人机对话技术研究进展与思考

嘉宾:袁彩霞 博士 北京邮电大学 副教授
整理:Hoh Xil
来源:阿里小蜜 & DataFun AI Talk
出品:DataFun
注:欢迎转载,转载请在留言区内留言。
导读:本次分享的主题为人机对话技术研究进展与思考。主要梳理了我们团队近两年的工作,渴望可以通过这样的介绍,能给大家一个关于人机对话 ( 包括它的科学问题和应用技术 ) 方面的启示,帮助我们进行更深入的研究和讨论。主要包括:
-
Spoken dialogue system:a bird view ( 首先我们来看什么是人机对话,尤其是 Spoken dialogue。其实说 Spoken 的时候,有两层含义:第一个 spoken 就是 speech,第二个我们处理的语言本身具有 spoken 的特性。但是,稍后会讲的 spoken 是指我们已经进行语音识别之后,转换为文本的一个特殊的自然语言,后面讨论的口语对话不过多地讨论它的口语特性,主要是讲人和机器之间的自然语言对话。)
-
X-driven dialogue system:紧接着来讲解我们近些年的研究主线 X-driven dialogue syatem,X 指构建一个对话系统时,所采用的数据是什么,从最早的 dialogue -> FAQ -> KB -> KG -> document 以及我们一直在尝试的图文多模态数据。
-
Concluding remarks ( 结束语 )
01
Spoken dialogue system:a bird view
学术界关于对话系统有着不同的划分,这种划分目前看来不是非常准确,也不是特别标准的划分了。但是,接下来的内容,主要是围绕着这两个主线:
限定领域,专门指任务型对话 ( 围绕某一特定用户对话目标而展开的 )。对于任务型对话,对话系统的优化目标就是如何以一个特别高的回报、特别少的对话轮次、特别高的成功率来达成用户的对话目标。所以即便是限定领域,我们这里讨论的也是特别限定的、专门有明确的用户对话目标的一种对话。
开放领域,not purely task-oriented, 已经不再是纯粹的对话目标驱动的对话,包括:闲聊、推荐、信息服务等等,后面逐步展开介绍。

我们在研究一个问题或者做论文答辩和开题报告时,经常讨论研究对象的意义在哪里。图中,前面讲的是应用意义,后面是理论意义。我们实验室在北京邮电大学叫智能科学与技术实验室,其实她的前身叫人工智能实验室。所以从名字来看,我们做了非常多的 AI 基础理论的研究,我们在研究这些理论的时候,也会讲 AI 的终极目的是研制一种能够从事人类思维活动的计算机系统。人类思维活动建立在获取到的信号的基础上。人类获取信号的方式大体有五类,包括视觉、听觉、触觉、味觉、嗅觉等,其中视觉和听觉是两个比较高级的传感器通道,尤其是视觉通道,占据了人类获得信息的80%以上。所以我们从这两个角度,设立了两个研究对象:第一个是语言,第二个是图像。而我们在研究语言的时候,发现语言有一个重要的属性,叫交互性,交互性最典型的一个体现就是对话;同时,语言不是一个独立的模态,语言的处理离不开跟它相关的另一个通道,就是视觉通道。所以我们早期更多是为了把交互和多模态这样的属性纳入到语言建模的范围,以其提升其它自然语言处理系统的性能,这就是我们研究的一个动机。
- Block diagram
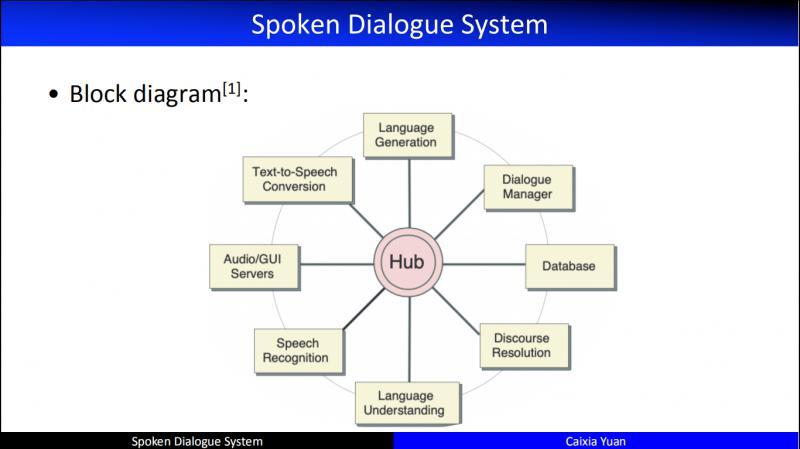
上图为 CMU 等在1997年提出来的人机对话框架,基于这个框架人们开发出了非常多优秀的应用系统,比如应用天气领域的 "Jupiter"。这个框架从提出到商业化应用,一直到今天,我们都还沿着这样的一个系统架构在进行开发,尤其是任务驱动的对话。
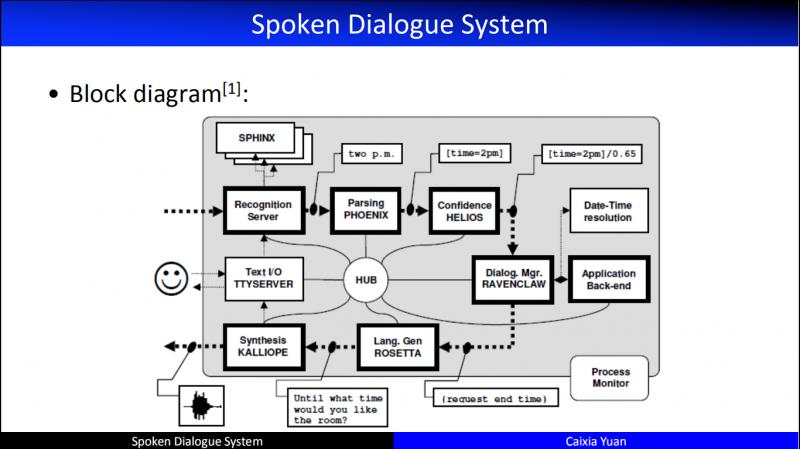
这就是具体的对话系统的技术架构。
- Specific domain
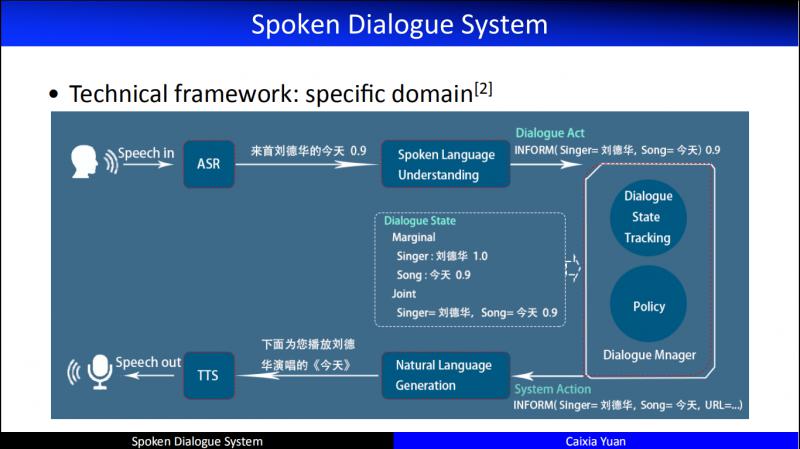
这个架构发展到现在,在功能模块上,已经有了一个很清晰的划分:
首先进行语音识别,然后自然语言理解,紧接着做对话管理,将对话管理的输出交给自然语言生成模块,最后形成自然语言应答返回给用户。这就是一个最典型的 specific domain 的架构。早期 task 限定的 dialogue,基本上都是按照这个架构来做的。这个架构虽然是一个 Pipeline,但是从研究的角度来讲,每一个模块和其它模块之间都会存在依赖关系。因此,我们试图从研究的角度把不同的功能模块进行统一建模。在这个建模过程中,又会产生新的学术性问题,我们旨在在这样的问题上可以产生驱动性的技术。
- Open domain
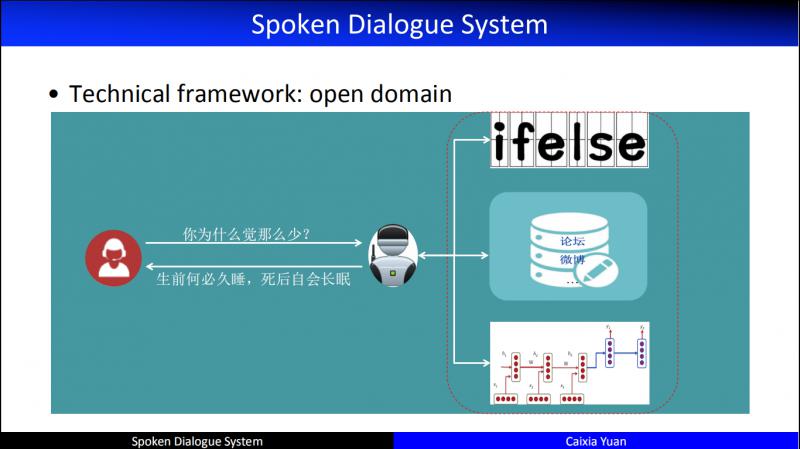
Open domain,也就是“闲聊”,实现上主要分为途径:
第一个是基于匹配/规则的闲聊系统;第二个是基于检索的闲聊系统;第三个是基于编解码结构的端到端对话系统。当然,实际情境中,这几个途径往往结合在一起使用。
02
X-Driven dialogue system
目前无论是任务型对话还是闲聊式对话,都采用数据驱动的方法,因此依据在构建人机对话系统时所用到的数据不同,建模技术和系统特性也就体现出巨大的不同。我们把使用的数据记为 X,于是就有了不同的 X 驱动的对话。
- Our roadmap
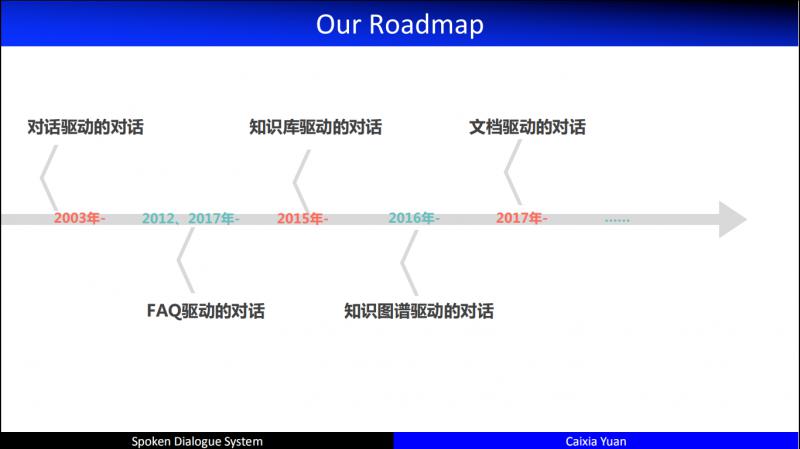
如果想让机器学会像人一样对话,我们可以提供的最自然的数据就是 dialogue。我们从2003年开始做对话驱动的对话;2012年开始做 FAQ 驱动的对话;2015年开始做知识库 ( KB ) 驱动的对话;2016年开始做知识图谱 ( KG ) 驱动的对话,相比于 KB,KG 中的知识点产生了关联,有了这种关联人们就可以在大规模的图谱上做知识推理;2017年开始做文档驱动的对话。这就是我们研究的大致脉络。
- Dialogue-driven dialogue
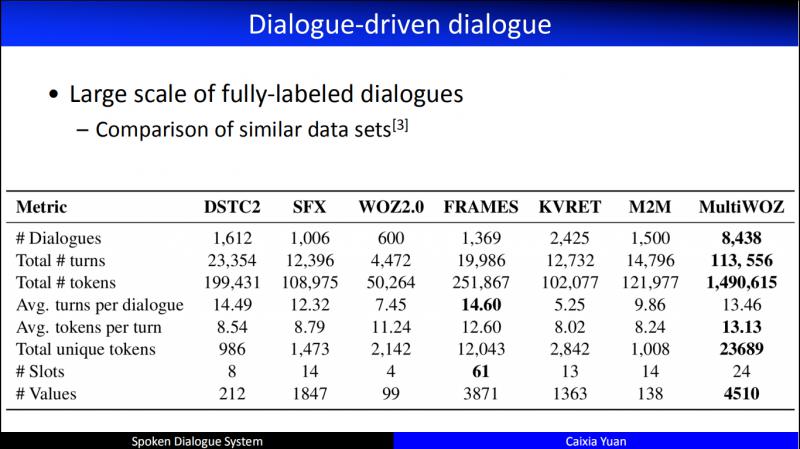
早期在做 Dialogue driven 的时候,多依赖人工采集数据,但是,从2013年以来,逐步开放了丰富的涵盖多领域多场景的公开数据集。比如最近的 MultiWOZ,从 task specific 角度讲,数据质量足够好、数据规模足够大,同时涵盖的对话情景也非常丰富。但是,目前公开的中文数据集还不是很多。
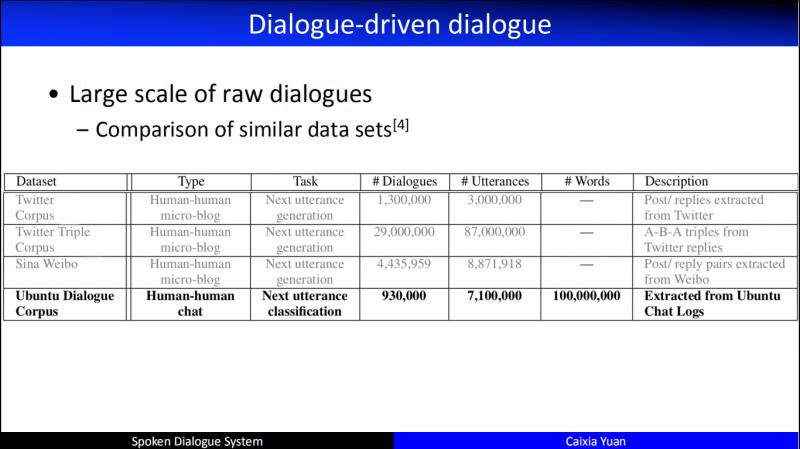
这个是和任务型对话无关的数据集,也就是采集的人与人对话的数据集。尤其以 Ubuntu 为例,从15年更新至今,已经积累了非常大规模的数据。
以 Dialogue 为输入,我们开展了任务型和非任务型两个方向的工作。先来看下任务型对话:
2.1 NLU

当一个用户输入过来,第一个要做的就是自然语言理解 ( NLU ),NLU 要做的三件事为:Domain 识别;Intent 识别;信息槽识别或叫槽填充。这三个任务可以分别独立地或采用管道式方法做,也可以联合起来进行建模。在联合建模以外,我们还做了一些特别的研究。比如我们在槽识别的时候,总是有新槽,再比如有些槽值非常奇怪,例如 "XX手机可以一边打电话一边视频吗?",对应着槽值 "视频电话",采用序列标注的方式,很难识别它,因为这个槽值非常不规范。用户输入可能像这样语义非常松散,不连续,也可能存在非常多噪音,在进行联合建模时,传统的序列标注或分类为思想,在实际应用中已经不足以解决问题了。
我们针对这个问题做了比较多的探讨,右图为我们2015年的一个工作:在这三个任务联合建模的同时,在槽填充这个任务上将序列标注和分类进行同时建模,来更好地完成 NLU。
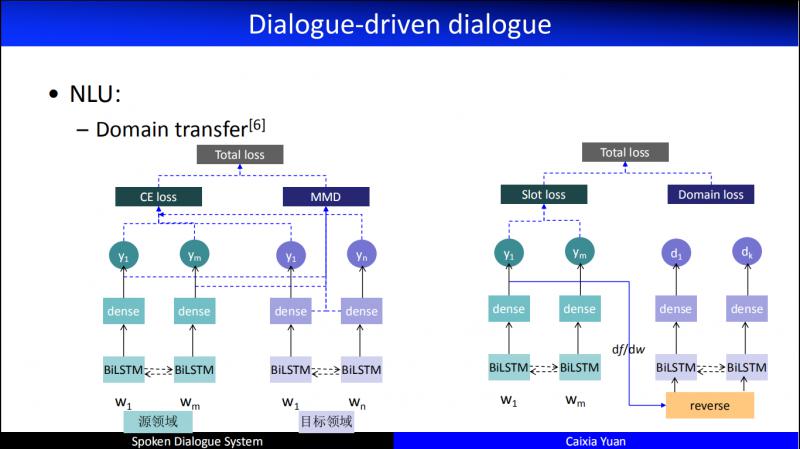
在 NLU 领域还有一个非常重要的问题,随着开发的业务领域越来越多,我们发现多领域对话产生了诸多非常重要的问题,例如在数据层有些 domain 数据可能很多,有些 domain 数据可能很少,甚至没有,于是就遇到冷启动的问题。因此,我们做了非常多的 domain transfer 的工作。上图为我们2016年的一个工作,我们会把数据比较多的看成源领域,数据比较少的看成目标领域。于是,尝试了基于多种迁移学习的 NLU,有的是在特征层进行迁移,有的是在数据层迁移,有的是在模型层进行迁移。图中是两个典型的在特征层进行迁移的例子,不仅关注领域一般特征,而且关注领域专门特征,同时采用了对抗网络来生成一个虚拟的特征集的模型。
2.2 NLU+DM
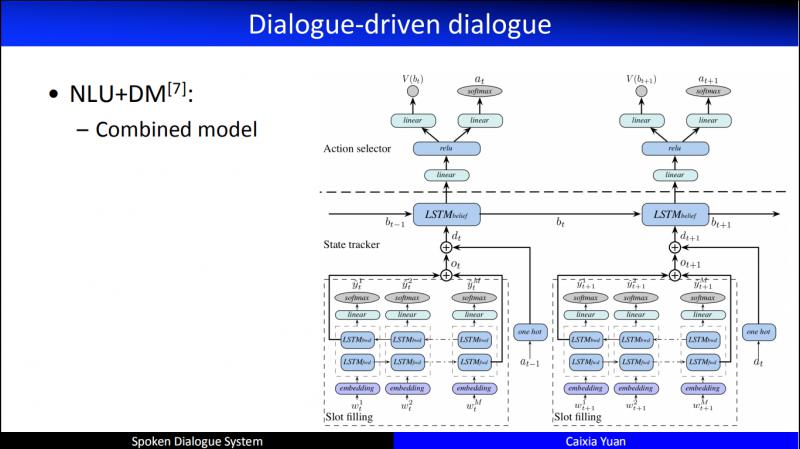
紧接着,我们研究了 NLU 和对话管理 ( DM ) 进行联合建模,因为我们发现人人对话的时候,不见得是听完对方说完话,理解了对方的意图,然后才形成对话策略,有可能这两个过程是同时发生的。甚或 DM 还可以反作用于 NLU。早期我们基于的一个假设是, NLU 可能不需要一个显式的过程,甚至不需要一个显式的 NLU 的功能,我们认为 NLU 最终是服务于对话管理 ( DM ),甚至就是对话管理 ( DM ) 的一部分。所以,2013年的时候,我们开始了探索,有两位特别优秀的毕业生在这两个方面做了特别多的工作。比如,如何更好地联合建模语言理解的输出和对话管理的策略优化。这是我们在 NLU 和 DM 联合建模的工作,同时提升了 NLU 和 DM 的性能。

在联合模型中,我们发现,DM 的建模涉及到非常多的 DRL ( 深度强化学习 ) 的工作,训练起来非常困难,比如如何设计一个好的用户模拟器,基于规则的,基于统计的,基于语言模型的,基于 RL 的等等我们尝试了非常多的办法,也取得了一系列有趣的发现。2018年时我们研究一种不依赖于规则的用户模拟器,业界管这个问题叫做 "Self"-play,虽然我们和 "Self"-play 在网络结构上差异挺大的,但是我们还是借鉴了 "Self"-play 训练的特性,把我们自己的系统叫做 "Self"-play。在这样的机制引导下,我们研究了不依赖于规则,不依赖于有标记数据的用户模拟器,使得这个用户模拟器可以像 Agent 一样,和我们所构造的对话的 Agent 进行交互,在交互的过程中完成对用户的模拟。
在训练过程中还有一个重要的问题,就是 reward 怎么来,我们知道在 task oriented 时,reward 通常是人类专家根据业务逻辑/规范制定出来的。事实上,当我们在和环境交互的时候不知道 reward 有多大,但是环境会隐式地告诉我们 reward 是多大,所以我们做了非常多的临接对和 reward reshaping 的工作。
2.3 小结

Dialogue-driven dialogue 这种形式的对话系统,总结来看:
优点:
定义非常好,逻辑清晰,每一个模块的输入输出也非常清晰,同时有特别坚实的数学模型可以对它进行建模。
缺点:
由于非常依赖数据,同时,不论是在 NLU 还是 NLG 时,我们都是采用有监督的模型来做的,所以它依赖于大量的、精细的标注数据。
而 DM 往往采用 DRL 来做。NIPS2018 时的一个 talk,直接指出:任何一个 RL 都存在的问题,就是糟糕的重现性、复用性、鲁棒性。
- FAQ-driven dialogue
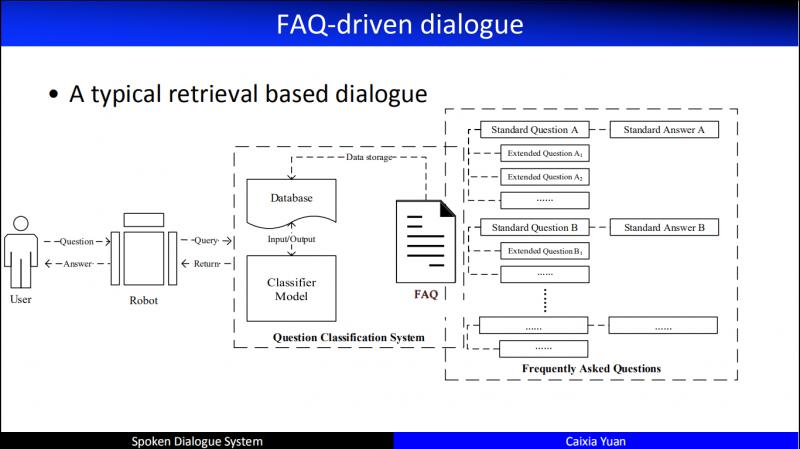
FAQ 是工业界非常常见的一种情景:有大量的标准问,以及这个标准问的答案是什么。基于这个标准问,一个用户的问题来了,如何找到和它相似的问题,进而把答案返回给用户,于是这个 Service 就结束了。
实际中,我们如何建 FAQ?更多的时候,我会把这个问题和我们库的标准问题做一个相似度的计算或者做一个分类。
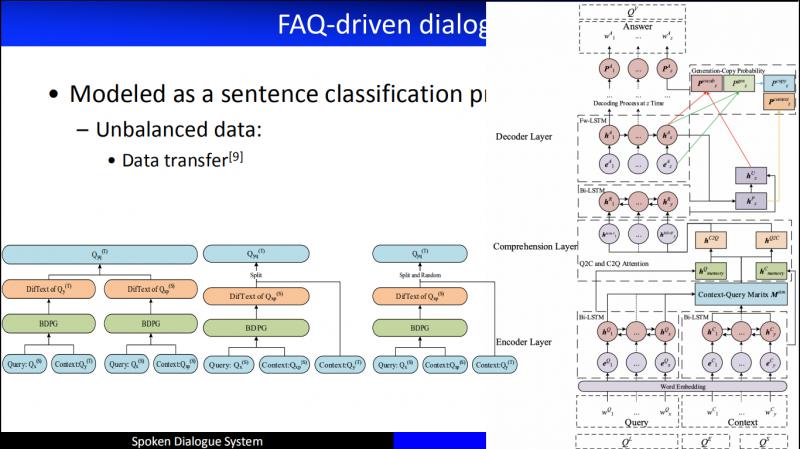
我们在做这个工作的时候发现一个特别大的问题,就是 Unbalanced Data 问题。比如,我们有5000个问题,每个问题都有标准答案,有些问题可能对应的用户问题特别多,比如 "屏幕碎了" 可能会有1000多种不同的问法,还有些问题,可能在几年的时间里都没有人问到过。所以,面对数据不均衡的问题,我们从2016年开始做了 Data transfer 的工作。
大致的思路是:我有一个标准问题,但是很糟糕,这个标准问题没有用户问题,也就是没有训练语料。接下来发现另外一个和这个标准问很相似的其它标准问有很多的训练语料,于是借助这个标准问,来生成虚拟样本,进而削弱了 Unbalance。
具体的方法:我们把目标领域的标准问看成 Query,把和它相似的标准问题及其对应的用户问题看成 Context,采用了 MRC 机器阅读理解的架构来生成一个答案,作为目标问题的虚拟的用户问题,取得了非常好的效果,并且尝试了三种不同的生成用户问题的方法。
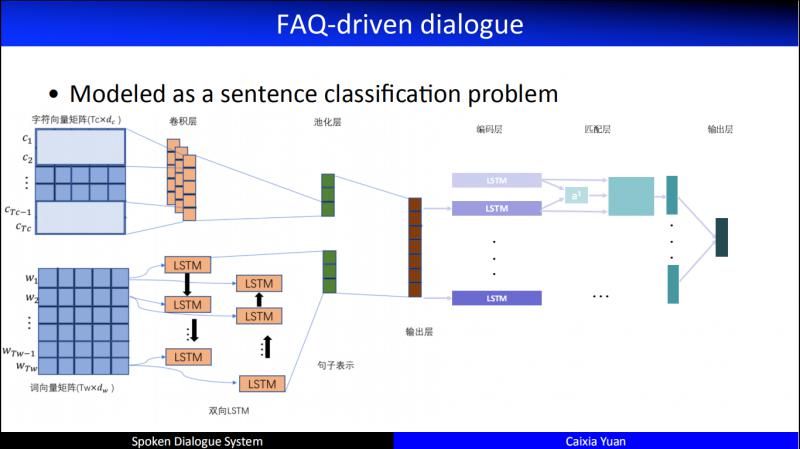
实际项目中,FAQ 中的 Q 可能有非常多的问题,例如3000多个类,需要做极限分类,这就导致性能低下,且非常耗时,不能快速响应用户的问题。于是我们做了一个匹配和分类进行交互的 model,取得了不错的效果。

目前,大部分人都认为 FAQ 驱动的 dialogue 不叫 dialogue,因为我们通常说的 dialogue 轮次是大于两轮的。而 FAQ 就是一个 QA 系统,没有交互性。有时候带来的用户体验非常不友好,比如当答案非常长的时候,系统要把长长的答案返回,就会一直讲,导致用户比较差的体验。于是,我们基于 FAQ 发展出了一个多轮对话的数据,如右图,这是我们正在开展的一个工作。
- KB-driven dialogue
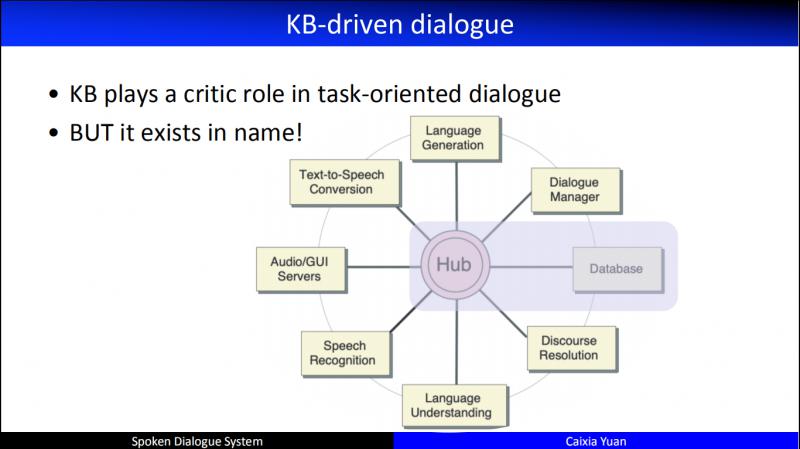
KB 最早人们认为它就是一个结构化的数据库,通常存储在关系型数据库中。比如要订一个酒店,这个酒店有各种属性,如位置、名称、户型、价格、面积等等。早期 CMU 的对话系统,所有的模块都要和 Hub 进行交互,最后 Hub 和后端的数据库进行交互。数据库的价值非常大,但是早期人们在建模人机对话的时候,都忽视了数据库。这里就会存在一个问题:机器和用户交互了很久,而在检索数据库时发现没有答案,或者答案非常多,造成用户体验非常糟糕。
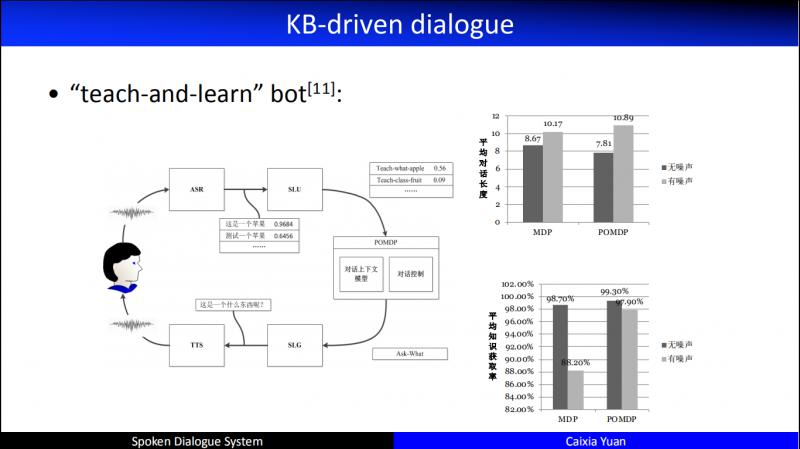
从2012年开始,我们开始把 KB 引入我们的对话系统。图中的对话系统叫做 "teach-and-learn" bot,这是一个多模态的对话,但是每个涉及到的 object,我们都会把它放到 DB 中。和用户交互过程中,不光看用户的对话状态,还要看数据库状态。这个想法把工作往前推进了一些。
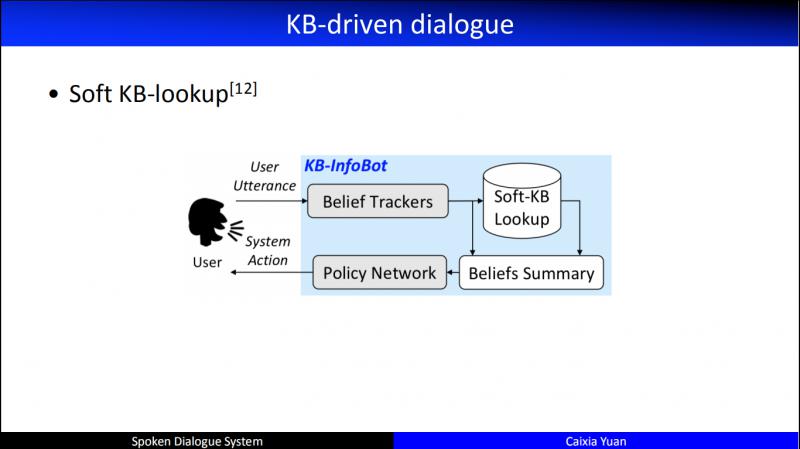
直到2016年,MSR 提出的 KB-InfoBot,第一次提出了进行数据库操作时,要考虑它的可导性,否则,就没办法在 RL 网络中像其它的 Agent action 一样进行求导。具体的思路:把数据库的查询和 Belief State 一起总结起来做同一个 belief,进而在这样的 belief 基础上做各种对话策略的优化。
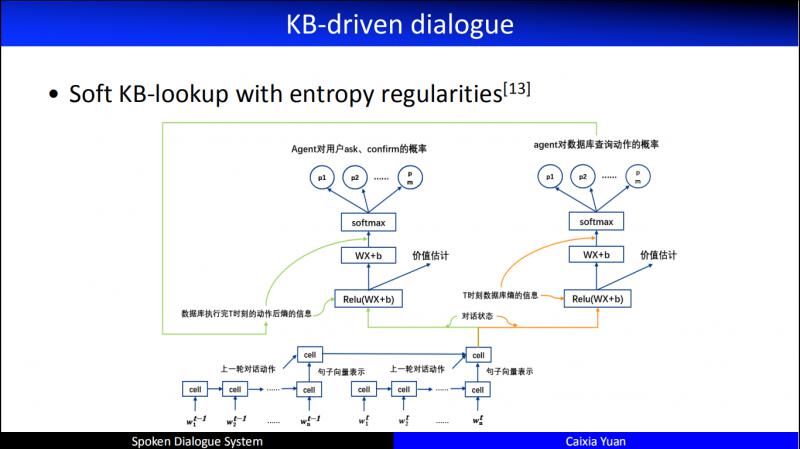
在上述方法的基础上,我们做了有效的改良,包括 entropy regularities 工作。是每次和用户进行交互时,数据库的 entropy 会发生变化。比如当机器问 "你想订哪里的酒店?",用户答 "阿里中心附近的。",于是数据库立刻进行了一次 entropy 计算进行更新,接着继续问 "你想订哪一天的?",用户答 "订7月28号的",于是又进行了一次 entropy 计算进行更新。这样在和用户进行交互的时候,不光看用户的 dialogue 输入,还看 DB 的 entropy 输入,以这两项共同驱动 Agent action 进行优化。
这里我们做了特别多的工作,信息槽从1个到5个,数据库的规模从大到小,都做了特别多的尝试,这样在和用户交互的时候,agent 可以自主的查询检索,甚至可以填充和修改数据库。
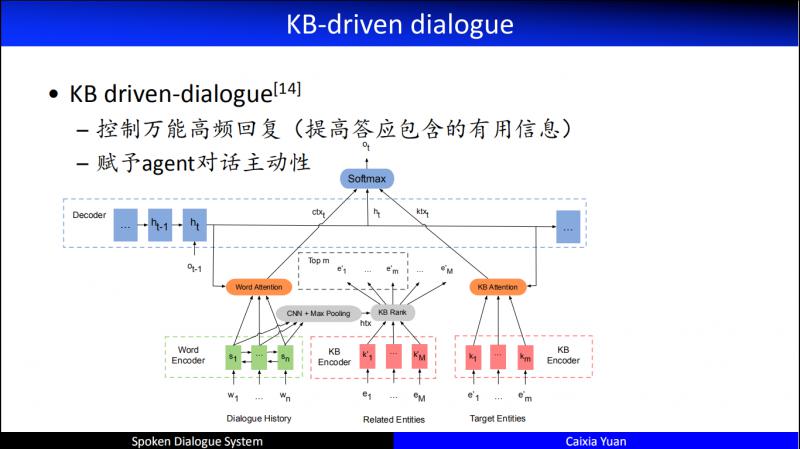
这是我们2017发布的一个工作,KB driven-dialogue,其优点:
控制万能高频回复 ( 提高答应包含的有用信息 )
赋予 agent 对话主动性
- KG-driven dialogue
刚刚讲的基于 KB 的 dialogue 任务,基本都认为对话任务就是在进行槽填充的任务,如果一个 agent 是主动性的,通过不停的和用户进行交互来采集槽信息,所以叫槽填充,当槽填完了,就相当于对话任务成功了。但是,当我们在定义槽的时候,我们认为槽是互相独立的,并且是扁平的。然而,实际中许多任务的槽之间存在相关性,有的是上下位关系,有的是约束关系,有的是递进关系等等。这样自然的就引出了知识图谱,知识图谱可以较好地描述上述的相关性。于是,产生了两个新问题:
知识图谱驱动的对话理解:实体链接
知识图谱驱动的对话管理:图路径规划
这里主要讲下第二个问题。
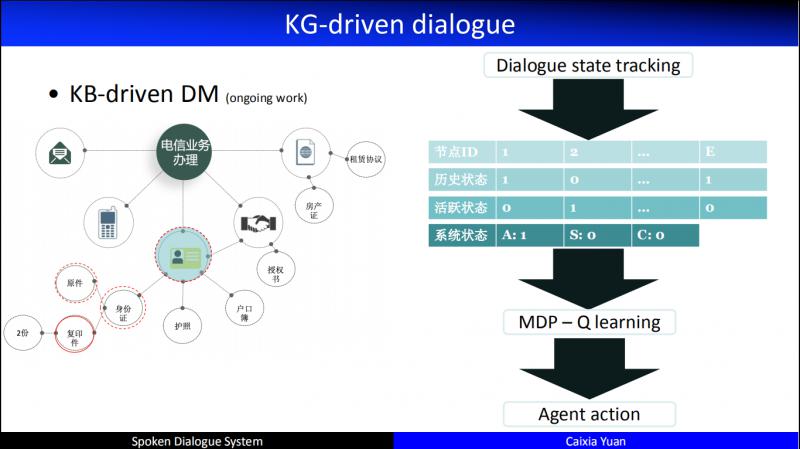
举个例子,我们在办理电信业务,开通一个家庭宽带,需要提供相关的证件,是自己去办,还是委托人去办,是房东还是租户等等,需要提供各种不同的材料。于是这个情景就产生了条件的约束,某一个 node 和其它 node 是上下位的关系,比如证件可以是身份证,也可以是护照或者户口簿等等。所以我们可以通过知识图谱来进行处理。
当一个用户的对话过来,首先会链接到不同的 node,再基于 node 和对话历史构造一个对话的 state,我们会维持一个全局的 state 和一个活跃的 state,同时活跃的 state 会定义三种不同的操作动作,一个是祖先节点,一个是兄弟节点,还有一个是孩子节点。所以,在这样的知识图谱上如何寻优,比如当通过某种计算得到,它应该在某个节点上进行交互的时候,我们就应该输出一个 action,这个 action 要和用户确认他是一个租户,还是自有住房等等。所以,这个 action 是有区别于此前所提到的在特定的、扁平的 slot 槽上和用户进行信息的确认、修改等还是有很大不同的。解决这样的问题,一个非常巨大的挑战就是状态空间非常大。比如图中的节点大概有120个,每个节点有3个不同的状态,知识从节点的状态来看就有3的120次幂种可能。这也是我们正在开展的待解决的一个问题。
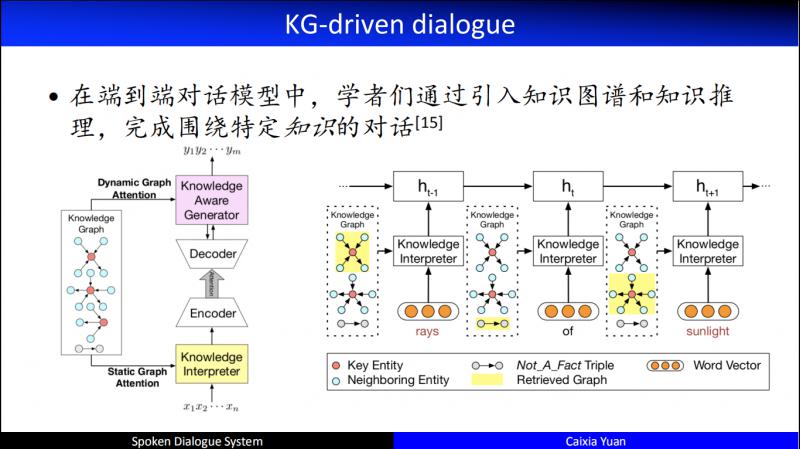
在端到端的对话模型 ( 闲聊 ) 中,也开始逐步地引入知识图谱。下面介绍两个比较具有代表性的引入知识图谱后的人机对话。其中右边是2018年 IJCAI 的杰出论文,清华大学黄民烈老师团队的工作,引入了通过 KG 来表示的 Commonsense,同时到底在编码器端还是在解码器端引入知识,以及如何排序,排序的时候如何结合对话的 history 做知识的推理等等,都做了特别全面的研究。
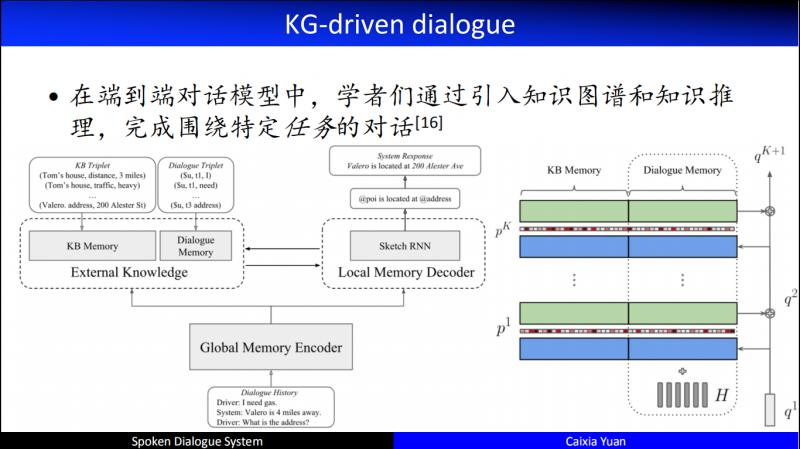
另一个比较有代表性的工作是在 ICLR2019 提出的,在架构中引入了 Local Memory 和 Global Memory 相融合的技术,通过这种融合,在编码器端和解码器端同时加入了知识的推理。

总结下 KB/KG-driven dialogue:
优点:
已经有大规模公开的数据 ( e.g.,InCar Assistant,MMD,M2M )。
训练过程可控&稳定,因为这里多数都是有监督学习。
缺点:
因为采用有监督的方式进行训练,所以存在如下问题:
① 环境确定性假设
② 缺少对动作的建模
③ 缺少全局的动作规划
Agent 被动,完全依赖于训练数据,所以模型是不赋予 Agent 主动性的。
构建 KB 和 KG 成本昂贵!
- Document-driven dialogue

Document 驱动的对话,具有如下优点:
① 应用场景真实丰富:
情景对话 ( conversation ),比如针对某个热门事件在微博会产生很多对话,这就是一个情景式的对话。
电信业务办理 ( service ),比如10086有非常多的套餐,如何从中选择一个用户心仪的套餐?每个套餐都有说明书,我们可以围绕套餐的说明书和用户进行交互,如 "您希望流量多、还是语音多",如果用户回答 "流量多",就可以基于文本知道给用户推荐流量多的套餐,如果有三个候选,机器就可以基于这三个候选和用户继续进行交互,缩小候选套餐范围,直到用户选出心仪的套餐。
电商产品推荐 ( recommendation ),可以根据商品的描述,进行各种各样的对话。这里的输入不是一个 dialogue,也不是一个 KB,甚至结构化的内容非常少,完全是一个 free document,如何基于这些 document 进行推荐,是一个很好的应用场景。
交互式信息查询 ( retrieval ),很多时候,一次查询的结果可能不能用户的需求,如何基于非结构化的查询结果和用户进行交互,来更好地达成用户的查询目的。
......
② 数据获取直接便捷:
相比于 dialogue、FAQ、KB、KQ 等,Document 充斥着互联网的各种各样的文本,都可以看成是文本的数据,获取方便,成本非常低。
③ 领域移植性强:
基于文本,不再基于专家定义的 slot,也不再基于受限的 KB/KG,从技术上讲,所构造的 model 本身是和领域无关的,所以它赋予了 model 很强的领域移植性。

这是我们正在进行的工作,情景对话偏向于闲聊,没有一个用户目标。这里需要解决的问题有两个:
如何引入文档:编码端引入文档、解码端引入文档
如何编码文档:文档过长、冗余信息过多
数据:
我们在 DoG 数据的基础上模拟了一些数据,形成了如上图所示的数据集,分 Blind 和 Non-blind 两种情形构造了不同的数据集。

我们发现,基于文本的端到端的聊天,有些是基于内容的闲聊,有些还需要回答特定的问题。所以,评价的时候,可以直接用 F1 评价回答特定问题,用闲聊通用的评价来评价基于内容的聊天。

刚刚讲的是偏闲聊式的对话,接下来讲下任务型对话。
这里的动机分为两种情况:单文档和多文档,我们目前在挑战多文档的情况,单文档则采用简单的多轮阅读理解来做。
多文档要解决的问题:
如何定义对话动作:因为是基于Document进行交互,而不再是基于slot进行交互,所以需要重新定义对话动作。
如何建模文档差异:以刚刚10086的例子为例,总共有10个业务,通过一轮对话,挑选出3个,这3个业务每个业务可能都有10种属性,那么其中一些属性值相同的属性,没必要再和用户进行交互,只需要交互它们之间不同的点,所以交互的角度需要随对话进行动态地变化。
数据:
这里采用的数据是 WikiMovies 和模拟数据,具体见上图。
- A very simple sketch of dialogue

上图为任务型对话和非任务型对话的几个重要节点,大家可以了解下。
03
Concluding remarks
任务型对话具有最丰富的落地场景。
纯闲聊型对话系统的学术价值尚不清楚。
任务型和非任务型边界愈加模糊,一个典型的人人对话既包括闲聊,又包括信息获取、推荐、服务。
引入外部知识十分必要,外部知识形态各异,建模方法也因而千差万别。
Uncertainty 和 few-shot 问题,是几乎所有的对话系统最大的 "卡脖子" 问题。
X-driven dialogue 中的 X 还有哪些可能?刚刚提到的 X 都还是基于文本的。事实上,从2005年开始,我们已经开始做 image 和文本数据融合的对话;从2013年开始做 Visual QA/Dialogue,挑战了 GuessWhat 和 GuessWhich 任务。
X=multi media ( MM Dialogue ),X 还可以很宽泛的就是指多媒体,不光有 image 还可能有 text,2018年已经有了相关的任务,并且开源了非常多的电商业务。这是一个非常有挑战性的工作,也使人机对话本身更加拟人化。
04
Reference
这是部分的参考文献,有些是我们自己的工作,有些是特别杰出的别人的工作。



今天的分享就到这里,感谢大家的聆听,也感谢我们的团队。

欢迎关注DataFunTalk同名公众号,收看第一手原创技术文章。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号