邱盛昌:OPPO商业化数据体系建设实战

导读:本文是OPPO商业数据研发负责人&技术专家邱盛昌老师带来的“OPPO商业化数据体系建设实践”的分享。整体内容围绕着下图中垂直划分的六个部分展开,分别为:数据平台、数据接入、数据开发、数据治理、数据应用和数据分析,这个图也概括了典型的数据体系的所有内容。
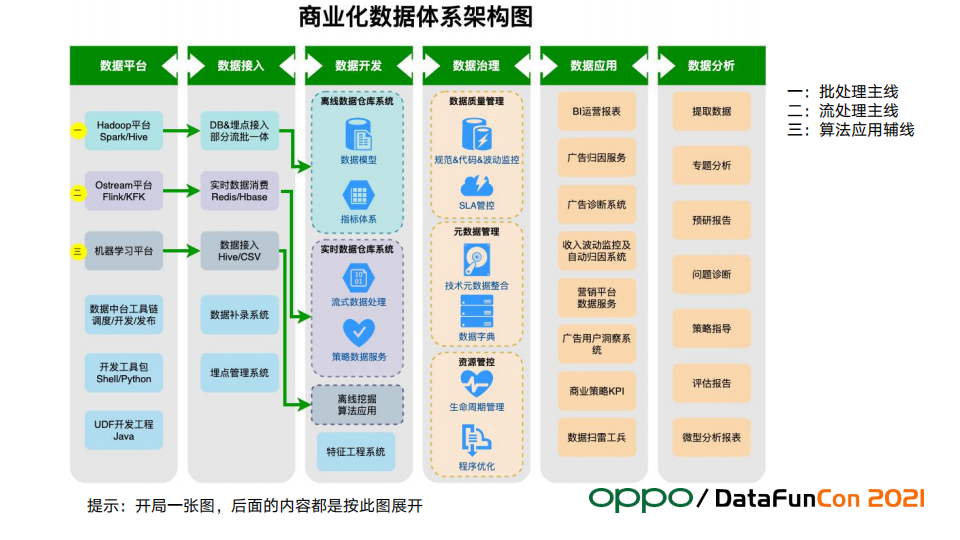
--
01 数据平台
数据平台由公司提供,商业数据研发作为平台使用方,首要职责是基于公司级的数据平台下构建商业化数据体系。平台与业务两个团队的分界遵循如下原则:“有则用,不等待,愿迁移,可贡献”。
在实践中,这个原则在最大程度保证了团队工程效率的同时,也让商业数据和数据平台之间做到了良性互动。
我们会优先利用平台的已有能力;如果没有,且无法及时提供,我们坚决自己做;要是后期平台有了相应的能力,我们也会把业务迁移到平台;或者把我们的能力提交贡献给平台。
1. 开发效率类工具包
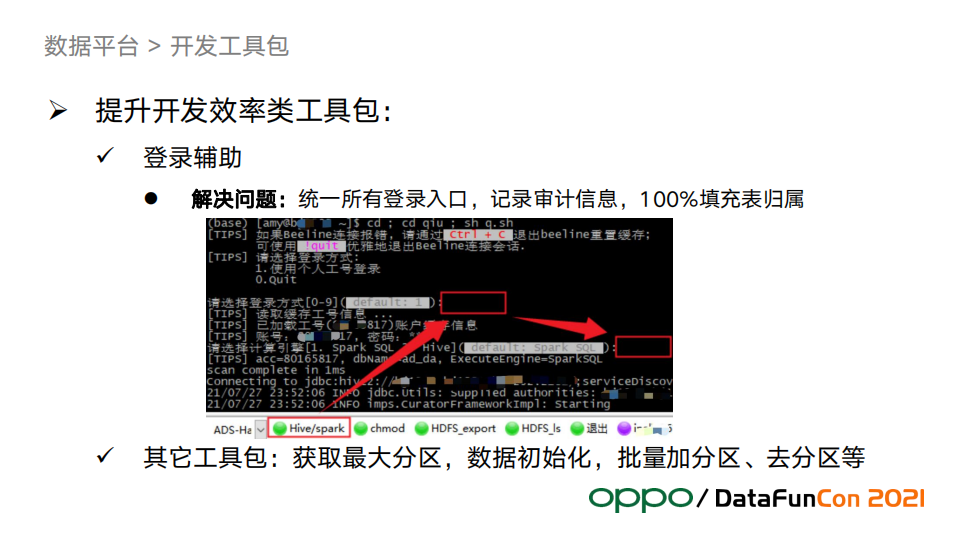
开发效率是数据工程团队优先要保证的目标,为此我们把开发同学日常工作中高频操作动作抽象成工具来提升开发效率。比如连接登陆计算引擎(Hive、Spark等)、获取hive表的最大分区、批量操作分区等等。
把这些动作工具化后有以下好处:
- 减少开发过程中机械操作部分,提升开发体验和效率;
- 减少人工出错的情况,保证数据安全和质量;
- 工具中统一了操作行为的元数据,方便数据审计和权限治理等工作。
- 上图演示了登陆辅助工具:有统一的入口访问引擎,同时工具提供了自动加载工号和密码填充,工具在统一记录审计信息的同时保证了每张表都有归属人信息,这在以后的元数据管理中起到巨大的作用。
2. 数据校验类工具包

数据需求不管是在开发中还是任务上线后,为了保证数据的完整性、一致性、正确性,都需要对数据进行比对验证和波动监控等数据校验工作。上图例子展示了“两表核对数据”工具在数据波动等问题后自动告警的信息。此类工具设计的重点是将异常定位标识展示完整,将责任人和影响的业务模块展示清晰,方便相关负责同学评估异常影响和及时排查问题,否则问题就会隐藏在数据中,引起用户投诉。
3. 可视化辅助工具包

邮件和公司的即时通讯工具TT,是数据触达用户的两个重要通道,用户随时随地可以通过这两种方式了解关注的业务数据。我们开发了可视化辅助工具包来加强数据触达用户的效率和可视化能力。TT也拥有类似微信的公众号、订阅号、机器人的功能。
首先我们申请了一批公众号,有针对质量管理的、收入监控的、商业智能和决策支持的,不同角色的用户关注不同的公众号就可以收到数据的消息推送。用户选择关注不同的订阅号,可以随时随地掌握自己感兴趣的主题,比如老板上班前或假期中就可以看到最新核心指标推送消息。
另外我们将一批机器人账号放在各类型的TT群中自动发布公告或者专门告知某个负责人处理相关数据问题,比如负责营销平台数据的机器人在每天扫完数据后就会群里发送结果,让负责的同学去处理。
辅助工具在上述过程中将部分工作流程自动化,比如简单通过几个参数配置就可以完成一个邮件数据的可视化图表配置等。
4. UDF开发原则

公司的数据平台提供了一些通用的UDF工具包,但是个性化需求的工具包我们会自己研发。我们部门在开发UDF过程中总结出了几条原则如上图。对于第一条,使用临时函数的好处是发布简单、影响范围小,所以能够快速上线。另外,开发数据的UDF要避开“后端思维”,比如碰到数据异常,要返回NULL而不是把异常抛出去阻断了程序运行,保障数据质量放在数据校验步骤来做,而不是UDF来做,如果因为几条脏数据阻断了程序运行,会极大影响到任务的SLA,非常不值得。
--
02 数据接入
数据接入的最终形态是全面配置化、中间件化,最好做到流批一体。数据接入可以根据需求在流式和批处理之间自由配置。
1. 出入库强制校验数据量
数据链路要在源头入库时做基本的数据校验。例如数据量强制校验,如果导入后不做校验直接跑数,常会导致后续处理问题频发。如果一个表导入后为空,会导致后边的任务在执行时候全部被挂起,或者数据量不正确,后边任务产出的数据全部是错的,影响范围巨大,恢复起来也慢。
2. 字段尽量全部接入
如果只接入单个需求所需字段,那么后续需求要用到此表其他字段的时候就需要重新再做一次来加字段,这样效率会低很多,且容易出错。
3. 历史要保留
每天抽取导入的数据可能不一样,所以历史分区在缓冲层要保留一段时间,而更长时间的历史保留应当放在ODS层。抽数一定要做分区表,最好每天一个分区。
4. 数据接入情况介绍
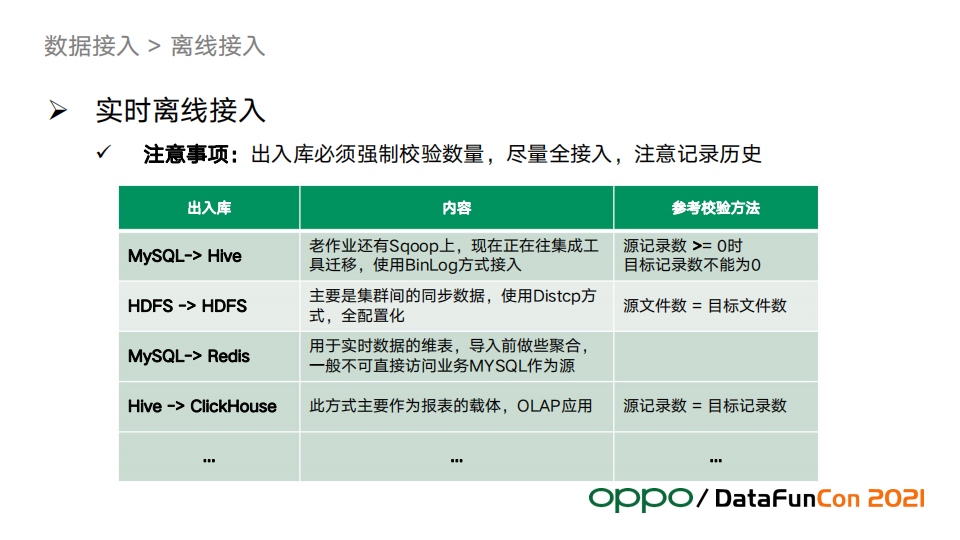
上图是按照导入导出的SRC和DST分为四类的数据出入仓方式。
--
03 数据开发
数据开发涉及到的内容比较多,本节会围绕数仓架构展开来讲:
- 构建基于维度建模理论的离线数据仓库系统
- 构建服务于收入监控/实验/策略/广告引擎的实时系统
1. 数仓架构
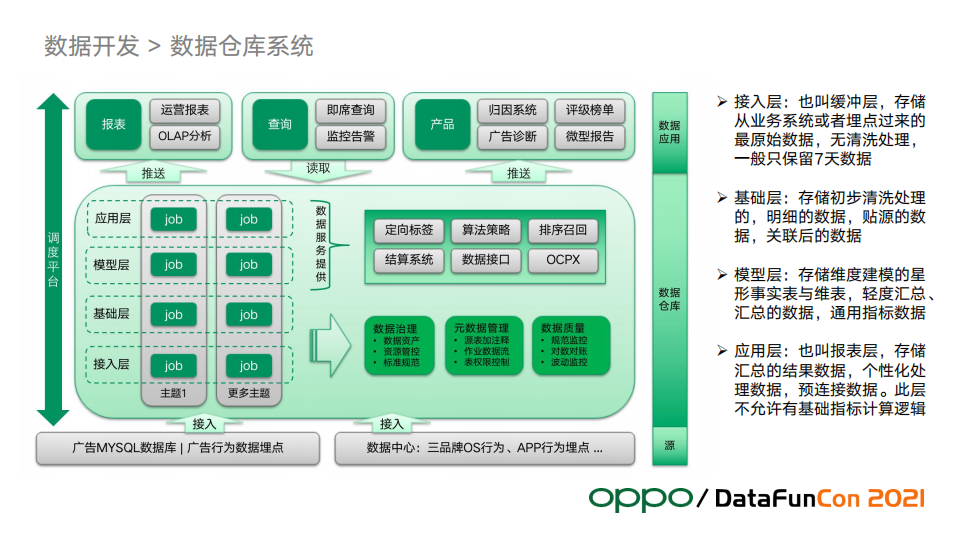
数据源层接入两大块数据:广告行为埋点数据、三品牌OS行为和APP行为埋点数据。三品牌的OS行为,这是厂商特有的数据,比如用户在手机上安装了哪些应用,启动卸载应用等信息;还有一些app行为信息,比如浏览器、软件商店等都会接入。
图中仓库层的左边数据建模的过程,可以分为不同主题。不同业务对主题的划分也不一样,但是总体都会分成图中的4层:接入层、基础层、模型层和应用层。
仓库层还会做一些数据治理的动作,包括数据质量、元数据管理、资产管理,都属于数仓的范畴。针对这些我们做了大量的工作用于资源管控、成本优化和质量规范监控。
还有一些偏底层的数据服务也属于数仓的范畴,包括定向标签、排序召回、广告策略需要的特征数据,数仓负责算好提供给应用方。结算系统因为数据量太大,也只能在数仓进行结算。
模型层和应用层还会以接口的形式提供数据服务,对于广告特别重要的OCPX也在这里。
2. 指标体系

主题域的划分、指标体系建设因不同的业务而采用不同的方法。例如,广告会按照效果广告和品牌广告去划分,同时结合广告行业的特点做应用分发、搜索、信息流等的主题建设。图中展示了广告的转化指标建设,整个流程有很多业务过程,会产生大量的数据。数据仓库模型层一开始只会开发基础指标,而对于业务KPI相关的业务我们会按照OSM模型来建设指标体系,比如找到业务的北极星指标。
3. 维度建模
维度建模的实践,我们将它归纳为三个核心观点,如下图所示:
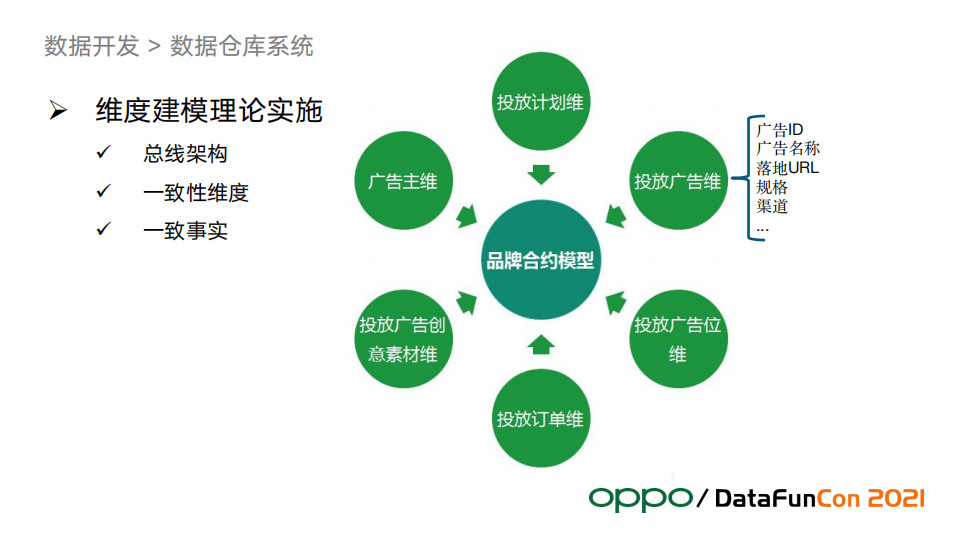
比如 “品牌合约模型”的广告主维度,如果换一个模型也有广告主维度的话,两个模型需要使用相同的维度来保证一致性,而且需要取广告的信息只能从这个表出,而不是再去关联其他更多的表,这就是一致性维度的简单理解。一致性事实会保证不同模型之间事实数据可以交叉探查,而且需要保证指标的口径统一。从图中的模型也可以看出我们主要采用的是维度建模中的星形模型,这也是最常用的模型。
4. ETL链路优化
ETL链路开发优化中散布着很多痛点。针对链路优化,为了让数据高效高质量地跑出来,我们总结了一些经验,如下图:
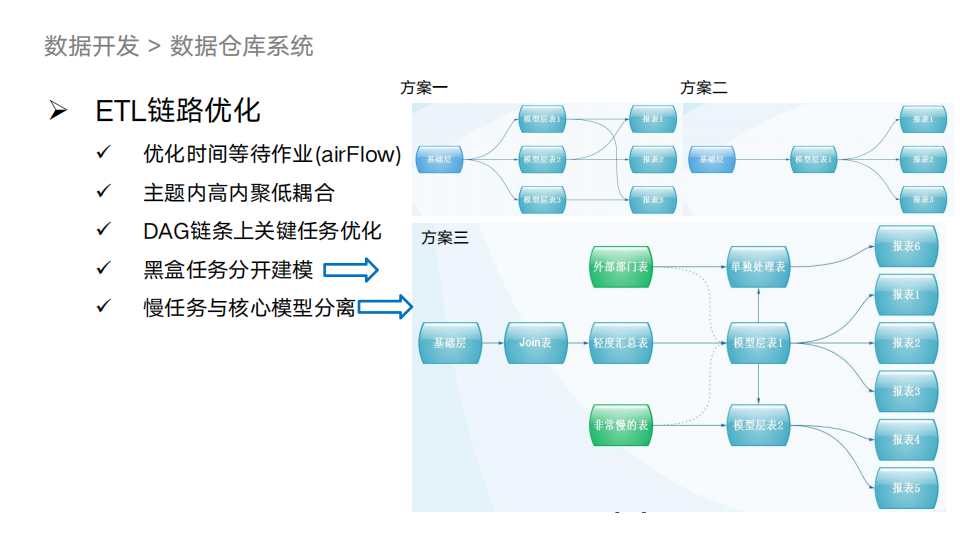
图中右边是数据链路建设的三种方案。
第一种可以看到不同的报表有各自独立的基础模型表。优点是效率高,缺点是实现非常复杂,且不易维护。
第二种是将报表的模型层统一,优点是结构简单,缺点是不同的模型数据会互相影响,造成跑数时不必要的相互等待。
第三种方案结合前两种的优点,把模型层中有外部依赖和没有外部依赖的做解耦单独建模,另外将比较大的慢表也和其他模型分开做解耦,这样方案最大程度上保证了较低的复杂度和较好的出数效率。
5. 商业化数据仓库的评估

按上图所示,我们通过稳定性、高效性、准确性、维护性和创新性这几个维度来评估数仓建设的成熟度。
--
04 数据治理
1. 元数据分类
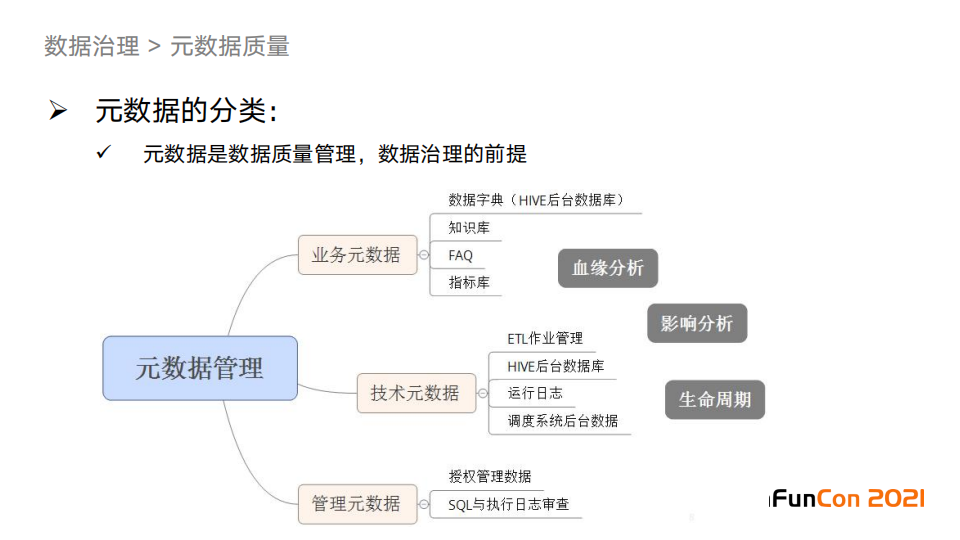
业务元数据主要是业务数据知识,我们把这些业务元数据组织成图中的四类,来满足各种角色对于这些知识的使用需求。
技术元数据非常有用,这是做数据治理的前提,比如用于构建应用、影响分析、问题排查等。
2. 各类元数据的用途
下面三张图介绍了三类元数据在OPPO的主要用途和部分应用的实例:

Hive和DB的元数据可以用于规范检查,从表的诞生开始就应该进入了元数据质量监控的范围, 这是实现治理常态化的重要手段。

调度管理在数仓中是非常重要的一环,调度的质量管控需要通过调度元数据来实现。调度中通常会有复杂的依赖和异常处理,是问题的多发区。提前发现调度问题是保障数据产出的实效性和质量的重要手段。

例子中的研发年报如果要人工统计,对于大的数仓几乎是不可能完成的任务,因为表的数量庞大。我们利用元数据提升了代码交付质量、支持技术运营统计。
3. 数据质量管理实施方案
数仓必须自己保证数据质量,不能只靠平台提供的能力,因为平台往往不会考虑和业务强相关的内容,可以适当利用平台的工具来辅助完成数据质量的管理。下图是我们的质量监控体系。
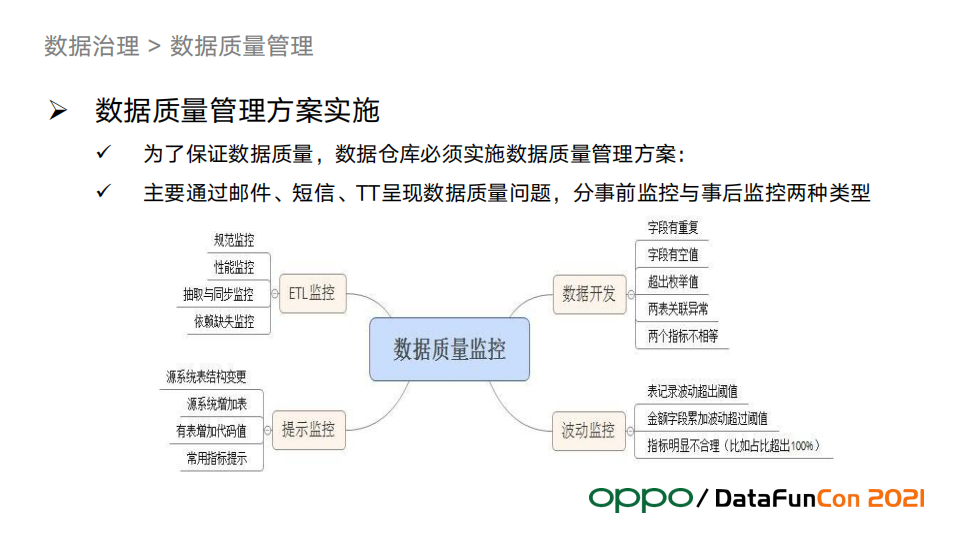
其中波动监控是一个难点,我们总结了一套方法论,后文会展开来讲。下边的例子展示了质量管理方案实施原则和应用案例,包含了未发布监控、依赖缺失监控等。

4. SLA准点率提升监控
准点率是数仓交付质量非常核心的一个要求,也是数据开发经常要处理的问题。在实践中我们形成了一套方法论,这套方法论主要是对报表分级然后采取不同的保证策略。
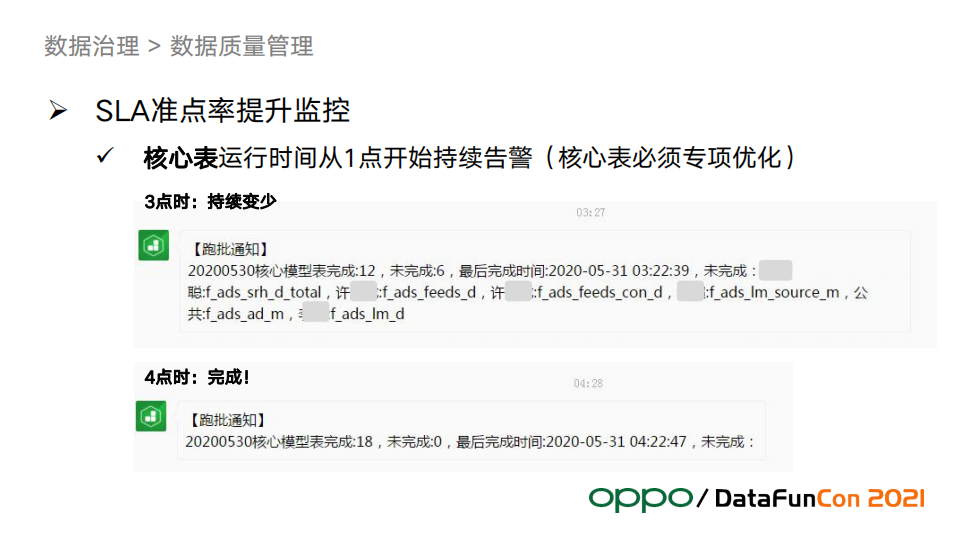
例子中的核心报表会在凌晨1点就启动监控,每个整点会发送任务执行进度情况,对于没有及时完成的任务,24小时值班运维会打电话叫醒负责人,负责人收到报警后及时处理以保证准点率;如果没有核心报表运行,并且完成时间在合理时间内,负责人则不会被叫醒。
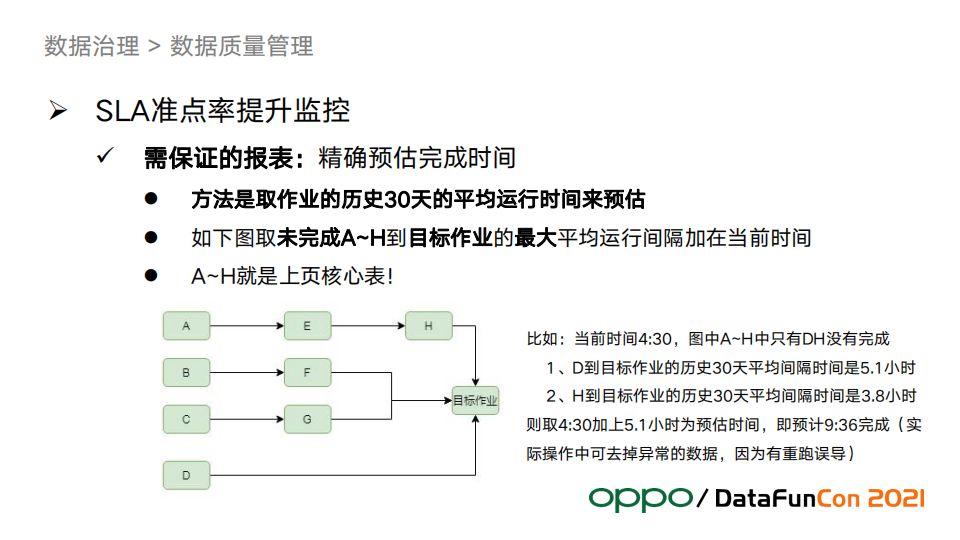
对于需要保证的报表,如何精确地报警很重要。这要求我们需要较为准确地评估预计完成时间。上图展示如何精确预估完成时间。如果我们预估的完成时间赶不上业务要求的交付时间,24小时值班运维就会通知负责人介入来保证按时交付,哪怕在凌晨。
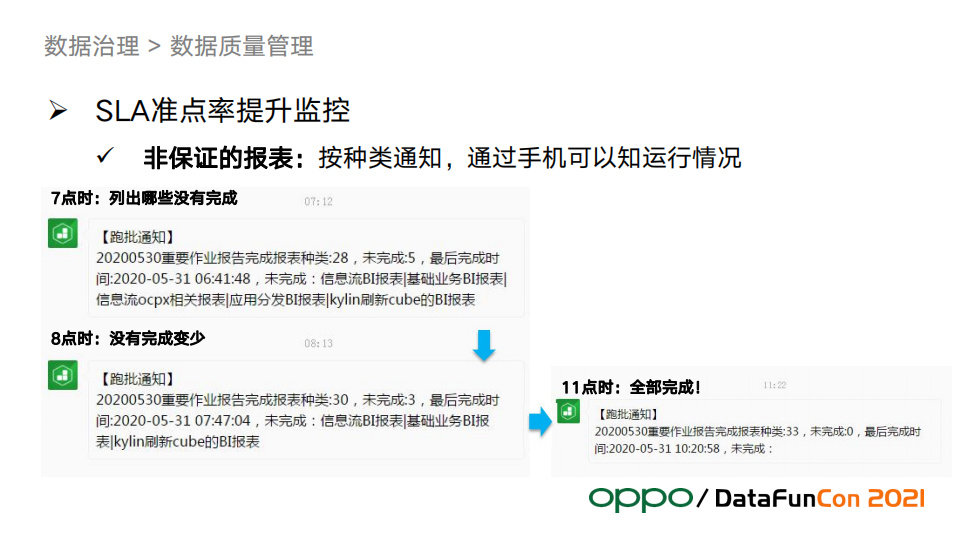
上图是非保证的报表的例子。虽然不需要保证在精确的时间点前交付,我们也需要知道执行情况,并且把执行情况通知到负责人,这样负责人可以随时随地掌握这些重要的信息,负责人看到后根据实际情况灵活处理即可。
--
05 数据应用
数据波动监控和广告归因是业务中的两个难点和业务价值高地。
1. 解决波动监控的三大痛点
最大痛点:告警太多,泛滥后容易麻木,相当于没有告警
第二痛点:准确率不高,误报、漏报很常见
第三痛点:阈值设置困难,一个阈值不能适用于所有场景,全部个性化阈值又太多
我们结合商业化数据的特点,形成了一套波动监控体系和方法论。
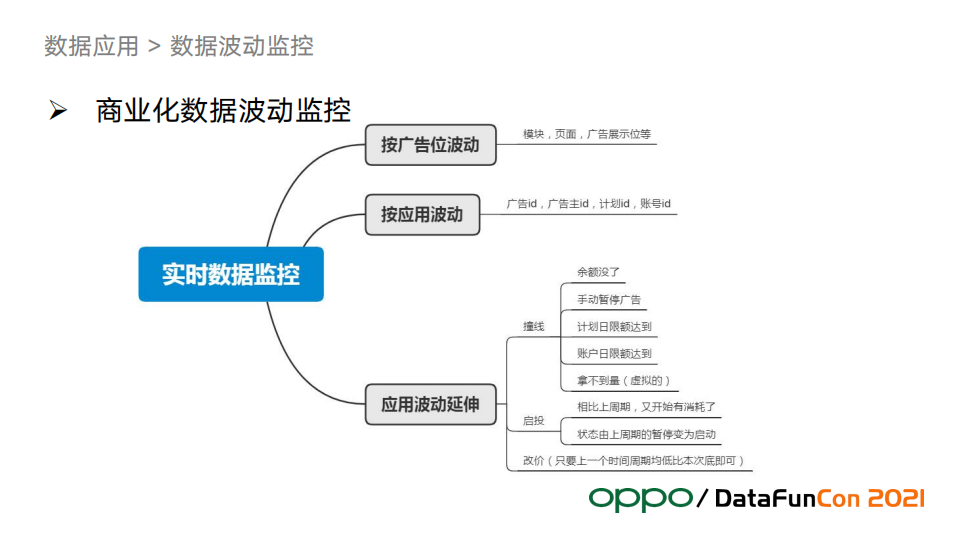
广告位的波动监控能够发现一些广告播放系统的bug,这块我们做的也比较多。
按应用监控方面,因为每个广告主的投放计划不一样,所以波动经常是合理的,比如客户不想投了、账户没钱了等,会造成数据波动,这种波动监控意义不大,发现也无法采取措施。
但是提前发现有动作的节点是有价值,为此我们抽象出三个可以监控的东西:撞线、启投、改价,这些报警可以指导业务动作,比如余额快没了,销售就会提前联系广告主充值。竞价被打败没有拿到流量,及时报警出来通知广告主改价。

上面提到我们对广告位波动做了很多事情,形成了一套有效的识别波动的方法。通过环比上个周期、同比昨天、同比上周,这三个条件组合判断后,会非常准确地识别有效波动。另外,阈值设定要按照金额分级,例如图中的例子,小广告主波动阈值会大;100W以上的大广告主的阈值会小一些。通过这套方法论和金额分级经验,很好地解决了波动监控的三大痛点。
下图是关于撞线、启投、改价的例子:

这类告警确定性很强,很容易就可以判断,往往不需要反复调阈值。
2. 广告归因服务
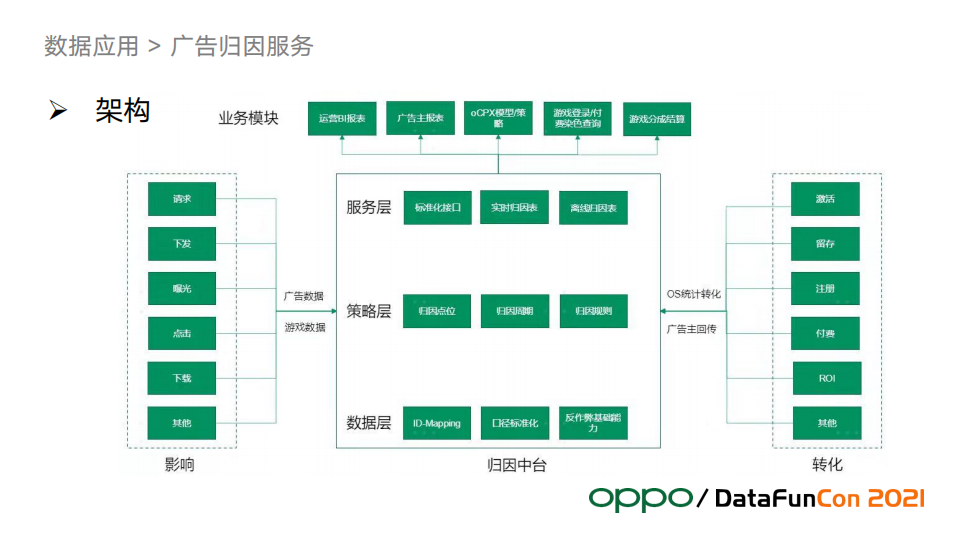
广告归因是广告业务特有的内容,对OPPO非常重要。上图是归因服务的整体架构。
图中右边是转化数据,左边是广告数据,中间是归因中台。转化加广告数据作为我们归因中台的输入数据,归因中台的作用就是怎么把转化归因到广告的数据中,比如这一次付费是哪一次广告点击带来的,有可能归因出来是上个月1号的那次点击下载APP带来的。归因中台从下到上分为三层:数据层、策略层、服务层。
数据层是准确归因的底层基础,ID-Mapping负责把互联网中的用户映射成一个实体用户,口径标准化提升统一口径提升数据质量,反作弊模块会从流量中刨除作弊流量。
策略层是归因的逻辑层。归因策略围绕着广告点位、归因周期和归因规则来组织,以求做到归因结果尽量准确。策略主要来自行业经验,比如不同的点位和流量的归因周期应该是多少等等都会在这一层管理。
服务层对外提供标准化口径的实时和离线归因服务,支撑了对各方的归因和运营服务。

--
06 数据分析
1. 数据提取
通过培训来赋能业务,让更多的人有能力自助完成数据提取和简单的分析工作。这样也能节省数仓开发团队的工作负载,让开发团队能聚焦在建设高质量的数据模型上。

2. 微型分析报告

例子中的日报,内容不多但是非常丰富,收入情况和效率指标都算好了,同时分析了波动情况,业务负责人随时随地可以看到这个报告,并且马上可以判断业务健康情况采取决策行动。

--
07 精彩问答
Q:cdm建模规范中派生指标和泛化指标构建数据集的时候有没有约束性的规范?
A:有命名的约束,另外我们通过id唯一确定一个指标。命名也要唯一,防止它有多个人来构建同一个指标。唯一性之外我们还会约束如何命名:我们有系统告诉你应该怎么命名,有一些经验在这里面,它会提供一些词根,或者是历史的统计信息,也就是大多数人如何命名某个指标。
Q:我们的流批一体用的是一套还是两套引擎?
A:我们当前只在接入层实现了流批一体,是公司的数据平台提供的这个能力,也就是mysql到hive,这里可以做到流批一体,只有一套程序,再往后的流批一体我们还在探索,没有实现。
Q:我们平台有没有代码扫描类似的功能?
A:其实这个取决于你自己的规则。我们的代码可以存在hive中的一个字段值中,所以我们可以根据规则去做正则,比如扫一下这里边的中文是不是太少了,说明注释可能太少会导致业务含义缺失等,也可以检查有没有做空值处理,根据自己的规则来做处理就好。
今天的分享就到这里,谢谢大家。
本文首发于微信公众号“DataFunTalk”。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号