杨玉基:知识图谱在美团推荐场景中的应用

导读: 美团是一个生活服务领域的平台,需要大量知识来理解用户的搜索意图,同时对于商家侧我们也需要利用现有的知识对海量信息进行挖掘与提取,进而优化用户体验。今天分享的主题是知识图谱在美团推荐场景中的应用。主要包括以下几方面内容:
- 美团知识图谱介绍
- 美团推荐场景介绍
- 美团推荐中的知识应用
- 总结与展望
--
01 美团知识图谱介绍
首先介绍美团的知识图谱:美团大脑。
美团所涉足的生活服务领域需要大量知识。例如,当用户搜索“10人聚餐”的query时,我们需要对它结合知识进行理解,得到用户想找大桌或者找包间的意图。同时,对于商家侧,我们也需要利用UGC评论中挖掘出类似于“有大桌”、“有包间”这样的标签。基于知识的理解和匹配,我们可以把满足需求的商家推荐给用户,当用户点击进入商家详情页时,有别于之前用户需要逐条查看海量评论,费时费力,我们从UGC中挖掘出细粒度的情感标签,把大部分用户关心的细粒度特征显式地展示出来,从而节省用户的时间,提升用户体验。

因为生活服务领域需要大量的知识,美团NLP中心从2018年开始就着手构建了生活娱乐领域超大规模的知识图谱——美团大脑。我们从餐饮图谱开始,后来逐渐扩展至标签图谱、场景图谱、商品图谱、到综图谱等。
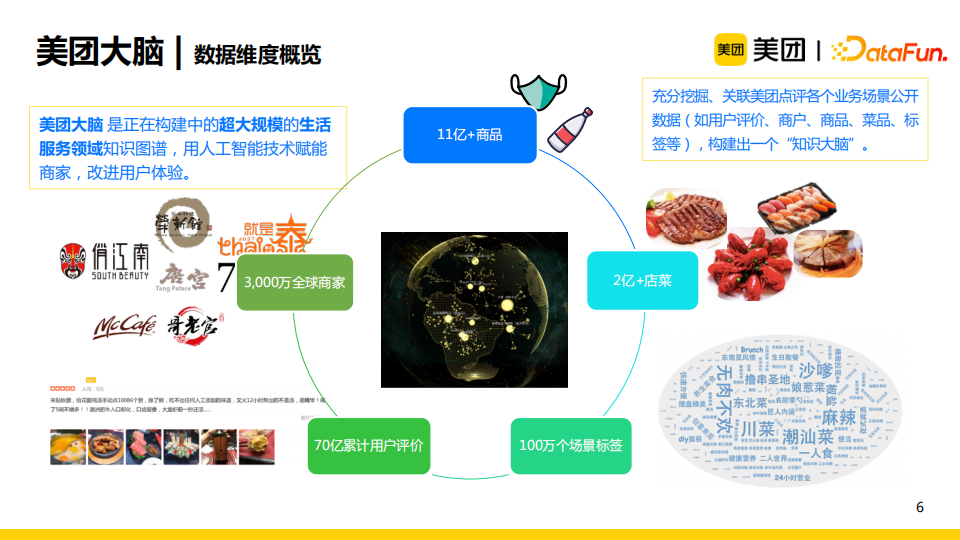
美团大脑目前是正在构建中的超大规模的生活服务领域知识图谱,其主要的主体类型是商家(千万级)、商品(十亿级)、店菜(亿级)、海量的用户评价(70亿量级)以及从评价中挖掘出的场景标签(百万级)。
--
02 美团推荐场景介绍
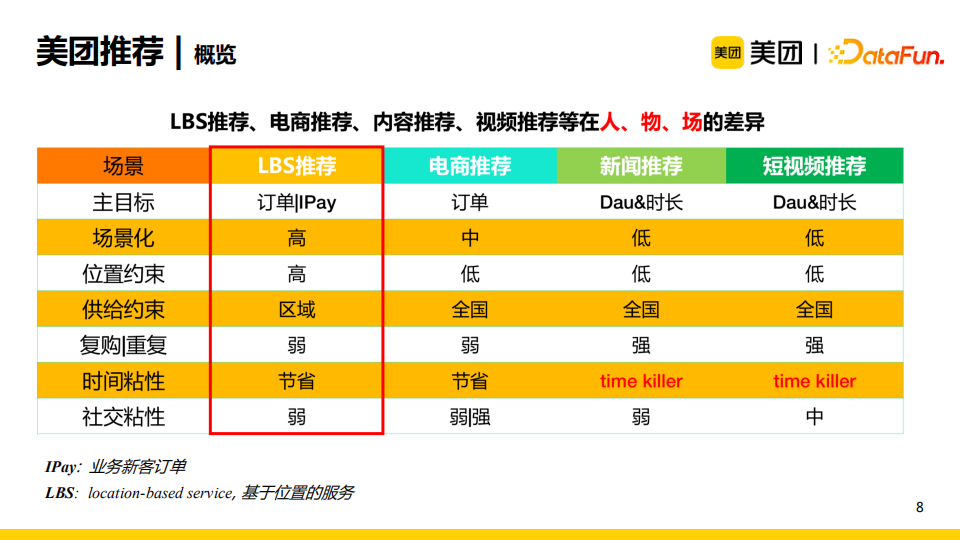
美团推荐属于LBS(基于位置的服务)推荐,它与电商推荐、新闻推荐、视频推荐等存在很大差异。LBS推荐中位置约束以及场景化的要求很高,供给约束是区域型的,其主目标是订单或者IPay(业务新客订单)而非Dau或者时长。此外,LBS推荐的社交粘性较弱。
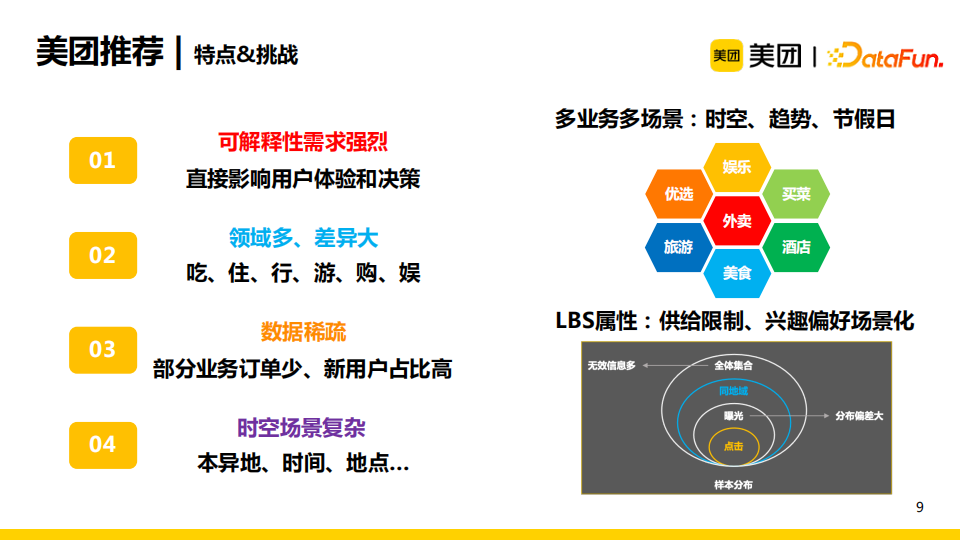
美团推荐存在着以下四点挑战:
- 可解释性需求强烈:可解释性可以直接影响用户的体验和决策,从而促进交易,达成美团的业务目标;
- 美团涉及的领域多、差异大:领域包含了吃、住、行、游、购、娱等;
- 数据稀疏:除了到餐外卖等高频业务外,大部分业务的订单相对较少,且新用户的占比偏高;
- 时空场景复杂:我们需要考虑到本异地、时间、地点等因素。一个典型的本异地的场景例子是一个用户在出差前需要查看目的地酒店。有关时间因素的例子如一个用户在早上喜欢吃豆浆油条,中午就喜欢吃正餐。又如一个用户在家和在公司喜欢点的外卖不一样,这就是一个考虑地点因素的例子。
--
03 美团推荐中的知识应用
1. 可解释性需求强烈
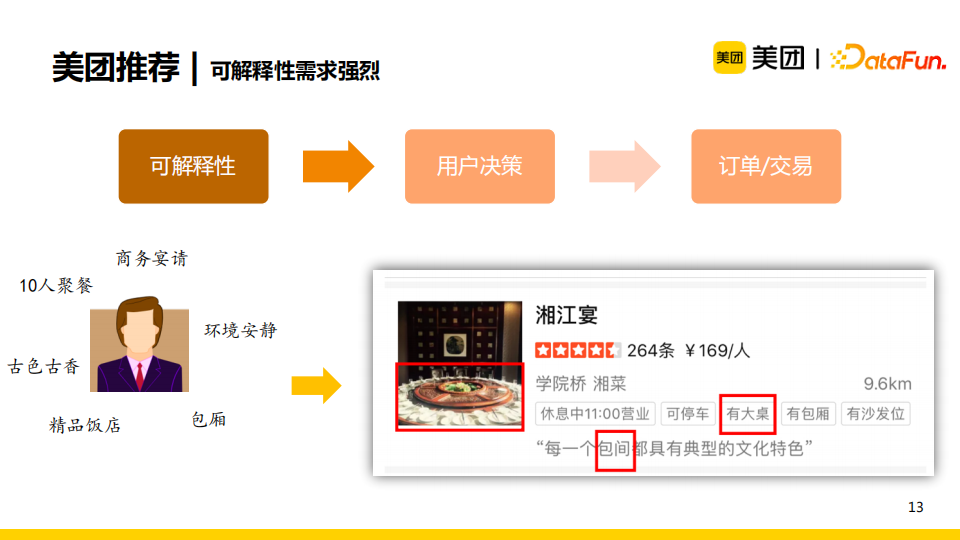
比如对于一个商务人士,他的搜索需求是“商务宴请”,若我们仅仅直接向他推荐“湘江宴”与标签“湘菜”,那么他无法得知商家是否能满足自己的宴请需求。如果我们将商家的“有大桌”,“包间”等知识信息展示给他时,那么他就可以轻松地判断出推荐的商家可以满足自己的需求。
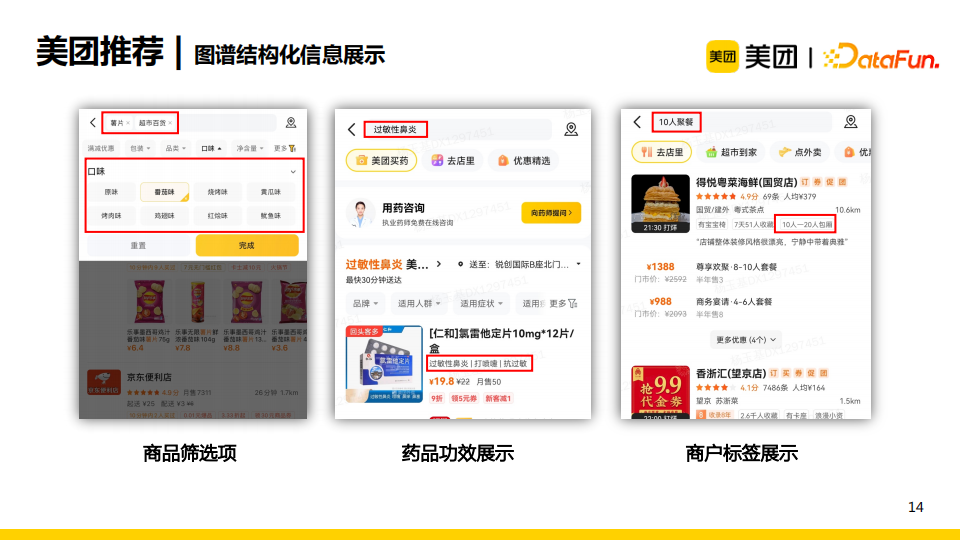
因此,知识图谱最典型的应用是结构化信息展示。例如,我们可以从药品的说明书中挖掘出药品的功效来展示给消费者;我们可以将知识图谱利用在商品筛选项中,如用户搜索薯片时向其展示按口味区分的筛选项,从而使他能够快速地选择符合口味的薯片进行购买。
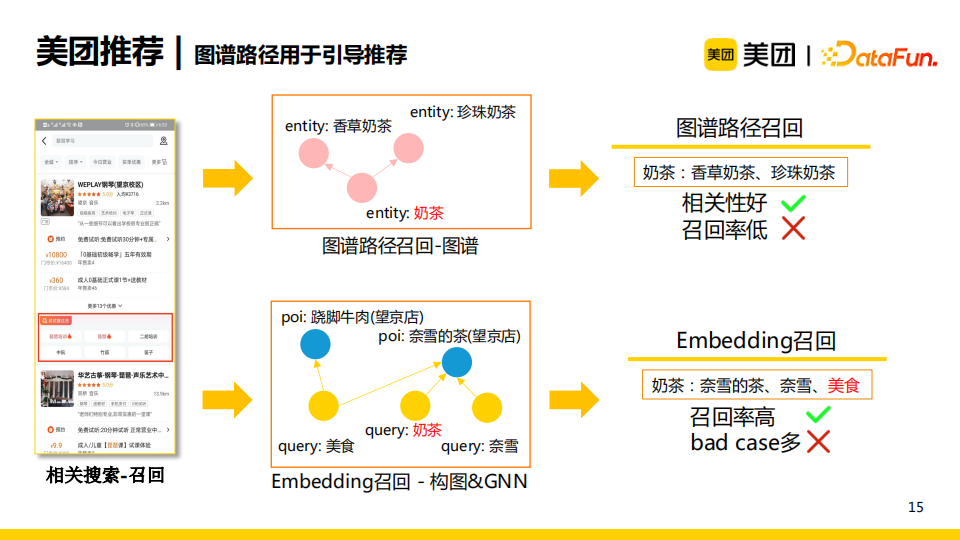
除了利用知识图谱来向用户进行结构化信息展示之外,我们还利用图谱路径来引导推荐。如相关搜索-召回的业务场景,当一个用户输入一个query以后下滑了很久都没有进行点击,那么我们就会为其推荐一部分更好的query。一个简单的做法就是直接使用知识图谱路径召回,将query对应的实体在图谱中有连接的下位实体推荐给用户,如“奶茶”对应的“珍珠奶茶”、“香草奶茶”等。这一方法的优点在于其召回的相关性较好,这得益于知识图谱的质量很高,缺点是召回率低,因为用户的query含有噪声信息,而知识图谱的实体较为纯净。在实际业务中,我们更常用的做法是利用embedding进行召回,具体做法是将用户历史query以及点击poi进行构图,之后使用GNN模型来训练embedding。当用户输入一个query时,我们在训练好的向量空间中搜索query向量的近邻向量作为候选召回。这一做法的优点是召回率高,但是召回的bad case较多,且即便embedding的质量非常高也无法避免bad case的出现。
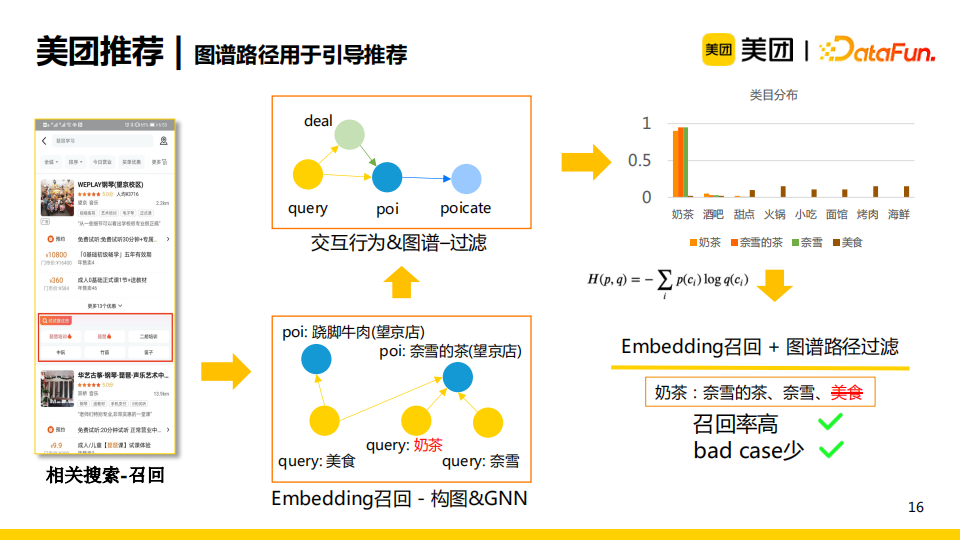
美团在业务中会首先使用embedding召回的方法生成一系列候选召回集合。随后,我们使用用户交互行为与知识图谱来进行构图。如上图所示,query与poi、query与deal(商家的团单)是点击关系,这部分来源于点击行为;deal属于poi,且每个poi都从属于一个类目,这部分信息来源于知识图谱。我们通过两部分信息的结合构成一系列路径,可以通过每一条路径来计算query属于哪一类poi类目的得分,其对应于query对应的类目分布。通过计算交叉熵,将不符合要求的候选召回过滤掉,从而实现在召回率高的同时减少bad case。
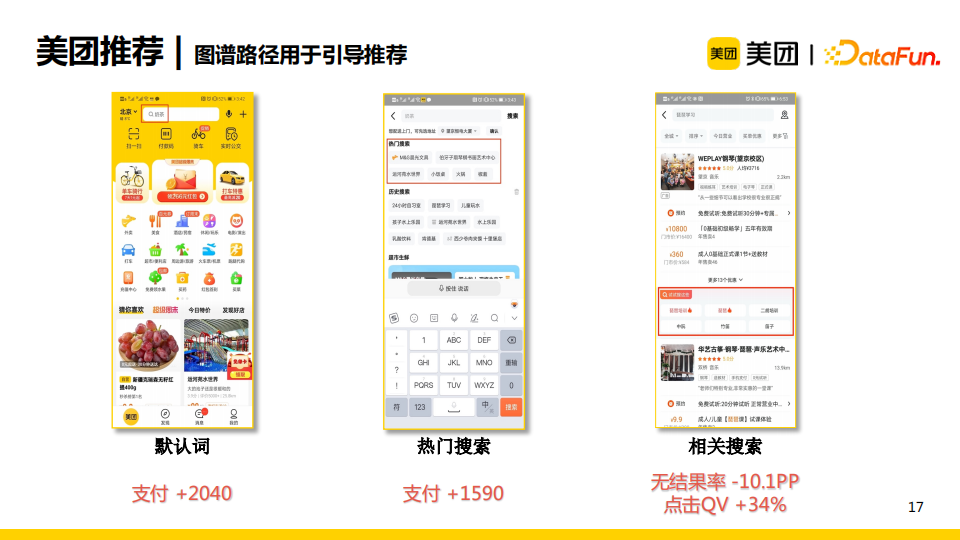
基于上述embedding召回+图谱路径过滤的方法,美团推荐的默认词模块、热门搜索模块、相关搜索模块都得到显著的业务指标的提升,尤其是相关搜索模块,无结果率下降了10个百分点,点击QV提升了34%。
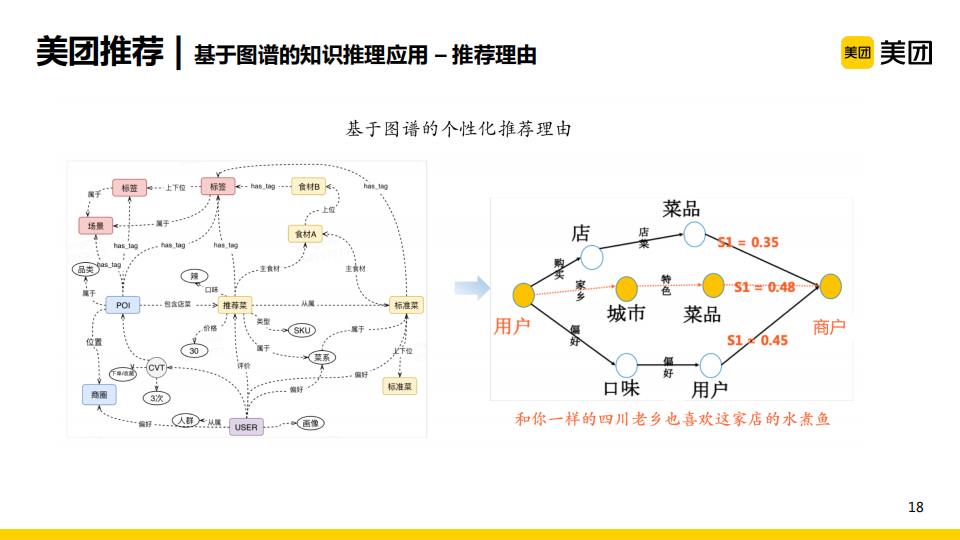
我们还基于图谱的知识推理来生成推荐理由。以上图为例,左侧是知识图谱,可以通过它来学习每个用户到每个商户的路径分。比如学习到用户的家乡属于某一个城市,以及这个城市的特色菜品,同时这个菜品又隶属于某个商户,若此时这一路径在当前用户对当前商户的所有路径中得分最高,就可以按照这条路径生成推荐理由,如“和你一样的四川老乡也喜欢这家店的水煮鱼”。可以看出,这一方法生成的推荐理由是十分个性化的,且其吸引力较强。
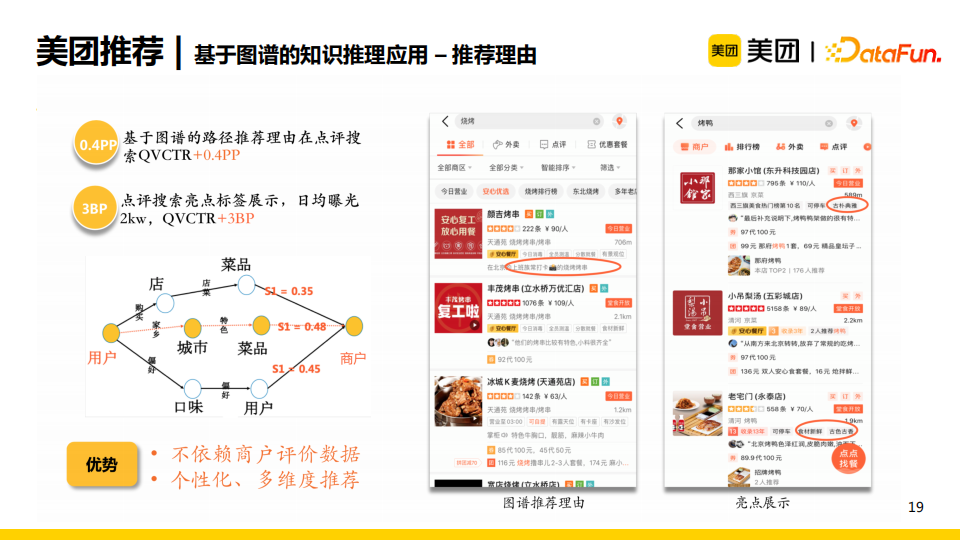
基于图谱的推荐理由生成在线上也取得了很好的收益。与从UGC中挖掘的推荐理由相比,这一方法有两个优势。
首先,这一方法不依赖商户评价数据,这对新店较为友好,我们可以使用用户交互行为和知识图谱来为用户提供个性化推荐理由。
第二,由于生成的路径很灵活,我们可以轻松地为用户从个性化与多维度的角度生成推荐理由。
2. 领域多、差异大

在美团推荐的场景下,我们需要为用户同时推荐多个领域的内容。例如点评内容推荐,我们需要为用户推荐的领域包括宠物、露营、旅游、运动、亲子、美食、野生动物等。传统模型使用一个向量表征用户,其对用户多兴趣的建模比较粗糙。最近有一些多兴趣模型的工作,使用多个向量表征用户,对用户的兴趣建模更加精细。

已有的工作使用用户item序列id作为输入,使用诸如多通道或者动态路由的结构来输出用户多个兴趣向量,但存在两个问题。首先,它们都以item为最小粒度,忽视了item蕴含的丰富语义信息,兴趣建模不精细。其次,这些模型的可解释性不强,它们无法回答用户的兴趣具体是什么以及item所从属的兴趣是什么。
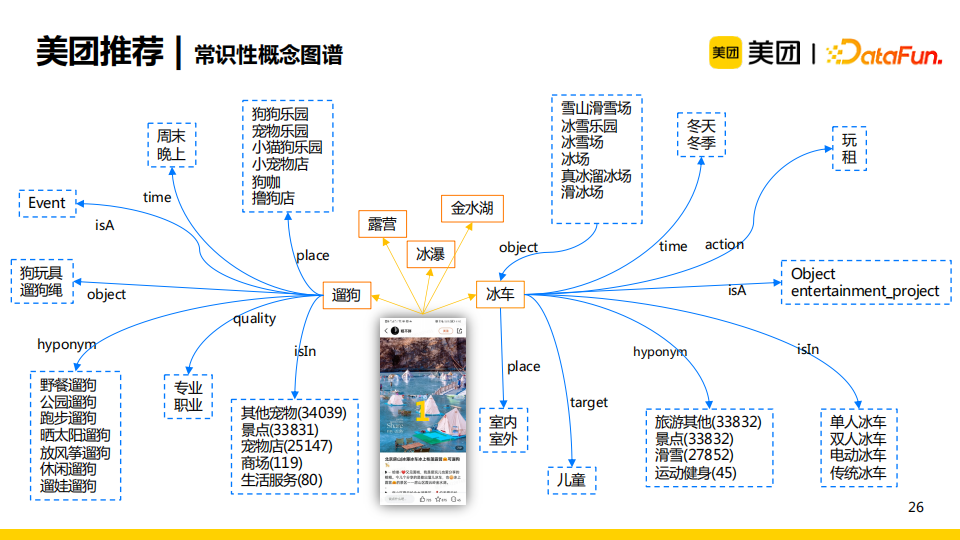
在美团推荐场景中,我们使用海量数据构建了基于常识的概念图谱。图谱中包含了事实、事件,它们都包含了具体的语义信息,如遛狗这一事件发生在周末晚上,地点在狗咖或者撸狗店等,需要使用到狗玩具、遛狗绳等。

我们想将概念图谱加入多兴趣建模中,使得兴趣建模更加精细。如上图所示,第一个点评内容包含了图谱中多个实体,每个实体都对应于多个兴趣集合。我们想要建模的可解释性更强,这就对应了三个目标:
- items需要有一个整体的兴趣集合
- 每个item对应一个兴趣分布
- 每个user对应一个兴趣分布
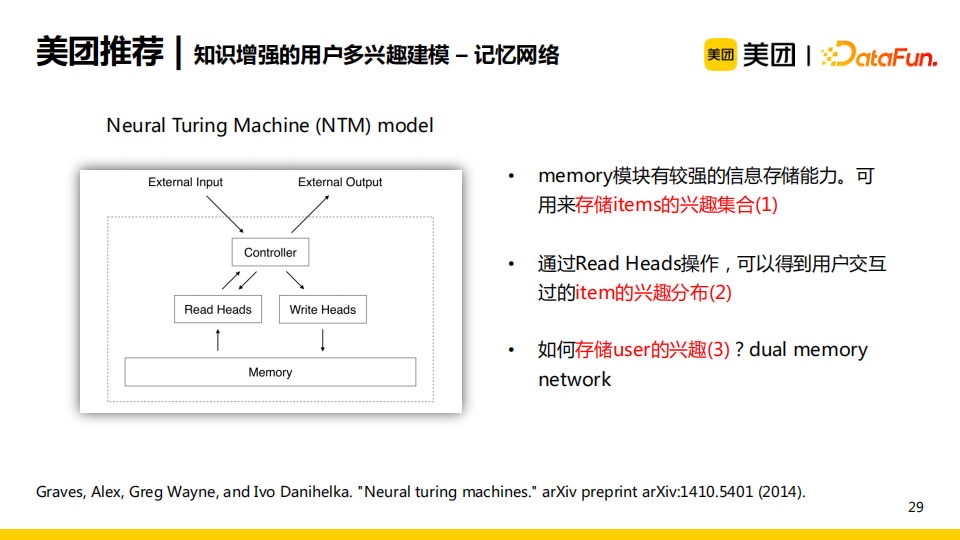
为了实现上述可解释性的目标,我们采用了基于神经图灵机(Neural Turing Machine,NTM)的记忆网络结构。NTM中的memory模块具有存储信息的能力,控制器controller用于控制读写操作。NTM的好处在于可以使用memory模块存储items的兴趣集合,实现了上述第一个目标;通过read操作,NTM可以得到用户交互的item的兴趣分布,实现了前述第二个目标。但是,原始的NTM无法存储user的兴趣,于是我们提出了基于双重记忆力模块的NTM。
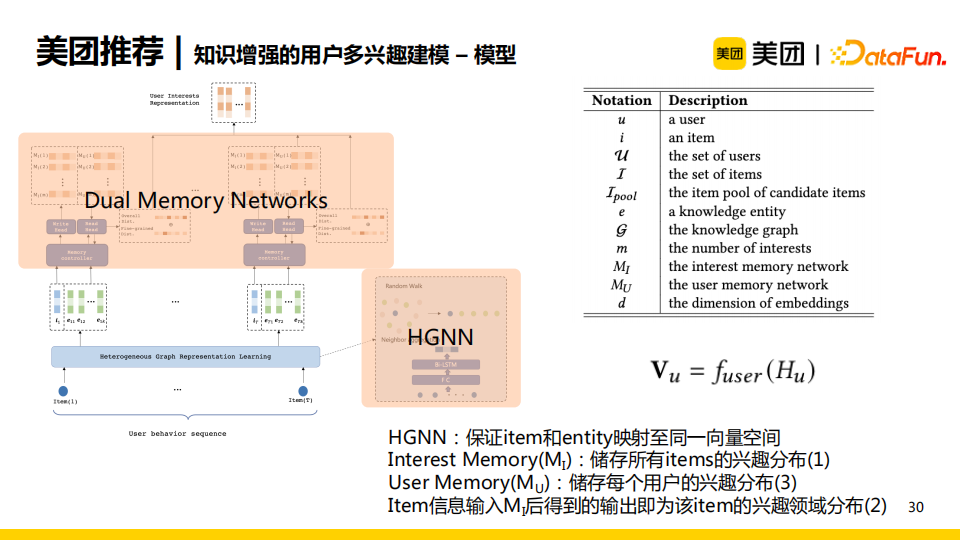
模型的输入是用户对应的item序列,包含点击序列以及点击的item多关联的entity。
首先,输入序列会通过异质图神经网络模型(HGNN),将item与entity在统一的向量空间中进行建模。
之后,item和entity向量会输入至双重记忆网络(Dual Memory Networks),通过读写操作更新MI(储存item的兴趣分布)和MU(储存user的兴趣分布)。我们可以通过目标item,使用读操作得到对应的兴趣分布。
最后,我们使用聚合操作可以得到用户的兴趣分布。通过这一网络结构,可以满足提出的三个目标。
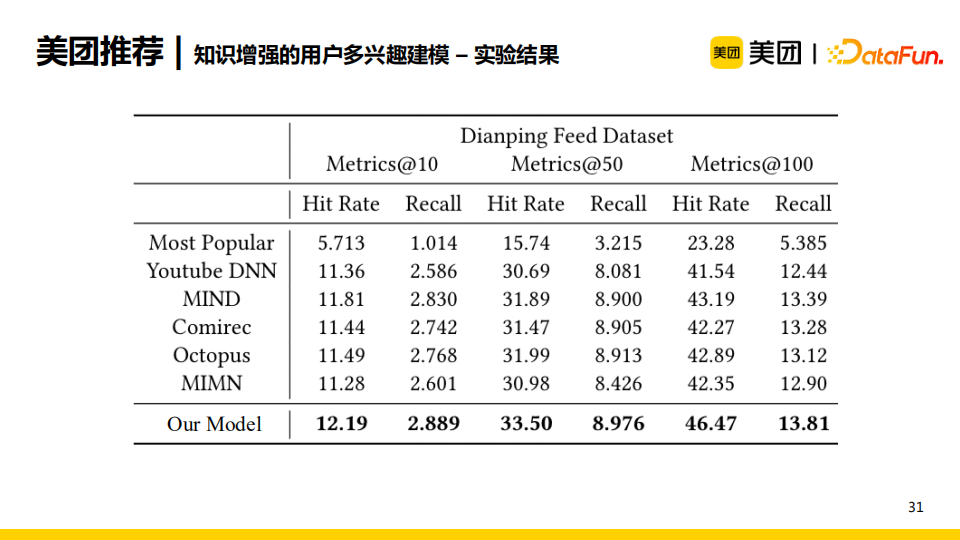
我们使用上述网络架构在点评业务上进行了对比实验。实验结果发现与单兴趣模型与已有的多兴趣模型相比,我们的模型在所有指标上都有不同程度的提升。
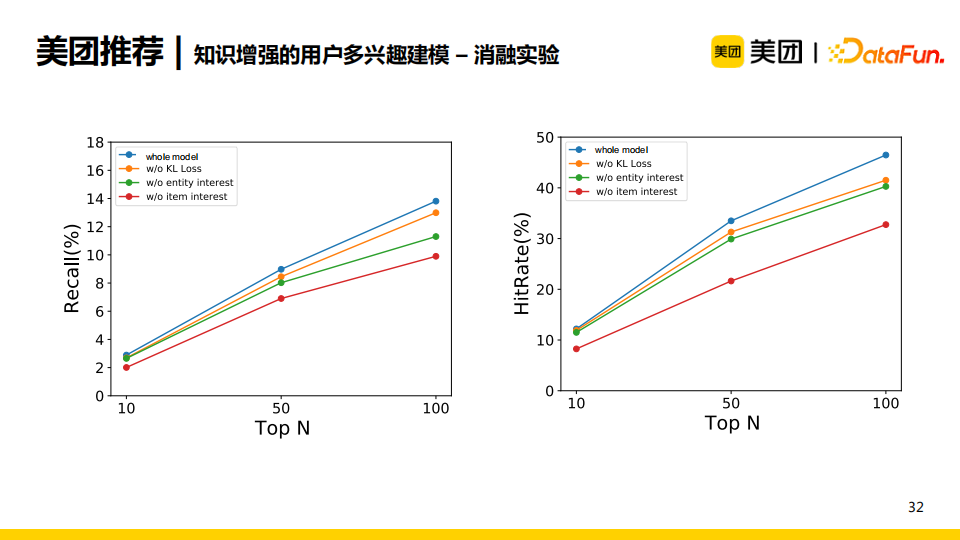
我们也进行了一些消融实验。当我们将网络结构中item memory去除后,模型效果下降得最明显;当我们将user interest去除后,模型效果也有所下降。为了保证item与对应的entity所学习到的分布的一致性,我们加入了KL散度损失函数进行约束。如果去除这一限制,模型效果也略有下降。消融实验有力地证明了双重记忆网络的有效性。
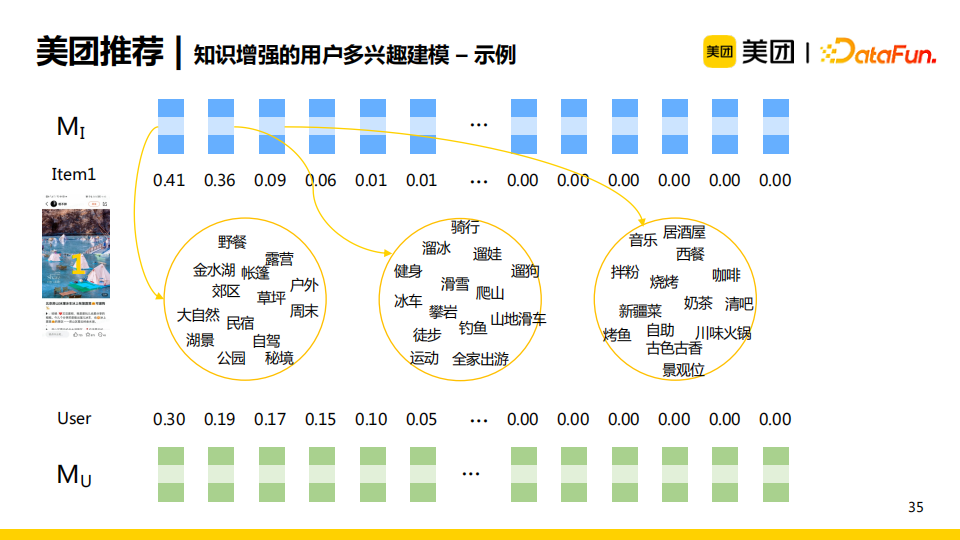
模型训练完成后MI可以被看作一系列“槽”,对应了每一个领域的兴趣。每个“槽”中存储了一些实体,那么所有item有一个整体的兴趣集合。当一个item输入记忆网络时,我们可以使用网络中的读操作得到item对应的兴趣分布。类似地,user也可以得到对应的兴趣分布。
3. 数据稀疏
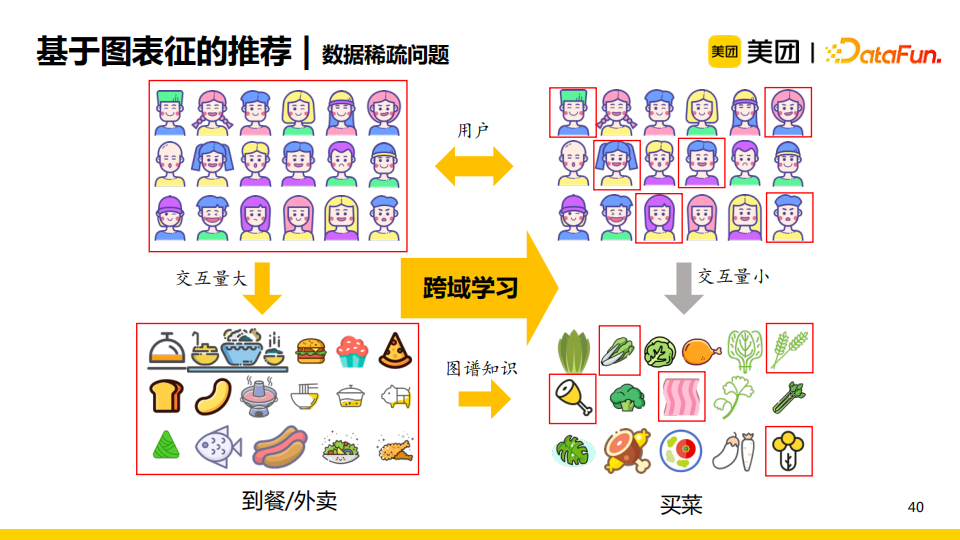
在美团的业务中,到餐/外卖这一业务交互量较大,但是如买菜业务的交互量就较小,只有部分用户与部分item进行交互。美团拥有丰富的图谱知识,我们发现买菜业务中的菜品其实与到餐/外卖业务中的菜品有一定关系。基于这一事实,我们考虑使用知识图谱与交互量较大的业务领域,使用跨域学习的方法来增强数据稀疏领域的业务效果。
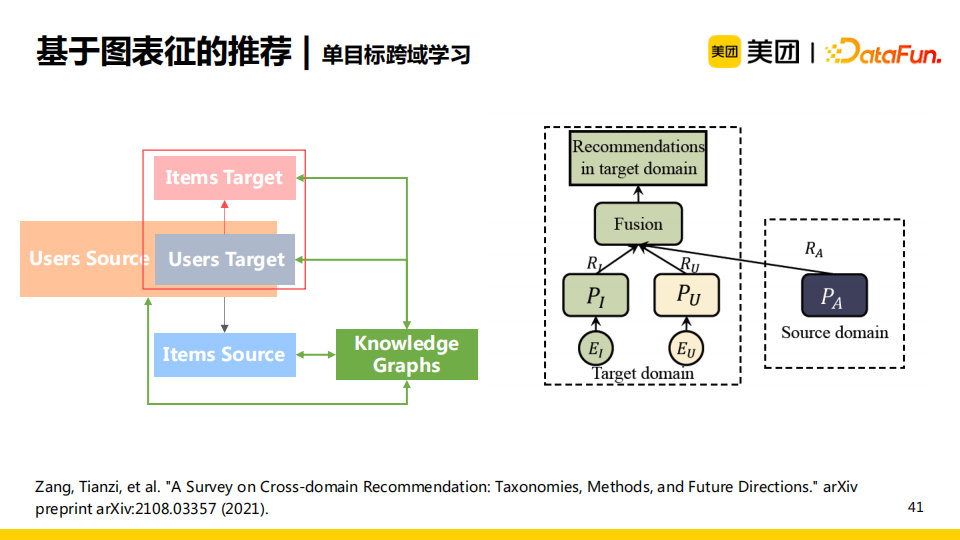
我们采用的是单目标的跨域学习,即只关注目标域中user和item的推荐效果。源域中的user、item以及知识图谱都作为网络的输入。这一方法的重点在于如何更好地将源域中的信息以及知识图谱中的信息融入目标域的向量表达中。
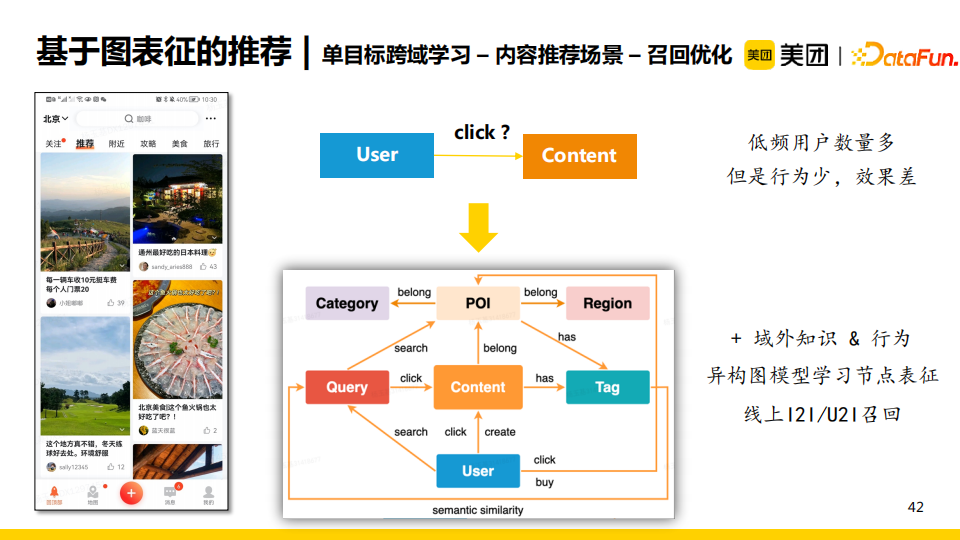
比如内容推荐场景包含的低频用户数量较多,他们的点击行为少,导致推荐效果较差。我们的解决方案是加入域外的知识图谱以及域外的交互行为。例如,用户在域外的点击、搜索行为,点击的poi在知识图谱中包含的知识(如属于的类目、商圈、标签等)都可以被用来构建一张更大的异构图,进而在这张图上学习节点表征。最后,我们在线上使用增强后的表征进行I2I/U2I的召回。
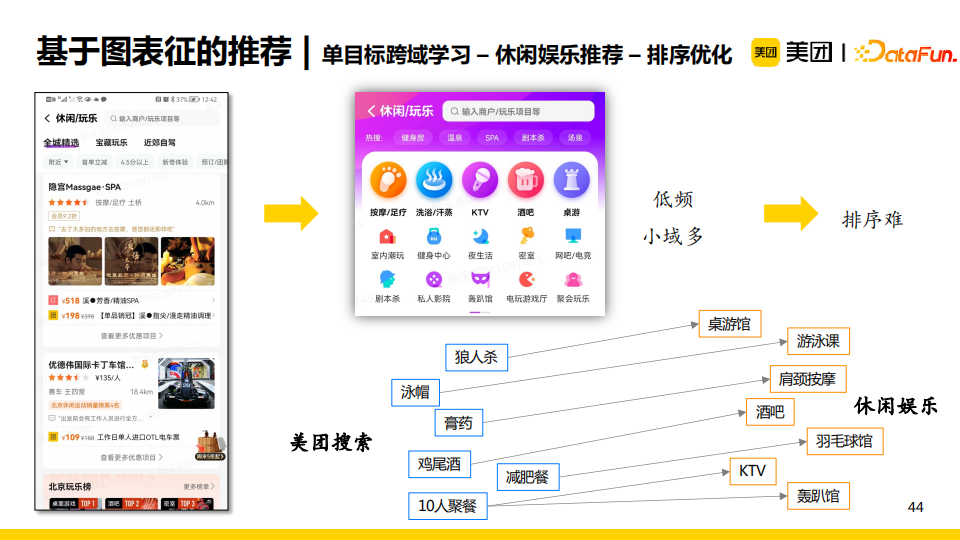
休闲娱乐推荐领域也属于低频的场景。不仅如此,该领域内还包含了很多小域,如按摩/足疗、洗浴/汗蒸、KTV等。这更加重了小域中的数据稀疏问题,导致针对众多小域中的item进行整体排序十分困难。这时,我们发现在“美团搜索”这个大域中很多实体或者搜索query可以对应于休闲娱乐小域中的实体或者用户意向,例如用户搜索“狼人杀”时隐含了桌游的意向,那么在休闲娱乐域我们就可以给他推荐“桌游馆”。
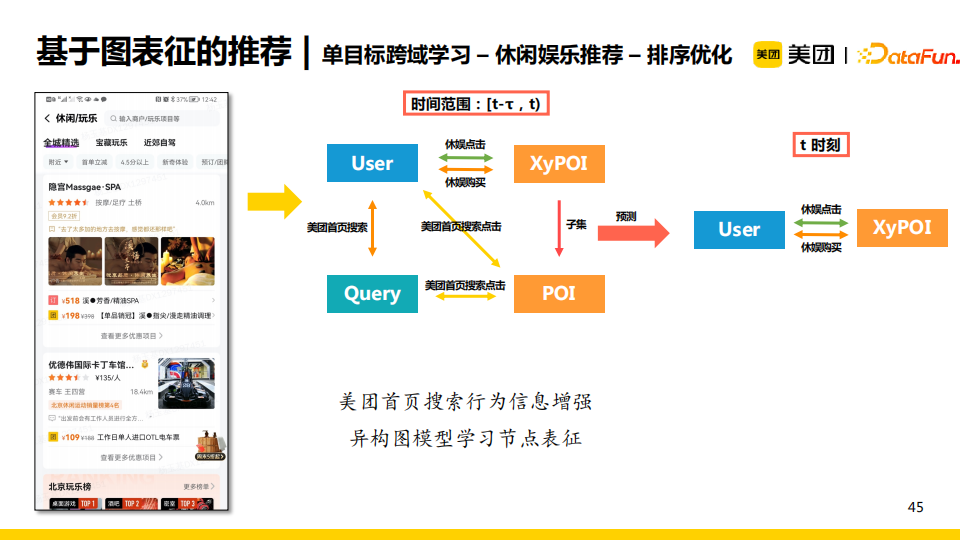
所以,我们考虑使用美团首页搜索行为与休闲娱乐领域的行为构建一张异构图,使得我们可以利用美团首页搜索行为信息增强休闲娱乐领域的节点表征。更具体地,我们认为首页搜索行为仅在一个时间间隔内(过去一周或者过去一个月)对目标域有效,所以我们采用了基于时序的采样和聚合。最终实验结果显示,在原有模型中增加了跨域学习后,在点击ndcg的指标上提升了26BP。
04 总结与展望
知识图谱在美团推荐中是一个十分重要的信息输入源。知识图谱的应用可以分为显式应用和隐式应用。显式应用是指直接将知识图谱应用于推荐中的展示引导和结构召回(如知识展示、路径召回、图谱推荐理由),解决了可解释需求强烈的问题。隐式应用是指将知识图谱通过表征更容易、更广泛地嵌入下游任务。它可以通过引入概念性常识图谱解决用户多兴趣建模中领域差异大的问题,还可以通过知识跨域增强改善目标域的数据稀疏问题。
之后我们会在两个方向上继续探索知识图谱在推荐中的应用。首先,我们会继续聚焦于通用推荐场景建模,如继续优化用户多兴趣、引入物品多模态、对用户与物品交互行为进一步探索场景时空性等。其次,针对很多业务中面临的数据稀疏问题,我们会着重探索推荐公平性、跨域学习以及图预训练。
--
05 精彩问答
Q1:知识图谱在图谱路径引导推荐中召回阶段和排序阶段是不是使用一个算法模型?还是一个模型将两个阶段的任务全部完成了?
A:首先,我们在做图谱路径引导推荐时,召回阶段使用的是GNN模型,如同质图模型GraphSage或者异质图模型R-GAT、R-GCN等。图谱其实在召回中的作用是对召回候选集进行过滤,去掉不太相关的bad case。其次,在一般工业级应用中,不会在召回层和排序层使用同一个模型,这可以让不同业务的同学分开优化各自负责的部分。
Q2:图谱路径到推荐理由的转化是人工适配还是机器自动完成?
A:目前我们会通过人工提前确定一些模板。模型利用知识图谱得到路径分最高的路径后去填充模板中对应的槽。在工业级的产品中,因为基于模型的文本生成算法出现bad case的概率较高且不太可控,影响用户体验,实际业务场景中会比较慎重地使用。
Q3:双重记忆网络在线上使用性能如何?
A:双重记忆网络主要用于用户多兴趣建模的召回场景。我们目前的使用方式是t+1调度更新,定期离线训练模型得到模型参数和item向量,每天infer得到user向量。线上使用时,我们直接使用得到的向量作为user和item的兴趣向量表征,在向量空间中通过ANN算法索引,性能不是问题。
今天的分享就到这里,谢谢大家。
阅读更多技术干货文章,请关注微信公众号“DataFunTalk”。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号