
基于逻辑规则的图谱推理

导读: 近年来,知识图谱在众多行业场景被大量应用,例如推荐、医疗。为了构造尽可能完备的图谱,知识图谱的推理工作也成为学术届和工业界的一个重要研究课题。来自Mila人工智能实验室的瞿锰博士,给大家分享了他们在图谱推理任务方向的一个研究:基于逻辑规则的图谱推理(RNNLogic: Learning Logic Rules for Reasoning on Knowledge Graphs),研究结果显示RNNLogic可以很好地兼顾图谱推理任务的模型效果和可解释性的问题。
本文将围绕以下几点展开:
- 图谱和图谱推理介绍
- 常见方法和优缺点
- 逻辑规则学习方法 RNNLogic
- 工作展望
--
01 图谱和图谱推理介绍

知识图谱可以看作是我们真实世界中的一些事实的集合,每一条事实可以表示成(h,r,t)或者r(h,t)的形式。比如说我们知道比尔盖茨是微软公司的创始人,我们就可以得到一个(Bill Gates, co-founder of, Microsoft)的3元组组成的事实。在实际生活当中,有众多知识图谱,总结了各个领域的相关知识。
这些知识图谱在很多应用中发挥着重要作用。比如推荐系统中,知识图谱可以帮助我们更好地挖掘用户的兴趣;还有药物再利用方面,对于药物的属性、疾病的属性以及药物和疾病之间关系的已有信息,可以帮助我们去发现新的药物和疾病间的联系,从而更好地去对抗疾病。
不过在实际应用过程中存在的一个问题,图谱信息是不完全的,而补全图谱的人工成本又是非常巨大的,尤其是像是一些医药、金融等一些特定的领域。如果还要考虑知识的动态更新的话,就更加大了图谱补全的难度。
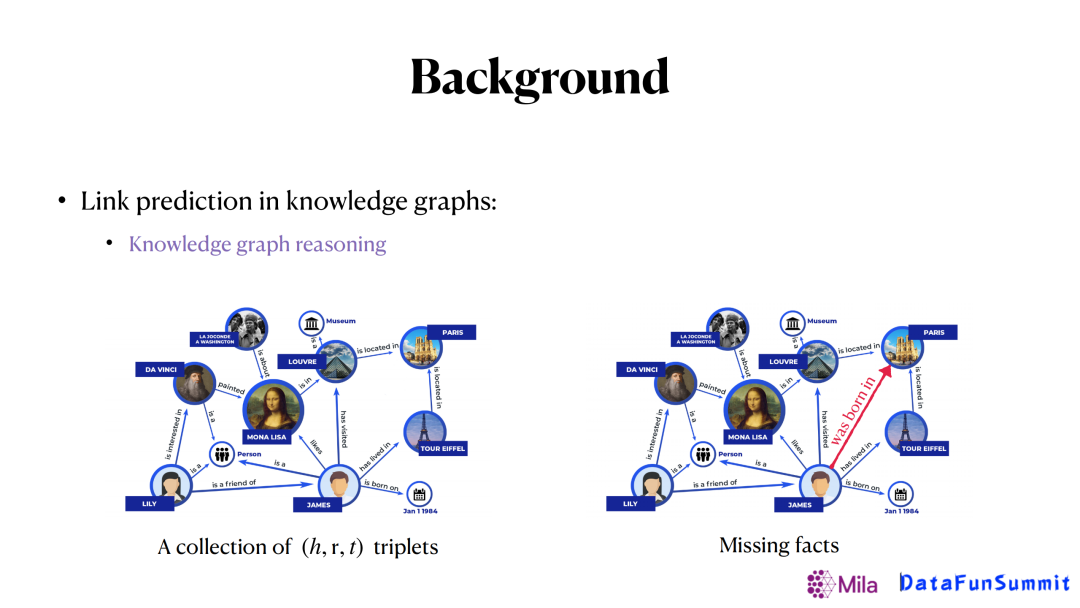
也正是这些问题促成了关系预测这个任务(用来补全图谱),在知识图谱里,关系预测也被称作知识图谱推理。图谱推理的任务就是给定已有图谱,去推理出图谱中的一些缺失的边。比如上图,我们希望能推出红色的边(詹姆斯出生在巴黎)。
--
02 常见方法和优缺点
1. 图谱表示法

图谱推理最常见的方法是基于知识图谱表示(KG Embedding)的方法,基本思想就是希望把每一个实体或者关系做向量嵌入,通过这些向量表示来进行推断找到缺失的边。
- 优点:通常能有较好的预测效果。
- 缺点:模型缺乏可解释性。
2. 归纳逻辑编程法
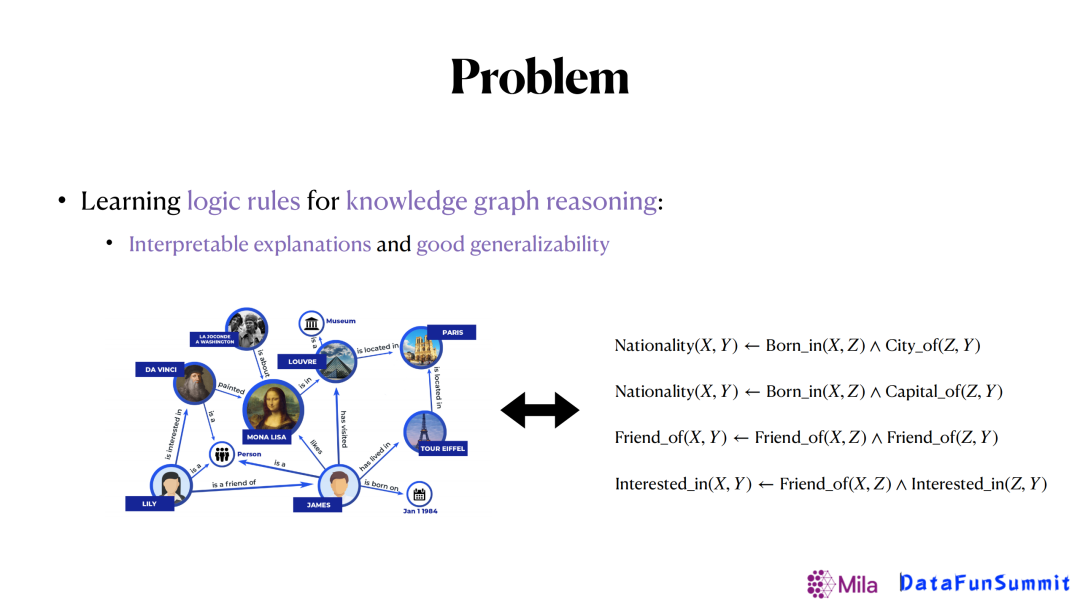
考虑到图谱嵌入法的可解释性差,我们希望通过学习一些逻辑规则来完成这个任务,提高可解释性。大概的思路是给定已有的知识图谱,我们希望可以从知识图谱里面提取出一些通用逻辑规则,如上图出生地(born in)和城市(city of)两个关系可以用来推断国籍(nationality),再反过来去做关系预测。通过这样的方式,可以使得模型的可解释性更强,而且生成的规则也具有更好的可泛化性。
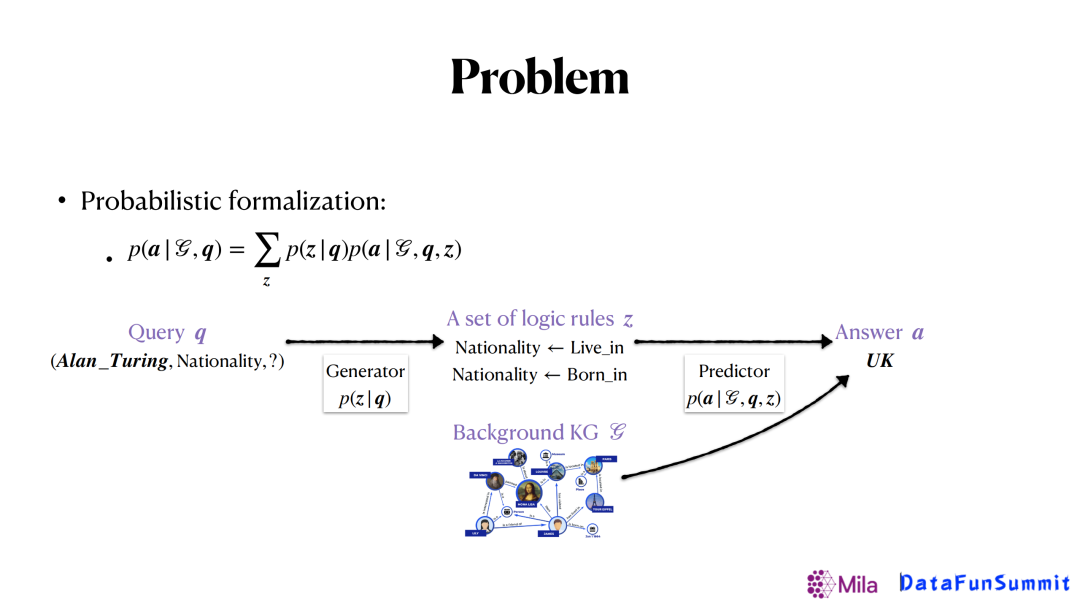
以上的问题可以通过概率形式建模。如上图所示,我们将这个任务建模分成两部分,生成器(generator)和 预测器(predictor)。其中生成器用来生成逻辑规则,预测器将利用生成的规则和已有的图谱去预测最后的答案。对于这样的形式,我们会有不同的方法来解决,其中之一是归纳逻辑编程(Inductive logic programming)。

这种方法的核心是学到一个好的预测器,然后在具体在操作的过程中,他们会利用一个固定的生成器(比如一套逻辑规则的模板)生成出大量的潜在逻辑规则,在预测阶段会给每个潜在的逻辑规则一个权重(weight),最后从所有的逻辑规则里面挑选权重大的规则,当作学习到的比较重要的规则。
- 优点:整个框架的优化比较简单。
- 缺点:对规则的搜索空间大,因为固定的生成器。如果想要得到比较好的结果就要尝试大量的逻辑规则,导致效率较低。
3. 基于强化学习的方法
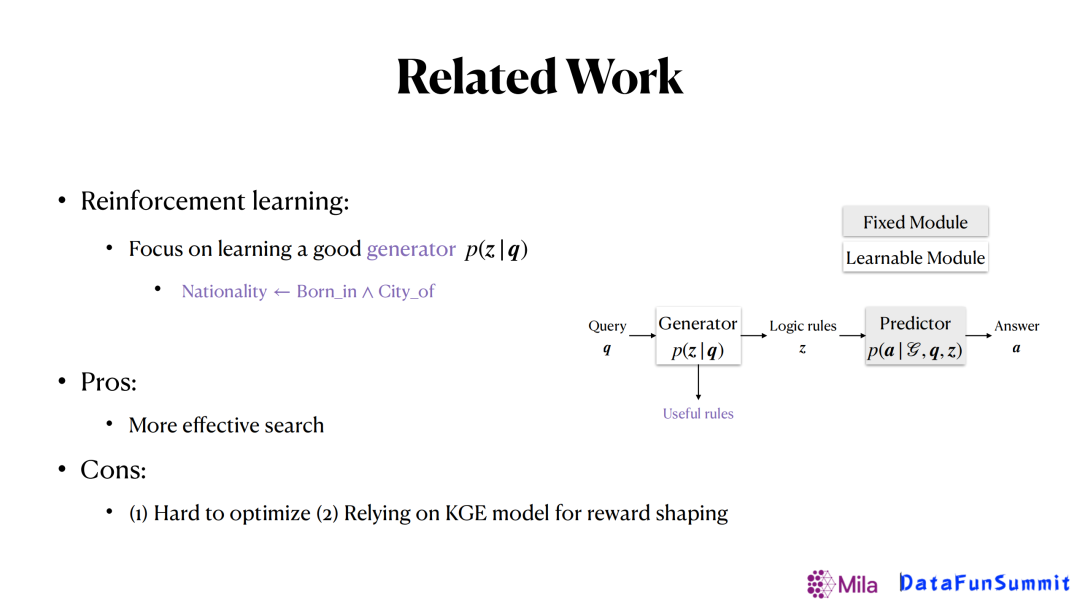
另外一类方法是基于强化学习的方法,其思想和之前的方法是完全相反的,是直接去学习一个生成器,给定一个查询(Query)后可以直接生成一个规则,一旦有了这个规则之后,就可以根据规则定义的关系在知识图谱上去做随机游走,得到我们想要的答案。在这个框架里,只有生成器是可以学习的,预测器是相对简单的,固定的。
- 优点:预测搜索效率高。
- 缺点:整个框架的优化很难;依赖KGE(图谱嵌入)的方法来做激励调整。
--
03 逻辑规则学习方法 RNNLogic
1. 研究背景

在对上面两个方法对比时,我们发现一个方法侧重在学习生成器,另一个侧重学习预测器。我们希望有一种框架,可以同时训练生成器和预测器,也就是RNNLogic的一个核心点。
2. RNNLogic方法

在我们的研究里主要考虑链式的逻辑规则,如上图中所示,可以将链式的逻辑规则变成一个关系序列,其中用END来表示结尾。那很自然的,我们可以通过LSTM来生成这些不同的链式逻辑规则,并输出每一条逻辑规则的概率,进而得到一个弱逻辑规则的集合。

接着我们使用了一个叫做随机逻辑编程(stochastic logic programming)的框架来去定义预测器。会通过生成器的弱关系集合进行游走,如图中所示的两种关系链,第一种可以得到France这个答案,第二个逻辑规则可以得到France,Canada和US三个答案。对于每个潜在答案,我们可以给它定义一个分数,也就是到达这个实体的逻辑规则的weight的和。最后就可以根据分数得到每种答案的概率,挑选出那些概率最大的来当成我们最终的答案。

当前方法的主要难点是如何优化,因为无论是生成器还是预测期,都是动态学习的,所以优化起来可能会有一定难度。而我们发现生成器和预测器两者的难度是不同的,前者由于对后者的依赖,使得生成器是需要依赖于预测器的结果来进行动态调整的,所以生成器会更难些。
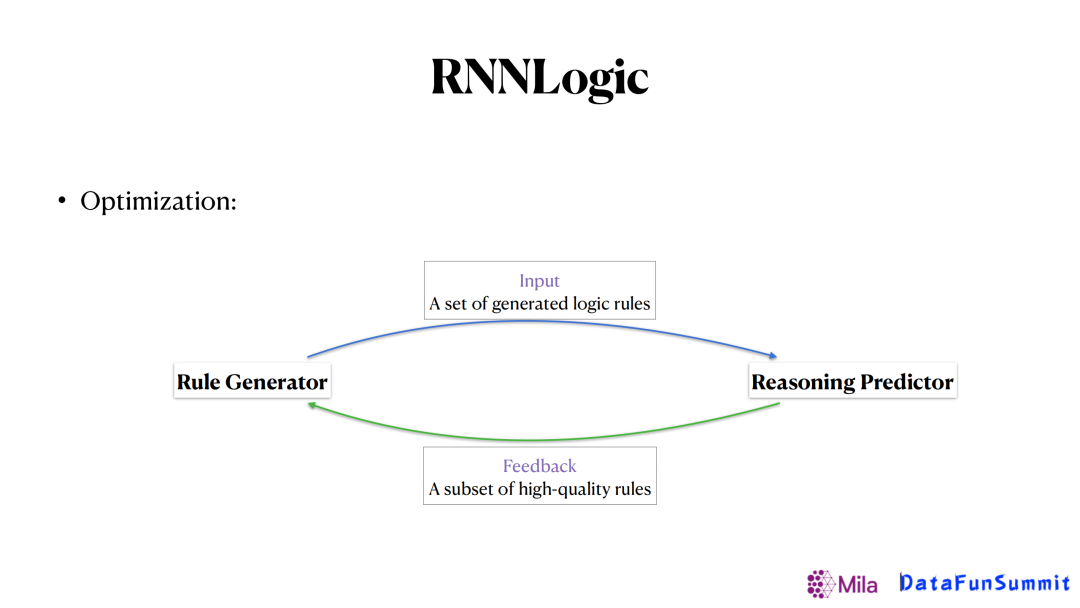
为了解决这个难点,我们提出了上图所示的框架。像之前的一些方法,是给定了一个生成器生成了一些逻辑规则送给预测期,让预测器给生成器反馈这个逻辑规则的集合是好还是坏。我们的思路是希望预测器给生成器的反馈更加具体,譬如哪几条规则更重要,从而帮助生成器更好地去更新,得到更好的结果。最后,整个优化的过程可以如下表示:

首先第一步,给定一个查询(Query),让生成器生成很多逻辑规则,再把逻辑规则和知识图谱同时送到预测器里面,去更新预测器,最大化生成正确答案的概率。
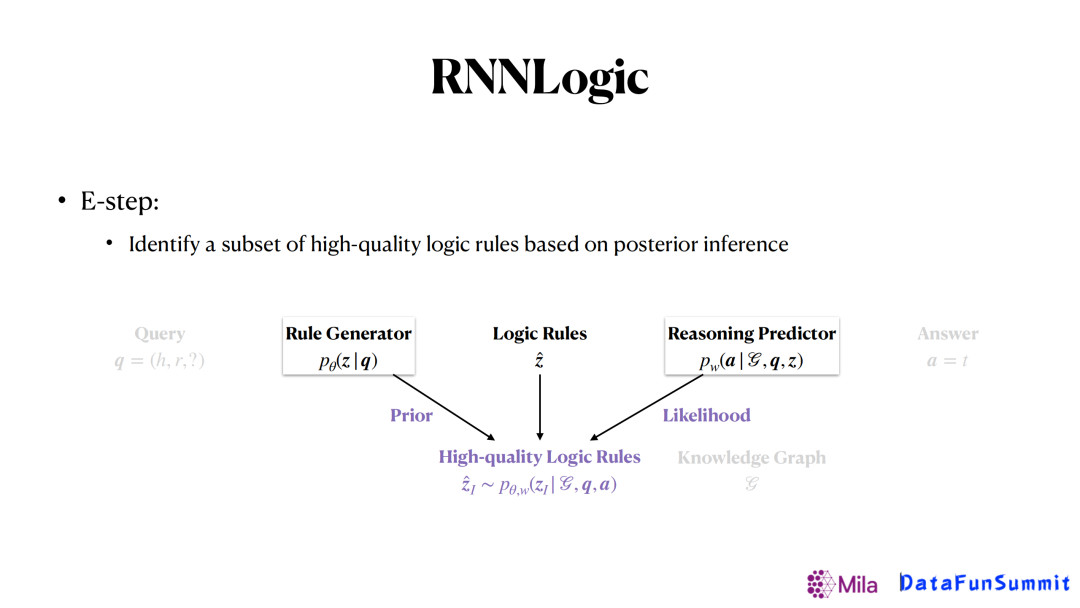
接着,从所有生成的这些逻辑规则里面去挑选出那些最重要的逻辑规则。这里我们通过使用后验推断的方法来计算每一条弱的逻辑规则的后验概率进行挑选。因此,在整个过程中,每一条弱的规则概率是由生成器来提供的,似然函数由预测器来提供。这样结合两者共同的信息来得到一个比较重要的逻辑规则。

最后,我们就可以把找到的高质量的逻辑规则当成训练数据,送回生成器去学习。
3. 实践效果
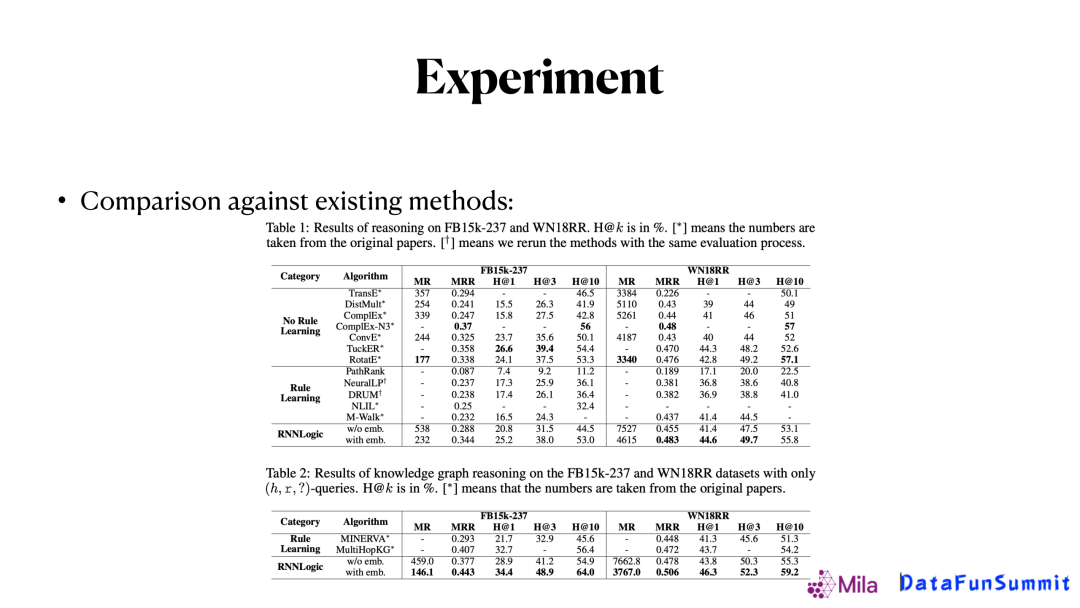
最后我们通过实验来比较我们的算法和现有算法的效果。上图是在常见的FB15K和WN18RR两个数据上的实验对比,可以看到,我们的方法能达到嵌入方法差不多的效果,而且有更好的可解释性,因此,它的潜力还是比较大的。
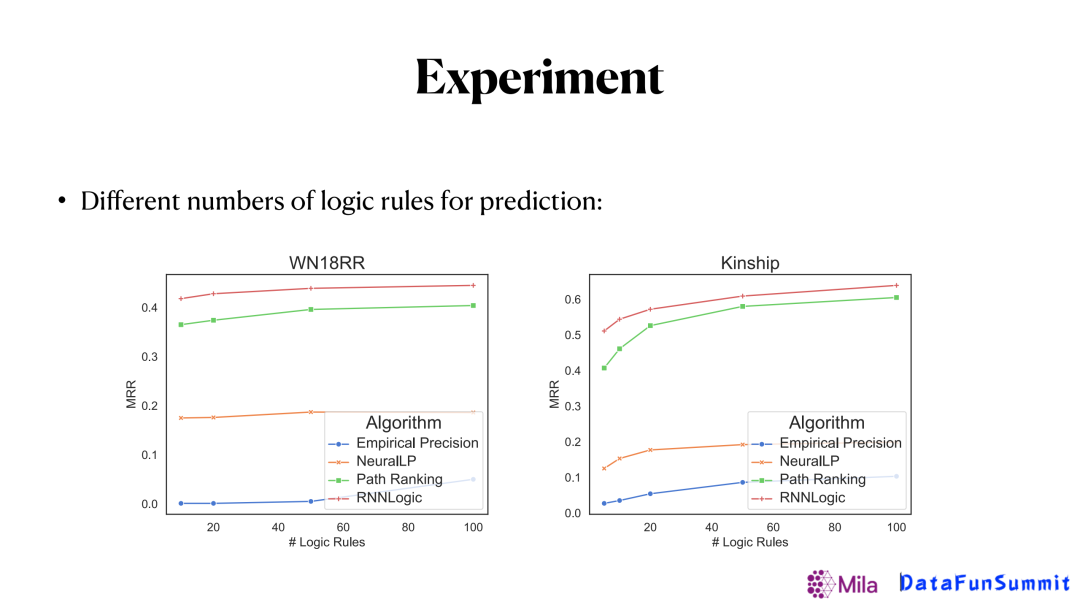
另一个有趣的实验是和模型生成的逻辑规则数量有关,可以看到针对某个关系,只生成10个逻辑规则就可以有个不错的效果,数量提升到100基本就收敛了。也就是只需要比较少的逻辑规则就可以对知识图谱中缺失的边进行有效的预测。

上图是我们最后生成的样例,整体规则是多样的,既有长度为1的比较短的规则,也有些跳四五步才能推断出来的很长的逻辑规则。
4. 更复杂的预测器(RNNLogic+)

接着我们实验一些更复杂的预测器来进行预测,前面仍然是给定一些逻辑规则,通过这些规则在图谱里我们会得到不同的路径,然后对于这些路径我们用不同的方法来打分。比如上图我们既用了LSTM的Score,也用了图嵌入(KGE)的Score来打分,来得出我们最终预测结果的得分和答案。
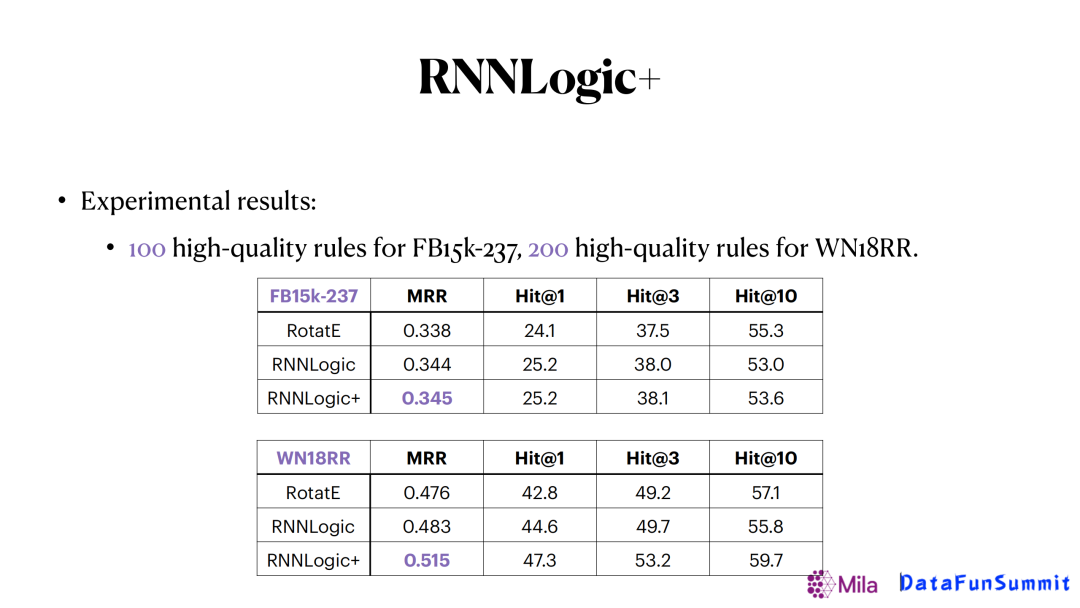
通过这个更复杂的预测器我们可以看到它的结果可以是被进一步提升的,如上图在两个数据集里我们分别用100个逻辑规则和200个逻辑规则,就可以得到非常好的结果。而且在像wordNet(WN18RR)这种相对稀疏的图谱中,提升更明显。
--
04 工作展望
基于逻辑规则的模型在知识图推理中受到越来越多的关注,因为它可以比较好的融合神经网络和符号规则的方法,而且会同时拥有比较好的可解释性和好的结果。今后一个值得探索的方向是,如何去设计更强大的neural-symbolic的模型。
第二个值得关注的方向是如何把文本信息结合进来。因为在实际应用的时候,我们会发现图谱并不是单独存在的,往往是和文本信息同时存在的,因此如何在这种混合的数据上面进行知识推理,也将会是一个值得探索的方向。
今天的分享就到这里,谢谢大家。
本文首发于微信公众号“DataFunTalk”。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号