以没有其他字符,表示是空字符串
(2)特殊的转义字符
\n:换行
\r:回车
\t:Tab键
\\:\
\":"
\':'
\b:删除键Backspace
(3)用十进制的0~65535之间的Unicode编码值,表示一个字符
在JVM内存中,一个字符占2个字节,Java使用Unicode字符集来表示每一个字符,即每一个字符对应一个唯一的Unicode编码值。char类型的数值参与算术运算或比较大小时,都是用编码值进行计算的。
char c1 = 23578;
System.out.println(c1);//尚
char c2 = 97;
System.out.println(c2);//a
//如何查看某个字符的Unicode编码?
//将一个字符赋值给int类型的变量即可
int codeOfA = 'A';
System.out.println(codeOfA);
int codeOfShang = '尚';
System.out.println(codeOfShang);
int codeOfTab = '\t';
System.out.println(codeOfTab);
(4)\u字符的Unicode编码值的十六进制型
char c = '\u0041'; //十进制Unicode值65,对应十六进制是41,但是\u后面必须写4位
char c = '\u5c1a'; //十进制Unicode值23578,对应十六进制是5c1a
5 基本数据类型转换(Conversion)
1 自动类型转换(隐式类型转换)
自动转换:
- 将
取值范围小的类型自动提升为取值范围大的类型。
基本数据类型的转换规则如图所示:
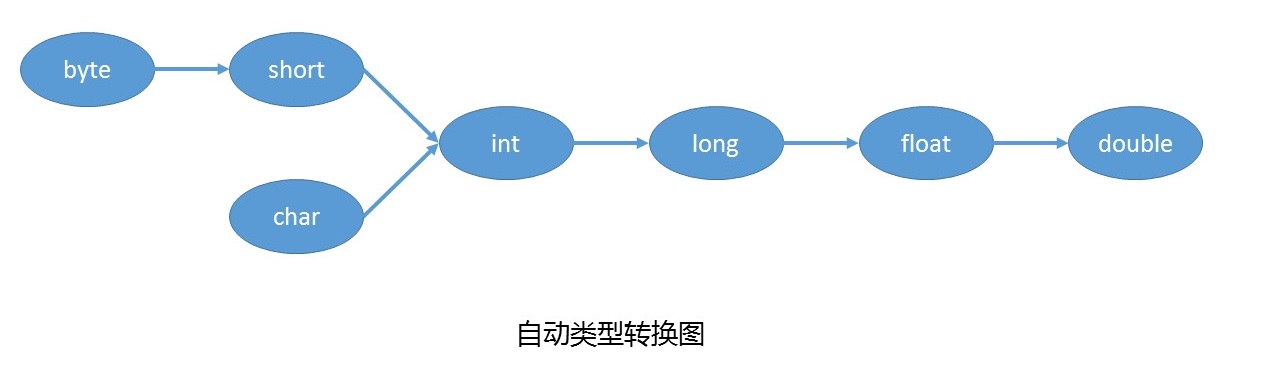
2 强制类型转换(显示类型转换)
int i = (int)3.14;//强制类型转换,损失精度
double d = 1.2;
int num = (int)d;//损失精度
int i = 200;
byte b = (byte)i;//溢出
3 基本数据类型与字符串类型的转换
1、任意数据类型的数据与String类型进行“+”运算时,结果一定是String类型
System.out.println("" + 1 + 2);//12
2、但是String类型不能通过强制类型()转换,转为其他的类型
String str = "123";
int num = (int)str;//错误的
int num = Integer.parseInt(str);//后面才能讲到,借助包装类的方法才能转
6 运算符(Operator)
运算符的分类:
- 按照功能分:算术运算符、赋值运算符、比较运算符、逻辑运算、条件运算符、Lambda运算符
| 分类 | 运算符 |
|---|---|
| 算术运算符(7个) | +、-、*、/、%、++、-- |
| 赋值运算符(12个) | =、+=、-=、*=、/=、%=、>>=、<<=、>>>=、&=、|=、^=等 |
| 关系运算符(6个) | >、>=、<、<=、==、!= |
| 逻辑运算符(6个) | &、|、^、!、&&、|| |
| 条件运算符(2个) | (条件表达式)?结果1:结果2 |
| 位运算符(7个) | &、|、^、~、<<、>>、>>> |
| Lambda运算符(1个) | ->(后面学) |
- 按照操作数个数分:一元运算符(单目运算符)、二元运算符(双目运算符)、三元运算符 (三目运算符)
| 分类 | 运算符 |
|---|---|
| 一元运算符(单目运算符) | 正号(+)、负号(-)、++、--、!、~ |
| 二元运算符(双目运算符) | 除了一元和三元运算符剩下的都是二元运算符 |
| 三元运算符 (三目运算符) | (条件表达式)?结果1:结果2 |
1 算术运算符
| 算术运算符 | 符号解释 |
|---|---|
+ |
加法运算,字符串连接运算,正号 |
- |
减法运算,负号 |
* |
乘法运算 |
/ |
除法运算,整数/整数结果还是整数 |
% |
求余运算,余数的符号只看被除数 |
++ 、 -- |
自增自减运算 |
2 关系运算符/比较运算符
| 关系运算符 | 符号解释 |
|---|---|
< |
比较符号左边的数据是否小于右边的数据,如果小于结果是true。 |
> |
比较符号左边的数据是否大于右边的数据,如果大于结果是true。 |
<= |
比较符号左边的数据是否小于或者等于右边的数据,如果大于结果是false。 |
>= |
比较符号左边的数据是否大于或者等于右边的数据,如果小于结果是false。 |
== |
比较符号两边数据是否相等,相等结果是true。 |
!= |
不等于符号 ,如果符号两边的数据不相等,结果是true。 |
3 逻辑运算符
| 逻辑运算符 | 符号解释 | 符号特点 |
|---|---|---|
& |
与,且 | 有false则false |
| ` | ` | 或 |
^ |
异或 | 相同为false,不同为true |
! |
非 | 非false则true,非true则false |
&& |
双与,短路与 | 左边为false,则右边就不看 |
| ` | ` |
&&和&区别,||和|区别:
&&和&区别:&&和&结果一样,&&有短路效果,左边为false,右边不执行;&左边无论是什么,右边都会执行。
||和|区别:||和|结果一样,||有短路效果,左边为true,右边不执行;|左边无论是什么,右边都会执行。
4 条件运算符
public static void main(String[] args) {
int i = (1==2 ? 100 : 200);
System.out.println(i);//200
int j = (3<=4 ? 500 : 600);
System.out.println(j);//500
}
5 位运算符
| 位运算符 | 符号解释 |
|---|---|
& |
按位与,当两位相同时为1时才返回1 |
| ` | ` |
~ |
按位非,将操作数的每个位(包括符号位)全部取反 |
^ |
按位异或。当两位相同时返回0,不同时返回1 |
<< |
左移运算符 |
>> |
右移运算符 |
>>> |
无符号右移运算符 |
6 赋值运算符
| 运算符 | 符号解释 |
|---|---|
| = | 将右边的常量值/变量值/表达式的值,赋值给左边的变量 |
| += | 将左边变量的值和右边的常量值/变量值/表达式的值进行相加,最后将结果赋值给左边的变量 |
| -= | 将左边变量的值和右边的常量值/变量值/表达式的值进行相减,最后将结果赋值给左边的变量 |
| *= | 将左边变量的值和右边的常量值/变量值/表达式的值进行相乘,最后将结果赋值给左边的变量 |
| /= | 将左边变量的值和右边的常量值/变量值/表达式的值进行相除,最后将结果赋值给左边的变量 |
| %= | 将左边变量的值和右边的常量值/变量值/表达式的值进行相模,最后将结果赋值给左边的变量 |
| <<= | 将左边变量的值左移右边常量/变量值/表达式的值的相应位,最后将结果赋值给左边的变量 |
| >>= | 将左边变量的值右移右边常量/变量值/表达式的值的相应位,最后将结果赋值给左边的变量 |
| >>>= | 将左边变量的值无符号右移右边常量/变量值/表达式的值的相应位,最后将结果赋值给左边的变量 |
| &= | 将左边变量的值和右边的常量值/变量值/表达式的值进行按位与,最后将结果赋值给左边的变量 |
| |= | 将左边变量的值和右边的常量值/变量值/表达式的值进行按位或,最后将结果赋值给左边的变量 |
| ^= | 将左边变量的值和右边的常量值/变量值/表达式的值进行按位异或,最后将结果赋值给左边的变量 |
7 运算符优先级
提示说明:
(1)表达式不要太复杂
(2)先算的使用()
口诀:
单目运算排第一;
乘除余二加减三;
移位四,关系五;
等和不等排第六;
位与、异或和位或;
短路与和短路或;
依次从七到十一;
条件排在第十二;
赋值一定是最后;
JavaSE_第3章 流程控制语句
1 顺序结构
顺序结构就是程序从上到下逐行地执行。表达式语句都是顺序执行的。并且上一行对某个变量的修改对下一行会产生影响。
2 分支语句
1 单分支条件判断:if
if(条件表达式){
语句体;
}
2 双分支条件判断:if...else
if(关系表达式) {
语句体1;
}else {
语句体2;
}
3 多分支条件判断:if...else if
if (判断条件1) {
执行语句1;
} else if (判断条件2) {
执行语句2;
}
...
}else if (判断条件n) {
执行语句n;
} else {
执行语句n+1;
}
4 if..else嵌套
在if的语句块中,或者是在else语句块中,
又包含了另外一个条件判断(可以是单分支、双分支、多分支)
执行的特点:
(1)如果是嵌套在if语句块中的
只有当外部的if条件满足,才会去判断内部的条件
(2)如果是嵌套在else语句块中的
只有当外部的if条件不满足,进入else后,才会去判断内部的条件
5 switch...case多分支选择结构
switch(表达式){
case 常量值1:
语句块1;
【break;】
case 常量值2:
语句块2;
【break;】
。。。
【default:
语句块n+1;
【break;】
】
}
3 循环语句
循环语句可以在满足循环条件的情况下,反复执行某一段代码,这段被重复执行的代码被称为循环体语句,当反复执行这个循环体时,需要通过修改循环变量使得循环判断条件为false,从而结束循环,否则循环将一直执行下去,形成死循环。
1 while循环
while循环语句基本格式:
while (循环条件语句①) {
循环体语句②;
}
执行流程:
- 第一步:执行循环条件语句①,看循环条件语句的值是true,还是false;
- 如果是true,执行第二步;
- 如果是false,循环语句中止,循环不再执行。
- 第二步:执行循环体语句②;
- 第三步:循环体语句执行完后,重新从第一步开始再执行一遍
2 do...while循环
do...while循环语句标准格式:
do {
循环体语句①;
} while (循环条件语句②);
执行流程:
- 第一步:执行循环体语句①;
- 第二步:执行循环条件语句②,看循环条件语句的值是true,还是false;
- 如果是true,执行第三步;
- 如果是false,循环语句终止,循环不再执行。
- 第三步:循环条件语句执行完后,重新从第一步开始再执行一遍
do...while循环至少执行一次循环体
3 for循环
for循环语句格式:
for(初始化语句①; 循环条件语句②; 迭代语句④){
循环体语句③
}
执行流程:
- 第一步:执行初始化语句①,完成循环变量的初始化;
- 第二步:执行循环条件语句②,看循环条件语句的值是true,还是false;
- 如果是true,执行第三步;
- 如果是false,循环语句中止,循环不再执行。
- 第三步:执行循环体语句③
- 第四步:执行迭代语句④,针对循环变量重新赋值
- 第五步:根据循环变量的新值,重新从第二步开始再执行一遍
4 关键字break
使用场景:终止switch或者当前循环
- 在选择结构switch语句中
- 在循环语句中
- 离开使用场景的存在是没有意义的
5 关键字:continue
使用场景:提前结束本次循环,继续下一次的循环
6 循环语句的区别
- 从循环次数角度分析
- do...while循环至少执行一次循环体语句
- for和while循环先循环条件语句是否成立,然后决定是否执行循环体,至少执行零次循环体语句
- 如何选择
- 遍历有明显的循环次数(范围)的需求,选择for循环
- 遍历没有明显的循环次数(范围)的需求,循环while循环
- 如果循环体语句块至少执行一次,可以考虑使用do...while循环
- 本质上:三种循环之间完全可以互相转换,都能实现循环的功能
- 三种循环结构都具有四要素:
- (1)循环变量的初始化表达式
- (2)循环条件
- (3)循环变量的修改的迭代表达式
- (4)循环体语句块
7 循环嵌套
所谓嵌套循环,是指一个循环的循环体是另一个循环。比如for循环里面还有一个for循环,就是嵌套循环。当然可以是三种循环任意互相嵌套。
例如:两个for嵌套循环格式
for(初始化语句①; 循环条件语句②; 迭代语句⑦) {
for(初始化语句③; 循环条件语句④; 迭代语句⑥) {
循环体语句⑤;
}
}
执行特点:外循环执行一次,内循环执行一轮。
JavaSE_第4章 数组
1 数组的概念
- 数组概念: 数组就是用于存储数据的长度固定的容器,保证多个数据的数据类型要一致。
所谓数组(array),就是相同数据类型的元素按一定顺序排列的集合,就是把有限个类型相同的变量用一个名字命名,以便统一管理他们,然后用编号区分他们,这个名字称为数组名,编号称为下标或索引(index)。组成数组的各个变量称为数组的元素(element)。数组中元素的个数称为数组的长度(length)。
数组的特点:
1、数组的长度一旦确定就不能修改
2、创建数组时会在内存中开辟一整块连续的空间。
3、存取元素的速度快,因为可以通过[下标],直接定位到任意一个元素。
2 数组的分类
1、按照维度分:
- 一维数组:存储一组数据
- 二维数组:存储多组数据,相当于二维表,一行代表一组数据,这是这里的二维表每一行长度不要求一样。
2、按照元素类型分:
- 基本数据类型的元素:存储数据值
- 引用数据类型的元素:存储对象(本质上存储对象的首地址)(这个在面向对象部分讲解)
注意:无论数组的元素是基本数据类型还是引用数据类型,数组本身都是引用数据类型。
3 一维数组的声明
- 一维数组的声明/定义格式
//推荐
数组类型[] 数组的名称;
//不推荐
数组类型 数组名[];
- 数组的声明,就是要确定:
(1)数组的维度:在Java中数组的标点符号是[],[]表示一维,[][]表示二维
(2)数组的元素类型:即创建的数组容器可以存储什么数据类型的数据。元素的类型可以是任意的Java的数据类型。例如:int, String, Student等
(3)数组名:就是代表某个数组的标识符,数组名其实也是变量名,按照变量的命名规范来命名。数组名是个引用数据类型的变量,因为它代表一组数据。
4 一维数组动态初始化
数组存储的元素的数据类型[] 数组名字 = new 数组存储的元素的数据类型[长度];
或
数组存储的数据类型[] 数组名字;
数组名字 = new 数组存储的数据类型[长度];
- new:关键字,创建数组使用的关键字。因为数组本身是引用数据类型,所以要用new创建数组对象。
- [长度]:数组的长度,表示数组容器中可以存储多少个元素。
- 注意:数组有定长特性,长度一旦指定,不可更改。和水杯道理相同,买了一个2升的水杯,总容量就是2升是固定的。
例如,定义可以存储5个整数的数组容器,代码如下:
int[] arr = new int[5];
int[] arr;
arr = new int[5];
int[] arr = new int[5]{1,2,3,4,5};//错误的,后面有{}指定元素列表,就不需要在[]中指定元素个数了。
5 一维数组的静态初始化
- 一维数组静态初始化格式1:
数据类型[] 数组名 = {元素1,元素2,元素3...};//必须在一个语句中完成,不能分开两个语句写
int[] arr = {1,2,3,4,5};//正确
int[] arr;
arr = {1,2,3,4,5};//错误
- 一维数组静态初始化格式2:
数据类型[] 数组名 = new 数据类型[]{元素1,元素2,元素3...};
或
数据类型[] 数组名;
数组名 = new 数据类型[]{元素1,元素2,元素3...};
int[] arr = new int[]{1,2,3,4,5};//正确
int[] arr;
arr = new int[]{1,2,3,4,5};//正确
6 一维数组的使用
数组的长度属性: 每个数组都具有长度,而且是固定的,Java中赋予了数组的一个属性,可以获取到数组的长度,语句为:数组名.length ,属性length的执行结果是数组的长度,int类型结果。
数组名.length
每一个存储到数组的元素,都会自动的拥有一个编号,从0开始,这个自动编号称为数组索引(index)或下标,可以通过数组的索引/下标访问到数组中的元素。
数组名[索引/下标]
Java中数组的下标从[0]开始,下标范围是[0, 数组的长度-1],即[0, 数组名.length-1]
7 数组下标越界异常
当访问数组元素时,下标指定超出[0, 数组名.length-1]的范围时,就会报数组下标越界异常:ArrayIndexOutOfBoundsException。
public class Test04ArrayIndexOutOfBoundsException {
public static void main(String[] args) {
int[] arr = {1,2,3};
// System.out.println("最后一个元素:" + arr[3]);//错误,下标越界ArrayIndexOutOfBoundsException
// System.out.println("最后一个元素:" + arr[arr.length]);//错误,下标越界ArrayIndexOutOfBoundsException
System.out.println("最后一个元素:" + arr[arr.length-1]);//对
}
}
创建数组,赋值3个元素,数组的索引就是0,1,2,没有3索引,因此我们不能访问数组中不存在的索引,程序运行后,将会抛出 ArrayIndexOutOfBoundsException 数组越界异常。在开发中,数组的越界异常是不能出现的,一旦出现了,就必须要修改我们编写的代码。
8 一维数组的遍历
数组遍历: 就是将数组中的每个元素分别获取出来,就是遍历。遍历也是数组操作中的基石。for循环与数组的遍历是绝配。
public class Test05ArrayIterate {
public static void main(String[] args) {
int[] arr = new int[]{1,2,3,4,5};
//打印数组的属性,输出结果是5
System.out.println("数组的长度:" + arr.length);
//遍历输出数组中的元素
System.out.println("数组的元素有:");
for(int i=0; i<arr.length; i++){
System.out.println(arr[i]);
}
}
}
9 一个一维数组内存图
public static void main(String[] args) {
int[] arr = new int[3];
System.out.println(arr);//[I@5f150435
}
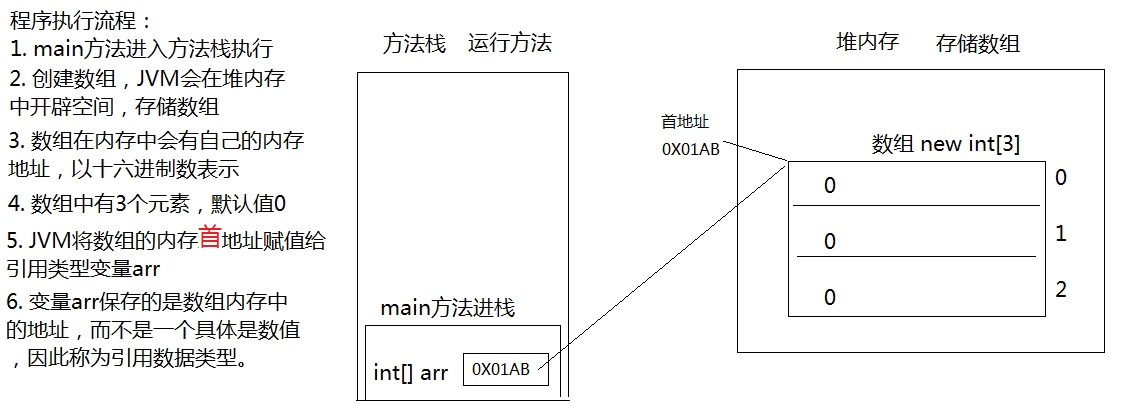
思考:打印arr为什么是[I@5f150435,它是数组的地址吗?
答:它不是数组的地址。
问?不是说arr中存储的是数组对象的首地址吗?
答:arr中存储的是数组的首地址,但是因为数组是引用数据类型,打印arr时,会自动调用arr数组对象的toString()方法,该方法默认实现的是对象类型名@该对象的hashCode()值的十六进制值。
问?对象的hashCode值是否就是对象内存地址?
答:不一定,因为这个和不同品牌的JVM产品的具体实现有关。例如:Oracle的OpenJDK中给出了5种实现,其中有一种是直接返回对象的内存地址,但是OpenJDK默认没有选择这种方式。
10 数组的常见算法:数组的遍历,数组的顺序查找,数组的二分查找,数组的翻转,数组的冒泡排序
JavaSE_第5章 面向对象基础(上)
1 面向对象编程思想概述
1、编程语言概述
Java是一种计算机程序设计语言。所有的计算机程序一直都是围绕着两件事在进行的,程序设计就是用某种语言编写代码来完成这两件事,所以程序设计语言又称为编程语言(编写程序的语言)。
- 如何表示和存储数据
- 基本数据类型的常量和变量:表示和存储一个个独立的数据
- 对象:表示和存储与某个具体事物相关的多个数据(例如:某个学生的姓名、年龄、联系方式等)
- 数据结构:表示和存储一组对象,数据结构有数组、链表、栈、队列、散列表、二叉树、堆......
- 基于这些数据都有什么操作行为,其实就是实现什么功能
- 数据的输入和输出
- 基于一个或两个数据的操作:赋值运算、算术运算、比较运算、逻辑运算等
- 基于一组数据的操作:统计分析、查找最大值、查找元素、排序、遍历等
2、程序设计方法
C语言是一种面向过程的程序设计语言,因为C语言是在面向过程思想的指引下去设计、开发计算机程序的。
Java语言是一种面向对象的程序设计语言,因为Java语言是在面向对象思想的指引下去设计、开发计算机程序的。
其中面向对象和面向过程都是一种编程思想,基于不同的思想会产生不同的程序设计方法。
- 面向过程的程序设计思想(Process-Oriented Programming),简称POP
- 关注的焦点是过程:过程就是操作数据的步骤,如果某个过程的实现代码在很多地方重复出现,那么就可以把这个过程抽象为一个函数,这样就可以大大简化冗余代码,也便于维护。
- 代码结构:以函数为组织单位。独立于函数之外的数据称为全局数据,在函数内部的称为局部数据。
- 面向对象的程序设计思想( Object Oriented Programming),简称OOP
- 关注的焦点是类:面向对象思想就是在计算机程序设计过程中,参照现实中事物,将事物的属性特征、行为特征抽象出来,用类来表示。某个事物的一个具体个体称为实例或对象。
- 代码结构:以类为组织单位。每种事物都具备自己的属性(即表示和存储数据,在类中用成员变量表示)和行为/功能(即操作数据,在类中用成员方法表示)。
2 类和对象
1、什么是类
类是一类具有相同特性的事物的抽象描述,是一组相关属性和行为的集合。
- 属性:就是该事物的状态信息。
- 行为:就是在你这个程序中,该状态信息要做什么操作,或者基于事物的状态能做什么。
2、什么是对象
对象是一类事物的一个具体个体(对象并不是找个女朋友)。即对象是类的一个实例,必然具备该类事物的属性和行为。
3、类与对象的关系
- 类是对一类事物的描述,是抽象的。
- 对象是一类事物的实例,是具体的。
- 类是对象的模板,对象是类的实体。
3 如何定义类
1、类的定义格式
关键字:class(小写)
【修饰符】 class 类名{
}
类的定义格式举例:
public class Student{
}
2、对象的创建
关键字:new
new 类名()//也称为匿名对象
//给创建的对象命名
//或者说,把创建的对象用一个引用数据类型的变量保存起来,这样就可以反复使用这个对象了
类名 对象名 = new 类名();
4 包的作用
(1)可以避免类重名:有了包之后,类的全名称就变为:包.类名
(2)可以控制某些类型或成员的可见范围
如果某个类型或者成员的权限修饰缺省的话,那么就仅限于本包使用。
(3)分类组织管理众多的类
5 如何声明包
关键字:package
package 包名;
注意:
(1)必须在源文件的代码首行
(2)一个源文件只能有一个声明包的package语句
包的命名规范和习惯:
(1)所有单词都小写,每一个单词之间使用.分割
(2)习惯用公司的域名倒置开头
例如:com.atguigu.xxx;
建议大家取包名时不要使用“java.xx"包
6 如何跨包使用类
注意:只有public的类才能被跨包使用
(1)使用类型的全名称
例如:java.util.Scanner input = new java.util.Scanner(System.in);
(2)使用import 语句之后,代码中使用简名称
import语句告诉编译器到哪里去寻找类。
import语句的语法格式:
import 包.类名;
import 包.*;
注意:
使用java.lang包下的类,不需要import语句,就直接可以使用简名称
import语句必须在package下面,class的上面
当使用两个不同包的同名类时,例如:java.util.Date和java.sql.Date。一个使用全名称,一个使用简名称
7 如何声明成员变量
【修饰符】 class 类名{
【修饰符】 数据类型 成员变量名;
}
示例:
public class Person{
String name;
char gender;
int age;
}
1、实例变量的特点
(1)实例变量的值是属于某个对象的
- 必须通过对象才能访问实例变量
- 每个对象的实例变量的值是独立的
(2)实例变量有默认值
| 分类 | 数据类型 | 默认值 |
|---|---|---|
| 基本类型 | 整数(byte,short,int,long) | 0 |
| 浮点数(float,double) | 0.0 | |
| 字符(char) | '\u0000' | |
| 布尔(boolean) | false | |
| 数据类型 | 默认值 | |
| 引用类型 | 数组,类,接口 | null |
2、实例变量的访问
对象.实例变量
例如:
package com.atguigu.test03.field;
public class TestPerson {
public static void main(String[] args) {
Person p1 = new Person();
p1.name = "张三";
p1.age = 23;
p1.gender = '男';
}
3、实例变量的内存分析
内存是计算机中重要的部件之一,它是与CPU进行沟通的桥梁。其作用是用于暂时存放CPU中的运算数据,以及与硬盘等外部存储器交换的数据。只要计算机在运行中,CPU就会把需要运算的数据调到内存中进行运算,当运算完成后CPU再将结果传送出来。我们编写的程序是存放在硬盘中的,在硬盘中的程序是不会运行的,必须放进内存中才能运行,运行完毕后会清空内存。Java虚拟机要运行程序,必须要对内存进行空间的分配和管理,每一片区域都有特定的处理数据方式和内存管理方式。
8 方法的概念
方法也叫函数,是一组代码语句的封装,从而实现代码重用,从而减少冗余代码,通常它是一个独立功能的定义,方法是一个类中最基本的功能单元。
Math.random()的random()方法
Math.sqrt(x)的sqrt(x)方法
System.out.println(x)的println(x)方法
Scanner input = new Scanner(System.in);
input.nextInt()的nextInt()方法
9 声明方法的位置
声明方法的位置必须在类中方法外,即不能在一个方法中直接定义另一个方法。
声明位置示例:
类{
方法1(){
}
方法2(){
}
}
错误示例:
类{
方法1(){
方法2(){ //位置错误
}
}
}
10 声明方法的语法格式
【修饰符】 返回值类型 方法名(【形参列表 】)【throws 异常列表】{
方法体的功能代码
}
11 方法调用语法格式
对象.非静态方法(【实参列表】)
1、形参和实参
- 形参(formal parameter):在定义方法时方法名后面括号中声明的变量称为形式参数(简称形参)即形参出现在方法定义时。
- 实参(actual parameter):调用方法时方法名后面括号中的使用的值/变量/表达式称为实际参数(简称实参)即实参出现在方法调用时。
- 调用时,实参的个数、类型、顺序顺序要与形参列表一一对应。如果方法没有形参,就不需要也不能传实参。
- 无论是否有参数,声明方法和调用方法是()都不能丢失
2、返回值问题
方法调用表达式是一个特殊的表达式:
- 如果被调用方法的返回值类型是void,调用时不需要也不能接收和处理(打印或参与计算)返回值结果,即方法调用表达式只能直接加;成为一个独立语句。
- 如果被调用方法有返回值,即返回值类型不是void,
- 方法调用表达式的结果可以作为赋值表达式的值,
- 方法调用表达式的结果可以作为计算表达式的一个操作数,
- 方法调用表达式的结果可以作为另一次方法调用的实参,
- 方法调用表达式的结果可以不接收和处理,方法调用表达式直接加;成为一个独立的语句,这种情况,返回值丢失。
12 方法调用内存分析
方法不调用不执行,调用一次执行一次,每次调用会在栈中有一个入栈动作,即给当前方法开辟一块独立的内存区域,用于存储当前方法的局部变量的值,当方法执行结束后,会释放该内存,称为出栈,如果方法有返回值,就会把结果返回调用处,如果没有返回值,就直接结束,回到调用处继续执行下一条指令。
栈结构:先进后出,后进先出。
13 特殊参数之一:可变参数
在JDK1.5之后,当定义一个方法时,形参的类型可以确定,但是形参的个数不确定,那么可以考虑使用可变参数。可变参数的格式:
【修饰符】 返回值类型 方法名(【非可变参数部分的形参列表,】参数类型... 形参名){ }
可变参数的特点和要求:
(1)一个方法最多只能有一个可变参数
(2)如果一个方法包含可变参数,那么可变参数必须是形参列表的最后一个
(3)在声明它的方法中,可变参数当成数组使用
(4)其实这个书写“≈”
【修饰符】 返回值类型 方法名(【非可变参数部分的形参列表,】参数类型[] 形参名){ }
只是后面这种定义,在调用时必须传递数组,而前者更灵活,既可以传递数组,又可以直接传递数组的元素,这样更灵活了。
14 方法的重载
- 方法重载:指在同一个类中,允许存在一个以上的同名方法,只要它们的参数列表不同即可,与修饰符和返回值类型无关。
- 参数列表:数据类型个数不同,数据类型不同(按理来说数据类型顺序不同也可以,但是很少见,也不推荐,逻辑上容易有歧义)。
- 重载方法调用:JVM通过方法的参数列表,调用匹配的方法。
- 先找个数、类型最匹配的
- 再找个数和类型可以兼容的,如果同时多个方法可以兼容将会报错
15 构造器
我们发现我们new完对象时,所有成员变量都是默认值,如果我们需要赋别的值,需要挨个为它们再赋值,太麻烦了。我们能不能在new对象时,直接为当前对象的某个或所有成员变量直接赋值呢。
可以,Java给我们提供了构造器(Constructor)。
1、构造器的作用
new对象,并在new对象的时候为实例变量赋值。
2、构造器的语法格式
构造器又称为构造方法,那是因为它长的很像方法。但是和方法还是有所区别的。
【修饰符】 class 类名{
【修饰符】 构造器名(){
// 实例初始化代码
}
【修饰符】 构造器名(参数列表){
// 实例初始化代码
}
}
注意事项:
- 构造器名必须与它所在的类名必须相同。
- 它没有返回值,所以不需要返回值类型,甚至不需要void
- 如果你不提供构造器,系统会给出无参数构造器,并且该构造器的修饰符默认与类的修饰符相同
- 如果你提供了构造器,系统将不再提供无参数构造器,除非你自己定义。
- 构造器是可以重载的,既可以定义参数,也可以不定义参数。
- 构造器的修饰符只能是权限修饰符,不能被其他任何修饰
16 静态关键字(static)
在类中声明的实例变量,其值是每一个对象独立的。但是有些成员变量的值不需要或不能每一个对象单独存储一份,即有些成员变量和当前类的对象无关。
在类中声明的实例方法,在类的外面必须要先创建对象,才能调用。但是有些方法的调用和当前类的对象无关,那么创建对象就有点麻烦了。
此时,就需要将和当前类的对象无关的成员变量、成员方法声明为静态的(static)。
1、静态变量
有static修饰的成员变量就是静态变量。
【修饰符】 class 类{
【其他修饰符】 static 数据类型 静态变量名;
}
2、静态变量的特点
- 静态变量的默认值规则和实例变量一样。
- 静态变量值是所有对象共享。
- 静态变量的值存储在方法区。
- 静态变量在本类中,可以在任意方法、代码块、构造器中直接使用。
- 如果权限修饰符允许,在其他类中可以通过“类名.静态变量”直接访问,也可以通过“对象.静态变量”的方式访问(但是更推荐使用类名.静态变量的方式)。
- 静态变量的get/set方法也静态的,当局部变量与静态变量重名时,使用“类名.静态变量”进行区分。
3、静态类变量和非静态实例变量、局部变量
- 静态类变量(简称静态变量):存储在方法区,有默认值,所有对象共享,生命周期和类相同,还可以有权限修饰符、final等其他修饰符
- 非静态实例变量(简称实例变量):存储在堆中,有默认值,每一个对象独立,生命周期每一个对象也独立,还可以有权限修饰符、final等其他修饰符
- 局部变量:存储在栈中,没有默认值,每一次方法调用都是独立的,有作用域,只能有final修饰,没有其他修饰符
4、静态方法
有static修饰的成员方法就是静态方法。
【修饰符】 class 类{
【其他修饰符】 static 返回值类型 方法名(形参列表){
方法体
}
}
5、静态方法的特点
- 静态方法在本类的任意方法、代码块、构造器中都可以直接被调用。
- 只要权限修饰符允许,静态方法在其他类中可以通过“类名.静态方法“的方式调用。也可以通过”对象.静态方法“的方式调用(但是更推荐使用类名.静态方法的方式)。
- 静态方法可以被子类继承,但不能被子类重写。
- 静态方法的调用都只看编译时类型。
6、本类中的访问限制区别
静态的类变量和静态的方法可以在本类的任意方法、代码块、构造器中直接访问。
非静态的实例变量和非静态的方法只能在本类的非静态的方法、非静态代码块、构造器中直接访问。
即:
- 静态直接访问静态,可以
- 非静态直接访问非静态,可以
- 非静态直接访问静态,可以
- 静态直接访问非静态,不可以
7、在其他类的访问方式区别
静态的类变量和静态的方法可以通过“类名.”的方式直接访问;也可以通过“对象."的方式访问。(但是更推荐使用”类名."的方式)
非静态的实例变量和非静态的方法只能通过“对象."方式访问。
JavaSE_第6章 面向对象基础--中
1 封装概述
1、为什么需要封装?
面向对象编程语言是对客观世界的模拟,客观世界里每一个事物的内部信息都是隐藏在对象内部的,外界无法直接操作和修改,只能通过指定的方式进行访问和修改。封装可以被认为是一个保护屏障,防止该类的代码和数据被其他类随意访问。适当的封装可以让代码更容易理解与维护,也加强了代码的安全性。
2、如何实现封装呢?
实现封装就是指控制类或成员的可见性范围?这就需要依赖访问控制修饰符,也称为权限修饰符来控制。
权限修饰符:public,protected,缺省,private
| 修饰符 | 本类 | 本包 | 其他包子类 | 其他包非子类 |
|---|---|---|---|---|
| private | √ | × | × | × |
| 缺省 | √ | √ | × | × |
| protected | √ | √ | √ | × |
| public | √ | √ | √ | √ |
外部类:public和缺省
成员变量、成员方法、构造器、成员内部类:public,protected,缺省,private
2 成员变量/属性私有化问题
成员变量(field)私有化之后,提供标准的get/set方法,我们把这种成员变量也称为属性(property)。
或者可以说只要能通过get/set操作的就是事物的属性,哪怕它没有对应的成员变量。
1、成员变量封装的目的
- 隐藏类的实现细节
- 让使用者只能通过事先预定的方法来访问数据,从而可以在该方法里面加入控制逻辑,限制对成员变量的不合理访问。还可以进行数据检查,从而有利于保证对象信息的完整性。
- 便于修改,提高代码的可维护性。主要说的是隐藏的部分,在内部修改了,如果其对外可以的访问方式不变的话,外部根本感觉不到它的修改。例如:Java8->Java9,String从char[]转为byte[]内部实现,而对外的方法不变,我们使用者根本感觉不到它内部的修改。
2、实现步骤
- 使用
private修饰成员变量
private 数据类型 变量名 ;
代码如下:
public class Person {
private String name;
private int age;
private boolean marry;
}
- 提供
getXxx方法 /setXxx方法,可以访问成员变量,代码如下:
public class Person {
private String name;
private int age;
private boolean marry;
public void setName(String n) {
name = n;
}
public String getName() {
return name;
}
public void setAge(int a) {
age = a;
}
public int getAge() {
return age;
}
public void setMarry(boolean m){
marry = m;
}
public boolean isMarry(){
return marry;
}
}
3、测试
package com.atguigu.encapsulation;
public class TestPerson {
public static void main(String[] args) {
Person p = new Person();
//实例变量私有化,跨类是无法直接使用的
/* p.name = "张三";
p.age = 23;
p.marry = true;*/
p.setName("张三");
System.out.println("p.name = " + p.getName());
p.setAge(23);
System.out.println("p.age = " + p.getAge());
p.setMarry(true);
System.out.println("p.marry = " + p.isMarry());
}
}
3 继承的概述
Java中的继承
其中,多个类可以称为子类,也叫派生类;多个类抽取出来的这个类称为父类、超类(superclass)或者基类。
继承描述的是事物之间的所属关系,这种关系是:is-a 的关系。例如,图中猫属于动物,狗也属于动物。可见,父类更通用或更一般,子类更具体。我们通过继承,可以使多种事物之间形成一种关系体系。
继承的好处
- 提高代码的复用性。
- 提高代码的扩展性。
- 表示类与类之间的is-a关系
4 继承的语法格式
通过 extends 关键字,可以声明一个子类继承另外一个父类,定义格式如下:
【修饰符】 class 父类 {
...
}
【修饰符】 class 子类 extends 父类 {
...
}
5 子类会继承父类所有的实例变量和实例方法
从类的定义来看,类是一类具有相同特性的事物的抽象描述。父类是所有子类共同特征的抽象描述。而实例变量和实例方法就是事物的特征,那么父类中声明的实例变量和实例方法代表子类事物也有这个特征。
- 当子类对象被创建时,在堆中给对象申请内存时,就要看子类和父类都声明了什么实例变量,这些实例变量都要分配内存。
- 当子类对象调用方法时,编译器会先在子类模板中看该类是否有这个方法,如果没找到,会看它的父类甚至父类的父类是否声明了这个方法,遵循从下往上找的顺序,找到了就停止,一直到根父类都没有找到,就会报编译错误。
6 Java只支持单继承,不支持多重继承
public class A{}
class B extends A{}
//一个类只能有一个父类,不可以有多个直接父类。
class C extends B{} //ok
class C extends A,B... //error
7 Java支持多层继承(继承体系)
class A{}
class B extends A{}
class C extends B{}
顶层父类是Object类。所有的类默认继承Object,作为父类。
8 一个父类可以同时拥有多个子类
class A{}
class B extends A{}
class D extends A{}
class E extends A{}
9 方法重写(Override)
我们说父类的所有方法子类都会继承,但是当某个方法被继承到子类之后,子类觉得父类原来的实现不适合于子类,该怎么办呢?我们可以进行方法重写 (Override)
1、方法重写
比如新的手机增加来电显示头像的功能,代码如下:
package com.atguigu.inherited.method;
public class Phone {
public void sendMessage(){
System.out.println("发短信");
}
public void call(){
System.out.println("打电话");
}
public void showNum(){
System.out.println("来电显示号码");
}
}
package com.atguigu.inherited.method;
//smartphone:智能手机
public class Smartphone extends Phone{
//重写父类的来电显示功能的方法
public void showNum(){
//来电显示姓名和图片功能
System.out.println("显示来电姓名");
System.out.println("显示头像");
}
}
package com.atguigu.inherited.method;
public class TestOverride {
public static void main(String[] args) {
// 创建子类对象
Smartphone sp = new Smartphone();
// 调用父类继承而来的方法
sp.call();
// 调用子类重写的方法
sp.showNum();
}
}
2、重写方法的要求
1.必须保证父子类之间重写方法的名称相同。
2.必须保证父子类之间重写方法的参数列表也完全相同。
2.子类方法的返回值类型必须【小于等于】父类方法的返回值类型(小于其实就是是它的子类,例如:Student < Person)。
注意:如果返回值类型是基本数据类型和void,那么必须是相同
3.子类方法的权限必须【大于等于】父类方法的权限修饰符。
注意:public > protected > 缺省 > private
父类私有方法不能重写
跨包的父类缺省的方法也不能重写
10 普通代码块
和构造器一样,也是用于实例变量的初始化等操作。
1、普通代码块的语法格式
【修饰符】 class 类{
{
普通代码块
}
【修饰符】 构造器名(){
// 实例初始化代码
}
【修饰符】 构造器名(参数列表){
// 实例初始化代码
}
}
11 静态代码块
如果想要为静态变量初始化,可以直接在静态变量的声明后面直接赋值,也可以使用静态代码块。
1、语法格式
在代码块的前面加static,就是静态代码块。
【修饰符】 class 类{
static{
静态代码块
}
}
2、静态代码块的特点
每一个类的静态代码块只会执行一次。
静态代码块的执行优先于非静态代码块和构造器。
12 Object根父类
1、如何理解根父类
类 java.lang.Object是类层次结构的根类,即所有类的父类。每个类都使用 Object 作为超类。
- Object类型的变量与除Object以外的任意引用数据类型的对象都多态引用
- 所有对象(包括数组)都实现这个类的方法。
- 如果一个类没有特别指定父类,那么默认则继承自Object类。例如:
public class MyClass /*extends Object*/ {
// ...
}
2、Object类的其中5个方法
(1)toString()
(2)getClass()
(3)equals()
(4)hashCode()
(5)finalize()
13 final关键字
1、final的意义
final:最终的,不可更改的
2、final修饰类
表示这个类不能被继承,没有子类
final class Eunuch{//太监类
}
class Son extends Eunuch{//错误
}
3、final修饰方法
表示这个方法不能被子类重写
class Father{
public final void method(){
System.out.println("father");
}
}
class Son extends Father{
public void method(){//错误
System.out.println("son");
}
}
4、final修饰变量
final修饰某个变量(成员变量或局部变量),表示它的值就不能被修改,即常量,常量名建议使用大写字母。
如果某个成员变量用final修饰后,没有set方法,并且必须初始化(可以显式赋值、或在初始化块赋值、实例变量还可以在构造器中赋值)
13 多态的形式和体现
1、多态引用
Java规定父类类型的变量可以接收子类类型的对象,这一点从逻辑上也是说得通的。
父类类型 变量名 = 子类对象;
父类类型:指子类继承的父类类型,或者实现的父接口类型。
所以说继承是多态的前提
2、多态引用的表现
表现:编译时类型与运行时类型不一致,编译时看“父类”,运行时看“子类”。
3、多态引用的好处和弊端
弊端:编译时,只能调用父类声明的方法,不能调用子类扩展的方法;
好处:运行时,看“子类”,如果子类重写了方法,一定是执行子类重写的方法体;变量引用的子类对象不同,执行的方法就不同,实现动态绑定。代码编写更灵活、功能更强大,可维护性和扩展性更好了。
14 应用多态解决问题
1、声明变量是父类类型,变量赋值子类对象
- 方法的形参是父类类型,调用方法的实参是子类对象
- 实例变量声明父类类型,实际存储的是子类对象
2、数组元素是父类类型,元素对象是子类对象
3、方法返回值类型声明为父类类型,实际返回的是子类对象
15 向上转型与向下转型
向上转型:自动完成
向下转型:(子类类型)父类变量
package com.atguigu.polymorphism.grammar;
public class ClassCastTest {
public static void main(String[] args) {
//没有类型转换
Dog dog = new Dog();//dog的编译时类型和运行时类型都是Dog
//向上转型
Pet pet = new Dog();//pet的编译时类型是Pet,运行时类型是Dog
pet.setNickname("小白");
pet.eat();//可以调用父类Pet有声明的方法eat,但执行的是子类重写的eat方法体
// pet.watchHouse();//不能调用父类没有的方法watchHouse
Dog d = (Dog) pet;
System.out.println("d.nickname = " + d.getNickname());
d.eat();//可以调用eat方法
d.watchHouse();//可以调用子类扩展的方法watchHouse
Cat c = (Cat) pet;//编译通过,因为从语法检查来说,pet的编译时类型是Pet,Cat是Pet的子类,所以向下转型语法正确
//这句代码运行报错ClassCastException,因为pet变量的运行时类型是Dog,Dog和Cat之间是没有继承关系的
}
}
instanceof关键字
为了避免ClassCastException的发生,Java提供了 instanceof 关键字,给引用变量做类型的校验,只要用instanceof判断返回true的,那么强转为该类型就一定是安全的,不会报ClassCastException异常。
变量/匿名对象 instanceof 数据类型
那么,哪些instanceof判断会返回true呢?
- 变量/匿名对象的编译时类型 与 instanceof后面数据类型是直系亲属关系才可以比较
- 变量/匿名对象的运行时类型<= instanceof后面数据类型,才为true
16 抽象类
1 语法格式
- 抽象方法:被abstract修饰没有方法体的方法。
- 抽象类:被abstract修饰的类。
抽象类的语法格式
【权限修饰符】 abstract class 类名{
}
【权限修饰符】 abstract class 类名 extends 父类{
}
抽象方法的语法格式
【其他修饰符】 abstract 返回值类型 方法名(【形参列表】);
注意:抽象方法没有方法体
代码举例:
public abstract class Animal {
public abstract void eat();
}
public class Cat extends Animal {
public void run (){
System.out.println("小猫吃鱼和猫粮");
}
}
public class CatTest {
public static void main(String[] args) {
// 创建子类对象
Cat c = new Cat();
// 调用eat方法
c.eat();
}
}
此时的方法重写,是子类对父类抽象方法的完成实现,我们将这种方法重写的操作,也叫做实现方法。
2 注意事项
关于抽象类的使用,以下为语法上要注意的细节,虽然条目较多,但若理解了抽象的本质,无需死记硬背。
-
抽象类不能创建对象,如果创建,编译无法通过而报错。只能创建其非抽象子类的对象。
理解:假设创建了抽象类的对象,调用抽象的方法,而抽象方法没有具体的方法体,没有意义。
-
抽象类中,也有构造方法,是供子类创建对象时,初始化父类成员变量使用的。
理解:子类的构造方法中,有默认的super()或手动的super(实参列表),需要访问父类构造方法。
-
抽象类中,不一定包含抽象方法,但是有抽象方法的类必定是抽象类。
理解:未包含抽象方法的抽象类,目的就是不想让调用者创建该类对象,通常用于某些特殊的类结构设计。
-
抽象类的子类,必须重写抽象父类中所有的抽象方法,否则,编译无法通过而报错。除非该子类也是抽象类。
理解:假设不重写所有抽象方法,则类中可能包含抽象方法。那么创建对象后,调用抽象的方法,没有意义。
17 接口
1 定义格式
接口的定义,它与定义类方式相似,但是使用 interface 关键字。它也会被编译成.class文件,但一定要明确它并不是类,而是另外一种引用数据类型。
引用数据类型:数组,类,枚举,接口,注解。
1、接口的声明格式
【修饰符】 interface 接口名{
//接口的成员列表:
// 公共的静态常量
// 公共的抽象方法
// 公共的默认方法(JDK1.8以上)
// 公共的静态方法(JDK1.8以上)
// 私有方法(JDK1.9以上)
}
2、接口的成员说明
接口定义的是多个类共同的公共行为规范,这些行为规范是与外部交流的通道,这就意味着接口里通常是定义一组公共方法。
在JDK8之前,接口中只允许出现:
(1)公共的静态的常量:其中public static final可以省略
(2)公共的抽象的方法:其中public abstract可以省略
理解:接口是从多个相似类中抽象出来的规范,不需要提供具体实现
在JDK1.8时,接口中允许声明默认方法和静态方法:
(3)公共的默认的方法:其中public 可以省略,建议保留,但是default不能省略
(4)公共的静态的方法:其中public 可以省略,建议保留,但是static不能省略
在JDK1.9时,接口又增加了:
(5)私有方法
除此之外,接口中不能有其他成员,没有构造器,没有初始化块,因为接口中没有成员变量需要动态初始化。
2 接口的使用
1、使用接口的静态成员
接口不能直接创建对象,但是可以通过接口名直接调用接口的静态方法和静态常量。
package com.atguigu.interfacetype;
public class TestUsb3 {
public static void main(String[] args) {
//通过“接口名.”调用接口的静态方法
Usb3.show();
//通过“接口名.”直接使用接口的静态常量
System.out.println(Usb3.MAX_SPEED);
}
}
2、类实现接口(implements)
接口不能创建对象,但是可以被类实现(implements ,类似于被继承)。
类与接口的关系为实现关系,即类实现接口,该类可以称为接口的实现类,也可以称为接口的子类。实现的动作类似继承,格式相仿,只是关键字不同,实现使用 implements关键字。
【修饰符】 class 实现类 implements 接口{
// 重写接口中抽象方法【必须】,当然如果实现类是抽象类,那么可以不重写
// 重写接口中默认方法【可选】
}
【修饰符】 class 实现类 extends 父类 implements 接口{
// 重写接口中抽象方法【必须】,当然如果实现类是抽象类,那么可以不重写
// 重写接口中默认方法【可选】
}
注意:
-
如果接口的实现类是非抽象类,那么必须重写接口中所有抽象方法。
-
默认方法可以选择保留,也可以重写。
重写时,default单词就不要再写了,它只用于在接口中表示默认方法,到类中就没有默认方法的概念了
-
接口中的静态方法不能被继承也不能被重写
示例代码:
package com.atguigu.interfacetype;
public class MobileHDD implements Usb3 {
//重写/实现接口的抽象方法,【必选】
public void out() {
System.out.println("读取数据并发送");
}
public void in(){
System.out.println("接收数据并写入");
}
//重写接口的默认方法,【可选】
//重写默认方法时,default单词去掉
public void end(){
System.out.println("清理硬盘中的隐藏回收站中的东西,再结束");
}
}
3、使用接口的非静态方法
- 对于接口的静态方法,直接使用“接口名.”进行调用即可
- 也只能使用“接口名."进行调用,不能通过实现类的对象进行调用
- 对于接口的抽象方法、默认方法,只能通过实现类对象才可以调用
- 接口不能直接创建对象,只能创建实现类的对象
package com.atguigu.interfacetype;
public class TestMobileHDD {
public static void main(String[] args) {
//创建实现类对象
MobileHDD b = new MobileHDD();
//通过实现类对象调用重写的抽象方法,以及接口的默认方法,如果实现类重写了就执行重写的默认方法,如果没有重写,就执行接口中的默认方法
b.start();
b.in();
b.stop();
//通过接口名调用接口的静态方法
// MobileHDD.show();
// b.show();
Usb3.show();
}
}
4、接口的多实现(implements)
之前学过,在继承体系中,一个类只能继承一个父类。而对于接口而言,一个类是可以实现多个接口的,这叫做接口的多实现。并且,一个类能继承一个父类,同时实现多个接口。
实现格式:
【修饰符】 class 实现类 implements 接口1,接口2,接口3。。。{
// 重写接口中所有抽象方法【必须】,当然如果实现类是抽象类,那么可以不重写
// 重写接口中默认方法【可选】
}
【修饰符】 class 实现类 extends 父类 implements 接口1,接口2,接口3。。。{
// 重写接口中所有抽象方法【必须】,当然如果实现类是抽象类,那么可以不重写
// 重写接口中默认方法【可选】
}
接口中,有多个抽象方法时,实现类必须重写所有抽象方法。如果抽象方法有重名的,只需要重写一次。
定义多个接口:
package com.atguigu.interfacetype;
public interface A {
void showA();
void show();
}
package com.atguigu.interfacetype;
public interface B extends A {
void showB();
void show();
}
定义实现类:
package com.atguigu.interfacetype;
public class C implements A,B {
@Override
public void showA() {
System.out.println("showA");
}
@Override
public void showB() {
System.out.println("showB");
}
@Override
public void show() {
System.out.println("show");
}
}
测试类
package com.atguigu.interfacetype;
public class TestC {
public static void main(String[] args) {
C c = new C();
c.showA();
c.showB();
c.show();
}
}
5、接口的多继承 (extends)
一个接口能继承另一个或者多个接口,接口的继承也使用 extends 关键字,子接口继承父接口的方法。
定义父接口:
package com.atguigu.interfacetype;
public interface Chargeable {
void charge();
void in();
void out();
}
定义子接口:
package com.atguigu.interfacetype;
public interface UsbC extends Chargeable,Usb3 {
void reverse();
}
定义子接口的实现类:
package com.atguigu.interfacetype;
public class TypeCConverter implements UsbC {
@Override
public void reverse() {
System.out.println("正反面都支持");
}
@Override
public void charge() {
System.out.println("可充电");
}
@Override
public void in() {
System.out.println("接收数据");
}
@Override
public void out() {
System.out.println("输出数据");
}
}
所有父接口的抽象方法都有重写。
方法签名相同的抽象方法只需要实现一次。
6、接口与实现类对象构成多态引用
实现类实现接口,类似于子类继承父类,因此,接口类型的变量与实现类的对象之间,也可以构成多态引用。通过接口类型的变量调用方法,最终执行的是你new的实现类对象实现的方法体。
接口的不同实现类:
package com.atguigu.interfacetype;
public class Mouse implements Usb3 {
@Override
public void out() {
System.out.println("发送脉冲信号");
}
@Override
public void in() {
System.out.println("不接收信号");
}
}
package com.atguigu.interfacetype;
public class KeyBoard implements Usb3{
@Override
public void in() {
System.out.println("不接收信号");
}
@Override
public void out() {
System.out.println("发送按键信号");
}
}
JavaSE_第7章 面向对象基础(下)
1 枚举
某些类型的对象是有限的几个,这样的例子举不胜举:
- 星期:Monday(星期一)......Sunday(星期天)
- 性别:Man(男)、Woman(女)
- 月份:January(1月)......December(12月)
- 季节:Spring(春节)......Winter(冬天)
- 支付方式:Cash(现金)、WeChatPay(微信)、Alipay(支付宝)、BankCard(银行卡)、CreditCard(信用卡)
- 员工工作状态:Busy(忙)、Free(闲)、Vocation(休假)
- 订单状态:Nonpayment(未付款)、Paid(已付款)、Fulfilled(已配货)、Delivered(已发货)、Checked(已确认收货)、Return(退货)、Exchange(换货)、Cancel(取消)
枚举类型本质上也是一种类,只不过是这个类的对象是固定的几个,而不能随意让用户创建。
在JDK1.5之前,需要程序员自己通过特殊的方式来定义枚举类型。
在JDK1.5之后,Java支持enum关键字来快速的定义枚举类型。
2 JDK1.5之前
在JDK1.5之前如何声明枚举类呢?
- 构造器加private私有化
- 本类内部创建一组常量对象,并添加public static修饰符,对外暴露这些常量对象
示例代码:
public class Season{
public static final Season SPRING = new Season();
public static final Season SUMMER = new Season();
public static final Season AUTUMN = new Season();
public static final Season WINTER = new Season();
private Season(){
}
public String toString(){
if(this == SPRING){
return "春";
}else if(this == SUMMER){
return "夏";
}else if(this == AUTUMN){
return "秋";
}else{
return "冬";
}
}
}
public class TestSeason {
public static void main(String[] args) {
Season spring = Season.SPRING;
System.out.println(spring);
}
}
3 JDK1.5之后
1、enum关键字声明枚举
【修饰符】 enum 枚举类名{
常量对象列表
}
【修饰符】 enum 枚举类名{
常量对象列表;
其他成员列表;
}
示例代码:
package com.atguigu.enumeration;
public enum Week {
MONDAY,TUESDAY,WEDNESDAY,THURSDAY,FRIDAY,SATURDAY,SUNDAY
}
public class TestEnum {
public static void main(String[] args) {
Season spring = Season.SPRING;
System.out.println(spring);
}
}
3、枚举类型常用方法
1.String toString(): 默认返回的是常量名(对象名),可以继续手动重写该方法!
2.String name():返回的是常量名(对象名)
3.int ordinal():返回常量的次序号,默认从0开始
4.枚举类型[] values():返回该枚举类的所有的常量对象,返回类型是当前枚举的数组类型,是一个静态方法
5.枚举类型 valueOf(String name):根据枚举常量对象名称获取枚举对象
4 包装类
Java提供了两个类型系统,基本类型与引用类型,使用基本类型在于效率,然而当要使用只针对对象设计的API或新特性(例如泛型),那么基本数据类型的数据就需要用包装类来包装。
| 序号 | 基本数据类型 | 包装类(java.lang包) |
|---|---|---|
| 1 | byte | Byte |
| 2 | short | Short |
| 3 | int | Integer |
| 4 | long | Long |
| 5 | float | Float |
| 6 | double | Double |
| 7 | char | Character |
| 8 | boolean | Boolean |
| 9 | void | Void |
5 装箱与拆箱
装箱:把基本数据类型转为包装类对象。
转为包装类的对象,是为了使用专门为对象设计的API和特性
拆箱:把包装类对象拆为基本数据类型。
转为基本数据类型,一般是因为需要运算,Java中的大多数运算符是为基本数据类型设计的。比较、算术等
JDK1.5之后,可以自动装箱与拆箱。
注意:只能与自己对应的类型之间才能实现自动装箱与拆箱。
Integer i = 4;//自动装箱。相当于Integer i = Integer.valueOf(4);
i = i + 5;//等号右边:将i对象转成基本数值(自动拆箱) i.intValue() + 5;
//加法运算完成后,再次装箱,把基本数值转成对象。
Integer i = 1;
Double d = 1;//错误的,1是int类型
6 包装类的一些API
1、基本数据类型和字符串之间的转换
(1)把基本数据类型转为字符串
int a = 10;
//String str = a;//错误的
//方式一:
String str = a + "";
//方式二:
String str = String.valueOf(a);
(2)把字符串转为基本数据类型
int a = Integer.parseInt("整数的字符串");
double d = Double.parseDouble("小数的字符串");
boolean b = Boolean.parseBoolean("true或false");
int a = Integer.valueOf("整数的字符串");
double d = Double.valueOf("小数的字符串");
boolean b = Boolean.valueOf("true或false");
7 内部类
1、什么是内部类?
将一个类A定义在另一个类B里面,里面的那个类A就称为内部类,B则称为外部类。
2、为什么要声明内部类呢?
总的来说,遵循高内聚低耦合的面向对象开发总原则。便于代码维护和扩展。
具体来说,当一个事物的内部,还有一个部分需要一个完整的结构进行描述,而这个内部的完整的结构又只为外部事物提供服务,不在其他地方单独使用,那么整个内部的完整结构最好使用内部类。而且内部类因为在外部类的里面,因此可以直接访问外部类的私有成员。
3、内部类都有哪些形式?
根据内部类声明的位置(如同变量的分类),我们可以分为:
(1)成员内部类:
- 静态成员内部类
- 非静态成员内部类
(2)局部内部类
- 有名字的局部内部类
- 匿名的内部类
1、成员内部类
如果成员内部类中不使用外部类的非静态成员,那么通常将内部类声明为静态内部类,否则声明为非静态内部类。
语法格式:
【修饰符】 class 外部类{
【其他修饰符】 【static】 class 内部类{
}
}
2、局部内部类
语法格式:
【修饰符】 class 外部类{
【修饰符】 返回值类型 方法名(【形参列表】){
【final/abstract】 class 内部类{
}
}
}
3、匿名内部类
new 父类(【实参列表】){
重写方法...
}
//()中是否需要【实参列表】,看你想要让这个匿名内部类调用父类的哪个构造器,如果调用父类的无参构造,那么()中就不用写参数,如果调用父类的有参构造,那么()中需要传入实参
new 父接口(){
重写方法...
}
//()中没有参数,因为此时匿名内部类的父类是Object类,它只有一个无参构造
匿名内部类是没有名字的类,因此在声明类的同时就创建好了唯一的对象。
8 什么是注解
注解是以“@注释名”在代码中存在的,还可以添加一些参数值,例如:
@SuppressWarnings(value=”unchecked”)
@Override
@Deprecated
注解Annotation是从JDK5.0开始引入。
虽然说注解也是一种注释,因为它们都不会改变程序原有的逻辑,只是对程序增加了某些注释性信息。不过它又不同于单行注释和多行注释,对于单行注释和多行注释是给程序员看的,而注解是可以被编译器或其他程序读取的一种注释,程序还可以根据注解的不同,做出相应的处理。所以注解是插入到代码中以便有工具可以对它们进行处理的标签。
1、 三个最基本的注解
1、@Override
用于检测被修饰的方法为有效的重写方法,如果不是,则报编译错误!
只能标记在方法上。
它会被编译器程序读取。
2、@Deprecated
用于表示被标记的数据已经过时,不建议使用。
可以用于修饰 属性、方法、构造、类、包、局部变量、参数。
它会被编译器程序读取。
3、@SuppressWarnings
抑制编译警告。
可以用于修饰类、属性、方法、构造、局部变量、参数
它会被编译器程序读取。
JavaSE_第8章 异常
1 认识Java的异常
1、什么是异常
在使用计算机语言进行项目开发的过程中,即使程序员把代码写得尽善尽美,在系统的运行过程中仍然会遇到一些问题,因为很多问题不是靠代码能够避免的,比如:客户输入数据的格式问题,读取文件是否存在,网络是否始终保持通畅等等。
- 异常 :指的是程序在执行过程中,出现的非正常的情况,如果不处理最终会导致JVM的非正常停止。
异常指的并不是语法错误,语法错了,编译不通过,不会产生字节码文件,根本不能运行.
异常也不是指逻辑代码错误而没有得到想要的结果,例如:求a与b的和,你写成了a-b
2、如何对待异常
程序员在编写程序时,就应该充分考虑到各种可能发生的异常和错误,极力预防和避免,实在无法避免的,要编写相应的代码进行异常的检测、异常消息的提示,以及异常的处理。
3、异常的抛出机制
Java中是如何表示不同的异常情况,又是如何让程序员得知,并处理异常的呢?
Java中把不同的异常用不同的类表示,一旦发生某种异常,就通过创建该异常类型的对象,并且抛出,然后程序员可以catch到这个异常对象,并处理,如果无法catch到这个异常对象,那么这个异常对象将会导致程序终止。
运行下面的程序,程序会产生一个数组索引越界异常ArrayIndexOfBoundsException。我们通过图解来解析下异常产生和抛出的过程。
2 Java异常体系
1、Throwable
java.lang.Throwable 类是 Java 语言中所有错误或异常的超类。
- 只有当对象是此类(或其子类之一)的实例时,才能通过 Java 虚拟机或者 Java 的
throw语句抛出。类似地,只有此类或其子类之一才可以是catch子句中的参数类型。
2、Error和Exception
Throwable有两个直接子类:java.lang.Error与java.lang.Exception,平常所说的异常指java.lang.Exception。
- Error:表示严重错误,一旦发生必须停下来查看问题并解决问题才能继续,无法仅仅通过try...catch解决的错误。(如果拿生病做比喻,就像是突发疾病,而且是危重症,必须立刻停下来治疗而不是靠短暂休息、吃药、打针、或小手术简单解决处理)
- 例如:StackOverflowError(栈内存溢出)和OutOfMemoryError(堆内存溢出,简称OOM)。
- Exception:表示普通异常,其它因编程错误或偶然的外在因素导致的一般性问题,程序员可以通过代码的方式检测、提示和纠正,使程序继续运行,但是只要发生也是必须处理,否则程序也会挂掉。(这就好比普通感冒、阑尾炎、牙疼等,可以通过短暂休息、吃药、打针、或小手术简单解决,但是也不能搁置不处理,不然也会要人命)。
- 例如:空指针访问、试图读取不存在的文件、网络连接中断、数组下标越界等
3 受检异常和非受检异常
我们平常说的异常就是指Exception,根据代码的编写编译阶段,编译器是否会警示当前代码可能发生xx异常,并督促程序员提前编写处理它的代码为依据,可以将异常分为:
- 编译时期异常(即checked异常、受检异常):在代码编译阶段,编译器就能明确警示当前代码可能发生(不是一定发生)xx异常,并督促程序员提前编写处理它的代码。如果程序员不听话,没有编写对应的异常处理代码,则编译器就会发威,直接判定编译失败,从而程序无法执行。通常,这类异常的发生不是由程序员的代码引起的,或者不是靠加简单判断就可以避免的,例如:FileNotFoundException(文件找不到异常)。
- 运行时期异常(即runtime异常、unchecked非受检异常):即在代码编译阶段,编译器完全不做任何检查,无论该异常是否会发生,编译器都不给出任何提示。只有等代码运行起来并确实发生了xx异常,它才能被发现。通常,这类异常是由程序员的代码编写不当引起的,只要稍加判断,或者细心检查就可以避免的。例如:ArrayIndexOutOfBoundsException数组下标越界异常,ClassCastException类型转换异常。
4 捕获异常try…catch
1、try...catch基本格式
捕获异常语法如下:
try{
可能发生xx异常的代码
}catch(异常类型1 e){
处理异常的代码1
}catch(异常类型2 e){
处理异常的代码2
}
....
try{}中编写可能发生xx异常的业务逻辑代码。
catch分支,分为两个部分,catch()中编写异常类型和异常参数名,{}中编写如果发生了这个异常,要做什么处理的代码。如果有多个catch分支,并且多个异常类型有父子类关系,必须保证小的子异常类型在上,大的父异常类型在下。
当某段代码可能发生异常,不管这个异常是编译时异常(受检异常)还是运行时异常(非受检异常),我们都可以使用try块将它括起来,并在try块下面编写catch分支尝试捕获对应的异常对象。
- 如果在程序运行时,try块中的代码没有发生异常,那么catch所有的分支都不执行。
- 如果在程序运行时,try块中的代码发生了异常,根据异常对象的类型,将从上到下选择第一个匹配的catch分支执行。此时try中发生异常的语句下面的代码将不执行,而整个try...catch之后的代码可以继续运行。
- 如果在程序运行时,try块中的代码发生了异常,但是所有catch分支都无法匹配(捕获)这个异常,那么JVM将会终止当前方法的执行,并把异常对象“抛”给调用者。如果调用者不处理,程序就挂了。
5 finally块
因为异常会引发程序跳转,从而会导致有些语句执行不到。而程序中有一些特定的代码无论异常是否发生,都需要执行。例如,IO流的关闭,数据库连接的断开等。这样的代码通常就会放到finally块中。
try{
}catch(...){
}finally{
无论try中是否发生异常,也无论catch是否捕获异常,也不管try和catch中是否有return语句,都一定会执行
}
或
try{
}finally{
无论try中是否发生异常,也不管try中是否有return语句,都一定会执行。
}
注意:finally不能单独使用。
当只有在try或者catch中调用退出JVM的相关方法,例如System.exit(0),此时finally才不会执行,否则finally永远会执行。
5 转换异常处理位置throws
1、throws编译时异常
如果在编写方法体的代码时,某句代码可能发生某个编译时异常,不处理编译不通过,但是在当前方法体中可能不适合处理或无法给出合理的处理方式,就可以通过throws在方法签名中声明该方法可能会发生xx异常,需要调用者处理。
声明异常格式:
修饰符 返回值类型 方法名(参数) throws 异常类名1,异常类名2…{ }
6 异常throw
Java程序的执行过程中如出现异常,会生成一个异常类对象,该异常对象将被提交给Java运行时系统,这个过程称为抛出(throw)异常。异常对象的生成有两种方式:
- 由虚拟机自动生成:程序运行过程中,虚拟机检测到程序发生了问题,就会在后台自动创建一个对应异常类的实例对象并抛出——自动抛出。
- 由开发人员手动创建:new 异常类型(【实参列表】);,如果创建好的异常对象不抛出对程序没有任何影响,和创建一个普通对象一样,但是一旦throw抛出,就会对程序运行产生影响了。
使用格式:
throw new 异常类名(参数);
7 自定义异常
为什么需要自定义异常类:
我们说了Java中不同的异常类,分别表示着某一种具体的异常情况,那么在开发中总是有些异常情况是核心类库中没有定义好的,此时我们需要根据自己业务的异常情况来定义异常类。例如年龄负数问题,考试成绩负数问题等等。
异常类如何定义:
- 自定义一个编译时异常类型:自定义类 并继承
java.lang.Exception。 - 自定义一个运行时异常类型:自定义类 并继承
java.lang.RuntimeException。
注意自定义的异常只能通过throw抛出。
演示自定义异常:
package com.atguigu.define;
public class NotTriangleException extends Exception{
public NotTriangleException() {
}
public NotTriangleException(String message) {
super(message);
}
}
JavaSE_第9章 多线程
1 线程与进程
-
程序:为了完成某个任务和功能,选择一种编程语言编写的一组指令的集合。
-
软件:1个或多个应用程序+相关的素材和资源文件等构成一个软件系统。
-
进程:是指一个内存中运行的应用程序,每个进程都有一个独立的内存空间,进程也是程序的一次执行过程,是系统运行程序的基本单位;系统运行一个程序即是一个进程从创建、运行到消亡的过程。
-
线程:线程是进程中的一个执行单元,负责当前进程中程序的执行,一个进程中至少有一个线程。一个进程中是可以有多个线程的,这个应用程序也可以称之为多线程程序。
简而言之:一个软件中至少有一个应用程序,应用程序的一次运行就是一个进程,一个进程中至少有一个线程。
2 并发与并行
-
并行(parallel):指两个或多个事件在同一时刻发生(同时发生)。指在同一时刻,有多条指令在多个处理器上同时执行。
-
并发(concurrency):指两个或多个事件在同一个时间段内发生。指在同一个时刻只能有一条指令执行,但多个进程的指令被快速轮换执行,使得在宏观上具有多个进程同时执行的效果。
-
并行:多项工作一起执行,之后再汇总,例如:泡方便面,电水壶烧水,一边撕调料倒入桶中
-
并发:同一时刻多个线程在访问同一个资源,多个线程对一个点,例如:春运抢票、电商秒杀...
注意:单核处理器的计算机肯定是不能并行的处理多个任务的,只能是多个任务在单个CPU上并发运行。同理,线程也是一样的,从宏观角度上理解线程是并行运行的,但是从微观角度上分析却是串行运行的,即一个线程一个线程的去运行,当系统只有一个CPU时,线程会以某种顺序执行多个线程,我们把这种情况称之为线程调度。
单核CPU:只能并发
多核CPU:并行+并发
3 线程调度
-
分时调度
所有线程轮流使用 CPU 的使用权,平均分配每个线程占用 CPU 的时间。
-
抢占式调度
优先让优先级高的线程使用 CPU,如果线程的优先级相同,那么会随机选择一个(线程随机性),Java使用的为抢占式调度。
-
抢占式调度详解
大部分操作系统都支持多进程并发运行,现在的操作系统几乎都支持同时运行多个程序。比如:现在我们上课一边使用编辑器,一边使用录屏软件,同时还开着画图板,dos窗口等软件。此时,这些程序是在同时运行,”感觉这些软件好像在同一时刻运行着“。
实际上,CPU(中央处理器)使用抢占式调度模式在多个线程间进行着高速的切换。对于CPU的一个核而言,某个时刻,只能执行一个线程,而 CPU的在多个线程间切换速度相对我们的感觉要快,看上去就是在同一时刻运行。
其实,多线程程序并不能提高程序的运行速度,但能够提高程序运行效率,让CPU的使用率更高。
-
4 继承Thread类
Java使用java.lang.Thread类代表线程,所有的线程对象都必须是Thread类或其子类的实例。每个线程的作用是完成一定的任务,实际上就是执行一段程序流即一段顺序执行的代码。Java使用线程执行体来代表这段程序流。Java中通过继承Thread类来创建并启动多线程的步骤如下:
- 定义Thread类的子类,并重写该类的run()方法,该run()方法的方法体就代表了线程需要完成的任务,因此把run()方法称为线程执行体。
- 创建Thread子类的实例,即创建了线程对象
- 调用线程对象的start()方法来启动该线程
5 实现Runnable接口
Java有单继承的限制,当我们无法继承Thread类时,那么该如何做呢?在核心类库中提供了Runnable接口,我们可以实现Runnable接口,重写run()方法,然后再通过Thread类的对象代理启动和执行我们的线程体run()方法
步骤如下:
- 定义Runnable接口的实现类,并重写该接口的run()方法,该run()方法的方法体同样是该线程的线程执行体。
- 创建Runnable实现类的实例,并以此实例作为Thread的target来创建Thread对象,该Thread对象才是真正
的线程对象。 - 调用线程对象的start()方法来启动线程。
代码如下:
6 Thread类构造方法
public Thread() :分配一个新的线程对象。
public Thread(String name) :分配一个指定名字的新的线程对象。
public Thread(Runnable target) :分配一个带有指定目标新的线程对象。
public Thread(Runnable target,String name) :分配一个带有指定目标新的线程对象并指定名字。
7 Thread类常用方法系列1
-
public void run() :此线程要执行的任务在此处定义代码。
-
public String getName() :获取当前线程名称。
-
public static Thread currentThread() :返回对当前正在执行的线程对象的引用。
-
public final boolean isAlive():测试线程是否处于活动状态。如果线程已经启动且尚未终止,则为活动状态。
-
public final int getPriority() :返回线程优先级
-
public final void setPriority(int newPriority) :改变线程的优先级
- 每个线程都有一定的优先级,优先级高的线程将获得较多的执行机会。每个线程默认的优先级都与创建它的父线程具有相同的优先级。Thread类提供了setPriority(int newPriority)和getPriority()方法类设置和获取线程的优先级,其中setPriority方法需要一个整数,并且范围在[1,10]之间,通常推荐设置Thread类的三个优先级常量:
- MAX_PRIORITY(10):最高优先级
- MIN _PRIORITY (1):最低优先级
- NORM_PRIORITY (5):普通优先级,默认情况下main线程具有普通优先级。
-
public void start() :导致此线程开始执行; Java虚拟机调用此线程的run方法。
-
public static void sleep(long millis) :使当前正在执行的线程以指定的毫秒数暂停(暂时停止执行)。
-
public static void yield():yield只是让当前线程暂停一下,让系统的线程调度器重新调度一次,希望优先级与当前线程相同或更高的其他线程能够获得执行机会,但是这个不能保证,完全有可能的情况是,当某个线程调用了yield方法暂停之后,线程调度器又将其调度出来重新执行。
-
void join() :等待该线程终止。
void join(long millis) :等待该线程终止的时间最长为 millis 毫秒。如果millis时间到,将不再等待。
void join(long millis, int nanos) :等待该线程终止的时间最长为 millis 毫秒 + nanos 纳秒。
8 线程安全
当我们使用多个线程访问同一资源(可以是同一个变量、同一个文件、同一条记录等)的时候,若多个线程只有读操作,那么不会发生线程安全问题,但是如果多个线程中对资源有读和写的操作,就容易出现线程安全问题。
9 尝试解决线程安全问题
要解决上述多线程并发访问一个资源的安全性问题:也就是解决重复票与不存在票问题,Java中提供了同步机制
(synchronized)来解决。
1、同步机制的原理
同步解决线程安全的原理:
同步机制的原理,其实就相当于给某段代码加“锁”,任何线程想要执行这段代码,都要先获得“锁”,我们称为它同步锁。因为Java对象在堆中的数据分为分为对象头、实例变量、空白的填充。而对象头中包含:
- Mark Word:记录了和当前对象有关的GC、锁标记等信息。
- 指向类的指针:每一个对象需要记录它是由哪个类创建出来的。
- 数组长度(只有数组对象才有)
哪个线程获得了“同步锁”对象之后,”同步锁“对象就会记录这个线程的ID,这样其他线程就只能等待了,除非这个线程”释放“了锁对象,其他线程才能重新获得/占用”同步锁“对象。
2、同步代码块和同步方法
同步方法:synchronized 关键字直接修饰方法,表示同一时刻只有一个线程能进入这个方法,其他线程在外面等着。
public synchronized void method(){
可能会产生线程安全问题的代码
}
同步代码块:synchronized 关键字可以用于某个区块前面,表示只对这个区块的资源实行互斥访问。
格式:
synchronized(同步锁){
需要同步操作的代码
}
3、同步锁对象的选择
同步锁对象可以是任意类型,但是必须保证竞争“同一个共享资源”的多个线程必须使用同一个“同步锁对象”。
对于同步代码块来说,同步锁对象是由程序员手动指定的,但是对于同步方法来说,同步锁对象只能是默认的,
- 静态方法:当前类的Class对象
- 非静态方法:this
4、同步代码的范围选择
锁的范围太小:不能解决安全问题
锁的范围太大:因为一旦某个线程抢到锁,其他线程就只能等待,所以范围太大,效率会降低,不能合理利用CPU资源。
10 线程间通信
为什么要处理线程间通信:
多个线程在处理同一个资源,但是处理的动作(线程的任务)却不相同。而多个线程并发执行时, 在默认情况下CPU是随机切换线程的,当我们需要多个线程来共同完成一件任务,并且我们希望他们有规律的执行, 那么多线程之间需要一些通信机制,可以协调它们的工作,以此来帮我们达到多线程共同操作一份数据。
比如:线程A用来生成包子的,线程B用来吃包子的,包子可以理解为同一资源,线程A与线程B处理的动作,一个是生产,一个是消费,此时B线程必须等到A线程完成后才能执行,那么线程A与线程B之间就需要线程通信,即—— 等待唤醒机制。
11 等待唤醒机制
什么是等待唤醒机制
这是多个线程间的一种协作机制。谈到线程我们经常想到的是线程间的竞争(race),比如去争夺锁,但这并不是故事的全部,线程间也会有协作机制。
就是在一个线程满足某个条件时,就进入等待状态(wait()/wait(time)), 等待其他线程执行完他们的指定代码过后再将其唤醒(notify());或可以指定wait的时间,等时间到了自动唤醒;在有多个线程进行等待时,如果需要,可以使用 notifyAll()来唤醒所有的等待线程。wait/notify 就是线程间的一种协作机制。
- wait:线程不再活动,不再参与调度,进入 wait set 中,因此不会浪费 CPU 资源,也不会去竞争锁了,这时的线程状态即是 WAITING或TIMED_WAITING。它还要等着别的线程执行一个特别的动作,也即是“通知(notify)”或者等待时间到,在这个对象上等待的线程从wait set 中释放出来,重新进入到调度队列(ready queue)中
- notify:则选取所通知对象的 wait set 中的一个线程释放;
- notifyAll:则释放所通知对象的 wait set 上的全部线程。
注意:
被通知线程被唤醒后也不一定能立即恢复执行,因为它当初中断的地方是在同步块内,而此刻它已经不持有锁,所以她需要再次尝试去获取锁(很可能面临其它线程的竞争),成功后才能在当初调用 wait 方法之后的地方恢复执行。
总结如下:
- 如果能获取锁,线程就从 WAITING 状态变成 RUNNABLE(可运行) 状态;
- 否则,线程就从 WAITING 状态又变成 BLOCKED(等待锁) 状态
调用wait和notify方法需要注意的细节
- wait方法与notify方法必须要由同一个锁对象调用。因为:对应的锁对象可以通过notify唤醒使用同一个锁对象调用的wait方法后的线程。
- wait方法与notify方法是属于Object类的方法的。因为:锁对象可以是任意对象,而任意对象的所属类都是继承了Object类的。
- wait方法与notify方法必须要在同步代码块或者是同步函数中使用。因为:必须要通过锁对象调用这2个方法。
12 生产者与消费者问题
等待唤醒机制可以解决经典的“生产者与消费者”的问题。
生产者与消费者问题(英语:Producer-consumer problem),也称有限缓冲问题(英语:Bounded-buffer problem),是一个多线程同步问题的经典案例。该问题描述了两个(多个)共享固定大小缓冲区的线程——即所谓的“生产者”和“消费者”——在实际运行时会发生的问题。生产者的主要作用是生成一定量的数据放到缓冲区中,然后重复此过程。与此同时,消费者也在缓冲区消耗这些数据。该问题的关键就是要保证生产者不会在缓冲区满时加入数据,消费者也不会在缓冲区中空时消耗数据。
生产者与消费者问题中其实隐含了两个问题:
- 线程安全问题:因为生产者与消费者共享数据缓冲区,不过这个问题可以使用同步解决。
- 线程的协调工作问题:
- 要解决该问题,就必须让生产者线程在缓冲区满时等待(wait),暂停进入阻塞状态,等到下次消费者消耗了缓冲区中的数据的时候,通知(notify)正在等待的线程恢复到就绪状态,重新开始往缓冲区添加数据。同样,也可以让消费者线程在缓冲区空时进入等待(wait),暂停进入阻塞状态,等到生产者往缓冲区添加数据之后,再通知(notify)正在等待的线程恢复到就绪状态。通过这样的通信机制来解决此类问题。
13 观点1:5种状态(JDK1.5之前)
简单来说,线程的生命周期有五种状态:新建(New)、就绪(Runnable)、运行(Running)、阻塞(Blocked)、死亡(Dead)。CPU需要在多条线程之间切换,于是线程状态会多次在运行、阻塞、就绪之间切换。
14 观点2:6种状态(JDK1.5之后)
在java.lang.Thread.State的枚举类中这样定义:
public enum State {
NEW,
RUNNABLE,
BLOCKED,
WAITING,
TIMED_WAITING,
TERMINATED;
}
首先它没有区分:就绪和运行状态,因为对于Java对象来说,只能标记为可运行,至于什么时候运行,不是JVM来控制的了,是OS来进行调度的,而且时间非常短暂,因此对于Java对象的状态来说,无法区分。只能我们人为的进行想象和理解。
其次根据Thread.State的定义,阻塞状态是分为三种的:BLOCKED、WAITING、TIMED_WAITING。
- BLOCKED:是指互有竞争关系的几个线程,其中一个线程占有锁对象时,其他线程只能等待锁。只有获得锁对象的线程才能有执行机会。
- TIMED_WAITING:当前线程执行过程中遇到Thread类的sleep或join,Object类的wait,LockSupport类的park方法,并且在调用这些方法时,设置了时间,那么当前线程会进入TIMED_WAITING,直到时间到,或被中断。
- WAITING:当前线程执行过程中遇到遇到Object类的wait,Thread类的join,LockSupport类的park方法,并且在调用这些方法时,没有指定时间,那么当前线程会进入WAITING状态,直到被唤醒。
- 通过Object类的wait进入WAITING状态的要有Object的notify/notifyAll唤醒;
- 通过Condition的await进入WAITING状态的要有Conditon的signal方法唤醒;
- 通过LockSupport类的park方法进入WAITING状态的要有LockSupport类的unpark方法唤醒
- 通过Thread类的join进入WAITING状态,只有调用join方法的线程对象结束才能让当前线程恢复;
说明:当从WAITING或TIMED_WAITING恢复到Runnable状态时,如果发现当前线程没有得到监视器锁,那么会立刻转入BLOCKED状态。
15 释放锁操作与死锁
任何线程进入同步代码块、同步方法之前,必须先获得对同步监视器的锁定,那么何时会释放对同步监视器的锁定呢?
1、释放锁的操作
当前线程的同步方法、同步代码块执行结束。
当前线程在同步代码块、同步方法中出现了未处理的Error或Exception,导致当前线程异常结束。
当前线程在同步代码块、同步方法中执行了锁对象的wait()方法,当前线程被挂起,并释放锁。
2、不会释放锁的操作
线程执行同步代码块或同步方法时,程序调用Thread.sleep()、Thread.yield()方法暂停当前线程的执行。
线程执行同步代码块时,其他线程调用了该线程的suspend()方法将该该线程挂起,该线程不会释放锁(同步监视器)。应尽量避免使用suspend()和resume()这样的过时来控制线程。
3、死锁
不同的线程分别锁住对方需要的同步监视器对象不释放,都在等待对方先放弃时就形成了线程的死锁。一旦出现死锁,整个程序既不会发生异常,也不会给出任何提示,只是所有线程处于阻塞状态,无法继续。
4、sleep()和wait()方法的区别
(1)sleep()不释放锁,wait()释放锁
(2)sleep()指定休眠的时间,wait()可以指定时间也可以无限等待直到notify或notifyAll
(3)sleep()在Thread类中声明的静态方法,wait方法在Object类中声明
因为我们调用wait()方法是由锁对象调用,而锁对象的类型是任意类型的对象。那么希望任意类型的对象都要有的方法,只能声明在Object类中。
JavaSE_第10章 基础API与常见算法
1 java.lang.Math
java.lang.Math 类包含用于执行基本数学运算的方法,如初等指数、对数、平方根和三角函数。类似这样的工具类,其所有方法均为静态方法,并且不会创建对象,调用起来非常简单。
public static double abs(double a):返回 double 值的绝对值。
double d1 = Math.abs(-5); //d1的值为5
double d2 = Math.abs(5); //d2的值为5
public static double ceil(double a):返回大于等于参数的最小的整数。
double d1 = Math.ceil(3.3); //d1的值为 4.0
double d2 = Math.ceil(-3.3); //d2的值为 -3.0
double d3 = Math.ceil(5.1); //d3的值为 6.0
public static double floor(double a):返回小于等于参数最大的整数。
double d1 = Math.floor(3.3); //d1的值为3.0
double d2 = Math.floor(-3.3); //d2的值为-4.0
double d3 = Math.floor(5.1); //d3的值为 5.0
public static long round(double a):返回最接近参数的 long。(相当于四舍五入方法)
long d1 = Math.round(5.5); //d1的值为6.0
long d2 = Math.round(5.4); //d2的值为5.0
- public static double pow(double a,double b):返回a的b幂次方法
- public static double sqrt(double a):返回a的平方根
- public static double random():返回[0,1)的随机值
- public static final double PI:返回圆周率
- public static double max(double x, double y):返回x,y中的最大值
- public static double min(double x, double y):返回x,y中的最小值
double result = Math.pow(2,31);
double sqrt = Math.sqrt(256);
double rand = Math.random();
double pi = Math.PI;
2 java.math包
(1)BigInteger
不可变的任意精度的整数。
- BigInteger(String val)
- BigInteger add(BigInteger val)
- BigInteger subtract(BigInteger val)
- BigInteger multiply(BigInteger val)
- BigInteger divide(BigInteger val)
- BigInteger remainder(BigInteger val)
- ....
@Test
public void test01(){
// long bigNum = 123456789123456789123456789L;
BigInteger b1 = new BigInteger("123456789123456789123456789");
BigInteger b2 = new BigInteger("78923456789123456789123456789");
// System.out.println("和:" + (b1+b2));//错误的,无法直接使用+进行求和
System.out.println("和:" + b1.add(b2));
System.out.println("减:" + b1.subtract(b2));
System.out.println("乘:" + b1.multiply(b2));
System.out.println("除:" + b2.divide(b1));
System.out.println("余:" + b2.remainder(b1));
}
(2)RoundingMode枚举类
CEILING :向正无限大方向舍入的舍入模式。
DOWN :向零方向舍入的舍入模式。
FLOOR:向负无限大方向舍入的舍入模式。
HALF_DOWN :向最接近数字方向舍入的舍入模式,如果与两个相邻数字的距离相等,则向下舍入。
HALF_EVEN:向最接近数字方向舍入的舍入模式,如果与两个相邻数字的距离相等,则向相邻的偶数舍入。
HALF_UP:向最接近数字方向舍入的舍入模式,如果与两个相邻数字的距离相等,则向上舍入。
UNNECESSARY:用于断言请求的操作具有精确结果的舍入模式,因此不需要舍入。
UP:远离零方向舍入的舍入模式。
(3)BigDecimal
不可变的、任意精度的有符号十进制数。
- BigDecimal(String val)
- BigDecimal add(BigDecimal val)
- BigDecimal subtract(BigDecimal val)
- BigDecimal multiply(BigDecimal val)
- BigDecimal divide(BigDecimal val)
- BigDecimal divide(BigDecimal divisor, int roundingMode)
- BigDecimal divide(BigDecimal divisor, int scale, RoundingMode roundingMode)
- BigDecimal remainder(BigDecimal val)
- ....
@Test
public void test02(){
/*double big = 12.123456789123456789123456789;
System.out.println("big = " + big);*/
BigDecimal b1 = new BigDecimal("123.45678912345678912345678912345678");
BigDecimal b2 = new BigDecimal("7.8923456789123456789123456789998898888");
// System.out.println("和:" + (b1+b2));//错误的,无法直接使用+进行求和
System.out.println("和:" + b1.add(b2));
System.out.println("减:" + b1.subtract(b2));
System.out.println("乘:" + b1.multiply(b2));
System.out.println("除:" + b1.divide(b2,20,RoundingMode.UP));//divide(BigDecimal divisor, int scale, int roundingMode)
System.out.println("除:" + b1.divide(b2,20,RoundingMode.DOWN));//divide(BigDecimal divisor, int scale, int roundingMode)
System.out.println("余:" + b1.remainder(b2));
}
3 java.util.Random
用于产生随机数
- boolean nextBoolean():返回下一个伪随机数,它是取自此随机数生成器序列的均匀分布的 boolean 值。
- void nextBytes(byte[] bytes):生成随机字节并将其置于用户提供的 byte 数组中。
- double nextDouble():返回下一个伪随机数,它是取自此随机数生成器序列的、在 0.0 和 1.0 之间均匀分布的 double 值。
- float nextFloat():返回下一个伪随机数,它是取自此随机数生成器序列的、在 0.0 和 1.0 之间均匀分布的 float 值。
- double nextGaussian():返回下一个伪随机数,它是取自此随机数生成器序列的、呈高斯(“正态”)分布的 double 值,其平均值是 0.0,标准差是 1.0。
- int nextInt():返回下一个伪随机数,它是此随机数生成器的序列中均匀分布的 int 值。
- int nextInt(int n):返回一个伪随机数,它是取自此随机数生成器序列的、在 0(包括)和指定值(不包括)之间均匀分布的 int 值。
- long nextLong():返回下一个伪随机数,它是取自此随机数生成器序列的均匀分布的 long 值。
@Test
public void test03(){
Random r = new Random();
System.out.println("随机整数:" + r.nextInt());
System.out.println("随机小数:" + r.nextDouble());
System.out.println("随机布尔值:" + r.nextBoolean());
}
4 JDK1.8之前
1、java.util.Date
new Date():当前系统时间
long getTime():返回该日期时间对象距离1970-1-1 0.0.0 0毫秒之间的毫秒值
new Date(long 毫秒):把该毫秒值换算成日期时间对象
2、java.text.SimpleDateFormat
@Test
public void test10() throws ParseException{
String str = "2019年06月06日 16时03分14秒 545毫秒 星期四 +0800";
SimpleDateFormat sf = new SimpleDateFormat("yyyy年MM月dd日 HH时mm分ss秒 SSS毫秒 E Z");
Date d = sf.parse(str);
System.out.println(d);
}
@Test
public void test9(){
Date d = new Date();
SimpleDateFormat sf = new SimpleDateFormat("yyyy年MM月dd日 HH时mm分ss秒 SSS毫秒 E Z");
//把Date日期转成字符串,按照指定的格式转
String str = sf.format(d);
System.out.println(str);
}
3、java.util.Calendar
Calendar 类是一个抽象类,它为特定瞬间与一组诸如 YEAR、MONTH、DAY_OF_MONTH、HOUR 等 日历字段之间的转换提供了一些方法,并为操作日历字段(例如获得下星期的日期)提供了一些方法。瞬间可用毫秒值来表示,它是距历元(即格林威治标准时间 1970 年 1 月 1 日的 00:00:00.000,格里高利历)的偏移量。与其他语言环境敏感类一样,Calendar 提供了一个类方法 getInstance,以获得此类型的一个通用的对象。
修改和获取 YEAR、MONTH、DAY_OF_MONTH、HOUR 等 日历字段对应的时间值。
void add(int field,int amount)
int get(int field)
void set(int field, int value)
5 JDK1.8之后
Java1.0中包含了一个Date类,但是它的大多数方法已经在Java 1.1引入Calendar类之后被弃用了。而Calendar并不比Date好多少。它们面临的问题是:
- 可变性:象日期和时间这样的类对象应该是不可变的。Calendar类中可以使用三种方法更改日历字段:set()、add() 和 roll()。
- 偏移性:Date中的年份是从1900开始的,而月份都是从0开始的。
- 格式化:格式化只对Date有用,Calendar则不行。
- 此外,它们也不是线程安全的,不能处理闰秒等。
可以说,对日期和时间的操作一直是Java程序员最痛苦的地方之一。第三次引入的API是成功的,并且java 8中引入的java.time API 已经纠正了过去的缺陷,将来很长一段时间内它都会为我们服务。
Java 8 吸收了 Joda-Time 的精华,以一个新的开始为 Java 创建优秀的 API。
- java.time – 包含值对象的基础包
- java.time.chrono – 提供对不同的日历系统的访问。
- java.time.format – 格式化和解析时间和日期
- java.time.temporal – 包括底层框架和扩展特性
- java.time.zone – 包含时区支持的类
Java 8 吸收了 Joda-Time 的精华,以一个新的开始为 Java 创建优秀的 API。新的 java.time 中包含了所有关于时钟(Clock),本地日期(LocalDate)、本地时间(LocalTime)、本地日期时间(LocalDateTime)、时区(ZonedDateTime)和持续时间(Duration)的类。
1、本地日期时间:LocalDate、LocalTime、LocalDateTime
| 方法 | 描述 |
|---|---|
| now() / now(ZoneId zone) | 静态方法,根据当前时间创建对象/指定时区的对象 |
| of() | 静态方法,根据指定日期/时间创建对象 |
| getDayOfMonth()/getDayOfYear() | 获得月份天数(1-31) /获得年份天数(1-366) |
| getDayOfWeek() | 获得星期几(返回一个 DayOfWeek 枚举值) |
| getMonth() | 获得月份, 返回一个 Month 枚举值 |
| getMonthValue() / getYear() | 获得月份(1-12) /获得年份 |
| getHours()/getMinute()/getSecond() | 获得当前对象对应的小时、分钟、秒 |
| withDayOfMonth()/withDayOfYear()/withMonth()/withYear() | 将月份天数、年份天数、月份、年份修改为指定的值并返回新的对象 |
| with(TemporalAdjuster t) | 将当前日期时间设置为校对器指定的日期时间 |
| plusDays(), plusWeeks(), plusMonths(), plusYears(),plusHours() | 向当前对象添加几天、几周、几个月、几年、几小时 |
| minusMonths() / minusWeeks()/minusDays()/minusYears()/minusHours() | 从当前对象减去几月、几周、几天、几年、几小时 |
| plus(TemporalAmount t)/minus(TemporalAmount t) | 添加或减少一个 Duration 或 Period |
| isBefore()/isAfter() | 比较两个 LocalDate |
| isLeapYear() | 判断是否是闰年(在LocalDate类中声明) |
| format(DateTimeFormatter t) | 格式化本地日期、时间,返回一个字符串 |
| parse(Charsequence text) | 将指定格式的字符串解析为日期、时间 |
6 java.lang.System类
系统类中很多好用的方法,其中几个如下:
- static long currentTimeMillis() :返回当前系统时间距离1970-1-1 0:0:0的毫秒值
- static void exit(int status) :退出当前系统
- static void gc() :运行垃圾回收器。
- static String getProperty(String key):获取某个系统属性,例如:java.version、user.language、user.country、file.encoding、user.name、os.version、os.name等等
7 java.util.Arrays类
java.util.Arrays数组工具类,提供了很多静态方法来对数组进行操作,而且如下每一个方法都有各种重载形式,以下只列出int[]和Object[]类型的,其他类型的数组依次类推:
- 数组元素拼接
- static String toString(int[] a) :字符串表示形式由数组的元素列表组成,括在方括号("[]")中。相邻元素用字符 ", "(逗号加空格)分隔。形式为:[元素1,元素2,元素3。。。]
static String toString(Object[] a) :字符串表示形式由数组的元素列表组成,括在方括号("[]")中。相邻元素用字符 ", "(逗号加空格)分隔。元素将自动调用自己从Object继承的toString方法将对象转为字符串进行拼接,如果没有重写,则返回类型@hash值,如果重写则按重写返回的字符串进行拼接。
- static String toString(int[] a) :字符串表示形式由数组的元素列表组成,括在方括号("[]")中。相邻元素用字符 ", "(逗号加空格)分隔。形式为:[元素1,元素2,元素3。。。]
- 数组排序
- static void sort(int[] a) :将a数组按照从小到大进行排序
- static void sort(int[] a, int fromIndex, int toIndex) :将a数组的[fromIndex, toIndex)部分按照升序排列
- static void sort(Object[] a) :根据元素的自然顺序对指定对象数组按升序进行排序。
- static
void sort(T[] a, Comparator<? super T> c) :根据指定比较器产生的顺序对指定对象数组进行排序。
- 数组元素的二分查找
- static int binarySearch(int[] a, int key)
- static int binarySearch(Object[] a, Object key) :要求数组有序,在数组中查找key是否存在,如果存在返回第一次找到的下标,不存在返回负数
- 数组的复制
- static int[] copyOf(int[] original, int newLength) :根据original原数组复制一个长度为newLength的新数组,并返回新数组
- static
T[] copyOf(T[] original,int newLength):根据original原数组复制一个长度为newLength的新数组,并返回新数组 - static int[] copyOfRange(int[] original, int from, int to) :复制original原数组的[from,to)构成新数组,并返回新数组
- static
T[] copyOfRange(T[] original,int from,int to):复制original原数组的[from,to)构成新数组,并返回新数组
- 比较两耳数组是否相等
- static boolean equals(int[] a, int[] a2) :比较两个数组的长度、元素是否完全相同
- static boolean equals(Object[] a,Object[] a2):比较两个数组的长度、元素是否完全相同
- 填充数组
- static void fill(int[] a, int val) :用val值填充整个a数组
- static void fill(Object[] a,Object val):用val对象填充整个a数组
- static void fill(int[] a, int fromIndex, int toIndex, int val):将a数组[fromIndex,toIndex)部分填充为val值
- static void fill(Object[] a, int fromIndex, int toIndex, Object val) :将a数组[fromIndex,toIndex)部分填充为val对象
8 字符串
java.lang.String 类代表字符串。Java程序中所有的字符串文字(例如"abc" )都可以被看作是实现此类的实例。字符串是常量;它们的值在创建之后不能更改。字符串缓冲区支持可变的字符串。因为 String 对象是不可变的,所以可以共享。
String 类包括的方法可用于检查序列的单个字符、比较字符串、搜索字符串、提取子字符串、创建字符串副本并将所有字符全部转换为大写或小写。
Java 语言提供对字符串串联符号("+")以及将其他对象转换为字符串的特殊支持(toString()方法)。
1、字符串String类型本身是final声明的,意味着我们不能继承String。
2、字符串的对象也是不可变对象,意味着一旦进行修改,就会产生新对象
我们修改了字符串后,如果想要获得新的内容,必须重新接收。
如果程序中涉及到大量的字符串的修改操作,那么此时的时空消耗比较高。可能需要考虑使用StringBuilder或StringBuffer的可变字符序列。
3、String对象内部是用字符数组进行保存的
JDK1.9之前有一个char[] value数组,JDK1.9之后byte[]数组
"abc" 等效于 char[] data={ 'a' , 'b' , 'c' }。
例如:
String str = "abc";
相当于:
char data[] = {'a', 'b', 'c'};
String str = new String(data);
// String底层是靠字符数组实现的。
4、String类中这个char[] values数组也是final修饰的,意味着这个数组不可变,然后它是private修饰,外部不能直接操作它,String类型提供的所有的方法都是用新对象来表示修改后内容的,所以保证了String对象的不可变。
5、就因为字符串对象设计为不可变,那么所以字符串有常量池来保存很多常量对象
常量池在方法区。
如果细致的划分:
(1)JDK1.6及其之前:方法区
(2)JDK1.7:堆
(3)JDK1.8:元空间
String s1 = "abc";
String s2 = "abc";
System.out.println(s1 == s2);
// 内存中只有一个"abc"对象被创建,同时被s1和s2共享。
1、String构造方法
public String():初始化新创建的 String对象,以使其表示空字符序列。String(String original): 初始化一个新创建的String对象,使其表示一个与参数相同的字符序列;换句话说,新创建的字符串是该参数字符串的副本。public String(char[] value):通过当前参数中的字符数组来构造新的String。public String(char[] value,int offset, int count):通过字符数组的一部分来构造新的String。public String(byte[] bytes):通过使用平台的默认字符集解码当前参数中的字节数组来构造新的String。public String(byte[] bytes,String charsetName):通过使用指定的字符集解码当前参数中的字节数组来构造新的String。
2、String的静态方法
- static String copyValueOf(char[] data): 返回指定数组中表示该字符序列的 String
- static String copyValueOf(char[] data, int offset, int count):返回指定数组中表示该字符序列的 String
- static String valueOf(char[] data) : 返回指定数组中表示该字符序列的 String
- static String valueOf(char[] data, int offset, int count) : 返回指定数组中表示该字符序列的 String
- static String valueOf(xx value):xx支持各种数据类型,返回各种数据类型的value参数的字符串表示形式。
3、拼接结果的存储和比较问题
public class TestString {
public static void main(String[] args) {
String str = "hello";
String str2 = "world";
String str3 ="helloworld";
String str4 = "hello".concat("world");
String str5 = "hello"+"world";
System.out.println(str3 == str4);//false
System.out.println(str3 == str5);//true
}
}
concat方法拼接,哪怕是两个常量对象拼接,结果也是在堆。
4、字符串对象的比较
1、==:比较是对象的地址
只有两个字符串变量都是指向字符串的常量对象时,才会返回true
String str1 = "hello";
String str2 = "hello";
System.out.println(str1 == str2);//true
String str3 = new String("hello");
String str4 = new String("hello");
System.out.println(str1 == str4); //false
System.out.println(str3 == str4); //false
2、equals:比较是对象的内容,因为String类型重写equals,区分大小写
只要两个字符串的字符内容相同,就会返回true
String str1 = "hello";
String str2 = "hello";
System.out.println(str1.equals(str2));//true
String str3 = new String("hello");
String str4 = new String("hello");
System.out.println(str1.equals(str3));//true
System.out.println(str3.equals(str4));//true
3、equalsIgnoreCase:比较的是对象的内容,不区分大小写
String str1 = new String("hello");
String str2 = new String("HELLO");
System.out.println(str1.equalsIgnoreCase(strs)); //true
4、compareTo:String类型重写了Comparable接口的抽象方法,自然排序,按照字符的Unicode编码值进行比较大小的,严格区分大小写
String str1 = "hello";
String str2 = "world";
str1.compareTo(str2) //小于0的值
5、compareToIgnoreCase:不区分大小写,其他按照字符的Unicode编码值进行比较大小
String str1 = new String("hello");
String str2 = new String("HELLO");
str1.compareToIgnoreCase(str2) //等于0
5、系列1:
(1)boolean isEmpty():字符串是否为空
(2)int length():返回字符串的长度
(3)String concat(xx):拼接,等价于+
(4)boolean equals(Object obj):比较字符串是否相等,区分大小写
(5)boolean equalsIgnoreCase(Object obj):比较字符串是否相等,不区分大小写
(6)int compareTo(String other):比较字符串大小,区分大小写,按照Unicode编码值比较大小
(7)int compareToIgnoreCase(String other):比较字符串大小,不区分大小写
(8)String toLowerCase():将字符串中大写字母转为小写
(9)String toUpperCase():将字符串中小写字母转为大写
(10)String trim():去掉字符串前后空白符
(11)public String intern():结果在常量池中共享
6、系列2:
(11)boolean contains(xx):是否包含xx
(12)int indexOf(xx):从前往后找当前字符串中xx,即如果有返回第一次出现的下标,要是没有返回-1
(13)int lastIndexOf(xx):从后往前找当前字符串中xx,即如果有返回最后一次出现的下标,要是没有返回-1
7、系列3:
(14)String substring(int beginIndex) :返回一个新的字符串,它是此字符串的从beginIndex开始截取到最后的一个子字符串。
(15)String substring(int beginIndex, int endIndex) :返回一个新字符串,它是此字符串从beginIndex开始截取到endIndex(不包含)的一个子字符串。
8、系列4:
(16)char charAt(index):返回[index]位置的字符
(17)char[] toCharArray(): 将此字符串转换为一个新的字符数组返回
(18)String(char[] value):返回指定数组中表示该字符序列的 String。
(19)String(char[] value, int offset, int count):返回指定数组中表示该字符序列的 String。
(20)static String copyValueOf(char[] data): 返回指定数组中表示该字符序列的 String
(21)static String copyValueOf(char[] data, int offset, int count):返回指定数组中表示该字符序列的 String
(22)static String valueOf(char[] data, int offset, int count) : 返回指定数组中表示该字符序列的 String
(23)static String valueOf(char[] data) :返回指定数组中表示该字符序列的 String
9、系列5:
(24)byte[] getBytes():编码,把字符串变为字节数组,按照平台默认的字符编码方式进行编码
byte[] getBytes(字符编码方式):按照指定的编码方式进行编码
(25)new String(byte[] ) 或 new String(byte[], int, int):解码,按照平台默认的字符编码进行解码
new String(byte[],字符编码方式 ) 或 new String(byte[], int, int,字符编码方式):解码,按照指定的编码方式进行解码
(编码方式见附录10.7.1)
10、系列6:
(26)boolean startsWith(xx):是否以xx开头
(27)boolean endsWith(xx):是否以xx结尾
11、系列7:
(28)boolean matchs(正则表达式):判断当前字符串是否匹配某个正则表达式。(正则表达式见附录10.7.2)
12、系列8:
(29)String replace(xx,xx):不支持正则
(30)String replaceFirst(正则,value):替换第一个匹配部分
(31)String repalceAll(正则, value):替换所有匹配部分
13、系列9:
(32)String[] split(正则):按照某种规则进行拆分
9 String与可变字符序列的区别
因为String对象是不可变对象,虽然可以共享常量对象,但是对于频繁字符串的修改和拼接操作,效率极低。因此,JDK又在java.lang包提供了可变字符序列StringBuilder和StringBuffer类型。
StringBuffer:老的,线程安全的(因为它的方法有synchronized修饰)
StringBuilder:线程不安全的
10 StringBuilder、StringBuffer的API
常用的API,StringBuilder、StringBuffer的API是完全一致的
(1)StringBuffer append(xx):拼接,追加
(2)StringBuffer insert(int index, xx):在[index]位置插入xx
(3)StringBuffer delete(int start, int end):删除[start,end)之间字符
StringBuffer deleteCharAt(int index):删除[index]位置字符
(4)void setCharAt(int index, xx):替换[index]位置字符
(5)StringBuffer reverse():反转
(6)void setLength(int newLength) :设置当前字符序列长度为newLength
(7)StringBuffer replace(int start, int end, String str):替换[start,end)范围的字符序列为str
(8)int indexOf(String str):在当前字符序列中查询str的第一次出现下标
int indexOf(String str, int fromIndex):在当前字符序列[fromIndex,最后]中查询str的第一次出现下标
int lastIndexOf(String str):在当前字符序列中查询str的最后一次出现下标
int lastIndexOf(String str, int fromIndex):在当前字符序列[fromIndex,最后]中查询str的最后一次出现下标
(9)String substring(int start):截取当前字符序列[start,最后]
(10)String substring(int start, int end):截取当前字符序列[start,end)
(11)String toString():返回此序列中数据的字符串表示形式
JavaSE_第11章 集合与迭代器
1 集合的概念
集合是java中提供的一种容器,可以用来存储多个数据。
集合和数组既然都是容器,它们有啥区别呢?
- 数组的长度是固定的。集合的长度是可变的。
- 数组中可以存储基本数据类型值,也可以存储对象,而集合中只能存储对象
集合主要分为两大系列:Collection和Map,Collection 表示一组对象,Map表示一组映射关系或键值对。
2 Collection接口
Collection 层次结构中的根接口。Collection 表示一组对象,这些对象也称为 collection 的元素。一些 collection 允许有重复的元素,而另一些则不允许。一些 collection 是有序的,而另一些则是无序的。JDK 不提供此接口的任何直接实现:它提供更具体的子接口(如 Set 和 List、Queue)实现。此接口通常用来传递 collection,并在需要最大普遍性的地方操作这些 collection。
Collection
1、添加元素
(1)add(E obj):添加元素对象到当前集合中
(2)addAll(Collection<? extends E> other):添加other集合中的所有元素对象到当前集合中,即this = this ∪ other
2、删除元素
(1) boolean remove(Object obj) :从当前集合中删除第一个找到的与obj对象equals返回true的元素。
(2)boolean removeAll(Collection<?> coll):从当前集合中删除所有与coll集合中相同的元素。即this = this - this ∩ coll
(3)boolean removeIf(Predicate<? super E> filter) :删除满足给定条件的此集合的所有元素。
(4)boolean retainAll(Collection<?> coll):从当前集合中删除两个集合中不同的元素,使得当前集合仅保留与c集合中的元素相同的元素,即当前集合中仅保留两个集合的交集,即this = this ∩ coll;
3 查询与获取元素
(1)boolean isEmpty():判断当前集合是否为空集合。
(2)boolean contains(Object obj):判断当前集合中是否存在一个与obj对象equals返回true的元素。
(3)boolean containsAll(Collection<?> c):判断c集合中的元素是否在当前集合中都存在。即c集合是否是当前集合的“子集”。
(4)int size():获取当前集合中实际存储的元素个数
(5)Object[] toArray():返回包含当前集合中所有元素的数组
3 Iterator接口
在程序开发中,经常需要遍历集合中的所有元素。针对这种需求,JDK专门提供了一个接口java.util.Iterator。Iterator接口也是Java集合中的一员,但它与Collection、Map接口有所不同,Collection接口与Map接口主要用于存储元素,而Iterator主要用于迭代访问(即遍历)Collection中的元素,因此Iterator对象也被称为迭代器。
想要遍历Collection集合,那么就要获取该集合迭代器完成迭代操作,下面介绍一下获取迭代器的方法:
public Iterator iterator(): 获取集合对应的迭代器,用来遍历集合中的元素的。
下面介绍一下迭代的概念:
- 迭代:即Collection集合元素的通用获取方式。在取元素之前先要判断集合中有没有元素,如果有,就把这个元素取出来,继续在判断,如果还有就再取出出来。一直把集合中的所有元素全部取出。这种取出方式专业术语称为迭代。
Iterator接口的常用方法如下:
public E next():返回迭代的下一个元素。public boolean hasNext():如果仍有元素可以迭代,则返回 true。
JavaSE_第12章 集合的重要接口
1 List接口介绍
java.util.List接口继承自Collection接口,是单列集合的一个重要分支,习惯性地会将实现了List接口的对象称为List集合。
List接口特点:
- List集合所有的元素是以一种线性方式进行存储的,例如,存元素的顺序是11、22、33。那么集合中,元素的存储就是按照11、22、33的顺序完成的)
- 它是一个元素存取有序的集合。即元素的存入顺序和取出顺序有保证。
- 它是一个带有索引的集合,通过索引就可以精确的操作集合中的元素(与数组的索引是一个道理)。
- 集合中可以有重复的元素,通过元素的equals方法,来比较是否为重复的元素。
2 List接口中常用方法
List作为Collection集合的子接口,不但继承了Collection接口中的全部方法,而且还增加了一些根据元素索引来操作集合的特有方法,如下:
List除了从Collection集合继承的方法外,List 集合里添加了一些根据索引来操作集合元素的方法。
1、添加元素
- void add(int index, E ele)
- boolean addAll(int index, Collection<? extends E> eles)
2、获取元素
- E get(int index)
- List subList(int fromIndex, int toIndex)
3、获取元素索引
- int indexOf(Object obj)
- int lastIndexOf(Object obj)
4、删除和替换元素
- E remove(int index)
- E set(int index, E ele)
3 List接口的实现类们
List接口的实现类有很多,常见的有:
ArrayList:动态数组
Vector:动态数组
LinkedList:双向链表
当然,还有很多List接口的实现类这里没有列出来,基础阶段先了解这几个。
(1)ArrayList与Vector的区别?
它们的底层物理结构都是数组,我们称为动态数组。
- ArrayList是新版的动态数组,线程不安全,效率高,Vector是旧版的动态数组,线程安全,效率低。
- 动态数组的扩容机制不同,ArrayList扩容为原来的1.5倍,Vector扩容增加为原来的2倍。
- 数组的初始化容量,如果在构建ArrayList与Vector的集合对象时,没有显式指定初始化容量,那么Vector的内部数组的初始容量默认为10,而ArrayList在JDK1.6及之前的版本也是10,JDK1.7之后的版本ArrayList初始化为长度为0的空数组,之后在添加第一个元素时,再创建长度为10的数组。
- Vector因为版本古老,支持Enumeration 迭代器。但是该迭代器不支持快速失败。而Iterator和ListIterator迭代器支持快速失败。如果在迭代器创建后的任意时间从结构上修改了向量(通过迭代器自身的 remove 或 add 方法之外的任何其他方式),则迭代器将抛出 ConcurrentModificationException。因此,面对并发的修改,迭代器很快就完全失败,而不是冒着在将来不确定的时间任意发生不确定行为的风险。
(2)链表的特点
逻辑结构:线性结构
物理结构:不要求连续的存储空间
存储特点:数据必须封装到“结点”中,结点包含多个数据项,数据值只是其中的一个数据项,其他的数据项用来记录与之有关的结点的地址。
例如:以下列出几种常见的链式存储结构(当然远不止这些)
(3)链表与动态数组的区别
动态数组底层的物理结构是数组,因此根据索引访问的效率非常高。但是非末尾位置的插入和删除效率不高,因为涉及到移动元素。另外添加操作时涉及到扩容问题,就会增加时空消耗。
链表底层的物理结构是链表,因此根据索引访问的效率不高,但是插入和删除不需要移动元素,只需要修改前后元素的指向关系即可,而且链表的添加不会涉及到扩容问题。
4 Set集合
Set接口是Collection的子接口,set接口没有提供额外的方法。但是比Collection接口更加严格了。
Set 集合不允许包含相同的元素,如果试把两个相同的元素加入同一个 Set 集合中,则添加操作失败。
Set集合支持的遍历方式和Collection集合一样:foreach和Iterator。
Set的常用实现类有:HashSet、TreeSet、LinkedHashSet。
5 HashSet
HashSet 是 Set 接口的典型实现,大多数时候使用 Set 集合时都使用这个实现类。
java.util.HashSet底层的实现其实是一个java.util.HashMap支持,然后HashMap的底层物理实现是一个Hash表。(什么是哈希表,下一节在HashMap小节在细讲,这里先不展开)
HashSet 按 Hash 算法来存储集合中的元素,因此具有很好的存取和查找性能。HashSet 集合判断两个元素相等的标准:两个对象通过 hashCode() 方法比较相等,并且两个对象的 equals() 方法返回值也相等。因此,存储到HashSet的元素要重写hashCode和equals方法。
6 LinkedHashSet
LinkedHashSet是HashSet的子类,它在HashSet的基础上,在结点中增加两个属性before和after维护了结点的前后添加顺序。java.util.LinkedHashSet,它是链表和哈希表组合的一个数据存储结构。LinkedHashSet插入性能略低于 HashSet,但在迭代访问 Set 里的全部元素时有很好的性能。
7 TreeSet
TreeSet里面维护了一个TreeMap,底层是基于红黑树实现的!
TreeSet特点:
- 不允许重复
- 实现排序:自然排序或定制排序
如何实现去重的?
如果使用的是自然排序,则通过调用实现的compareTo方法
如果使用的是定制排序,则通过调用比较器的compare方法
如何排序?
方式一:自然排序
让待添加的元素类型实现Comparable接口,并重写compareTo方法
方式二:定制排序
创建Set对象时,指定Comparator比较器接口,并实现compare方法
8 Collections工具类
参考操作数组的工具类:Arrays。
Collections 是一个操作 Set、List 和 Map 等集合的工具类。Collections 中提供了一系列静态的方法对集合元素进行排序、查询和修改等操作,还提供了对集合对象设置不可变、对集合对象实现同步控制等方法:
- public static
boolean addAll(Collection<? super T> c,T... elements)将所有指定元素添加到指定 collection 中。 - public static
int binarySearch(List<? extends Comparable<? super T>> list,T key)在List集合中查找某个元素的下标,但是List的元素必须是T或T的子类对象,而且必须是可比较大小的,即支持自然排序的。而且集合也事先必须是有序的,否则结果不确定。 - public static
int binarySearch(List<? extends T> list,T key,Comparator<? super T> c)在List集合中查找某个元素的下标,但是List的元素必须是T或T的子类对象,而且集合也事先必须是按照c比较器规则进行排序过的,否则结果不确定。 - public static <T extends Object & Comparable<? super T>> T max(Collection<? extends T> coll)在coll集合中找出最大的元素,集合中的对象必须是T或T的子类对象,而且支持自然排序
- public static
T max(Collection<? extends T> coll,Comparator<? super T> comp)在coll集合中找出最大的元素,集合中的对象必须是T或T的子类对象,按照比较器comp找出最大者 - public static void reverse(List<?> list)反转指定列表List中元素的顺序。
- public static void shuffle(List<?> list) List 集合元素进行随机排序,类似洗牌
- public static <T extends Comparable<? super T>> void sort(List
list)根据元素的自然顺序对指定 List 集合元素按升序排序 - public static
void sort(List list,Comparator<? super T> c)根据指定的 Comparator 产生的顺序对 List 集合元素进行排序 - public static void swap(List<?> list,int i,int j)将指定 list 集合中的 i 处元素和 j 处元素进行交换
- public static int frequency(Collection<?> c,Object o)返回指定集合中指定元素的出现次数
- public static
void copy(List<? super T> dest,List<? extends T> src)将src中的内容复制到dest中 - public static
boolean replaceAll(List list,T oldVal,T newVal):使用新值替换 List 对象的所有旧值 - Collections 类中提供了多个 synchronizedXxx() 方法,该方法可使将指定集合包装成线程同步的集合,从而可以解决多线程并发访问集合时的线程安全问题
- Collections类中提供了多个unmodifiableXxx()方法,该方法返回指定 Xxx的不可修改的视图。
9 Map集合
现实生活中,我们常会看到这样的一种集合:IP地址与主机名,身份证号与个人,系统用户名与系统用户对象等,这种一一对应的关系,就叫做映射。Java提供了专门的集合类用来存放这种对象关系的对象,即java.util.Map<K,V>接口。
我们通过查看Map接口描述,发现Map<K,V>接口下的集合与Collection<E>接口下的集合,它们存储数据的形式不同。
Collection中的集合,元素是孤立存在的(理解为单身),向集合中存储元素采用一个个元素的方式存储。Map中的集合,元素是成对存在的(理解为夫妻)。每个元素由键与值两部分组成,通过键可以找对所对应的值。Collection中的集合称为单列集合,Map中的集合称为双列集合。- 需要注意的是,
Map中的集合不能包含重复的键,值可以重复;每个键只能对应一个值(这个值可以是单个值,也可以是个数组或集合值)。
10 Map常用方法
1、添加操作
- V put(K key,V value)
- void putAll(Map<? extends K,? extends V> m)
2、删除
- void clear()
- V remove(Object key)
3、元素查询的操作
- V get(Object key)
- boolean containsKey(Object key)
- boolean containsValue(Object value)
- boolean isEmpty()
4、元视图操作的方法:
- Set
keySet() - Collection
values() - Set<Map.Entry<K,V>> entrySet()
5、其他方法
- int size()
11 Map集合的遍历
Collection集合的遍历:(1)foreach(2)通过Iterator对象遍历
Map的遍历,不能支持foreach,因为Map接口没有继承java.lang.Iterable
(1)分开遍历:
- 单独遍历所有key
- 单独遍历所有value
(2)成对遍历:
- 遍历的是映射关系Map.Entry类型的对象,Map.Entry是Map接口的内部接口。每一种Map内部有自己的Map.Entry的实现类。在Map中存储数据,实际上是将Key---->value的数据存储在Map.Entry接口的实例中,再在Map集合中插入Map.Entry的实例化对象,如图示:
package com.atguigu.map;
import java.util.Collection;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class TestMapIterate {
public static void main(String[] args) {
HashMap<String,String> map = new HashMap<>();
map.put("许仙", "白娘子");
map.put("董永", "七仙女");
map.put("牛郎", "织女");
map.put("许仙", "小青");
System.out.println("所有的key:");
Set<String> keySet = map.keySet();
for (String key : keySet) {
System.out.println(key);
}
System.out.println("所有的value:");
Collection<String> values = map.values();
for (String value : values) {
System.out.println(value);
}
System.out.println("所有的映射关系");
Set<Map.Entry<String,String>> entrySet = map.entrySet();
for (Map.Entry<String,String> entry : entrySet) {
// System.out.println(entry);
System.out.println(entry.getKey()+"->"+entry.getValue());
}
}
}
12 Map的实现类们
Map接口的常用实现类:HashMap、TreeMap、LinkedHashMap和Properties。其中HashMap是 Map 接口使用频率最高的实现类。
1、HashMap和Hashtable
HashMap和Hashtable都是哈希表。HashMap和Hashtable判断两个 key 相等的标准是:两个 key 的hashCode 值相等,并且 equals() 方法也返回 true。因此,为了成功地在哈希表中存储和获取对象,用作键的对象必须实现 hashCode 方法和 equals 方法。
- Hashtable是线程安全的,任何非 null 对象都可以用作键或值。
- HashMap是线程不安全的,并允许使用 null 值和 null 键。
2、LinkedHashMap
LinkedHashMap 是 HashMap 的子类。此实现与 HashMap 的不同之处在于,后者维护着一个运行于所有条目的双重链接列表。此链接列表定义了迭代顺序,该迭代顺序通常就是将键插入到映射中的顺序(插入顺序)。
3、TreeMap
基于红黑树(Red-Black tree)的 NavigableMap 实现。该映射根据其键的自然顺序进行排序,或者根据创建映射时提供的 Comparator 进行排序,具体取决于使用的构造方法。
JavaSE_第13章 泛型
1 使用核心类库中的泛型类/接口
自从JDK1.5引入泛型的概念之后,对之前核心类库中的API做了很大的修改,例如:集合框架集中的相关接口和类、java.lang.Comparable接口、java.util.Comparator接口、Class类等等。
下面以Collection、ArrayList集合以及Iterator迭代器为例演示,泛型类与泛型接口的使用。
案例一:Collection集合相关类型
(1)创建一个Collection集合(暂时创建ArrayList集合对象),并指定泛型为
(2)添加5个[0,100)以内的整数到集合中,
(3)使用foreach遍历输出5个整数,
(4)使用集合的removeIf方法删除偶数,为Predicate接口指定泛型
(5)再使用Iterator迭代器输出剩下的元素,为Iterator接口指定泛型
案例二:Comparable接口
(1)声明矩形类Rectangle,包含属性长和宽,属性私有化,提供有参构造、get/set方法、重写toString方法,提供求面积和周长的方法。
(2)矩形类Rectangle实现java.lang.Comparable
(3)在测试类中,创建Rectangle数组,并创建5个矩形对象
(4)调用Arrays的sort方法,给矩形数组排序,并显示排序前后的结果。
2 自定义泛型类与泛型接口
当我们在类或接口中定义某个成员时,该成员的相关类型是不确定的,而这个类型需要在使用这个类或接口时才可以确定,那么我们可以使用泛型。
- 当某个类/接口的非静态实例变量的类型不确定,需要在创建对象或子类继承时才能确定
- 当某个(些)类/接口的非静态方法的形参类型不确定,需要在创建对象或子类继承时才能确定
语法格式:
【修饰符】 class 类名<类型变量列表> 【extends 父类】 【implements 父接口们】{
}
【修饰符】 interface 接口名<类型变量列表> 【extends 父接口们】{
}
3 使用泛型类与泛型接口小结
在使用这种参数化的类与接口时,我们需要指定泛型变量的实际类型参数:
(1)实际类型参数必须是引用数据类型,不能是基本数据类型
(2)子类继承泛型父类时,子接口继承泛型父接口、或实现类实现泛型父接口时,
- 指定类型变量对应的实际类型参数,此时子类或实现类不再是泛型类
package com.atguigu.genericclass.define;
//ChineseStudent不再是泛型类
public class ChineseStudent extends Student<String>{
public ChineseStudent() {
super();
}
public ChineseStudent(String name, String score) {
super(name, score);
}
}
public class Rectangle implements Comparable<Rectangle>
- 指定类型变量(该类型变量可以和原来字母一样,也可以换一个字母),此时子类、子接口、实现类仍然是泛型类或泛型接口
public interface Iterable<T>
public interface Collection<E>extends Iterable<E>
public interface List<E>extends Collection<E>
public class ArrayList<E>extends AbstractList<E>implements List<E>, RandomAccess, Cloneable, Serializable
(3)在创建泛型类的对象时指定类型变量对应的实际类型参数
package com.atguigu.genericclass.define;
public class TestStudent {
public static void main(String[] args) {
//语文老师使用时:
Student<String> stu1 = new Student<String>("张三", "良好");
ChineseStudent chineseStudent = new ChineseStudent("张三", "良好");
//数学老师使用时:
//Student<double> stu2 = new Student<double>("张三", 90.5);//错误,必须是引用数据类型
Student<Double> stu2 = new Student<Double>("张三", 90.5);
//英语老师使用时:
Student<Character> stu3 = new Student<Character>("张三", 'C');
//错误的指定
//Student<Object> stu = new Student<String>();//错误的
}
}
JDK1.7支持简写形式:Student
stu1 = new Student<>("张三", "良好"); 指定泛型实参时,必须左右两边一致,不存在多态现象
4 泛型方法的调用
在java.util.Arrays数组工具类中,有很多泛型方法,例如:
- public static
List asList(T... a):将实参对象依次添加到一个固定大小的List列表集合中。 - public static
T[] copyOf(T[] original, int newLength):复制任意对象数组,新数组长度为newLength。 - ...
package com.atguigu.genericmethod;
import java.util.Arrays;
import java.util.List;
public class TestArrays {
public static void main(String[] args) {
List<String> list = Arrays.asList("java", "world", "hello", "atguigu");
System.out.println(list);
String[] arr = {"java", "world", "hello"};
String[] strings = Arrays.copyOf(arr, arr.length * 2);
System.out.println(Arrays.toString(strings));
}
}
泛型方法在调用时,由实参的类型确定泛型方法类型变量的具体类型。
5 自定义泛型方法
前面介绍了在定义类、接口时可以声明<类型变量>,在该类的方法和属性定义、接口的方法定义中,这些<类型变量>可被当成普通类型来用。但是,在另外一些情况下,
(1)如果我们定义类、接口时没有使用<类型变量>,但是某个方法形参类型不确定时,这个方法可以单独定义<类型变量>;
(2)另外我们之前说类和接口上的类型形参是不能用于静态方法中,那么当某个静态方法的形参类型不确定时,静态方法可以单独定义<类型变量>。
语法格式:
【修饰符】 <类型变量列表> 返回值类型 方法名(【形参列表】)【throws 异常列表】{
//...
}
- <类型变量列表>:可以是一个或多个类型变量,一般都是使用单个的大写字母表示。例如:
、<K,V>等。
6 类型变量的上限
当在声明类型变量时,如果不希望这个类型变量代表任意引用数据类型,而是某个系列的引用数据类型,那么可以设定类型变量的上限。
语法格式:
<类型变量 extends 上限>
如果有多个上限
<类型变量 extends 上限1 & 上限2>
如果多个上限中有类有接口,那么只能有一个类,而且必须写在最左边。接口的话,可以多个。
如果在声明<类型变量>时没有指定任何上限,默认上限是java.lang.Object。
7 泛型擦除
当使用参数化类型的类或接口时,如果没有指定泛型,那么会怎么样呢?
会发生泛型擦除,自动按照最左边的第一个上限处理。如果没有指定上限,上限即为Object。
package com.atguigu.limmit;
import java.util.ArrayList;
import java.util.Collection;
public class TestErase {
public static void main(String[] args) {
NumberTools tools = new NumberTools(8,5);
Number sum = tools.getSum();//自动按照Number处理
System.out.println("sum = " + sum);
Number subtract = tools.getSubtract();
System.out.println("subtract = " + subtract);
Collection coll = new ArrayList();
coll.add("hello");
coll.add(1);
for (Object o : coll) {//自动按照Object处理
System.out.println(o);
}
}
}
8 Java泛型指定限制问题
声明一个方法,形参是Collection,但是元素类型不确定,怎么办?
package com.atguigu.wildcard;
import java.util.ArrayList;
import java.util.Collection;
public class TestProblem {
public static void m1(Collection<Object> coll){
for (Object o : coll) {
System.out.println(o);
}
}
public static void m2(Collection coll){
for (Object o : coll) {
System.out.println(o);
}
}
public static <T> void m3(Collection<T> coll){
for (T o : coll) {
System.out.println(o);
}
}
public static void main(String[] args) {
m1(new ArrayList<Object>());//Collection<Object> coll = new ArrayList<Object>();
m1(new ArrayList<>());//Collection<Object> coll = new ArrayList<>();//与上面完全等价
m1(new ArrayList());//Collection<Object> coll = new ArrayList();//有警告
// m1(new ArrayList<String>());//Collection<Object> coll = new ArrayList<String>();//错误
//编译看左边,左边泛型擦除,此处泛型按照Object处理,右边泛型指定啥都没用
m2(new ArrayList<Object>());//Collection coll = new ArrayList<Object>();
m2(new ArrayList<>());//Collection coll = new ArrayList<>();//与上面完全等价
m2(new ArrayList());//Collection coll = new ArrayList();//泛型擦除
m2(new ArrayList<String>());//Collection coll = new ArrayList<String>();
m3(new ArrayList<Object>());//Collection<Object> coll = new ArrayList<Object>();
m3(new ArrayList<>());//Collection<> coll = new ArrayList<>();//与上面完全等价
m3(new ArrayList());//Collection<Object> coll = new ArrayList();//有警告
m3(new ArrayList<String>());//Collection<String> coll = new ArrayList<String>();
}
}
9 类型通配符
当我们声明一个变量/形参时,这个变量/形参的类型是一个泛型类或泛型接口,例如:Comparator
package com.atguigu.wildcard;
import java.util.ArrayList;
import java.util.Collection;
public class TestWildcard {
public static void m4(Collection<?> coll){
for (Object o : coll) {
System.out.println(o);
}
}
public static void main(String[] args) {
//右边泛型指定为任意类型或不指定都可以
m4(new ArrayList<Object>());//Collection<?> coll = new ArrayList<Object>();
m4(new ArrayList<>());//Collection<?> coll = new ArrayList<>();
m4(new ArrayList());//Collection<?> coll = new ArrayList();
m4(new ArrayList<String>());//Collection<?> coll = new ArrayList<String>();
}
}
10 类型通配符的三种使用形式
类型通配符 ? 有三种使用形式:
- <?>:完整形式为:类名<?> 或接口名<?>,此时?代表任意类型。
- <? extends 上限>:完整形式为:类名<? extends 上限类型> 或接口名<? extends 上限类型>,此时?代表上限类型本身或者上限的子类,即?代表 <= 上限的类型。
- :完整形式为:类名\ 或接口名\,此时?代表下限类型本身或者下限的父类,即?代表>= 下限的类型。
案例:
声明一个集合工具类MyCollections,要求包含:
- public static boolean different(Collection<?> c1, Collection<?> c2):比较两个Collection集合,此时两个Collection集合的泛型可以是任意类型,如果两个集合中没有相同的元素,则返回true,否则返回false。
- public static
void addAll(Collection<? super T> c1, T... args):可以将任意类型的多个对象添加到一个Collection集合中,此时要求Collection集合的泛型指定必须>=元素类型。 - public static
void copy(Collection<? super T> dest,Collection<? extends T> src):可以将一个Collection集合的元素复制到另一个Collection集合中,此时要求原Collection泛型的类型<=目标Collection的泛型类型。
11 使用类型通配符来指定类型参数的问题
package com.atguigu.wildcard;
import java.util.ArrayList;
import java.util.Collection;
public class TestWildcardProblem {
public static void main(String[] args) {
Collection<?> c1 = new ArrayList<>();
// c1.add(new Object());
// c1.add("hello");
// c1.add(1);
//不能添加,c1只读
Collection<? extends Object> c2 = new ArrayList<>();
// c2.add(new Object());
// c2.add("hello");
// c2.add(1);
//不能添加,c2只读
Collection<? super Number> c3 = new ArrayList<>();
// c3.add(new Object());
// c3.add("hello");
c3.add(1);
//可以添加Number对象或Number子类对象
}
}
JavaSE_第14章 File类与IO流
1 概述
File类是java.io包下代表与平台无关的文件和目录,也就是说如果希望在程序中操作文件和目录都可以通过File类来完成,File类能新建、删除、重命名文件和目录。
在API中File的解释是文件和目录路径名的抽象表示形式,即File类是文件或目录的路径,而不是文件本身,因此File类不能直接访问文件内容本身,如果需要访问文件内容本身,则需要使用输入/输出流。
2 构造方法
-
public File(String pathname):通过将给定的路径名字符串转换为抽象路径名来创建新的 File实例。 -
public File(String parent, String child):从父路径名字符串和子路径名字符串创建新的 File实例。 -
public File(File parent, String child):从父抽象路径名和子路径名字符串创建新的 File实例。 -
构造举例,代码如下:
package com.atguigu.file;
import java.io.File;
public class FileObjectTest {
public static void main(String[] args) {
// 文件路径名
String pathname = "D:\\aaa.txt";
File file1 = new File(pathname);
// 文件路径名
String pathname2 = "D:\\aaa\\bbb.txt";
File file2 = new File(pathname2);
// 通过父路径和子路径字符串
String parent = "d:\\aaa";
String child = "bbb.txt";
File file3 = new File(parent, child);
// 通过父级File对象和子路径字符串
File parentDir = new File("d:\\aaa");
String childFile = "bbb.txt";
File file4 = new File(parentDir, childFile);
}
}
小贴士:
- 一个File对象代表硬盘或网络中可能存在的一个文件或者目录。
- 无论该路径下是否存在文件或者目录,都不影响File对象的创建。
- 如果File对象代表的文件或目录存在,则File对象实例初始化时,就会用硬盘中对应文件或目录的属性信息(例如,时间、类型等)为File对象的属性赋值,否则除了路径和名称,File对象的其他属性将会保留默认值。
3 常用方法
1、获取文件和目录基本信息的方法
public String getName():返回由此File表示的文件或目录的名称。public long length():返回由此File表示的文件的长度。public String getPath():将此File转换为路径名字符串。public long lastModified():返回File对象对应的文件或目录的最后修改时间(毫秒值)
2、各种路径问题
public String getPath():将此File转换为路径名字符串。public String getAbsolutePath():返回此File的绝对路径名字符串。String getCanonicalPath():返回此File对象所对应的规范路径名。
File类可以使用文件路径字符串来创建File实例,该文件路径字符串既可以是绝对路径,也可以是相对路径。
默认情况下,系统总是依据用户的工作路径来解释相对路径,这个路径由系统属性“user.dir”指定,通常也就是运行Java虚拟机时所作的路径。
-
绝对路径:从盘符开始的路径,这是一个完整的路径。
-
相对路径:相对于项目目录的路径,这是一个便捷的路径,开发中经常使用。
-
规范路径:所谓规范路径名,即对路径中的“..”等进行解析后的路径名
-
window的路径分隔符使用“\”,而Java程序中的“\”表示转义字符,所以在Windows中表示路径,需要用“\”。或者直接使用“/”也可以,Java程序支持将“/”当成平台无关的路径分隔符。或者直接使用File.separator常量值表示。
-
把构造File对象指定的文件或目录的路径名,称为构造路径,它可以是绝对路径,也可以是相对路径
-
当构造路径是绝对路径时,那么getPath和getAbsolutePath结果一样
-
当构造路径是相对路径时,那么getAbsolutePath的路径 = user.dir的路径 + 构造路径
-
当路径中不包含".."和"/开头"等形式的路径,那么规范路径和绝对路径一样,否则会将..等进行解析。路径中如果出现“..”表示上一级目录,路径名如果以“/”开头,表示从“根目录”下开始导航。
3、判断功能的方法
public boolean exists():此File表示的文件或目录是否实际存在。public boolean isDirectory():此File表示的是否为目录。public boolean isFile():此File表示的是否为文件。
4、创建删除功能的方法
public boolean createNewFile():当且仅当具有该名称的文件尚不存在时,创建一个新的空文件。public boolean delete():删除由此File表示的文件或目录。 只能删除空目录。public boolean mkdir():创建由此File表示的目录。public boolean mkdirs():创建由此File表示的目录,包括任何必需但不存在的父目录。
5、列出目录的下一级
-
public String[] list():返回一个String数组,表示该File目录中的所有子文件或目录。 -
public File[] listFiles():返回一个File数组,表示该File目录中的所有的子文件或目录。 -
public File[] listFiles(FileFilter filter):返回所有满足指定过滤器的文件和目录。如果给定 filter 为 null,则接受所有路径名。否则,当且仅当在路径名上调用过滤器的 FileFilter.accept(File pathname)方法返回 true 时,该路径名才满足过滤器。如果当前File对象不表示一个目录,或者发生 I/O 错误,则返回 null。 -
public String[] list(FilenameFilter filter):返回返回所有满足指定过滤器的文件和目录。如果给定 filter 为 null,则接受所有路径名。否则,当且仅当在路径名上调用过滤器的 FilenameFilter .accept(File dir, String name)方法返回 true 时,该路径名才满足过滤器。如果当前File对象不表示一个目录,或者发生 I/O 错误,则返回 null。 -
public File[] listFiles(FilenameFilter filter):返回返回所有满足指定过滤器的文件和目录。如果给定 filter 为 null,则接受所有路径名。否则,当且仅当在路径名上调用过滤器的 FilenameFilter .accept(File dir, String name)方法返回 true 时,该路径名才满足过滤器。如果当前File对象不表示一个目录,或者发生 I/O 错误,则返回 null。
4 IO的分类
根据数据的流向分为:输入流和输出流。
- 输入流 :把数据从
其他设备上读取到内存中的流。- 以InputStream,Reader结尾
- 输出流 :把数据从
内存中写出到其他设备上的流。- 以OutputStream、Writer结尾
根据数据的类型分为:字节流和字符流。
- 字节流 :以字节为单位,读写数据的流。
- 以InputStream和OutputStream结尾
- 字符流 :以字符为单位,读写数据的流。
- 以Reader和Writer结尾
根据IO流的角色不同分为:节点流和处理流。
- 节点流:可以从或向一个特定的地方(节点)读写数据。如FileReader.
- 处理流:是对一个已存在的流进行连接和封装,通过所封装的流的功能调用实现数据读写。如BufferedReader.处理流的构造方法总是要带一个其他的流对象做参数。一个流对象经过其他流的多次包装,称为流的链接。
这种设计是装饰模式(Decorator Pattern)也称为包装模式(Wrapper Pattern),其使用一种对客户端透明的方式来动态地扩展对象的功能,它是通过继承扩展功能的替代方案之一。在现实生活中你也有很多装饰者的例子,例如:人需要各种各样的衣着,不管你穿着怎样,但是,对于你个人本质来说是不变的,充其量只是在外面加上了一些装饰,有,“遮羞的”、“保暖的”、“好看的”、“防雨的”....
常用的节点流:
- 文 件 FileInputStream FileOutputStrean FileReader FileWriter 文件进行处理的节点流。
- 字符串 StringReader StringWriter 对字符串进行处理的节点流。
- 数 组 ByteArrayInputStream ByteArrayOutputStream CharArrayReader CharArrayWriter 对数组进行处理的节点流(对应的不再是文件,而是内存中的一个数组)。
- 管 道 PipedInputStream、PipedOutputStream、PipedReader、PipedWriter对管道进行处理的节点流。
常用处理流:
- 缓冲流:BufferedInputStream、BufferedOutputStream、BufferedReader、BufferedWriter---增加缓冲功能,避免频繁读写硬盘。
- 转换流:InputStreamReader、OutputStreamReader---实现字节流和字符流之间的转换。
- 数据流:DataInputStream、DataOutputStream -提供读写Java基础数据类型功能
- 对象流:ObjectInputStream、ObjectOutputStream--提供直接读写Java对象功能
5 大顶级抽象父类们
| 输入流 | 输出流 | |
|---|---|---|
| 字节流 | 字节输入流InputStream | 字节输出流OutputStream |
| 字符流 | 字符输入流Reader | 字符输出流Writer |
6 字节输出流【OutputStream】
java.io.OutputStream 抽象类是表示字节输出流的所有类的超类,将指定的字节信息写出到目的地。它定义了字节输出流的基本共性功能方法。
public void write(int b):将指定的字节输出流。虽然参数为int类型四个字节,但是只会保留一个字节的信息写出。public void write(byte[] b):将 b.length字节从指定的字节数组写入此输出流。public void write(byte[] b, int off, int len):从指定的字节数组写入 len字节,从偏移量 off开始输出到此输出流。public void flush():刷新此输出流并强制任何缓冲的输出字节被写出。public void close():关闭此输出流并释放与此流相关联的任何系统资源。
小贴士:close方法,当完成流的操作时,必须调用此方法,释放系统资源。
7 FileOutputStream类
OutputStream有很多子类,我们从最简单的一个子类开始。java.io.FileOutputStream 类是文件输出流,用于将数据写出到文件。
public FileOutputStream(File file):创建文件输出流以写入由指定的 File对象表示的文件。public FileOutputStream(String name): 创建文件输出流以指定的名称写入文件。
当你创建一个流对象时,必须传入一个文件路径。如果该文件不存在,会创建该文件。如果有这个文件,会清空这个文件的数据。如果传入的是一个目录,则会报IOException异常。
8 字节输入流【InputStream】
java.io.InputStream 抽象类是表示字节输入流的所有类的超类,可以读取字节信息到内存中。它定义了字节输入流的基本共性功能方法。
public int read(): 从输入流读取一个字节。返回读取的字节值。虽然读取了一个字节,但是会自动提升为int类型。如果已经到达流末尾,没有数据可读,则返回-1。public int read(byte[] b): 从输入流中读取一些字节数,并将它们存储到字节数组 b中 。每次最多读取b.length个字节。返回实际读取的字节个数。如果已经到达流末尾,没有数据可读,则返回-1。public int read(byte[] b,int off,int len):从输入流中读取一些字节数,并将它们存储到字节数组 b中,从b[off]开始存储,每次最多读取len个字节 。返回实际读取的字节个数。如果已经到达流末尾,没有数据可读,则返回-1。public void close():关闭此输入流并释放与此流相关联的任何系统资源。
小贴士:close方法,当完成流的操作时,必须调用此方法,释放系统资源。
9 FileInputStream类
java.io.FileInputStream 类是文件输入流,从文件中读取字节。
FileInputStream(File file): 通过打开与实际文件的连接来创建一个 FileInputStream ,该文件由文件系统中的 File对象 file命名。FileInputStream(String name): 通过打开与实际文件的连接来创建一个 FileInputStream ,该文件由文件系统中的路径名 name命名。
当你创建一个流对象时,必须传入一个文件路径。如果文件不存在,会抛出FileNotFoundException 。如果传入的是一个目录,则会报IOException异常。
10 复制文件
复制图片文件,代码使用演示:
package com.atguigu.fileio;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class FileCopy {
public static void main(String[] args) throws IOException {
// 1.创建流对象
// 1.1 指定数据源
FileInputStream fis = new FileInputStream("D:\\test.jpg");
// 1.2 指定目的地
FileOutputStream fos = new FileOutputStream("test_copy.jpg");
// 2.读写数据
// 2.1 定义数组
byte[] b = new byte[1024];
// 2.2 定义长度
int len;
// 2.3 循环读取
while ((len = fis.read(b))!=-1) {
// 2.4 写出数据
fos.write(b, 0 , len);
}
// 3.关闭资源
fos.close();
fis.close();
}
}
11 字符输入流【Reader】
java.io.Reader抽象类是表示用于读取字符流的所有类的超类,可以读取字符信息到内存中。它定义了字符输入流的基本共性功能方法。
public int read(): 从输入流读取一个字符。 虽然读取了一个字符,但是会自动提升为int类型。返回该字符的Unicode编码值。如果已经到达流末尾了,则返回-1。public int read(char[] cbuf): 从输入流中读取一些字符,并将它们存储到字符数组 cbuf中 。每次最多读取cbuf.length个字符。返回实际读取的字符个数。如果已经到达流末尾,没有数据可读,则返回-1。public int read(char[] cbuf,int off,int len):从输入流中读取一些字符,并将它们存储到字符数组 cbuf中,从cbuf[off]开始的位置存储。每次最多读取len个字符。返回实际读取的字符个数。如果已经到达流末尾,没有数据可读,则返回-1。public void close():关闭此流并释放与此流相关联的任何系统资源。
小贴士:close方法,当完成流的操作时,必须调用此方法,释放系统资源。
12 FileReader类
java.io.FileReader 类是读取字符文件的便利类。构造时使用系统默认的字符编码和默认字节缓冲区。
FileReader(File file): 创建一个新的 FileReader ,给定要读取的File对象。FileReader(String fileName): 创建一个新的 FileReader ,给定要读取的文件的名称。
当你创建一个流对象时,必须传入一个文件路径。类似于FileInputStream 。如果该文件不存在,则报FileNotFoundException。如果传入的是一个目录,则会报IOException异常。
13 字符输出流【Writer】
java.io.Writer 抽象类是表示用于写出字符流的所有类的超类,将指定的字符信息写出到目的地。它定义了字节输出流的基本共性功能方法。
public void write(int c)写入单个字符。public void write(char[] cbuf)写入字符数组。public void write(char[] cbuf, int off, int len)写入字符数组的某一部分,off数组的开始索引,len写的字符个数。public void write(String str)写入字符串。public void write(String str, int off, int len)写入字符串的某一部分,off字符串的开始索引,len写的字符个数。public void flush()刷新该流的缓冲。public void close()关闭此流,但要先刷新它。
14 FileWriter类
java.io.FileWriter 类是写出字符到文件的便利类。构造时使用系统默认的字符编码和默认字节缓冲区。
FileWriter(File file): 创建一个新的 FileWriter,给定要读取的File对象。FileWriter(String fileName): 创建一个新的 FileWriter,给定要读取的文件的名称。
当你创建一个流对象时,必须传入一个文件路径,类似于FileOutputStream。如果文件不存在,则会自动创建。如果文件已经存在,则会清空文件内容,写入新的内容。
1、续写
public FileWriter(File file,boolean append): 创建文件输出流以写入由指定的 File对象表示的文件。public FileWriter(String fileName,boolean append): 创建文件输出流以指定的名称写入文件。
这两个构造方法,参数中都需要传入一个boolean类型的值,true 表示追加数据,false 表示清空原有数据。这样创建的输出流对象,就可以指定是否追加续写了,代码使用演示:
操作类似于FileOutputStream。
package com.atguigu.fileio;
import org.junit.Test;
import java.io.FileWriter;
import java.io.IOException;
public class FWWriteAppend {
@Test
public void test01()throws IOException {
// 使用文件名称创建流对象,可以续写数据
FileWriter fw = new FileWriter("fw.txt",true);
// 写出字符串
fw.write("尚硅谷真棒");
// 关闭资源
fw.close();
}
}
2、换行
package com.atguigu.fileio;
import java.io.FileWriter;
import java.io.IOException;
public class FWWriteNewLine {
public static void main(String[] args) throws IOException {
// 使用文件名称创建流对象,可以续写数据
FileWriter fw = new FileWriter("fw.txt");
// 写出字符串
fw.write("尚");
// 写出换行
fw.write("\r\n");
// 写出字符串
fw.write("硅谷");
// 关闭资源
fw.close();
}
}
3、关闭和刷新
【注意】FileWriter与FileOutputStream不同。因为内置缓冲区的原因,如果不关闭输出流,无法写出字符到文件中。但是关闭的流对象,是无法继续写出数据的。如果我们既想写出数据,又想继续使用流,就需要flush 方法了。
flush:刷新缓冲区,流对象可以继续使用。close:先刷新缓冲区,然后通知系统释放资源。流对象不可以再被使用了。
代码使用演示:
package com.atguigu.fileio;
import java.io.FileWriter;
import java.io.IOException;
public class FWWriteFlush {
public static void main(String[] args)throws IOException {
// 使用文件名称创建流对象
FileWriter fw = new FileWriter("fw.txt");
// 写出数据,通过flush
fw.write('刷'); // 写出第1个字符
fw.flush();
fw.write('新'); // 继续写出第2个字符,写出成功
fw.flush();
// 写出数据,通过close
fw.write('关'); // 写出第1个字符
fw.close();
fw.write('闭'); // 继续写出第2个字符,【报错】java.io.IOException: Stream closed
fw.close();
}
}
小贴士:即便是flush方法写出了数据,操作的最后还是要调用close方法,释放系统资源。
15 缓冲流
缓冲流,也叫高效流,按照数据类型分类:
- 字节缓冲流:
BufferedInputStream,BufferedOutputStream - 字符缓冲流:
BufferedReader,BufferedWriter
缓冲流的基本原理,是在创建流对象时,会创建一个内置的默认大小的缓冲区数组,通过缓冲区读写,减少系统IO次数,从而提高读写的效率。
1 构造方法
public BufferedInputStream(InputStream in):创建一个 新的缓冲输入流。public BufferedOutputStream(OutputStream out): 创建一个新的缓冲输出流。
构造举例,代码如下:
// 创建字节缓冲输入流
BufferedInputStream bis = new BufferedInputStream(new FileInputStream("bis.txt"));
// 创建字节缓冲输出流
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("bos.txt"));
public BufferedReader(Reader in):创建一个 新的缓冲输入流。public BufferedWriter(Writer out): 创建一个新的缓冲输出流。
构造举例,代码如下:
// 创建字符缓冲输入流
BufferedReader br = new BufferedReader(new FileReader("br.txt"));
// 创建字符缓冲输出流
BufferedWriter bw = new BufferedWriter(new FileWriter("bw.txt"));
16 InputStreamReader类
转换流java.io.InputStreamReader,是Reader的子类,是从字节流到字符流的桥梁。它读取字节,并使用指定的字符集将其解码为字符。它的字符集可以由名称指定,也可以接受平台的默认字符集。
InputStreamReader(InputStream in): 创建一个使用默认字符集的字符流。InputStreamReader(InputStream in, String charsetName): 创建一个指定字符集的字符流。
构造举例,代码如下:
InputStreamReader isr = new InputStreamReader(new FileInputStream("in.txt"));
InputStreamReader isr2 = new InputStreamReader(new FileInputStream("in.txt") , "GBK");
示例代码:
package com.atguigu.transfer;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
public class InputStreamReaderDemo {
public static void main(String[] args) throws IOException {
// 定义文件路径,文件为gbk编码
String fileName = "E:\\file_gbk.txt";
// 创建流对象,默认UTF8编码
InputStreamReader isr1 = new InputStreamReader(new FileInputStream(fileName));
// 定义变量,保存字符
int charData;
// 使用默认编码字符流读取,乱码
while ((charData = isr1.read()) != -1) {
System.out.print((char)charData); // ��Һ�
}
isr1.close();
// 创建流对象,指定GBK编码
InputStreamReader isr2 = new InputStreamReader(new FileInputStream(fileName) , "GBK");
// 使用指定编码字符流读取,正常解析
while ((charData = isr2.read()) != -1) {
System.out.print((char)charData);// 大家好
}
isr2.close();
}
}
17 OutputStreamWriter类
转换流java.io.OutputStreamWriter ,是Writer的子类,是从字符流到字节流的桥梁。使用指定的字符集将字符编码为字节。它的字符集可以由名称指定,也可以接受平台的默认字符集。
OutputStreamWriter(OutputStream in): 创建一个使用默认字符集的字符流。OutputStreamWriter(OutputStream in, String charsetName): 创建一个指定字符集的字符流。
package com.atguigu.transfer;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStreamWriter;
public class OutputStreamWriterDemo {
public static void main(String[] args) throws IOException {
// 定义文件路径
String FileName = "E:\\out_utf8.txt";
// 创建流对象,默认UTF8编码
OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream(FileName));
// 写出数据
osw.write("你好"); // 保存为6个字节
osw.close();
// 定义文件路径
String FileName2 = "E:\\out_gbk.txt";
// 创建流对象,指定GBK编码
OutputStreamWriter osw2 = new OutputStreamWriter(new FileOutputStream(FileName2),"GBK");
// 写出数据
osw2.write("你好");// 保存为4个字节
osw2.close();
}
}
18 数据流与对象流
前面学习的IO流,在程序代码中,要么将数据直接按照字节处理,要么按照字符处理。那么,如果读写Java其他数据类型的数据,怎么办呢?
String name = “巫师”;
int age = 300;
char gender = ‘男’;
int energy = 5000;
double price = 75.5;
boolean relive = true;
Student stu = new Student("张三",23,89);
Java提供了数据流和对象流来处理这些类型的数据:
- DataOutputStream:数据输出流允许应用程序以适当方式将基本 Java 数据类型写入输出流中。然后,应用程序可以使用数据输入流(DataInputStream)将数据读入。
- DataInputStream:数据输入流允许应用程序以与机器无关方式从底层输入流中读取基本 Java 数据类型。
- ObjectOutputStream:将 Java 基本数据类型和对象写入字节输出流中。稍后可以使用 ObjectInputStream 将数据读入。通过在流中使用文件可以实现Java各种基本数据类型的数据以及对象的持久存储。如果流是网络套接字流,则可以在另一台主机上或另一个进程中接收这些数据或重构对象。
- ObjectInputStream:ObjectInputStream 对以前使用 ObjectOutputStream 写入的基本数据和对象进行反序列化。
因为DataOutputStream和DataInputStream只支持Java基本数据类型和字符串的读写,而不支持Java对象的对象。而ObjectOutputStream和ObjectInputStream既支持Java基本数据类型的数据读写,又支持Java对象的读写,所以下面直接介绍对象流ObjectOutputStream和ObjectInputStream即可。
public ObjectOutputStream(OutputStream out): 创建一个指定OutputStream的ObjectOutputStream。public ObjectInputStream(InputStream in): 创建一个指定InputStream的ObjectInputStream。
构造举例,代码如下:
FileOutputStream fos = new FileOutputStream("game.dat");
ObjectOutputStream oos = new ObjectOutputStream(fos);
FileInputStream fis = new FileInputStream("game.dat");
ObjectInputStream ois = new ObjectInputStream(fis);
19 使用对象流读写各种类型的数据
ObjectOutpuStream也从OutputStream父类中继承基本方法:
public void write(int b):将指定的字节输出流。虽然参数为int类型四个字节,但是只会保留一个字节的信息写出。public void write(byte[] b):将 b.length字节从指定的字节数组写入此输出流。public void write(byte[] b, int off, int len):从指定的字节数组写入 len字节,从偏移量 off开始输出到此输出流。public void flush():刷新此输出流并强制任何缓冲的输出字节被写出。public void close():关闭此输出流并释放与此流相关联的任何系统资源。
还支持将各种Java数据类型的数据写入输出流中:
- public void writeBoolean(boolean val):写入一个 boolean 值。
- public void writeByte(int val):写入一个8位字节。
- public void writeShort(int val):写入一个16位的 short 值。
- public void writeChar(int val):写入一个16位的 char 值。
- public void writeInt(int val):写入一个32位的 int 值。
- public void writeLong(long val):写入一个64位的 long 值。
- public void writeFloat(float val):写入一个32位的 float 值。
- public void writeDouble(double val):写入一个64位的 double 值。
- public void writeUTF(String str):将表示长度信息的两个字节写入输出流,后跟字符串 s 中每个字符的 UTF-8 修改版表示形式。如果 s 为 null,则抛出 NullPointerException。根据字符的值,将字符串 s 中每个字符转换成一个字节、两个字节或三个字节的字节组。注意,将 String 作为基本数据写入流中与将它作为 Object 写入流中明显不同。
ObjectInputStream除了从InputStream父类中继承基本方法之外,
public int read(): 从输入流读取一个字节。返回读取的字节值。虽然读取了一个字节,但是会自动提升为int类型。如果已经到达流末尾,没有数据可读,则返回-1。public int read(byte[] b): 从输入流中读取一些字节数,并将它们存储到字节数组 b中 。每次最多读取b.length个字节。返回实际读取的字节个数。如果已经到达流末尾,没有数据可读,则返回-1。public int read(byte[] b,int off,int len):从输入流中读取一些字节数,并将它们存储到字节数组 b中,从b[off]开始存储,每次最多读取len个字节 。返回实际读取的字节个数。如果已经到达流末尾,没有数据可读,则返回-1。public void close():关闭此输入流并释放与此流相关联的任何系统资源。
还支持从输入流中读取各种Java数据类型的数据:
- public boolean readBoolean():读取一个 boolean 值。
- public byte readByte():读取一个 8 位的字节。
- public short readShort():读取一个 16 位的 short 值。
- public char readChar():读取一个 16 位的 char 值。
- public int readInt():读取一个 32 位的 int 值。
- public long readLong():读取一个 64 位的 long 值。
- public float readFloat():读取一个 32 位的 float 值。
- public double readDouble():读取一个 64 位的 double 值。
- public String readUTF():读取 UTF-8 修改版格式的 String。
注意:读的顺序和方法与写的顺序和方法要一一对应。
示例代码:
package com.atguigu.object;
import org.junit.Test;
import java.io.*;
public class ReadWriteDataOfAnyType {
@Test
public void save() throws IOException {
String name = "巫师";
int age = 300;
char gender = '男';
int energy = 5000;
double price = 75.5;
boolean relive = true;
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("game.dat"));
oos.writeUTF(name);
oos.writeInt(age);
oos.writeChar(gender);
oos.writeInt(energy);
oos.writeDouble(price);
oos.writeBoolean(relive);
oos.close();
}
@Test
public void reload()throws IOException{
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("game.dat"));
String name = ois.readUTF();
int age = ois.readInt();
char gender = ois.readChar();
int energy = ois.readInt();
double price = ois.readDouble();
boolean relive = ois.readBoolean();
System.out.println(name+"," + age + "," + gender + "," + energy + "," + price + "," + relive);
ois.close();
}
}
20 序列化与反序列化概念
Java 提供了一种对象序列化的机制。用一个字节序列可以表示一个对象,该字节序列包含该对象的类型和对象中存储的属性等信息。字节序列写出到文件之后,相当于文件中持久保存了一个对象的信息。
反之,该字节序列还可以从文件中读取回来,重构对象,对它进行反序列化。对象的数据、对象的类型和对象中存储的数据信息,都可以用来在内存中创建对象。看图理解序列化:
ObjectOutputStream流中支持序列化的方法是:
public final void writeObject (Object obj): 将指定的对象写出。
ObjectInputStream流中支持反序列化的方法是:
public final Object readObject (): 读取一个对象。
21 Serializable序列化接口与transient关键字
某个类的对象需要序列化输出时,该类必须实现java.io.Serializable 接口,Serializable 是一个标记接口,不实现此接口的类将不会使任何状态序列化或反序列化,会抛出NotSerializableException 。
- 如果对象的某个属性也是引用数据类型,那么如果该属性也要序列化的话,也要实现
Serializable接口 - 该类的所有属性必须是可序列化的。如果有一个属性不需要可序列化的,则该属性必须注明是瞬态的,使用
transient关键字修饰。 - 静态变量的值不会序列化。因为静态变量的值不属于某个对象。
JavaSE_第15章 网络编程
1 软件结构
C/S结构 :全称为Client/Server结构,是指客户端和服务器结构。常见程序有QQ、红蜘蛛、飞秋等软件。
B/S结构 :全称为Browser/Server结构,是指浏览器和服务器结构。常见浏览器有IE、谷歌、火狐等。
两种架构各有优势,但是无论哪种架构,都离不开网络的支持。网络编程,就是在一定的协议下,实现两台计算机的通信的程序。
2 IP地址和域名
1、IP地址
IP地址:指互联网协议地址(Internet Protocol Address),俗称IP。IP地址用来给一个网络中的计算机设备做唯一的编号。假如我们把“个人电脑”比作“一台电话”的话,那么“IP地址”就相当于“电话号码”。
IP地址分类方式一:
-
IPv4:是一个32位的二进制数,通常被分为4个字节,表示成
a.b.c.d的形式,例如192.168.65.100。其中a、b、c、d都是0~255之间的十进制整数,那么最多可以表示42亿个。 -
IPv6:由于互联网的蓬勃发展,IP地址的需求量愈来愈大,但是网络地址资源有限,使得IP的分配越发紧张。
为了扩大地址空间,拟通过IPv6重新定义地址空间,采用128位地址长度,每16个字节一组,分成8组十六进制数,表示成
ABCD:EF01:2345:6789:ABCD:EF01:2345:6789,号称可以为全世界的每一粒沙子编上一个网址,这样就解决了网络地址资源数量不够的问题。IPv4和IPv6地址格式不相同,因此在很长一段时间里,互联网中出现IPv4和IPv6长期共存的局面。2012年6月6日,国际互联网协会举行了世界IPv6启动纪念日,这一天,全球IPv6网络正式启动。多家知名网站,如Google、Facebook和Yahoo等,于当天全球标准时间0点(北京时间8点整)开始永久性支持IPv6访问。2018年6月,三大运营商联合阿里云宣布,将全面对外提供IPv6服务,并计划在2025年前助推中国互联网真正实现“IPv6 Only”。 7月,百度云制定了中国的IPv6改造方案。8月3日,工信部通信司在北京召开IPv6规模部署及专项督查工作全国电视电话会议,中国将分阶段有序推进规模建设IPv6网络,实现下一代互联网在经济社会各领域深度融合。
IP地址分类方式二:
公网地址( 万维网使用)和 私有地址( 局域网使用)。192.168.开头的就是私有址址,范围即为192.168.0.0--192.168.255.255,专门为组织机构内部使用
常用命令:
- 查看本机IP地址,在控制台输入:
ipconfig
- 检查网络是否连通,在控制台输入:
ping 空格 IP地址
ping 220.181.57.216
特殊的IP地址:
- 本地回环地址(hostAddress):
127.0.0.1 - 主机名(hostName):
localhost
2、域名
因为IP地址数字不便于记忆,因此出现了域名,域名容易记忆,当在连接网络时输入一个主机的域名后,域名服务器(DNS)负责将域名转化成IP地址,这样才能和主机建立连接。 ------- 域名解析
- 在浏览器中输入www . qq .com 域名,操作系统会先检查自己本地的hosts文件是否有这个网址映射关系,如果有,就先调用这个IP地址映射,完成域名解析。
- 如果hosts里没有这个域名的映射,则查找本地DNS解析器缓存,是否有这个网址映射关系,如果有,直接返回,完成域名解析。
- 如果hosts与本地DNS解析器缓存都没有相应的网址映射关系,首先会找TCP/ip参数中设置的首选DNS服务器,在此我们叫它本地DNS服务器,此服务器收到查询时,如果要查询的域名,包含在本地配置区域资源中,则返回解析结果给客户机,完成域名解析,此解析具有权威性。
- 如果要查询的域名,不由本地DNS服务器区域解析,但该服务器已缓存了此网址映射关系,则调用这个IP地址映射,完成域名解析,此解析不具有权威性。
- 如果本地DNS服务器本地区域文件与缓存解析都失效,则根据本地DNS服务器的设置(是否设置转发器)进行查询,如果未用转发模式,本地DNS就把请求发至13台根DNS,根DNS服务器收到请求后会判断这个域名(.com)是谁来授权管理,并会返回一个负责该顶级域名服务器的一个IP。本地DNS服务器收到IP信息后,将会联系负责.com域的这台服务器。这台负责.com域的服务器收到请求后,如果自己无法解析,它就会找一个管理.com域的下一级DNS服务器地址(http://qq.com)给本地DNS服务器。当本地DNS服务器收到这个地址后,就会找(http://qq.com)域服务器,重复上面的动作,进行查询,直至找到www . qq .com主机。
- 如果用的是转发模式,此DNS服务器就会把请求转发至上一级DNS服务器,由上一级服务器进行解析,上一级服务器如果不能解析,或找根DNS或把转请求转至上上级,以此循环。不管是本地DNS服务器用是是转发,还是根提示,最后都是把结果返回给本地DNS服务器,由此DNS服务器再返回给客户机。
3 端口号
网络的通信,本质上是两个进程(应用程序)的通信。每台计算机都有很多的进程,那么在网络通信时,如何区分这些进程呢?
如果说IP地址可以唯一标识网络中的设备,那么端口号就可以唯一标识设备中的进程(应用程序)了。
- 端口号:用两个字节表示的整数,它的取值范围是0~65535。
- 公认端口:0~1023。被预先定义的服务通信占用,如:HTTP(80),FTP(21),Telnet(23)
- 注册端口:1024~49151。分配给用户进程或应用程序。如:Tomcat(8080),MySQL(3306),Oracle(1521)。
- 动态/ 私有端口:49152~65535。
如果端口号被另外一个服务或应用所占用,会导致当前程序启动失败。
4 网络通信协议
- 网络通信协议:通过计算机网络可以使多台计算机实现连接,位于同一个网络中的计算机在进行连接和通信时需要遵守一定的规则,这就好比在道路中行驶的汽车一定要遵守交通规则一样。在计算机网络中,这些连接和通信的规则被称为网络通信协议,它对数据的传输格式、传输速率、传输步骤等做了统一规定,通信双方必须同时遵守才能完成数据交换。
- TCP/IP协议: 传输控制协议/因特网互联协议( Transmission Control Protocol/Internet Protocol),是Internet最基本、最广泛的协议。它定义了计算机如何连入因特网,以及数据如何在它们之间传输的标准。它的内部包含一系列的用于处理数据通信的协议,并采用了4层的分层模型,每一层都呼叫它的下一层所提供的协议来完成自己的需求。
上图中,OSI参考模型:模型过于理想化,未能在因特网上进行广泛推广。 TCP/IP参考模型(或TCP/IP协议):事实上的国际标准。
- TCP/IP协议中的四层分别是应用层、传输层、网络层和链路层,每层分别负责不同的通信功能。
链路层:链路层是用于定义物理传输通道,通常是对某些网络连接设备的驱动协议,例如针对光纤、网线提供的驱动。 - 网络层:网络层是整个TCP/IP协议的核心,它主要用于将传输的数据进行分组,将分组数据发送到目标计算机或者网络。而IP协议是一种非常重要的协议。IP(internet protocal)又称为互联网协议。IP的责任就是把数据从源传送到目的地。它在源地址和目的地址之间传送一种称之为数据包的东西,它还提供对数据大小的重新组装功能,以适应不同网络对包大小的要求。
- 传输层:主要使网络程序进行通信,在进行网络通信时,可以采用TCP协议,也可以采用UDP协议。TCP(Transmission Control Protocol)协议,即传输控制协议,是一种面向连接的、可靠的、基于字节流的传输层通信协议。UDP(User Datagram Protocol,用户数据报协议):是一个无连接的传输层协议、提供面向事务的简单不可靠的信息传送服务。
- 应用层:主要负责应用程序的协议,例如HTTP协议、FTP协议、SNMP(简单网络管理协议)、SMTP(简单邮件传输协议)和POP3(Post Office Protocol 3的简称,即邮局协议的第3个版)等。
而通常我们说的TCP/IP协议,其实是指TCP/IP协议族,因为该协议家族的两个最核心协议:TCP(传输控制协议)和IP(网际协议),为该家族中最早通过的标准,所以简称为TCP/IP协议。
5 UDP协议
UDP:用户数据报协议(User Datagram Protocol),它是非面向连的,不可靠的无连接通信协议,即在数据传输时,数据的发送端和接收端不建立逻辑连接。简单来说,当一台计算机向另外一台计算机发送数据时,发送端不会确认接收端是否存在,就会发出数据,同样接收端在收到数据时,也不会向发送端反馈是否收到数据。
由于使用UDP协议消耗资源小,通信效率高,所以通常都会用于音频、视频和普通数据的传输例如视频会议都使用UDP协议,因为这种情况即使偶尔丢失一两个数据包,也不会对接收结果产生太大影响。
但是在使用UDP协议传送数据时,由于UDP的面向无连接性,不能保证数据的完整性,因此在传输重要数据时不建议使用UDP协议。
- 大小限制的:数据被限制在64kb以内,超出这个范围就不能发送了。
- 数据报(Datagram):网络传输的基本单位
6 TCP协议
TCP:传输控制协议 (Transmission Control Protocol)。它是面向连接的,可靠的通信协议,即传输数据之前,在发送端和接收端建立逻辑连接,然后再传输数据,它提供了两台计算机之间可靠无差错的数据传输。是一种面向连接的、可靠的、基于字节流的传输层的通信协议,可以连续传输大量的数据。类似于打电话的效果。
这是因为它为当一台计算机需要与另一台远程计算机连接时,TCP协议会采用“三次握手”方式让它们建立一个连接,用于发送和接收数据的虚拟链路。数据传输完毕TCP协议会采用“四次挥手”方式断开连接。
TCP协议负责收集这些数据信息包,并将其按适当的次序放好传送,在接收端收到后再将其正确的还原。TCP协议保证了数据包在传送中准确无误。TCP协议使用重发机制,当一个通信实体发送一个消息给另一个通信实体后,需要收到另一个通信实体确认信息,如果没有收到另一个通信实体确认信息,则会再次重复刚才发送的消息。
1、三次握手
TCP协议中,在发送数据的准备阶段,客户端与服务器之间的三次交互,以保证连接的可靠。
- 第一次握手,客户端向服务器端发出连接请求,等待服务器确认。
- 第二次握手,服务器端向客户端回送一个响应,通知客户端收到了连接请求。
- 第三次握手,客户端再次向服务器端发送确认信息,确认连接。
完成三次握手,连接建立后,客户端和服务器就可以开始进行数据传输了。由于这种面向连接的特性,TCP协议可以保证传输数据的安全,所以应用十分广泛,例如下载文件、浏览网页等。
2、四次挥手
TCP协议中,在发送数据结束后,释放连接时需要经过四次挥手。
- 第一次挥手:客户端向服务器端提出结束连接,让服务器做最后的准备工作。此时,客户端处于半关闭状态,即表示不再向服务器发送数据了,但是还可以接受数据。
- 第二次挥手:服务器接收到客户端释放连接的请求后,会将最后的数据发给客户端。并告知上层的应用进程不再接收数据。
- 第三次挥手:服务器发送完数据后,会给客户端发送一个释放连接的报文。那么客户端接收后就知道可以正式释放连接了。
- 第四次挥手:客户端接收到服务器最后的释放连接报文后,要回复一个彻底断开的报文。这样服务器收到后才会彻底释放连接。这里客户端,发送完最后的报文后,会等待2MSL,因为有可能服务器没有收到最后的报文,那么服务器迟迟没收到,就会再次给客户端发送释放连接的报文,此时客户端在等待时间范围内接收到,会重新发送最后的报文,并重新计时。如果等待2MSL后,没有收到,那么彻底断开。
7 Socket分类
通信的两端都要有Socket(也可以叫“套接字”),是两台机器间通信的端点。网络通信其实就是Socket间的通信。Socket可以分为:
- 流套接字(stream socket):使用TCP提供可依赖的字节流服务
- ServerSocket:此类实现TCP服务器套接字。服务器套接字等待请求通过网络传入。
- Socket:此类实现客户端套接字(也可以就叫“套接字”)。套接字是两台机器间通信的端点。
- 数据报套接字(datagram socket):使用UDP提供“尽力而为”的数据报服务
- DatagramSocket:此类表示用来发送和接收UDP数据报包的套接字。
1、ServerSocket类
ServerSocket类的构造方法:
- ServerSocket(int port) :创建绑定到特定端口的服务器套接字。
ServerSocket类的常用方法:
- Socket accept():侦听并接受到此套接字的连接。
2、Sokcet类
Socket类的常用构造方法:
- public Socket(InetAddress address,int port):创建一个流套接字并将其连接到指定 IP 地址的指定端口号。
- public Socket(String host,int port):创建一个流套接字并将其连接到指定主机上的指定端口号。
Socket类的常用方法:
- public InputStream getInputStream():返回此套接字的输入流,可以用于接收消息
- public OutputStream getOutputStream():返回此套接字的输出流,可以用于发送消息
- public InetAddress getInetAddress():此套接字连接到的远程 IP 地址;如果套接字是未连接的,则返回 null。
- public InetAddress getLocalAddress():获取套接字绑定的本地地址。
- public int getPort():此套接字连接到的远程端口号;如果尚未连接套接字,则返回 0。
- public int getLocalPort():返回此套接字绑定到的本地端口。如果尚未绑定套接字,则返回 -1。
- public void close():关闭此套接字。套接字被关闭后,便不可在以后的网络连接中使用(即无法重新连接或重新绑定)。需要创建新的套接字对象。 关闭此套接字也将会关闭该套接字的 InputStream 和 OutputStream。
- public void shutdownInput():如果在套接字上调用 shutdownInput() 后从套接字输入流读取内容,则流将返回 EOF(文件结束符)。 即不能在从此套接字的输入流中接收任何数据。
- public void shutdownOutput():禁用此套接字的输出流。对于 TCP 套接字,任何以前写入的数据都将被发送,并且后跟 TCP 的正常连接终止序列。 如果在套接字上调用 shutdownOutput() 后写入套接字输出流,则该流将抛出 IOException。 即不能通过此套接字的输出流发送任何数据。
注意:先后调用Socket的shutdownInput()和shutdownOutput()方法,仅仅关闭了输入流和输出流,并不等于调用Socket的close()方法。在通信结束后,仍然要调用Scoket的close()方法,因为只有该方法才会释放Socket占用的资源,比如占用的本地端口号等。
3、DatagramSocket
DatagramSocket 类的常用方法:
- public DatagramSocket(int port)创建数据报套接字并将其绑定到本地主机上的指定端口。套接字将被绑定到通配符地址,IP 地址由内核来选择。
- public DatagramSocket(int port,InetAddress laddr)创建数据报套接字,将其绑定到指定的本地地址。本地端口必须在 0 到 65535 之间(包括两者)。如果 IP 地址为 0.0.0.0,套接字将被绑定到通配符地址,IP 地址由内核选择。
- public void close()关闭此数据报套接字。
- public void send(DatagramPacket p)从此套接字发送数据报包。DatagramPacket 包含的信息指示:将要发送的数据、其长度、远程主机的 IP 地址和远程主机的端口号。
- public void receive(DatagramPacket p)从此套接字接收数据报包。当此方法返回时,DatagramPacket 的缓冲区填充了接收的数据。数据报包也包含发送方的 IP 地址和发送方机器上的端口号。 此方法在接收到数据报前一直阻塞。数据报包对象的 length 字段包含所接收信息的长度。如果信息比包的长度长,该信息将被截短。
4、DatagramPacket类
DatagramPacket类的常用方法:
- public DatagramPacket(byte[] buf,int length)构造 DatagramPacket,用来接收长度为 length 的数据包。 length 参数必须小于等于 buf.length。
- public DatagramPacket(byte[] buf,int length,InetAddress address,int port)构造数据报包,用来将长度为 length 的包发送到指定主机上的指定端口号。length 参数必须小于等于 buf.length。
- public int getLength()返回将要发送或接收到的数据的长度。
8 开发步骤
服务器端程序包含以下四个基本的 步骤:
- 调用 ServerSocket(int port) :创建一个服务器端套接字,并绑定到指定端口上。用于监听客户端的请求。
- 调用 accept() :监听连接请求,如果客户端请求连接,则接受连接,返回通信套接字对象。
- 调用 该Socket 类对象的 getOutputStream() 和 getInputStream () :获取输出流和输入流,开始网络数据的发送和接收。
- 关闭Socket 对象:客户端访问结束,关闭通信套接字。
客户端程序包含以下四个基本的步骤 :
- 创建 Socket :根据指定服务端的 IP 地址或端口号构造 Socket 类对象。若服务器端响应,则建立客户端到服务器的通信线路。若连接失败,会出现异常。
- 打开连接到 Socket 的输入/ 出流: 使用 getInputStream()方法获得输入流,使用getOutputStream()方法获得输出流,进行数据传输
- 按照一定的协议对 Socket 进行读/ 写操作:通过输入流读取服务器放入线路的信息(但不能读取自己放入线路的信息),通过输出流将信息写入线路。
- 关闭 Socket :断开客户端到服务器的连接,释放线路
9 演示单个客户端与服务器单次通信
需求:客户端连接服务器,连接成功后给服务发送“lalala”,服务器收到消息后,给客户端返回“欢迎登录”,客户端接收消息后,断开连接
1、服务器端示例代码
package com.atguigu.tcp.one;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.InetAddress;
import java.net.ServerSocket;
import java.net.Socket;
public class Server {
public static void main(String[] args)throws Exception {
//1、准备一个ServerSocket对象,并绑定8888端口
ServerSocket server = new ServerSocket(8888);
System.out.println("等待连接....");
//2、在8888端口监听客户端的连接,该方法是个阻塞的方法,如果没有客户端连接,将一直等待
Socket socket = server.accept();
InetAddress inetAddress = socket.getInetAddress();
System.out.println(inetAddress.getHostAddress() + "客户端连接成功!!");
//3、获取输入流,用来接收该客户端发送给服务器的数据
InputStream input = socket.getInputStream();
//接收数据
byte[] data = new byte[1024];
StringBuilder s = new StringBuilder();
int len;
while ((len = input.read(data)) != -1) {
s.append(new String(data, 0, len));
}
System.out.println(inetAddress.getHostAddress() + "客户端发送的消息是:" + s);
//4、获取输出流,用来发送数据给该客户端
OutputStream out = socket.getOutputStream();
//发送数据
out.write("欢迎登录".getBytes());
out.flush();
//5、关闭socket,不再与该客户端通信
//socket关闭,意味着InputStream和OutputStream也关闭了
socket.close();
//6、如果不再接收任何客户端通信,可以关闭ServerSocket
server.close();
}
}
2、客户端示例代码
package com.atguigu.tcp.one;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.Socket;
public class Client {
public static void main(String[] args) throws Exception {
// 1、准备Socket,连接服务器,需要指定服务器的IP地址和端口号
Socket socket = new Socket("127.0.0.1", 8888);
// 2、获取输出流,用来发送数据给服务器
OutputStream out = socket.getOutputStream();
// 发送数据
out.write("lalala".getBytes());
//会在流末尾写入一个“流的末尾”标记,对方才能读到-1,否则对方的读取方法会一致阻塞
socket.shutdownOutput();
//3、获取输入流,用来接收服务器发送给该客户端的数据
InputStream input = socket.getInputStream();
// 接收数据
byte[] data = new byte[1024];
StringBuilder s = new StringBuilder();
int len;
while ((len = input.read(data)) != -1) {
s.append(new String(data, 0, len));
}
System.out.println("服务器返回的消息是:" + s);
//4、关闭socket,不再与服务器通信,即断开与服务器的连接
//socket关闭,意味着InputStream和OutputStream也关闭了
socket.close();
}
}
10 演示多个客户端与服务器之间的多次通信
通常情况下,服务器不应该只接受一个客户端请求,而应该不断地接受来自客户端的所有请求,所以Java程序通常会通过循环,不断地调用ServerSocket的accept()方法。
如果服务器端要“同时”处理多个客户端的请求,因此服务器端需要为每一个客户端单独分配一个线程来处理,否则无法实现“同时”。
咱们之前学习IO流的时候,提到过装饰者设计模式,该设计使得不管底层IO流是怎样的节点流:文件流也好,网络Socket产生的流也好,程序都可以将其包装成处理流,甚至可以多层包装,从而提供更多方便的处理。
案例需求:多个客户端连接服务器,并进行多次通信
- 每一个客户端连接成功后,从键盘输入英文单词或中国成语,并发送给服务器
- 服务器收到客户端的消息后,把词语“反转”后返回给客户端
- 客户端接收服务器返回的“词语”,打印显示
- 当客户端输入“stop”时断开与服务器的连接
- 多个客户端可以同时给服务器发送“词语”,服务器可以“同时”处理多个客户端的请求
1、服务器端示例代码
package com.atguigu.tcp.many;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.PrintStream;
import java.net.ServerSocket;
import java.net.Socket;
public class Server {
public static void main(String[] args) throws IOException {
// 1、准备一个ServerSocket
ServerSocket server = new ServerSocket(8888);
System.out.println("等待连接...");
int count = 0;
while(true){
// 2、监听一个客户端的连接
Socket socket = server.accept();
System.out.println("第" + ++count + "个客户端"+socket.getInetAddress().getHostAddress()+"连接成功!!");
ClientHandlerThread ct = new ClientHandlerThread(socket);
ct.start();
}
//这里没有关闭server,永远监听
}
static class ClientHandlerThread extends Thread{
private Socket socket;
private String ip;
public ClientHandlerThread(Socket socket) {
super();
this.socket = socket;
ip = socket.getInetAddress().getHostAddress();
}
public void run(){
try{
//(1)获取输入流,用来接收该客户端发送给服务器的数据
BufferedReader br = new BufferedReader(new InputStreamReader(socket.getInputStream()));
//(2)获取输出流,用来发送数据给该客户端
PrintStream ps = new PrintStream(socket.getOutputStream());
String str;
// (3)接收数据
while ((str = br.readLine()) != null) {
//(4)反转
StringBuilder word = new StringBuilder(str);
word.reverse();
//(5)返回给客户端
ps.println(word);
}
System.out.println("客户端" + ip+"正常退出");
}catch(Exception e){
System.out.println("客户端" + ip+"意外退出");
}finally{
try {
//(6)断开连接
socket.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
2、客户端示例代码
package com.atguigu.tcp.many;
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStream;
import java.io.PrintStream;
import java.net.Socket;
import java.util.Scanner;
public class Client {
public static void main(String[] args) throws Exception {
// 1、准备Socket,连接服务器,需要指定服务器的IP地址和端口号
Socket socket = new Socket("127.0.0.1", 8888);
// 2、获取输出流,用来发送数据给服务器
OutputStream out = socket.getOutputStream();
PrintStream ps = new PrintStream(out);
// 3、获取输入流,用来接收服务器发送给该客户端的数据
InputStream input = socket.getInputStream();
BufferedReader br;
if(args!= null && args.length>0) {
String encoding = args[0];
br = new BufferedReader(new InputStreamReader(input,encoding));
}else{
br = new BufferedReader(new InputStreamReader(input));
}
Scanner scanner = new Scanner(System.in);
while(true){
System.out.println("输入发送给服务器的单词或成语:");
String message = scanner.nextLine();
if(message.equals("stop")){
socket.shutdownOutput();
break;
}
// 4、 发送数据
ps.println(message);
// 接收数据
String feedback = br.readLine();
System.out.println("从服务器收到的反馈是:" + feedback);
}
//5、关闭socket,断开与服务器的连接
scanner.close();
socket.close();
}
}
JavaSE_第16章 反射
1 反射的概念
Java程序中,所有的对象都有两种类型:编译时类型和运行时类型,而很多时候对象的编译时类型和运行时类型不一致。
因为加载完类之后,就产生了一个Class类型的对象,并将引用存储到方法区,那么每一个类在方法区内存都可以找到唯一Class对象与之对应,这个对象包含了完整的类的结构信息,我们可以通过这个对象获取类的结构。这种机制就像一面镜子,Class对象像是类在镜子中的镜像,通过观察这个镜像就可以知道类的结构,所以,把这种机制形象地称为反射机制。
非反射:类(原物)-->类信息
反射:Class对象(镜像)-->类(原物)
2 类的加载过程
当程序主动使用某个类时,如果该类还未被加载到内存中,系统会通过加载、连接、初始化三个步骤来对该类进行初始化,如果没有意外,JVM将会连续完成这三个步骤,所以有时也把这三个步骤统称为类加载。
类的加载又分为三个阶段:
(1)加载:load
就是指将类型的class字节码数据读入内存
(2)连接:link
①验证:校验合法性等
②准备:准备对应的内存(方法区),创建Class对象,为类变量赋默认值,为静态常量赋初始值。
③解析:把字节码中的符号引用替换为对应的直接地址引用
(3)初始化:initialize(类初始化)即执行
3 类初始化
1、哪些操作会导致类的初始化?
(1)运行主方法所在的类,要先完成类初始化,再执行main方法
(2)第一次使用某个类型就是在new它的对象,此时这个类没有初始化的话,先完成类初始化再做实例初始化
(3)调用某个类的静态成员(类变量和类方法),此时这个类没有初始化的话,先完成类初始化
(4)子类初始化时,发现它的父类还没有初始化的话,那么先初始化父类
(5)通过反射操作某个类时,如果这个类没有初始化,也会导致该类先初始化
类初始化执行的是
(),该方法由(1)类变量的显式赋值代码(2)静态代码块中的代码构成
2、哪些使用类的操作,但是不会导致类的初始化?
(1)使用某个类的静态的常量(static final)
(2)通过子类调用父类的静态变量,静态方法,只会导致父类初始化,不会导致子类初始化,即只有声明静态成员的类才会初始化
(3)用某个类型声明数组并创建数组对象时,不会导致这个类初始化
4 类加载器
很多开发人员都遇到过java.lang.ClassNotFoundException或java.lang.NoClassDefError,想要更好的解决这类问题,或者在一些特殊的应用场景,比如需要支持类的动态加载或需要对编译后的字节码文件进行加密解密操作,那么需要你自定义类加载器,因此了解类加载器及其类加载机制也就成了每一个Java开发人员的必备技能之一。
1、类加载器分为:
(1)引导类加载器(Bootstrap Classloader)又称为根类加载器
它负责加载jre/rt.jar核心库
它本身不是Java代码实现的,也不是ClassLoader的子类,获取它的对象时往往返回null
(2)扩展类加载器(Extension ClassLoader)
它负责加载jre/lib/ext扩展库
它是ClassLoader的子类
(3)应用程序类加载器(Application Classloader)
它负责加载项目的classpath路径下的类
它是ClassLoader的子类
(4)自定义类加载器
当你的程序需要加载“特定”目录下的类,可以自定义类加载器;
当你的程序的字节码文件需要加密时,那么往往会提供一个自定义类加载器对其进行解码
后面会见到的自定义类加载器:tomcat中
2、Java系统类加载器的双亲委托模式
简单描述:
下一级的类加载器,如果接到任务时,会先搜索是否加载过,如果没有,会先把任务往上传,如果都没有加载过,一直到根加载器,如果根加载器在它负责的路径下没有找到,会往回传,如果一路回传到最后一级都没有找到,那么会报ClassNotFoundException或NoClassDefError,如果在某一级找到了,就直接返回Class对象。
应用程序类加载器 把 扩展类加载器视为父加载器,
扩展类加载器 把 引导类加载器视为父加载器。
不是继承关系,是组合的方式实现的。
5获取Class对象的四种方式
(1)类型名.class
要求编译期间已知类型
(2)对象.getClass()
获取对象的运行时类型
(3)Class.forName(类型全名称)
可以获取编译期间未知的类型
(4)ClassLoader的类加载器对象.loadClass(类型全名称)
可以用系统类加载对象或自定义加载器对象加载指定路径下的类型
package com.atguigu.classtype;
import org.junit.Test;
public class GetClassObject {
@Test
public void test01() throws ClassNotFoundException{
Class c1 = GetClassObject.class;
GetClassObject obj = new GetClassObject();
Class c2 = obj.getClass();
Class c3 = Class.forName("com.atguigu.classtype.GetClassObject");
Class c4 = ClassLoader.getSystemClassLoader().loadClass("com.atguigu.classtype.GetClassObject");
System.out.println("c1 = " + c1);
System.out.println("c2 = " + c2);
System.out.println("c3 = " + c3);
System.out.println("c4 = " + c4);
System.out.println(c1 == c2);
System.out.println(c1 == c3);
System.out.println(c1 == c4);
}
@Test
public void test02(){
int[] arr1 = {1,2,3,4,5};
int[] arr2 = {10,34,5,66,34,22};
int[][] arr3 = {{1,2,3,4},{4,5,6,7}};
String[] arr4 = {"hello","world"};
Class c1 = arr1.getClass();
Class c2 = arr2.getClass();
Class c3 = arr3.getClass();
Class c4 = arr4.getClass();
System.out.println("c1 = " + c1);
System.out.println("c2 = " + c2);
System.out.println("c3 = " + c3);
System.out.println("c4 = " + c4);
System.out.println(c1 == c2);
System.out.println(c1 == c3);
System.out.println(c1 == c4);
System.out.println(c3 == c4);
}
}
6 获取类型的详细信息
可以获取:包、修饰符、类型名、父类(包括泛型父类)、父接口(包括泛型父接口)、成员(属性、构造器、方法)、注解(类上的、方法上的、属性上的)
示例代码获取常规信息:
package com.atguigu.reflect;
package com.atguigu.reflect;
import java.lang.reflect.Constructor;
import java.lang.reflect.Field;
import java.lang.reflect.Method;
import java.lang.reflect.Modifier;
public class TestClassInfo {
public static void main(String[] args) throws Exception {
//1、先得到某个类型的Class对象
Class clazz = String.class;
//比喻clazz好比是镜子中的影子
//2、获取类信息
//(1)获取包对象,即所有java的包,都是Package的对象
Package pkg = clazz.getPackage();
System.out.println("包名:" + pkg.getName());
//(2)获取修饰符
//其实修饰符是Modifier,里面有很多常量值
/*
* 0x是十六进制
* PUBLIC = 0x00000001; 1 1
* PRIVATE = 0x00000002; 2 10
* PROTECTED = 0x00000004; 4 100
* STATIC = 0x00000008; 8 1000
* FINAL = 0x00000010; 16 10000
* ...
*
* 设计的理念,就是用二进制的某一位是1,来代表一种修饰符,整个二进制中只有一位是1,其余都是0
*
* mod = 17 0x00000011
* if ((mod & PUBLIC) != 0) 说明修饰符中有public
* if ((mod & FINAL) != 0) 说明修饰符中有final
*/
int mod = clazz.getModifiers();
System.out.println("类的修饰符有:" + Modifier.toString(mod));
//(3)类型名
String name = clazz.getName();
System.out.println("类名:" + name);
//(4)父类,父类也有父类对应的Class对象
Class superclass = clazz.getSuperclass();
System.out.println("父类:" + superclass);
//(5)父接口们
System.out.println("父接口们:");
Class[] interfaces = clazz.getInterfaces();
for (Class iter : interfaces) {
System.out.println(iter);
}
//(6)类的属性, 你声明的一个属性,它是Field的对象
/* Field clazz.getField(name) 根据属性名获取一个属性对象,但是只能得到公共的
Field[] clazz.getFields(); 获取所有公共的属性
Field clazz.getDeclaredField(name) 根据属性名获取一个属性对象,可以获取已声明的
Field[] clazz.getDeclaredFields() 获取所有已声明的属性
*/
// Field valueField = clazz.getDeclaredField("value");
// System.out.println("valueField = " +valueField);
System.out.println("------------------------------");
System.out.println("成员如下:");
System.out.println("属性有:");
Field[] declaredFields = clazz.getDeclaredFields();
for (Field field : declaredFields) {
//修饰符、数据类型、属性名
int modifiers = field.getModifiers();
System.out.println("属性的修饰符:" + Modifier.toString(modifiers));
String name2 = field.getName();
System.out.println("属性名:" + name2);
Class<?> type = field.getType();
System.out.println("属性的数据类型:" + type);
}
System.out.println("-------------------------");
//(7)构造器们
System.out.println("构造器列表:");
Constructor[] constructors = clazz.getDeclaredConstructors();
for (int i=0; i<constructors.length; i++) {
Constructor constructor = constructors[i];
System.out.println("第" + (i+1) +"个构造器:");
//修饰符、构造器名称、构造器形参列表 、抛出异常列表
int modifiers = constructor.getModifiers();
System.out.println("构造器的修饰符:" + Modifier.toString(modifiers));
String name2 = constructor.getName();
System.out.println("构造器名:" + name2);
//形参列表
System.out.println("形参列表:");
Class[] parameterTypes = constructor.getParameterTypes();
for (Class parameterType : parameterTypes) {
System.out.println(parameterType);
}
//异常列表
System.out.println("异常列表:");
Class<?>[] exceptionTypes = constructor.getExceptionTypes();
for (Class<?> exceptionType : exceptionTypes) {
System.out.println(exceptionType);
}
System.out.println();
}
System.out.println("---------------------------------");
//(8)方法们
System.out.println("方法列表:");
Method[] declaredMethods = clazz.getDeclaredMethods();
for (int i=0; i<declaredMethods.length; i++) {
Method method = declaredMethods[i];
System.out.println("第" + (i+1) +"个方法:");
//修饰符、返回值类型、方法名、形参列表 、异常列表
int modifiers = method.getModifiers();
System.out.println("方法的修饰符:" + Modifier.toString(modifiers));
Class<?> returnType = method.getReturnType();
System.out.println("返回值类型:" + returnType);
String name2 = method.getName();
System.out.println("方法名:" + name2);
//形参列表
System.out.println("形参列表:");
Class[] parameterTypes = method.getParameterTypes();
for (Class parameterType : parameterTypes) {
System.out.println(parameterType);
}
//异常列表
System.out.println("异常列表:");
Class<?>[] exceptionTypes = method.getExceptionTypes();
for (Class<?> exceptionType : exceptionTypes) {
System.out.println(exceptionType);
}
System.out.println();
}
}
}
7 创建任意引用类型的对象
两种方式:
1、直接通过Class对象来实例化(要求必须有公共的无参构造)
2、通过获取构造器对象来进行实例化
方式一的步骤:
(1)获取该类型的Class对象(2)创建对象
方式二的步骤:
(1)获取该类型的Class对象(2)获取构造器对象(3)创建对象
如果构造器的权限修饰符修饰的范围不可见,也可以调用setAccessible(true)
示例代码:
package com.atguigu.reflect;
import org.junit.Test;
import java.lang.reflect.Constructor;
public class TestCreateObject {
@Test
public void test1() throws Exception{
// AtGuiguClass obj = new AtGuiguClass();//编译期间无法创建
Class<?> clazz = Class.forName("com.atguigu.ext.demo.AtGuiguClass");
//clazz代表com.atguigu.ext.demo.AtGuiguClass类型
//clazz.newInstance()创建的就是AtGuiguClass的对象
Object obj = clazz.newInstance();
System.out.println(obj);
}
@Test
public void test2()throws Exception{
Class<?> clazz = Class.forName("com.atguigu.ext.demo.AtGuiguDemo");
//java.lang.InstantiationException: com.atguigu.ext.demo.AtGuiguDemo
//Caused by: java.lang.NoSuchMethodException: com.atguigu.ext.demo.AtGuiguDemo.<init>()
//即说明AtGuiguDemo没有无参构造,就没有无参实例初始化方法<init>
Object stu = clazz.newInstance();
System.out.println(stu);
}
@Test
public void test3()throws Exception{
//(1)获取Class对象
Class<?> clazz = Class.forName("com.atguigu.ext.demo.AtGuiguDemo");
/*
* 获取AtGuiguDemo类型中的有参构造
* 如果构造器有多个,我们通常是根据形参【类型】列表来获取指定的一个构造器的
* 例如:public AtGuiguDemo(String title, int num)
*/
//(2)获取构造器对象
Constructor<?> constructor = clazz.getDeclaredConstructor(String.class,int.class);
//(3)创建实例对象
// T newInstance(Object... initargs) 这个Object...是在创建对象时,给有参构造的实参列表
Object obj = constructor.newInstance("尚硅谷",2022);
System.out.println(obj);
}
}
8 操作任意类型的属性
(1)获取该类型的Class对象
Class clazz = Class.forName("包.类名");
(2)获取属性对象
Field field = clazz.getDeclaredField("属性名");
(3)如果属性的权限修饰符不是public,那么需要设置属性可访问
field.setAccessible(true);
(4)创建实例对象:如果操作的是非静态属性,需要创建实例对象
Object obj = clazz.newInstance(); //有公共的无参构造
Object obj = 构造器对象.newInstance(实参...);//通过特定构造器对象创建实例对象
(4)设置属性值
field.set(obj,"属性值");
如果操作静态变量,那么实例对象可以省略,用null表示
(5)获取属性值
Object value = field.get(obj);
如果操作静态变量,那么实例对象可以省略,用null表示
示例代码:
package com.atguigu.reflect;
public class Student {
private int id;
private String name;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "Student{" +
"id=" + id +
", name='" + name + '\'' +
'}';
}
}
package com.atguigu.reflect;
import java.lang.reflect.Field;
public class TestField {
public static void main(String[] args)throws Exception {
//1、获取Student的Class对象
Class clazz = Class.forName("com.atguigu.reflect.Student");
//2、获取属性对象,例如:id属性
Field idField = clazz.getDeclaredField("id");
//3、如果id是私有的等在当前类中不可访问access的,我们需要做如下操作
idField.setAccessible(true);
//4、创建实例对象,即,创建Student对象
Object stu = clazz.newInstance();
//5、获取属性值
/*
* 以前:int 变量= 学生对象.getId()
* 现在:Object id属性对象.get(学生对象)
*/
Object value = idField.get(stu);
System.out.println("id = "+ value);
//6、设置属性值
/*
* 以前:学生对象.setId(值)
* 现在:id属性对象.set(学生对象,值)
*/
idField.set(stu, 2);
value = idField.get(stu);
System.out.println("id = "+ value);
}
}
9 调用任意类型的方法
(1)获取该类型的Class对象
Class clazz = Class.forName("包.类名");
(2)获取方法对象
Method method = clazz.getDeclaredMethod("方法名",方法的形参类型列表);
(3)创建实例对象
Object obj = clazz.newInstance();
(4)调用方法
Object result = method.invoke(obj, 方法的实参值列表);
如果方法的权限修饰符修饰的范围不可见,也可以调用setAccessible(true)
如果方法是静态方法,实例对象也可以省略,用null代替
示例代码:
package com.atguigu.reflect;
import org.junit.Test;
import java.lang.reflect.Method;
public class TestMethod {
@Test
public void test()throws Exception {
// 1、获取Student的Class对象
Class<?> clazz = Class.forName("com.atguigu.reflect.Student");
//2、获取方法对象
/*
* 在一个类中,唯一定位到一个方法,需要:(1)方法名(2)形参列表,因为方法可能重载
*
* 例如:void setName(String name)
*/
Method setNameMethod = clazz.getDeclaredMethod("setName", String.class);
//3、创建实例对象
Object stu = clazz.newInstance();
//4、调用方法
/*
* 以前:学生对象.setName(值)
* 现在:方法对象.invoke(学生对象,值)
*/
Object setNameMethodReturnValue = setNameMethod.invoke(stu, "张三");
System.out.println("stu = " + stu);
//setName方法返回值类型void,没有返回值,所以setNameMethodReturnValue为null
System.out.println("setNameMethodReturnValue = " + setNameMethodReturnValue);
Method getNameMethod = clazz.getDeclaredMethod("getName");
Object getNameMethodReturnValue = getNameMethod.invoke(stu);
//getName方法返回值类型String,有返回值,getNameMethod.invoke的返回值就是getName方法的返回值
System.out.println("getNameMethodReturnValue = " + getNameMethodReturnValue);//张三
}
@Test
public void test02()throws Exception{
Class<?> clazz = Class.forName("com.atguigu.ext.demo.AtGuiguClass");
Method printInfoMethod = clazz.getMethod("printInfo", String.class);
//printInfo方法是静态方法
printInfoMethod.invoke(null,"尚硅谷");
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号