
通用高效的数据修复方法:Row level repair
导读:随着大数据的进一步发展,NoSQL 数据库系统迅速发展并得到了广泛的应用。其中,Apache Cassandra 是最广泛使用的数据库之一。对于 Cassandra 的优化是大家研究的热点,而 ScyllaDB 则为其提供了一个新的思路。ScyllaDB 是一个基于 C++ 的开源的高性能的 Cassandra 的实现,较之 Cassandra 在性能上有了很大的提升。Nodetool repair 是 Cassandra 日常维护的重要一环,今天主要和大家分享一下 ScyllaDB 在这方面的优化。
今天的介绍会围绕下面五点展开:
ScyllaDB 介绍
Row level repair 介绍
Row level repair 实现
实验结果
总结
▌ScyllaDB 介绍
首先给大家简单介绍一下 ScyllaDB:
- ScyllaDB 的产生背景
我们公司是一家具有较多的底层软件开发经验的公司,团队创始人是 KVM 和 OSv 的作者。对于 Cassandra 数据库的优化,我们进行了一系列尝试。最开始是从操作系统的角度,通过提高操作系统的性能来提高 Cassandra 应用的性能,其效果是提高了 Cassandra 约20%的性能而无法再获得更高的性能提升。为了更好地优化 Cassandra,团队开始思考是否可以重新实现 Cassandra。我们首先开发了一个非常高性能的 C++ 的开源框架 Seastar,然后基于 Seastar 框架改写的 Cassandra 数据库,即 ScyllaDB。
- ScyllaDB 的特点

ScyllaDB 是一个开源的高性能的 Cassandra 的实现,具有以下几个特点:
一个速度极快的 NoSQL 数据库
单个节点的 QPS 可以达到1000000;可以扩展多个节点以提高性能,99%情况下延迟低于1毫秒。
使用 C++ 开发,没有 GC
每个物理 CPU 只部署一个线程,线程间无共享,无锁
每个物理 CPU 只部署一个线程,每个线程内部会有自己的 task,scheduler。每个线程跑完全独立的 Cassandra 的任务,因此不同线程之间没有共享,从而也没有锁。这样的效果是获得了较大的性能提升,并且在有较多物理核的时候具有较高的可扩展性。
在用户态实现 CPU 和 DISK scheduler,以及可选 TCP/IP 协议栈
在用户态实现 CPU scheduler,不同的任务设定不同的优先级,分配不同的 CPU 资源;进行了磁盘的优化,不使用操作系统的 page cache,完全 DMA 操作,实现 DISK scheduler,精确控制各个模块 DISK 的使用情况;实现了可选的用户态的 TCP/IP 协议栈。
提供 Apache Cassandra 和 Amazon DynamoDB 的 API
▌Row level repair ( 行级修复 )
- 什么是 repair

首先介绍一下什么是 repair:
修复是 Cassandra 中一个重要的维护操作。
Cassandra 中的数据具有多个副本,有可能在写操作发生时某些节点不在线,从而拿不到数据的副本,导致了数据的不一致。这种情况发生时,需要让各个节点的数据一致,即 repair。
repair 的两个步骤:
第一步:发现不同节点数据副本之间的不一致。
第二步:修复不一致的数据。
- Partition level repair ( 分区级修复 ) 的问题
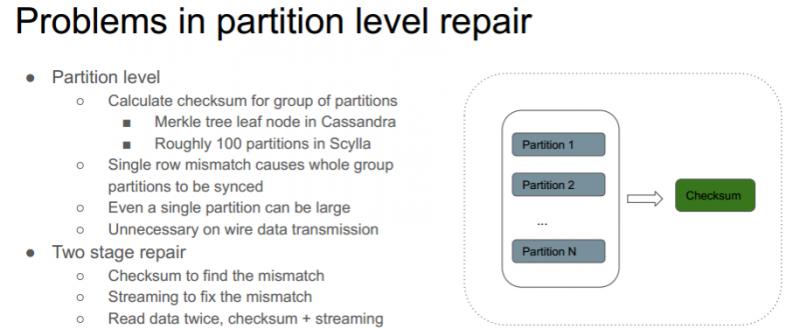
Partition level
目前的 Cassandra 以及 ScyllaDB 3.1 版本之前使用的是 partition level repair。为发现数据不一致需要对一组 partitions 进行哈希得到一组 checksum。对于 Cassandra 是 Merkle tree ( 默克尔树 ) 中的叶子节点,对于 ScyllaDB 是将 token range 进行拆分,直到每个 range 里面有约100个 partition。
其问题在于,哈希的粒度太大,会导致不必要的数据传输:
① 单个行的不一致会导致所有一组 partitions 在网络上传输。
② 有些节点上的分区会很大 ( 达到 5G )。
Two stage repair
Repair 过程包括两个阶段:
① 通过计算比较哈希值寻找不一致的数据,记录下来不一致的节点和 token range。
② Streaming:根据记录的节点和 token range 传输数据进行 repair。
其问题在于,需要两次读取数据,读磁盘开销较高。
- Row level repair ( 行级修复 ) 介绍
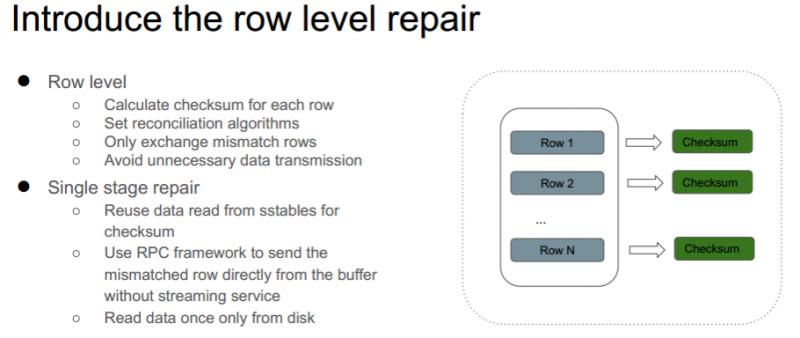
Row level
考虑 partition level 修复粒度太大,存在不必要数据传输的问题,减小修复的粒度:
① 对每一行进行哈希计算得到一个 checksum。
② 利用 set reconciliation 算法,使每个节点得到一个统一的哈希集合,包含所有应有数据的哈希值。
③ 只传输不一致的数据行。
Single stage repair
Row level repair 只有一个阶段,因为通过缩小粒度,正在工作的数据集规模被大大缩小,可以完全放进内存。数据只需要从磁盘读取一次,使用 RPC 框架传输缓存中的不一致数据而不需要额外的 streaming 操作,大大降低了读数据的开销。
下面,重点分享下 row level repair 的实现细节。
▌Row level repair 的实现

Row level repair 具有两个重要元素:
① Master:运行 nodetool repair 命令的节点。
② Followers:具有数据备份的节点。
Row level repair 有三个主要步骤:
① 首先,master 与其 followers 协商 sync boundary ( 同步边界 ),以便确定 repair 工作开始的 range。Sync boundary 确定了一 个range,使其中的数据行可以全部放进内存。这个 range 可以小于一个 partition,因此允许 repair 工作在一个大的 partition 的一小部分上。
② 然后,master 从 followers 获取上述范围内它缺少的数据行,使得 master 最终包含所有数据行。这里缺少的数据行有两个含义:其一是确实缺少的数据,其二是有但是内容不同的数据。
③ 最后,master 通过分析得知 followers 各自缺少的数据行,并将缺失的数据行发送给对应的 follower,最终所有 followers 包含所有的数据行。
下面详细介绍 row level repair 的各个步骤。
步骤一:协商 sync boundary ( 同步边界 )
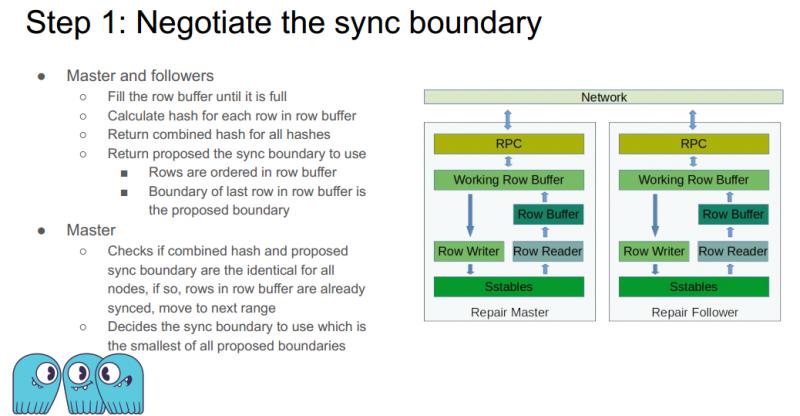
首先,Master 和 followers 读取数据直到设定大小的数据行缓存满 ( 如 32M ),计算缓存中每行数据的哈希,并对得到的所有哈希计算一个整体哈希值 ( 如异或 )。Followers 将得到的联合哈希值返回给 master,同时也将 sync boundary 返回给 master。这里请注意,缓存中的数据行是有序的,缓存中的最后一行将作为返回的 sync boundary。
然后,此时的 master 节点已经拿到了所有 followers 节点的整体哈希值和 sync boundary,master 比较这些哈希值和 sync boundary。如果所有节点哈希值一致且 sync boundary 一致,则代表此时这个 range 的数据完全一致,因此继续处理下一个 range 的数据。如果 sync boundary 不一致,master 会选择最小的一个作为本轮的 sync boundary。如果选择的不是最小的,则会导致有多余的数据在本轮同步,违反了有限数据到内存的原则。
步骤二:移动数据到 working row buffer ( 工作缓存 )
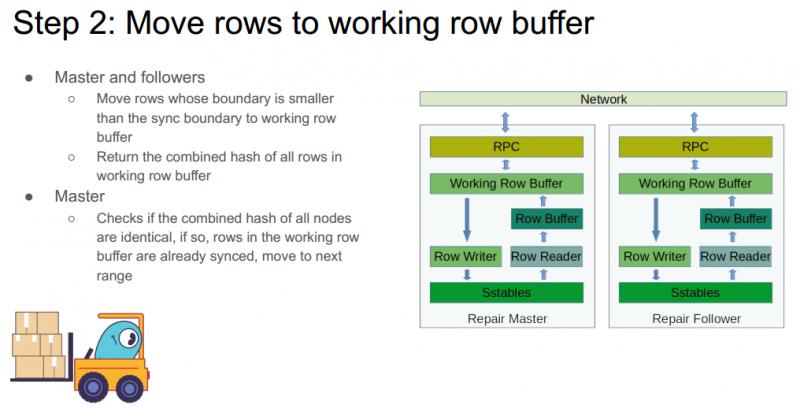
经过第一步的操作,此时所有节点具有一个统一的 sync boundary。
首先,每个节点把 sync boundary 之内的所有数据移动到 working row buffer 中,每个 follower 会返回一个整体哈希值。
然后,master 节点检查 working row buffer 中各个节点的整体哈希值是否一致,如果一致,则继续处理下一个 range 的数据。如果不一致,则进行下面第三个步骤。
步骤三:得到所有数据行哈希值
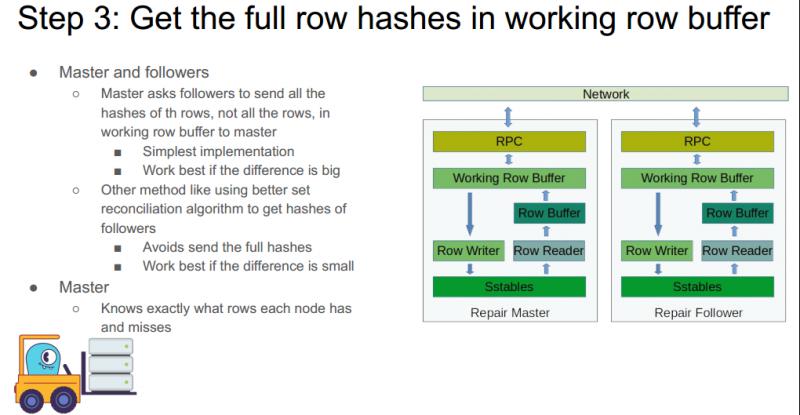
如果存在节点 working row buffer 中数据的整体哈希值不一致,此时则需要对数据进行 repair。Repair 工作首先要进行的,就是得到各个节点 working row buffer 中所有数据的哈希值集合。这个过程有两个比较常用的方法:
第一种是比较暴力的方法:Master 节点要求所有 follower 节点将其所有数据行的哈希值集合发送给 master,这种方法最容易实现,并且在数据差异特别大的时候是最有效 ( 经测试,如果差异数据占比15%以上,这种暴力方式最有效 )。
第二种方法 ( 如 IDF ) 巧妙地构建一些很小的数据结构,followers 不需要传输所有的哈希值,而是只发送这个数据结构让 master 推测出其具有的数据行。这种方法在数据差异较小的时候最有效。
当拿到所有的哈希之后,master 节点就很清晰地知道了每个 follower 节点有哪些数据行,缺少那些数据行。接下来则需要进行第四个步骤,得到所有的数据行。
步骤四:获取所有缺少的数据行
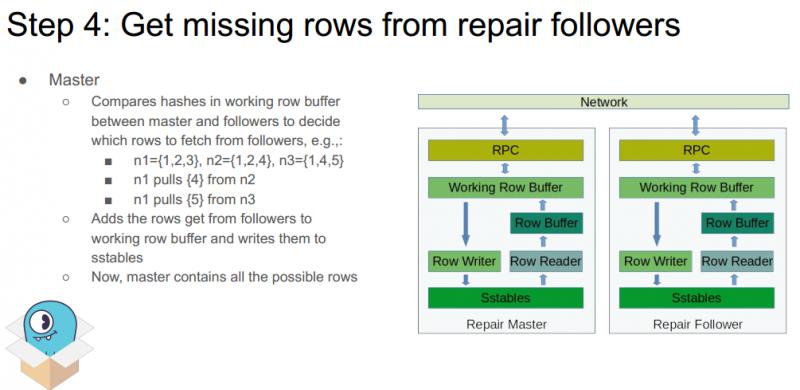
Master 节点通过第三个步骤获得了所有节点 working row buffer 中的数据行哈希。Master 比较本节点的哈希值集合和 follower 节点的哈希值集合,得到本节点缺少的数据行,从而确定应该去每个 follower 节点获取哪些数据,例如:
n1 节点包含数据 {1,2,3},n2 节点包含数据 {1,2,4},n3 节点包含数据 {1,4,5},n1 节点是 master 节点,则 n1 需要从 n2 获取数据 {4},从 n3 获取数据 {5},最终 n1 包含数据 {1,2,3,4,5}。
然后 Master 从 follower 节点读取缺少的数据到 working row buffer,并写进磁盘 SStables。此时,master 节点已经包含了所有的数据信息。
步骤五:将缺少的数据发送给 followers
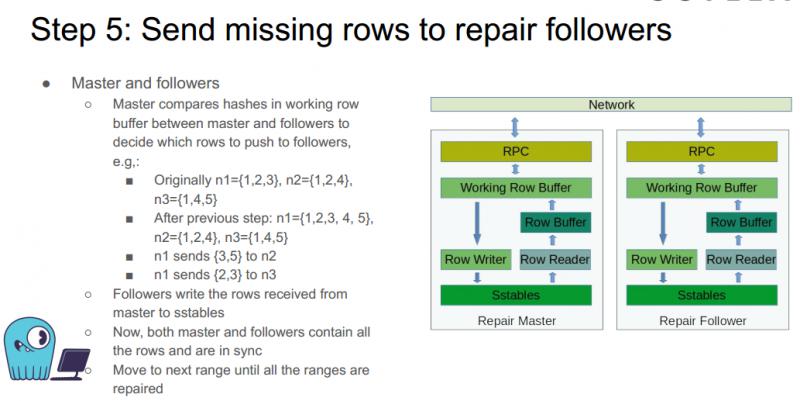
通过前四步,master 节点已经具有了 sync boundary 以内的所有数据,接下来则需要对 follower 节点进行修复。
Master 通过比较本节点和 follower 节点 working row buffer 中数据的哈希值,确定需要将哪些数据推送到哪些节点。例如步骤四中的例子:
最开始 n1 节点包含数据 {1,2,3},n2 节点包含数据 {1,2,4},n3 节点包含数据 {1,4,5}。经过第四步, n1 包含数据 {1,2,3,4,5},n2 包含数据 {1,2,4} ,n3 包含数据 {1,2,5}。在本步骤,n1 将 {3,5} 发送给 n2,将 {2,3} 发送给 n3。
然后 follower 节点将从 master 节点接受到的数据写进磁盘 SStables。此时 master 和 follower 节点中 sync boundary 之内的数据已经达到一致,本轮的 repair 结束。
如果还有更多数据需要 repair,则重复这五个步骤,知道所有数据修复完毕。
▌实验结果
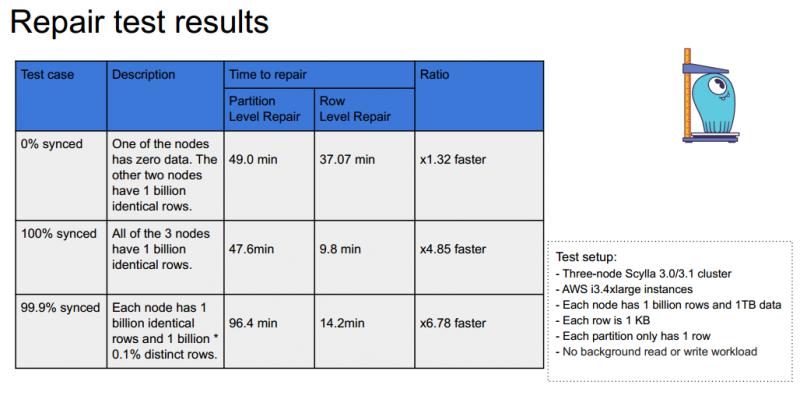
实验测试了一个三节点集群,每个节点包含十亿行数据,大小为 1TB,每行数据大小为 1KB,每个分区只有一行数据。测试包含三个场景:
第一个场景是,其中一个节点完全没有数据,另外两个节点有相同的数据,模拟节点的重建。
第二个场景是,各个节点数据完全一致,用来测试数据一致的情况下的 repair 操作的速度。
第三个场景是最常见的情况,即各个节点大量数据是一致的,只有千分之一的数据行不一致。因为在集群运维过程中,是比较推荐定期 repair 的,如果定期 repair,实际数据差异是比较小的。
第三种场景,row level repair 速度获得了六倍的提升,原因是为什么呢?
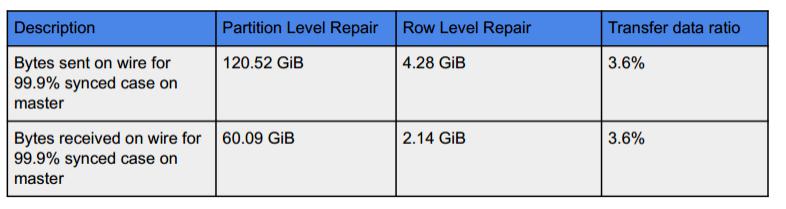
第三种场景,row level repair 速度获得了六倍的提升,原因是为什么呢?我们对 master 节点需要真正传输和接受的数据量做了一个统计,row level repair 只有 partition level repair 的约4%,数据传输量的大幅度减少是速度提升的最主要原因。

综上,从实验结果分析得知,row level repair 速度快的原因有三个方面:
没有多余的数据传输,本次实验每个 partition 只有一行数据,当每个 partition 中数据更多时,速度提升会更多。
更快的哈希方法,partition level repair 数据量比较多,因此使用效果更强的256位加密 SHA256 哈希方法,而 row level repair 数据量较少,因此使用64位无加密 xxhash,因此速度更快。
提高了 repair 的并行度,partition level repair 只并行修复一个 token range 的数据,但是 row level repair 同时并行修复更多的 token range 的数据。Scylla 3.1 是16个,3.2更加优化,可以根据每个节点的内存情况确定并行数量。在未来的版本中,还会进一步优化,根据节点之间网络的延迟自动计算一个最优的并行数。这一点对于跨 DC 的集群非常有用,跨 DC 的集群节点之间延迟较高。在这种情况下,为了提高 repair 的吞吐量,需要提高有效缓存的大小。
▌总结

通过前面的介绍,大家应该对 row level repair 有了大致的了解。Row level repair 降低了数据修复的粒度,从分区粒度到单行数据的粒度,减少了数据的传输量,减少了数据修复所需的时间,并且减少了 IO 请求,减少了磁盘的读取。
综上,Row level repair 是一个通用的高效的数据修复方法,希望能对大家有所帮助。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号