活动精彩实录 | 王峰:Cassandra在360的多场景应用及未来趋势
大家好,我是360的王峰,我今天主要通过Cassandra在多场景下的应用来介绍一下Cassandra在360落地的情况。
我会从以下这几个方面进行介绍。首先介绍下Cassandra落地的背景和业务情况,接着看看当前业界的一些进展,然后我还会分享对数据库发展趋势的一些个人看法,最后给大家介绍一下Cassandra在360未来的一个定位。
关于我
先介绍下我自己,我大概在2009年就开始接触Cassandra的一些早期版本了,当时也是为了在一些百度的项目中得到一些简单的应用。接着我来到了360,从2011年5月开始,借着360云盘业务的发展,才实现了Cassandra的大规模落地。目前我主要在负责基础云大数据体系的建设,还有云上弹性的大数

Cassandra和360的历史回顾
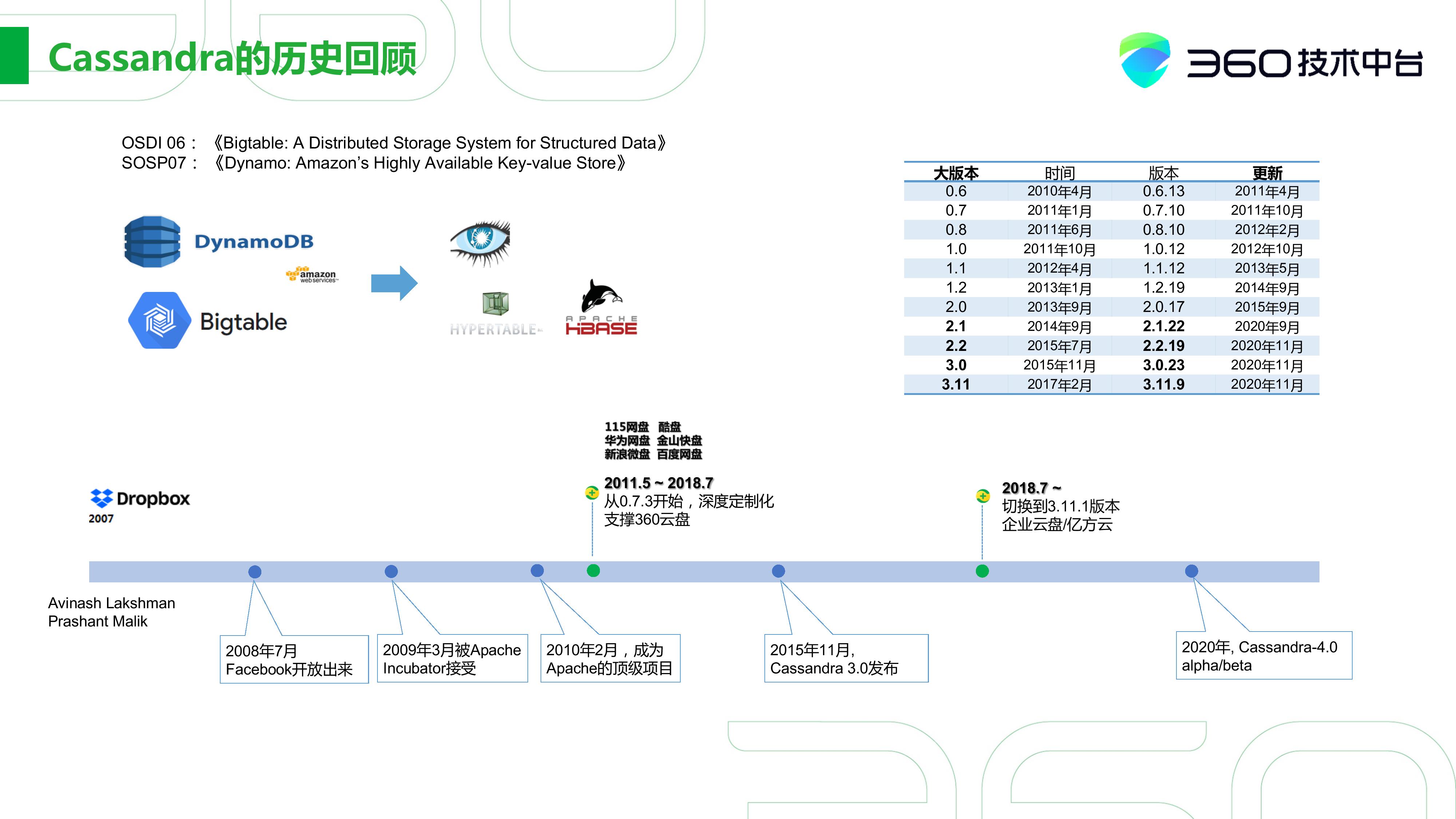
首先我想跟大家简单回顾一下Cassandra的历史。
Cassandra可以最早追溯到2006、2007年的两篇在顶级会议上发表的论文,一篇是谷歌关于bigtable的,还有一篇是亚马逊关于Dynamo的。然后次年,也就是从2008年开始,以bigtable架构为基础的两个产品,Hypertable和Hbase基本上就已经出来了。
在2008年,Facebook的两位工程师也基于这两篇论文实现了Cassandra的一个基本系统。在当年这个时间点,其实还有比较有意思的一点,就是Dropbox的一个出现。这个时间点之后,国内各家公司也是以Dropbox为蓝本,开始争相推出自己的网盘。
在2008年7月,Facebook就已经把Cassandra放出来了。2009年,Cassandra作为孵化项目被Apache社区所接受,之后在2012年正式成为顶级项目。最早从2010年开始,国内就有一些公司开始模仿Dropbox推出面向个人的存储服务了。
2011年之后,大家都纷纷看到了商机,这个趋势也就更加的明显。那一年其实大家会发现出现了很多网盘,包括115、酷盘、华为、金山、百度,当然包括360等等。现在来看,其实很多网盘已经不存在了。那时360选择Cassandra作为后端的存储,以支撑整个360云盘的产品线。当初Cassandra的版本也不是特别的稳定,所以我们当时就做了很多的深度定制化。
另一个时间节点就是2015年11月了,当时是Cassandra 3.0的发布,我们发现Cassandra社区发展的很快,实现了我们很多之前不是很完善的功能。因此我们准备在未来的两三年更新到某个社区版本。
直到2018年7月份,我们正式切换到了社区的3.11.1版本,开始在企业云盘和亿方云上大规模的应用,并一直使用到现在。当然,我们也做了一些简单的定制化,但现在Cassandra社区的版本比之前版本有了翻天覆地的变化。2020年,Cassandra 4.0发了几个Alpha/Beta版本,未来我们也可能在这方面做一些关注。
360数据与应用场景
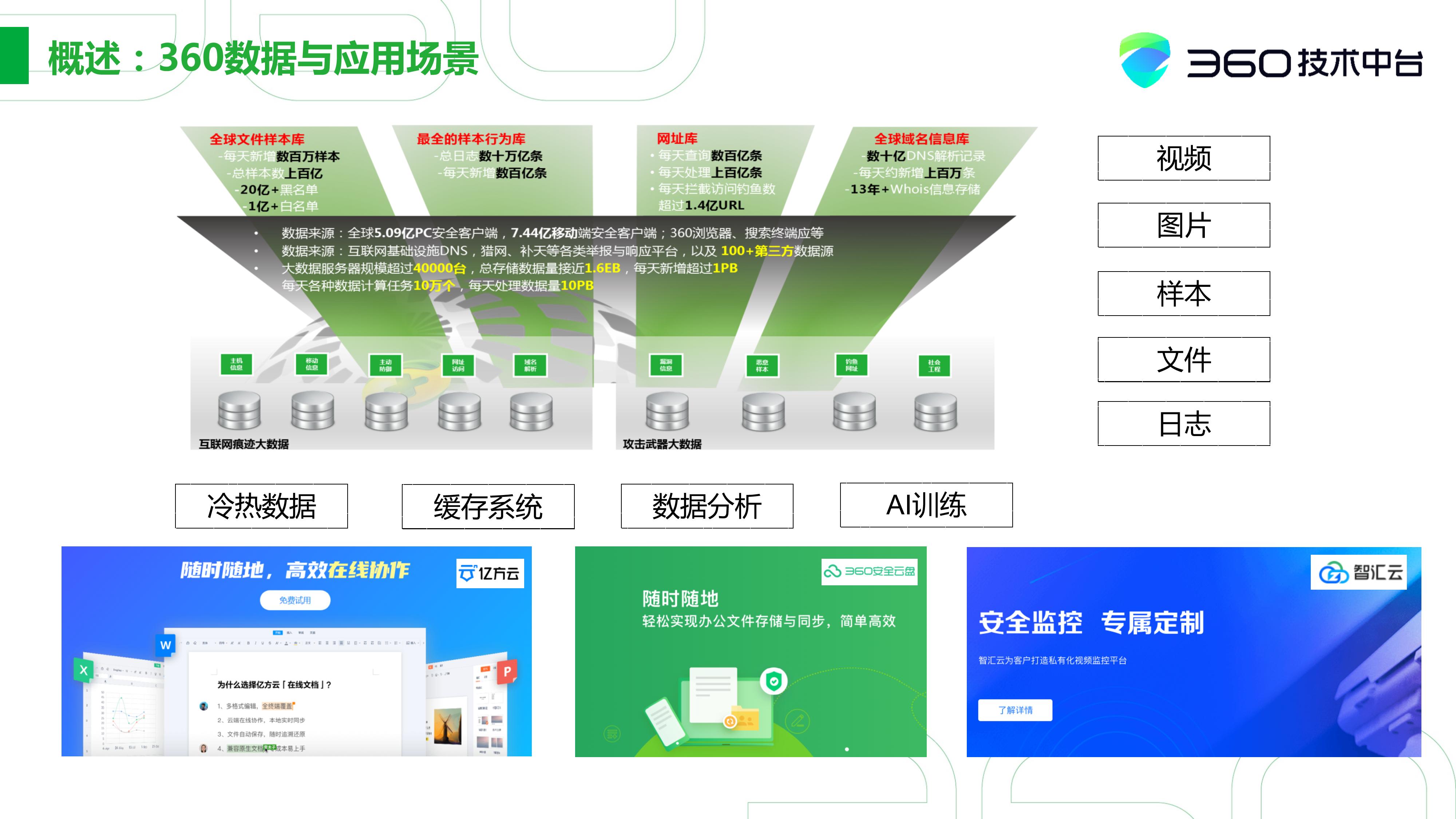
360的数据其实主要是两块,一方面是互联网,另外一方面是安全。安全数据肯定是全球文件的最大样本库,还包括行为库、网址库、域名库,这些都是和安全相关的。
当然,360还有自己互联网的业务。比如下图中以亿方云为代表的个人存储,还有以视频为核心的智汇云,就是围绕着视频生态来做的一些上层的产品。所以整体业务就涉及到大量的结构化、半结构化、非结构化的存储,包括视频图片、文件日志。这些可能都是360数据的一部分,其中很大的一部分大数据可能以Hadoop生态为主。
对于我之前说的类似这种个人数据存储、个人图片的半结构化、非结构化的数据,其实我们大量的在用Cassandra做一个存储。
我详细地介绍一下Cassandra在360的一些应用场景,整体上可以归结为几类。
场景一:通用对象存储
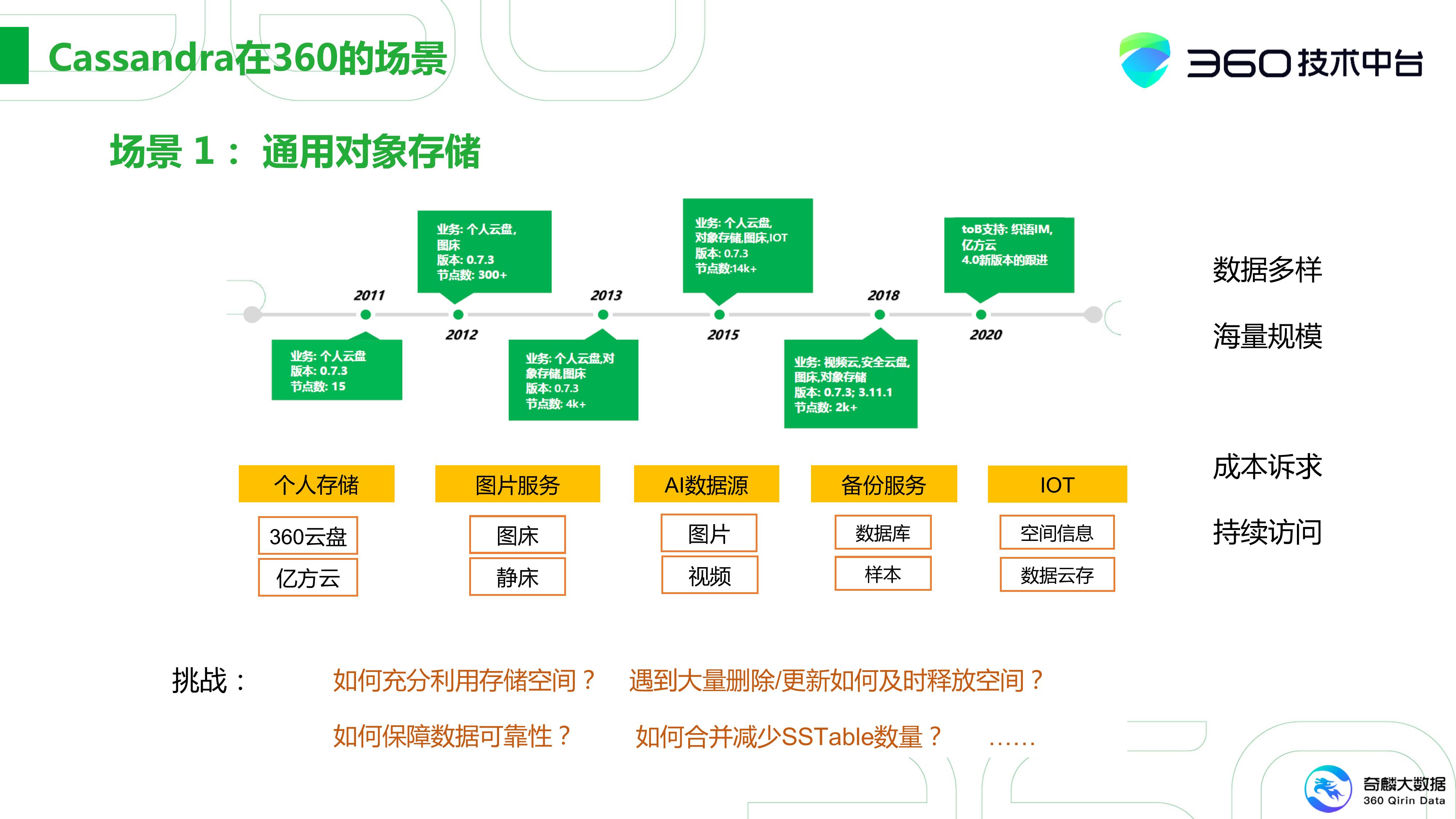
这就是我上面说的以个人云存储为契机发展起来的一套系统。这套系统从2011年最初的15个节点,到15年个人云存储的竞争激烈时,已经达到14,000个节点。当然,对于国内做个人云存储的服务商来说,如果用户数越多,成本可能也越高。
因此在15年其实就有一些分化了,比如百度云盘在这个基础上有持续的投入,用户数其实也在一直持续的扩大。在360这可能就有所收敛,把个人云盘往企业云盘、安全云盘上转型,数据量和集群的规模会有所下降。360对个人存储这块还是有比较好的一个预期,因此还会继续的发展,但不会有之前这么大的规模。
对于通用的对象存储有几个特点:首先是数据的多样化,有结构化、半结构化、非结构化的数据。尤其是图片视频这样的非结构化数据会比较多。然后还有像我们内部的图片服务。对于图床、静床这样通用的公共服务也都基于这个,所以这就带来了海量的数据存储需求。其实这成本也是非常大的。
比方在2015年,不管是百度网盘还是360云盘,每年的成本都大概在10亿以上。换句话说,300台全新机器的Cassandra集群,可以在一星期到两个星期内存满。所以对于这块业务来说,它的成本诉求是非常大的。
另外由于它是在线访问,那它对持续在线的要求也会比较高。这样其实又带来一些挑战,比如你首先需要利用好自己的现存的存量空间,才能让成本越来越低。如果持续遇到大量的删除和更新,如何及时释放一些空间,以及如何保证数据的可靠性。因为它本身基于local append的方式去做的LSM模型,所以需要通过Compaction合并减少SSTable的数量。
如果在数据量很小的情况下,这些挑战其实还好。但当数据规模飞速地增长时,这都是要面临的挑战。所以我们在主要场景上对平台还是做了很多改动的。
场景二:轻量数据分析的应用
Cassandra应用还是主要以宽表的存储场景为主——数据源通过抽取服务,落地到Kafka,接着进行批流计算。比如通过Flink做一些OLAP的预处理,生成可视化报表,同时把数据落地到Cassandra上,通过spark做一些分析。
它使用的场景其实也很简单,第一个就是对360大量样本漏洞的扫描。在安全领域有一个首发的优势,谁能先找出漏洞,做出的贡献是最大的。所以我们需要的就是快速样本扫描的应用,这也是基于Cassandra做的。
另外就是做一些轻量的BI分析,最主要的还是通过Flink的预处理形成了一个轻量的Pipeline。这在早期的安全业务和小型业务上使用得会多一些。基本上它优势就是极轻量化的部署,节点数量大概也就10台以内就足够了,主要是面向ToB的场景。

场景三:海量安全日志全文检索
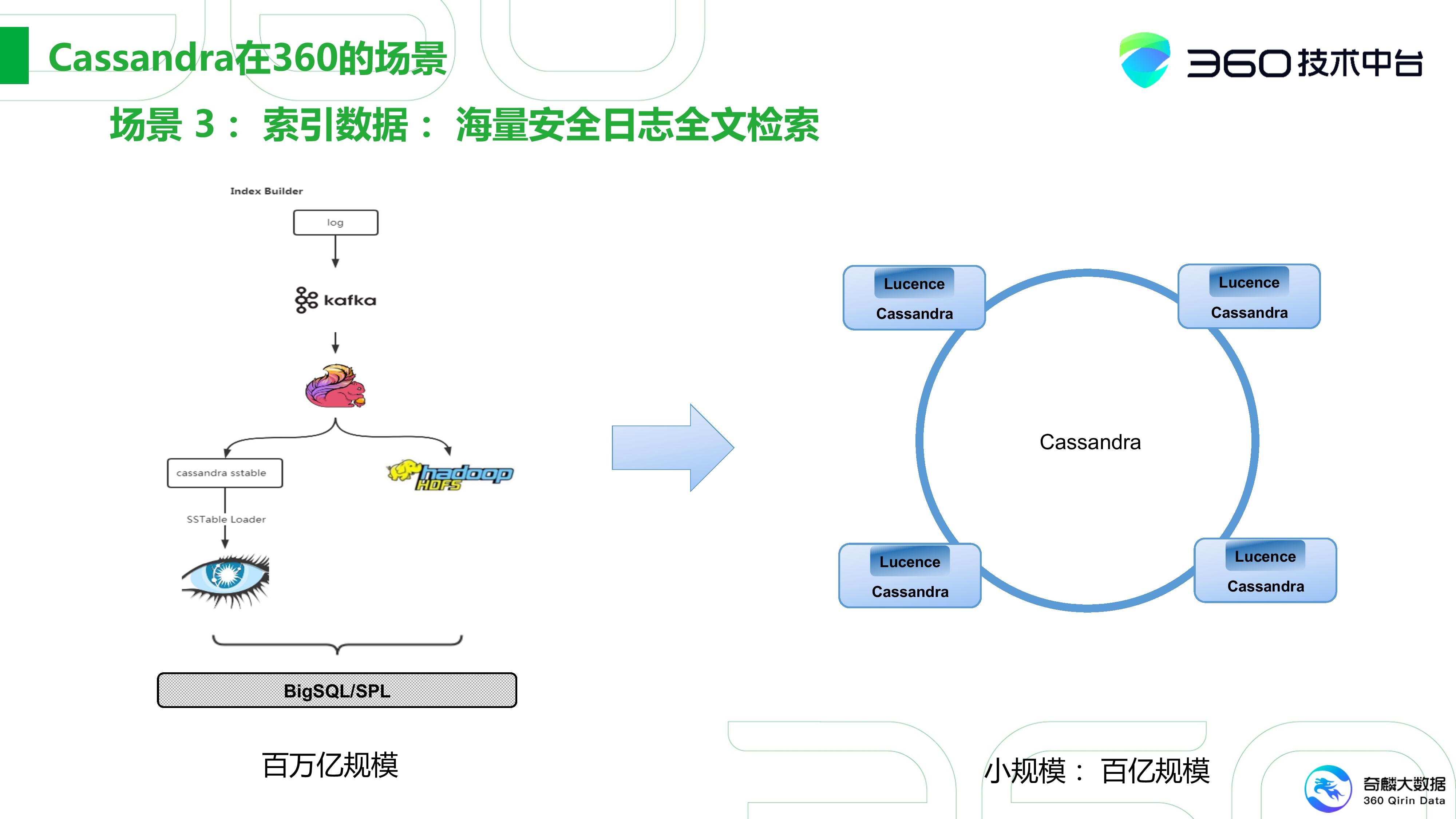
第三种场景就是海量这种安全日志的全文检索,这在360是一块比较有挑战性的工作。360会有大量数据安全的日志,安全分析师需要从日志中去溯源,比方查找一个APT攻击。
像我们这种搜索引擎,目前的建库规模也就在千亿级别。但在安全日志基本上就是百万亿的级别,基本上都是在两三个数量级以上的。
其次它没有冷热之分,一般搜索大家更多会关心最近的数据,但是对安全来讲,它是没有差别的。 一个APT攻击可能在数年前就已经埋下了,现在我们需要通过一些蛛丝马迹,找出这些漏洞,这样的挑战实际上非常大。
我们最初通过流式数据建立索引,接着将索引存放在Cassandra中。然后数据是放在HDFS中。这样每天要大概建千亿级别的索引,这样的规模实际上是非常大的。这两套系统通过上层的一个BigSQL(我们研发的一套大SQL检索)还有面向研发的这种SPL语言进行检索。
另一方面,这是一套非常专用的系统,比如面向我国政府的需求量大的的场景。但他们数据规模并可能没那么大。将这种百万亿规模的海量的存储架构落地到B端其实是不太可行的,所以这更像是一套专用的系统。
我们后来在做这块的时候,是将我们在HBase层面的一套二级索引搬到了Cassandra上,也就相当于内嵌Lucence,从而提供全文检索的功能,其实我们主要还是为了支持百亿规模的检索系统,让我们可以很快的落地B端。
大家也可能会问为什么我不用ES(Elastic Search),这其实是基于两点:
-
首先是Cassandra的架构,它支持从0到1, 1到n的这种灵活的扩展。
-
其次本身ES在我们实测中,在十亿到百亿级别的规模下,性能会相对好一些。但是我们架好Lucence后,其实百亿级别的查询检索性能会稍微高一些。
场景四:时序与图
这个场景想必大家也都比较了解,比如OpenTSDB能在HBase上运行,靠HBase为底层的基座,将数据按时序进行存储,从而对上层的TSDB提供一些时序服务。如果大家了解JanusGraph,这其实也是可以建在HBase之上的。
当落地一些2B场景时,我们认为HBase和Cassandra在数据模型上是可以对等的,但Cassandra这种灵活性、小型化可能正是我们需要的,所以我们将服务跑在了Cassandra上。
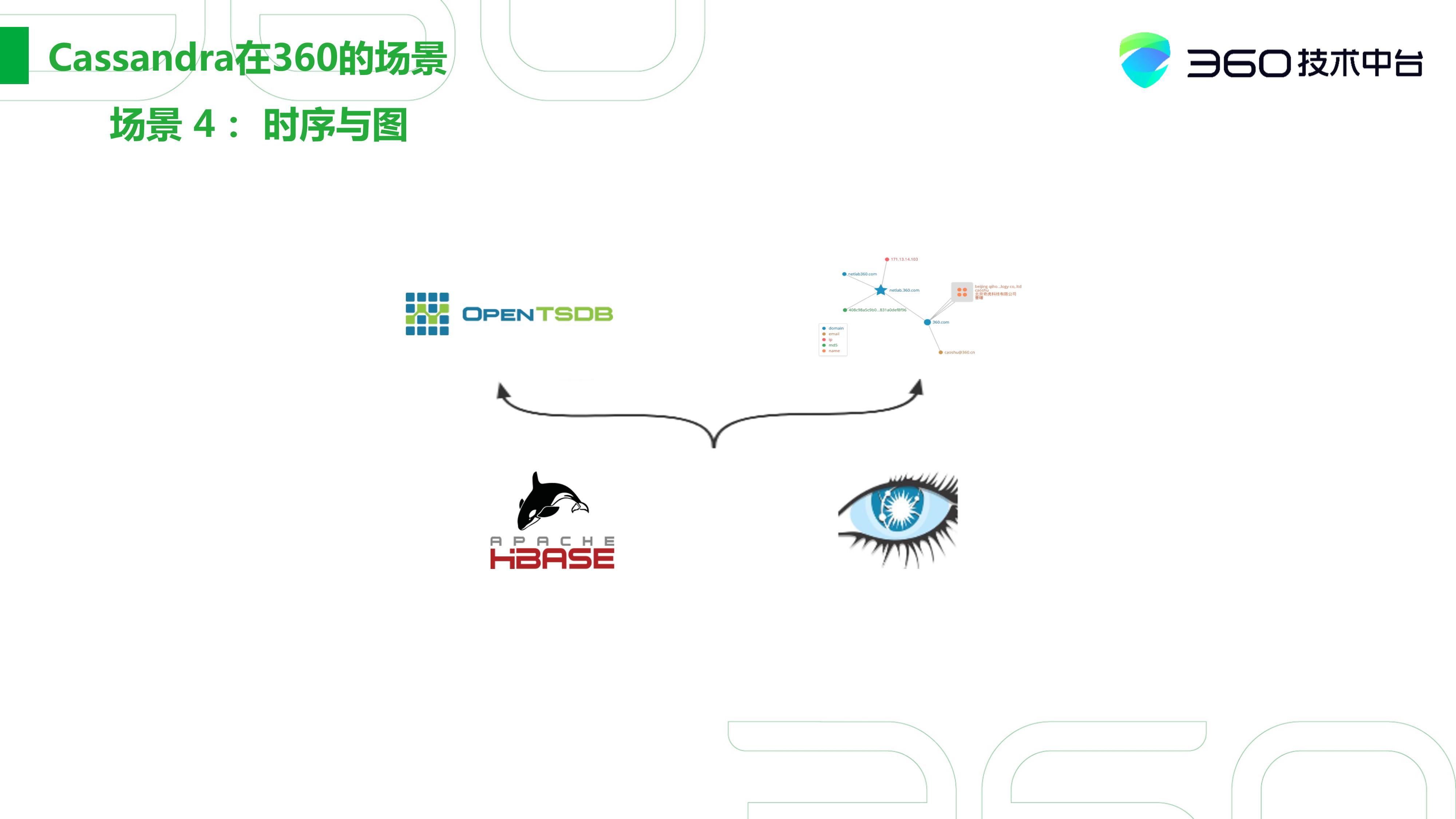
下面是我们基于Cassandra做的一个图数据库,是一套网络数据分析的系统。这套数据库主要存储了DNS数据,像样本的、认证的、证书一类的数据。 通过可视化,我们可以进行一些关联分析,做一些溯源。
这套系统对标的像是谷歌投资的一家以色列公司VirusTotal,还有国内的ThreatBook、Threat Graph一类的。这整套系统完全是基于Cassandra搭建的,360这套系统的竞争力还是相对比较明显的。

如果综合来看这这四种场景,360目前以通用的对象存储为主,但同时我们也在尝试拓展一些新的应用场景。
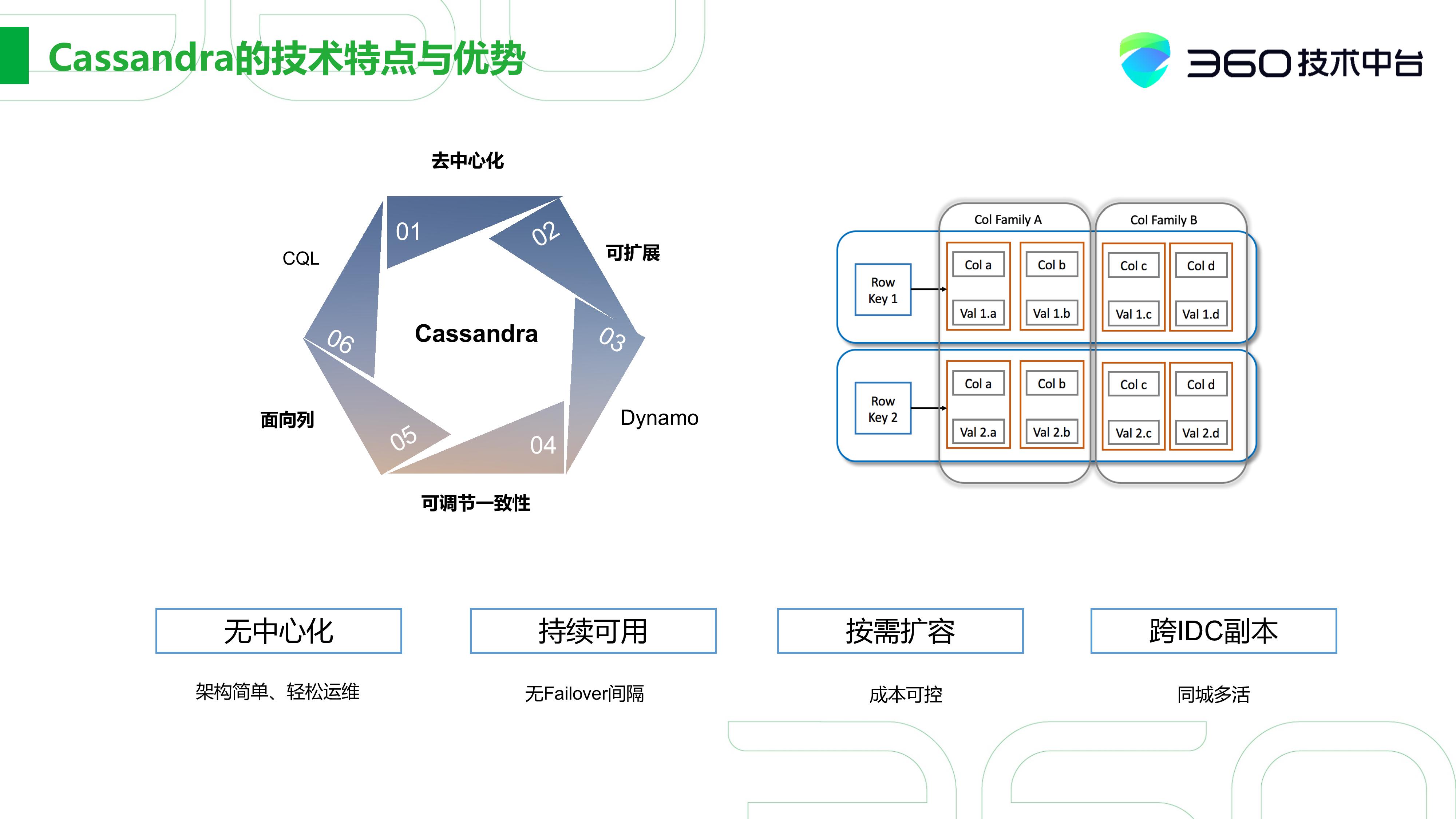
Cassandra的技术特点和优势
那下面我们可以看下Cassandra的技术特点和优势,这也是为什么我们要持续发展Cassandra的原因。
我们更多看中的Cassandra去中心化的设计,它有架构简单、可以轻松运维的特点。其次是持续可用,它可以持续写入,不像HBase会有failover的时间间隔。
接着就是按需扩容。 HBase的架构是建立在HDFS之上的,在大规模的存储平台上,整体的成本会降低平摊的平均成本。但在中小型规模的应用场景中没有这么多的数据,我们需要一个小型化的数据库存储以满足相同的需求。这就是我们常常说的从1个节点到n个节点的扩容,这一块Cassandra的优势是非常明显的。
另外在Cassandra版本的迭代中,在这种跨IDC副本的存储上,它也有很强的优势。我可以很轻松地通过设置两个IDC、一致性级别就可以构造同城多活的模式。对于一些关键的原数据存储,我们就是这么做的。
Wide-Column: Cassandra VS HBase
在宽表这一块,我们可以通过下图中几个方面将Cassandra和HBase进行对比,其中有以下注意的几点
-
高可用:Cassandra本身无中心,所以不会有单点故障。 HBase可能会有HDFS方面的单点故障, 也可能会有自身服务的单点故障,这都会导致整体MTTR(平均修复时间)时间较长。
-
数据恢复机制:Cassandra提供了Hinted handoff、读修复、repair等一系列修复机制。HBase肯定依赖于HDFS的块汇报、读修复。从数据恢复效率来讲,我个人认为相比Cassandra的EC更多通过的是Key-Value这种方式进行修复,可能HBase通过Trunk方式的修复力度会大一些。因此它的效率会更高一些,把EC的机制加进去之后会更明显。
在SCAN效率上,因为HBase依赖于HDFS,所以它的OUTSCAN(绕过HBase本身直接扫描下面文件)在批处理的场景下可能效率会更高一些。
在360中,HBase主要还是用于大规模存储、高吞吐的场景,我们更多把它用于一种离线的数据分析场景,如网页建库这一块。因为它能容忍访问的抖动和Region在迁移过程中短暂的中断。
对于Cassandra,我们更多会用在中等数据规模、低延迟的、高在线服务质量要求一些场景中。

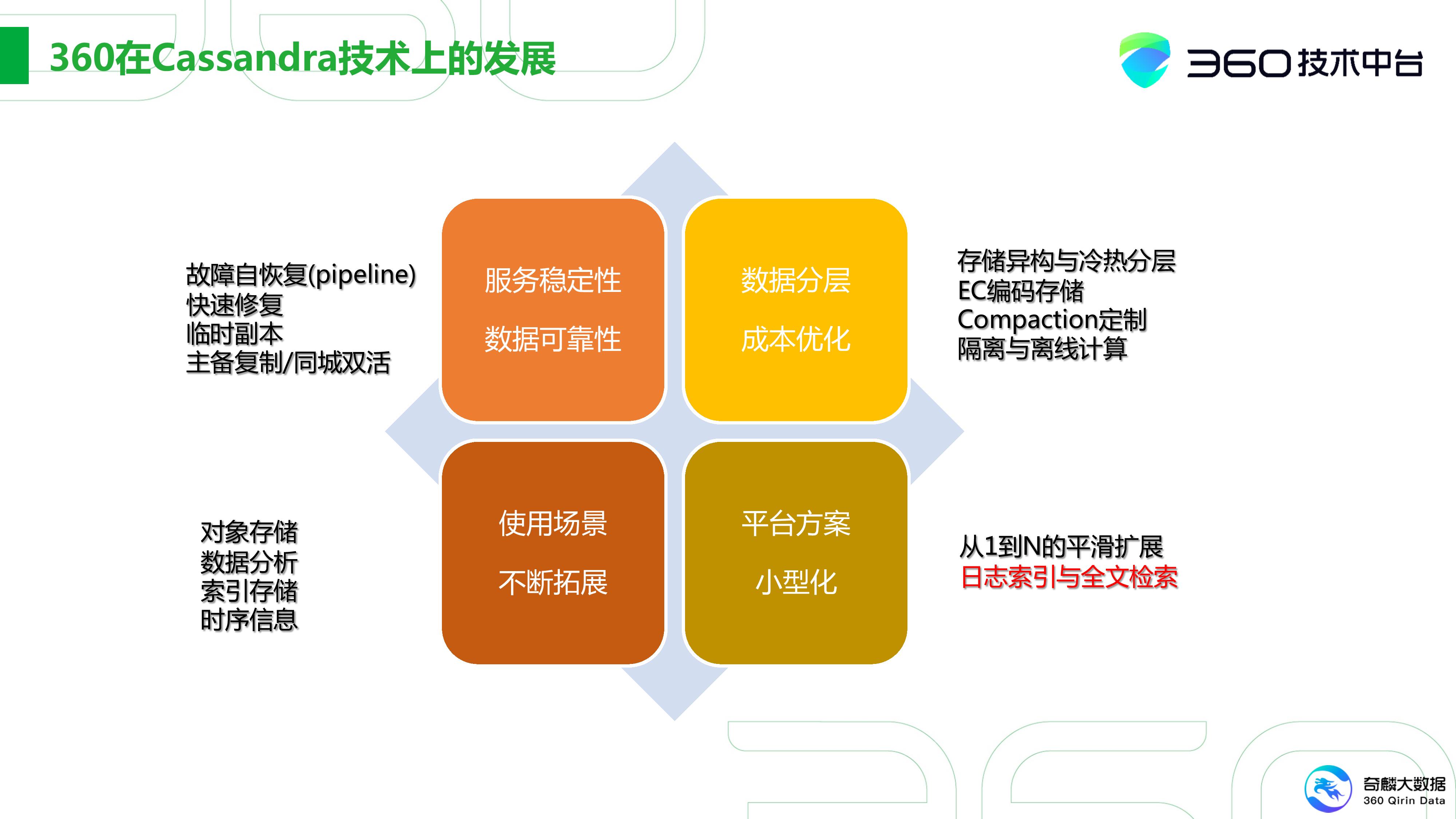
360在Cassandra技术上的发展
360目前接触Cassandra已经大约10年了,我们最早是基于0.7.3版本发展起来的。我们在这方面也做了很多的改动,前期主要是提高服务的稳定性、数据的可靠性,就是构建基本的能力。同时,我们也有一些故障自动恢复的Pipline之类的工具,可以加快恢复速度。还有通过临时副本的机制保证Cassandra集群能在最短时间内达到全副本的状态。最后就是主备复制和同城双活。
第二块就是成本上的考量,我们的思路也很简单。首先是存储的异构和冷热分层,通过EC可插式编码降低数据的平均副本数。另外Cassandra本身是一套存储系统,我们也尝试用它的计算能力做一些离线的计算。
像我之前提到的,我们在转型做2B的场景下做了一些小型化的方案,包括我们从1到N的平滑拓展。有些之前在HBase下场景,完全可以迁移到Cassandra上来实现。
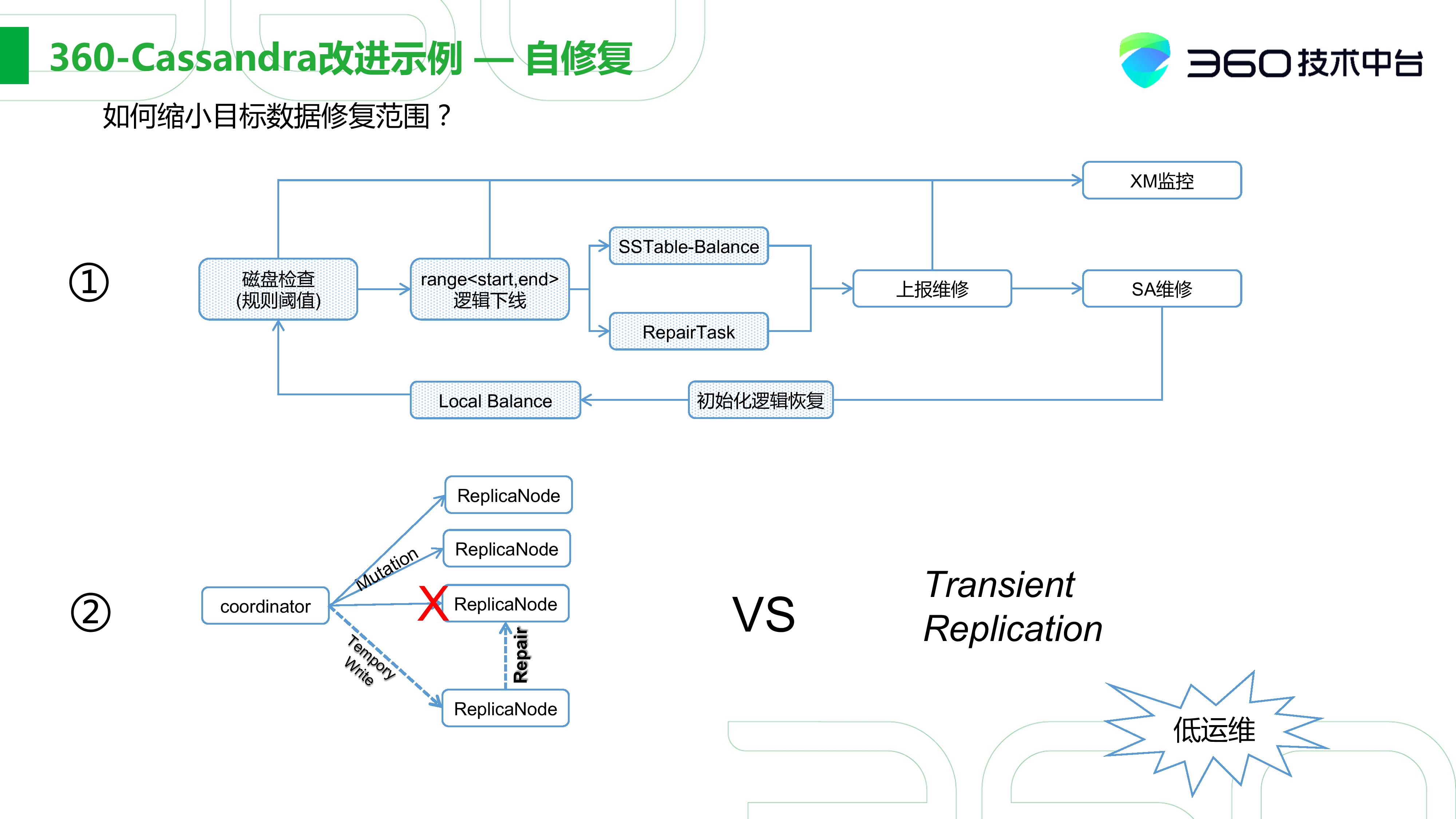
360 Cassandra 改进示例 - 自修复
我们现在用一些例子来展示我们在Cassandra下主要的一些改动,之前在技术上做了哪些方面的优化。
第一个是自修复,对于海量数据存储遇到最大的困难其实是磁盘的故障率,如果服务器超过了一万台,坏盘的几率是非常高的。因此我们不得不做一些和磁盘数据修复相关的事情,如果全靠人完成的话,那人力的开销成本是非常大的。
我们前期也做了很多这方面的事情,比如我们需要基于规则去检查smart control、硬件的一些信息。如果我们监测到一个磁盘在未来几天或一个星期磁盘可能会坏掉,在真正坏掉之前我们会做一些磁盘迁移的工作。当磁盘不可读时,我们会启动这repair task,从ring上做一些修复。当磁盘真正坏后,我们会自动上报维修,SA会在坏盘数积累到一定程度后进行统一的更换。换盘后,系统也会触发一些恢复的逻辑,接着通过Cassandra常规的方式恢复数据。
另外是临时副本,这点我们实现的比较早。 比如当三个节点中有一台故障时,Coordinator会把副本写到另一台临时节点上,等故障节点恢复后,再将数据恢复回来。这和社区的Transient Replication有一些区别,区别在于我们的写入后只是一个暂存,用户是不可见的,但社区版本在写入临时副本后用户是可见的,因此我认为社区实现的会更好些。
这就是我们一些低运维的操作,当数据量大的时候,这些优势就显现出来了。我们当时最高峰时有一万多台机器,但真正在进行运维的只有一个人。到目前为止,大部分的东西都可以通过自动化平台化来实现,所以我们以Cassandra为基础的运维其实就一个人。
360 Cassandra 改进示例 - 数据分层与EC
EC是我们在2013、2014年左右实现的比较早的策略,主要是为了降低成本。当时个人云存储发展过于迅速,结果导致我们成本上开销较大,因此不得不实现EC。 随着后期的优化,我们整体上对Cassandra进行了改造。
第一个是数据分层,我们更多的通过节点物理架构上的调整,可能里面存在着NVME的存储,同时也有HDD的存储。当然有些表是通过EC的方式实现,这样我们便会写入NVME中,接着我们会按时间顺序通过Compaction将它们写入HDD中,再过段时间我们可能会用自己的rebalance机制将它写入EC中。
通过这套机制,我们在成本上会有较大的降低。成本和可靠性是我们在Cassandra最主要努力的两个方向。

业界/社区近年的工作
社区方面的工作我就不详细介绍了,关于Cassandra 4.0的一些变动,这个DataStax同行做的幻灯片有详细的介绍。

数据库发展的趋势
接着让我来分享下对于数据库发展的看法。
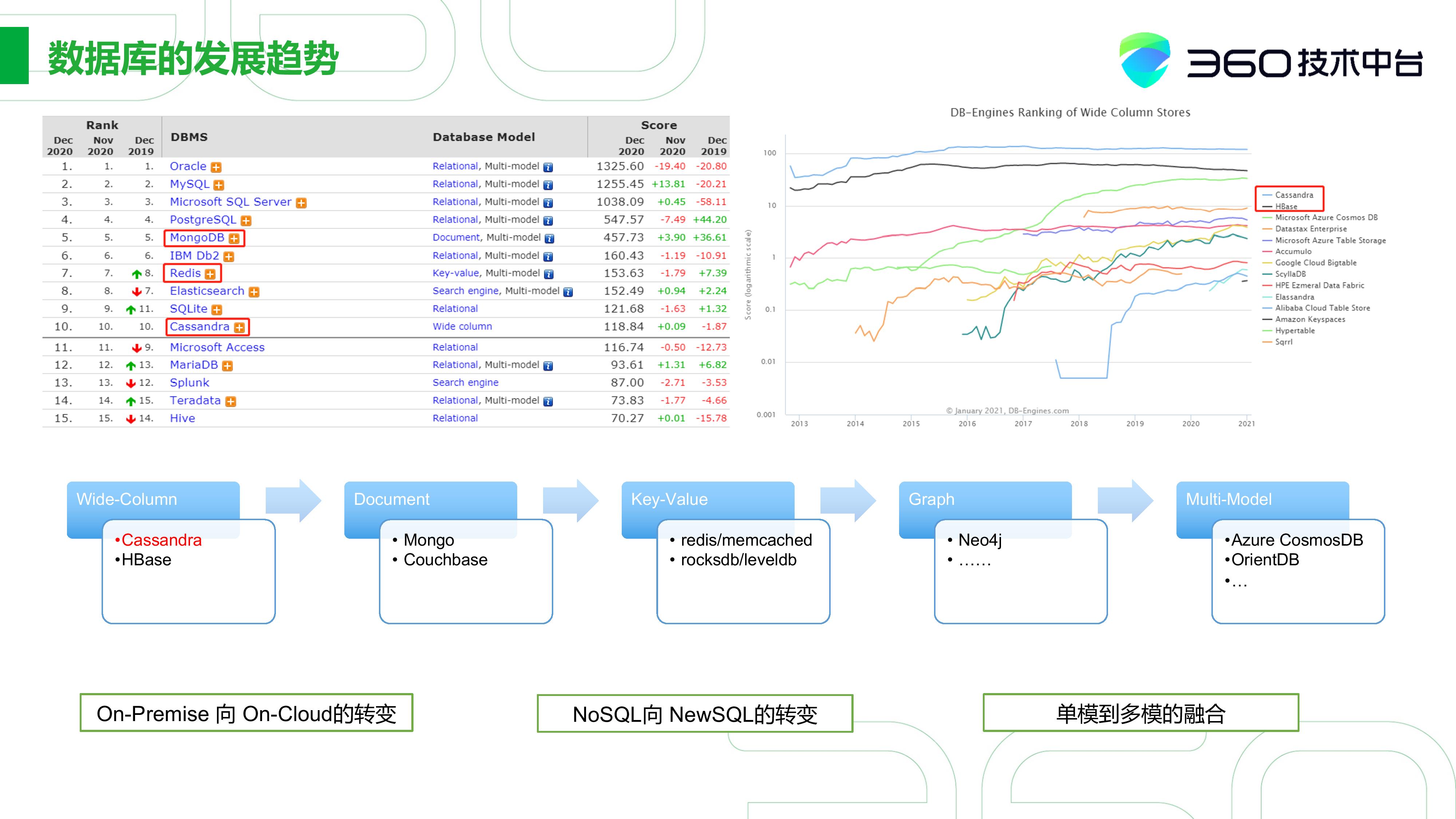
首先让我们来看看DB-Engine下面两张表,我们大概可以对比下各个数据库排名,从而了解Cassandra的地位。我们可以大概看到Cassandra一直位于行业前十。在右图宽表数据库排名中我们可以看到,在宽表存取数据模型一样的情况下Cassandra排名要比HBase高一些。
此外我整理了有大概三个方向的变化:
-
私有化部署往云(云原生数据库)的转变
-
NoSQL向NewSQL的转变
-
单模到多模的融合
大家可以看左图数据库中,无论是SQL还是NoSQL,在database model中都有一个“Multi-model” 的标签。很多数据库其实都希望能支持多模的存储。
从On-Premise向On-Cloud的转变
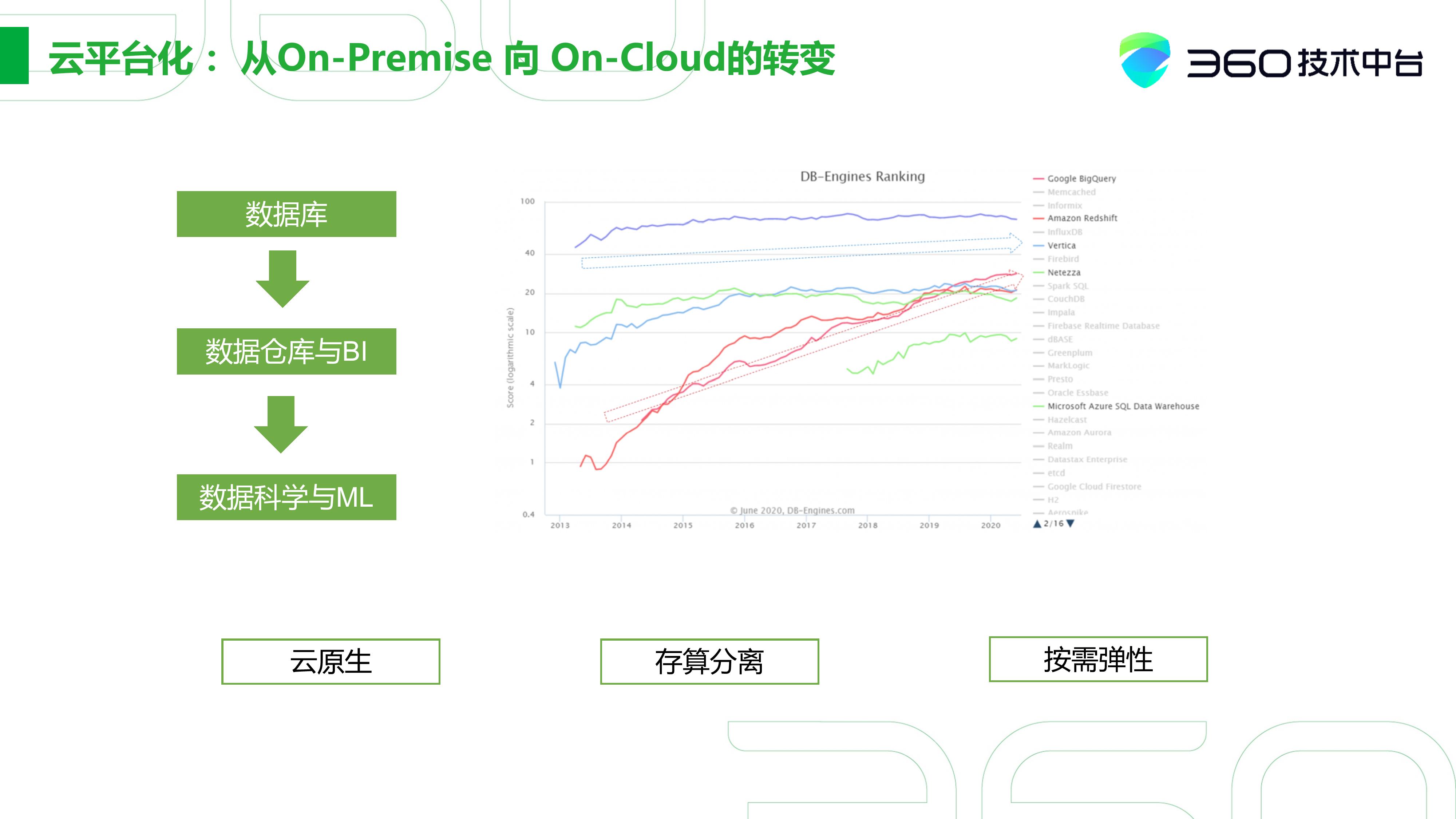
展开来讲,首先是私有化部署往云的转变。其实不止是数据库, 其实从数据仓库到数据科学,大家都在往这个方面转变。右图反映了分析数据库存储随时间的变化,传统的数据库呈一个平稳上升的趋势,如以BigQuery和Redshift为代表的数据库,发展是比较快的。它主要的特点是存算分离和按需弹性。
NoSQL向NewSQL转变
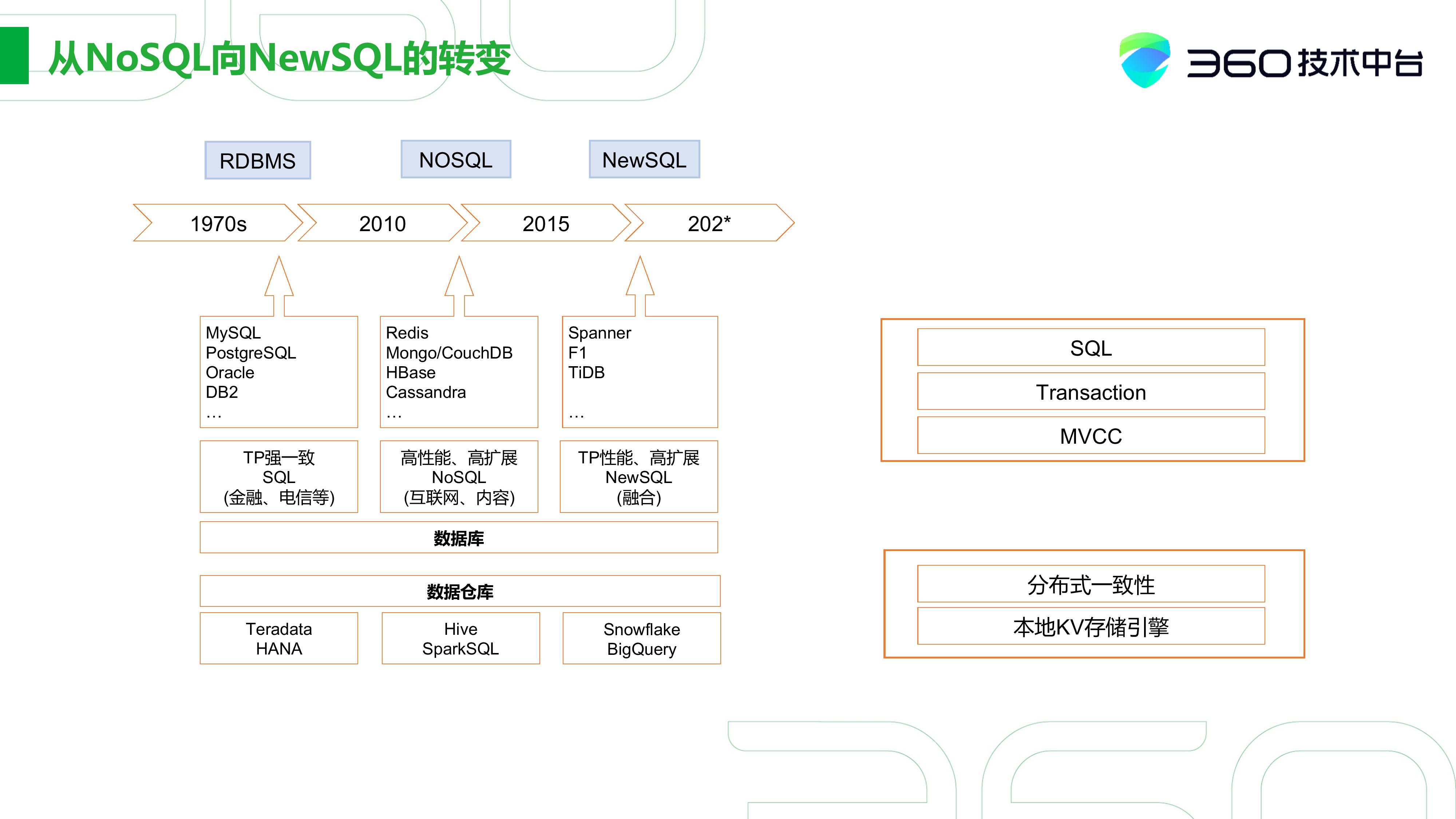
第二个是NoSQL向NewSQL的转变。在上世纪70年代到2000年之前还是以TP强一致性的关系式数据库为主,主要用于金融、电信的领域。
但2000年之后,随着互联网的兴起,半结构化数据在急剧性的增长,以Mongo、Cassandra、HBase为代表的NoSQL数据库也在2001年开始快速的发展起来,主要用于互联网非结构化数据的存储。
然而随着像Spanner、F1论文的出现,NewSQL这方面的需求就开始变大,它既要求有TP的强一致性,也要求有NoSQL高性能、高拓展的灵活性,所以产生了两种数据库之间的融合。
数据仓库也十分类似,如最早的Teradata、HANA,到现在代表NoSQL的Hive、SparkSQL, 包括今年比较火的Snowflake。
单模到多模的融合
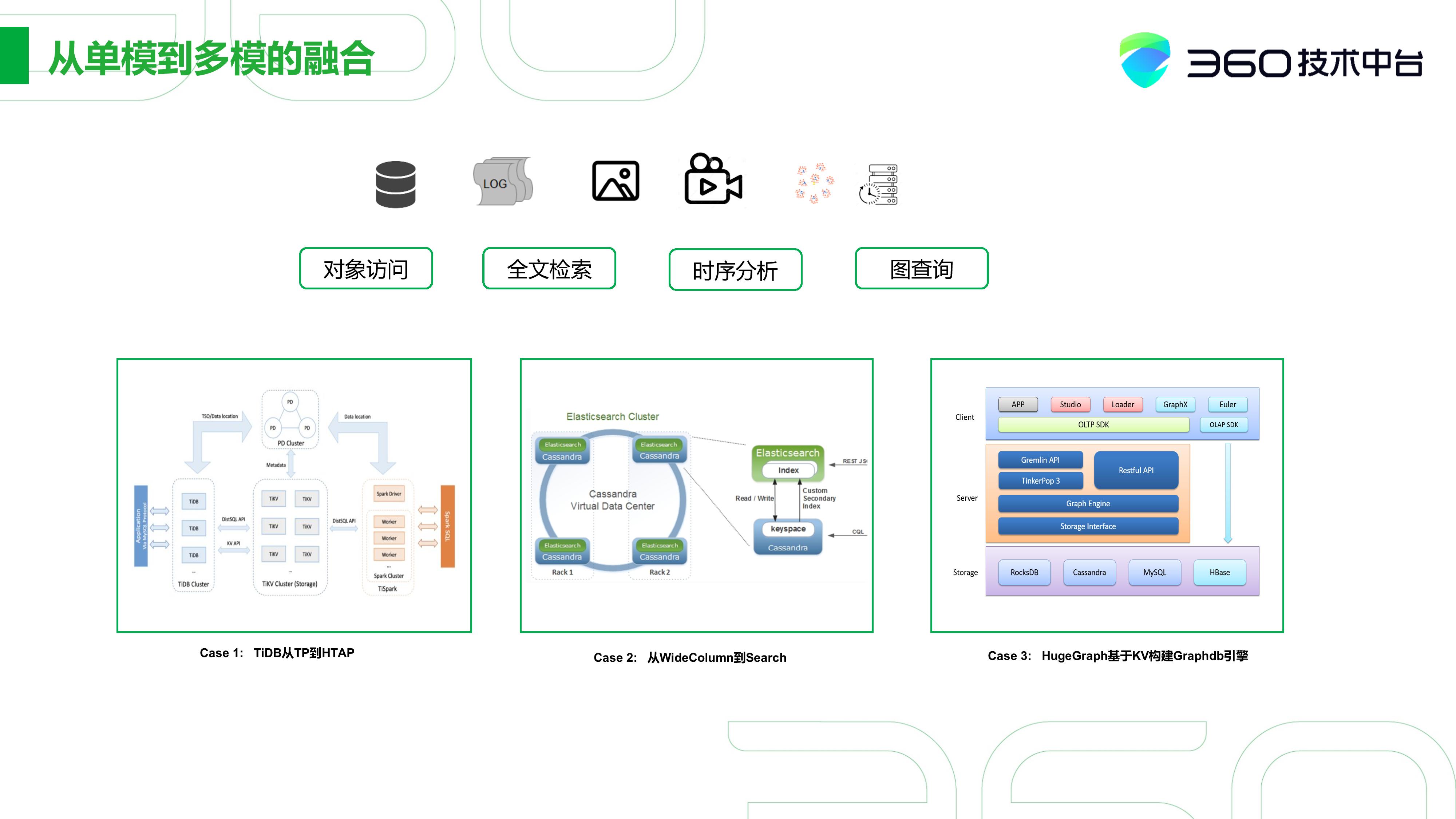
大家可以看到从2010年往后,除了传统的关系型数据,大量的半结构化非结构化数据增长的比较快,对这种数据的访问需求其实也变得多种多样,如对象访问、全文检索、时序分析、图的查询等等。能否对现有的数据库或模式进行针对这些场景拓展,这也是很有需求的。
举个例子,首先就是TiDB,国内很多小伙伴也应该听过,是一套以做事务为主的数据库。到后面,它就以针对事务分析一体做了延展。
对国外环境比较了解的小伙伴可能知道,有将Cassandra和ElasticSearch进行结合,从而实现全文检索功能的案例。这相当于从WideColumn拓展到Search。
还有以NoSQL数据库为基础,进行构建Graphdb的引擎的场景,比如国内百度HugeGraph。
业界/社区可能的工作
以下的猜想只代表我个人的观点,并不是社区的最终发展方向,主要有三个猜想。
首先是时序和搜索的支持,从WideColumn向Multi-Model的发展。我知道DataStax很早将Solr融合到DataStax Enterprise中支持搜索。
其次是NewSQL,Cassandra本身的事务在不断的增强,那会不会有可能朝NewSQL的方向发展呢?
第三个是弹性云化,这依赖于网络和硬件的发展,现在100GB的网络已经逐渐成为了主流。在未来的3到5年,整体的网络设施甚至可能会超过IO硬件的发展。那弹性的云化可能会成为一个发展目标。现在我们已经有了对Cassandra进行了容器化的Cassandra K8s,这大大提升了Cassandra的隔离性和拓展性。这便可以把离线的计算力可以调动上去,从而实现离在线的混步 。
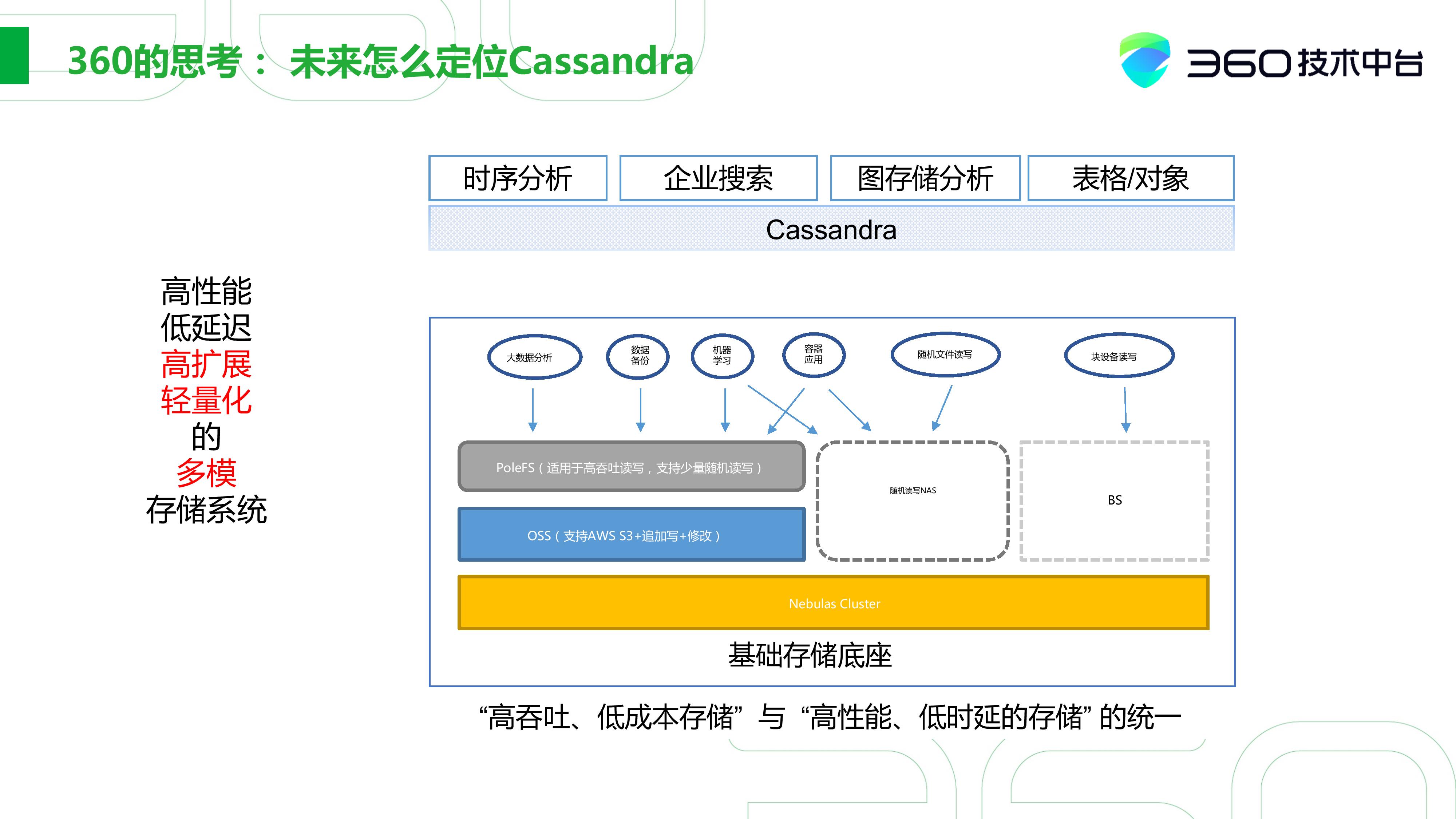
360的思考:未来如何定位Cassandra
最后我们说说Cassandra在360未来的定位。
360也经历了从商业数据库到开源到自研一个历程, 所以我们在自研方面投入了很多力量,包括“高吞吐、低成本存储”与“高性能、低时延存储”的统一,希望提供一套整体的存储基座。在上层数据库层面,可能会做一些存算分离的调整,这样我们便可以依托于Cassandra实现一些时序分析、企业搜索、图存储分析以及表格/对象的场景。
我们对Cassandra的定位是希望它能做到高性能、低延迟、高拓展、轻量化、多模。但在未来2~3年可能会整体迁移到基础存储底座之上。
提问环节
1. Canssandra看起来可以适用很多的场景,但和专用的系统,如时序和influxDB,图和图数据库Neo4j相比是否会存在劣势?(47:05)
对于时序,Cassandra可以做底层基础的底座,OpenTSDB可以利用Cassandra的数据模型实现持续数据的组织。
图数据库也同理,这是一种典型的存算分离的架构。如果你用Neo4j和现在这种模式实现的HugeGraph或JanusGraph相比,它有自己一套数据组织的方式,比如单机模式,可能性能会相对高一些。但这种基于Cassandra构建的图数据库的拓展性则会更优,这也是它特有的趋势。
我们在用这种图数据库做网络安全分析时,在点查或多步邻居这方面的性能能满足我们绝大多数场景的需求。如果我们需要做图计算的分析,我们可以用SCAN来加载Cassandra或HBase中的底层数据,再用Spark里的GraphX做一些计算。总体来说,它的灵活性和可拓展性是一般Neo4j不具备的。
当然,这也取决于你的数据规模,Neo4j对单机本身的数据规模在十亿、百亿之间使用案例会比较好。但我们用Cassandra构建的图数据库规模已经达到了百亿甚至千亿的规模,明年甚至可能会再提高至少50%到1500亿。当然,这些基于Cassandra的开源方案相对于企业版的Neo4j成本也会低很多。
2. 关于Cassandra集群的监控是否有一些很好的经验?
Cassandra本身能通过虚拟表获取一些信息,但我们的做法有些不同。我们关注的首先是磁盘,第二个则是通过JMX将信息收集起来,再做整体分析。
Cassandra的系统相对稳定,更多的问题可能存在于磁盘上,尤其是现在使用比较廉价的硬件情况下,所以我们更需要关注的则是数据的可靠性,要能快速恢复数据。
其他方面,因为Cassandra的对等性,所以它的监控逻辑会的相对简单。我们在之前的活动里也提到,360的Cassandra监控体系其实被纳入到了一个完整监控体系Xmanager中。
我们一方面,会通过主动排查巡检,另一方面通过自动化流程的打通。总体来说,Cassandra运维的稳定性要远远高于HBase,所以它也能满足我们日常线上服务质量的要求。
3. 关于之前提到的NoSQL和NewSQL概念,Cassandra是否会支持HTAP(Hybrid Transactional/Analytical Processing)特性?
我回答这个问题可能不是很适合,因为360本身并没有做到这点。比如TiDB本身就是一个TP系统,在TP的基础上通过三个副本中两个副本去保证我的TP,然后另外一个副本可能是做一个AP,也就是列存的方式来实现。
Cassandra能否通过这种方式实现这样的架构,既能满足 AP的场景,又能满足TP的场景,但这都是一个猜想了。但是我个人认为,短期内社区也不会这么去做。所以说整体上来讲,短期大家如果需要这方面可能会有点失望。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号