李呈祥:bilibili在湖仓一体查询加速上的实践与探索

导读: 本文主要介绍哔哩哔哩在数据湖与数据仓库一体架构下,探索查询加速以及索引增强的一些实践。主要内容包括:
- 什么是湖仓一体架构
- 哔哩哔哩目前的湖仓一体架构
- 湖仓一体架构下,数据的排序组织优化
- 湖仓一体架构下,索引增强与优化的实践探索
--
01 什么是湖仓一体
当我们讲湖仓一体时,涉及到数据湖和数据仓库两个概念。
什么是数据湖?通常来说,它有以下几个特点:
- 有一个统一的存储系统,所有的数据都放到这个统一的存储系统里,没有数据孤岛。
- 支持任意数据类型,比较自由,包括结构化、半结构化和非结构化的数据。这些不同类型的数据都可以统一放到存储系统里。
- 对于多个计算引擎是开放的,包括实时、离线的分析等,计算引擎很丰富。
- 有比较灵活的数据处理接口。有基于SQL这种级别的数据处理,也可以像基于Spark,提供更底层的,基于Dataset甚至RDD这种层面的,更甚者对于机器学习一些场景去对数据进行解析。也可以直接用文件系统,通过API直接读取文件。
- 因其灵活性,数据质量相对较低,比较难管理。
因此,基于数据湖的灵活与易用,它非常适合用于基于未知数据的探索与创新。
什么是数据仓库?它有以下几个特性:
- 强格式(schema),事前对数据进行建模
- 有封闭的数据格式与存储,不对其他引擎开放
- 查询效率高:存储与计算的紧密结合优化,丰富的索引/预计算等支持
- 数据入仓,无论是实时的还是离线的,或者说数据的存储组织由数仓内部而非写入任务决定
- 数据质量高,容易运维管理,建设成本高
因此,高效和可靠的特性使得数据仓库非常适用于基于已知数据的分析与决策。
哔哩哔哩和大部分互联网公司一样,之前的大数据平台都是基于开源的Hadoop生态系统。存储用的是HDFS,计算引擎则有Hive,Spark以及Presto等。在我看来,这是一个比较典型的数据湖的架构。但是,我们也有很多交互分析的需求,为了解决这些需求,我们会引入特定的分布式数仓,引擎使用的是ClickHouse。
这样就会引入新的问题。
比如,针对某个数据产品或者数据服务,为了对其提供比较好的查询效率和性能,需要先把数据从HDFS入仓到ClickHouse,使得整个的流程变长。其次,会带来数据冗余的问题,因为数据在HDFS上有一份,在ClickHouse上也有一份。第三,在入仓过程中,可能会对数据做一些操作,使得数据发生变化,导致很难与HFDS里的其他数据进行关联,导致数据孤岛出现。这两年,像Iceberg,Hudi以及Delta Lake这种数据湖的存储格式也逐渐被很多公司引入去解决上述问题。对我们来说,我们主要使用的是Iceberg这种引擎去解决数据湖和数据仓库之间存在gap的问题。
在我们看来,湖仓一体的目标有三个:
第一,希望它还是像数据湖一样灵活。主要是我们还是用统一的HDFS存储,和之前的SQL on Hadoop生态系统无缝兼容,包括基于Spark或者Flink ETL数据接入,SQL/ML/DataSet等各层次API访问以及Presto/Spark/Hive等多种计算引擎的支持。
第二,希望它像数据仓库一样高效。针对于写成Iceberg格式的表,我们希望它能够做到或者接近于专用的分布式数仓的高效查询效率,包括数据分布组织、索引、预计算、计算存储一体化/缓存等整体的增强和优化。像Iceberg本身提供了粗粒度这种事务的能力,使得我们能够拥有支持更多的变化读写,实时进实时出仓的额外能力。
第三,希望它能像风一样自由,这个是对用户而言,希望可以做到智能化,用户的使用门槛更低,易用性更高。之前,用户想要使其ETL结果的数据分析查询效率更高的话,需要关注很多方面,比如写出的数据是不是小文件会非常多,ETL里的SQL逻辑怎么写使得写出去的数据怎样排序,是否需要做预计算等,并且这些方面和用户的业务逻辑没有关系。
用户想追求比较高的查询效率,这些在原来的方案中,用户需要考虑这些事情,也就是说,用户需要自己变成一个大数据专家才能解决这些问题,并且还要自己去开发,有额外的ETL任务,因此,对用户的门槛就比较高。第二步,它需要做到更自动化。对用户来说,只需要考虑常用的过滤字段,聚合维度和统计项等是哪些。后台的这种自动服务可以帮助解决数据的组织、排序等问题。第三阶段,希望能做到智能化。用户只需要关注表里有哪些字段,算什么类型等业务信息。后面的这些数据的组织,索引的构建以及预计算等全部都能被自动化。用户不需要关心这些,只需关注基于某张表,怎么写SQL表达业务逻辑就行。

--
02 湖仓一体架构
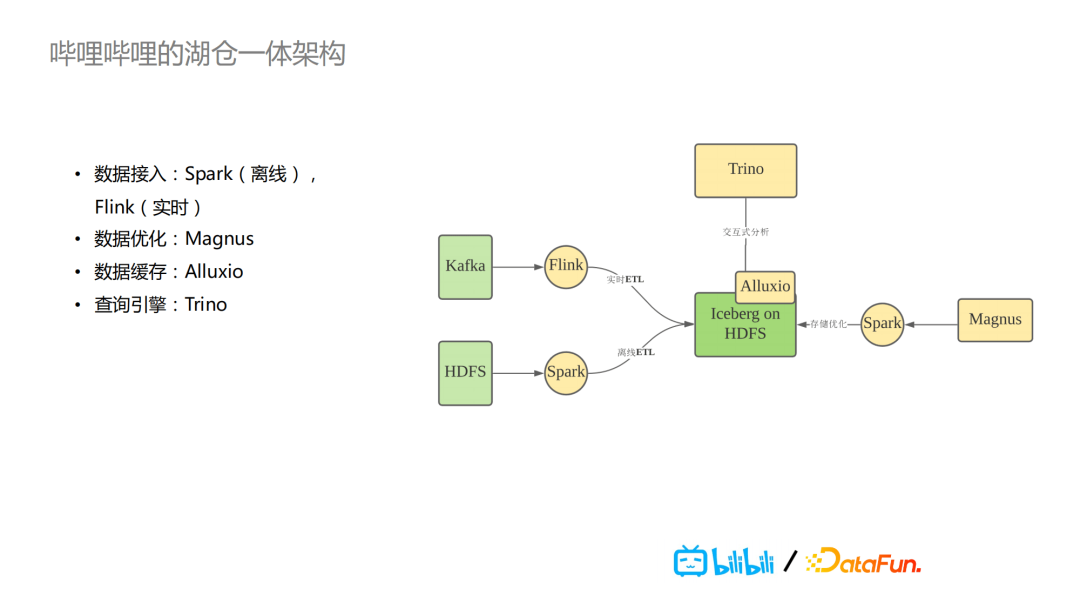
在哔哩哔哩,湖仓一体架构的核心是Iceberg,这是我们在Hudi,Delta Lake以及Iceberg这三个中进行选择的最终结果。整个的数据处理流程架构大概是这样的:实时的数据在Kafka里,通过Flink实施ETL,将数据以Iceberg格式写到HDFS,离线的数据则通过Spark写入HDFS。对于用户来说,数据写到Iceberg时,我们的后台有一个自研的Magnus服务,会针对数据落地到HDFS上的Iceberg表进行持续的整体的组织优化。具体如何进行优化,会在下一个部分详细介绍,主要是运用Spark任务。
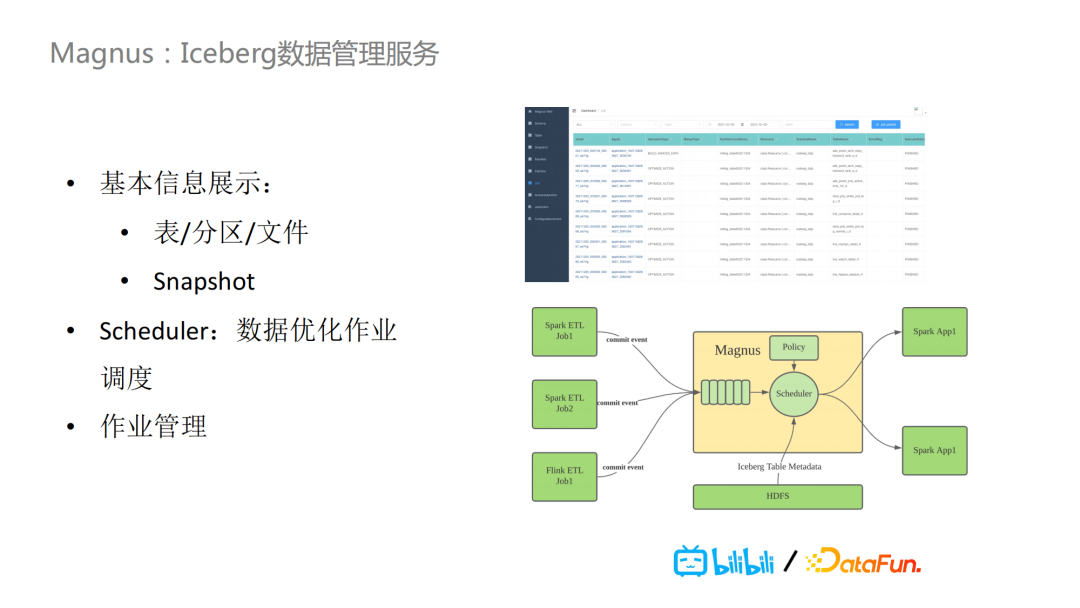
在分析端,我们用的是Trino做查询引擎,它是PrestoSQL改名后的称呼。同时,我们还用了Alluxio,因为Iceberg里元数据以及索引数据相较于原始数据来说,数据量都比较小,所以我们将其缓存到Alluxio,方便缓存加速。Magnus则是我们基于湖仓一体核心Iceberg的数据管理服务。它主要的任务是对于Iceberg数据做优化和管理,包括基本信息的展示,比如表/分区/文件以及Snapshot等。在其内部还有一个scheduler,用于数据优化作业的调度。无论是离线的批任务,还是实时的任务,把数据写到Iceberg的表里的时候,都会把这些commit event发送到Magnus,里面会有一个队列,scheduler会根据制定的特定policy去消费队列,去决定对哪些Iceberg表做相应工作,拉起对应的Spark任务做具体事情。
之前,基于Iceberg,Hudi或者Delta Lake的湖仓一体架构,大家比较关注或者说应用场景比较多的就是实时数仓。因为它们的对于粗粒度的事务的支持,去解决提供(近)实时数仓的能力。对于我们来说,除了一些比较重要的,比较独立的数据产品服务我们会放到专门的像ClickHouse这样的分布式数仓里去做删除和查询。实际上,我们在数仓建设过程中,还是有大量的业务场景还是基于之前的Hadoop的数据湖的架构上,我们数仓开发部门的同学基于这种数据湖架构去做数仓的建设,比如从ods到dwd等不同的分层建模。实际上,大部分数仓建模工作,其数据还是写到HFDS上,然后应用Presto或者Spark去做分析。
在这种场景之下,我们湖仓一体架构的目标是如何加速查询性能,使其效率可以达到或者接近专门的分布式数仓那样。我们分析里开源的湖仓一体方案以及分布式数仓的性能Gap,这就涉及到Runtime引擎、存储以及预计算等性能方面上的比较,这里面涉及到的性能相关的因素非常多。本文主要分享在存储里的排序组织以及索引上的一些探索和实践。为什么选择这两个因素,主要是我们的调研结果认为它们是开源的湖仓一体方案与分布式数仓的性能gap里最明显的部分。

--
03 数据的排序组织
首先,我们来看数据的排序组织。
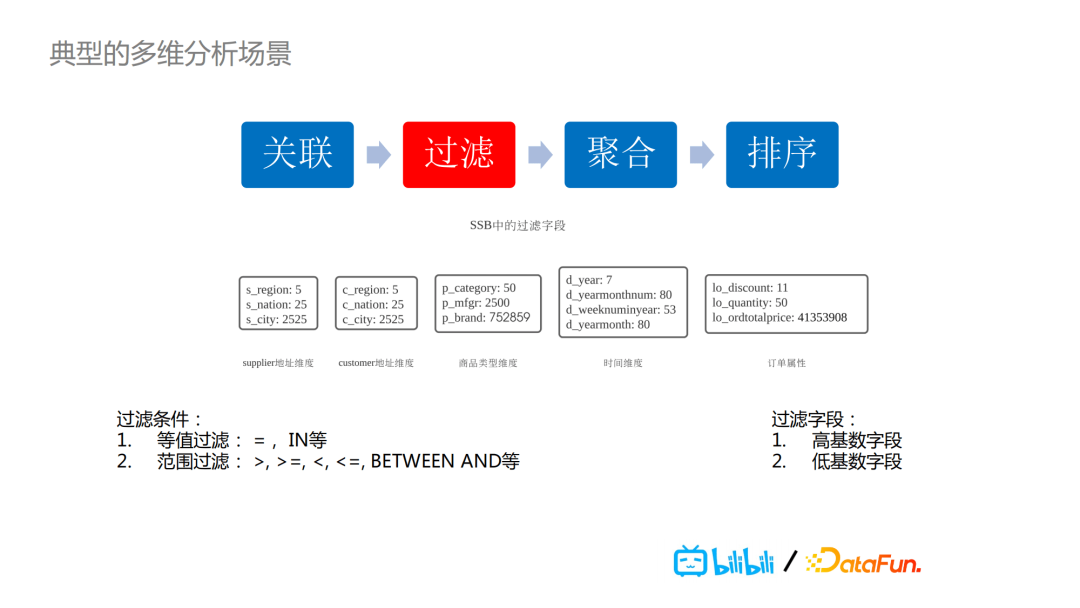
说到典型的数据分析场景,我们这次做的分享是基于star schema 作为一个benchmark的多维分析场景,整个数据模型就是一个事实表外加多个维度表,查询的模式也是比较固定的。先关联,再过滤,接着聚合,最后对结果做排序。其中的过滤条件可以是等值过滤也可能是范围过滤,而过滤字段可以是高基数字段也可能是低基数字段。
因此,在这种典型的多维分析场景下,也是我们实际业务中会经常遇到的问题是:我们如何在各种类型字段及各种过滤条件下,执行查询时只读取需要的数据,而不是做全表的扫描?这里有两个比较关键的点,通过数据的组织外加索引,使得我们只查询读取SQL逻辑上所需要的那部分数据。

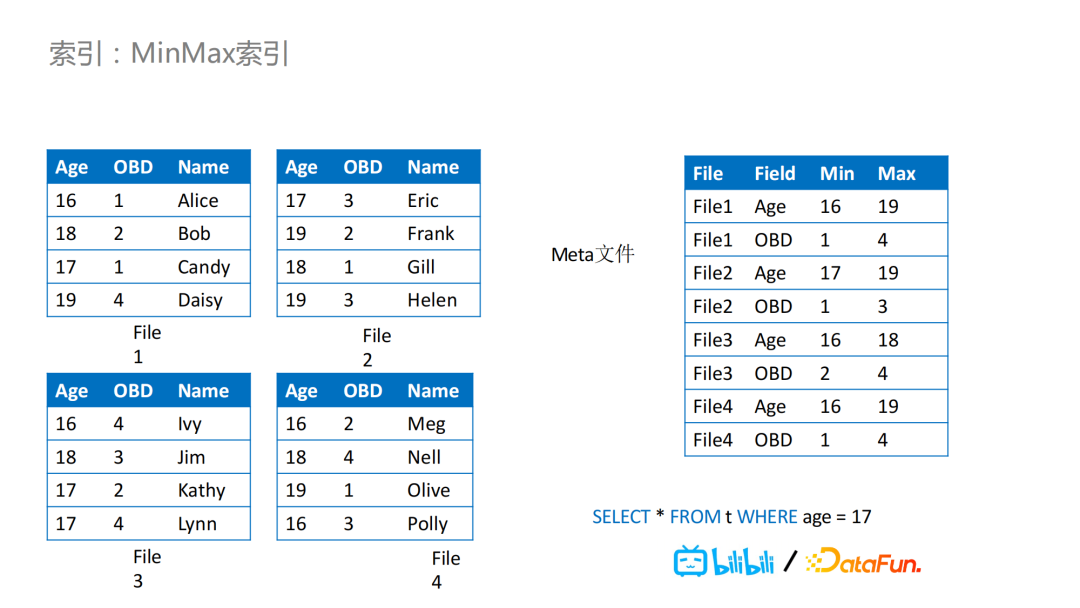
就索引来说,比如Iceberg,它已经默认提供文件级别的MinMax索引,在Meta文件里,它会记录每列的Min和Max值。
举个例子,我们有四个文件,在Meta文件里就会记录相应的Max和Min值,那么对于下图的查询案例,我们可以通过age=17对文件进行过滤,按照age对数据文件之间的数据进行排序,那么在这个查询中,读取时的过滤效果会非常好,可以不用读取其中的三个文件,因为通过Iceberg的Meta文件,可以判断出来我们只需要读取文件2,提高了查询效率。
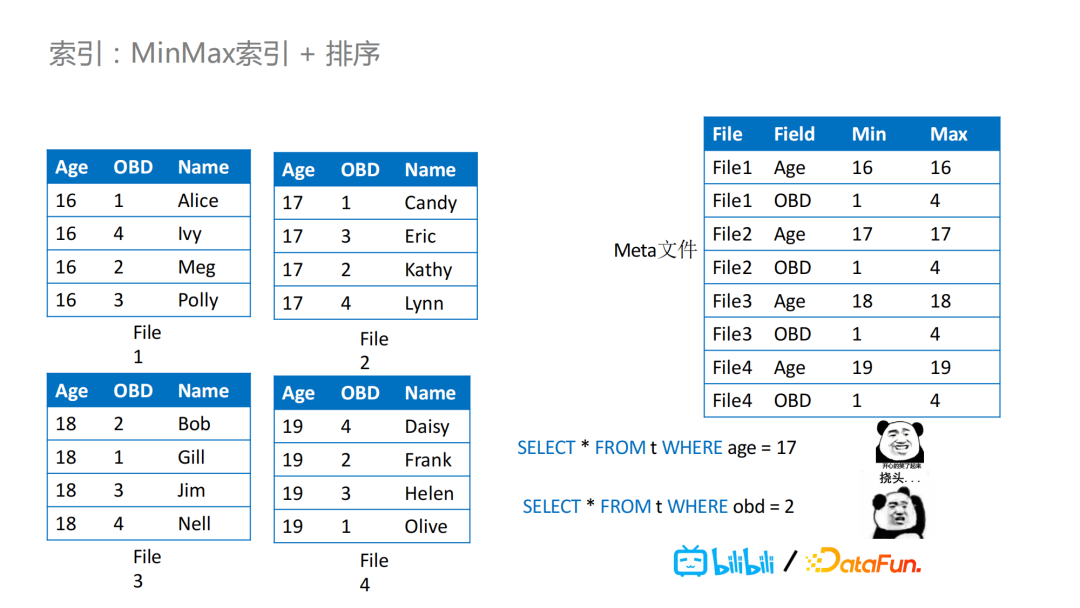
但是,我们做好排序之后,比如说我们另外有一个查询,需要根据obd这个字段去做过滤,这时候就会产生问题。通常,用户的查询里过滤的字段不止一个,我们在做排序设定的时候,当全局依次用a,b,c三个字段做排序,对a的数据聚集性是最好的,越往后的字段聚集性越不好。如果字段a的基数比较高,那么对于字段b,甚至后面的字段c等,可能就完全没有过滤效果。在用这些字段进行具体查询时,过滤就基本无效。
这是MinMax索引排序经常会遇到的一个问题,一种解决方案是使用projection的方式——按照另外字段再做一次排序来保存数据。而在哔哩哔哩,采用的是引入Z-Order排序的方式。
Z-Order具体是什么呢?举例来说,我们有a,b,c三个字段,用这三个字段进行排序的时候,我们希望同时可以保证它们的聚集性,而不是像global order那样优先保证a的,其次是b和c的。我们希望在最终的排序结果里三个字段都能有一定的聚集性。
具体怎么做呢?实际上,Z-Order是把天然没有有序性的多维数据以某种方式映射成一维数据进行比较。映射后的一维数据,能够保证各个原始维度按照同种程度去保证其聚集性。举一个简单的例子,如下图所示,对X,Y这两个维度进行比特位的交叉组值,形成了Interleave Index进而得出一个新的值,这个值被称作Z-Value。从图中,可以看到针对X,Y这两个字段的数据,生成的z-value会呈现出一个Z形嵌套。这样的一个结构,在进行切分时,能够同时保证X,Y两个字段的聚集性。
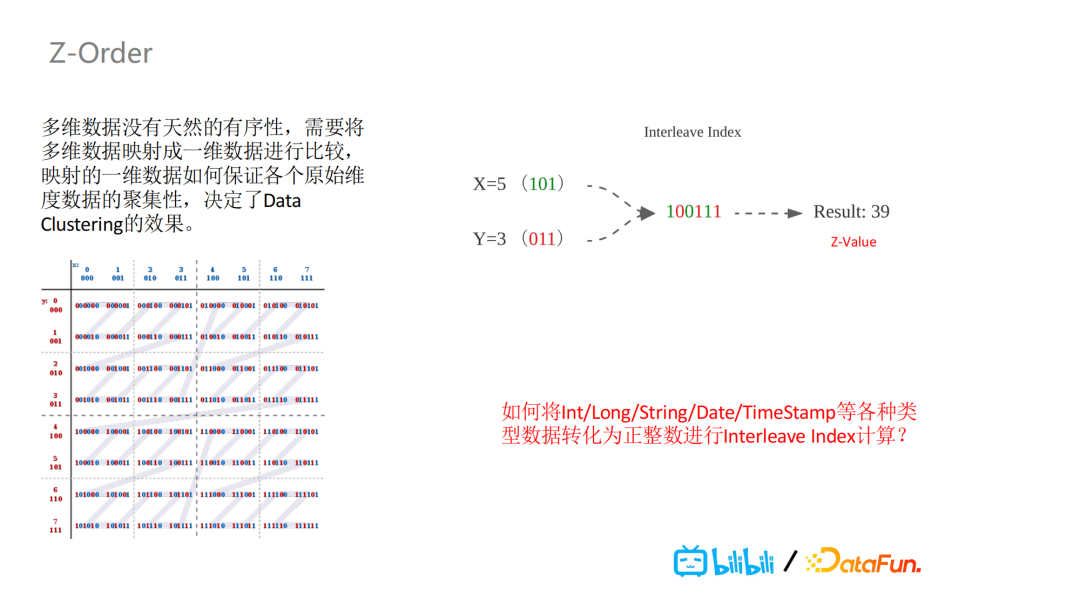

这种聚集性,又会带来一个新的问题:我们支持的数据类型不止Int类型,如何将
Int/Long/String/Date/Timestamp等各种类型数据进行正整型转化,进行Interleave Index计算以及计算出相应Z-Value?
因此,实现Z-Order 的一个前提是需要保证数据以保序的方式映射成一个正整型。对于Int类型的数据,可以做首位比特逆转来实现;对于其它类型的数据,实现的方式都不太一样,比如对String类型,会取固定的前几位来进行排序。
但是保序映射也存在问题:
第一,从原始值到映射值的过程中可能会丢失数值信息。比如String类型的数据,如果只取前几位的话,后面的信息就丢失掉了。
第二,映射值的分布无法保证从0开始是正整形,导致z-value不符合Z-Order曲线的嵌套分布。比如,X的取值是0,1,2,3,4,5,6,7,Y的取值是8,16,24,32这种,计算出来的z-value排序效果实际上和数据按照order by y,x的效果是一样的。也就是说这种排序并没有带来额外的好处,对于X的聚集性无法保证。

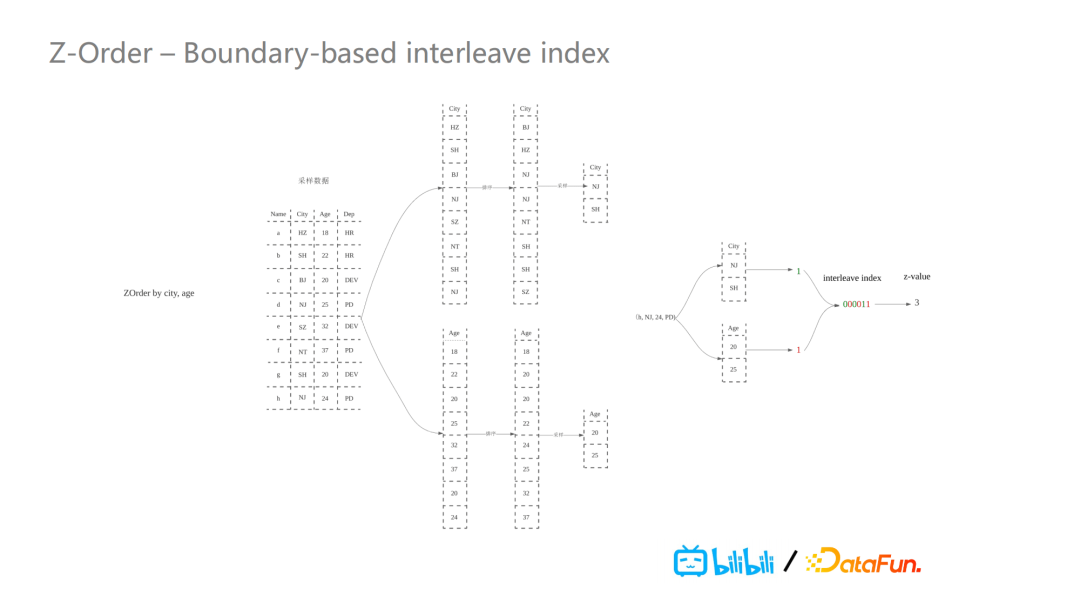
因此,我们引入了Boundary-based interleave Index这种计算方式。它主要对Spark RangePartitioner进行了一些改造,实现了一个新的排序方法。以下图为例,我们需要对city和age两个字段进行Z-Order排序,我们对这两个字段进行数据采样,采样之后,对每个字段进行排序后再继续采样。把boundary采样出来之后,对于进来的数据,Spark的shuffle partition会把这个值和boundary进行比较,取boundary的index值去进行计算出它的z-value值。因为我们是按照boundary的index值进行计算,所以z-value肯定是从零开始的正整型。
下图是Z-Order的一个效果呈现,具体来说,我们对所示的三个字段进行Z-Order排序,然后我们发现它可以做到百分之八十多的data skipping,即百分之八十的数据在在查询时不用被读取。

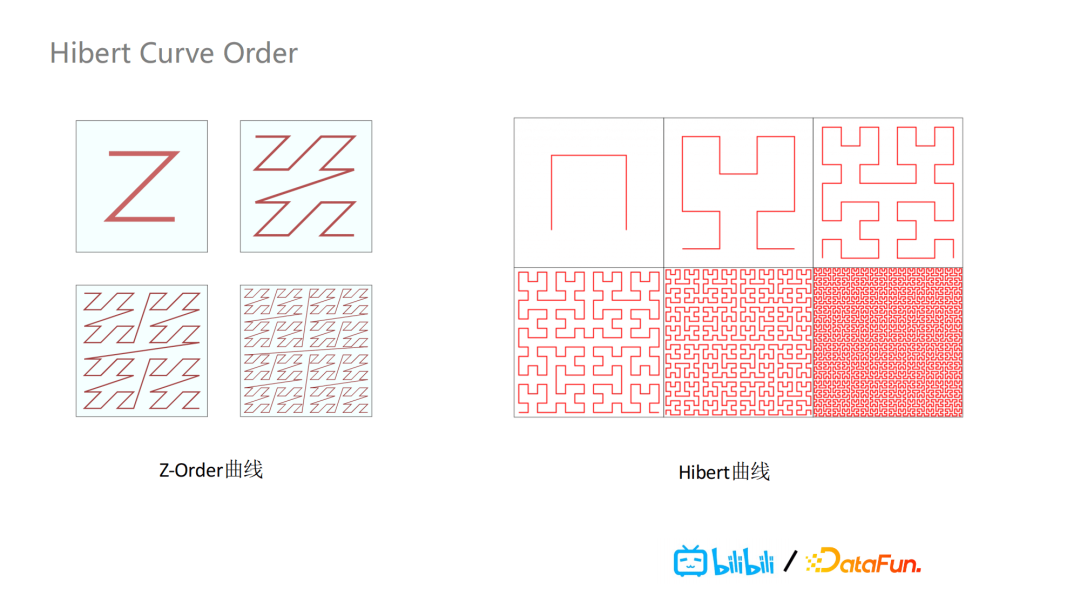
另外,我们还支持了基于Hibert曲线的排序,Z-Order排序存在一个缺陷就是它会存在跨度较大的连接线,这样会导致在文件切割时,如果大跨度连接线被包含在某个文件里时,会导致这个文件的Min,Max跨度很大,data skippingde效果就大打折扣。Hibert曲线就不存在连接线跨度非常大的问题,效果也就比Z-Order更好,如下图所示。
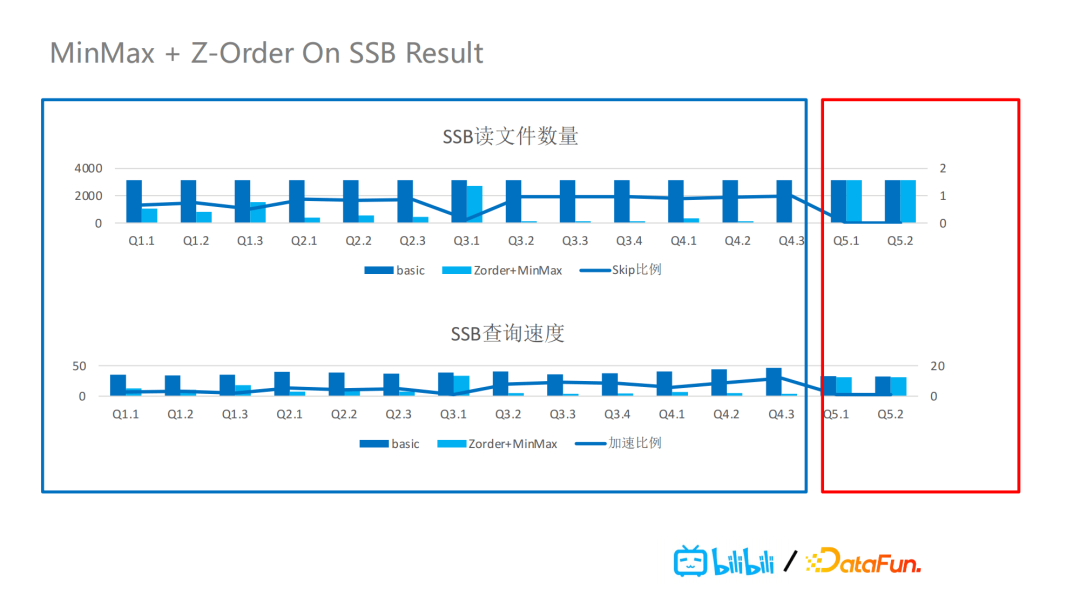
我们支持了Z-Order排序组织之后,再加上MinMax索引,它们在Star Schema Benchmark(SSB)的效果如下图所示。可以发现文件读取数量和查询速度都有非常大的提升。但是Z-Order排序字段越多,排序效果也会越差,因此我们建议2-4个。如果不进行数据的组织排序,MinMax索引的过滤效果就会非常有限。
--
04 索引的增强
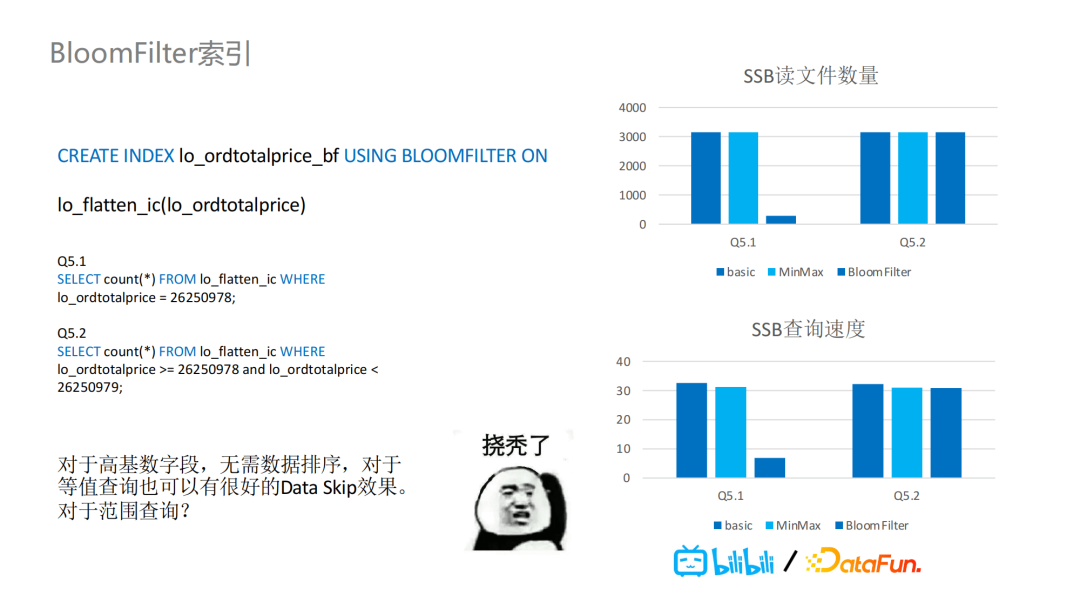
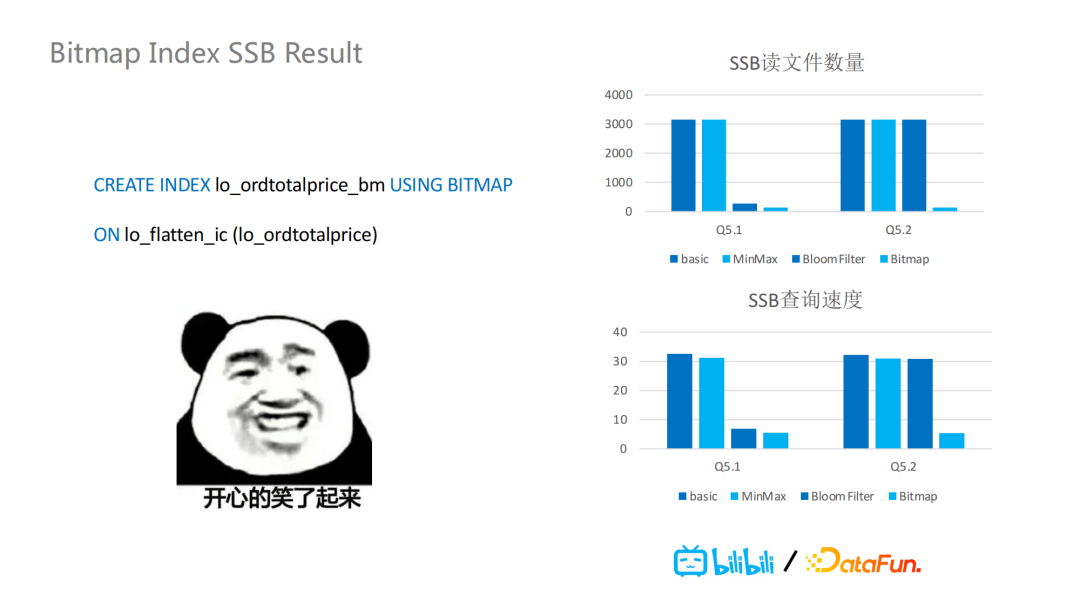
针对Iceberg,我们引入了基于文件级别的BloomFilter索引的支持,每个表的每个字段可以创建BloomFilter过滤器。针对SSB,我们增加了两个额外测试,一个是等值的数据查询,另一个则是范围过滤的数据查询。如图所示,加了BloomFilter后的等值数据查询,读取的文件数量大大减少,查询速度也有很大的提升。但是对于范围查询,BloomFilter这种索引并不支持根据范围过滤条件过滤数据文件。
因此,我们引入了BitMap索引的支持。
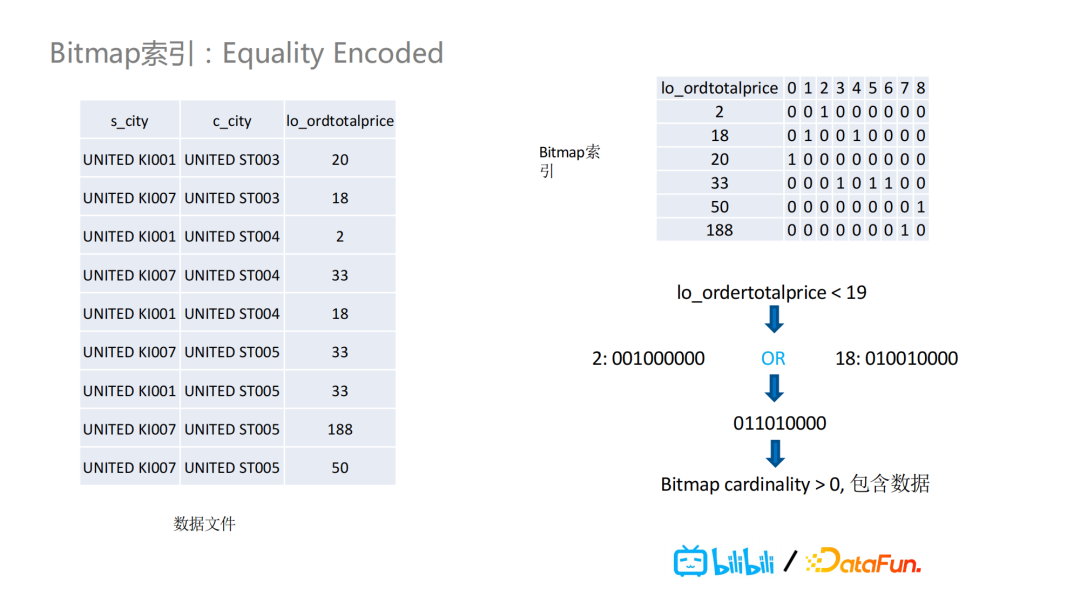
如下图的totalprice字段,我们引入BitMap索引,过滤条件为totoalprice小于19时,可以把2和18的BitMap进行一次或运算的操作,进而判断操作结果是否大于零。大于零就说明这个文件里包含所需要的查询数据,需要读取这个数据。
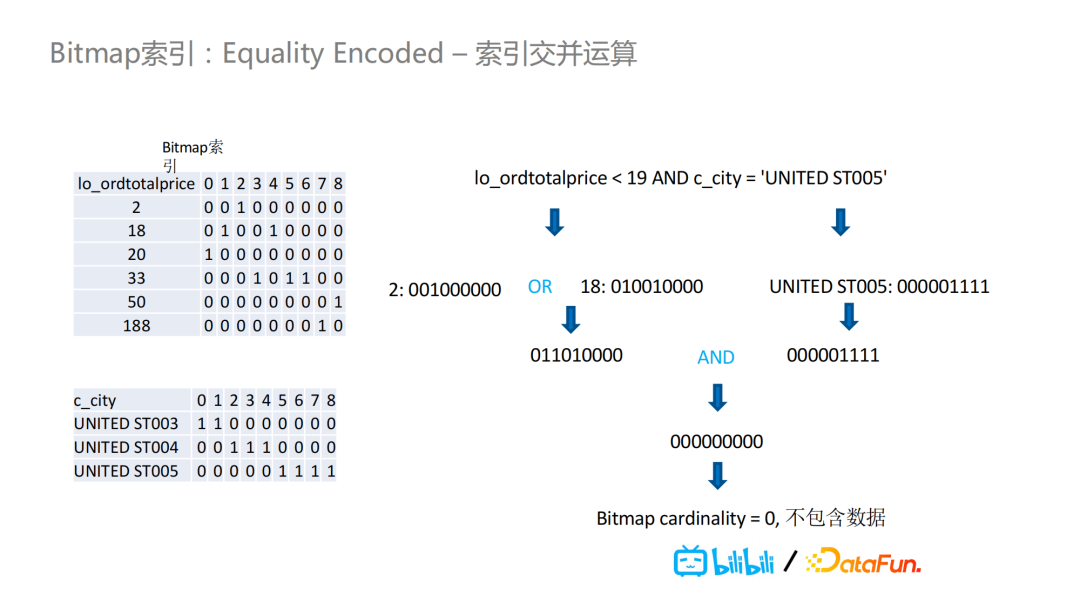
BitMap还有一个额外的好处在于:当过滤条件有两个的时候,我们需要查询totalprice小于19并且city是“United ST005”的数据。对于这两个查询,单独查询需要的数据可能在某个文件里都存在,但是当我们这对这两个条件做BitMap且运算后会发现某个文件里同时满足这两个条件的数据并不存在,因此我们可以不用读取这个文件。也就是说,BitMap的交并运算可以更好地在复杂过滤条件的情况下过滤掉更多的数据文件。
但是BitMap有两个比较重要的、功能实现上需要解决的问题。
其一,进行范围过滤时,比如需要查询price小于51的,需要把2到50的这些数据进行编码和计算,大量的读写和计算会非常影响查询效率。其二,针对每一个基数,都需要存储对应的BitMap,存储的代价比较大,尤其是高基数的字段。
针对第一个问题,我们引入了Range Encoded的BitMap去解决问题。举例来说,针对price字段数值为18的值,我们存储的不是它的BitMap,而是存储了它与数值为2的BitMap的或运算结果。简单说来,如果BitMap字段里有一个值是1,那么其后面的所有值都是1。通过这种编码的BitMap,我们就可以保证对于范围查询而言,我们都可以优化成只需要最多两个BitMap的值就能取出任意条件范围内的值。

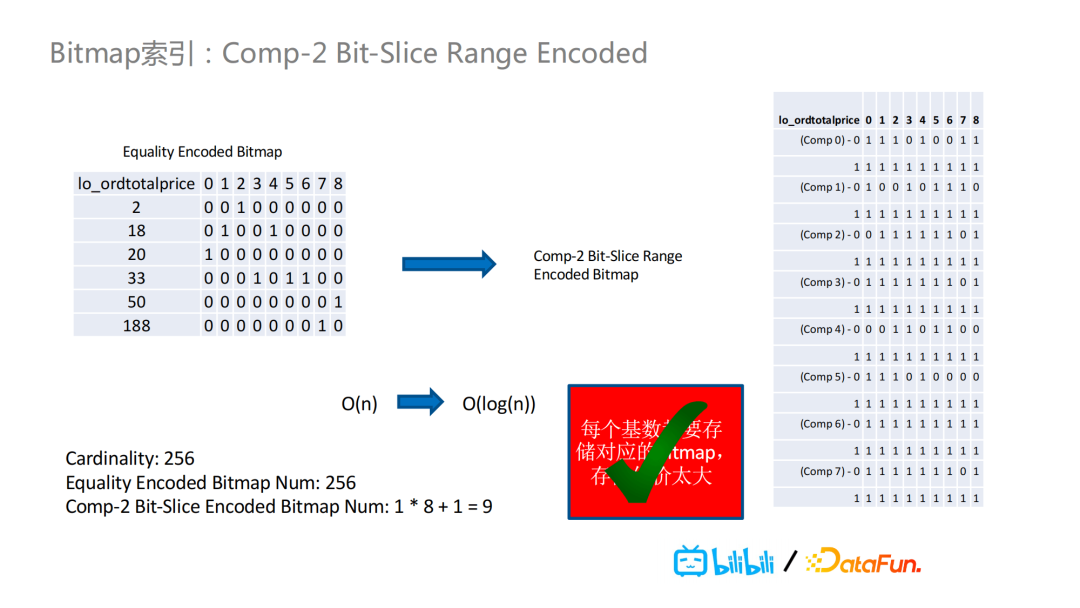
为了解决第二个问题,我们引入了Bit-Slice Encoded的BitMap索引。
在下图的例子中,我们看到price的取值有2,18,20,33等具体值以及相应的BitMap,对这些具体值进行按位切分,图中的“Comp 0”代表第零位。比如对于第零位为8的值,有18和188,那么就对这两个值进行BitMap的或运算并且将其结果存储到Comp 0里值为8的对应Bit Map里。对于其它的位,也是以同样的方式进行存储。这样之下,如果我们之前有256个基数,经过Bit-SLice Encoded之后,我们就只需要30个BitMap了,而不是之前的256个BitMap。

我们还可以把Bit-Slice Encoded的BitMap从十进制进化成二进制的位数表示,此处不做详细介绍。
总的来说,我们可以把Bit-Slice Encoded和Range Encoded的BitMap进行结合,对于二进制的Bit-Slice Range Encoded的BitMap,可以把256个基数的BitMap转化成只需要9个BitMap的结果。
基于以上两点,BitMap很好的解决了没有排序的数据组织中的高基数的范围查询的问题。它的SSB结果中显示查询效率有1-10倍的提升,读取文件数量则有0-400倍的减少。也就是说,不仅是查询性能的提升,也能使计算引擎的负载有很大程度的减少,硬件资源可以有更多的存储。
以上这些工作,不仅是在Iceberg这个项目以及相关Spark项目上做了对应的扩展和改造去实现的,也有SQL层面上的接口扩展。比如支持新的API,包括在Iceberg里,对Spark 3进行的语法扩展,通过distributed by支持文件间的排序,排序方式有哈希, Range, Z-Order以及Hibert曲线。Locally ordered by则是支持文件内的排序。也就是说用户可以自定义文件间和文件内的排序方式。后续的就是Magnus通过optimizer具体做相应数据优化任务。我们支持上文提到过的BitMap和BloomFilter文件级别的索引,通过Iceberg的Actions可以拉起相应Spark任务,去做对应的写索引和删除索引的操作。

通过对于数据的排序的组织,以及索引的支持,我们也总结了在多维分析的数据场景下的配置策略,如下图所示。这些策略使得我们能够支持任意多字段,任意过滤类型,在绝大部分多维分析场景下,只访问尽量少的文件,加速查询。

今天的分享就到这里,谢谢大家。
本文首发于微信公众号“DataFunTalk”。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号