
苏涛:对抗样本技术在互联网安全领域的应用

导读: 验证码作为网络安全的第一道屏障,其重要程度不言而喻。当前,卷积神经网络的高速发展使得许多验证码的安全性大大降低,一些新型验证码甚至选择牺牲可用性从而保证安全性。针对对抗样本技术的研究,给验证码领域带来了新的契机,并已应用于验证码反识别当中,为这场旷日持久攻防对抗注入了新的活力。
分享内容包括三大方面:
- 对抗样本介绍
- 极验对抗样本技术探索与应用
- 后续的工作与思考
--
01 对抗样本介绍
1. 什么是对抗样本

对抗样本 ( Adversarial Examples ) 的概念最早是 Christian Szegedy(克里斯蒂安·塞格迪)在 ICLR2014 (国际学习表征会议)上提出来的,即在数据集中通过故意添加细微的非随机的干扰所形成输入样本,受干扰之后的输入导致模型以高置信度给出了一个错误的输出。
如上图(左)原始图像以57%的置信度判断为“熊猫”,但是加入了微小的干扰之后,在人眼完全看不出差别的情况下,模型却以99%的置信度输出“长臂猿”。
当然,对抗样本不仅仅会出现在图片上,语音、文本上也会出现对抗样本,一段语音上加入微不可察的背景音,可以让语音识别模型输出错误的语音内容;在一段文本上使用近义词替换,也可以构造出对抗样本,误导语言模型。
那么为什么深度神经网络会出现对抗样本呢?
目前获得普遍认可的15年古德菲洛的观点,是深度神经网络的高维线性性导致了对抗样本的出现。
直观的理解,在进行一个高维度的线性运算时,每个维度都做一些微小的改动,会使输出结果发生巨大的变化。如上图,原始的输入是x,线性运算的权重是w,此时将样本分类到类别1的概率是5%,但是我们将输入的每一个维度都改变0.5,此时将样本分类到类别1的概率就变成了88%。
以上是对抗样本的一些简单的定义和目前比较被广泛认可的原因。
2. 为什么需要对抗样本
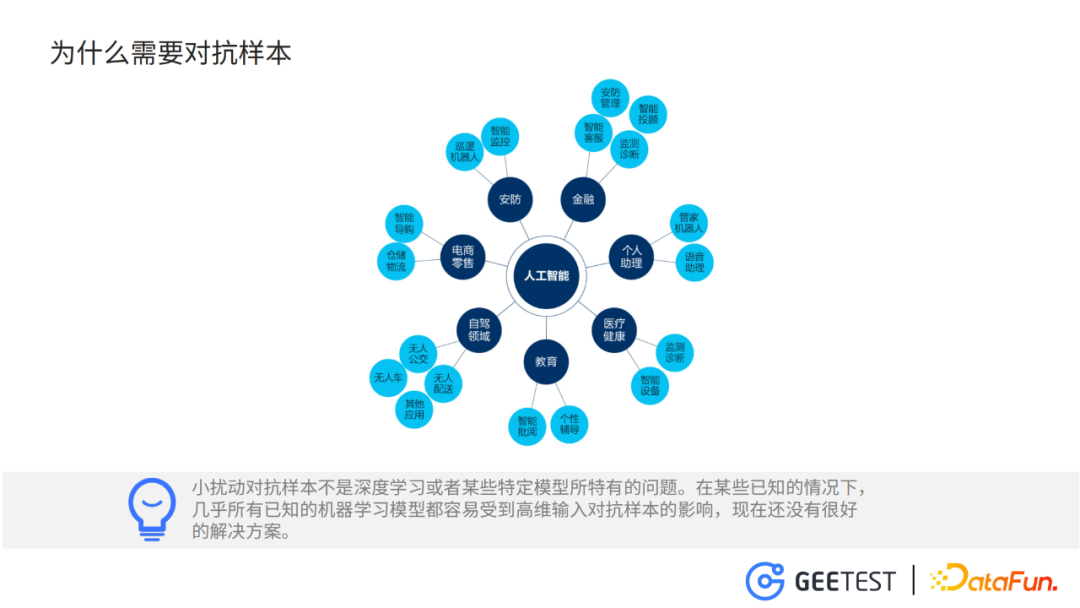
自从2012年AlexNet诞生以来,深度神经网络迎来了一段爆发式发展,并且广泛地应用于自动驾驶、医疗、金融、安防等领域。可以说深度神经网络模型已经深入我们生活的方方面面。对抗样本对这些模型的威胁是一个客观存在的事实,如果将STOP交通指示牌上加上一些微小的扰动,就会被检测模型识别为减速。行人穿上带有训练好的马赛克图案的衣服,就能在智能监控模型的视线中“隐身”。
所以,我们大力研究对抗样本技术,一方面是利用对抗样本探索深度神经网络的安全性,另一个方面利用对抗样本防御AI滥用的情况,如自动化验证码的识别,人脸识别模型的滥用,自动化鱼叉式的钓鱼攻击。
3. 对抗样本发展史和研究态势
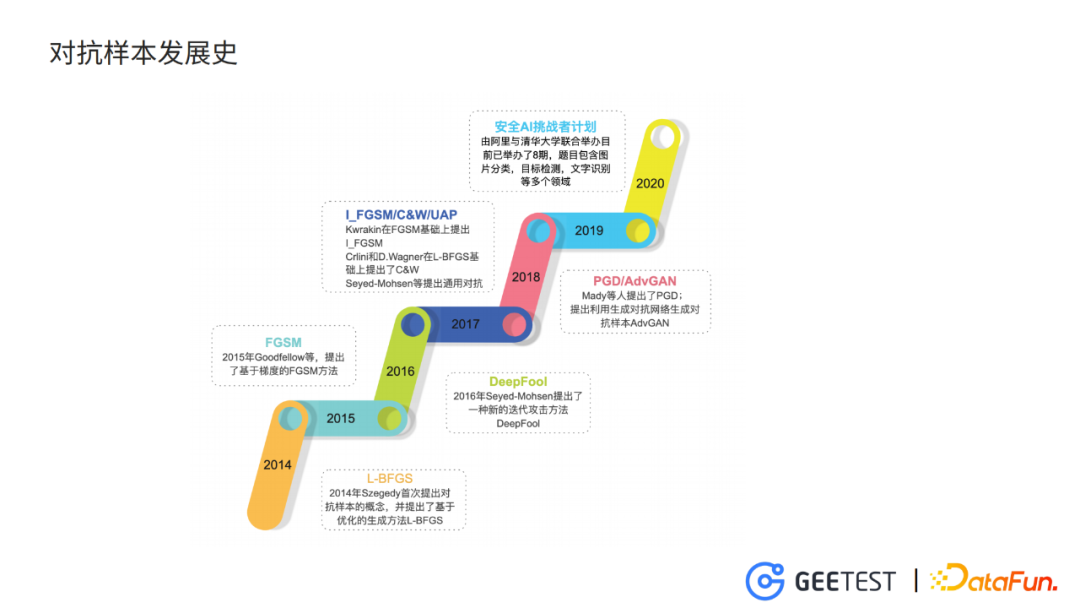
Szegedy在2014年的表征学习国际会议上提出对抗样本的概念,他认为这是高维非线性导致的,并且提出了基于优化方法的L-BFGS方法。第二年Goodfellow等人,证明了对抗样本的出现是高维线性的结果,并提出了基于梯度的快速梯度符号法。之后,各种以FGSM为基础的对抗样本生成方法纷纷出现,其中比较有代表性的是I_FGSM,它在FGSM基础上进行多次迭代。
在L-BFGS基础上提出的C&W,这个奇怪的名字是两位作者名字的首字母 。
2018年肖超伟提出的advGAN,输入原始clean图片,使用生成对抗网络来生成对抗图片。
随后各种基于梯度迭代的攻击方法,基于优化的攻击方法和基于GAN的方法逐渐丰富起来。并且,对抗样本在计算机视觉、nlp、语音识别等各个领域的应用也逐渐被挖掘出来。
在dblp搜索adversarial example可以发现,从14年以来,对抗样本相关的论文也日益增长,对抗样本俨然成为了一大热门的研究领域。
--
02 极验对抗样本技术探索与应用
上面我们已经对对抗样本技术有了一个些初步的了解,下面我们来介绍一下我们极验在对抗样本技术上的探索与对抗样本技术在验证码上的应用。
1. 验证码的破解方法
极验从2012年就开发了拼图验证码,随后又上线了九宫格验证码和文字点选验证码。我们也研究了各种市面上的验证码的破解方法。
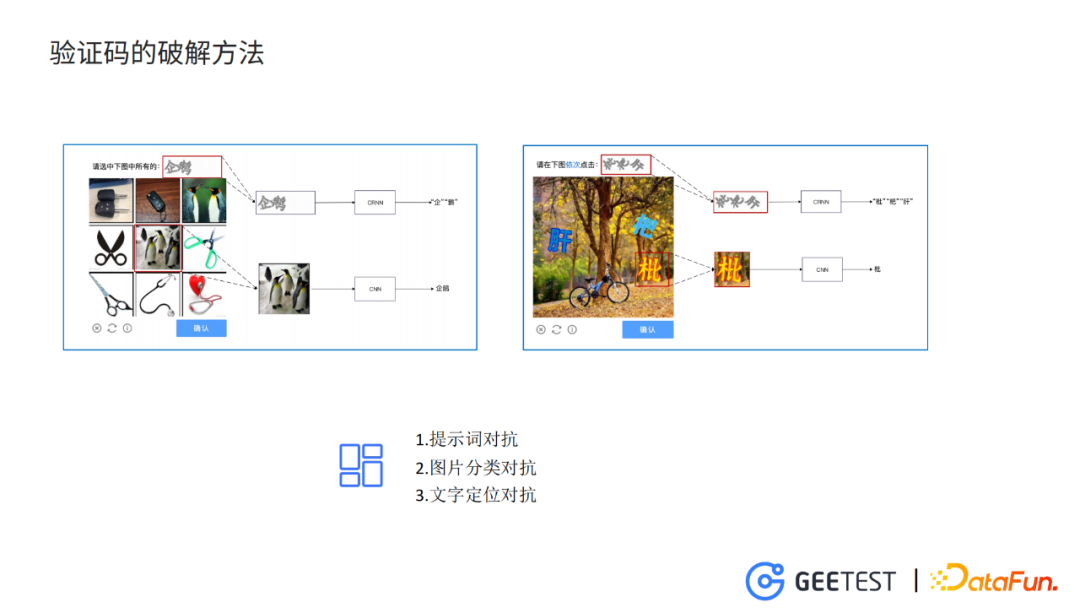
图片中分别是极验的九宫格验证码和文字点选验证码。
对于九宫格验证码,我们的破解方式和破解流程如下:从验证码上抠出上面的提示词,进入CRNN网络,输出这个提示词的内容。然后分别抠出9个小图片,进入CNN,预测出每个图片的类别。结合给出的提示词的内容和每个小图片的类别,得到最后的答案。
对于文字点选验证码的破解,同样是抠出提示词,进入到CRNN。但是对于文字位置的识别,我们需要用到一个目标检测的模型来检测出文字的位置,然后再根据位置将图片中的每个字抠出来,之后的流程与九宫格验证码的破解方式相同。
洞悉了主流的九宫格验证码和文字点选验证码的破解方式,我们就可以针对模型识别的每一个环节来生成对抗样本。例如针对提示词的对抗,针对图片分类的对抗,针对目标检测定位文字位置的对抗。
2. 几何感知对抗样本生成框架
- 黑点表示clean样本
- 两条虚线f,h分别是训练模型和验证模型,实线g测试模型
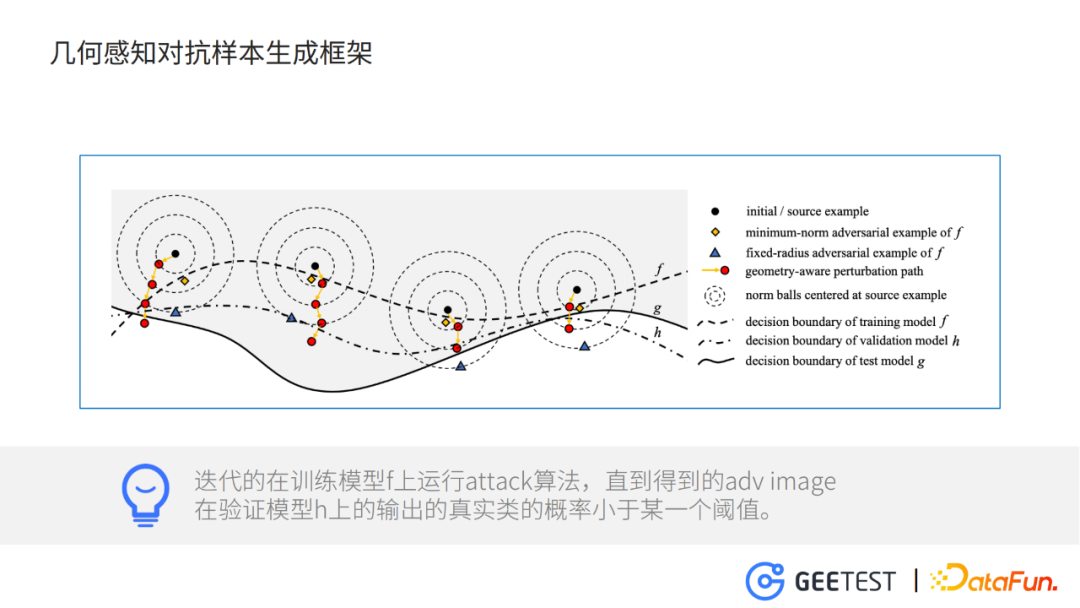
整个框架做的事情就是,迭代的在模型f上运行attack算法,直到得到的adv image在验证模型h上的输出正确类别的概率小于某一个阈值,并且在迭代的过程中逐步放开对抗干扰的L-p范数的限制。
为什么要把模型分成训练模型、验证模型和测试模型?主要是为了提升对抗样本的转移率,也就是说,在模型A上训练得到的对抗样本,在模型B上也能有很好的效果。这方面可以类比为提升一个模型在没有见过的数据集上的泛化性。
比如,黄色菱形表示f的最优对抗样本,如果不用验证模型h做一下约束,只利用训练模型f生成对抗样本,那么很可能迭代到这个位置就停止了,这样对抗样本在训练模型f上,过拟合了。
至于为什么要逐步放开对抗干扰的约束限制,主要是为了保证在达到对抗效果的情况下,能够使对抗图片相对于原始图片,看起来差不多。
比如,对于一张图片,先设定干扰的约束值为6,如果更新几次后就能够达到攻击的效果,那么迭代停止;如果多次更新仍然不能达到攻击效果,那么再增大约束值到10,继续更新。
上图中最右边的样本,经过2次增大约束值,就达到了攻击的效果,最左边的样本,经过了4次,才达到效果。
3. 具体的攻击方法
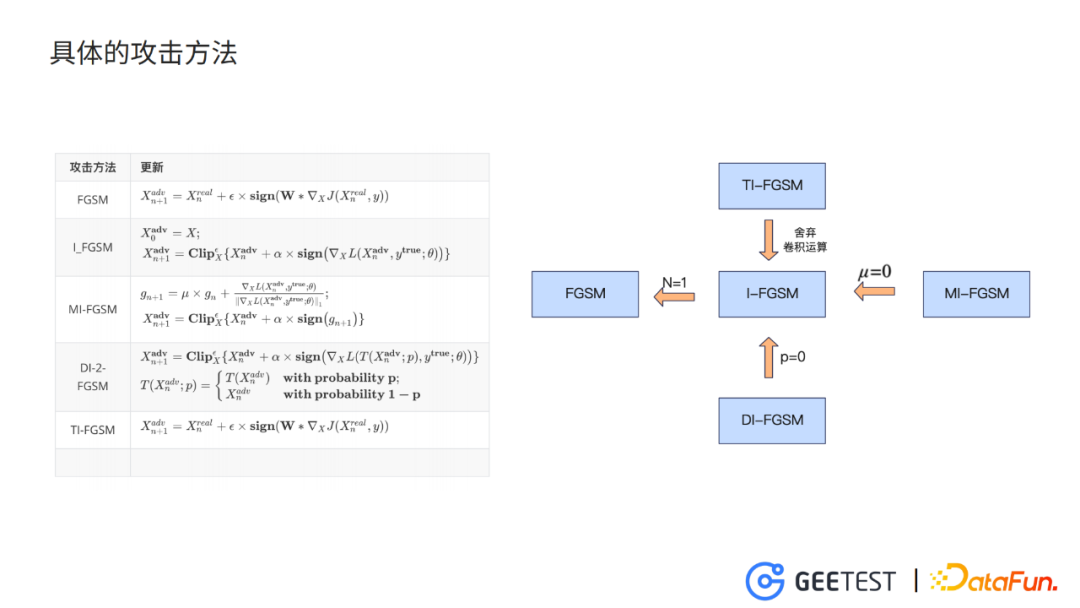
内部的攻击方法比较简单,用的是FGSM和它的一些增加了技巧的变体,主要是为了提升对抗样本的对抗性和转移力。
FGSM,是最速梯度符号法,算法的思想很简单:
- 训练模型时增大loss函数,需要计算loss函数对干扰噪声的梯度,此时我们在梯度的正方向上更新参数,就能够使loss函数增大。
- FGSM只进行一次参数的更新,I-FGSM迭代多次。
- MI-FGSM引入动量m,保留短期梯度的历史信息,提升稳定性。
- DI-FGSM以一定的概率p,对输入进行多样化处理,可以理解成一个小的data augmentaion。
- TI-FGSM利用一个事先定义好的kernel,对扰动参数的梯度进行卷积平滑,同样是为了提升对抗转移率。
以上就是我们的整个架构内部攻击的一些方法。
4. 对抗样本初步效果
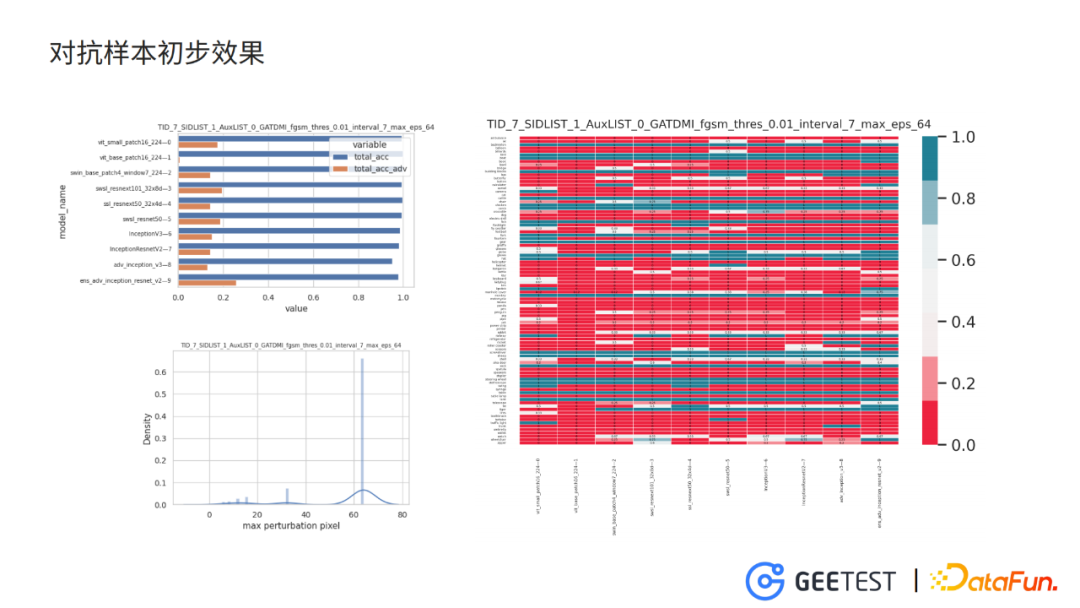
这里我们利用在imagenet预训练的参数,微调出10个识别九宫格验证码的模型,这10个模型有不同的结构——有vision transformer、resnet、inception作为基础block的深度神经网络。这些模型在干净样本上的分类准确度均达到了98%以上。
以 model7作为攻击目标,model1作为训练模型,model0作为验证模型,允许的最大干扰像素值为64(这个参数会影响生成的对抗样本图片的质量),并且对抗样本在验证模型上对正确类别上的置信度小于0.01。
实验结论 :
如上图(左上)条形图是各个模型分别在干净样本和在对抗样本上的分类准确度,从实验的结果来看,仅仅在单个模型上训练的对抗干扰,就能将其他没见过的模型的分类准确度下降到20%以下。
如上图(右)热图,反应每个类别、各个模型在对抗样本上的分类准确率。对抗样本在各个类别的图片上对抗效果都比较理想。
如上图(左下)最大扰动像素值的分布图,大部分的对抗图片的最大扰动像素值是64,可以预见这批对抗图片与原始图片的差异较大。

如图,上图是对抗图片生成的验证码,下图是干净图片生成的验证码;可以看出对抗图片较为模糊,与原图差距非常大,部分图片仅仅只能通过物品的轮廓勉强分辨图片的内容(如椅子、水壶、斧头等),有的图片甚至完全无法辨认(如右一的火箭)。
这是我们初步实验的结果。模型的对抗性和可用性可能需要经过一系列的权衡,最终达到一个均衡的效果。
5. 权衡图片质量与对抗效果
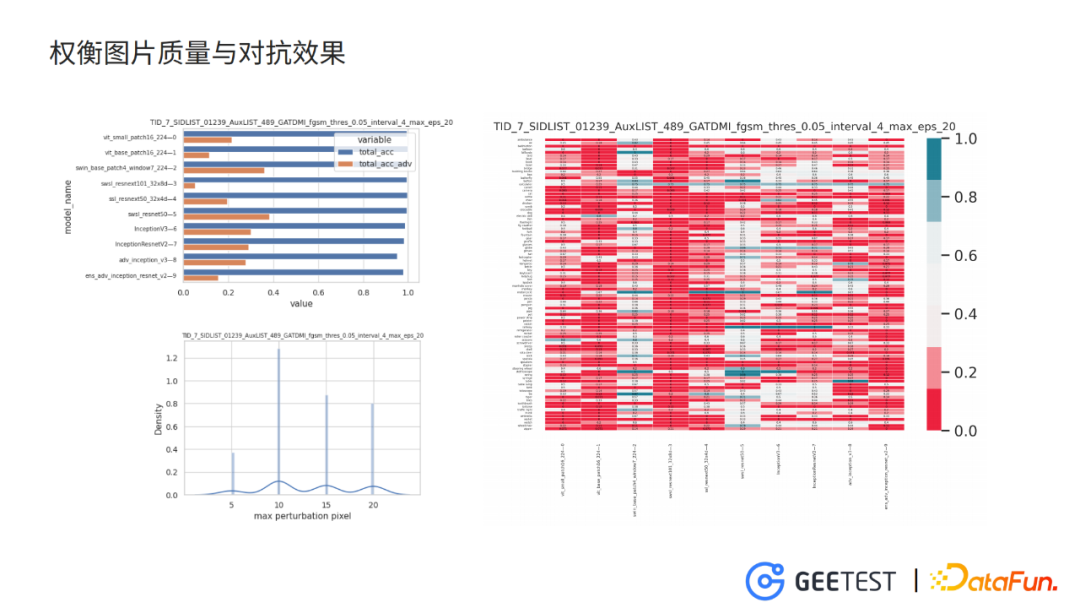
设置最大干扰像素值为64,验证模型置信度阈值0.01时,训练得到的对抗样本图片干扰太过严重,使得图片雪花点比较多、比较模糊,图片可用性小。
逐渐减少最大干扰像素,增大验证模型置信度阈值,同时将训练模型和验证模型配置为多个模型的Ensemble,这样使对抗样本在不损失太多对抗性的情况下,提升图片质量。
以 model7作为攻击目标,model 01239作为训练模型,model 489作为验证模型,允许的最大干扰像素值为20,并且对抗样本在验证模型上对正确类别上的置信度小于0.05。
对抗图片在目标模型上的分类准确度在30%左右,同时在其他没见过的模型上的准确度也在30%-40%,对抗效果与之前的训练设置相比存在下降。
但是,分析最大干扰像素的分布,大部分图片在像素阈值增大到10之后就达到对抗效果,并停止了迭代。此时对抗图片的图片质量能够保证可用性。

图片中虽然还是存在少量比较模糊的图片,比如右上角听诊器,但是大部分图片跟原始图片相差不是很大。在真正使用的时候,我们可以用评估图片质量的算法将这些比较模糊的图片剔除掉。
6. 语序识别的对抗初探
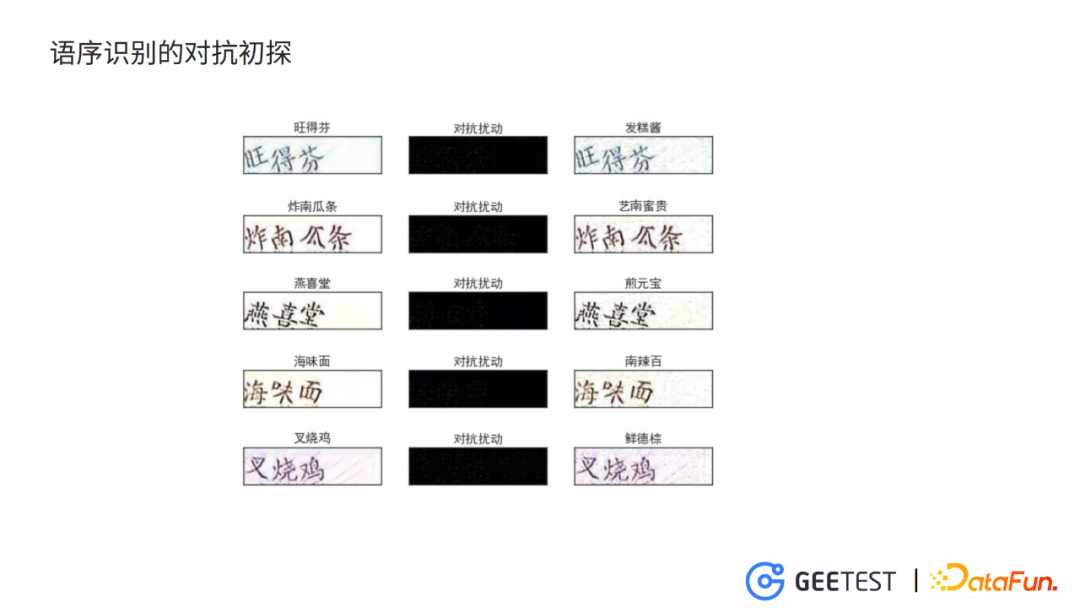
除了对九宫格验证码的破解模型生成了防御性质的对抗样本,在针对语序识别的crnn和针对文字位置识别的目标检测模型的对抗做了初步的探索。
同样是用I_FGSM攻击方法,迭代使crnn模型的ctc loss不断增大,生成的对抗样本在训练crnn模型上输出错误的结果,如“炸南瓜条” 被识别为“艺南蜜贵”,“燕喜堂”被识别为“煎元宝”。但是肉眼看上去,对抗样本与原始的干净样本差别不大。
7. 目标识别的对抗

目标检测对抗样本,我们尝试了针对yolov3的攻击,初始化干扰,加到原始图片上进入yolov3检测模型,迭代更新干扰,最小化真实文字位置的预测置信度。
攻击的结果,如上图yolov3对文字点选验证码中的文字无法完全定位,而且肉眼也几乎无法分辨对抗样本与干净样本的差别。
8. 九宫格对抗样本的工程化
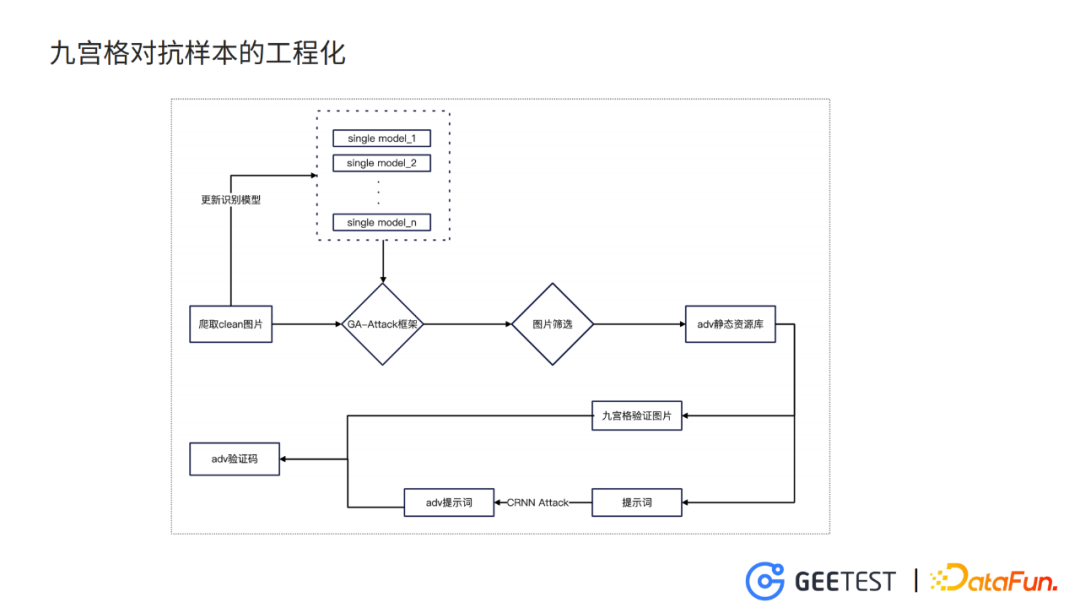
我们先爬取各种需要类别的图,然后更新模型库的每一个模型,进入刚才提到的几何感知的框架,训练得到对抗样本的图片,再经过一轮图片的筛选,就得到一个静态资源库。
而生成九宫格验证码的时候,从静态资源库里提取图片,生成九宫格验证码的图片,再生成干净的提示词,之后利用CRNN的攻击,生成对抗的提示词,组合得到最终的九宫格验证码的对抗样本。
--
03 后续的工作与思考
以上是我们目前做的关于对抗样本在验证码领域应用的一些工作和探索,对后续的工作我们也有一些规划和思考。
1. 基于GAN的生成技术AdvGAN
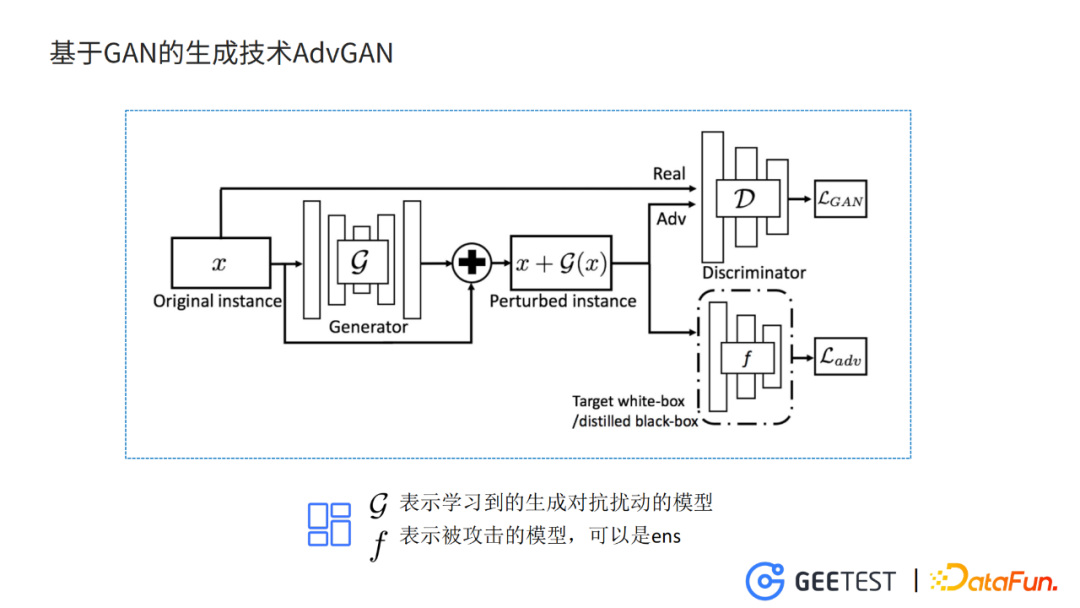
之前我们使用FGSM这个比较简单的方法来生成对抗样本,生成的过程和模型训练的过程是没有办法分开的,这样没有办法把模型的框架完整移植到针对目标检测和针对提示词的攻击上。我们想到换一个框架,用基于GAN的生成技术,比如AdvGAN。
基于GAN的对抗样本生成方式,好处是直接在G模型训练的过程中,将对抗干扰的特征保存在G模型的参数中,实现模型的训练和对抗样本生成的过程解耦。对抗样本的生成过程,不再需要迭代或者优化,提升生成的效率,也减小了部署的成本。
今天的分享就到这里,谢谢大家。
本文首发于微信公众号“DataFunTalk”。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号