罗强:腾讯新闻如何处理海量商业化数据?

导读: 随着信息化时代的来临,信息呈现出爆炸式的增长。尤其是在移动互联网的推动下,每天大量信息涌入让人们应接不暇,腾讯新闻客户端的出现,就是以帮助用户寻找有用信息而出现。这时,面对海量的数据、繁多的业务,如何处理手中的数据,利用数据赋能是今天会议讨论的重点。
今天的介绍会围绕下面三部分展开:
- 背景介绍
- 海量日志处理架构
- 数据应用举例
--
01 背景介绍
首先介绍一下腾讯新闻的背景。
团队目前承担腾讯新闻客户端,体育和新闻插件的创新业务的输入,广告和用户行为的数据采集、处理、计算和分析的工作。最大的特点就是数据多、业务广。数据庞大,业务应用多样,例如数据会被用于报表展示、算法模型的训练、产品决策等场景。
--
02 海量日志处理架构
1. 总体架构
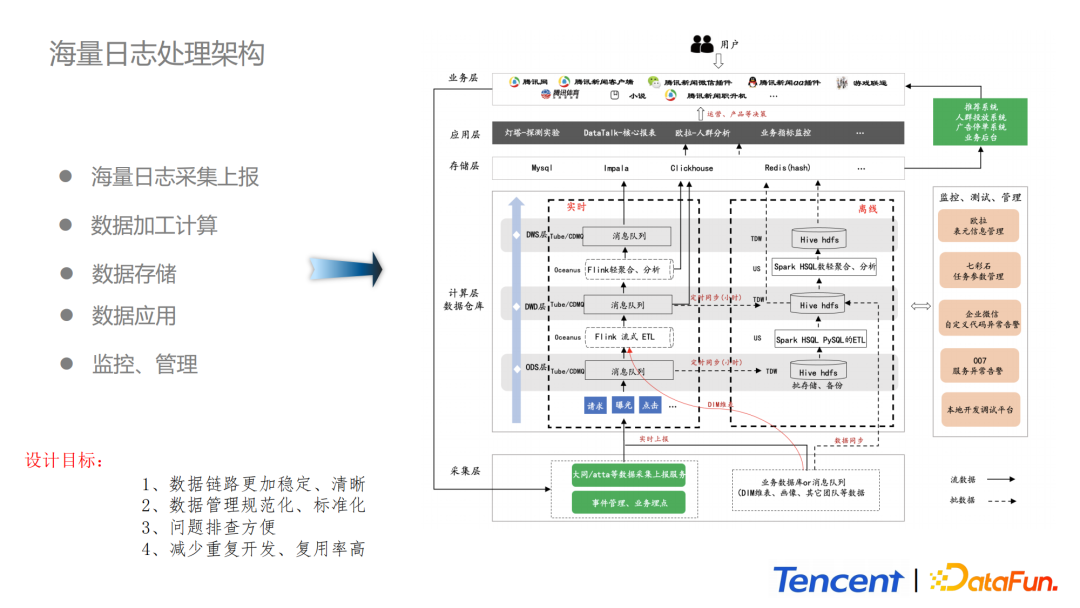
众所周知,业务在实际开发过程中需要一套有效的数据管理、组织、处理方法,使得整个数据体系更加有序。上图展示的是腾讯新闻整体的处理架构,包括:
-
采集层:依托于大同数据采集上报服务,大同是目前内部力推的数据治理的客户端上报平台。
-
计算层:包括实时计算与离线计算。离线是基于TDW(hive表)和HDFS建立的各个业务请求、点击、曝光等维度的数据表,同时利用欧拉平台的数据分层、数据分类、数据血缘等能力完成数据资产的管理。实时计算方面使用Oceanus平台和内部的Datahub完成整个数据的开发。这个设计解决了需求多变、代码复杂、系统高可用、海量数据低延时接入、数据高复用等问题。在ODS原始数据层、DWD数据明细层、DWS主题轻汇聚层,我们采用集团的Tube消息中间件,以及BG内部的CDMQ。Tube消息中间件解决海量数据及时接入的问题。数据各层由流式计算引擎进行业务的清洗与转化,结果会回流到下一个消息中间件,供下游使用。对于ODS层的实时数据我们会每隔一个小时同步到TDW,大概存储周期为3天,这部分数据既能用于离线计算,又能作为数据的备份。比如一些链路发生异常,可以利用这部分数据进行问题排查和数据恢复。
-
数据存储层:组件比较丰富,有Impala、ClickHouse、Mysql、Redis等。Impala主要应用在内部灯塔平台和Datatalk平台进行报表和数据探测的工作中。
2.数据上报
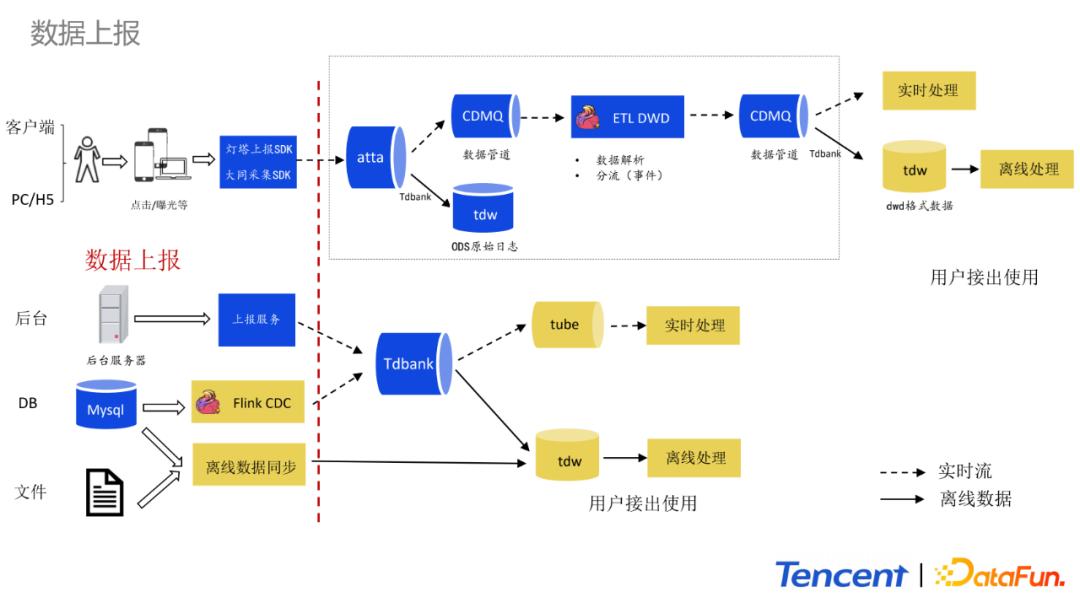
这部分详细地讲解整个数据上报体系。目前数据上报会根据数据源进行分类上报。数据源主要分为四大类:
-
客户端:包括客户端、PC、H5这类数据。采用灯塔SDK进行上报,使用大同SDK进行采集。同时会基于大同平台进行事件的管理,例如埋点的事件管理和统一参数的上报。大同平台有效地解决需求散乱、数据难校验、上报不规范等问题。在整个实时链路中,这部分数据接着会通过atta分发到TDW(hive表)和CDMQ实时中间件供下游进行实时消费。
-
后台:主要包括后台服务器日志的上报。这部分数据会上报到Tdbank。Tdbank会同时将数据转化为TDW(hive表),同时还会分发到Tube实时流中,供下游进行实时消费。
-
DB:跟后台数据上报类似。以前的方式是DB同步,例如按小时更新或者按天更新将Mysql更新数据放到Hive表中。目前,会通过Flink CDC监听Mysql的binLog实时更新业务维表。
-
文件:例如业务配置和运营的配置文件,量不大,会通过手动的方式离线同步到TDW(hive表)中去。
3. 实时计算框架
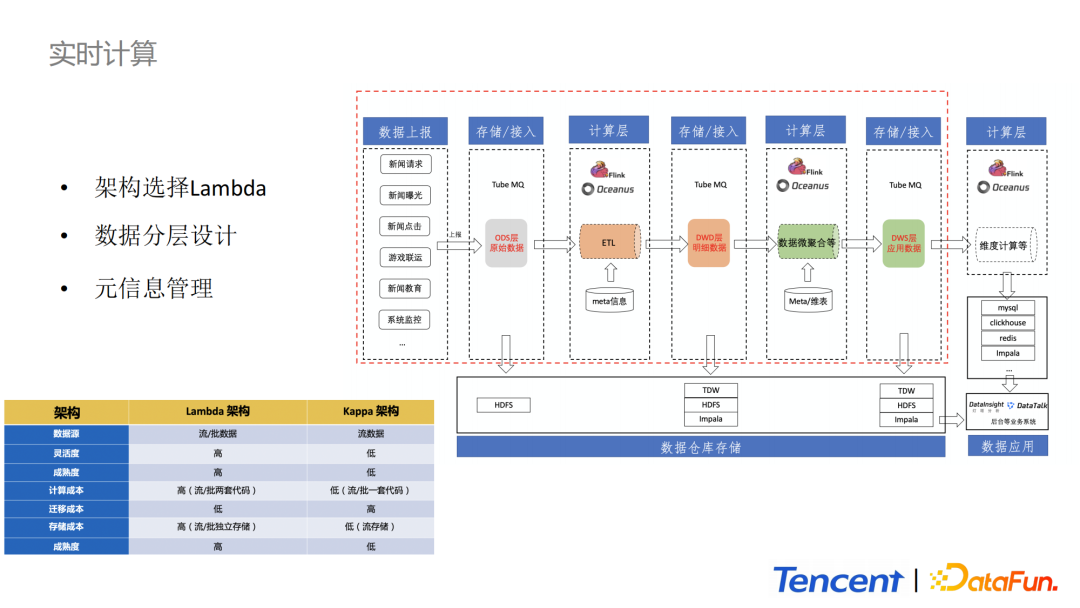
实时计算架构整体上选择Lamda架构,ODS层到DWD层数据的处理,实时和离线部分是公用的,也体现了流批一体的概念。下面就分模块介绍实时计算部分的整体架构。
-
存储/接入层:负责客户端与后台的实时中间数据上报。数据被上报到消息中间件中,消息中间件一方面负责消息的存储,另一方面承担数据分发给离线和在线处理平台的功能,同时它是数据源和数据处理系统之间的桥梁。
-
DWD:DWD层的设计是为了减少下游频繁对ODS层数据进行消费。对于新的需求开发我们只需要申请DWD层的Tube消费节点即可。这样处理极大地节省了计算单元。
-
计算层:主要负责数据的ETL、维表关联、特征抽取等业务逻辑的计算。
-
数据仓库存储层:主要采用TDW(hive表)、HDFS和Impala作为存储介质。ODS层的原始数据默认保存在HDFS上,保存周期默认为3天。
另外,DWD和DWS层数据支持写入TDW和HDFS去做离线计算。同时也支持导入Impala进行存储,以供灯塔平台和DataTalk平台等进行数据探测和报表展示。
4. 离线计算框架
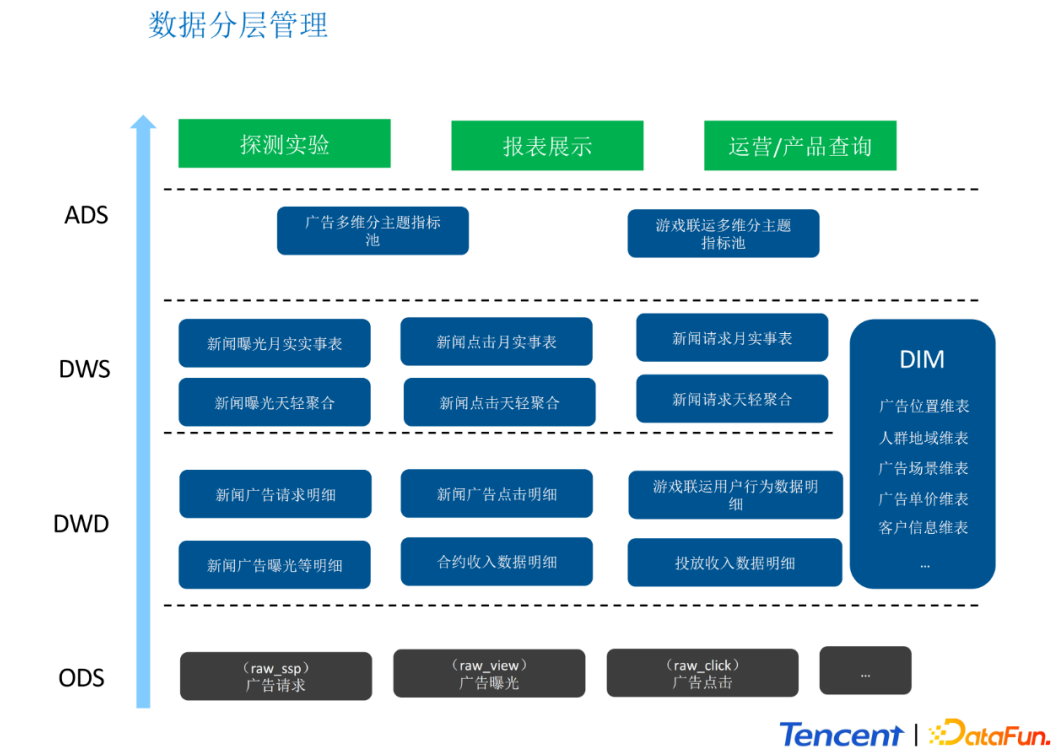
针对离线计算部分,我们对数据进行了分层管理,简单概括为以下四层:
-
ODS:原始数据存储层。存储大同上报或后台上报的原始数据,例如广告点击曝光等数据。
-
DWD:数据明细存储层。存储经过清洗和标准化的数据。
-
DWS:数据轻度汇合层。基于单业务场景或者单用户行为的汇总。
-
ADS:数据应用层。只要存储最终的,呈现结果的数据。例如存储报表和进入Impala之前的数据,或者 存储需要进入Redis、ClickHouse等的数据。
我们对数据层的调用进行了约束:
-
DWD层必须存在。且所有的ETL逻辑都在DWD层上。
-
DWS层优先调用DWD层。ADS优先调用DWS层。
-
DWD层不做过多与DIM维表的关联。
同时我们对于表的命名进行规范,该命名规范使得杂乱无章的数据表变得规范有序,使得内部业务合作变得便利。具体规范如下:

5. 数据质量及链路保障
关于数据质量以及链路保障,分为在线和离线两部分进行讲解。
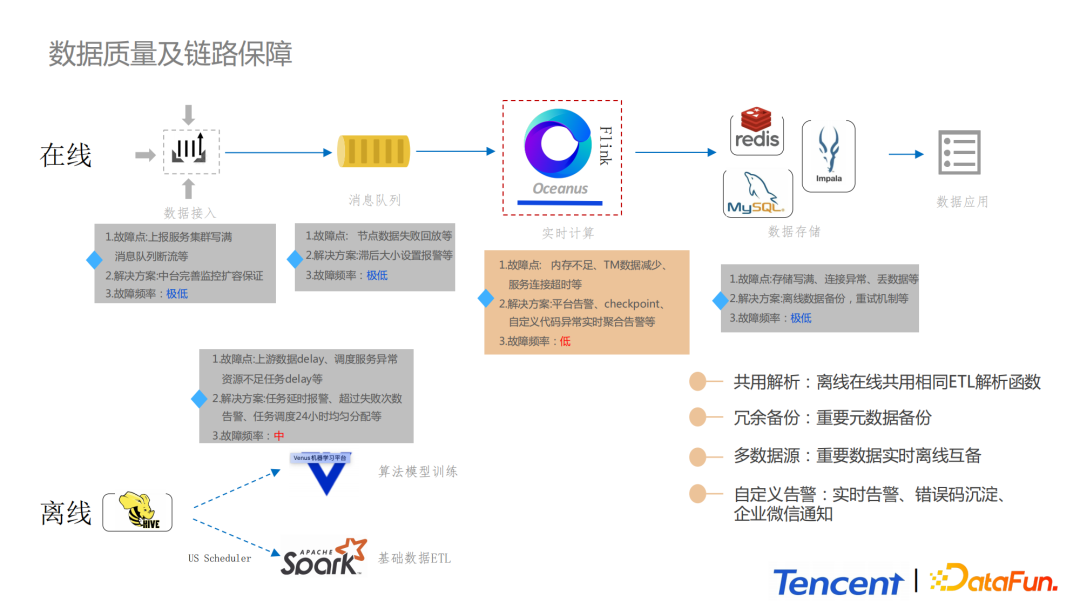
离线部分,一方面会依托平台提供指标监控告警以及SLA保障的能力;另一方面,在代码层面进行设计,通过异常捕获、分级告警,出错分层管理,重置机制等,提高整个系统的高可用和稳定性。
实时部分,最容易出错的就是Flink实时计算部分,例如出现内存不足、TaskManager突然减少、网络抖动导致的服务连接超时等。我们会依托于Oceanus平台提供的告警能力。我们设计了一套代码层级的告警作为报警独立模块。首先我们通过try catch捕捉Flink Task中的异常,同时这些报警信息会被发送到消息中间件,然后报警信息会在消息中间件中被聚合,为了预防报警疲劳,报警信息会被分级,错误码会被沉淀,然后报警会统一通过企业微信进行通知,正常情况问题可在5min内被解决。
6. 总结
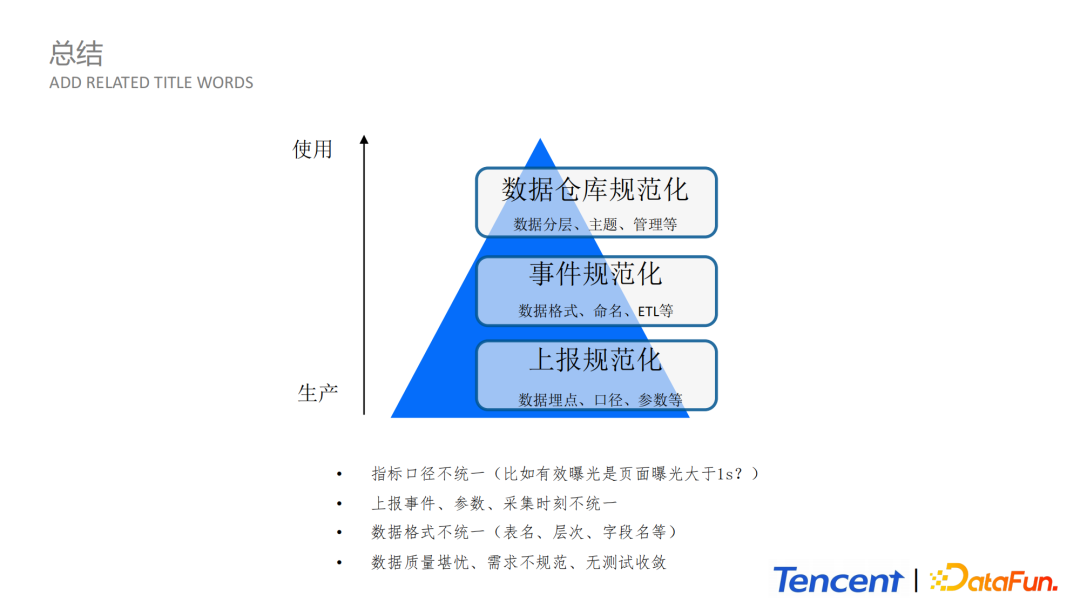
我们在实时和离线对海量日志处理设计方案上的收益可以总结如下:
-
首先,通过大同平台上报,使得上报更加规范化;
-
第二是事件规范化,各个BG之间可以应用同一规范数据,有统一规范的数据格式和命名规则;
-
第三就是数据仓库规范化,包括分层、主题、管理等,使得整体管理更加清晰。
03 数据应用举例
1. Flink CDC(Change Data Capture)- DB数据同步技术
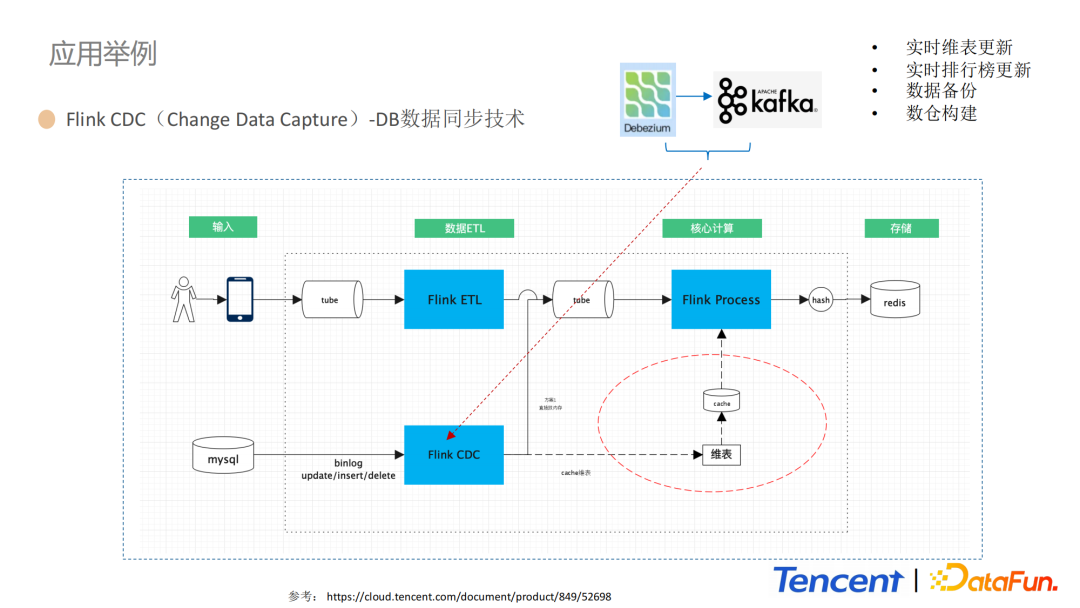
这部分,我们通过Flink CDC的DB数据同步技术,进一步举例说明我们的海量数据处理流程。上图是通过Flink CDC进行实时更新维表和实时排行榜更新的设计方案,整体主要包括输入数据源、Flink实时ETL模块、Flink核心计算模块和数据存储模块四部分。Flink内部继承开源组件Debezium和Kafka,CDC技术可以实时捕捉Mysql的增删改,然后将数据同步到下游,同步到多个数据源,然后通过抽取数据库日志的方式完成数据上报。
2. Flink CDC实现方法

Flink CDC实现方式主要有两种:SQL模式和自定义反序列化模式。个人倾向于选择第二种方式,可以更加灵活地实现业务需求。通过实现反序列化相关接口,数据库的变更数据可以通过SourceRecord得到,解析之后的数据可以通过collect进行收集然后传到下游进行消费。
今天的分享就到这里,谢谢大家。
本文首发于微信公众号“DataFunTalk”。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号