阿里新零售中的智能补货(I)— 库存模型
文章作者:阿里零售通算法团队
出品社区:DataFun
导读: 零售通作为阿里巴巴新零售的八路大军之一,肩负着“共建智能分销平台”和“让百万小店拥抱DT时代”的重要使命。一方面,我们通过线上平台(零售通APP)将零售品牌商的货品展现给小店的店主,并提供交易渠道让店主进行批发进货;另一方面,我们通过天猫小店和如意POS对小店进行赋能,帮助他们在线下的销售中能迅速发现C端消费者的需求,提升小店的坪效。 在这种B2B2C的创新分销模式中,智能化的供应链体系不仅要保证平台能持续稳定的为小店进行供货,还要控制供应链成本,让数字化渠道成为最经济的分销方式。
我们在不断迎接新零售模式下供应链各种挑战的过程中,逐渐沉淀出一套利用大数据和智能算法解决供应链补货的方法论,在这里与大家分享。本系列分为两部分:第一部分主要介绍智能补货的库存模型;第二部分会详细介绍补货模型中的销量预测算法以及我们在预测中用的一些经验和方法论。 本篇将对第一部分,即智能补货的库存模型进行介绍。
--
01 为什么需要智能补货
零售通作为连接商家、小店和C端消费者的数字化分销平台,保障货品供应的持续性和稳定性成为供应链的首要目标之一。不同于天猫、淘宝等直接面向C端消费者的平台,零售通直接触达的用户是小店的店主。他们在平台上进行采购的主要目的之一是用于补货。如果此时需要补充的货品在平台上已售罄,这不仅会损失平台的成交额(GMV),也造成了店内的货品供应不足,导致小店的收入降低。另一方面,如果为了最大化保障供应率,而将一大批货品囤积在零售通的仓库中进行售卖,则有可能导致某些货品长时间卖不出去,增加了库存周转时间和滞销率,降低了供应的效率。
因此,供应链补货的目标是通过供应方式(供应时间,供应数量,供应周期等)的决策达到仓库中需求和供给的平衡,使得仓库中货品的库存既可以最大化满足用户的需求,也能将库存周转时间控制在一定范围之内,保证供应的效率。(因此在很多行业中,供应链补货又叫做“库存平衡”。)

在某些传统行业中,供应链的补货任务大部分还是通过人工完成。一方面,传统行业的渠道信息数字化大多构建得不完善,无法完全通过数据实现精准补货;另一方面,传统行业的计算能力有限,在求解某些优化问题中无法实现大规模的复杂计算。而零售通背靠阿里巴巴集团这颗参天大树,不仅在数据获取渠道上突破了线下渠道数据的限制,还在计算资源上得到了充分的保证。这些优势为零售通供应链在智能补货算法的应用和发展提供了成长的土壤,使得通过基于机器学习和运筹学构建的智能补货算法体系成为可能。
--
02 库存理论(inventory theory)
无论是传统零售还是新零售,货品都会经历从生产制造到分销、再到消费整个周转过程。分销中的每个环节都需要维持一定货品库存来应对需求的不确定性。因此,分销商或者零售通都需要解决以下三个问题并作出正确的决策:
-
未来某段时间的需求是多少?
-
需要为未来的需求准备多少货?
-
每天的库存水位是多少?
无论作出何种决策,这三个问题都可以用“进-销-存”模型来描述。
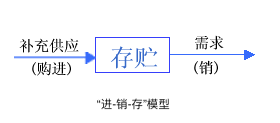
该模型需要进行连续决策,即以上三个问题不是一次性决策,而需要周而复始的不断进行下去。另外,上一次的决策结果(补货数量)会影响下一次决策状态(当前库存)。用数学可以对此过程进行如下描述:
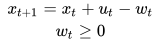
其中 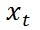 是 t 时刻的货品在库数量,
是 t 时刻的货品在库数量,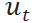 是需要进行决的 t 时刻的补货量,
是需要进行决的 t 时刻的补货量,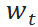 是 t 至 t+1 时刻的需求量总和。t 到 t+1 是两次决策的时间间隔,取决于补货的具体形式。
是 t 至 t+1 时刻的需求量总和。t 到 t+1 是两次决策的时间间隔,取决于补货的具体形式。
在“进-销-存”过程中,会发生成本的支出。进货时会产生订购和运输成本;货品储存在仓库中会产生存储成本(比如仓租和管理成本);货品售卖后会产生配送成本。
t 时刻的总成本可以用 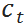 来表示,它是进货量、在库数量和需求量的函数图片。供应链补货所采取的决策目标就是在满足需求的情况下,最小化过程中产生的总成本。
来表示,它是进货量、在库数量和需求量的函数图片。供应链补货所采取的决策目标就是在满足需求的情况下,最小化过程中产生的总成本。
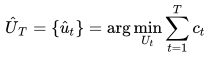
在运筹学中,该模型被形式化,并扩充为库存理论(Inventory theory),作为该学科的一个分支。库存理论在建立后的近80年中不断演化发展,为各行各业的生产制造和库存存储提供指导,发挥着十分重要的作用。有兴趣的读者可以进一步阅读[1][2],以获得库存理论更多的细节。
--
03 安全库存模型(safety stock)
上面的库存理论讲到补货的决策目标是在满足需求的情况下,最小化供应成本。作为模型的一种简化,我们先忽略成本因素,仅考虑如何决策才能满足用户的需求。
显而易见,如果不考虑成本,最佳的供应方式就是“用户买多少就进多少货”。但现实中进货总是发生在用户购买之前的,即“先进货,再售卖”。因此决定当前进多少货就变成了对未来的需求量预测。从统计学的角度,未来某段时间的需求服从一定的统计分布:
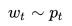
对模型作进一步的简化,我们假设需求服从的分布是正态分布:
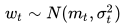
其中均值 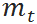 和标准差
和标准差 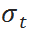 是待确定的参数。根据“进-销-存”模型,当给定 t 时刻的库存时,t+1 时刻 的库存
是待确定的参数。根据“进-销-存”模型,当给定 t 时刻的库存时,t+1 时刻 的库存 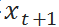 也服从正态分布:
也服从正态分布:
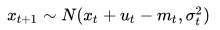
如果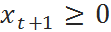 ,说明 t 到 t+1 时刻的需求能被充分满足;反之则会发生缺货,导致成交额的损失。
,说明 t 到 t+1 时刻的需求能被充分满足;反之则会发生缺货,导致成交额的损失。
从正态分布的性质我们知道,无论我们如何增大补货量,都无法100%的保障用户的需求,因为正态分布分布的最大值是∞。(当然现实中不可能发生需求∞的情况,但是有可能是一个很大的数值,比如双11促销时的需求。)这里我们引入一个名词叫做服务水平(service level - sl),它表明需求有多大的概率可以被满足。对于单个货品来说,服务水平 = 1- 缺货概率;而对于多个货品,服务水平 = 1 - 缺货率。通常我们所说“将缺货率控制在5%”,即相当于“将服务水平提升至95%”以上。对于服从正态分布的 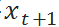 来说,我们可以将服务水平通过积分表达出来:
来说,我们可以将服务水平通过积分表达出来:
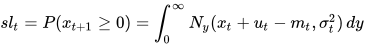
等式右边的积分可以用误差函数进一步表示:
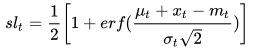
如果要保证服务水平大于95%,则需要误差函数满足:
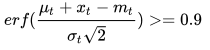
通过查表可得:
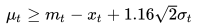
上面不等式的右边部分就是在图片时刻满足95%服务水平的最小补货量。
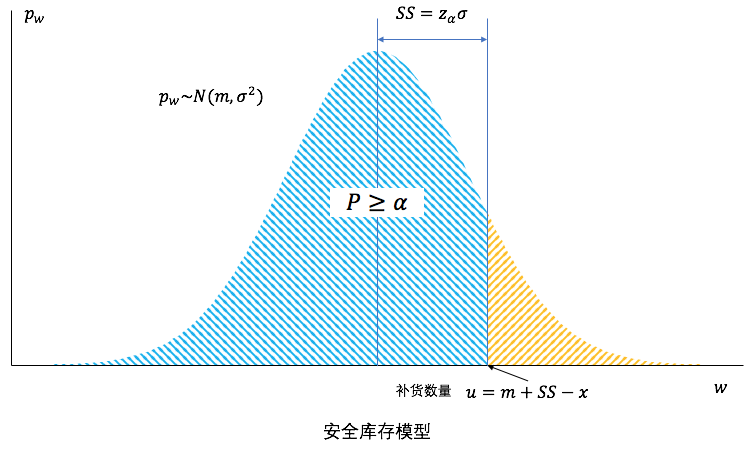
不难看出,为了满足较高的服务水平,我们不仅需要补足正常需求量(这里叫做需求量的均值),还要考虑需求波动带来的不确定性。为保证需求波动所额外准备的库存,就叫做安全库存(safety stock - SS)[3]。一般来说,安全库存可以表示为以下形式[4]:
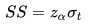
其中Z值对应了 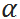 服务水平下的显著系数,服务水平越高,Z值越大。安全库存仅与服务水平和需求的标准差有关,与需求本身的数量无关。
服务水平下的显著系数,服务水平越高,Z值越大。安全库存仅与服务水平和需求的标准差有关,与需求本身的数量无关。
--
04 现实中的限制
安全库存模型仅考虑了为满足需求而求解得到的补货量最小值,但现实情况比该模型复杂得多。首先需要指出当补货订单下发后,货品不会马上入仓进行销售。在这期间供应商需要及时作出响应,并进行生产备货。在供应商发货后,货品还需要通过物流到达目的仓库,在这期间也会产生时间的延迟。我们可以定义补货订单下发到货品到仓的总体时间延迟为供应商交付时间(vendor leading time-VLT)。该交付时间我们我可以与供应商协商,保证交付时间小于一定的天数,也可以根据该供应商的历史表现统计得到。在第一种情况下,我们可以认为VLT是一个定值,那么安全库存模型得到的最小补货量只需要做稍微的改变:
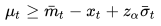
其中需求的均值和标准差只需要改变为“t+1时刻再向前数VLT时间至t时刻”的需求分布均值 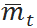 和标准差
和标准差 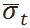 。后一种情况稍微复杂一些,因为根据历史统计得到的VLT也是一个分布。可以证明,在单位时间的需求分布不变且需求和VLT分别独立的服从正态分布的情况下,最小补货量可以表示为[5]:
。后一种情况稍微复杂一些,因为根据历史统计得到的VLT也是一个分布。可以证明,在单位时间的需求分布不变且需求和VLT分别独立的服从正态分布的情况下,最小补货量可以表示为[5]:
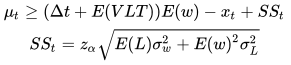
其中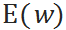 和
和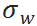 分别是单位时间需求的均值和标准差,
分别是单位时间需求的均值和标准差,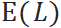 和
和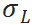 分别是VLT的均值和标准差。
分别是VLT的均值和标准差。
除了VLT之外,成本也是安全库存模型没有考虑的因素。成本分为物流成本和库存成本。在需求一定的情况下,如果订货太多,则会提升库存周转天数,增加库存成本。如果订货太少,则在供应商配送过程中货品装不满一车,导致物流成本率的增加。库存理论中有一种“经济订购批量”模型(economic order quantity - EOQ)[6]来最优化订货量,使得总成本最低。在零售通的供应链模式中,我们主要通过库存周转天数和最小起订量(minimum order quantity - MOQ)来近似表达成本的限制。
在零售通平台上,库存周转天数是指货品从入仓到销售之间存储在仓库中的天数。某个单品的库存周转天数越长,说明该单品所消耗的库存成本越高。最小起订量是一个补货订单中包含货品金额的最小值。如果订单中的补货量小于最小起订量,说明供应商的物流成本过高,不会进行发货供应。最小起订量是对一个供应商下的多个货品而言的,因为某一次补货订单可以包含多个单品的补货量。
除了考虑成本的因素,我们还需要考虑仓库收货的产能。仓库的收货发货需要人工作业,每天处理的订单量是有限的。如果某次补货的数量过大,导致仓库无法及时收货,则有可能导致货品无法入仓而发生损坏。另一种限制是“整箱补货”,因为在销售上可以零售,但供应上只能整箱批发。补货模型需要作出相应的调整来满足以上种种限制。
这一系列现实中的限制条件都使得一个简单的需求平衡问题变得复杂化。事实上,这里仅列出了零售通平台上需要考虑的主要限制。在不同的场景下(比如双11大促),限制条件将会变得更多更复杂。这导致了很多现实问题无法被数学形式化和模型化,从而给不出算法最优解。这也是新零售场景中供应链补货算法需要迎接的挑战和解决的难题。
--
05 整数线性规划(ILP): 一个简单的补货模型
基于上述限制条件,我们可以基于安全库存模型进一步改进补货模型。首先我们应该定义一个优化的目标,比如“最小化整体库存周转天数”。优化该目标需要满足以下限制:
1)保证每个货品的服务水平大于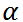 ;
;
2)供应商的最小起订量大于元Q;
3)订单中补货总量不超过仓库产能件K。
其它的限制暂时不考虑,因为它们并不影响我们对该问题的阐述。但其中有一个隐含的限制需要说明,就是即使不用整箱补货,每个单品也只能“一件一件的补”,比如不可能补1.5个货品。
下面我们将用数学形式化的表达优化目标和每一个限制。首先对一些变量和下标进行定义:

限制1: 每个货品的服务水平大于 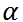 (安全库存模型):
(安全库存模型):
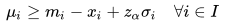
限制2: 供应商的最小起订量大于Q元:
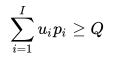
限制3: 订单中补货总量不超过仓库产能K件:
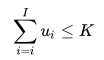
限制4: 单品的补货数量大于0且为整数
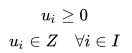
优化目标:最小化整体库存周转天数。(因为单品库存周转天数是需求的函数,如果需求随着时间变化,则无法将其表示为线性的形式。这里为了简单起见,假设每天的需求分布不变。)
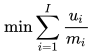
优化目标和限制条件均为关于  的线性表达式,加上
的线性表达式,加上 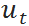 必须是整数的限制,可以很容易看出该问题是一个整数线性规划(integer linear programming - ILP)[7],可以通过很多算法工具包(比如cplex,gurobi等)进行求解。上面的公式写成更加紧凑的形式为:
必须是整数的限制,可以很容易看出该问题是一个整数线性规划(integer linear programming - ILP)[7],可以通过很多算法工具包(比如cplex,gurobi等)进行求解。上面的公式写成更加紧凑的形式为:
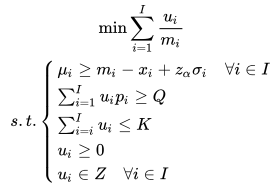
该整数规划模型虽然是对复杂的真实环境进行了简单的抽象,但它却反映了供应链补货的本质。我们可以形象的描述为“在钢丝上跳舞”。首先我们的决策不是自由的,它需要在各种“条条框框”(比如MOQ、产能、整箱补货等)中进行;其次补货时不能“用力过猛”,补得太多会导致库存周转天数上升,成本增高;也不能用力过轻,补得太少会导致需求无法被充分满足,导致成交额的损失。而整数规划模型正是描述了这种“恰到好处”的决策。而这种恰到好处不仅需要我们深入的理解新零售业务,并对此进行模型抽象,也需要我们对未来的需求以及需求的波动性进行准确的预测。下一期我们将着重讨论如何预测未来的需求分布,以及大数据和智能算法在其中的应用。
--
06 参考文献
-
Zipkin Paul H., Foundations of Inventory Management, Boston: McGraw Hill, 2000, ISBN 0-256-11379-3
-
Porteus, Evan L. Foundations of Stochastic Inventory Theory. Stanford, CA: Stanford University Press, 2002. ISBN 0-8047-4399-1
-
Monk, Ellen and Bret Wagner. Concepts in Enterprise Resource Planning. 3rd Edition. Boston: Course Technology Cengage Learning, 2009
-
Steven Nahmias, Production and Operation Analysis, Irwin 1989
-
Harris, Ford W. Operations Cost (Factory Management Series), Chicago: Shaw (1915)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号