陈宏申:浅谈京东电商商品文案挖掘难点与优化实践

导读: 在电商推荐中,除了推送商品的图片和价格信息外,文案也是商品非常重要的维度。基于编码器解码器范式的序列文本生成模型是文案挖掘的核心,但该种方法面临着两大技术挑战:一是文案生成结果不可靠和生成质量不可控,无法满足业务对电商商品文案内容可靠性的严格要求;二是序列文本生成模型经常面临数据坍塌,比较容易生成万金油式的安全文案,文案内容本身的多样性会越来越低,且无法捕捉语言本身的流行或演化趋势。针对以上两大挑战,在以文案生成系统为核心的基础上,引入了文案摘要清洗系统和文案质量评估系统,总结提出了一个通用的电商商品文案挖掘方案。今天将和大家分享京东电商平台的电商商品文案挖掘的优化实践,包括以下几方面内容:
- 电商商品文案挖掘的挑战和方案框架
- 电商商品文案摘要清洗系统的优化实践
- 电商商品文案生成系统的优化实践
- 电商商品文案质量评估系统的优化实践
--
01 电商商品文案挖掘的挑战和方案框架
1. 电商商品文案的应用场景
首先来看一下电商商品文案的应用场景。

电商商品文案不仅可以用于描述商品的独特卖点,同时可以用于介绍商品的一些特质。根据电商商品文案的长度,可分为短文案和长文案。例如,15字的短文案可以体现茅台酒、手机的卖点,同时也描述了商品的特点;百余字的长文案可以描述眼霜、一本书等。
2. 电商商品文案挖掘的两大挑战
基于编码器解码器范式的序列文本生成模型可以用于文案挖掘,就是把商品的一些信息,例如标题、类别等进行模型投喂,然后直接拿某种类型的文案作为一个参考答案进行模型训练和学习。毫无疑问,基于编码器解码器范式的序列文本生成模型,肯定是文案挖掘的核心,但是在业务实践中,该种方法存在两个方面的技术挑战。

序列文本生成模型天然存在生成结果不可靠、生成质量不可控的问题,而京东电商平台对电商商品文案的内容本身的可靠性有着相对严格的要求,这就面临第一个技术挑战:文本生成质量如何控制。
另一个问题是序列文本生成模型经常容易面临数据坍塌。在业务实践中观察序列文本生成模型的结果,经常能看到:如果文本生成的业务场景比较复杂或者编码解码问题本身比较难,序列文本生成模型越倾向于生成那种频率比较高、相对平均且安全的文案;而且该模型在推上线运行后,会学习它自己已经生成的线上文案,长此以往,该模型越会生成那种万金油式的安全文案,线上文案的内容本身的多样性会随着系统的运行越来越低。另外,序列文本生成模型由于模型本身的设计,也不太容易捕捉语言本身的流行或者演化趋势,比如一些新词、新的流行语或时尚一点的东西,该模型都不太可能捕捉得到。这是电商商品文案挖掘的应用实践中面临的第二个巨大技术挑战。
3. 电商商品文案挖掘方案框架
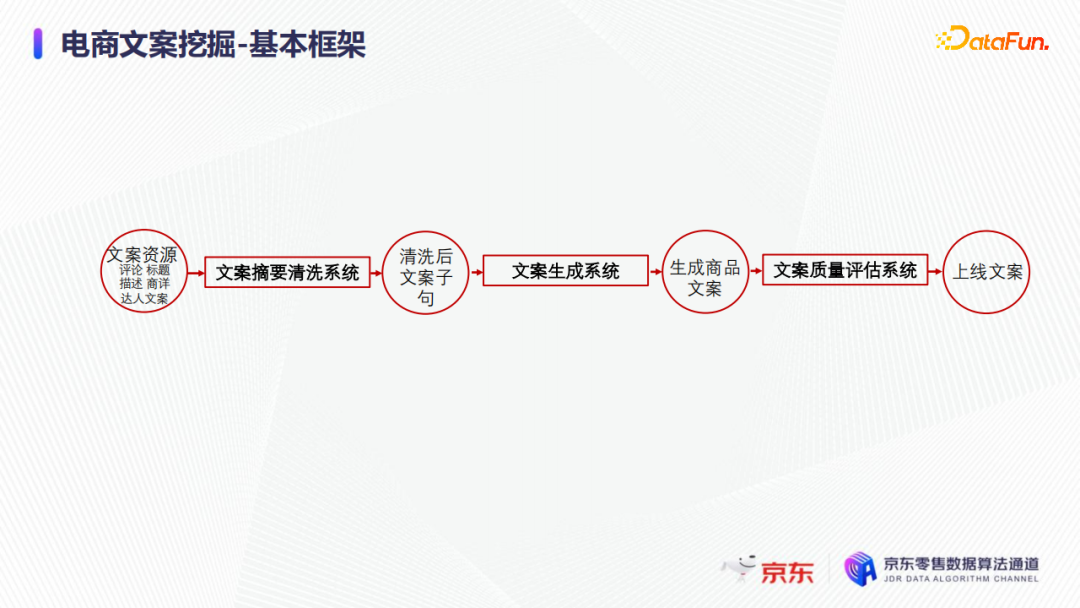
根据业务实践,总结提出了一个通用的电商商品文案挖掘方案框架,如上图所示,挖掘方案的核心是文案生成系统;在此基础上针对文案挖掘的两大技术挑战,引入了文案摘要清洗系统和文案质量评估系统。
文案摘要清洗系统核心解决的是数据坍塌,没有新的资源引入和没有新的创作素材的问题,如果能够将人工创作的一些素材片段引入到文案生成中,那么自然有机会打破数据坍塌,不致使模型收敛到常用热门的平均的表达形式上。
在电商平台的商品文案中,常见的人工文案素材来源有哪些呢?
最为典型的人工文案素材就是商品的评论。电商用户在购买了商品之后会评价,甚至有的用户会撰写很多很长的使用体验;大家买东西的时候也会经常刷评论,看一看比较高质量的用户评论所提示的信息。
另一个人工创作的文案素材来源就是商品标题和商品详情页的商品描述,其中在京东电商平台上的商品详情页常是图片搭配精美的广告宣传来展示的,因此需要提前做一些清洗加工,例如图片文字的OCR,一些异常识别等,然后提取出人工所创作的文案素材,再合并上结构化的商品信息(标题、类别属性等),最终输入到文案生成模型中,用于生成商品的文案。
经生成模型生成的文案需要经过文案质量评估系统剔除不合格的文案。在文案质量评估系统的设计上有较高要求,即剔除不合格的文案后,需要达到人工审核后直接上线的要求。
以上就是电商商品文案挖掘方案的总体框架,接下来将分别介绍该方案框架如何在短文案和长文案中应用落地。
4. 电商商品文案挖掘方案的应用落地
(1) 案例一,短文案应用形式
首先以一个暖水袋的案例来介绍短文案的应用形式。
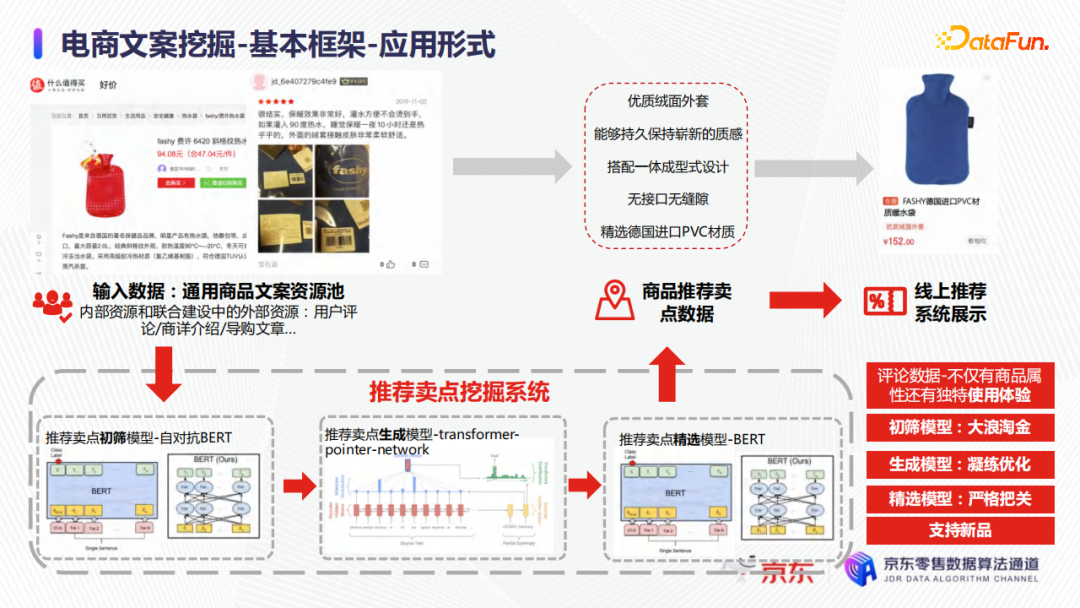
在上图中的左上角,是一个用户对某个暖水袋的评价:保暖效果非常好、灌水方便不烫手、外面的绒非常柔软舒适等。为了最终生成短文案,可以把这整个一大长段的用户评价,按标点符号先截成一些词句,然后这些词句经过一个初筛模型去判别哪些句子可以作为商品的卖点。例如,“灌入90度热水”这个词句是半截话,就不适合作为商品的卖点;“外面的绒套接触皮肤非常柔软舒适”就非常适合作为商品的卖点。有了这样的词句,电商商品文案的表达形式就更丰富,可以输入到文案生成模型中去,上图中的文案生成模型是一个传统的transformer-pointer-network的深度学习模型,后面会介绍相关的优化实践。最后通过精选模型的优质短文案,例如优质绒面外套,能够持久保持崭新的质感,无接口无缝隙等,会推送到线上去做展示。
总结来说,初筛模型就是要从大量不相关的文案词句中摘取一些相关的文案,文案生成模型就是把初筛模型摘取出来的结果进行总结和凝练,精选模型是要把初筛和凝练的结果同时再做一个筛选和把关,最终得到满足业务需求的结果。
(2) 案例二,长文案应用形式
接下来以下图中的案例来介绍长文案的应用形式。
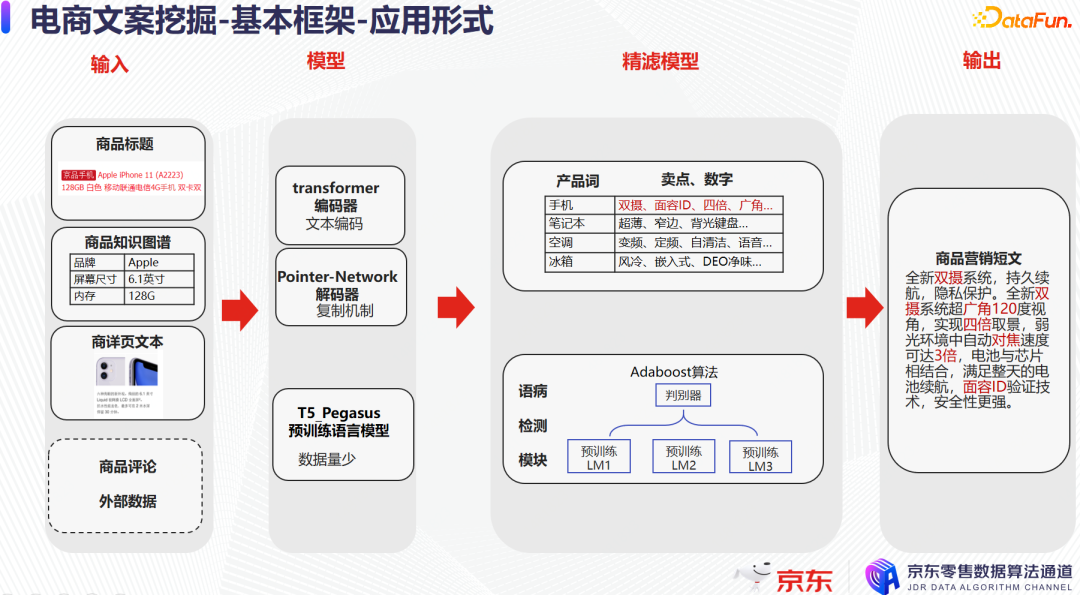
长文案相关的初筛模型是复用短文案的,以短词句形式来抽取文案素材,作为文案生成模型的输入。例如商品标题、商品属性信息的知识图谱、商品详情页和商品评论中抽取出的词句片段,输入到文案生成模型中。在精滤模型上,不仅会用总结的规则去剔除明显出错的一些内容,还会用多组语言模型去做投票比较和筛选,筛选出有明显问题的文案;为了严格确保最终输出到平台的文案质量不会有问题,只要有一个语言模型认定当前的文案可能有问题,则直接剔除该文案。最后输出到平台上,如上图中这样一个百余字左右的商品营销短文。
介绍完电商商品文案挖掘的挑战、方案总体框架及其应用落地形式,接下来将分别介绍三个系统(文案摘要清洗系统、文案生成系统、文案质量评估系统)的优化实践。
--
02 电商商品文案摘要清洗系统的优化实践
如前文介绍,文案摘要清洗系统是需要筛选和清洗商品的用户评价或详情页OCR内容,从中抽取出相关的文案词句作为文案生成模型输入的文案素材。
1. 基于预训练的自对抗筛选模型
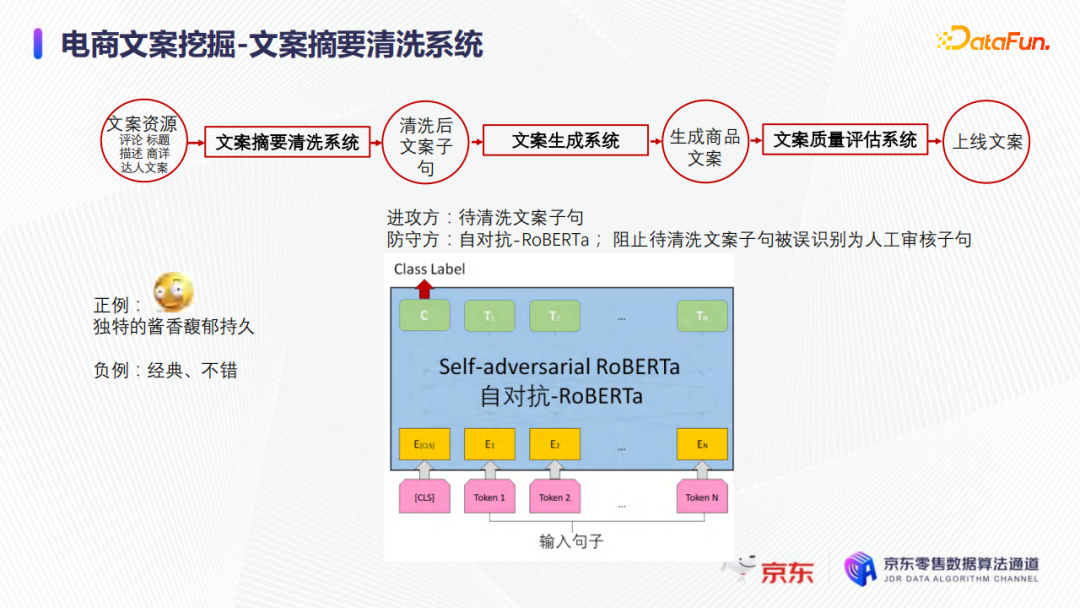
如上图所示,以上是文案摘要清洗系统中的筛选分类模型。从模型结构上看,该模型实际上是一个预训练模型,直接在预训练模型上进行FINE-TUNE和分类;同时也是一个自对抗模型。比如启动阶段只有1000~10000之间的样例,现在希望这个模型可以挖掘出这一类的文案,给出的这些样例可以作为正例,但没有负例,并且实际业务中也没有那么多资源用人工打标的方式去构造什么样文案是不满足业务需求的负例。因此干脆把所有待清洗的文案词句都认为是负例,这样模型就可以学习正例和负例。同时模型学习过程中,需要注意样本的均衡,尤其要特别注意正负样例的采样和采样的倍数,以保证模型不会学得太偏。因为是把所有待清洗的词句都当作负例,负例数量是正例的十倍百倍都不止,所以需要把正例进行加权等处理,同时测试的时候,拿负例作为进攻方。
该模型不需要严格地区分正例和负例,如果能百分之百严格区分的话,那么将得不到任何有效的结果,没法从待清洗的词句中筛选文案词句;该模型是应该有差错的,正是这些差错才能最终筛选出有效结果,即一些和正例可能特别像的待清洗文案词句,就会被模型识别为正例。在训练的过程中,待清洗文案词句被标记为负例;但在测试的时候,因为该模型不可能达到百分百的准确率,比如有2%的失误,就会有2%的待清洗的文案词句可能和正例特别像,就通过了该模型的筛选。以上就是利用对抗的思想去筛选出和正例可能特别像的待清洗文案词句。
2. 采用级联思想的文案筛选优化实践
但如果只筛选一遍,比如有99%的准确率,1%的待清洗文案通过筛选,在实际业务中筛选出来的文案仍然是一个非常大的量级,同时依然包含了大量不满足业务需求的文案词句,例如负向情感问题、和商品不相关的问题等。因此采用了级联的思想,连接多个模型,通过层层过滤、逐层筛选清洗的方式,筛选出质量非常高的文案词句,如下图所示。因为文案摘要清洗系统的原则是宁可错杀,不可放过低质量的文案词句。
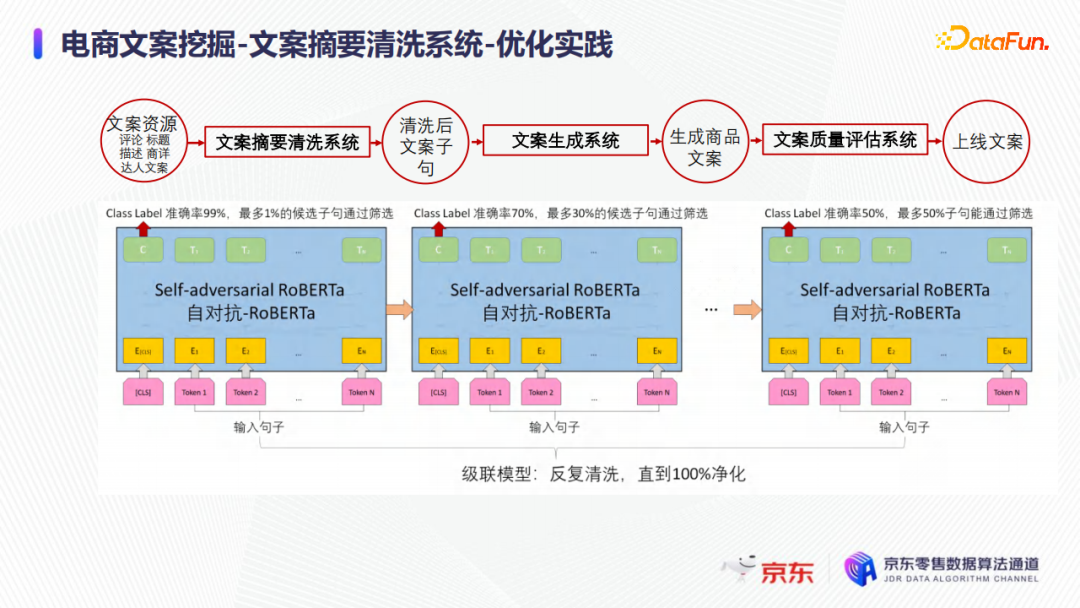
在实际业务中,虽然级联的这些模型的结构和框架相同,但每个模型的训练目标是不同的,例如有区分情感的,有区分和商品相关性的,并且初期的第一个阶段,仅仅是做一个笼统的清洗,相当于是孔比较大的筛子,例如只要和人工采集的文案正样本有一点不像的文案词句,就会被剔除。
--
03 电商商品文案生成系统的优化实践
在文案生成系统中,实际业务中使用了非常经典的transformer-pointer。
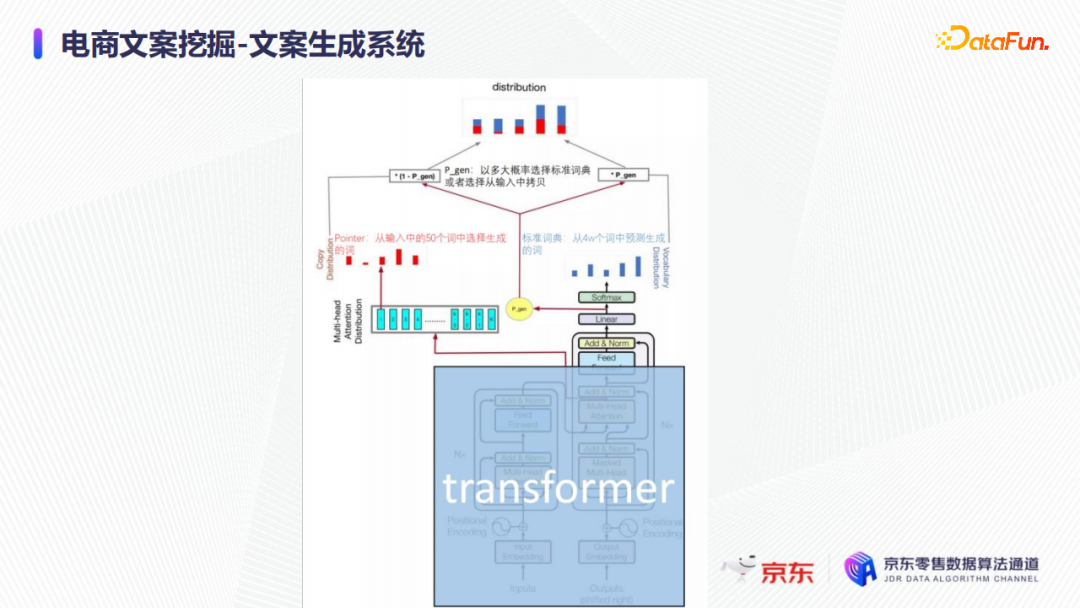
Transformer可以从标注的,比如四万个词或十万个词里面,去预测文案生成的每一个词串当中下一个词可能是哪个;而Pointer就是从输入的,比如50个词或100个词猜,因此引入Pointer之后,文案生成的难度大大降低,同时文案生成的效果也有比较大的提升。如上图所示,如果只有右边的标准transformer的话,文案生成的难度会大很多。
1. 引入超大规模预训练语言模型的优化实践
在业务实践中,引入了超大规模预训练语言模型来提升文案生成流畅度和多样性。
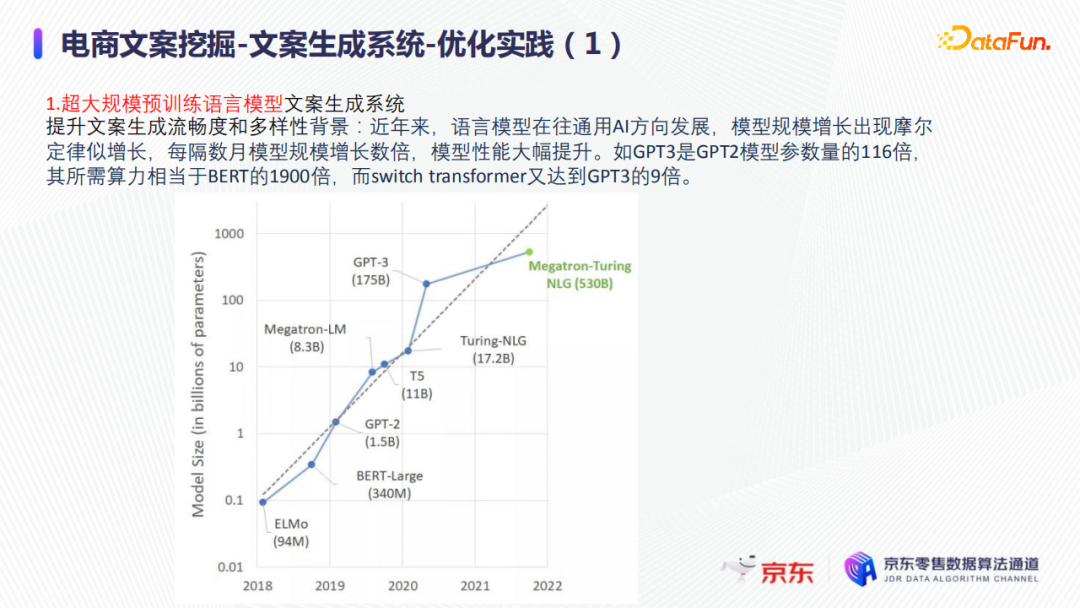
近几年来,语言模型在往通用AI方向发展,模型规模增长出现摩尔定律似的增长,即每隔数月模型规模增长数倍,模型性能大幅提升,如上图所示,GPT3是GPT2模型参数量的116倍,其所需算力相当于BERT的1900倍,而switch transformer又达到GPT3的9倍。现阶段的实际业务仍然使用的是T5级别,相当于预训练的大型transformer,并且是蒸馏之后的一个版本,规模上要小很多,也更实用。
超大规模预训练的语言模型在业务实践中主要带来了哪些方面的收益呢?电商业务涉及到很多品类,比如有家电、服装等等,如果对每一个品类都去设计一个模型,可能需要有30多个模型。使用超大规模预训练的语言模型,可以使用一个模型搞定所有的品类。另一好处是针对一些小的品类。有一些小的品类,训练样本非常少,通常只能借助迁移学习,用其他大的品类的数据来训练模型,然后再用几十条、上百条或者上千条极长尾的小品类去FINE-TUNE这个模型,这是一个妥协的方式,但超大规模预训练的语言模型是在一个通用的语言模型上去做FINE-TUNE,则不需要另外再去FINE-TUNE。
2. 后验式蒸馏提升中长尾商品文案生成效果的优化实践
在电商场景下,中长尾商品特别多,并且商品的热度分布极其不均,二八效应非常显著。例如,80%的商品都是没有任何用户评价,所有商品的平均用户评论数大概是3~5,这意味着,只有少部分商品有上万条,甚至几十万条评论,商品的长尾分布现象极其严重。热门商品的素材资源(用户评论、问答等)丰富,热门商品文案生成较为容易;但中长尾商品素材较少,中长尾商品文案生成较难。
借助前面提到的超大规模预训练的语言模型,可以缓解中长尾商品文案生成难的问题,但当线上无法采用那么大的模型时,怎么去解决这个问题呢?
在实际业务中进行如下优化:将热门商品上如用户评价等丰富的素材都用于训练文案生成模型,然后将热门商品文案生成模型的知识做蒸馏,后验式蒸馏到中长尾商品文案生成模型中,也就是把热门商品的用户行为蒸馏到几乎没有用户行为的商品上去,来提升中长尾商品文案的生成效果。
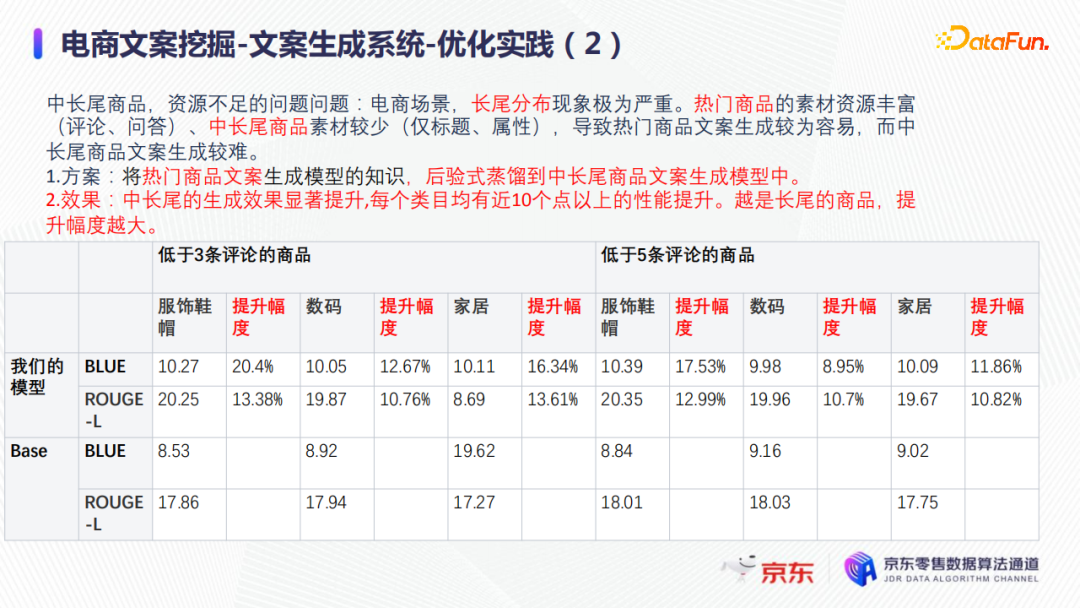
最终得到的实际效果如上图所示:每个类目上的中长尾商品的生成文案质量都几乎有10%以上的提升,并且越是长尾的商品,文案生成效果提升越为显著。在短文案和长文案的具体挖掘应用实践分别在已发表的两篇文章中:
《(AAAI21) Probing Product Description Generation via Posterior Distillation》,
《(SIGIR20) User-Inspired Posterior Network for Recommendation Reason Generation》。
其中,在长文案的应用实践中,还加入中间隐藏层的知识蒸馏,去降低信息短路,以提升知识蒸馏的效率,如下图所示。
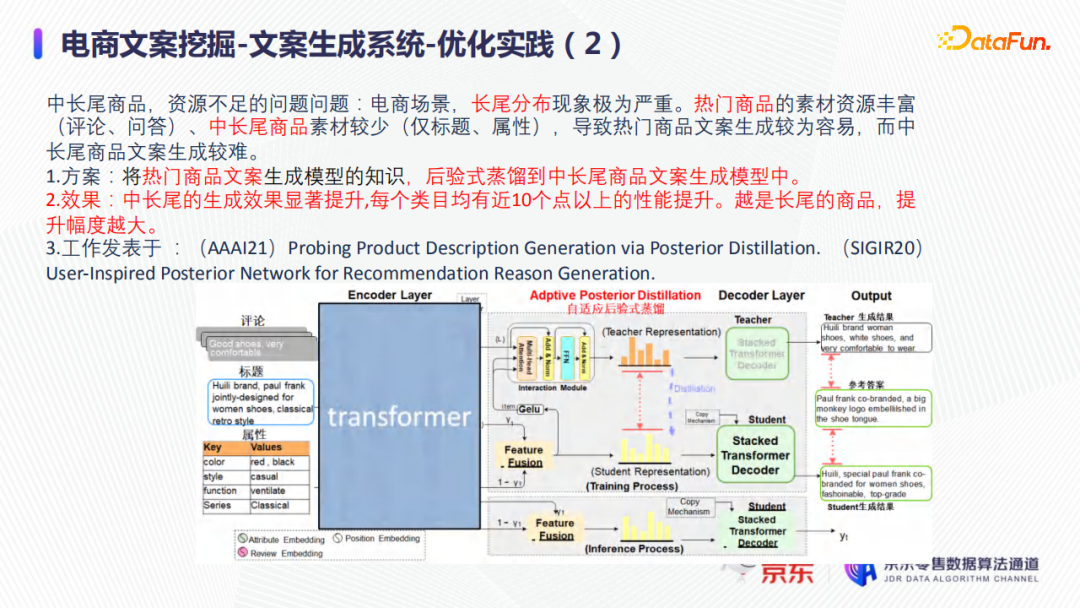
在短文案的应用实践中,模型的知识蒸馏仅限于学习预测时候的分布,但是应用于生成长文案的模型本身比较大,如果仅仅在输出(Output)这一部分进行知识蒸馏提取的话,信息丢失比较多,因此必须多看几个部分。
3. 基于参考模板的文案生成优化实践
除了前面提到的小品类由于商品的热度分布不均没有充分的训练数据外,新的文案类型也常面临着训练数据不足,尤其对比那些经长时间的业务运转已经累积了数百万训练数据的文案类型,起步阶段的新文案类型可能只有百余篇、千余篇可用于训练的文案。同时线上环境受限于计算资源,无法使用结构上特别复杂的模型,就没有那么强的能力生成优质的商品文案。
那要如何给一个新商品去生成优质的文案或新的文案类型呢?
首先找出类似商品的文案,参考这些文案,整理人工参考文案模板,并将参考文案模版做为文案生成模型中预测时的输入,因此如下图所示,在预测生成商品文案的词串时,下一个词将有三个来源:① 大概几万字的常用解码词典,② 约几十个的类似商品的参考文案模板词,③ 数百的商品文案生成的常规输入,如品类、品牌、标题等。其中,类似商品的参考文案模板的引入大大降低了文案生成的难度,因为相当于模型提前看到了参考答案。
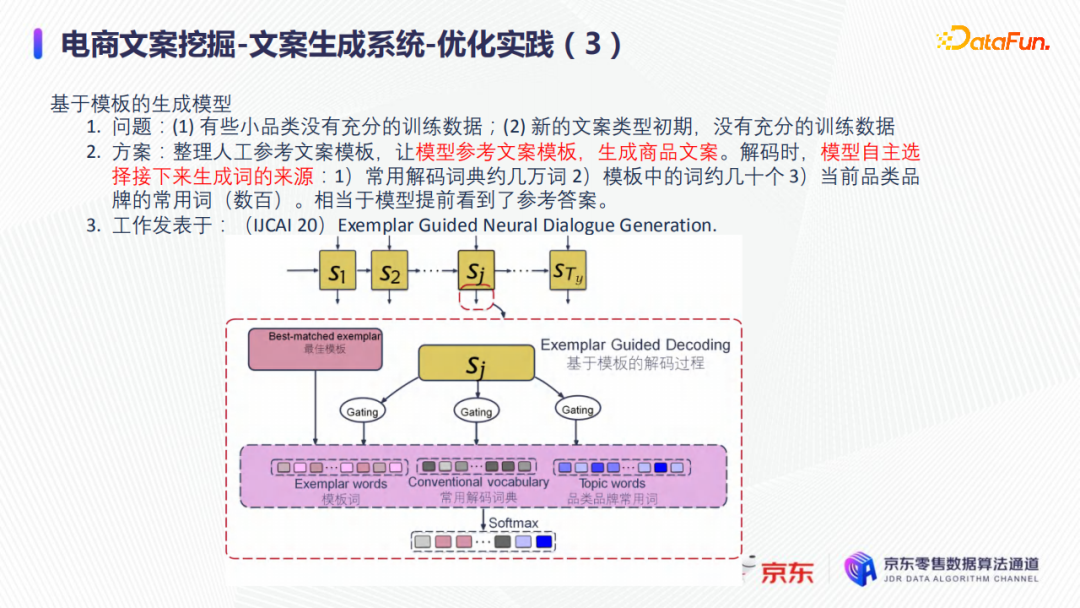
如果从本质上看,在模型框架上,非常像transformer-pointer模型,但相比于标准的transformer-pointer,增加了另外一个信息copy的来源:类似商品的参考文案模版词,因此需要引入一个检索模型;该检索模型可以用外援的,也可以用in-value计算,也可以用向量召回的方式去做类似商品的文案的提取。
4. 基于训练集增强的文案生成优化实践
针对训练数据不足,如下图所示,进行了以下两种方式的训练集增强:一是利用同义词替换从词的角度做训练数据量的增加;二是利用句子改写,仅变换自己的表达形式,即同义不同表达方式,从句子的角度上做训练集增强。在具体落地方案上,同义词替换可以采用BERT Mask的方式;句子集上的替换,直接利用比较成熟的中英文互译系统,将中文先翻译成英文,再从英文翻译成中文。
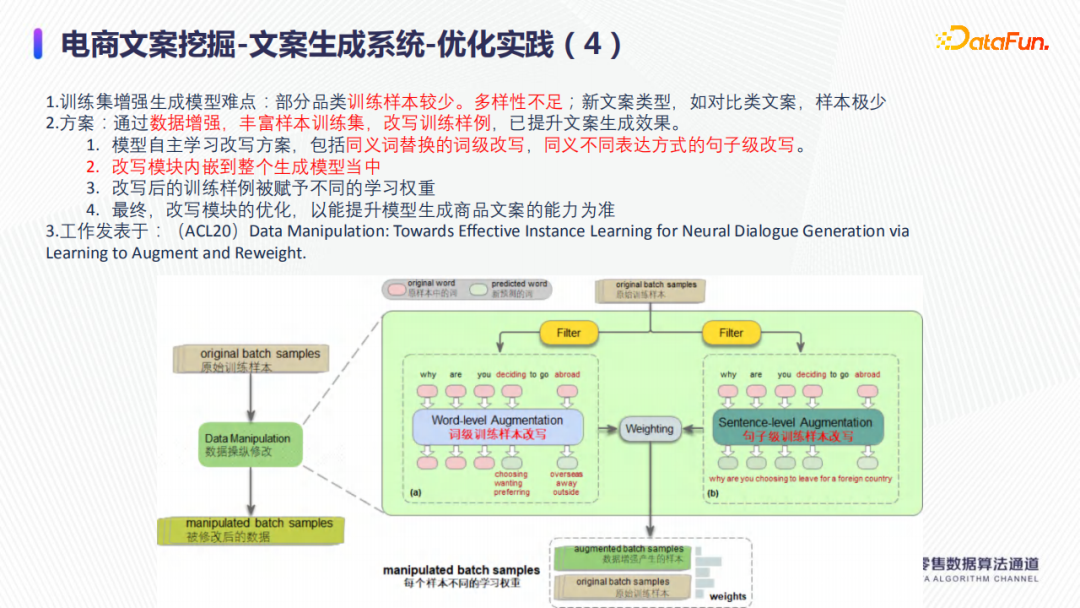
当然,无论是词级别的样本的数据增强,还是句子级别的样本的数据增强,都可能是带噪音的,因此在实际的应用中,需要给样本赋予不同的学习权重。
简单的做法,可以是增强的样本的学习权重比较低,质量比较可靠的原始样本学习权重相对高一点。
灵活一点的做法是引入一个验证集去做测试,比如一个增强的样本的初始学习权重和原始样本的学习权重一样,如果最终的性能表现在验证集上测试表现更好,就维持该学习权重。如果最终的表现更差,则自动降低该增强的样本的学习权重,来避免增强的样本带来的负面影响。因为做训练集增强是希望生成模型可以学到不同类型的句子表达,如果带来负面影响,则应降低其对效果的影响,训练集增强优化始终以提升文案生成的能力为准。已发表论文做了详细的阐述:《(ACL20) Data Manipulation: Towards Effective Instance Learning for Neural Dialogue Generation via Learning to Augment and Reweight》。
--
04 电商商品文案质量评估系统的优化实践
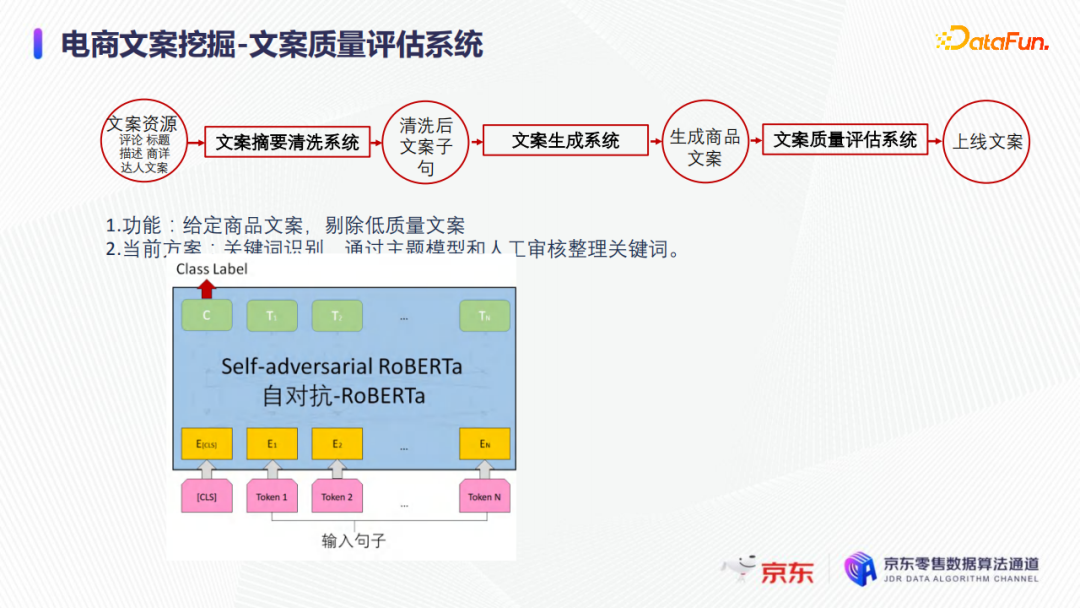
文案质量评估系统是要剔除生成的低质量文案,可以复用文案摘要清洗系统的基于判别的模式,如下图所示。也可以用如GPT或者单纯的预训练语言模型等方式去判别句子的流畅度,或者通过主体模型和人工审核整理的关键词或其他的各个方面去判别文案的质量。当然也可以结合不同模态的商品信息,进行文案质量评估。

今天的分享就到这里,谢谢大家。
本文首发于微信公众号“DataFunTalk”。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号