苗大东:京东基于强化学习的电商搜索排序算法

导读: 电商场景的搜索排序算法根据用户搜索请求,经过召回、粗排、精排、重排与混排等模块将最终的结果呈现给用户,算法的优化目标是提升用户转化。传统的有监督训练方式,每一步迭代的过程中优化当前排序结果的即时反馈收益。但是,实际上用户和搜索系统之间不断交互,用户状态也在不断变化,每一次交互后排序结果和用户反馈也会对后续排序产生影响。因此,我们通过强化学习来建模用户和搜索系统之间的交互过程,优化长期累积收益。目前这个工作已经在京东全量上线。
今天的介绍会围绕下面五点展开:
- 搜索排序场景及算法概述
- 强化学习在搜索排序中的建模过程
- 基于RNN用户状态转移建模
- 基于DDPG的长期价值建模
- 规划与展望
--
01 搜索排序场景及算法概述
首先和大家分享下搜索排序的典型场景以及常用的算法。
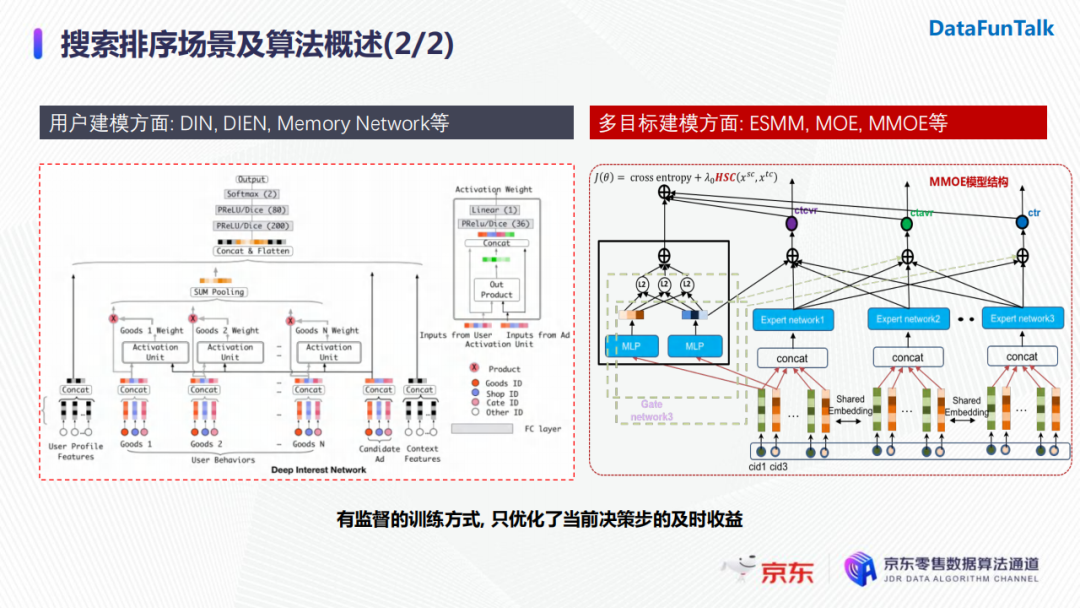
搜索排序场景下的主要优化目标是提升用户转化率,常用的算法分别从用户建模角度(DIN、DIEN、Memory Network等)和多目标建模角度(ESMM、MOE、MMOE等)进行设计。这些模型都采用了有监督的训练方式,在每一步迭代的过程中都是优化当前排序结果的即时奖励。而实际上用户和搜索系统之间存在交互,用户状态是不断改变的,这也使得每一步排序结果和反馈跟后续排序有相关性。为了提升搜索精排的效率,我们使用强化学习来建模用户和搜索系统之间的交互过程,并且考虑对后续排序结果影响带来的长期价值。
--
02 强化学习在搜索排序中的建模过程

我们的工作经过整理后发表在2021CIKM上,接下来介绍的算法也主要与这篇论文相关。
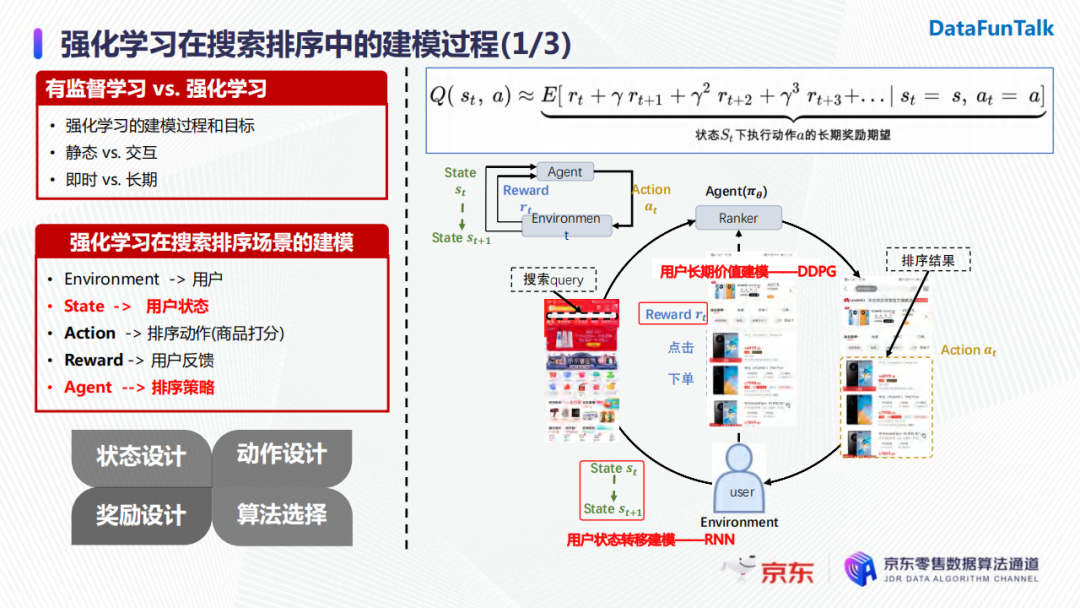
首先介绍强化学习在搜索排序中的建模。强化学习的优化目标是长期价值的期望最大化。如上图公式中所示,长期价值期望Q是在一个状态下,执行一个动作后,当前时刻的即时奖励和后续时刻带来的累积折损奖励之和。它和有监督学习的最主要区别在于后者通常优化当前决策带来的即时收益,而强化学习是去优化决策的长期价值。
在搜索场景下强化学习的建模过程如上图所示,当用户(即强化学习中的environment)发起一次搜索请求时,我们的排序引擎会基于当前用户的状态,选取一个排序动作(排序动作即为对候选商品进行打分)并将排序结果呈现给用户。用户在看到排序结果后会做出一系列反馈,如下单或者点击。此时,用户的状态会发生变化,排序模块会收到用户的反馈(即奖励)。排序模块收到奖励之后会对策略进行迭代优化,进而在收到下一次用户请求时会基于新的用户状态和排序策略进行下一步动作的执行。
基于上述完整算法流程,我们需要对用户状态进行建模,并且对排序策略建模优化长期价值。强化学习的建模思路主要依照其四要素:状态、动作、奖励的设计以及算法的选择。在业界对于强化学习在搜索排序的应用也有一些研究,我们主要参考了阿里巴巴的一篇论文以及2019年YouTube强化学习在推荐中的应用的论文。但是,经过一些实验后,我们最终的方案和业界还是存在比较大的差异。

首先,阿里的那篇文章是建模用户在单次搜索中多次翻页情况下的序列决策过程,即当用户在一次请求后,模型会考虑当前页的及时反馈以及后续翻页后反馈带来的影响,对应的优化目标是用户单次搜索多次翻页的场景价值。而我们的方案进一步考虑了用户多次搜索的决策过程,因为用户在发生购买行为前会经过一系列搜索决策。具体地,我们会考虑用户在本次搜索结果的即时奖励以及对后续搜索结果影响的长期价值,对应的优化目标是用户在整个搜索决策过程中的长期价值。结合具体的建模过程以及工业界落地的时候针对时效性的考虑,我们的技术路线主要包括两个方面:
- 对状态的建模,使用RNN来表征用户的状态以及用户状态的转移;
- 对用户长期价值,使用DDPG进行建模。这一步需要以RNN状态转移建模作为基础,结合动作设计、奖励设计以及算法的选择来完成。
--
03 基于RNN的用户状态转移建模
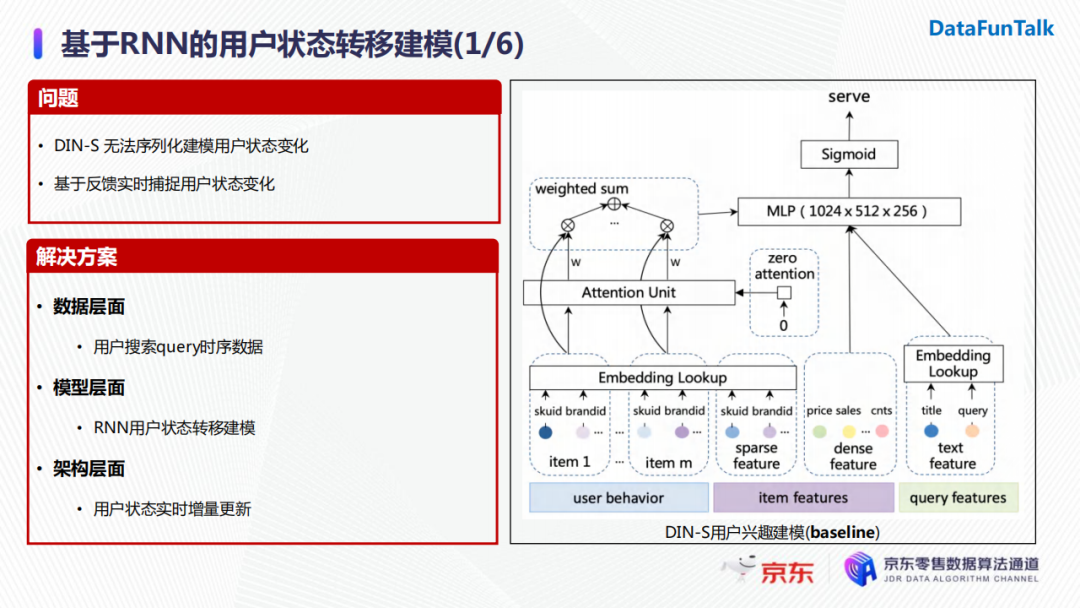
我们线上的baseline是一个基于DIN的模型, 建模目标商品与用户历史行为序列中商品的关系,从而对用户的状态进行表征。但是我们还希望序列化建模用户的状态变化,这是DIN无法实现的。与此同时,线上的用户状态也在实时不断地变化更新,所以我们需要通过一种方式实时捕捉线上的反馈,并对用户状态的变化做一个表征。具体解决方案分为三个方面:
数据层面:用户搜索query的时序数据;
模型层面:选择RNN来建模用户的状态转移;
架构层面:因为涉及到用户在线的状态更新,所以会有加入用户状态实时增量更新的一个通路。
1. 数据层面
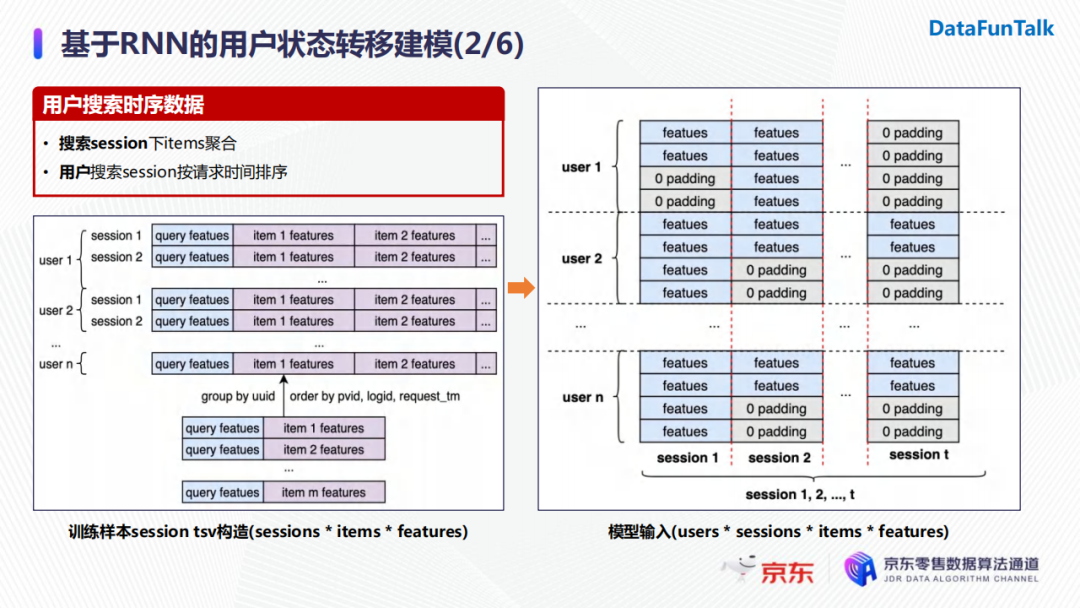
在数据层面,通常来说,训练样本的构造方式是用户在某次搜索下的所有商品,并进行展开,如上图左下所示,这些样本就成为传统有监督学习的训练数据。为了把用户的搜索数据进行时序展开,我们进行了两步操作:
首先,我们会把用户在一个搜索session下所有的曝光商品结合在一起(无序的);然后,用户的搜索session会按照时间进行排序,并将其放入用户索引下。
在样本输入模型之前我们需要对其进行转化。比如在训练RNN模型时,输入的batch size即为用户数量,在RNN每一个time step输入用户的一个session(即用户的一次请求),其中包含请求中所有商品的特征。
2. 模型层面
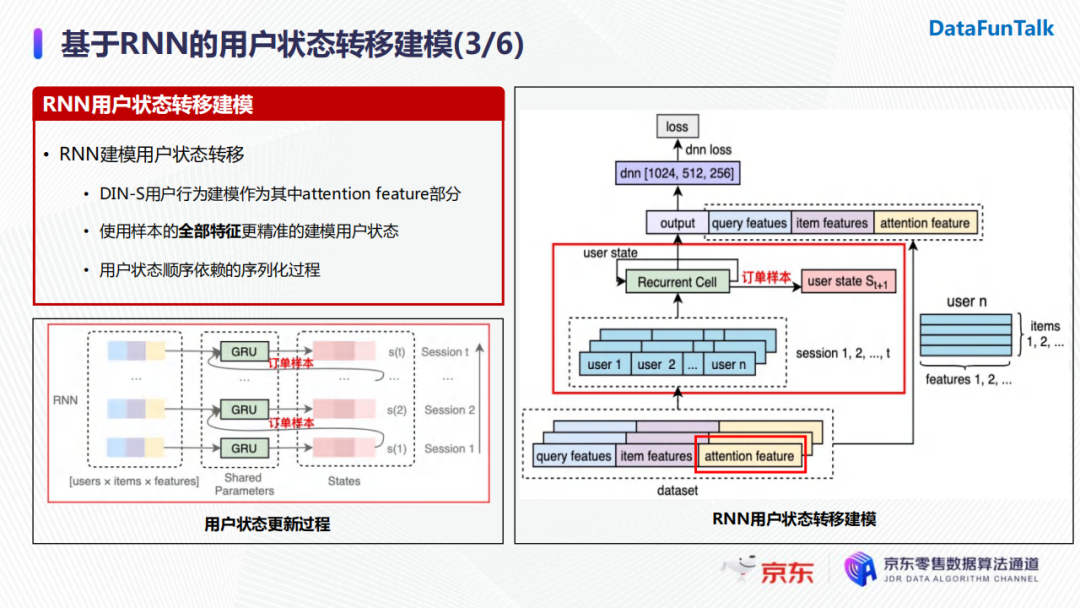
为了兼容baseline的DIN模型,我们将DIN生成的特征作为attention feature加入模型。在每一个timestep,用户对应session下的所有商品特征会经过一个GRU,得到每个商品的输出向量以及隐状态向量,而隐状态向量会与下一个timestep的session特征一起作为新的输入传递进GRU,并对GRU进行状态更新。在这个过程中,用户当前时刻的状态依赖于上一时刻的状态以及当前时刻的输入,因此它是一个序列化建模的过程。
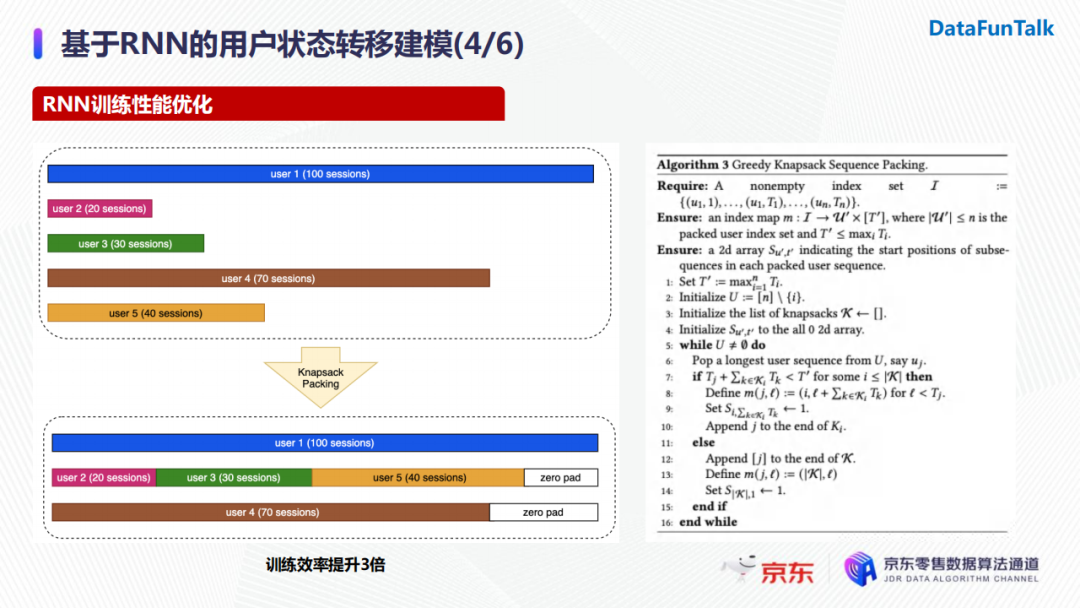
但是,实际在模型训练时,我们需要考虑到用户搜索数量的差异。具体地,某个用户可能有上百次搜索请求,而其他用户只有几十个甚至几个请求。训练RNN时为了保证输入长度的一致我们会加入padding,搜索请求数量的巨大差异导致不必要的开销,对RNN的性能产生影响。基于这一问题,我们会将搜索长度较短的用户进行筛选并进行拼接,进而减少不必要的padding。经过实验,优化后的RNN训练效率提升了约三倍。
3. 架构层面
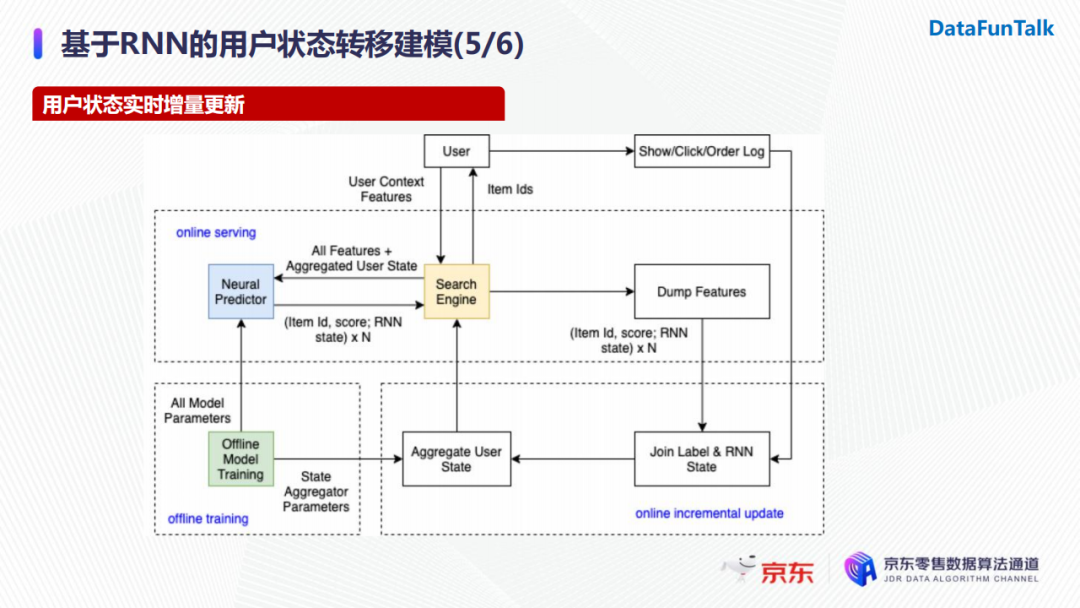
针对用户状态的实时增量更新,我们使用的架构可以分为三个模块,并针对目标进行对应的优化。
- 离线训练:我们会把训练好的模型导出成两个部分,一部分是用户历史状态的表示,它可以作为特征提供至线上进行使用;另一部分是模型所有参数,它用于线上模型的打分。
- 线上服务:当用户发起一次搜索请求时,系统会拿到当前待排序的所有商品以及用户的embedding表示。我们将这两部分输入传递给模型,得到模型对候选商品的打分以及RNN的状态向量。随后我们会将返回的feature以及商品的打分做持久化存储。
- 在线增量更新:增量更新时会将用户的实时反馈(点击或者下单行为)与持久化的样本特征进行join,之后使用ID作为索引更新当前用户的状态,最终同步至特征服务器上。在用户embedding同步完毕后,下一次用户请求时就已经可以使用新的用户状态,这样就完成了用户状态的在线增量更新,避免了线上使用用户历史行为序列重复计算用户状态。
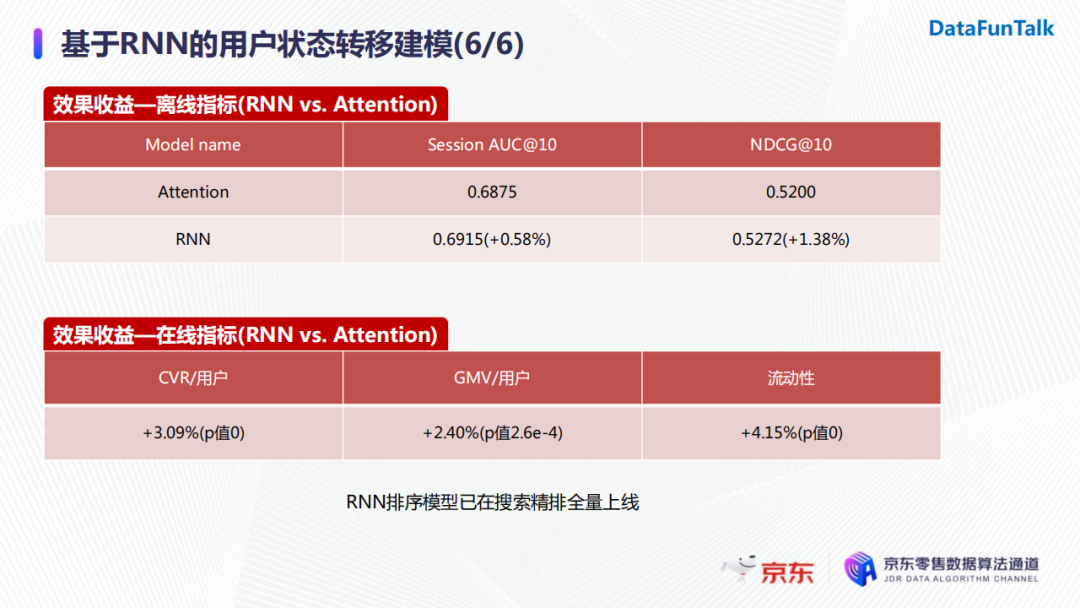
我们使用RNN用户状态转移建模对精排进行了全量更新。离线情况下session的AUC@10相较于基于Attention机制的baseline模型提升了0.58%。在线AB实验后,在用户的转化率以及每个用户带来的GMV上也分别有显著的提升。
--
04 基于DDPG的长期价值建模
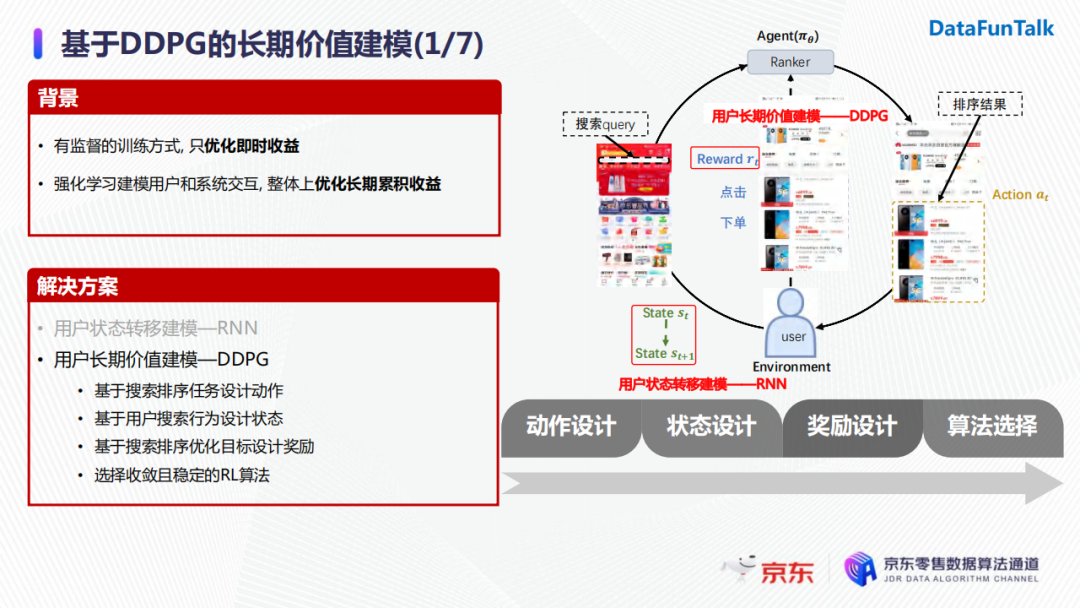
我们想通过强化学习来建模用户和搜索系统之间的交互,在整体上优化长期累积收益。在具体落地时,算法需要根据动作设计、状态设计、奖励设计、算法选择来分为多个阶段:
首先我们基于搜索任务设计动作空间,然后基于用户的搜索行为使用前述的RNN模型进行状态建模,接着我们会基于搜索排序的优化目标设计奖励,最后基于整个策略迭代的收敛性和稳定性选择相应的学习算法。
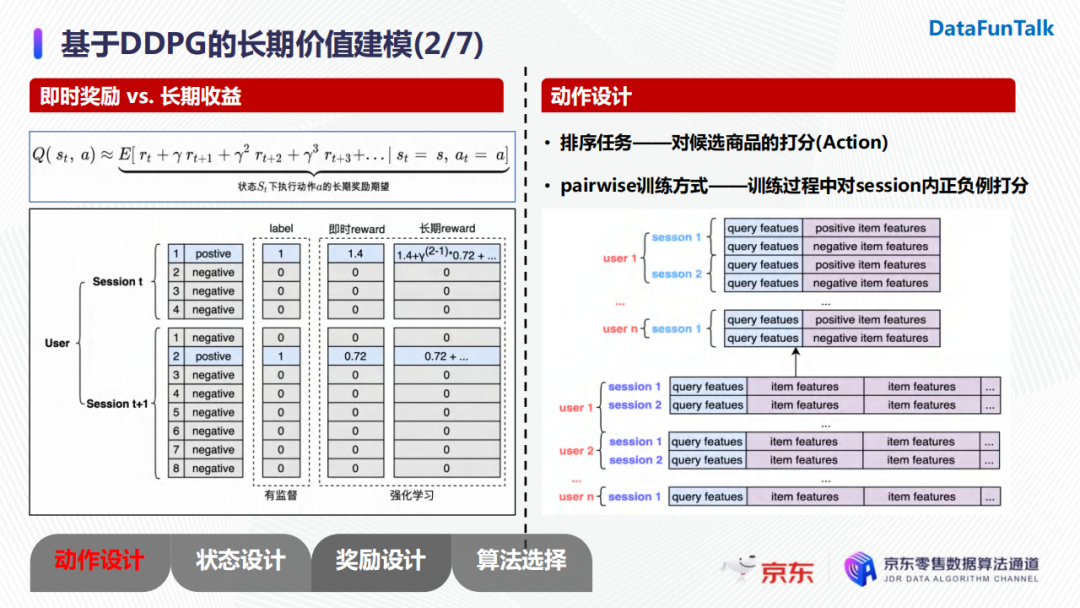
首先,考虑长期收益的优势在于它纳入了后续筛选带来的累积收益,而有监督学习的每一步都是在优化特征与转化label之间的直接关系。对于动作设计,由于我们面对的是一个排序任务,所以动作即为对候选商品的打分。我们在模型训练阶段选择了pairwise的训练方式,所以我们需要对输入样本的形式进行一些改动。具体地,我们会从用户的每个session中把每一个正样本保留下来,并对应地随机采样一个负样本,从而形成一个样本对。对应地,在训练过程中动作便转化为对构造的正负样本对进行打分。

由于我们采用pairwise的训练方式,我们采用的奖励函数是根据正负样本的分差进行构建的。我们的优化目标是用户转化率,所以我们希望在模型对正负样本对进行打分时,不仅排序可以正确,而且正样本与负样本的分差尽可能大。所以,奖励函数设计时,如果正样本和负样本排序正确时,分差越大奖励越大;反之,我们希望分差越大乘法也越大。上图中我们给出了三种奖励函数的设计:常数reward、交叉熵reward以及sigmoidreward。
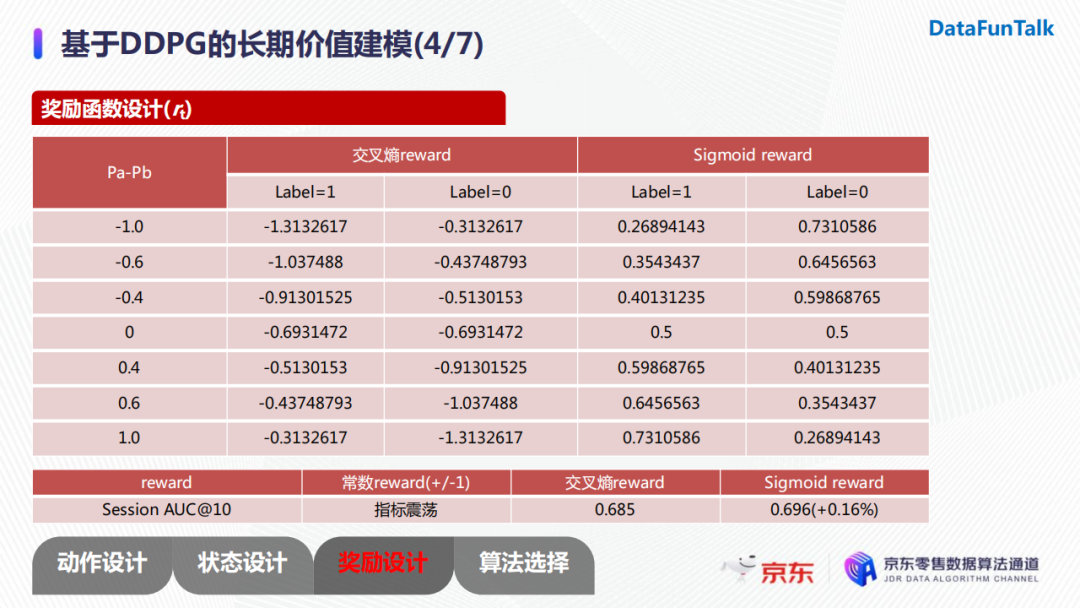
我们对这些reward做了一些实验。常数reward在我们的场景下指标一直是振荡的,收敛性比较差,主要原因是只要模型打分顺序正确,它给予的都是固定的奖励,这就导致了若两个商品打分分别为0.51与0.49,虽然它们的区分度不高,但是奖励与其他样本对是一致的。
此外,在比较交叉熵reward以及sigmoid reward时,我们发现交叉熵reward一直是一个负值,而具有正值收益的sigmoid reward相较于前者有了0.16%的指标提升。
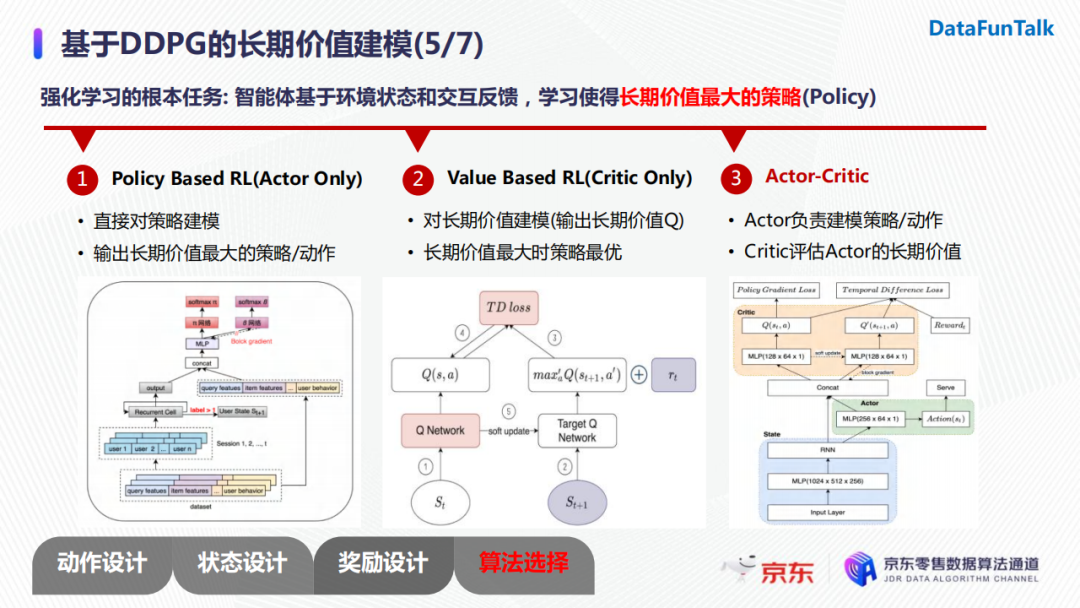
强化学习的根本任务是智能体基于环境状态和交互反馈,学习能让长期价值最大化的策略。一般地,有三种方法进行建模:
- 基于策略:直接对策略进行建模,让策略不断地朝着长期价值最大的方向进行迭代,最终输出长期价值最大的策略/动作。策略可以理解为使基于输入用户状态,对候选的商品进行直接打分;
- 基于长期价值:典型的模型是DQN。当长期价值最大的时候,其对应的策略也是最优的。但是DQN无法解决连续的动作空间,只能建模离散的动作空间;
- Actor-critic:Actor负责对策略或者动作进行建模,Critic负责评价Actor生成的策略或者动作的长期价值。
我们在线上分别对这第一、第三种方式进行过实验,最后发现Actor-critic的建模方法效果较好,于是选择使用这种框架进行算法迭代。
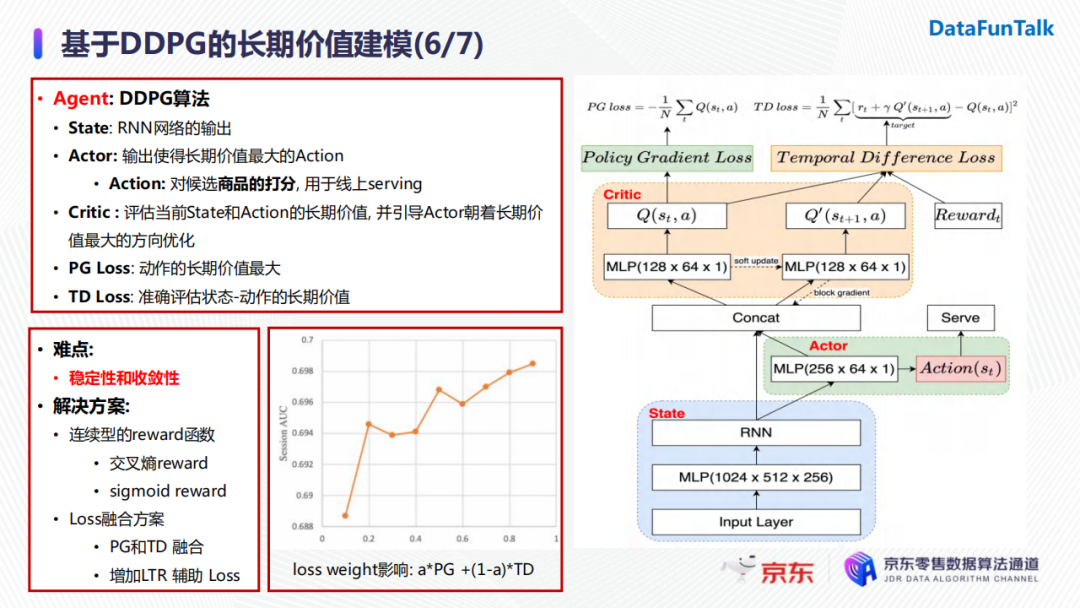
现在就来具体介绍一下DDPG的网络结构。整个网络包含三个模块:
- ** State网络**:使用RNN进行用户状态转移建模;
- Actor网络: 使用State网络生成的状态向量作为输入,输出对候选商品的打分(即action);
- Critic网络:使用State网络生成的状态向量以及Actor网络生成的action作为输入,输出对应的长期价值,并引导Actor朝着长期价值最大的方向进行优化。
整个网络设计了两种损失函数。第一个为PolicyGradient的损失函数,它的作用是优化Actor网络的参数,使得其输出的action的长期价值最大;另一个为时间差分的损失函数,作用是优化Critic网络,使得其可以对Actor输出的动作给出的长期价值的评估越来越准。
在网络训练过程中我们也遇到了很多难点,其中最重要也是最常见的问题便是稳定性和收敛性问题。我们最终给出的具体解决方案是使用连续型的reward函数以及采用损失函数融合的方法。Loss的融合最直接的方式是将Policy Gradient的loss和时间差分loss进行加权求和。我们通过实验发现随着loss weight的增加,我们的指标也有上升的趋势。值得注意的是,当权重等于0或1时,模型都是不收敛的,这也证明了单独使用Policy Gradient损失或者时间差分损失进行模型优化是无法满足模型的稳定性与收敛性的。
另外,我们也尝试增加了一些有监督的辅助损失函数,其也会对指标带来一定的提升。
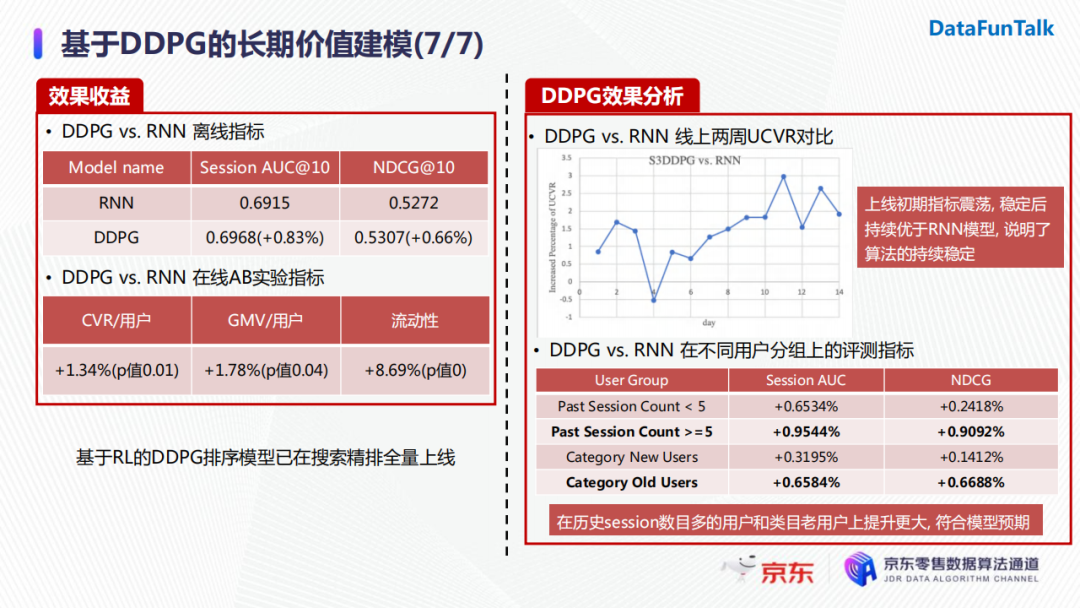
DDPG在离线指标上相较于RNN模型在Session AUC@10上有了0.83%的提升,在线AB实验指标如用户转化率以及GMV也均有大于1个点的显著提升。
目前DDPG也在搜索精排中进行了一次全量更新。其实大家也会很担心DDPG在线上的稳定性问题,我们对此也做了很多分析。
首先,我们对比了两周的线上指标(后续其实观察了更长时间),发现DDPG在上线初期指标出现震荡,但是模型稳定之后其指标持续优于RNN模型,证明了算法的稳定性。
另外,我们考虑了不同用户分组上的评测指标,例如将用户按照他的历史搜索次数进行筛选和分组。实验发现,DDPG在用户历史搜索越多时,其对长期价值的建模越准确。这在使用新老用户进行分组实验时也体现了相似的结论,与我们的建模预期吻合。
--
05 规划与展
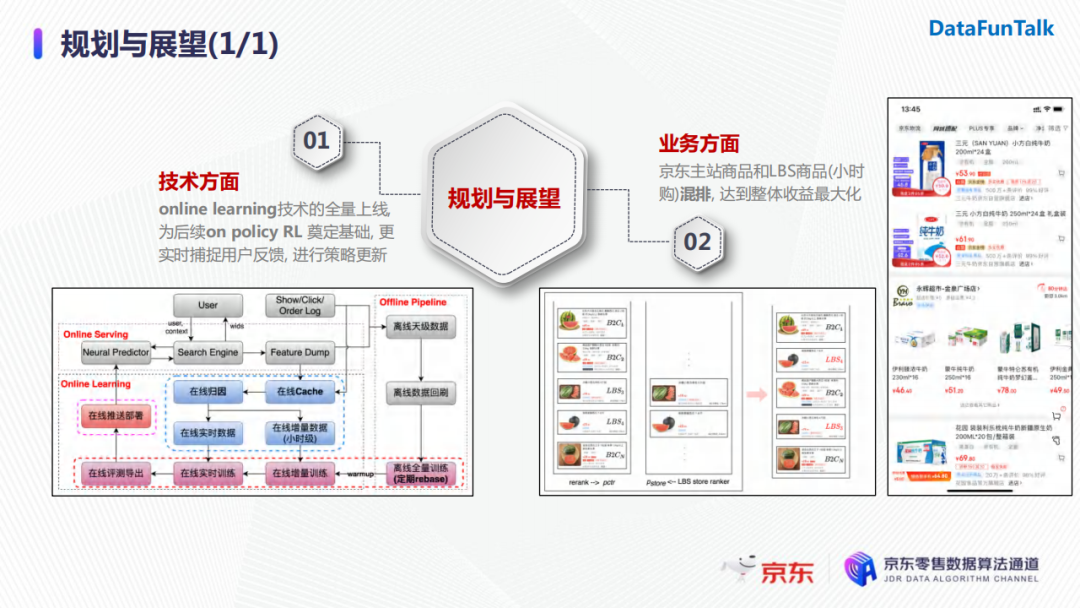
首先,在技术方面,因为我们一开始强化学习的模型并没有在线上使用online learning,所以刚开始迭代的时候模型还是进行离线更新。目前我们online learning的技术已经全量上线了,后续会做一些更复杂的探索,为on-policy的强化学习算法奠定基础。采用on-policy强化学习算法能够更加实时捕捉用户反馈,不断地进行策略的更新。
另一方面,在业务层面,京东主站商品和LBS商品(小时购)部署的排序模块是两个独立模型。那么如何对这两种类型的商品进行混排来达到整体收益最大化是我们想要探索的目标。
--
06 精彩问答
Q1:Dump feature中包含什么内容?
A:首先,dump feature包含用户在此次请求时模型使用到的所有商品特征;此外,RNN模型生成的hidden state也会一起加入dump feature中,为后续RNN状态在线增量更新做准备。
Q2:请问有没有尝试过offline强化学习的方法?
A:其实刚才介绍的模型就是一个offline RL的方法。我们的模型会使用历史上一段时间的数据,在训练时我们先离线地使模型达到收敛状态,再将其推至线上进行服务。模型一般一天更新一次,所以在一天之内模型的参数是不变的,但是用户的状态向量会做不断的增量更新。
Q3:请问模型是使用什么方式进行部署的,性能怎么样?
A:其实这是我们京东内部模型部署的一个架构,我们称其为Predictor。在正常情况下,我们模型导出之后会有一些验分的流程,之后会将其推送至Predictor进行线上部署。针对性能的话,虽然在线上有RNN模块,但是我们已经把使用用户历史的搜索计算出的用户状态保存下来并作为RNN的初始状态,所以每一步RNN前向计算都是一个增量计算的过程,对性能没有特别大的影响。
Q4:请问我们的环境是静态数据吗?如果是静态数据,怎么做探索?
A:在训练的过程中,环境是一个静态数据,我们使用用户的历史session,通过RNN不断地学习下一个session的状态。在线服务时,当模型有了初始状态之后,在线环境会给予它实时反馈,进而做在线的更新。
Q5:请问有没有考虑过listwise的排序方法?
A:Listwise排序更多地会用在有监督学习中。在我们强化学习的建模中,我们除了考虑当前的即时奖励之外还会考虑后续的长期价值。但是,我们并没有在用户当前搜索下考虑商品与商品之间的关系, session内样本构造还是一个pairwise的方法。
Q6:请问为什么会设计这种连续的reward函数?
A:这和我们动作的设计有关。我们的动作是对候选商品的排序打分,这是一个连续的动作空间。另外,我们的目标是输出排序动作后,模型对正负样本存在一定的区分性,即在排序正确的情况下得分相差越多,奖励越高。此外,如果给予打分接近、没有太大区分度的两个商品同等的奖励对模型的收敛性不是特别好。
Q7:请问模型在线上会有探索的过程吗?探索的过程是否会造成收益的损失?
A:目前我们的模型是离线训练好后推至线上服务的,并且在一天之内不会进行参数更新,所以也没有线上的探索过程。目前online learning的模型已经全量上线了,之后我们会采用离线预训练好一个模型、在线做探索的方法进行一些尝试。但是,直接去线上做策略探索的话,损失是我们承担不起的,所以一般还是会有一个离线预训练模型,加上线上online learning进行policy的探索。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号