HTTP协议原理概述
一.HTTP通讯原理说明
1.HTTP请求报文格式如下:
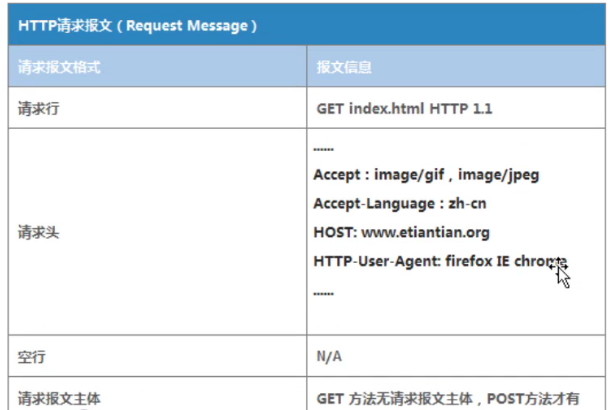
其中请求行包含的内容:
请求方法:希望客户端完成什么样的请求,
get:获取服务端的文件内容 post:存储提交数据到服务端。
index.html表示要请求的文件。
协议版本:http1.0 http1.1 http2.0,http1.0:属于TCP短连接类型协议
http1.1:属于TCP长连接类型协议。
请求头:包含一些请求的图片资源,以及语言类型,请求主机和所使用的浏览器信息。
还有一个空行信息
最后是请求主体:get方法:没有请求主体内容,post方法:会有请求主体内容
2.HTTP响应报文格式:

(1).响应的起始行:包括响应的状态码和状态信息等
不同的状态码对应不同的作用:

(2).响应的头部信息:服务端有关信息的介绍说明
(3).空行信息:隔离上下文,说明响应头部结束
(4).响应主体内容:请求后进行响应返回的内容信息
二.HTTP协议资源说明
1.媒体资源类型:web服务可以处理接收的资源类型(text/html css jpg avi)
一般在web服务软件程序中,会有一个文件来定义媒体资源类型(mime.type)
2.URL/URI
URL:统一资源定位符类似(www.jd.com) URI:统一资源标识符(error2.aspx)
3.静态文件资源
静态网页资源的几个重要特征:
(1).每一个页面都有一个固定的URL地址,且URL一般以html,htm,shtml等常见形式为后缀
而且地址中不含有问号“?”或“&”等特殊符号
(2).静态网页是实实在在保存在服务器上的文件实体,每个网页都是一个独立的文件
(3).网页内容是固定不变的,因此,容易被搜索引擎收录(容易被用户找到)
(4).因为网页没有数据库的支持,所以在网站制作和维护方面的工作量较大,
当网站信息量很大时,完全依靠静态网页比较困难
(5).网页的交互性较差,在程序的功能实现方面有较大的限制
(6).网页程序在用户浏览器端解析,如IE浏览器,程序解析效率很高,
由于服务器端不进行解析,并且不需要读取数据库,因此服务器端可以接受更多的并发访问。
当客户端向服务器请求数据时,服务器会直接从磁盘文件系统上返回数据(不做任何解析)。
待客户端拿到数据后,在浏览器端解析并展现出来
4.动态网页资源
(1).网页扩展名后缀常见为:.asp、.aspx、.php、.js、.do、.cgi等。
(2).网页一般以数据库技术为基础,大大降低了网站维护的工作量。
(3).采用动态网页技术的网站可以实现更多的功能,如用户注册、用户登录、在线调查、投票、用户管理、订单处理、发博文等。
(4).动态网页并不是独立存在于服务器上的网页文件,当用户请求服务器上的动态程序时,服务器解析这些程序并可能通过读取数据库来返回一个完整的网页内容。
(5).动态网页中的“?”在搜索引擎的收录方面存在一定的问题,搜索引擎一般不会从一个网站的数据库中访问全部网页,或者出于技术等方面的考虑,
搜索蜘蛛一般不会去抓取网址中“?”后面的内容,因此在企业通过搜索引擎进行推广时,需要针对采用动态网页的网站做一定的技术处理(伪静态技术),以便适应搜索引擎的抓取要求。
5.仿静态文件资源
根本实质还是动态资源,将动态资源伪装成静态,动态不便于搜索引擎收录,响应速度较慢。
三.网站度量值统计方法:
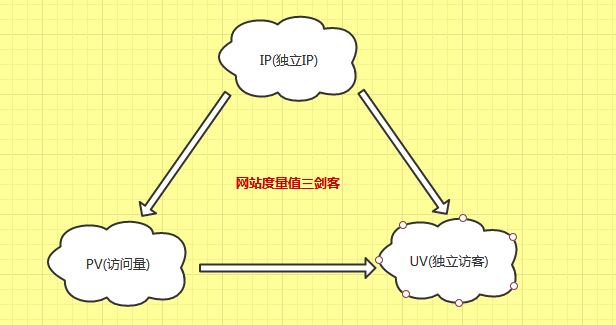
1.IP(独立IP),即Internet Protocol,这里指独立IP数,独立IP数是指不同IP地址的计算机访问网站时被计的总次数
2.PV(访问量)即Page View,中文翻译为页面浏览,即页面浏览量或点击量,不管客户端是不是相同,也不管IP是不是相同,用户只要访问网站页面就会被计算PV
3.UV(独立访客)即Unique Visitor,同一个客户端(PC或移动端)访问网站被计为一个访客。一天(00:00-24:00)内相同的客户端访问同一个网站只计一次UV

 浙公网安备 33010602011771号
浙公网安备 33010602011771号