
OLAP技术的选择,进化和思考
引言:
企业数字化的进程,由数据库的发展轨迹主导,而数据库本身的演进又受制于硬件的技术瓶颈。简单来说,数据库需要一个强大的计算机来支撑,但单块CPU显然没有这个能力,因此通过网络连接多块CPU、磁盘的分布式技术成为数据库发展的主要推动力,但相关硬件技术的发展速度有所差异,“在多年以前,数据库的硬件瓶颈主要在于磁盘和网络带宽,随着磁盘读写速度和网络带宽的提升,也就是IO不会成为数据库的明显瓶颈。”炎凰数据研发工程师吴立表示,“如今,CPU成为了数据库执行效率上的新的瓶颈。”
专家介绍:
吴立
上海炎凰数据科技有限公司研发工程师,硕士,毕业于上海交通大学,在上海炎凰数据主要负责时序数据库的开发。之前在Splunk工作,主要参与数据采集相关的开发工作。
DataFun社区|出品
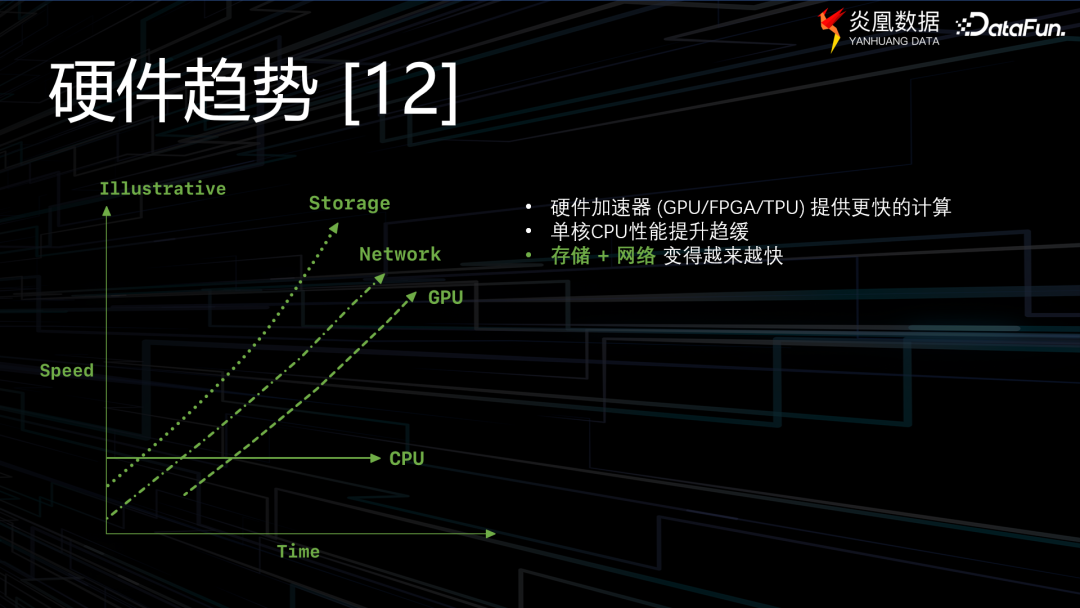
炎凰数据在数据库开发过程中,最重要的原则就是顺应新的场景需求,以及具体的硬件发展现状,进行技术演进决策。
▼01.列存储:数以类聚
炎凰数据在数据库技术演进中有几个关键节点,列存储技术的引入在早期非常关键。
炎凰数据的核心创始团队均来源于全球大数据分析引擎领军企业Splunk,吴立也不例外,“Splunk成立的时间比较早,在大约二十年前,Splunk的产品在业内是非常先进的,但他们实际上采用了行存的存储形式,在当时还是可以解决用户问题的,比如日志索引、搜索等。”
比如在做数据聚合搜索的时候,对于行存,就是同一行数据存在一个数据块或者一个连续的存储空间里面,而列存就是同一列数据存在一个连续的存储空间里面。聚合操作一般只针对某一列数据,也就是某一个字段,比如计算某一列数值的和。数据计算通常是针对同一个字段的数据。有了列存之后,可以一次性把所需数据提取出来,相比之下,如果是行存,则需要不断进行寻址才能找到对应的某列数据,因为它们分散在不同的数据块里面。
行存的逻辑是存储每个实体的多维度信息,而列存则是存储每个维度包含的所有实体的信息。在大数据场景下,列存相比行存有很明显的优势。“此外,列存储的另外一个优势是,由于数据性质相同,列式数据可以很好地做数据压缩,进一步提升效率。”
在具体落地中,通过调研很多产品的优缺点,炎凰数据进一步确认了列式存储的数据格式,“我们调研了很多列存的数据格式,比如Parquet、Avro等,最终,基于内存设计、标准化、语言无关、平铺和层级数据结构支持、硬件感知等方面的优秀特性,认为Arrow是一个非常通用并且可被广泛接受的数据格式。我们在应用中,结合具体的使用场景使数据的处理和交换更加高效。”
这项技术可以给OLAP应用带来很大的体验提升,但吴立在亲身经历中体会到,虽然技术是为产品服务的,但是技术演进随时可能面临风险。因为技术改造终究是很漫长的过程,工程量极大,在真正落地之前并不能100%确定能够应对未来两三年的技术发展要求。“除了列存储,还有比如实时搜索这样的功能,具体落地时,都存在各种各样的难题,包括学习曲线、框架支撑等等。”
列式存储相当于在空间上将查询、分析与计算所需的重要元素进行汇集或提前过滤,这是加速的重要原则。而这些元素的同质性自然能带来另一项计算加速优势,也就是SIMD并行计算,其对列式数据的每一项同时进行相同的运算。
“如果对性能要求很高,SIMD是很自然的选择。我们希望在产品特别是内核执行的各个阶段都能进行优化,并利用好硬件带来的优势。在落地过程中,有一个关键问题是,SIMD对CPU架构的适配性要求很高,每次适应新的CPU架构,都可能面临不支持SIMD指令的情况。我们会选择对SIMD支持更友好的library来对数据结构进行解析,从而实现CPU的适配。比如为了适配ARM的CPU架构,有一些功能组件会采用架构支持的指令集进行编译,使产品在新的架构上能高效运行。
▼02.JIT即时编译:开源的力量
即时编译是一种通用技术,与任何具体执行策略都不关联,从而在编译层面的优化将有很大的自由度。编译优化也是相对于向量化计算的一种典型加速方式,两者各有优劣。
“我们在搜索的过程中发现,在简单的表达式求值场景中,性能没有完全达到期望值。因为炎凰数据打造的是Schema on Read(读时建模)产品,应用中会涉及到大量的数据读取之后在计算层面的过滤。“
Schema on Read也就是读时建模是炎凰数据的产品核心关注点,主要是为了适应当下大数据场景中常见的异构数据分析面临的挑战。
“在搜索过程中还涉及到投影计算,过滤和投影是计算非常重的,如果这两个计算的性能不好,就会影响整个SQL语句执行的效率。“
为此,炎凰数据决定在编译优化层面应用JIT即时编译技术,JIT的主要思想是程序在运行时被编译成代码,不需要提前编译,虽然会牺牲一定的编译速度,但也降低了链接的额外开销。
在SQL查询执行的不同步骤中,执行引擎需要计算表达式,表达式以DAG的形式表示,而JIT编译可以提高表达式在计算时的效率。
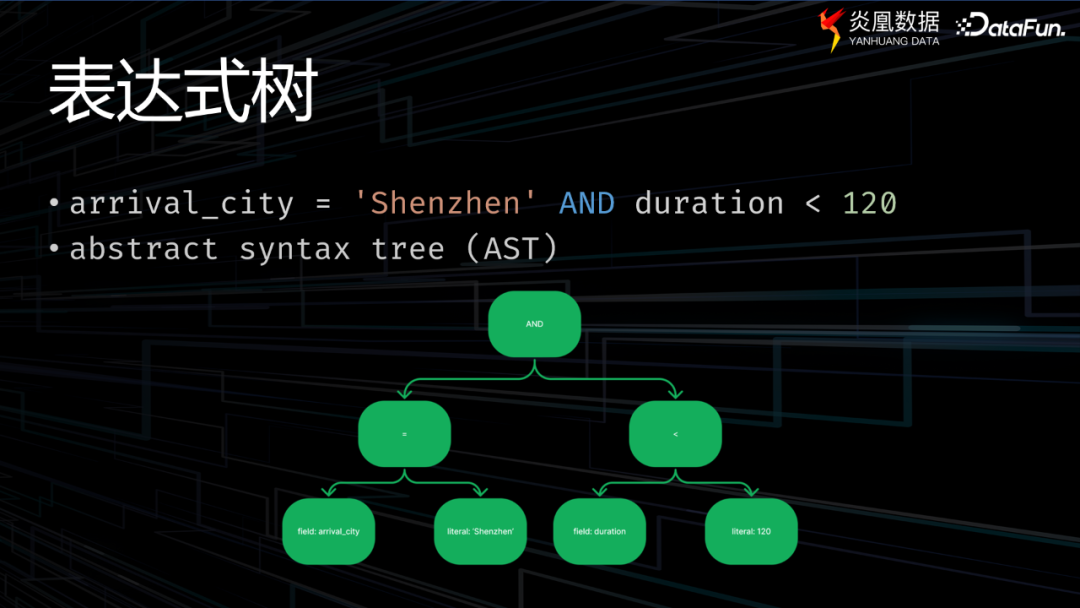
在经过调研和选型之后,炎凰数据发现,正好Arrow也提供了表达式优化的工具——Gandiva,“一方面,Gandiva提供了很多内置的表达式库,同时对投影和过滤计算过程都有良好的支持;另外一方面Gandiva在编译优化表达式的时候有优化,进一步计算的效率。”
但Gandiva并不是一个很完美的产品,为此,炎凰数据在这个工具的基础上,对于不满足特定场景的需求进一步进行完善和补全。“比如想在这个library里面添加一个自定义函数接口的时候,相关的注册机制没有完善,就会遇到问题。通常的做法是把这一部分代码建立一个分支,完善后patch到我们的产品里面。但这种做法带来的后果是,经常会随着项目往前发展,带来一些冲突。”
炎凰数据借用了开源的力量,把这部分代码贡献给Arrow开源项目,再从项目的上流分支做一些改进增强,从而解决了这个问题。
JIT即时编译带来的优势非常明显,大大减少了表达式计算在过滤和投影阶段的时间,使得用户查询特别是在涉及大量表达式的时候变得更快。

在具体开发中,炎凰数据实现了很多改造,包括数据类型、高阶函数等方面的支持,以及缓存复用、外部函数注册等机制,这些成果全部贡献给了Arrow项目。
▼03.push mode:改头换面
数据库的性能优化点不仅在于硬件层面的适配,也在于软件架构中的参与方,也就是数据何时被消费。如果是用户主动,则在用户有消费需求的时候从系统拉取数据进行处理,这被称为pull mode;如果是供应方主动,则不需要关心用户消费时间点,可以提前提取数据、处理数据,把数据以推送的形式提供给用户,这被称为push mode。
pull mode和push mode之间没有说哪个更好,需要结合具体场景来比较。pull mode在查询引擎中是一个很经典的模式,接口简单,从而可以很容易地扩展新功能。但是对于push mode,其技术复杂性更高,不过在新场景支持和效率提升特别是流式数据处理、缓存效率等方面,push mode更加有优势。
”为了实现技术改造,炎凰数据把pull mode相关的所有执行引擎的算子都替换成了push mode的算子,在整个项目中做了大量的脏活累活。“push mode带来了进一步的查询性能提升,“收益非常明显,虽然程度不一,但对查询的提升基本是全面的。”
全方位提升的结果凝聚炎凰数据整个团队的努力,团队也踩了不少坑,“整体模式切换是比较痛苦的过程,因为要去协调整个整个团队的资源,不能影响正常产品功能的发布,也要考虑用户的新需求,同时让用户在老的引擎和新的引擎里面都能够工作。比如有些issue是在产品发布之后才发现的,这就提醒我们在工程排期上多留一些buffer,从而提高容错率。”
▼04.产品追求:始终如一
列式存储、JIT即时编译以及push mode,一系列的技术优化,最终都是为了用户查询体验的提升,极致的产品追求,反映的是炎凰数据成熟的产品思维,“从终端用户的角度来看,他们不会关心技术具体是怎么做的,只关心查询结果是否能够尽快提供,特别是在大数据量的情况下,这是我们所有产品的落脚点。”
炎凰数据的核心优势在于异构数据的处理,从数据的采集到存储、搜索、可视化都能够有非常好的体验。在产品开发的关键节点也就是核心引擎研发中,炎凰数据始终关注技术发展趋势以及技术生态的支持,并坚持一个原则,“我们在开发的过程中,不同的阶段要给到用户一个相对完整的产品体验,同时也不损耗我们对产品的长远规划。”
炎凰数据当下的技术演进和产品更新的选择,顺应了OLAP技术不断趋同、走向标准化,以及数据平台一体化的趋势。在这个背景下,炎凰数据对竞争优势的理解有着自己的执着,“我们始终如一的追求,都在于对异构化的数据更高效的处理,以及为用户在从采集到可视化的各个层面提供给更好的体验,存储要保证安全,分析要保证快速,可视化要满足分析的需求。只要在各个层面都做的足够优秀,当作为一个一体化产品呈现给用户的时候,它才能够在业内占据一席之地。”
- End -
访谈人:吴立 上海炎凰数据科技有限公司研发工程师
与谈人:刘晓坤 DataFun
编辑:刘晓坤 DataFun

 浙公网安备 33010602011771号
浙公网安备 33010602011771号