kubernetes概述之深入理解pod对象
一.深入理解Pod对象
1.Pod容器的分类
Pod的概念:
- 最小部署单元
- 一组容器的集合
- 一个Pod中的容器共享网络命名空间
- Pod是短暂的
Pod的容器分类:
Infrastructure Container:基础容器 -- 维护整个Pod的网络空间
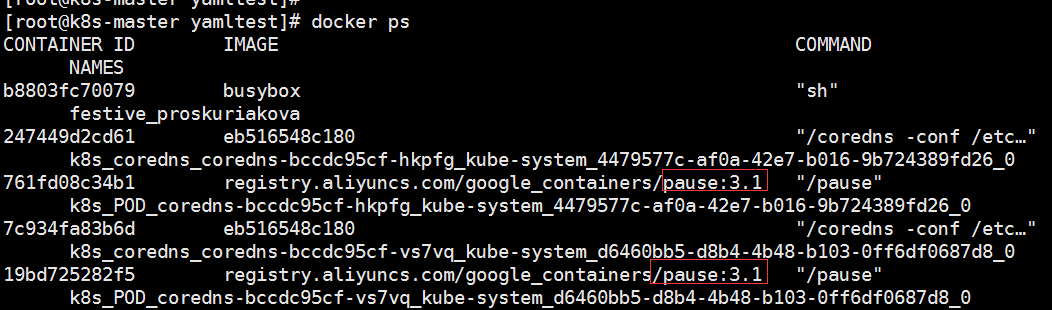
一般这里的pause镜像的作用就是维护pod的网络空间
InitContainers:初始化容器 -- 先与业务容器开始执行
Containers:业务容器 -- 并行启动
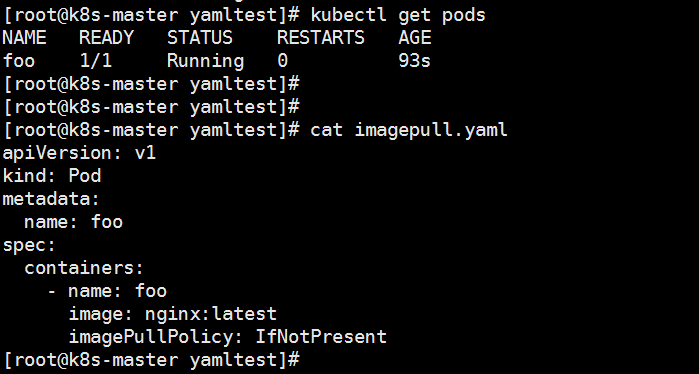
2.镜像拉取策略
- IfNotPresent:默认值,镜像在宿主机上不存在时才拉取
- Always:每次创建Pod都会被重新拉取一次镜像
- Never:Pod永远不会主动拉取这个镜像


apiVersion: v1
kind: Pod
metadata:
name: foo
spec:
containers:
- name: foo
image: nginx:latest
imagePullPolicy: IfNotPresent
3.资源限制
Pod和container的资源请求和限制:
- spec.containers[].resources.limits.cpu
- spec.containers[].resources.limits.memory
- spec.containers[].resources.requests.cpu
- spec.containers[].resources.requests.memory
主要是limit和requests两个参数,request是k8s预分配的内存大小,k8s根据这个大小进行调度,而limit是限制pod的容量大小,只有这么多容量可用
这里强调下cpu的参数:500m代表0.5个cpu,1000m代表1个cpu
apiVersion: v1 kind: Pod metadata: name: fronted spec: containers: - name: db image: mysql env: - name: MYSQL_ROOT_PASSWORD value: "password" resources: requests: memory: "64Mi" cpu: "250m" limits: memory: "128Mi" cpu: "500m"

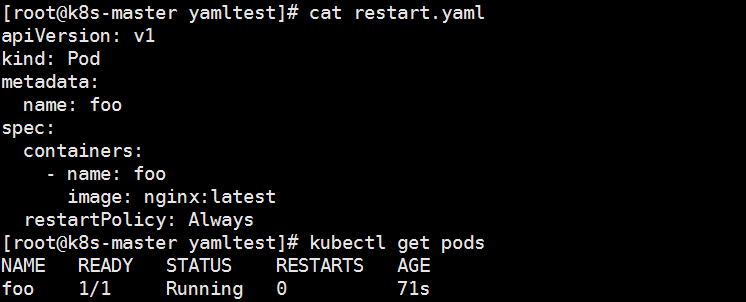
4.重启策略(restartPolicy)
- Always:当容器终止退出后,总是重启容器,默认策略
- OnFailure:当容器异常退出(退出状态码非0)时,才重启容器
- Nerver:当容器终止退出,从不重启容器
apiVersion: v1
kind: Pod
metadata:
name: foo
spec:
containers:
- name: foo
image: nginx:latest
restartPolicy: Always
5.健康检查(Probe)
Probe有以下两种类型:
(1)livenessProde
如果检查失败,将杀死容器,根据Pod的restartPolicy来操作
(2)readlinessProde
如果检查失败,kubernetes会把Pod从service endpoints中剔除
Probe支持以下三种检查方法:
(1)httpGet:发送HTTP请求,返回200-400范围状态码为成功。
(2)exec:执行shell命令返回状态码是0为成功。
(3)tcpSocket:发起TCP Socket建立成功
apiVersion: v1 kind: Pod metadata: labels: test: liveness name: liveness-exec spec: containers: - name: liveness image: k8s.gcr.io/busybox args: - /bin/sh - -c - touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600 livenessProbe: exec: command: - cat - /tmp/healthy initialDelaySeconds: 5 periodSeconds: 5
这里是调用shell创建文件休眠30s,之后删除在休眠600s,之后cat这个文件根据状态码进行监控检查,默认策略是根据Pod的restartPolicy来重启的
官网参考:https://kubernetes.io/docs/tasks/configure-pod-container/configure-liveness-readiness-probes/

可以看出没经过一段时间便会重启pod,以实现效果
6.调度约束
创建一个pod的过程:
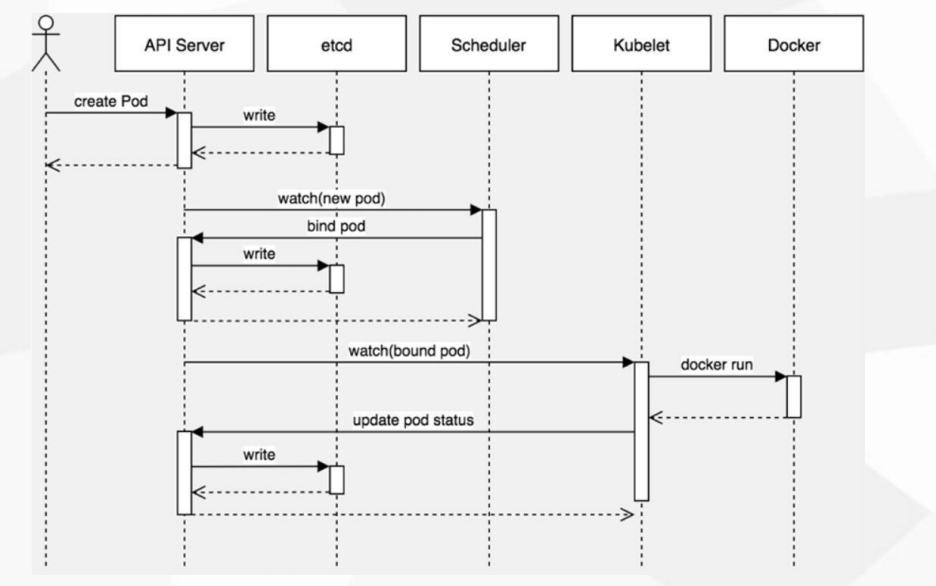
总体来说:用户创建完pod提交至API server,之后写入Etcd,Api server的watch方法通知Scheduler有pod需要调度,Scheduler将调度完的列表响应给Api server,Api server将列表信息写入etcd,Apiserver通知node节点上的kubelet,kubelet绑定自身的pod,然后run docekr 返回给Api server,将机器状态写入etcd。
也可以指定pod调度到某些节点上
(1).通过nodeName指定
apiVersion: v1
kind: Pod
metadata:
name: pod-example
labels:
app: nginx
spec:
nodeName: k8s-node1
containers:
- name: nginx
image: nginx:latest

(2).nodeSelector用于将Pod调度到匹配Label的Node上
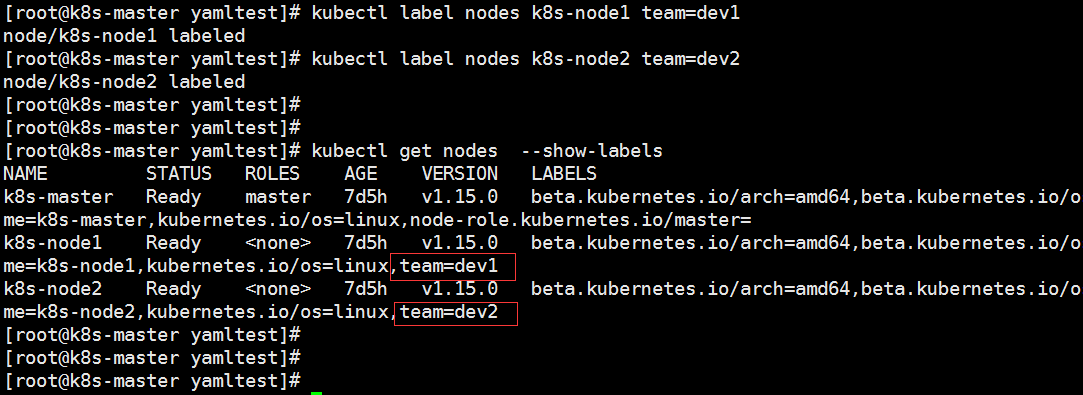
为节点创建分组:
kubectl label nodes k8s-node1 team=dev1
apiVersion: v1
kind: Pod
metadata:
name: pod-example
spec:
nodeSelector:
team: dev1
containers:
- name: nginx
image: nginx:latest

7.故障排查
通常的值与描述:

kubectl describe TYPE/NAME
kubectl logs TYPE/NAME [-c CONTAINER]
kubectl exec POD [-c CONTAINER] -- COMMAND [args...]
pod创建失败一般用上述命令查看具体原因
官网参考:https://kubernetes.io/docs/concepts/workloads/pods/pod-lifecycle/
二.部署应用常用控制器
1.Deployment(无状态应用部署)
Pod与Controllers的关系:
- controllers:在集群上管理和运行容器的对象
- 通过label-selector相关联
- Pod通过控制器实现应用的运维,如伸缩,滚动升级等

Deployment主要作用:
- 部署无状态应用
- 管理Pod和ReplicaSet
- 具有上线部署,副本设定,滚动升级,回滚等功能
- 提供声明式更新,例如只更新一个新的Image
应用场景:Web服务,微服务
有状态的应用一般包含需要数据持久化的应用,或者启动服务有顺序的那种
apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deployment namespace: default spec: replicas: 3 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:latest ports: - containerPort: 80
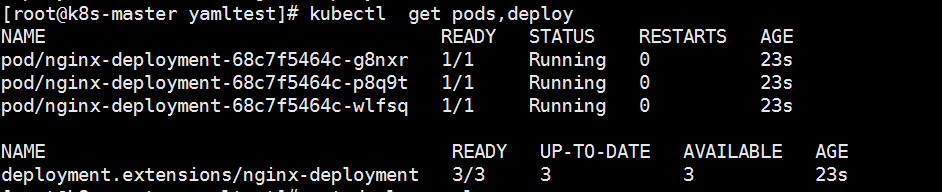
2.DaemonSet(守护进程状态控制器)
- 在每一个node上运行一个Pod
- 新加入的Node也同样会自动运行一个Pod
应用场景: Agent
flannel的网络模式就是累死这种agent

3.Job(批处理任务)
Job分为普通任务和定时任务,一次性执行
应用场景:离线数量处理,视频解码等业务
apiVersion: batch/v1 kind: Job metadata: name: pi spec: template: spec: containers: - name: pi image: perl command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"] restartPolicy: Never backoffLimit: 4
执行kubectl create -f my-job.yaml结果如下:

4.CronJob(定时任务)
定时任务,像linux的Crontab一样,定时任务,应用场景:通知,备份
apiVersion: batch/v1beta1 kind: CronJob metadata: name: hello spec: schedule: "*/1 * * * *" jobTemplate: spec: template: spec: containers: - name: hello image: busybox args: - /bin/sh - -c - date; echo Hello from the Kubernetes cluster restartPolicy: OnFailure

小结:
- Deployment:无状态部署
- DaemonSet:守护进程部署
- Job & CronJob:批处理
三.Service - 统一入口访问应用
1.什么是Service
Service提供了统一访问应用的服务,能够动态添加管理Pod资源
- 防止Pod失联(服务发现)
- 定义一组Pod的访问策略(做负载均衡使用)
- 支持ClusterIP,NodePort以及LoadBalancer三种类型
- Service的底层实现主要有iptables和ipvs二种网络模式
2.Pod与Service的关系
- Pod与Service通过label-selector相关联
- 通过Service实现Pod的负载均衡(TCP/UDP 4层)

3.Service 类型
Service有三种类型,分别是ClusterIp,NodePort,LoadBalancer
ClusterIP:分配一个内部集群IP地址,只能在集群内部访问也就是(同Namespace内的Pod),默认ServiceType,ClusterIP模式的Service为你提供的,就是一个Pod的稳定的Ip地址,即VIP
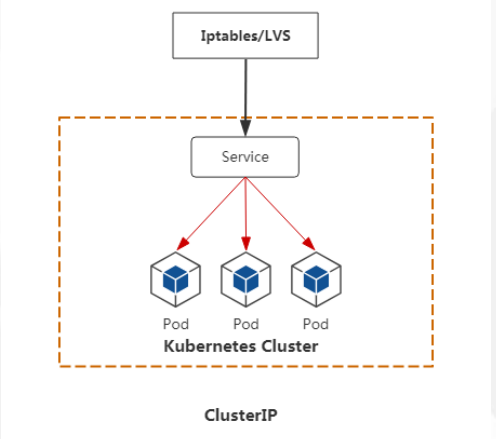
属于默认的service类型,只能集群内部访问使用
apiVersion: apps/v1beta2 kind: Deployment metadata: name: nginx-deployment namespace: default spec: replicas: 3 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:latest ports: - containerPort: 80 --- apiVersion: v1 kind: Service metadata: name: nginx-service labels: app: nginx spec: ports: - port: 80 targetPort: 80 selector: app: nginx
执行创建命令创建后的结果如下:
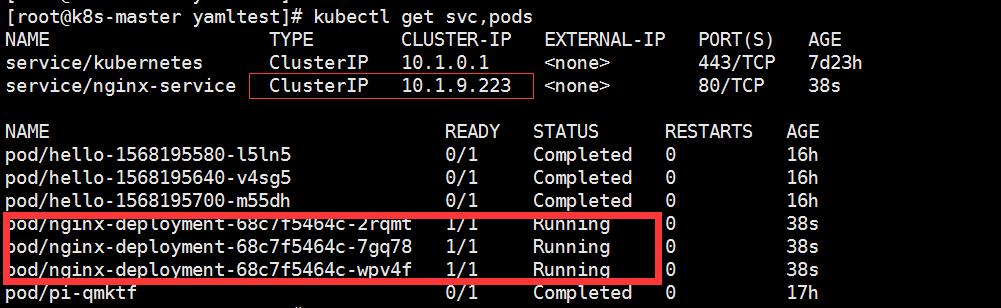
此时访问这个VIP即可通信:
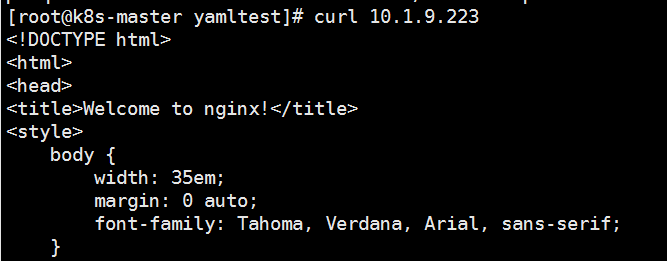
NodePort:分配一个集群IP地址,并在每个节点上启用一个端口来暴露服务,可以在集群外部访问
kind: Deployment metadata: name: nginx-deployment namespace: default spec: replicas: 3 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:latest ports: - containerPort: 80 --- apiVersion: v1 kind: Service metadata: name: nginx-service labels: app: nginx spec: type: NodePort ports: - port: 80 targetPort: 80 selector: app: nginx
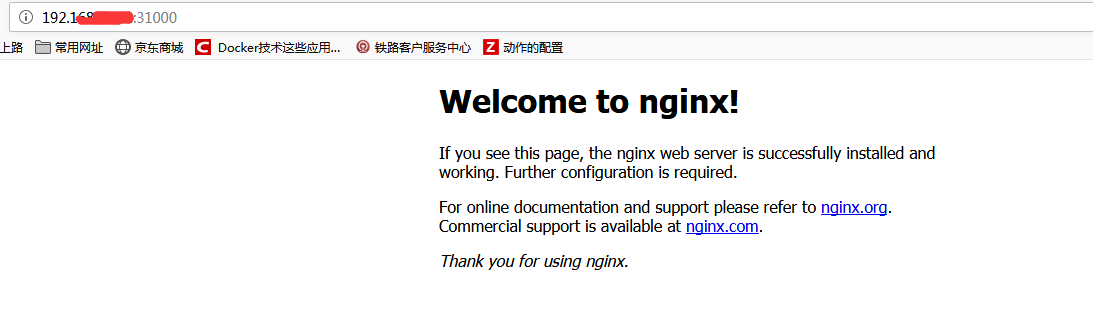
执行创建结果:

这个时候我们可以利用这个nodeip+端口访问这个服务
LoadBalancer:分配一个内部集群Ip地址,并在每个节点上启用一个端口来暴露服务,除此之外,kubernetes会请求底层平台上的负载均衡器,将每个Node作为后端添加进去
一般此种方式用于公有云的负载
4.Service代理模式
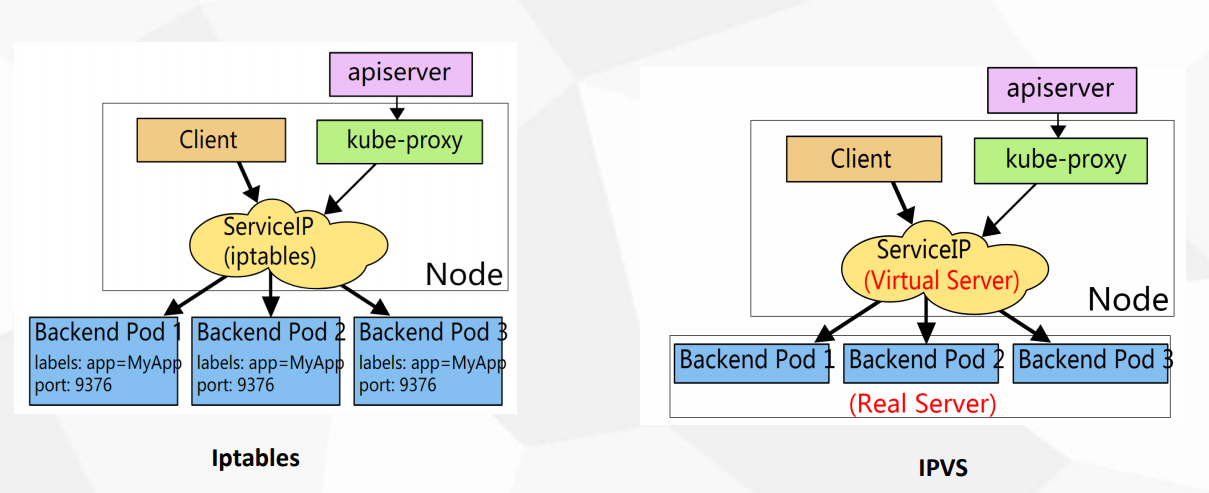
Service支持的两种网络代理模式Iptables和IPVS
iptables:灵活功能强大,规则从上到下匹配,遍历匹配和更新,呈线性延时,可扩展性
ipvs:工作又内核态,有更好的性能,调度算法丰富,rr,wrr,lc,wlc,ip,hash
5.DNS
DNS服务监视Kubernetes API,为每个Service创建DNS记录用于域名解析
用service.namespace调用即可

 浙公网安备 33010602011771号
浙公网安备 33010602011771号