
闲来无事,敲两行代码,平生碌碌,唯不负韶华!
正则表达式学习笔记:课程连接
这里使用的语言为python
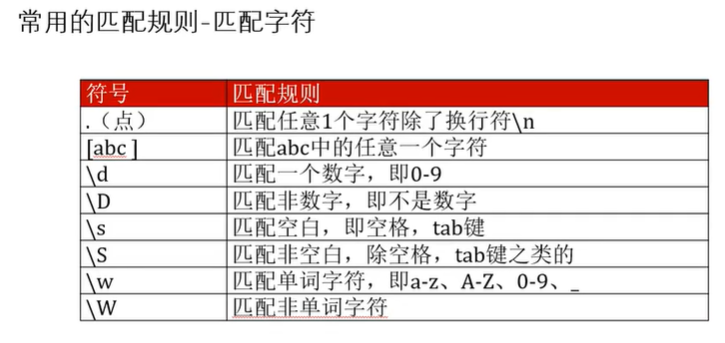

点的使用
# [.] 点的使用 //可以匹配除了换行符以外任意的字符
如:一个点
import re data = 'tormorrow' pattern = '.' res = re.match(pattern, data) print(res.group())
结果为:t
如两个点
import re data = 'tormorrow' pattern = '..' res = re.match(pattern, data) print(res.group())
结果为:to
找到某一姓氏的名字:
names = '李文', '李商隐', '李白', '小李' pattern = '李.' for name in names: res = re.match(pattern, name) if res: print(res.group()) print(name)
运行结果;
李文
李文
李商
李商隐
李白
李白
中括号的使用
[] 代表匹配集合中的任意一个字符,注意是一个字符
所有小写字母表示:[a-z]
范围表示[c-g] c到g的集合
大写同理;
import re strings = 'hello ' pattern = '[he]' res = re.match(pattern, strings) if res: print(res.group())
运行结果:
h
import re strings = 'echo ' pattern = '[he]' res = re.match(pattern, strings) if res: print(res.group())
运行结果:
e
匹配数字
\d 匹配一个数字 0-9之间的
注意:且匹配有位置要求;
如:
import re strings = '003 ' pattern = '\d' res = re.match(pattern, strings) if res: print(res.group())
结果:0
如:第一个不是数字
import re strings = 'T003 ' pattern = '\d' res = re.match(pattern, strings) if res: print(res.group())
结果:未匹配到
匹配一个非数字
\D 匹配一个非数字,且有位置要求,在第一位
import re strings = '003 ' pattern = '\D' res = re.match(pattern, strings) if res: print(res.group())
运行结果:未匹配到
如:
import re strings = 'T003 'i pattern = '\D' res = re.match(pattern, strings) if res: print(res.group())
运行结果:
T
匹配空格
\s 匹配一个空白空格
如:
strings = '00 3 ' pattern = '\s' res = re.match(pattern, strings) if res: print('匹配到了'+res.group()) else: print('未匹配到')
运行结果:未匹配到
如:
import re strings = ' 00 3 ' pattern = '\s' res = re.match(pattern, strings) if res: print('匹配到了'+res.group()) else: print('未匹配到')
运行结果:匹配到了
匹配非空白字符
\S 大些S 匹配非空白字符
import re strings = ' 00 ' pattern = '\S' res = re.match(pattern, strings) if res: print('匹配到了'+res.group()) else: print('未匹配到')
结果: 未匹配到
import re strings = 'w00 ' pattern = '\S' res = re.match(pattern, strings) if res: print('匹配到了'+res.group()) else: print('未匹配到')
结果:匹配到了w
匹配单词字符
\w 匹配单词字符,比如: a-z 或 A-Z 或 0-9 或 "_" 下划线
\W 匹配非单词字符,于小w正好相反
匹配个数
匹配出现0次或无线次
* " * ": 匹配前一个字符出现 0 次或者无限次,即可有可无
如:
import re strings = 'Hello ' pattern = '[A-Z][A-Z]*' res = re.match(pattern, strings) if res: print('匹配到了'+res.group()) else: print('未匹配到')
结果为:
匹配到了H
如:
import re strings = 'OMG... ' pattern = '[A-Z][A-Z]*' res = re.match(pattern, strings) if res: print('匹配到了'+res.group()) else: print('未匹配到')
结果为:
匹配到了OMG
匹配1次或无限次
+ : "+ " 加号代表匹配1次或者无限次数,即,至少1次
如:
import re strings = 'OMG... ' pattern = '[A-Z][A-Z]+' res = re.match(pattern, strings) if res: print('匹配到了'+res.group()) else: print('未匹配到')
结果:
匹配到了OMG
如:
import re strings = 'Hello... ' pattern = '[A-Z][A-Z]+' res = re.match(pattern, strings) if res: print('匹配到了'+res.group()) else: print('未匹配到')
结果:
未匹配到
小练习:
用正则表达式匹配变量名
分析:变量名由 字母、数字、下划线组成、但是起始位置不可以是 数字
所以:
pattern = '[a-zA-Z_]\w*'
或
pattern = '[a-zA-Z_]+\w*'
如:
import re strings = 'time_99 ' pattern = '[a-zA-Z_]\w*' res = re.match(pattern, strings) if res: print('匹配到了' + res.group()) else: print('未匹配到')
结果:
匹配到了time_99
如:
import re strings = '9_time_99 ' pattern = '[a-zA-Z_]\w*' res = re.match(pattern, strings) if res: print('匹配到了' + res.group()) else: print('未匹配到')
结果:
未匹配到
如:
import re strings = 'time+99 ' pattern = '[a-zA-Z_]\w*' res = re.match(pattern, strings) if res: print('匹配到了' + res.group()) else: print('未匹配到')
结果:匹配到了time
注意:当匹配的时候需要注意是否完全匹配了
匹配1次或者0次
\? 该字符前的字符出现最多1次 最少0次
import re strings = 'i-can' pattern = '[a-zA-Z_][\w]?' res = re.match(pattern, strings) if res: print('匹配到了' + res.group()) else: print('未匹配到')
结果:
匹配到了i
import re strings = 'ican' pattern = '[a-zA-Z_][\w]?' res = re.match(pattern, strings) if res: print('匹配到了' + res.group()) else: print('未匹配到')
结果:匹配到了ic
小练习:
匹配英文字符,遇到数字取一个停止,遇到其他特殊字符直接结束
pattern = '[a-zA-Z_]+[0-9]?'
次数限制
{} :花括号用来描述前导字符匹配的次数
{m}:精确匹配m次
{m,} : 前导字符至少出现m 次
{m,n} : 前导字符出现m 次 到n次
如;
import re strings = '123456777' pattern = '\d{4}' res = re.match(pattern, strings) if res: print('匹配到了' + res.group()) else: print('未匹配到')
结果:匹配到了1234
import re strings = '123456777d' pattern = '\d{4,}' res = re.match(pattern, strings) if res: print('匹配到了' + res.group()) else: print('未匹配到')
结果:
匹配到了123456777
小练习:
匹配邮箱:
import re strings = '1075933062@qq.com' pattern = '[a-zA-Z0-9]{6,11}@qq.com' res = re.match(pattern, strings) if res: print('匹配到了' + res.group()) else: print('未匹配到')
结果:
匹配到了1075933062@qq.com
原生字符匹配
r : r+ 字符串代表原生字符匹配
应用场景:想要在匹配路径时,但只是希望特定的某个路径
在python中存在转义字符,如换行符 \n Tab \t 还有转移字符本身 \
常用于匹配路径系统文件路径
如不使用原生:
import re strings = 'C:\\file.txt' pattern = 'C:\\\\file.txt' res = re.match(pattern, strings) if res: print('匹配到了' + res.group()) else: print('未匹配到')
结果:
匹配到了C:\file.txt
如使用原生:
import re strings = 'C:\\file.txt' pattern = r'C:\\file.txt' res = re.match(pattern, strings) if res: print('匹配到了' + res.group()) else: print('未匹配到')
结果:
匹配到了C:\file.txt
匹配开头和结尾

^: "^" 匹配字符串的开头
$: "$" 匹字符串的结尾
注意:[^-] 代表取反的意思:就是匹配不是-的字符
放在括号中右取反的意思。
import re # 匹配电话号码 strings = '0429-7777777' pattern = '([^-]*)-(\d*)' res = re.match(pattern, strings) if res: print('匹配到了' + res.group()) print('前部为:'+ res.group(1)) print('后部为:'+ res.group(2)) else: print('未匹配到')
如: 匹配以P开头的字符串
import re strings = 'Python' pattern = '^P.*' res = re.match(pattern, strings) if res: print('匹配到了' + res.group()) else: print('未匹配到')
结果:匹配到了Python
如:字符串不是以P开头,就没有办法匹配
import re strings = 'IPython' pattern = '^P.*' res = re.match(pattern, strings) if res: print('匹配到了' + res.group()) else: print('未匹配到')
结果:
未匹配到
以“.com ” 结尾的邮箱表示方法
import re strings = '1075933062@qq.com' pattern = '[\w]{6,11}@[\w]{2,3}.com$' res = re.match(pattern, strings) if res: print('匹配到了' + res.group()) else: print('未匹配到')
结果:
匹配到了1075933062@qq.com
如:不是以.com 结尾
import re strings = '1075933062@qq.com' pattern = '[\w]{6,11}@[\w]{2,3}.comtt$' res = re.match(pattern, strings) if res: print('匹配到了' + res.group()) else: print('未匹配到')
结果:未匹配到
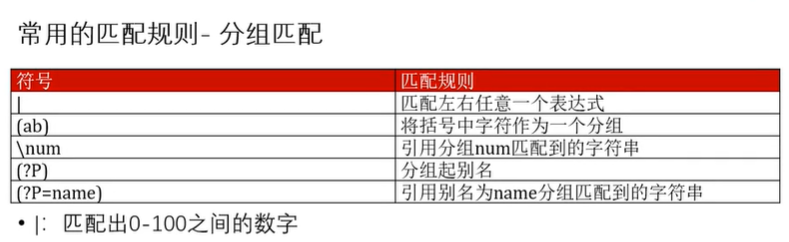
或选项
| : 匹配可以同时匹配两组表达式
从左到右一次进行匹配
如:
import re strings = 'com' pattern = 'co|com' res = re.match(pattern, strings) if res: print('匹配到了' + res.group()) else: print('未匹配到')
运行结果:
匹配到了co
解释:由于pattern可以同时匹配两组字串,co 或 com,但是co在com的前面,所以先匹配到co
分组匹配
将括号中的字符作为一个分组
(ab)() : 每个括号为一个组
group(0)
group()
代表整个匹配
import re # 匹配电话号码 strings = '0429-7777777' pattern = '([0-9]*)-(\d*)' res = re.match(pattern, strings) if res: print('匹配到了' + res.group()) print('前部为:'+ res.group(1)) print('后部为:'+ res.group(2)) else: print('未匹配到')
import re
strings = 'com'
pattern = 'co|com'
res = re.match(pattern, strings)
if res:
print('匹配到了' + res.group())
else:
print('未匹配到')


 浙公网安备 33010602011771号
浙公网安备 33010602011771号