
技术基础 | 在Apache Cassandra中改变VNodes数量的影响
Apache Cassandra中num_tokens的默认值在4.0版本中将会有变化!这看起来好像只是在CHANGES.txt文件中做了个小小的改动,但实际上这个改动将会对集群的日常运维有着深远的影响。
在这篇文章中,我们将会来仔细讨论num_tokens值的改变将会如何影响集群极其运行情况。
Apache Cassandra中有很多可以用于改变其行为的设置选项,num_tokens设置参数就是其中之一。像很多其他的设置参数一样,num_tokens也是在cassandra.yaml文件中,并且有一个默认值。不过它与其他设置参数相似的点也就到此为止了。
正如你所见,大多数Cassandra的设置参数只会对集群的单一方面产生影响,但是num_tokens值的改变意味着一系列的集群行为都将会被改变。
Apache Cassandra项目已经提交并解决了CASSANDRA-13701 JIRA问题,将num_tokens的默认值从256改为了16。这个改变具有重大意义,想要理解这个改变所带来的的影响和结果,我们需要先理解num_tokens在集群中所扮演的角色。
01 永远不要在生产环境中尝试的事
在我们进行深入探讨之前,需要注意的是,一旦一个节点已经加入了集群,num_tokens这个设置参数就不应该再有任何的改变。因为这样会使得该节点在重启时将发生故障。
一个数据中心中所有节点的num_tokens值应该是一样的。从过去来说,异构的集群是允许有不同的num_tokens值的。虽然这种情况很少见,我们也不推荐这么做——但从理论上讲,如果节点的硬件规格提升两倍,你是可以将num_tokens的值加倍的。
另外,一个数据中心的节点的num_tokens值与另一个数据中心的节点的num_tokens值不同,这种情况是很常见的。这正是在保证零宕机时间的前提下,可以安全的改变一个正在运行的集群的num_tokens值的部分原因。
02 基础知识
num_tokens这一设置影响了Cassandra如何在节点间分配数据、如何从节点中取出数据,以及如何在节点间移动数据。
在后台,Cassandra用分区算法(partitioner)来决定数据存储在集群的何处。分区算法是一个具有一致性的哈希算法,它可以将分区键(partition key,即主键的第一部分)一一映射到相应的令牌,而令牌则会决定与这些分区键相关的数据将会被存储在哪些节点。
集群中的每个节点都会被分配来自令牌环(token ring)中的一个或多个唯一的令牌值(哈希值)——这是一种形象而巧妙的说法,其实每个节点被分配的是一段首尾相接的数字范围中的一个数字。
也就是说,所谓的“被分配的数字”就是前面提到的令牌哈希值,而所谓的“首尾相接的数字范围”就是前面提到的哈希环。之所以说令牌环(哈希环)是环状的,是因为它的最大值的下一个值是它的最小值。
被分配的令牌定义了节点在令牌环上所负责的令牌范围,这个范围通常被称为“令牌区间(token range)”。
一个节点所负责的“令牌区间”的边界是两个值所定义的:一是该节点被分配的令牌值,二是在令牌环上自该令牌值向后推所得到的最小的可用哈希值。被分配的令牌值是包括在节点的令牌区间内的,不过令牌环上最小的可用令牌值则不包括在内——该值通常为前一个相邻节点占用。
一个首尾相接的令牌环意味着节点所负责的令牌可能包括了该令牌环的最大令牌值和最小令牌值。至少曾出现过一次这样的状况——在令牌环上向后推所得到的最小可用令牌值越过了令牌环中首尾相接的点,即向后推的最小令牌值越过了令牌环的最大值。
举例来说,在下面的令牌环分配图中,我们有一个令牌值范围为0-99的令牌环。令牌10被分配给了节点1。在集群中,节点1前面的节点是节点5,它被分配的令牌是令牌90。这样一来,节点1所负责的令牌值的范围就是91到10了。
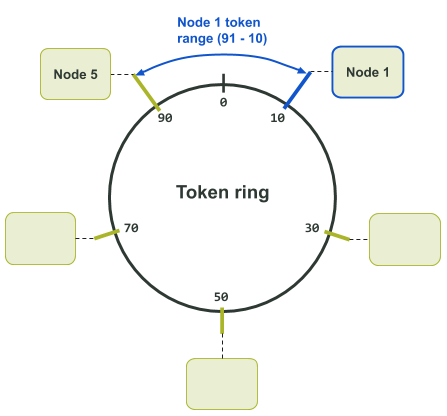
在这个特定的例子中,节点1所负责的令牌值的范围就越过了令牌环中最大值。
注意,上面的图例只是数据副本数量为1的情况,因为这是令牌环上的每个令牌值都只对应一个节点的情况。如果数据有多个副本,节点的邻居就会成为副本节点,负责该令牌值对应的副本数据了——请看下面的令牌环分配图:
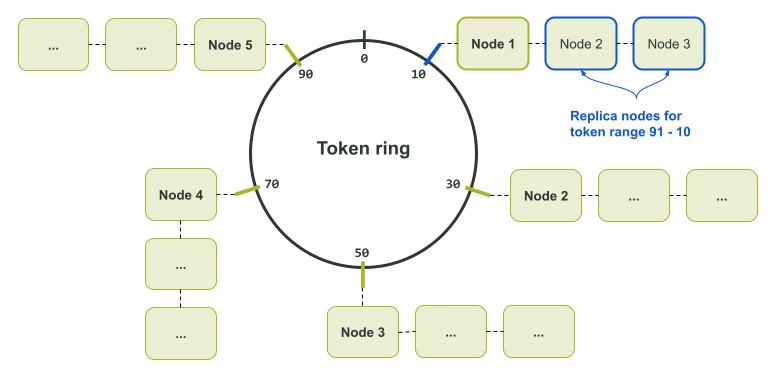
之所以将分区算法定义为一个具有一致性的哈希算法,其实是因为它本身就有这样的特性——无论多少次地输入某一特定的值,它总会生成并输出同样的值。
这种特性保证了所有的节点(node)、协调节点(coordinator)或是其他的任何组件在一个给定的分区键下,总能计算出同样的值。而这个计算得到的令牌值则可被用于可靠地定位存储着所需数据的节点。
结果就是,令牌环的最大最小值就由分区算法来定义。举例来说,默认使用的基于Murmur哈希函数的Murur3Partitioner算法的范围是-2^63到+2^63 - 1;而以前曾使用的基于MD5哈希函数的RandomPartitioner算法的范围则是0 to 2^127 - 1。
这样的一个系统有一个严重的副作用,就是一旦一个集群选定了一个分区算法,那么之后就不能再更改了。若想要更改分区算法,则需先重新创建一个集群,再选择所想使用的分区算法,然后再将数据导入到新的集群中。
03 早些时候……
在Cassandra 1.2版本之前的时代,节点只能被手动分配单独一个令牌。现在你依然可以通过cassandra.yaml文件中的initial_token设置参数来实现同样的效果。
那时候,默认使用的分区算法是RandomPartitioner。在一个集群从无到有的过程中,虽然令牌的分配过程是是手动的,但是RandomPartitioner分区算法使得计算分配令牌的过程相当简单直白。
举例来说,如果你的集群有3个节点,你需要做的就是用2^127 - 1除以3,这样所得到的商就是相邻的令牌所相差的正确增量。
你的第一个节点的起始令牌为0,即initial_token参数为0。接下来的节点的initial_token就会是(2^127 - 1) / 3,然后第三个节点的initial_token会是(2^127 - 1) / 3 * 2。这样,每个节点的令牌范围大小就会是一致的。
在各个节点的硬件配置完全一样且数据在集群中平均分布的前提下,平均分配每个节点所负责的令牌范围会使得节点过载的可能性较低。令牌分配的不均可能会导致所谓的“热点问题(hot spot)”——即由于需要比别的节点处理更多请求或储存更多数据,某个节点会处于较强的压力之下。
尽管搭建一个单个节点对应单个令牌的集群可能是一个非常手动的过程,但是它们的部署过程还是很常见,尤其是对于那些节点数通常超过1000的超大型Cassandra集群来说。这种部署的优点之一就是可以保证令牌的分布是均匀的。
虽然从头搭建一个单个节点对应单个令牌的集群可以保证负载的均匀分布,想要扩大集群可就没有那么容易了。如果你在拥有三个节点的集群中再插入一个节点,结果就是四个节点当中的两个节点的令牌范围会小于另外两个节点的令牌范围。
想要修复这个问题并使得令牌分布获得再平衡,你就得运行nodetool move从而将令牌重新分配给其他节点。但是这个过程繁琐且昂贵,因为其中牵涉了很多在整个集群范围内移动的数据流。一个替代方案是每次扩大集群的时候,就将其扩大两倍。不过这通常意味着需要使用比你实际需要的更多的硬件。
在一个单个节点对应单个令牌的集群中保持令牌的均匀分布就像是管理一个整洁无暇的后花园,你需要投入时间、养护以及注意力,或者要有大量的智能自动化方案。
对于单个节点对应单个令牌的集群来说,扩展性只是所有挑战的一半。而挑战的另一半,则是某些故障场景会极大地延长恢复所需要的时间。
让我们来举个例子,假设你在一个数据中心里有一个拥有6个节点的集群,集群数据的副本数为3 (Replication Factor = 3)。这些副本可能会存储在节点1和节点4,或节点2和节点5,或节点3和节点6。在这种情景下,每个节点负责3套副本中每套副本的六分之一。
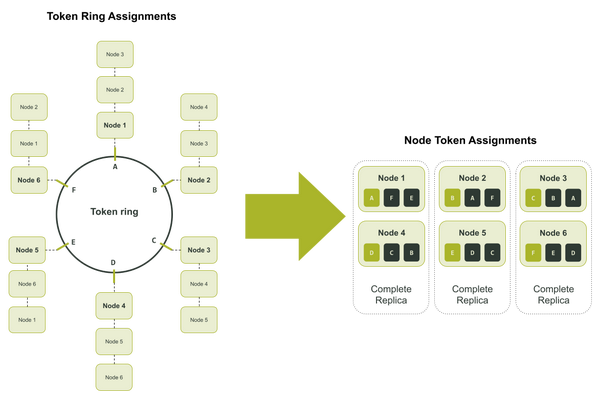
在上面的图中,令牌环上的每一个令牌区间都被分配了一个英文字母,这是为了更容易地记录每个节点被分配到的令牌。
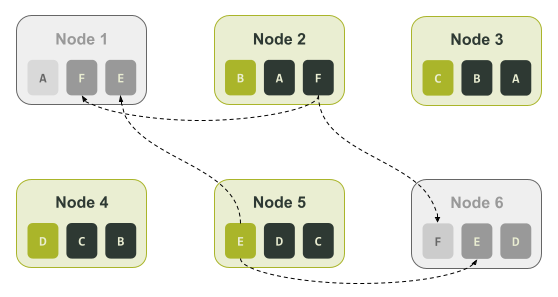
如果这个集群出现了故障,导致节点1和节点6变成不可用状态,你就只能通过节点2和节点5来回复它们所拥有的那独特的1/6的数据。也就是说,只有节点2可以被用于恢复与令牌区间F相关的数据,也只有节点5可以被用于恢复与令牌区间E相关的数据。下图展示了这个原理:
04 vnodes前来救场
为了解决单个节点对应单个令牌这种分配方案的多个缺点,增强后的Cassandra 1.2版本允许一个节点可以被分配多个令牌,即一个节点可以负责多个令牌区间。Cassandra的这项特性被称为“虚拟节点”,简称vnode。
vnode这项特性是在CASSANDRA-4119这个JIRA中被引入的,根据任务描述,vnode的目标是:
-
降低集群伸缩的运维复杂性
-
缩短故障重建时间
-
故障发生时能够平均分配负载
-
平均分配数据流操作带来的影响
-
针对硬件异构性提供更可行的支持
Vnode这项特性的引入催生了cassandra.yaml文件中的num_tokens设置参数,它定义了一个节点负责的vnode(即令牌区间)的数量。
增加每个节点所负责的vnode的数量,则每个令牌区间会相应缩小。这是因为令牌环上的令牌数目总是有限的,分出越多的区间,则每个区间的范围就会越小。
为了能够保持对更老的1.x系列版本的集群的向下兼容性,num_tokens的默认值为1。而且在出厂设置(vanilla installation)里,这个设置参数被有效地禁用了——具体来说,就是该值在cassandra.yaml文件中已经被注释掉了。但是这个注释行和以前的多次开发提交确实让大家得以窥见vnode这项新特性的未来。
就像cassandra.yaml文件和那些git提交记录所预示的,当Cassandra 2.0版本推出之时,vnode这项特性被默认启用了。num_tokens的所在行并不再被注释掉,在出厂设置(vanilla installation)里,它有效的默认值为256。
这开创了集群的新时代——令牌相对还能保持平均分配,同时集群可以简单地扩张。
有了由256个vnode组成的节点以及附带的其他功能,扩张集群的过程就像是做梦一样——你可以只管在你的集群中插入一个新的节点,Cassandra就会自动计算并分配令牌!令牌值是随机计算出来的,所以随着时间的推移,当你添加更多节点时,集群会收敛到一种平衡的状态。
这个就像是魔法一般的工程项目使得人们再也不需要花费数小时做计算,更无需多次用nodetool move操作来实现集群的扩张——虽然这种方案仍然还可以被使用。
如果你有一个非常大的集群或者有其他的要求,你仍可以使用在Cassandra 2.0中已经被注释掉的initial_token设置参数。如果要这样做,那么num_token的值仍然要手动设置成在initial_token设置参数中所定义的令牌数量。
05 记得了解相关的限制条件
这个特性就像是我们拥有了个人开发助手——你交给他们一个节点,告诉他们将节点插入集群,然后过一会儿他们就会将令牌分配好,并且节点也已经成了集群的一部分。但是,塞翁得马焉知非祸……
虽然使用256个vnode时令牌分布会更为均匀,但会出现可用性降低更快的问题——讽刺的是,我们越多地分拆令牌区间,我们的数据将越快面临不可用的问题。而当vnode数量较少时,更容易会出现令牌区间不均的问题。
这里所说的“数量较少”是指vnode的数量少于32个。当vnode数量较少时,Cassandra的随机令牌分配机制就变得无能为力。其原因是面对生成的长度差异很大的令牌区间,系统没有足够的令牌用于平衡令牌的分配。
06 一图胜千言
借助用于测试的集群,很容易能演示出上面提到的可用性和令牌区间分配不均的问题。我们可以用ccm搭建一个拥有6个节点的单个节点对应单个令牌的集群。在计算了令牌分配,并配置启动我们的测试集群后,会得到如下输出结果。
$ ccm node1 nodetool status Datacenter: datacenter1 ======================= Status=Up/Down |/ State=Normal/Leaving/Joining/Moving -- Address Load Tokens Owns (effective) Host ID Rack UN 127.0.0.1 71.17 KiB 1 33.3% 8d483ae7-e7fa-4c06-9c68-22e71b78e91f rack1 UN 127.0.0.2 65.99 KiB 1 33.3% cc15803b-2b93-40f7-825f-4e7bdda327f8 rack1 UN 127.0.0.3 85.3 KiB 1 33.3% d2dd4acb-b765-4b9e-a5ac-a49ec155f666 rack1 UN 127.0.0.4 104.58 KiB 1 33.3% ad11be76-b65a-486a-8b78-ccf911db4aeb rack1 UN 127.0.0.5 71.19 KiB 1 33.3% 76234ece-bf24-426a-8def-355239e8f17b rack1 UN 127.0.0.6 30.45 KiB 1 33.3% cca81c64-d3b9-47b8-ba03-46356133401b rack1
接着,我们可以使用cqlsh创建一个测试键空间(keyspace),并向其中输入数据。
$ ccm node1 cqlsh
Connected to SINGLETOKEN at 127.0.0.1:9042.
[cqlsh 5.0.1 | Cassandra 3.11.9 | CQL spec 3.4.4 | Native protocol v4]
Use HELP for help.
cqlsh> CREATE KEYSPACE test_keyspace WITH REPLICATION = { 'class' : 'NetworkTopologyStrategy', 'datacenter1' : 3 };
cqlsh> CREATE TABLE test_keyspace.test_table (
... id int,
... value text,
... PRIMARY KEY (id));
cqlsh> CONSISTENCY LOCAL_QUORUM;
Consistency level set to LOCAL_QUORUM.
cqlsh> INSERT INTO test_keyspace.test_table (id, value) VALUES (1, 'foo');
cqlsh> INSERT INTO test_keyspace.test_table (id, value) VALUES (2, 'bar');
cqlsh> INSERT INTO test_keyspace.test_table (id, value) VALUES (3, 'net');
cqlsh> INSERT INTO test_keyspace.test_table (id, value) VALUES (4, 'moo');
cqlsh> INSERT INTO test_keyspace.test_table (id, value) VALUES (5, 'car');
cqlsh> INSERT INTO test_keyspace.test_table (id, value) VALUES (6, 'set');
想要确认该集群是否已经完美地实现令牌的平均分配,我们可以查看该集群的令牌环。
$ ccm node1 nodetool ring test_keyspace
Datacenter: datacenter1
==========
Address Rack Status State Load Owns Token
6148914691236517202
127.0.0.1 rack1 Up Normal 125.64 KiB 50.00% -9223372036854775808
127.0.0.2 rack1 Up Normal 125.31 KiB 50.00% -6148914691236517206
127.0.0.3 rack1 Up Normal 124.1 KiB 50.00% -3074457345618258604
127.0.0.4 rack1 Up Normal 104.01 KiB 50.00% -2
127.0.0.5 rack1 Up Normal 126.05 KiB 50.00% 3074457345618258600
127.0.0.6 rack1 Up Normal 120.76 KiB 50.00% 6148914691236517202
在“Owns”那列,我们可以看到所有的节点都拥有50%的数据。为了让这个例子更容易理解,我们可以在每个令牌的右边手动添加一个代表该令牌的字母。这样一来,这些令牌区间就会被如下这样表示:
$ ccm node1 nodetool ring test_keyspace
Datacenter: datacenter1
==========
Address Rack Status State Load Owns Token Token Letter
6148914691236517202 F
127.0.0.1 rack1 Up Normal 125.64 KiB 50.00% -9223372036854775808 A
127.0.0.2 rack1 Up Normal 125.31 KiB 50.00% -6148914691236517206 B
127.0.0.3 rack1 Up Normal 124.1 KiB 50.00% -3074457345618258604 C
127.0.0.4 rack1 Up Normal 104.01 KiB 50.00% -2 D
127.0.0.5 rack1 Up Normal 126.05 KiB 50.00% 3074457345618258600 E
127.0.0.6 rack1 Up Normal 120.76 KiB 50.00% 6148914691236517202 F
接着,我们可以捕获ccm node1 nodetool describering test_keyspace的输出结果,并且将令牌序号换成上面令牌环输出结果中相应的字母。
$ ccm node1 nodetool describering test_keyspace Schema Version:6256fe3f-a41e-34ac-ad76-82dba04d92c3 TokenRange: TokenRange(start_token:A, end_token:B, endpoints:[127.0.0.2, 127.0.0.3, 127.0.0.4], rpc_endpoints:[127.0.0.2, 127.0.0.3, 127.0.0.4], endpoint_details:[EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1)]) TokenRange(start_token:C, end_token:D, endpoints:[127.0.0.4, 127.0.0.5, 127.0.0.6], rpc_endpoints:[127.0.0.4, 127.0.0.5, 127.0.0.6], endpoint_details:[EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack1)]) TokenRange(start_token:B, end_token:C, endpoints:[127.0.0.3, 127.0.0.4, 127.0.0.5], rpc_endpoints:[127.0.0.3, 127.0.0.4, 127.0.0.5], endpoint_details:[EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack1)]) TokenRange(start_token:D, end_token:E, endpoints:[127.0.0.5, 127.0.0.6, 127.0.0.1], rpc_endpoints:[127.0.0.5, 127.0.0.6, 127.0.0.1], endpoint_details:[EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1)]) TokenRange(start_token:F, end_token:A, endpoints:[127.0.0.1, 127.0.0.2, 127.0.0.3], rpc_endpoints:[127.0.0.1, 127.0.0.2, 127.0.0.3], endpoint_details:[EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack1)]) TokenRange(start_token:E, end_token:F, endpoints:[127.0.0.6, 127.0.0.1, 127.0.0.2], rpc_endpoints:[127.0.0.6, 127.0.0.1, 127.0.0.2], endpoint_details:[EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack1)])
根据上面的输出结果,特别是end_token这一列,我们就可以知道所有的节点被分配的令牌区间。就像前文“基础知识”部分中提到的那样,令牌区间是由前一个令牌(start_token)开始(不包括在内),直到本节点被分配的令牌(end_token)为止(包括在内)。
每个节点被分配的令牌区间如下图所示:
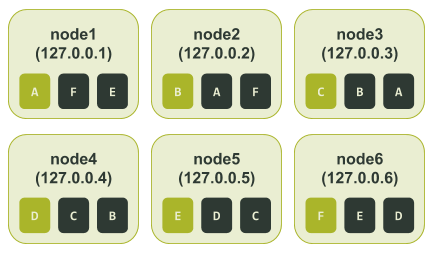
在这种配置下,如果节点3(node3)和节点6(node6)变为不可用状态,我们将会丢失一整个数据副本。不过即使应用程序使用的一致性级别(consistency level)为LOCAL_QUORUM,所有的数据仍然可用,因为我们在剩下的四个节点中依然存有两个数据副本。
现在,让我们来考虑一下集群使用vnode的情况。为了举例,我们可以将num_tokens设为3,这样比较小的令牌数会让我们的例子更容易理解。在使用ccm配置并启动多个节点后,我们的测试集群的初始情况如下:
对于大多数集群大小小于500个节点的生产部署,建议使用更大的num_tokens值。
$ ccm node1 nodetool status Datacenter: datacenter1 ======================= Status=Up/Down |/ State=Normal/Leaving/Joining/Moving -- Address Load Tokens Owns (effective) Host ID Rack UN 127.0.0.1 71.21 KiB 3 46.2% 7d30cbd4-8356-4189-8c94-0abe8e4d4d73 rack1 UN 127.0.0.2 66.04 KiB 3 37.5% 16bb0b37-2260-440c-ae2a-08cbf9192f85 rack1 UN 127.0.0.3 90.48 KiB 3 28.9% dc8c9dfd-cf5b-470c-836d-8391941a5a7e rack1 UN 127.0.0.4 104.64 KiB 3 20.7% 3eecfe2f-65c4-4f41-bbe4-4236bcdf5bd2 rack1 UN 127.0.0.5 66.09 KiB 3 36.1% 4d5adf9f-fe0d-49a0-8ab3-e1f5f9f8e0a2 rack1 UN 127.0.0.6 71.23 KiB 3 30.6% b41496e6-f391-471c-b3c4-6f56ed4442d6 rack1
在上面的输出结果中我们可以直观迅速地看到该集群可能已经处于失衡状态。
就像我们针对单个节点对应单个令牌的集群所做的那样,这里我们可以用cqlsh创建一个测试键空间,并向其中输入数据。接着,我们通过读取数据来看一下令牌环的情况。同样的,为了使这个例子更容易理解,我们在每个令牌的右边手动添加一个代表该令牌的字母。
$ ccm node1 nodetool ring test_keyspace
Datacenter: datacenter1
==========
Address Rack Status State Load Owns Token Token Letter
8828652533728408318 R
127.0.0.5 rack1 Up Normal 121.09 KiB 41.44% -7586808982694641609 A
127.0.0.1 rack1 Up Normal 126.49 KiB 64.03% -6737339388913371534 B
127.0.0.2 rack1 Up Normal 126.04 KiB 66.60% -5657740186656828604 C
127.0.0.3 rack1 Up Normal 135.71 KiB 39.89% -3714593062517416200 D
127.0.0.6 rack1 Up Normal 126.58 KiB 40.07% -2697218374613409116 E
127.0.0.1 rack1 Up Normal 126.49 KiB 64.03% -1044956249817882006 F
127.0.0.2 rack1 Up Normal 126.04 KiB 66.60% -877178609551551982 G
127.0.0.4 rack1 Up Normal 110.22 KiB 47.96% -852432543207202252 H
127.0.0.5 rack1 Up Normal 121.09 KiB 41.44% 117262867395611452 I
127.0.0.6 rack1 Up Normal 126.58 KiB 40.07% 762725591397791743 J
127.0.0.3 rack1 Up Normal 135.71 KiB 39.89% 1416289897444876127 K
127.0.0.1 rack1 Up Normal 126.49 KiB 64.03% 3730403440915368492 L
127.0.0.4 rack1 Up Normal 110.22 KiB 47.96% 4190414744358754863 M
127.0.0.2 rack1 Up Normal 126.04 KiB 66.60% 6904945895761639194 N
127.0.0.5 rack1 Up Normal 121.09 KiB 41.44% 7117770953638238964 O
127.0.0.4 rack1 Up Normal 110.22 KiB 47.96% 7764578023697676989 P
127.0.0.3 rack1 Up Normal 135.71 KiB 39.89% 8123167640761197831 Q
127.0.0.6 rack1 Up Normal 126.58 KiB 40.07% 8828652533728408318 R
就像上面“Owns”那列所显示的,令牌区间的分配有着较大的失衡现象,导致各个节点所负责的数据量有很大的不同。
IP地址为127.0.0.3的节点有着最小的令牌区间,该节点拥有39.89%的数据副本;而IP地址为127.0.0.2的节点有着最大的令牌区间,该节点拥有66.6%的数据副本——这两者居然几乎相差了26%。
就像前面所做的那样,我们可以捕获ccm node1 nodetool describering test_keyspace的输出结果,并且将令牌序号换成上面令牌环输出结果中相应的字母。
$ ccm node1 nodetool describering test_keyspace
Schema Version:4b2dc440-2e7c-33a4-aac6-ffea86cb0e21
TokenRange:
TokenRange(start_token:J, end_token:K, endpoints:[127.0.0.3, 127.0.0.1, 127.0.0.4], rpc_endpoints:[127.0.0.3, 127.0.0.1, 127.0.0.4], endpoint_details:[EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:K, end_token:L, endpoints:[127.0.0.1, 127.0.0.4, 127.0.0.2], rpc_endpoints:[127.0.0.1, 127.0.0.4, 127.0.0.2], endpoint_details:[EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:E, end_token:F, endpoints:[127.0.0.1, 127.0.0.2, 127.0.0.4], rpc_endpoints:[127.0.0.1, 127.0.0.2, 127.0.0.4], endpoint_details:[EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:D, end_token:E, endpoints:[127.0.0.6, 127.0.0.1, 127.0.0.2], rpc_endpoints:[127.0.0.6, 127.0.0.1, 127.0.0.2], endpoint_details:[EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:I, end_token:J, endpoints:[127.0.0.6, 127.0.0.3, 127.0.0.1], rpc_endpoints:[127.0.0.6, 127.0.0.3, 127.0.0.1], endpoint_details:[EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:A, end_token:B, endpoints:[127.0.0.1, 127.0.0.2, 127.0.0.3], rpc_endpoints:[127.0.0.1, 127.0.0.2, 127.0.0.3], endpoint_details:[EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:R, end_token:A, endpoints:[127.0.0.5, 127.0.0.1, 127.0.0.2], rpc_endpoints:[127.0.0.5, 127.0.0.1, 127.0.0.2], endpoint_details:[EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:M, end_token:N, endpoints:[127.0.0.2, 127.0.0.5, 127.0.0.4], rpc_endpoints:[127.0.0.2, 127.0.0.5, 127.0.0.4], endpoint_details:[EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:H, end_token:I, endpoints:[127.0.0.5, 127.0.0.6, 127.0.0.3], rpc_endpoints:[127.0.0.5, 127.0.0.6, 127.0.0.3], endpoint_details:[EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:L, end_token:M, endpoints:[127.0.0.4, 127.0.0.2, 127.0.0.5], rpc_endpoints:[127.0.0.4, 127.0.0.2, 127.0.0.5], endpoint_details:[EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:N, end_token:O, endpoints:[127.0.0.5, 127.0.0.4, 127.0.0.3], rpc_endpoints:[127.0.0.5, 127.0.0.4, 127.0.0.3], endpoint_details:[EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:P, end_token:Q, endpoints:[127.0.0.3, 127.0.0.6, 127.0.0.5], rpc_endpoints:[127.0.0.3, 127.0.0.6, 127.0.0.5], endpoint_details:[EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:Q, end_token:R, endpoints:[127.0.0.6, 127.0.0.5, 127.0.0.1], rpc_endpoints:[127.0.0.6, 127.0.0.5, 127.0.0.1], endpoint_details:[EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:F, end_token:G, endpoints:[127.0.0.2, 127.0.0.4, 127.0.0.5], rpc_endpoints:[127.0.0.2, 127.0.0.4, 127.0.0.5], endpoint_details:[EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:C, end_token:D, endpoints:[127.0.0.3, 127.0.0.6, 127.0.0.1], rpc_endpoints:[127.0.0.3, 127.0.0.6, 127.0.0.1], endpoint_details:[EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:G, end_token:H, endpoints:[127.0.0.4, 127.0.0.5, 127.0.0.6], rpc_endpoints:[127.0.0.4, 127.0.0.5, 127.0.0.6], endpoint_details:[EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:B, end_token:C, endpoints:[127.0.0.2, 127.0.0.3, 127.0.0.6], rpc_endpoints:[127.0.0.2, 127.0.0.3, 127.0.0.6], endpoint_details:[EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:O, end_token:P, endpoints:[127.0.0.4, 127.0.0.3, 127.0.0.6], rpc_endpoints:[127.0.0.4, 127.0.0.3, 127.0.0.6], endpoint_details:[EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack1)])
最后,我们就可以知道所有节点所被分配到的令牌区间了——它们如下图所示:
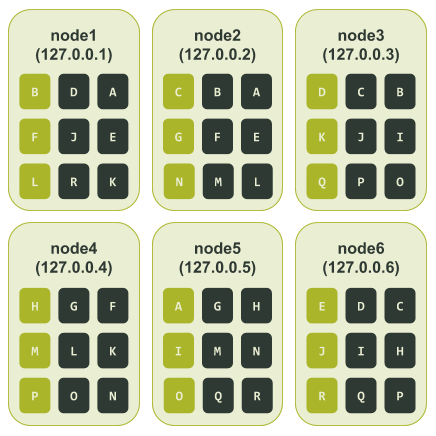
根据上图,我们可以看看如果发生像是前面提到的单个节点对应单个令牌的集群所遇到的故障(即节点3和节点6处于不可用状态),结果会如何。
上图中我们可以看到节点3和节点6都负责令牌区间C、D、I、J、Q。所以如果我们的应用程序的一致性级别是LOCAL_QUORUM,那么与这些令牌相关的数据都会处于不可用状态。
换句话说,与单个节点对应单个令牌的集群不同,在这种情况下,33.3%的数据可能再也无法被读取了。
07 上机架
经验丰富的Cassandra使用者会注意到,到目前为止,我们只在一个单独的机架(rack)上针对我们的集群进行了令牌分配测试。在使用vnode时,我们可以通过部署更多的机架来提高可用性。
当使用多个机架时,Cassandra会试着在每个机架上都只存放一个单独的数据副本——即Cassandra会试着确保在同一个机架上,不会出现两个完全相同的令牌区间。
这里的重点是要做好集群的配置工作——对于一个给定的数据中心,其机架的数量应该与其复制因子(replication factor)相等。
让我们再用一下前面num_tokens被设为3的例子,不过这次我们在测试集群中会定义3个机架。在用ccm配置并启动节点后,我们重新配置好的测试集群的初始状态如下:
$ ccm node1 nodetool status Datacenter: datacenter1 ======================= Status=Up/Down |/ State=Normal/Leaving/Joining/Moving -- Address Load Tokens Owns (effective) Host ID Rack UN 127.0.0.1 71.08 KiB 3 31.8% 49df615d-bfe5-46ce-a8dd-4748c086f639 rack1 UN 127.0.0.2 71.04 KiB 3 34.4% 3fef187e-00f5-476d-b31f-7aa03e9d813c rack2 UN 127.0.0.3 66.04 KiB 3 37.3% c6a0a5f4-91f8-4bd1-b814-1efc3dae208f rack3 UN 127.0.0.4 109.79 KiB 3 52.9% 74ac0727-c03b-476b-8f52-38c154cfc759 rack1 UN 127.0.0.5 66.09 KiB 3 18.7% 5153bad4-07d7-4a24-8066-0189084bbc80 rack2 UN 127.0.0.6 66.09 KiB 3 25.0% 6693214b-a599-4f58-b1b4-a6cf0dd684ba rack3
我们仍能看到一些表明集群可能处于失衡状态的迹象,不过这是次要问题——在上面的代码中,我们的主要关注点在于现在我们在1个集群中定义了3个机架,并且为每个机架分配了2个节点。
与前面我们对单个节点的集群所做的操作类似,我们可以用cqlsh创建一个测试键空间,并向其中输入数据。接着,我们通过读取数据来看一下令牌环的情况。与前面的测试相同,为了使这个例子更容易理解,我们在每个令牌的右边手动添加一个代表该令牌的字母。
ccm node1 nodetool ring test_keyspace
Datacenter: datacenter1
==========
Address Rack Status State Load Owns Token Token Letter
8993942771016137629 R
127.0.0.5 rack2 Up Normal 122.42 KiB 34.65% -8459555739932651620 A
127.0.0.4 rack1 Up Normal 111.07 KiB 53.84% -8458588239787937390 B
127.0.0.3 rack3 Up Normal 116.12 KiB 60.72% -8347996802899210689 C
127.0.0.1 rack1 Up Normal 121.31 KiB 46.16% -5712162437894176338 D
127.0.0.4 rack1 Up Normal 111.07 KiB 53.84% -2744262056092270718 E
127.0.0.6 rack3 Up Normal 122.39 KiB 39.28% -2132400046698162304 F
127.0.0.2 rack2 Up Normal 121.42 KiB 65.35% -1232974565497331829 G
127.0.0.4 rack1 Up Normal 111.07 KiB 53.84% 1026323925278501795 H
127.0.0.2 rack2 Up Normal 121.42 KiB 65.35% 3093888090255198737 I
127.0.0.2 rack2 Up Normal 121.42 KiB 65.35% 3596129656253861692 J
127.0.0.3 rack3 Up Normal 116.12 KiB 60.72% 3674189467337391158 K
127.0.0.5 rack2 Up Normal 122.42 KiB 34.65% 3846303495312788195 L
127.0.0.1 rack1 Up Normal 121.31 KiB 46.16% 4699181476441710984 M
127.0.0.1 rack1 Up Normal 121.31 KiB 46.16% 6795515568417945696 N
127.0.0.3 rack3 Up Normal 116.12 KiB 60.72% 7964270297230943708 O
127.0.0.5 rack2 Up Normal 122.42 KiB 34.65% 8105847793464083809 P
127.0.0.6 rack3 Up Normal 122.39 KiB 39.28% 8813162133522758143 Q
127.0.0.6 rack3 Up Normal 122.39 KiB 39.28% 8993942771016137629 R
与前面的测试步骤一样,我们可以捕获ccm node1 nodetool describering test_keyspace的输出结果,并且将令牌序号换成上面令牌环输出结果中相应的字母。
$ ccm node1 nodetool describering test_keyspace
Schema Version:aff03498-f4c1-3be1-b133-25503becf208
TokenRange:
TokenRange(start_token:B, end_token:C, endpoints:[127.0.0.3, 127.0.0.1, 127.0.0.2], rpc_endpoints:[127.0.0.3, 127.0.0.1, 127.0.0.2], endpoint_details:[EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack3), EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack2)])
TokenRange(start_token:L, end_token:M, endpoints:[127.0.0.1, 127.0.0.3, 127.0.0.5], rpc_endpoints:[127.0.0.1, 127.0.0.3, 127.0.0.5], endpoint_details:[EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack3), EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack2)])
TokenRange(start_token:N, end_token:O, endpoints:[127.0.0.3, 127.0.0.5, 127.0.0.4], rpc_endpoints:[127.0.0.3, 127.0.0.5, 127.0.0.4], endpoint_details:[EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack3), EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack2), EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:P, end_token:Q, endpoints:[127.0.0.6, 127.0.0.5, 127.0.0.4], rpc_endpoints:[127.0.0.6, 127.0.0.5, 127.0.0.4], endpoint_details:[EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack3), EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack2), EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:K, end_token:L, endpoints:[127.0.0.5, 127.0.0.1, 127.0.0.3], rpc_endpoints:[127.0.0.5, 127.0.0.1, 127.0.0.3], endpoint_details:[EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack2), EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack3)])
TokenRange(start_token:R, end_token:A, endpoints:[127.0.0.5, 127.0.0.4, 127.0.0.3], rpc_endpoints:[127.0.0.5, 127.0.0.4, 127.0.0.3], endpoint_details:[EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack2), EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack3)])
TokenRange(start_token:I, end_token:J, endpoints:[127.0.0.2, 127.0.0.3, 127.0.0.1], rpc_endpoints:[127.0.0.2, 127.0.0.3, 127.0.0.1], endpoint_details:[EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack2), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack3), EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:Q, end_token:R, endpoints:[127.0.0.6, 127.0.0.5, 127.0.0.4], rpc_endpoints:[127.0.0.6, 127.0.0.5, 127.0.0.4], endpoint_details:[EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack3), EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack2), EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:E, end_token:F, endpoints:[127.0.0.6, 127.0.0.2, 127.0.0.4], rpc_endpoints:[127.0.0.6, 127.0.0.2, 127.0.0.4], endpoint_details:[EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack3), EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack2), EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:H, end_token:I, endpoints:[127.0.0.2, 127.0.0.3, 127.0.0.1], rpc_endpoints:[127.0.0.2, 127.0.0.3, 127.0.0.1], endpoint_details:[EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack2), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack3), EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:D, end_token:E, endpoints:[127.0.0.4, 127.0.0.6, 127.0.0.2], rpc_endpoints:[127.0.0.4, 127.0.0.6, 127.0.0.2], endpoint_details:[EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack3), EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack2)])
TokenRange(start_token:A, end_token:B, endpoints:[127.0.0.4, 127.0.0.3, 127.0.0.2], rpc_endpoints:[127.0.0.4, 127.0.0.3, 127.0.0.2], endpoint_details:[EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack3), EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack2)])
TokenRange(start_token:C, end_token:D, endpoints:[127.0.0.1, 127.0.0.6, 127.0.0.2], rpc_endpoints:[127.0.0.1, 127.0.0.6, 127.0.0.2], endpoint_details:[EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack3), EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack2)])
TokenRange(start_token:F, end_token:G, endpoints:[127.0.0.2, 127.0.0.4, 127.0.0.3], rpc_endpoints:[127.0.0.2, 127.0.0.4, 127.0.0.3], endpoint_details:[EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack2), EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack3)])
TokenRange(start_token:O, end_token:P, endpoints:[127.0.0.5, 127.0.0.6, 127.0.0.4], rpc_endpoints:[127.0.0.5, 127.0.0.6, 127.0.0.4], endpoint_details:[EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack2), EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack3), EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:J, end_token:K, endpoints:[127.0.0.3, 127.0.0.5, 127.0.0.1], rpc_endpoints:[127.0.0.3, 127.0.0.5, 127.0.0.1], endpoint_details:[EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack3), EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack2), EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:G, end_token:H, endpoints:[127.0.0.4, 127.0.0.2, 127.0.0.3], rpc_endpoints:[127.0.0.4, 127.0.0.2, 127.0.0.3], endpoint_details:[EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack2), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack3)])
TokenRange(start_token:M, end_token:N, endpoints:[127.0.0.1, 127.0.0.3, 127.0.0.5], rpc_endpoints:[127.0.0.1, 127.0.0.3, 127.0.0.5], endpoint_details:[EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack3), EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack2)])
最后,我们就如同前面的测试一样,可以知道所有节点所被分配到的令牌区间了:
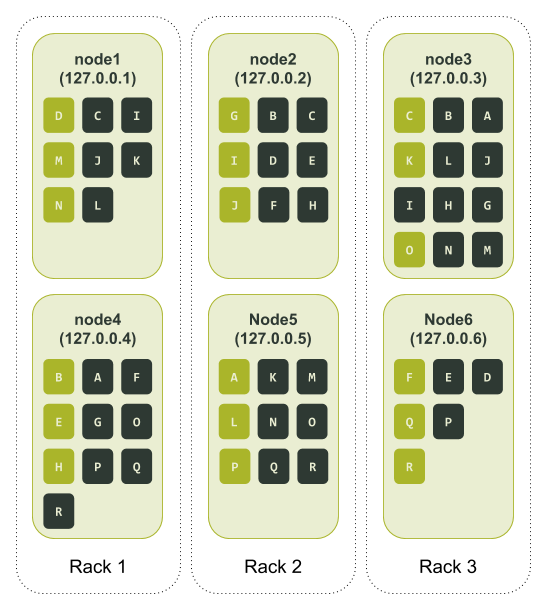
从Cassandra分配令牌的方式中可以看出,一套完整的数据副本会被分别存储在三个机架的每个机架的两个节点上。如果我们回头再看看前面节点3和节点6同时不可用的故障场景,我们会发现此时系统仍然能够为一致性级别(consistency level)为LOCAL_QUORUM的查询请求提供服务。
唯一剩下的主要问题在于分配给节点3的令牌数量远大于其他节点,而与节点3在同一个机架的节点6则与之相反,被分配的节点数量比其他节点要少一些。
08 过多的vnode会毁掉集群
鉴于令牌分配不均的问题通常在vnode数量较少的情况下发生,可能有人会觉得使用大量的vnode会是最好的选项。然而,除了由多节点故障导致的数据不可用的情况更有可能发生以外,大量的vnode还会影响数据流的操作。
为了修复节点上的数据,Cassandra会在每个vnode上开启一轮修复会话。这些修复会话需要按顺序处理。所以,vnode数量越多,修复所需的时间就越多,运行一轮修复的开销也就越大。
为了修正由vnode数量较大引起的修复过程缓慢的问题,Cassandra 3.0版本引入了CASSANDRA-5220问题。这个改变使得Cassandra能将一组节点共同的令牌区间集中在一个修复会话中。虽然同时修复多个令牌区间使得一轮修复会话所包含的内容更多,但这减少了同时执行的修复会话的数量。
我们可以通过在一个真实的硬件的集群上做一个简单的测试,来看看修复vnode会产生的效果。
为了做这个测试,首先我们需要创建一个用单个令牌运行修复任务的集群。然后我们可以再创建一个一样的集群,不过vnode的数量是256,然后也用这个集群运行同样的修复任务。
我们将使用tlp-cluster在AWS上创建一个Cassandra集群,并且应用如下特性:
-
对象大小:i3.2xlarge
-
节点数量:12
-
机架数量:3(每个机架上4个节点)
-
Cassandra版本:3.11.9(写作本文时最新的稳定版本)
下面是创建集群所用到的命令语句。
$ tlp-cluster init --azs a,b,c --cassandra 12 --instance i3.2xlarge --stress 1 TLP BLOG "Blogpost repair testing" $ tlp-cluster up $ tlp-cluster use --config "cluster_name:SingleToken" --config "num_tokens:1" 3.11.9 $ tlp-cluster install
我们安排好所需的硬件之后,我们就需要单独对每一个节点的initial_token性质进行设定。我们可以用一个简单的Python命令来计算每一个节点的起始令牌。
Python 2.7.16 (default, Nov 23 2020, 08:01:20)
[GCC Apple LLVM 12.0.0 (clang-1200.0.30.4) [+internal-os, ptrauth-isa=sign+stri on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> num_tokens = 1
>>> num_nodes = 12
>>> print("\n".join(['[Node {}] initial_token: {}'.format(n + 1, ','.join([str(((2**64 / (num_tokens * num_nodes)) * (t * num_nodes + n)) - 2**63) for t in range(num_tokens)])) for n in range(num_nodes)]))
[Node 1] initial_token: -9223372036854775808
[Node 2] initial_token: -7686143364045646507
[Node 3] initial_token: -6148914691236517206
[Node 4] initial_token: -4611686018427387905
[Node 5] initial_token: -3074457345618258604
[Node 6] initial_token: -1537228672809129303
[Node 7] initial_token: -2
[Node 8] initial_token: 1537228672809129299
[Node 9] initial_token: 3074457345618258600
[Node 10] initial_token: 4611686018427387901
[Node 11] initial_token: 6148914691236517202
[Node 12] initial_token: 7686143364045646503
在所有节点上都启动了Cassandra之后,使用下面的tlp-stress命令可以在每个节点上先预装载大约3GB的数据。
在这个命令中,我们将键空间的复制因子(replication factor)设为3,并且将gc_grace_seconds设为0。这是为了让hint在被创建之后立即被删除,这样它们就不会被传送到终端节点了。
ubuntu@ip-172-31-19-180:~$ tlp-stress run KeyValue --replication "{'class': 'NetworkTopologyStrategy', 'us-west-2':3 }" --cql "ALTER TABLE tlp_stress.keyvalue WITH gc_grace_seconds = 0" --reads 1 --partitions 100M --populate 100M --iterations 1
数据加载完成后,集群状态如下:
ubuntu@ip-172-31-30-95:~$ nodetool status Datacenter: us-west-2 ===================== Status=Up/Down |/ State=Normal/Leaving/Joining/Moving -- Address Load Tokens Owns (effective) Host ID Rack UN 172.31.30.95 2.78 GiB 1 25.0% 6640c7b9-c026-4496-9001-9d79bea7e8e5 2a UN 172.31.31.106 2.79 GiB 1 25.0% ceaf9d56-3a62-40be-bfeb-79a7f7ade402 2a UN 172.31.2.74 2.78 GiB 1 25.0% 4a90b071-830e-4dfe-9d9d-ab4674be3507 2c UN 172.31.39.56 2.79 GiB 1 25.0% 37fd3fe0-598b-428f-a84b-c27fc65ee7d5 2b UN 172.31.31.184 2.78 GiB 1 25.0% 40b4e538-476a-4f20-a012-022b10f257e9 2a UN 172.31.10.87 2.79 GiB 1 25.0% fdccabef-53a9-475b-9131-b73c9f08a180 2c UN 172.31.18.118 2.79 GiB 1 25.0% b41ab8fe-45e7-4628-94f0-a4ec3d21f8d0 2a UN 172.31.35.4 2.79 GiB 1 25.0% 246bf6d8-8deb-42fe-bd11-05cca8f880d7 2b UN 172.31.40.147 2.79 GiB 1 25.0% bdd3dd61-bb6a-4849-a7a6-b60a2b8499f6 2b UN 172.31.13.226 2.79 GiB 1 25.0% d0389979-c38f-41e5-9836-5a7539b3d757 2c UN 172.31.5.192 2.79 GiB 1 25.0% b0031ef9-de9f-4044-a530-ffc67288ebb6 2c UN 172.31.33.0 2.79 GiB 1 25.0% da612776-4018-4cb7-afd5-79758a7b9cf8 2b
然后我们可以用下面的命令在每个节点上都运行一次全面修复(full repair)。
$ source env.sh $ c_all "nodetool repair -full tlp_stress"
每个节点的修复时长如下:
[2021-01-22 20:20:13,952] Repair command #1 finished in 3 minutes 55 seconds [2021-01-22 20:23:57,053] Repair command #1 finished in 3 minutes 36 seconds [2021-01-22 20:27:42,123] Repair command #1 finished in 3 minutes 32 seconds [2021-01-22 20:30:57,654] Repair command #1 finished in 3 minutes 21 seconds [2021-01-22 20:34:27,740] Repair command #1 finished in 3 minutes 17 seconds [2021-01-22 20:37:40,449] Repair command #1 finished in 3 minutes 23 seconds [2021-01-22 20:41:32,391] Repair command #1 finished in 3 minutes 36 seconds [2021-01-22 20:44:52,917] Repair command #1 finished in 3 minutes 25 seconds [2021-01-22 20:47:57,729] Repair command #1 finished in 2 minutes 58 seconds [2021-01-22 20:49:58,868] Repair command #1 finished in 1 minute 58 seconds [2021-01-22 20:51:58,724] Repair command #1 finished in 1 minute 53 seconds [2021-01-22 20:54:01,100] Repair command #1 finished in 1 minute 50 seconds
将这些时间加总起来得到整个修复完成所需的时间,即36分钟44秒。
上面用到的集群同样可以用来测试当vnode的数量为256时,系统所需要的修复时长。我们所需要做的就是执行下面的这些步骤:
-
在所有节点上关闭Cassandra
-
删除data、commitlog、hints和saved_caches这四个文件夹中的所有内容(它们位于每个节点的/var/lib/cassandra/路径下)
-
在cassandra.yaml配置文件中将num_tokens的值设为256,并且删除initial_token这一设置参数
-
在所有节点上重新启动Cassandra
在向集群中输入数据后,集群状态如下:
ubuntu@ip-172-31-30-95:~$ nodetool status Datacenter: us-west-2 ===================== Status=Up/Down |/ State=Normal/Leaving/Joining/Moving -- Address Load Tokens Owns (effective) Host ID Rack UN 172.31.30.95 2.79 GiB 256 24.3% 10b0a8b5-aaa6-4528-9d14-65887a9b0b9c 2a UN 172.31.2.74 2.81 GiB 256 24.4% a748964d-0460-4f86-907d-a78edae2a2cb 2c UN 172.31.31.106 3.1 GiB 256 26.4% 1fc68fbd-335d-4689-83b9-d62cca25c88a 2a UN 172.31.31.184 2.78 GiB 256 23.9% 8a1b25e7-d2d8-4471-aa76-941c2556cc30 2a UN 172.31.39.56 2.73 GiB 256 23.5% 3642a964-5d21-44f9-b330-74c03e017943 2b UN 172.31.10.87 2.95 GiB 256 25.4% 540a38f5-ad05-4636-8768-241d85d88107 2c UN 172.31.18.118 2.99 GiB 256 25.4% 41b9f16e-6e71-4631-9794-9321a6e875bd 2a UN 172.31.35.4 2.96 GiB 256 25.6% 7f62d7fd-b9c2-46cf-89a1-83155feebb70 2b UN 172.31.40.147 3.26 GiB 256 27.4% e17fd867-2221-4fb5-99ec-5b33981a05ef 2b UN 172.31.13.226 2.91 GiB 256 25.0% 4ef69969-d9fe-4336-9618-359877c4b570 2c UN 172.31.33.0 2.74 GiB 256 23.6% 298ab053-0c29-44ab-8a0a-8dde03b4f125 2b UN 172.31.5.192 2.93 GiB 256 25.2% 7c690640-24df-4345-aef3-dacd6643d6c0 2c
和前面在单个节点对应单个令牌的集群所做的修复测试一样,当我们在这个启用了vnode的节点上运行修复测试,修复所需的时长就会被记录下来。
[2021-01-22 22:45:56,689] Repair command #1 finished in 4 minutes 40 seconds [2021-01-22 22:50:09,170] Repair command #1 finished in 4 minutes 6 seconds [2021-01-22 22:54:04,820] Repair command #1 finished in 3 minutes 43 seconds [2021-01-22 22:57:26,193] Repair command #1 finished in 3 minutes 27 seconds [2021-01-22 23:01:23,554] Repair command #1 finished in 3 minutes 44 seconds [2021-01-22 23:04:40,523] Repair command #1 finished in 3 minutes 27 seconds [2021-01-22 23:08:20,231] Repair command #1 finished in 3 minutes 23 seconds [2021-01-22 23:11:01,230] Repair command #1 finished in 2 minutes 45 seconds [2021-01-22 23:13:48,682] Repair command #1 finished in 2 minutes 40 seconds [2021-01-22 23:16:23,630] Repair command #1 finished in 2 minutes 32 seconds [2021-01-22 23:18:56,786] Repair command #1 finished in 2 minutes 26 seconds [2021-01-22 23:21:38,961] Repair command #1 finished in 2 minutes 30 seconds
将这些时间加总起来得到整个修复完成所需的时间,即39分钟23秒。
虽然对于每个节点3GB数据的情况来说,两种情况下的修复时长并没有相差太多。但是很容易看出,当每个节点的数据大小达到数百GB时,修复的时间差就会迅速扩大。
不幸的是,像是系统启动和数据中心重建这样的所有的数据流操作,都会遇见这种由大量vnode引起的修复问题。具体来说,当一个节点需要将数据传输到另一个节点,节点就会为每个令牌区间分别开启一个流传输会话。由于数据是通过JVM来传输的,这就会导致很多没必要的开销。
09 二级索引也被影响
更糟的是,由于Cassandra的读取路径(read path)的工作原理,大量的vnode还会对二级索引(secondary indexes)产生负面影响。
当协调节点(coordinator node)从客户端接收到一个带二级索引的请求,它会将该请求分发给集群或数据中心内的所有节点,分发范围取决于一致性级别(consistency level)的要求。
接着,每个收到请求的节点在自己负责的令牌区间(token range)的SSTable中进行查询,寻找和这个带二级索引的请求相匹配的结果。然后这些与请求相匹配的数据就会被返回给协调节点。
所以,vnode数量越多,对于带二级索引的请求的延迟的影响越大。不仅如此,这种对二级索引的性能的影响,会随着集群副本数量的增加以指数形式增长。在多个数据中心的节点都使用多个vnode的情况下,二级索引的效率甚至会更低。
10 新希望
至此,我们拥有的是这样的一个Cassandra特性:它在降低集群伸缩的复杂性方面确实达标了,但不幸的是,伴随着这种好处而来的代价是令牌区间的分配失衡以及操作性能的降低。话虽如此,vnode的故事还远未结束。
最终,这成为了一个广为人知的事实:Apache Cassandra项目中大量的vnode会对集群造成大家并不乐见的副作用。为了对付这个问题,聪明的Cassandra贡献者们以及committer们在Cassandra 3.0版本中添加了CASSANDRA-7032——一个能够感知副本的令牌分配算法。
这个算法的思路是让num_tokens可以使用一个较低的值,同时还得保持令牌区间的相对平衡。这次对于令牌分配算法的改进在cassandra.yaml文件中添加了设置参数allocate_tokens_for_keyspace。
当一个已经存在的用户键空间(user keyspace)被分配给allocate_tokens_for_keyspace这个设置参数时,系统就会使用这个新算法,而不会使用随机令牌分配器(random token allocator)。
在后台,Cassandra会读取节点上已有定义的键空间的复制因子(replication factor),并在该节点第一次进入集群时,Cassandra会根据键空间的复制因子来计算该节点的令牌分配。
与随机令牌生成器(random token generator)不同,这个新算法的副本感知生成器(replica aware generator)就像是交响乐团里富有经验的一员,它技能娴熟且能够与周边情况相适应。因此,新算法生成令牌区间的步骤包括了:
-
构建初始令牌环
-
通过从中间拆分所有现有的令牌范围来计算候选的新令牌
-
评估所有候选令牌的预期提升,然后按优先级形成队列
-
遍历队列中的候选令牌并找到最好的组合
-
由于令牌被重新组合,将会重新评估队列中的候选令牌的提升
尽管这个副本感知令牌分配算法(replica aware token allocation algorithm)对Cassandra来说是一大提升,但是在使用这个算法的时候还是有一些要注意的地方。
首先,使用这个算法意味着只能使用Murmur3Partitioner分区算法。如果你的集群较老且使用的是其他的分区算法(如RandomPartitioner),尽管该集群随着时间的推移已升级到3.0版本,这个新算法仍然不适用。
第二个问题,也是一个更常见的阻碍:当我们从头创建一个新集群时,我们需要一些技巧才能使用这个新算法。
由于这个问题确实很常见,点击文末“阅读原文”查看我们的一篇文章,在其中我们专门解释了如何使用这个新算法搭建一个令牌分配均衡的新集群。
就像你看到的,Cassandra 3.0版本确实致力于解决vnode的一些瑕疵问题。而且即将推出的Cassandra 4.0版本还将带来更多可喜的变化和提升。
比如通过CASSANDRA-15260将会在cassandra.yaml文件中添加一个新的设置参数allocate_tokens_for_local_replication_factor。它与它的姊妹参数allocate_tokens_for_keyspace有着类似的功能,当它被赋值之后,副本感知令牌分配算法就会被激活。
不过与allocate_tokens_for_keyspace不同的是,allocate_tokens_for_local_replication_factor对用户更加友好。这是因为在从零创建平衡的新集群时,后者不会带来任何其他琐碎繁杂的额外工作。在最简单的情况下,你可以先为allocate_tokens_for_local_replication_factor设置一个值,然后就可以开始添加节点了。
有经验的用户仍可以将令牌手动分配给初始节点,以确保满足所需的复制因子(replication factor)。在这之后,后续的节点可以在复制因子被赋值给allocate_tokens_for_local_replication_factor之后添加到集群中。
可以说,Cassandra 4.0版本最长的发布时间和重大更改之一是对num_tokens这一设置选项的默认值的更新。
就像在本文一开头就提到的那样,有赖于CASSANDRA-13701,Cassandra 4.0推出时,在cassandra.yaml文件中的num_tokens一值将会被设置为16。另外,allocate_tokens_for_local_replication_factor这一设置参数将会默认启用,其默认值为3。
这些更改都是更好的用户默认设置。在Cassandra 4.0的出厂设置(vanilla installation)中,只要有足够的主机来满足复制因子为3的条件,副本感知令牌分配算法就会被启用。这样做的结果就是不仅新节点令牌区间的分配会非常均衡,而且同时还可以享有vnode较少时的所有好处。
11 结论
具有一致性的哈希令牌分配这一功能构成了Cassandra主干的一部分。虚拟节点(vnode)则消除了在维护这一关键功能过程中的不确定因素,尤其是它可以帮助节点更快且更容易地伸缩。
根据经验来说,vnode数量越小,令牌的分配就越不均衡,进而导致一些节点会出现过载的问题。或者如果vnode数量越大,则集群范围的操作就会花费越长的时间完成;与此同时,如果有多个节点宕机的话,也就越有可能出现数据不可用的情况。
3.0版本中的功能以及4.0版本对这些功能的增强,让Cassandra能够在vnode数量较少的情况下同时保持相对均衡的令牌分配。最终,当新用户使用Cassandra 4.0的出厂设置时,这会催生更好的“开箱即用”的使用体验。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号