初识TDengine
1. 几个概念
TSDB: Time Series Database,时序数据库。非关系型数据库,主要用于处理带时间标签(按照时间的顺序变化,即时间序列化)的数据,带时间标签的数据也称为时间序列数据。时序数据库的特点在于:写多于读、顺序写、很少更新、区块删除。因此时序数据库非常契合那些产生频率快、严重依赖于采集时间、测点多信息量大的工业数据,比如:电力、化工、气象等行业。
SQL:Structured Query Language,结构化查询语言。是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统;简单点讲就是操作数据库的一种语言。
2. TDengine简介
开发公司是涛思数据,国产的开源时序数据库,具有支持SQL、缓存、流式计算、订阅、集群部署等特点。
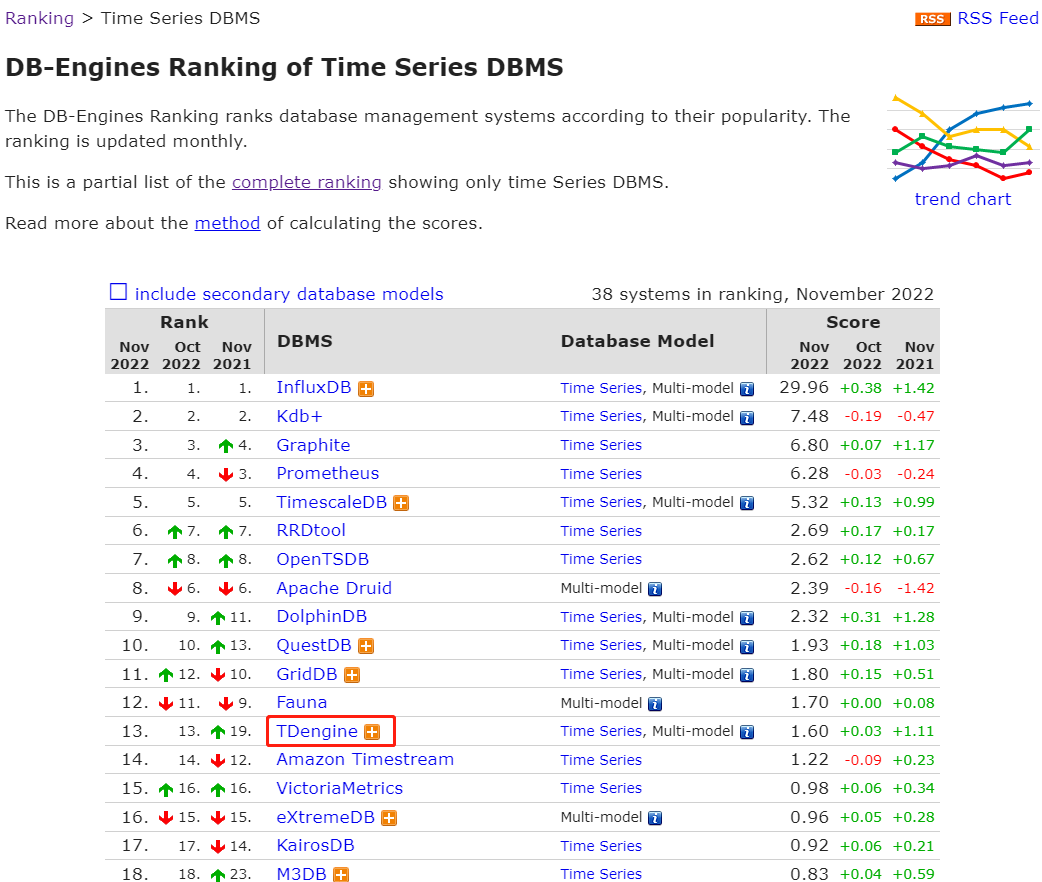
下面是2022年11月在DB-Engines网站上时序数据库的排名,可以看到是有进步的。
3. 安装
TDengine支持多种方式的安装,如果不需要他的造数据的demo的话,推荐使用docker安装,安装包的安装会带有一个名为taosBenchmark的产品性能测试工具,它可以模拟生成数据,测试TDengine的插入、查询和订阅等功能的性能。
这里贴一下docker安装的步骤:
如果已经安装了 Docker,首先拉取最新的 TDengine 容器镜像:
docker pull tdengine/tdengine:latest
或者指定版本的容器镜像:
docker pull tdengine/tdengine:3.0.1.4
然后只需执行下面的命令:
docker run -d -p 6030:6030 -p 6041:6041 -p 6043-6049:6043-6049 -p 6043-6049:6043-6049/udp tdengine/tdengine
更多的安装方式请参考官方文档。
4. 几个概念
库
和关系型数据库的库的概念没有什么区别,库里面存放的是数据表。
超级表 STable
因为TSDB主要的应用场景在工业数据的采集,那么自然会存在许多类型相同的设备需要被采集数据。超级表可以简单看作设备类型的抽象。
子表 Subtable
如果说超级表是模板,代表某种设备类型,那么子表就是具体的设备,子表依赖于超级表。
采集量(Metric)和 标签(Label/Tag)
一个设备需要被监控采集的数据,会动态变化的就是采集量;静态不变的数据比如设备名称等就是标签。
这些只是一部分简化后的概念,更具体的请查阅官方文档。
5. 简单使用SQL操作数据库
在2中我们提到TDengine是支持SQL进行操作的,现在以docker安装的TDengine为例,我们简单说一下怎么用SQL操作TDengine。
首先我们需要进入TDengine的命令行操作界面。
# 进入容器内部
docker exec -it $容器ID bash
# 执行taos命令,进入命令行模式
taos
会出现如下界面:
root@9d229d2bd7b0:~# taos
Welcome to the TDengine Command Line Interface, Client Version:3.0.1.6
Copyright (c) 2022 by TDengine, all rights reserved.
****************************** Tab Completion **********************************
* The TDengine CLI supports tab completion for a variety of items, *
* including database names, table names, function names and keywords. *
* The full list of shortcut keys is as follows: *
* [ TAB ] ...... complete the current word *
* ...... if used on a blank line, display all valid commands *
* [ Ctrl + A ] ...... move cursor to the st[A]rt of the line *
* [ Ctrl + E ] ...... move cursor to the [E]nd of the line *
* [ Ctrl + W ] ...... move cursor to the middle of the line *
* [ Ctrl + L ] ...... clear the entire screen *
* [ Ctrl + K ] ...... clear the screen after the cursor *
* [ Ctrl + U ] ...... clear the screen before the cursor *
**********************************************************************************
Server is Community Edition.
下面是简单的SQL示例:
# 展示数据库
show databases;
# 创建数据库
CREATE DATABASE power KEEP 365 DURATION 10 BUFFER 16 WAL_LEVEL 1;
上面一条SQL的意思是:创建一个名为power的数据库,这个数据库数据保存365天(KEEP),同时呢只允许插入比当前时间早10天的数据(DURATION),后面两个参数BUFFER和WAL_LEVEL是涉及内存池和落盘策略的设置。
以我们的项目为例,创建一个超级表。
-- 温湿度计
CREATE STABLE WSD
(
ts timestamp,
Temp float,
Hum float
)
TAGS (equipId binary(20));
因为目前没有太好的数据库可视化工具来适配TDengine,而且官方的TDengineGUI又不支持最新版的TDengine,再加上数据库的字段非常简单,见名知意,所以这里没有加注释,如果需要了解,官方SQL文档里写的很清楚请自行查阅。
上面提到,超级表就是一个模板,上面的建表SQL意为:
创建一个表名为“WSD”的超级表,表包含3个字段:
ts(时间戳,TDengine所有表必须包含并放在第一位的字段)
Temp(float类型,温度)
Hum(float类型,湿度)
有了模型之后,就是创建具体的设备,这里我的方案是在代码中根据接收到的物联设备消息的内容拼接SQL,因为设备的种类(即模型)我们是可以预见的,但是具体的设备我们是无法预知的,所以事先创建具体的子表对应具体的设备是不合理的,拼接的SQL示例如下:
insert into WSD001 using WSD tags(11111)(ts, Temp, Hum)values (1670918059000, 26, 30)
SQL的意思是:设备WSD001(表名,模型为WSD,如果不存在这张表,会创建)新增一条数据。
6. 流式计算
在我们的项目场景中,会统计一些累加的数据,比如用电量、用气量等等。物联设备推送的数据往往是某个设备的数据,但是我们可能需要按系统统计多个设备的数据的和。以每小时统计一次中央空调系统的用电量为例,我们需要是将这一个小时内多个电表的最后一次推送的数据求和,因为用电量是累加,也就等于最大值求和,即:用电量 = sum(max(EPI))
在超级表中取max是无法获取到正确的数据的,分别对子表取max在累加又显得很笨,TD提供了一种流式计算的方案来实现这类计算,可以简单理解为MySQL的视图。
在举例之前,需要了解几个概念:
示例SQL
create
stream bpd_epi_s into bpd_epi as
select _WSTART as ts, max(epi) as val, equipId, tbname
from bpd partition by tbname interval (30m) FILL(PREV);
意为:创建一个名为“bpd_epi_s”的流式计算数据放在超级表“bpd_epi”中,存放的是变配电(bpd)系统按照30min为区间取各个设备的最大epi值,存储的数据有_WSTART(窗口开始时间)、max(epi),equipId(设备id)、tbname(子表名称,也即设备编码)。
再说下删除stream,首先要drop stream xx,然后drop stable xxx,剩下的关联超级表的子表会自动删除。
7. java项目中使用
官方文档给出了多个demo,可以自行选择实现方案
https://github.com/taosdata/TDengine

 浙公网安备 33010602011771号
浙公网安备 33010602011771号