
翟佳:高可用、强一致、低延迟——BookKeeper的存储实现
分享嘉宾:翟佳 StreamNative 联合创始人
编辑整理:张晓伟 美团点评
出品平台:DataFunTalk
导读:多数读者们了解BookKeeper是通过Pulsar,实际上BookKeeper在数据库和存储场景都有着非常广泛的应用。BookKeeper是Pulsar的底层存储,Pulsar有着广泛数据入口,Pulsar跟Kafka及各类MQ(RabbitMQ、ACTIVEMQ)的较大区别是Pulsar是统一的云原生消息流平台,不但是分布式系统,而且做了存算分离,可以让用户在云的环境下,体验到云原生的优势,例如随意扩缩容、数据灵活迁移复制等。希望通过本文,让大家对Pulsar底层的BookKeeper有更深入的了解。
今天的介绍会围绕下面四点展开:
- BookKeeper的简介
- BookKeeper的特性
- BookKeeper存储介质的演进
- BookKeeper的社区资源
--
01 BookKeeper的简介
1. 业务场景需求的统一
Pulsar里有很重要的概念是“统一”,这个统一的特性是由BookKeeper支持实现的。这里的统一是指需求的统一,在消息场景下,用户场景分两类:
第一类是线上业务场景,例如1984年诞生的IBM MQ到现在的各类开源MQ解决的是线上业务场景,这些MQ的服务质量会对业务服务质量有着直接的影响,所以这类需求对数据质量,例如对数据持久性、数据延迟、消费模型的灵活性有较强的要求。
第二类是大数据场景,例如2010年左右随着实时计算的广泛使用,Kafka的这种高带宽和高吞吐使用需求。
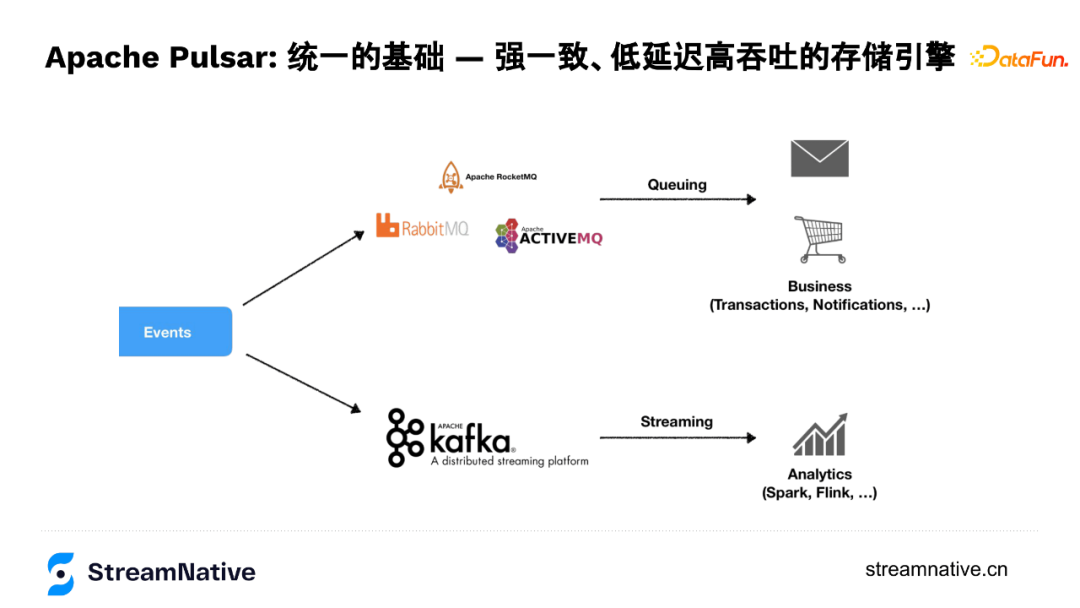
由于面向场景不同、技术栈不同,这两种场景在业务上又同时存在,给业务带来不同的基础设施API、不同的使用方式、不同系统的运维成本等问题。所以Pulsar针对这些问题,做了两层API的统一:既兼容MQ的并发消费模型,提供比较好的服务质量,同时通过底层存储层抽象,可以提供很高的吞吐和带宽,这就是我们要介绍的Apache BookKeeper项目。
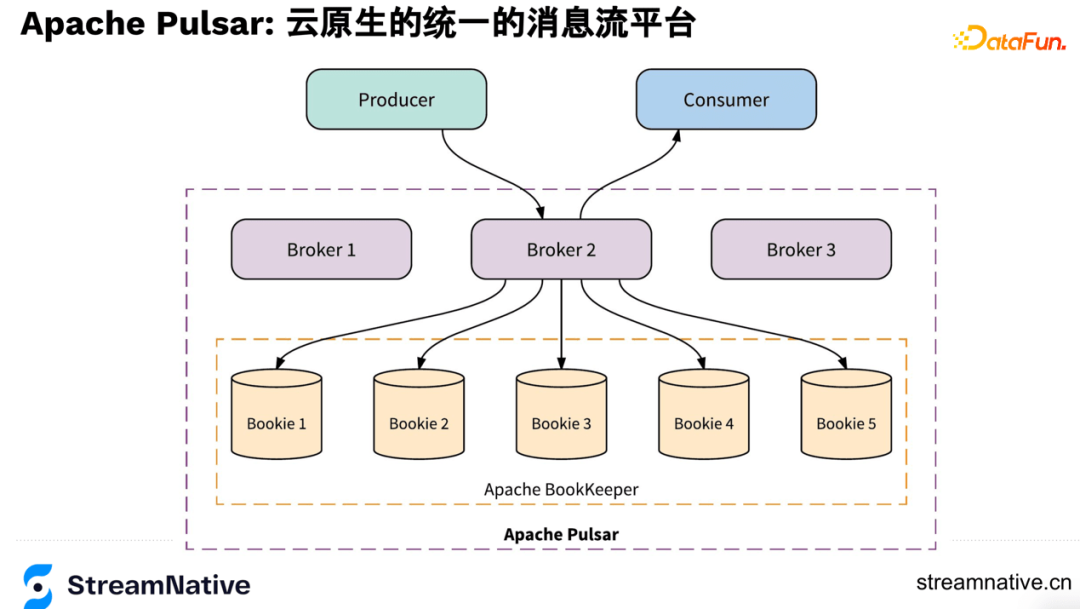
2. Apache BookKeeper简介
很多服务里都有日志,例如MySQL的binlog和HDFS的namenode的editlog,都是对日志的一个抽象,而BookKeeper就是把这个抽象变成了一个分布式的服务,摆脱了对单机容量瓶颈的限制,把日志变成了可无限扩展的服务。BookKeeper使用packet source协议和ZooKeeper的zap协议,通过log append only的方式实现了低延迟和高吞吐。在APCP里选择CP,而availability是通过多副本并发的方式提供高可用,BookKeeper有着低延迟、高吞吐、持久化、数据的强一致性、服务的高可用、单节点可以存储很多日志、IO隔离等优势,针对这些特性在后文会展开介绍。
3. BookKeeper的诞生
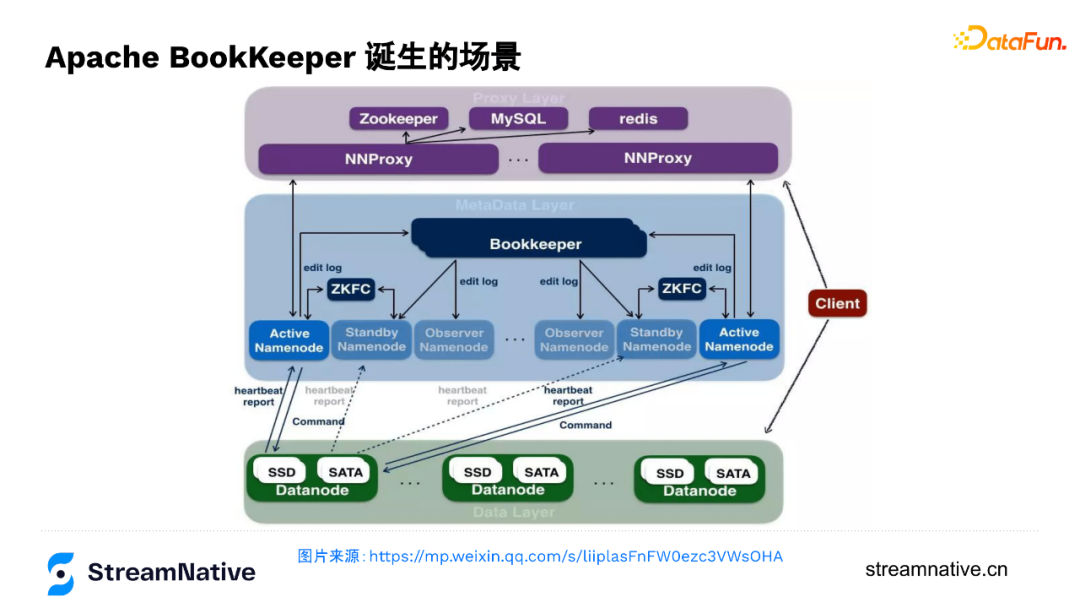
BookKeeper也是Apache的一个项目,同样是由雅虎捐献诞生,原本是为了应对雅虎开源HDFS里元数据存储的需求。
下图是字节跳动技术文章的一个图,主要是呈现在字节跳动如何用BookKeeper支撑元数据服务,支撑起EB级别的HDFS集群。这个集群DN有好几万台,需要很多NameNode,就需要一个可以保障active/standby/observer NameNode之间强一致性的日志服务,单机容量瓶颈下很难支撑这么大的体量时,引入了一个分布式的日志服务,这就是BookKeeper诞生的场景。随着HDFS大规模的问题开始出现之后,BookKeeper成为了HDFS在HA上的刚需需求,例如在EMC内部的HDFS集群,也是用的BookKeeper来做NameNode的editlog服务。BookKeeper是一种分布式场景下很常见的复制状态机的实现(通过复制log,保持各个节点状态机的同步,A节点持久化log后,把log同步到B节点,在B节点进行log的一个重放,让B节点达到跟A节点一样的一个状态)。由于在HDFS场景中,保存的只是NN的变更日志,所以算是元数据的元数据,对数据一致性、对吞吐、对时延的要求自然极高。
4. BookKeeper使用案例
BookKeeper也有局限性,是append only的一个抽象变成了分布式服务,相对而言比较底层。所以用户多是一些比较大的互联网公司或其他有大数据量的需求的用户,这些用户会在BookKeeper之上做一些二次开发,例如Pulsar在BookKeeper之上做了一层broker服务,对BookKeeper的每个分片做一些管理然后将其作为数据的存储服务。
类似的还有Twitter和Salesforce。Twitter的技术栈是构建在实时计算上的,在Twitter内部,BookKeeper是作为很重要的基础设施,不但有类似Pulsar的服务eventbus,还有其他使用场景例如搜索、广告、Stream computing, 以及作为类似KV存储的Manhattan Database的元数据服务,这些场景都用到了BookKeeper。在规模上,Twitter BookKeeper有两个集群,每个集群约有1500个节点,每天有17PB的数据,每秒1.5万亿的records。而在Salesforce的使用背景,是Salesforce想去掉对Oracle的依赖,所以自研了类似Amazon Aurora的NewSQL Database,其内部很多跟元数据相关或有一致性要求的服务都是通过BookKeeper来满足的,并且也有部分后端场景将BookKeeper作为存储服务去用。
--
02 BookKeeper的特性
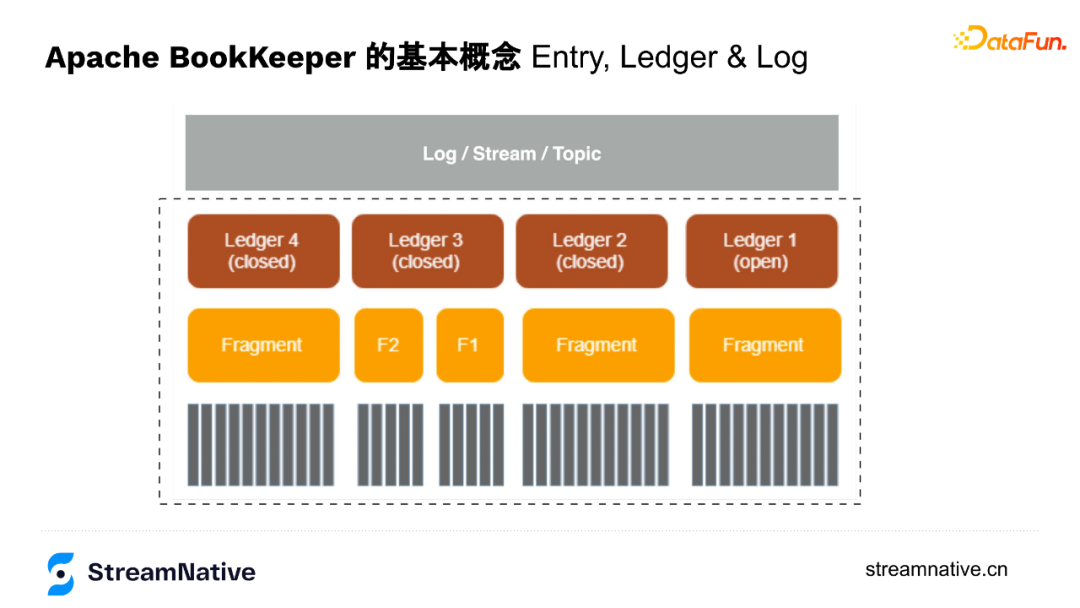
1. BookKeeper基本概念
- Ledger
可以理解为BookKeeper是会计,Ledger是账本,每个账本是记录信息的一个单元,写完之后转为closed状态(只读),最新的账本是打开状态(openLedger),以append only的方式持续存储数据。
- Fragment
可以理解为BookKeeper内部维护的一个以append only的方式添加的数据组。
Fragment之下就是用户以append only的方式追加的一条条数据。
2. BookKeeper的节点对等架构
openLedger时有3个参数:Ensemble选择几个节点存储这个账本,Write Quorum控制数据写几个副本(并发写,不同于Kafka或HDFS,BookKeeper没有数据节点之间主从同步的关系,把数据同步的协调者从服务端移到了客户端),Ack Quorum控制等几个副本返回ack。
以下图为例openLedger(5,3,2),在保存这个账本时,选择了5个节点,但是只写3个副本,等2个副本来返回ack。第一个参数一般可用于调整并发度,因为写3个副本是通过轮转的方式写入,例如第1个record是写1-3节点,第2个record写2-4节点,第3个record写3-5节点,第4个record写4-5和1节点这样轮转。这种方式即便3个副本,也可以把5个节点都用起来。
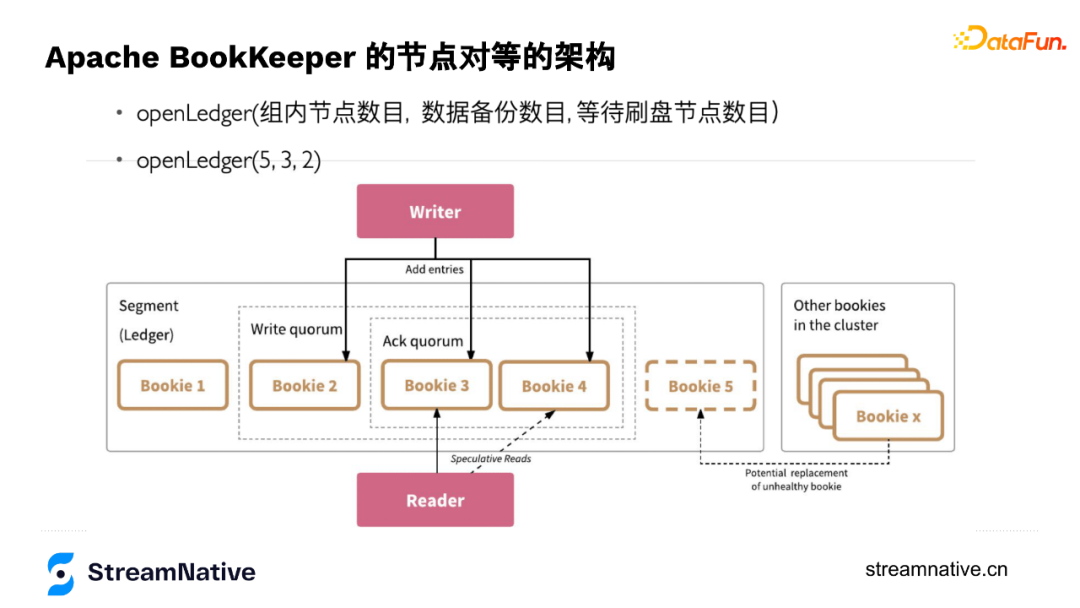
这几个参数便捷的特性可让用户通过机架感知、机房感知、resource感知等各种方式进行灵活设置。当选好节点后节点之间的排序就已完成,每个record会带个index,index和节点已有绑定关系,例如index为1的,都放在123上,为2的都放在234上。通过这种方式可以让我们知道每个节点存了哪些消息,当某个节点宕机,根据这个节点的位置信息,把对应record还在哪些节点上有副本的信息找出来进行多对多的恢复。这么做的另一个好处是不用再维护元数据信息,只需要有每个节点记录index信息,在openLedger时记录好每个节点的顺序即可。
openLedger(5,3,2)数据存储结构就是下图中右边的结构,如果选择Ensemble=3,Write Quorum=3,数据存储结构就是下图左边的结构:

综上,用户可以通过Ensemble来调整读写带宽,通过Write Quorum调整强一致性的控制,通过Ack Quorum权衡在有较多副本时也可以有较低的长尾时延(但一致性就可能有一定的损失)。
3. BookKeeper可用性
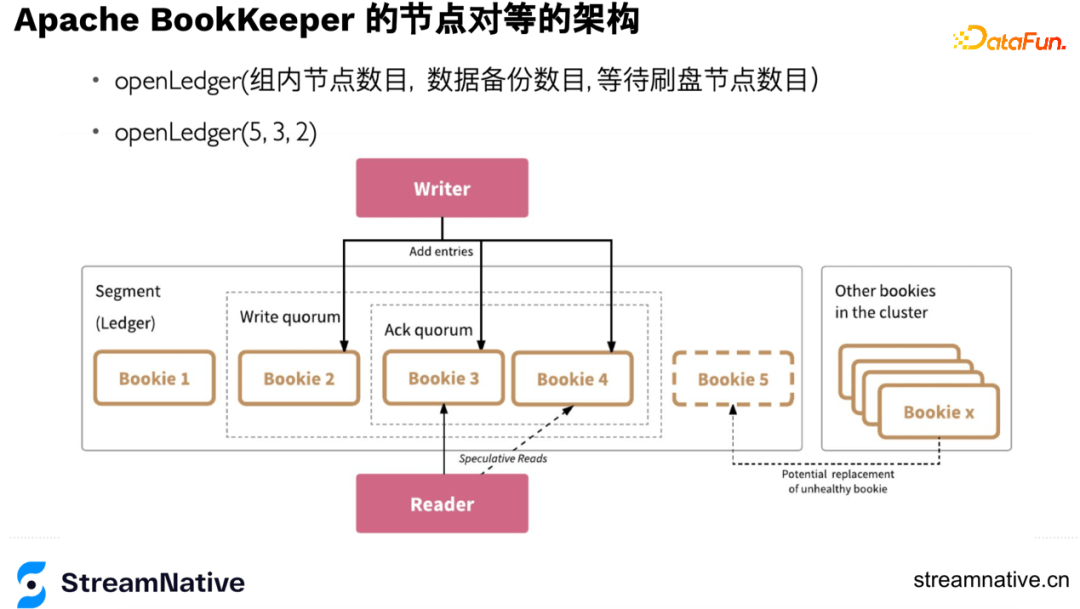
- 读的高可用
读的访问是对等的,任意一个节点返回就算读成功。这个特性可以把延迟固定在一个阈值内,当遇到网络抖动或坏节点,通过延迟的参数避障。例如读的延迟时间2ms,读节点3超过2ms,就会并发地读节点4,任意一个节点返回就算读成功,如下图Reader部分。
- 写的高可用
在openLedger时会记录每个节点的顺序,假如写到5节点宕机,会做一次元数据的变更,从这个时间开始,先进行数据恢复,同时新的index中会把5节点变为6节点,如下图x节点替换5节点:
4. BookKeeper一致性
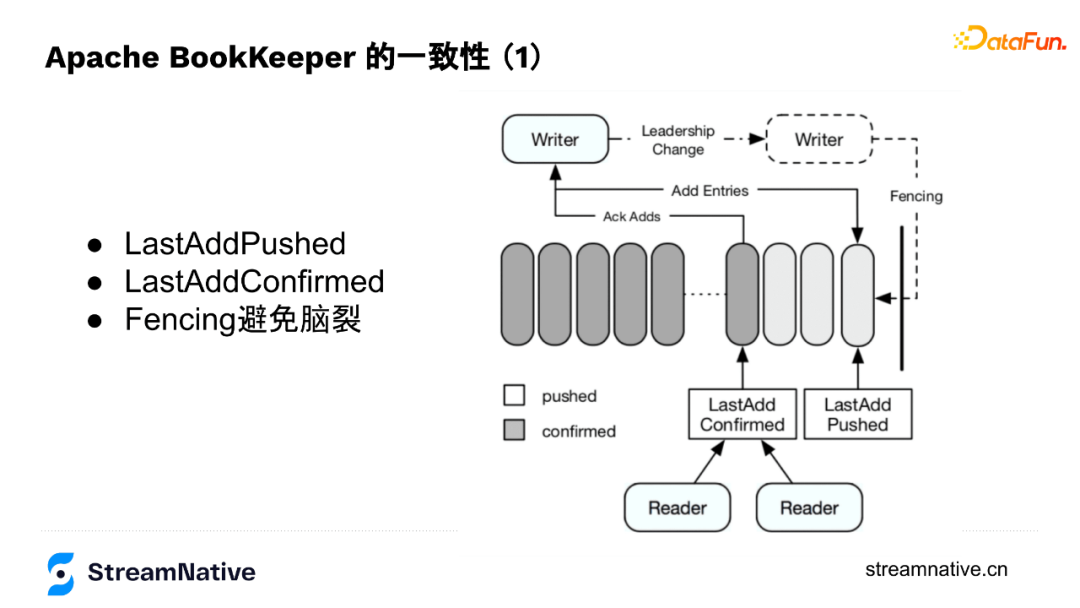
BookKeeper底层节点对等设计让写入数据的Writer成为了协调者,Writer来保存数据是否存储成功的状态,例如节点是否出现问题、副本够不够、切换Fragment时要不要做数据恢复、在写入过程中出现宕机时,通过fencing的方式防止脑裂等。所以,Writer维护了2个index:LastAddPushed和LastAddConfirmed。
LastAddPushed会随消息ID递增,LastAddConfirmed则记录最后一个连续的消息成功写入了(例如Ack Quorum为2,有2个成功返回了即为成功),但因为返回顺序不一定与消息顺序一致,例如123个消息,3的消息先返回了,2的还未返回,按连续的规则就是2不是3。
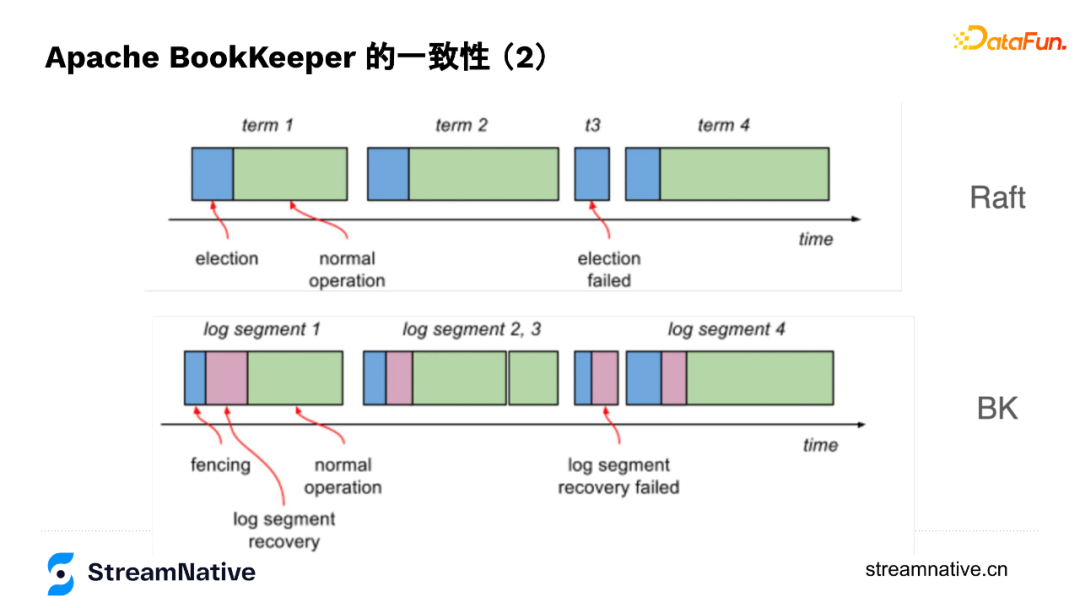
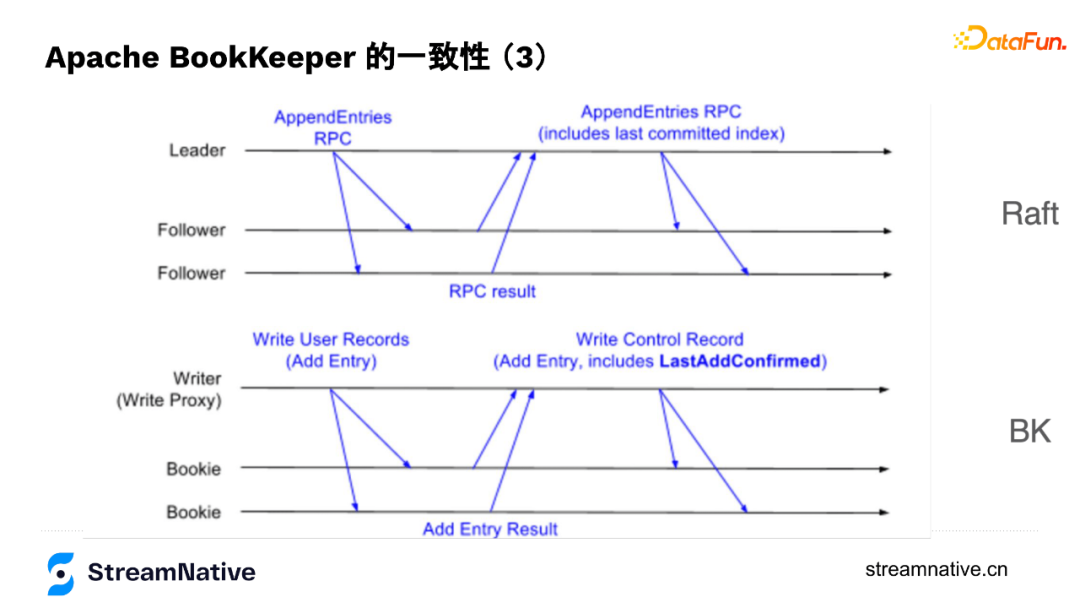
5. BookKeeper与Raft的对比
在底层原理上,Raft与BookKeeper有很多类似的地方,Raft每个数据写入的组织形式是term,跟BookKeeper的segment类似,每个term也会选择一组节点存储数据,然后不断往后追加数据,通过数据节点之间的协同保证数据一致性。
在数据结构上,Raft在保存数据时有Entry,Entry除了带本身的index还会带上last committed index,与BookKeeper中的LastAddConfirmed较为类似,只是BK是通过Writer来协调数据在不同节点的一致性,Raft有leader来协调数据在不同节点的一致性。
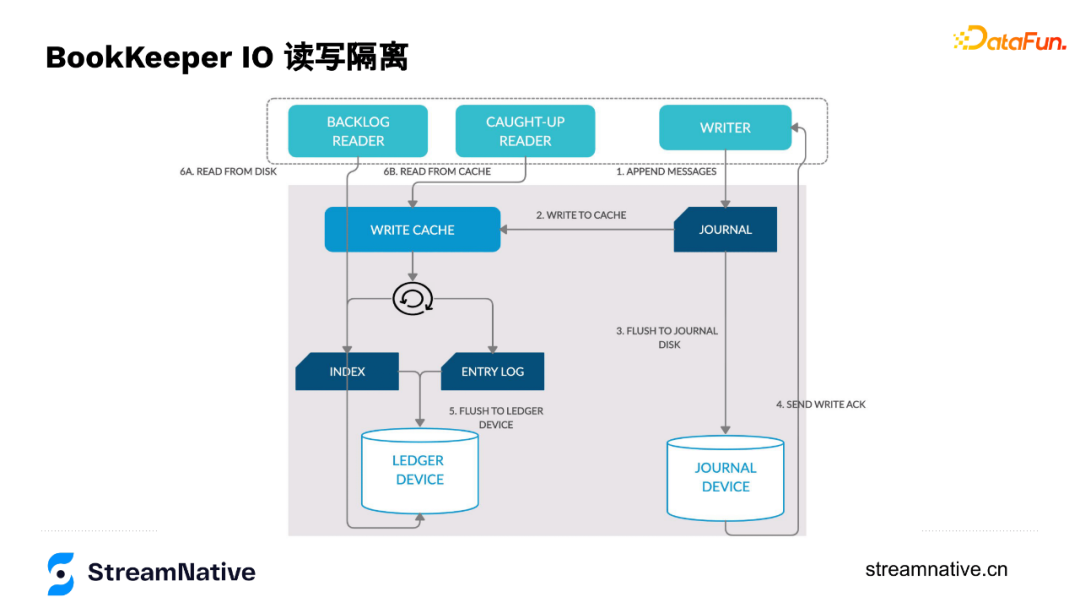
6. BookKeeper的IO读写分离
下图是每个数据节点的数据流转过程,数据写入时,Writer通过append only方式写入到Journal,Journal在把数据写到内存的同时会按一定频率(默认1ms或500 byte)把数据持久化到Journal Device里,写完后会告诉Writer这个节点写入成功了(持久化到磁盘是默认配置)。
Journal在数据写入时有写到内存中,接下来在内存中做排序(用于解决如果按写的顺序读会导致分区随机性强的问题),然后把数据刷到数据盘中。读的时候,如果读最新的数据,可以直接从内存里返回,如果读历史数据,也只去读数据盘,不会对Journal Device写入有影响。这样针对有读瓶颈或写瓶颈的用户,可以把Journal Disk或Ledger Disk换成SSD盘,提升性能,并且防止读写的互相干扰。
--
03 BookKeeper的存储介质演变
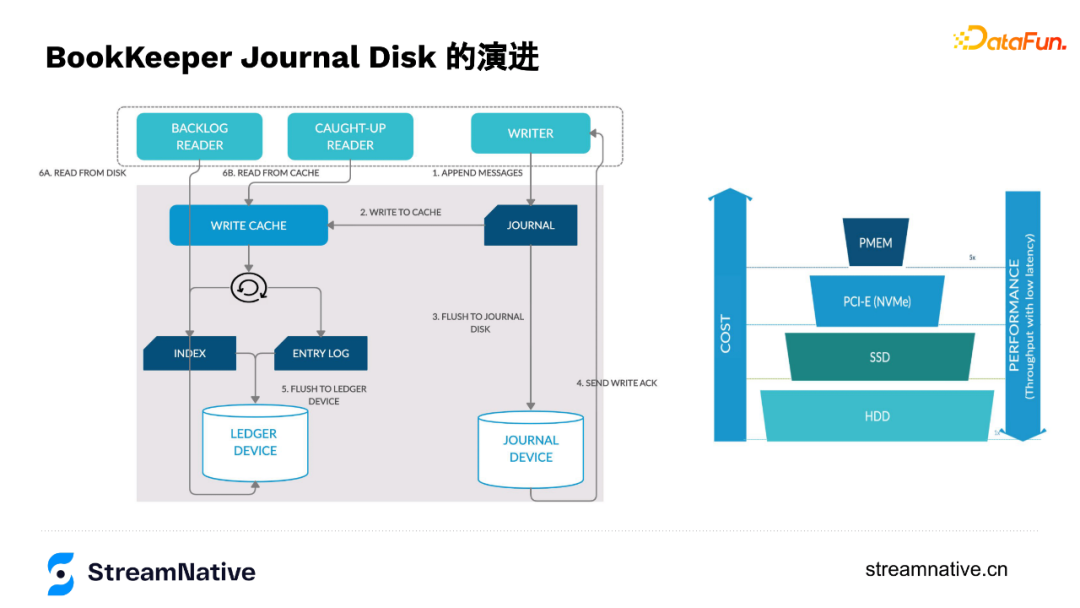
1. BookKeeper的Disk演进
在演进过程中,因为顺序读的情况比较多,所以读的部分变化不大,但在写的这部分经历了HDD到SSD再到NVMe SSD,再到现在部分用户换成了Intel的PMem的过程(如下图所示)。在换到NVMe SSD时,部分用户通过多目录的方式可以把SSD的IO带宽打的很满。
2. PMEM在BookKeeper上的应用
PMem的特性非常匹配Journal Disk,单块PMem可以达到3-4GB的带宽,不但能提供高带宽吞吐而且可持久化。PMem容量相比SSD比较小、相比内存又比较大,在刚推出时单条128GB,有着GB级别的吞吐和ns级别的延迟。
高吞吐低容量的PMem非常适合Journal持久话刷盘的需求,例如宕机后,需要对没刷到磁盘的这部分数据做恢复,需要Journal做replay log重放,由于只是增量日志而非全量数据,所以并不需要很大的容量,正好和PMem容量不大相匹配。而且,PMem的寿命会比SSD的寿命长一些,例如在每天同样写入量下SSD可能只能用1年而PMem预计可以使用4-5年。
雅虎(现在是Verizon Media)有实际通过PMEem优化BookKeeper的案例,在只增加5%的单机成本情况下提升了5倍的带宽吞吐和低于5ms的时延保障(BookKeeper社区与Intel正在合作做性能测试,预计未来会产出白皮书说明)。
在雅虎案例中用10台Pulsar(底层是用PMem做Journal Disk的BookKeeper)替换了33台Kafka,比原Kafka方案成本降低了一半,产出的对比结果如下:

--
04 社区资源
- 团队构成
由Apache Pulsar核心研发团队创立,同时有Apache Pulsar和Apache BookKeeper项目管理委员会(PMC)主席,有6名Apache Pulsar PMC成员和3名Apache BookKeeper PMC成员,有约20名 Apache Committer。
- 里程碑
公司成立于2019年,2020年发布商业化产品StreamNative Cloud,目前有50+付费客户,覆盖金融、IoT、互联网、制造多个行业。
- 优势
是社区和代码的构建维护者,有全球最专业的Pulsar设计开发、运维、管理团队的7*24小时服务,提供开箱即用的云服务和咨询培训服务。

今天的分享就到这里,谢谢大家。
分享嘉宾:

本文首发于微信公众号“DataFunTalk”。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号