技术基础 | 监测Apache Cassandra的简明方式——MCAC
点击这里在GitHub上访问我们,以便深入了解DataStax的开源项目——Apache Cassandra指标收集器(Metric Collector for Apache Cassandra, or, MCAC)并试用示例程序。
作为一个具有复原力的系统,Apache Cassandra可以让用户在其基础上构建应用程序,但是很多使用者会感觉Cassandra有一点像是一个黑匣子。Cassandra并不是没有丰富的监测指标,事实上,每个Cassandra表格都提供了超过300个指标系列(metric series)可供用户使用。
但问题是,将集群本身、操作系统和应用层面的指标进行可视化并放入一个统一标准的视图,这对于Cassandra的使用者来说并不容易。
01 什么是Apache Cassandra指标收集器
为了解决这个问题,DataStax推出了一个新的开源项目,叫做Apache Cassandra指标收集器(Metric Collector for Apache Cassandra,简称为MCAC)。这个项目就Apache Cassandra的监测问题提供了一个开箱即用的解决方案。下面我们将简单介绍这个工具是怎么工作的。
MCAC是基于已经被广泛运用的collectd守护进程构建的,并在其基础上做了一些具有创意的微调。Collectd是一个指标收集守护进程,它己经被广泛采用,并与包括prometheus、graphite、stackdriver以及其它各种外部指标系统集成良好。
虽然collectd可以开箱即用式地通过JMX(Java管理扩展)搜集指标数据,这个方法很可能耗时良久且只能适用于导出部分指标数据。更别提很多人根本不想在每个节点上都维护和配置指标守护进程。
我们已经将MCAC使用在了DataStax Astra中的Health(健康)标签,并与我们为Apache Cassandra定制的Kubernetes operator相捆绑。
02 MCAC的与众不同之处
为了解决上述的问题,MCAC将我们的Java守护进程和可移植的Linux collectd打包成为一个单独的组件。
开发者需要做的仅仅是将这个守护进程添加到cassandra-env.sh中,它将会启动collectd并通过一个Unix套接字将Cassandra中的每一个指标数据传入collectd。MCAC适用于从2.2到4.0的所有Apache Cassandra版本。
这种高效的传递指标数据的方式可以做到输出每个节点的成千上万个指标,同时几乎不会对C*的性能构成任何影响。
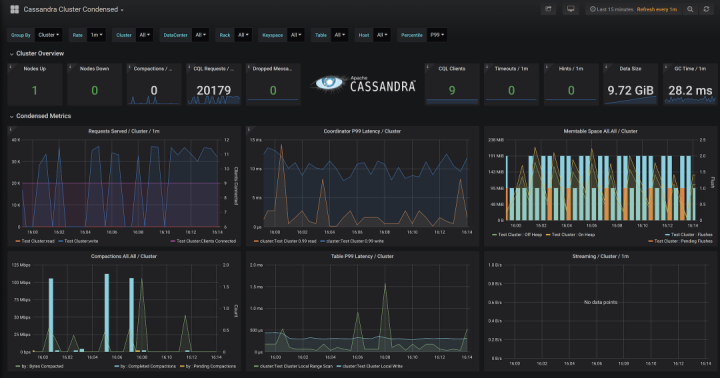
MCAC不止发送指标数据,它还特别考虑了如何以开箱即用的方式与Prometheus协同工作。比如柱状图(histograms)是为了Prometheus中的聚合(aggregation)而特别设计,再比如标签(labels)会在数据传入时被自动转换。这意味着你可以跨数据中心、跨机架(rack)甚至跨表灵活切割指标数据。
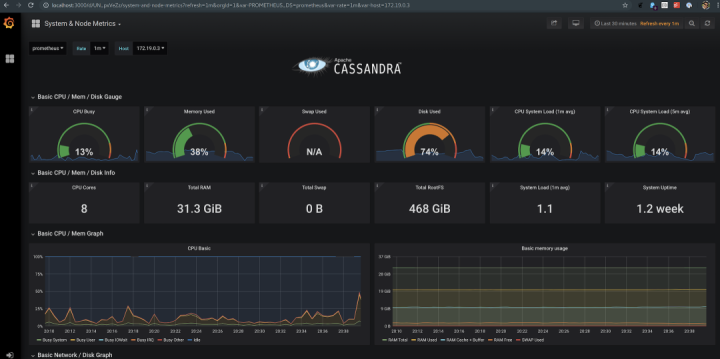
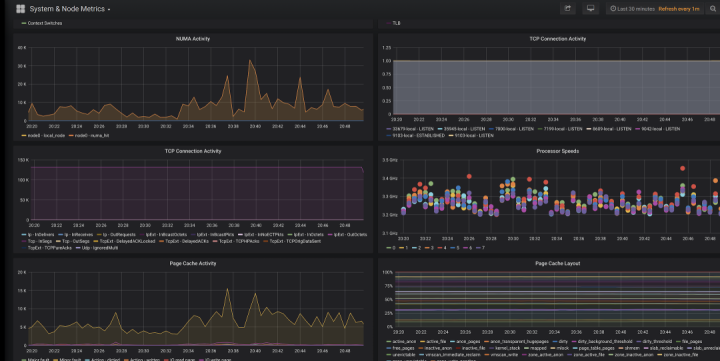
Cassandra的指标数据只是等式的一部分,借助collectd,我们还可以收集并展示操作系统层面的指标数据,像是上下文切换(context switches)和磁盘/网络性能。
与节点活动情况相关的指标和非指标事件,MCAC也会为其创建历史日志。非指标事件包括关于刷盘(Flushes)、压实操作(Compactions)、异常(Exceptions)、垃圾回收(GC)等细节信息。这份DataLog(数据日志)可以用于分析性能或其它对集群产生影响的事件。
如果您需要帮助,我们的SRE (Service Reliability Engineering)团队随时待命,帮助您诊断故障并解决问题。
最后,要是没有办法可视化这些指标数据可就太糟了!MCAC提供预置的Grafana仪表盘,用来将所有指标联结在一起。Grafana仪表盘为使用者提供了监测Cassandra数据库最好的解决方案。这些仪表盘会随着时间变化,它们关注系统的特定方面,从而让使用者更容易借此深入了解自己的集群。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号