
[大牛翻译系列]Hadoop(17)MapReduce 文件处理:小文件
5.1 小文件
大数据这个概念似乎意味着处理GB级乃至更大的文件。实际上大数据可以是大量的小文件。比如说,日志文件通常增长到MB级时就会存档。这一节中将介绍在HDFS中有效地处理小文件的技术。
技术24 使用Avro存储多个小文件
假定有一个项目akin在google上搜索图片,并将数以百万计的图片存储分别在HDFS中。很不幸的是,这样做恰好碰上了HDFS和MapReduce的弱项,如下:
- Hadoop的NameNode将所有的HDFS元数据保存在内存中以加快速度。Yahoo估计平均每个文件需要600字节内存。那么10亿个文件就需要60GB内存。对于当下的中端服务器来说,60GB内存就显得太多了。
- 如果MapReduce的数据源是大量的文本文件或可分割文件,那么map任务个数就是这些文件占据的快的数量。如果MapReduce的数据源是成千上百万的文件,那么作业将会消耗大量的时间在内核中创建和销毁map任务进程上。这些时间将会比实际处理数据的时间还要长。
- 如果在一个有调度器的受控环境中运行MapReduce作业,那么map任务的个数可能是受到限制的。由于默认每个文件都需要至少一个map任务,这样就有可能因为任务过多而被调度器拒绝运行。
思考如下问题:文件的大小和HDFS块大小相比,大概是什么比例?50%,70%,还是90%。如果大数据项目启动后,又突然需要成倍地扩展需要处理的文件。如果扩展仅仅需要增加节点,而不需要重新设计Hadoop过程,迁移文件等,是不是很美妙的事情。思考这些问题并在设计阶段及早准备是很有必要的。
问题
需要处理HDFS中的大量文件,同时又不能超出NameNode的内存限制。
方案
最简单的方案就是将HDFS中的小文件打包到一个大的文件容器中。这个技术中将本地磁盘中所有的目标文件存储到HDFS中的一个单独的Avro文件。然后在MapReduce中处理Avro文件和其中的小文件。
讨论
图5.1中介绍了这个技术的第一部分,如何在HDFS中创建Avro文件。这样做可以减少HDFS中需要创建的文件数量,随之减少了NameNode的内存消耗。
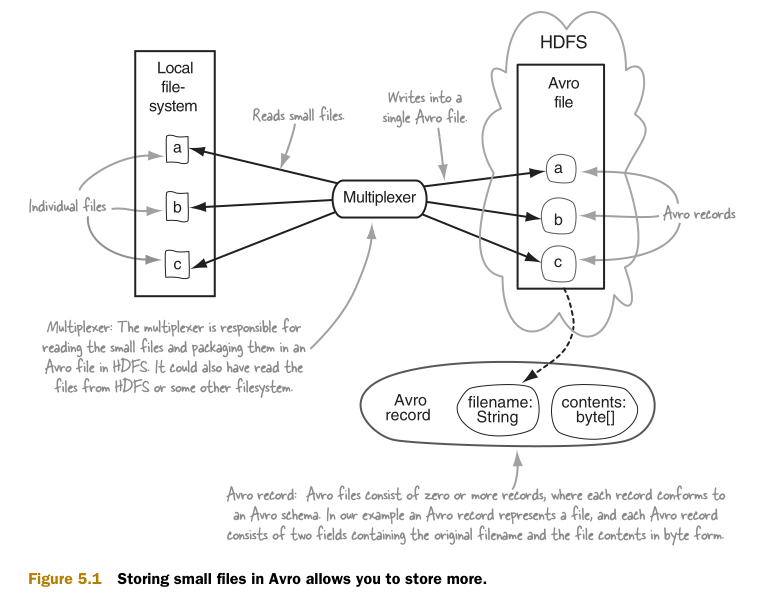
Avro是由Hadoop之父Doug Cutting发明的数据序列化和PRC库。主要用于提高Hadoop数据交换,通用性和版本控制的能力。Avro有着很强的架构模式演化能力,相比它的竞争对手如SequenceFiles等有更明显的竞争优势。第3章中详细介绍了Avro和它的竞争对手们。
让我们来看看以下的JAVA代码如何创建Avro文件:
从目录中读取多个小文件并在HDFS中生成一个单一的Avro文件
1 public class SmallFilesWrite { 2 3 public static final String FIELD_FILENAME = "filename"; 4 public static final String FIELD_CONTENTS = "contents"; 5 6 private static final String SCHEMA_JSON = 7 "{\"type\": \"record\", \"name\": \"SmallFilesTest\", " 8 + "\"fields\": [" 9 + "{\"name\":\" + FIELD_FILENAME 10 + "\", \"type\":\"string\"}," 11 + "{\"name\":\" + FIELD_CONTENTS 12 + "\", \"type\":\"bytes\"}]}"; 13 14 public static final Schema SCHEMA = Schema.parse(SCHEMA_JSON); 15 16 public static void writeToAvro(File srcPath, OutputStream outputStream)throws IOException { 17 18 DataFileWriter<Object> writer = 19 new DataFileWriter<Object>(new GenericDatumWriter<Object>()).setSyncInterval(100); 20 21 writer.setCodec(CodecFactory.snappyCodec()); 22 writer.create(SCHEMA, outputStream); 23 24 for (Object obj : FileUtils.listFiles(srcPath, null, false)) { 25 File file = (File) obj; 26 String filename = file.getAbsolutePath(); 27 byte content[] = FileUtils.readFileToByteArray(file); 28 GenericRecord record = new GenericData.Record(SCHEMA); 29 record.put(FIELD_FILENAME, filename); 30 record.put(FIELD_CONTENTS, ByteBuffer.wrap(content)); 31 writer.append(record); 32 System.out.println(file.getAbsolutePath() + ": " + DigestUtils.md5Hex(content)); 33 } 34 35 IOUtils.cleanup(null, writer); 36 IOUtils.cleanup(null, outputStream); 37 } 38 39 public static void main(String... args) throws Exception { 40 Configuration config = new Configuration(); 41 FileSystem hdfs = FileSystem.get(config); 42 File sourceDir = new File(args[0]); 43 Path destFile = new Path(args[1]); 44 OutputStream os = hdfs.create(destFile); 45 writeToAvro(sourceDir, os); 46 } 47 }
|
压缩依赖 为了运行这一章中的代码,需要在相应主机上安装Snappy和LZOP压缩编码器。请参考附录A来安装和配置。 |
然后观察这段代码以Hadoop的配置目录作为数据源的运行结果。
$ bin/run.sh \ com.manning.hip.ch5.SmallFilesWrite /etc/hadoop/conf test.avro /etc/hadoop/conf/ssl-server.xml.example: cb6f1b218... /etc/hadoop/conf/log4j.properties: 6920ca49b9790cb... /etc/hadoop/conf/fair-scheduler.xml: b3e5f2bbb1d6c... ...
看起来很可靠。然后来确认HDFS中的输出文件:
$ hadoop fs -ls test.avro 2011-08-20 12:38 /user/aholmes/test.avro
为了确保所有都和预期一样,编写代码读取HDFS中的Avro文件,并输出每个文件内容的MD5哈希值。代码如下:
1 public class SmallFilesRead { 2 3 private static final String FIELD_FILENAME = "filename"; 4 private static final String FIELD_CONTENTS = "contents"; 5 6 public static void readFromAvro(InputStream is) throws IOException { 7 8 DataFileStream<Object> reader = new DataFileStream<Object>(is, new GenericDatumReader<Object>()); 9 10 for (Object o : reader) { 11 GenericRecord r = (GenericRecord) o; 12 System.out.println( 13 r.get(FIELD_FILENAME) + ": " + 14 DigestUtils.md5Hex(((ByteBuffer) r.get(FIELD_CONTENTS)).array())); 15 } 16 17 IOUtils.cleanup(null, is); 18 IOUtils.cleanup(null, reader); 19 } 20 21 public static void main(String... args) throws Exception { 22 Configuration config = new Configuration(); 23 FileSystem hdfs = FileSystem.get(config); 24 Path destFile = new Path(args[0]); 25 InputStream is = hdfs.open(destFile); 26 readFromAvro(is); 27 } 28 }
这段代码比前一段代码要简单。因为Avro将结构模式(schema)写入了每一个Avro文件。在逆序列化的时候,不需要告诉Avro结构模式的信息。现在来测试代码:
$ bin/run.sh com.manning.hip.ch5.SmallFilesRead test.avro /etc/hadoop/conf/ssl-server.xml.example: cb6f1b21... /etc/hadoop/conf/log4j.properties: 6920ca49b9790c... /etc/hadoop/conf/fair-scheduler.xml: b3e5f2bbb1d6...
现在Avro文件就被存储在了HDFS中。下一步是用MapReduce处理文件。如图5.2所示,用一个只有Map的MapReduce作业读取Avro记录作为输入,然后输出一个包含有文件名和文件内容的MD5哈希值的文本文件。
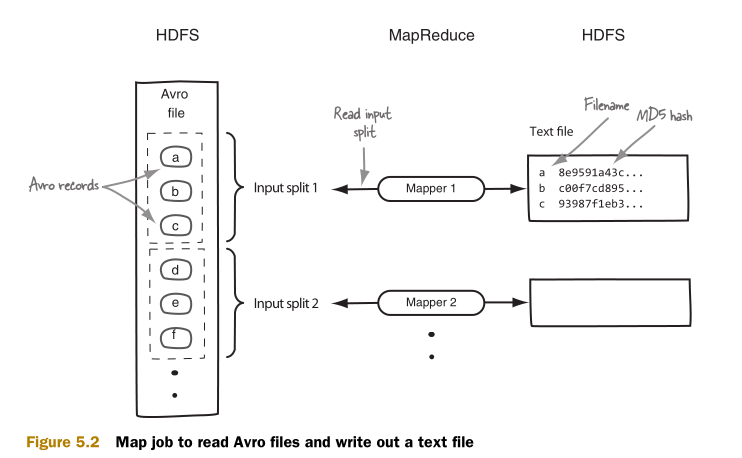
以下是MapReduce作业的实现代码:
一个以包含了多个小文件的Avro文件作为输入源的MapReduce作业
1 public class SmallFilesMapReduce { 2 3 public static void main(String... args) throws Exception { 4 JobConf job = new JobConf(); 5 job.setJarByClass(SmallFilesMapReduce.class); 6 Path input = new Path(args[0]); 7 Path output = new Path(args[1]); 8 output.getFileSystem(job).delete(output, true); 9 AvroJob.setInputSchema(job, SmallFilesWrite.SCHEMA); 10 job.setInputFormat(AvroInputFormat.class); 11 job.setOutputFormat(TextOutputFormat.class); 12 job.setMapperClass(Map.class); 13 FileInputFormat.setInputPaths(job, input); 14 FileOutputFormat.setOutputPath(job, output); 15 job.setNumReduceTasks(0); 16 JobClient.runJob(job); 17 } 18 19 public static class Mapper 20 implements Mapper<AvroWrapper<GenericRecord>, NullWritable, Text, Text> { 21 22 @Override 23 public void map(AvroWrapper<GenericRecord> key, 24 NullWritable value, 25 OutputCollector<Text, Text> output, 26 Reporter reporter) throws IOException { 27 28 outKey.set(key.datum().get(SmallFilesWrite.FIELD_FILENAME).toString()); 29 30 outValue.set(DigestUtils.md5Hex( 31 ((ByteBuffer) key.datum().get(SmallFilesWrite.FIELD_CONTENTS)) 32 .array())); 33 34 output.collect(outKey, outValue); 35 } 36 } 37 }
如果将前面代码创建的Avro文件作为输入源,那么这个作业的日志文件将包含最初的文件名和它们的哈希值。执行过程如下:
$ bin/run.sh com.manning.hip.ch5.SmallFilesMapReduce test.avro output $ hadoop fs -cat output/part* /etc/hadoop/conf/capacity-scheduler.xml: 0601a2.. /etc/hadoop/conf/taskcontroller.cfg: 5c2c191420... /etc/hadoop/conf/configuration.xsl: e4e5e17b4a8... ...
这个技术假设需要处理的文件时无法连接合并的,如图像文件。如果文件可以连接,那么就可以考虑其它的方案。使用Avro应尽可能保证文件的大小和HDFS快的大小相当,以减少NameNode中需要存储的数据。
小结
也可以用Hadoop的SequenceFile来处理小文件。SequenceFile是一个更成熟的技术,比Avro出现时间更长。但是SequenceFiles是JAVA专用的,相比Avro相比丰富的交互性和版本控制语义。
Google的Protocol Buffers和源自Facebook的Apache Thrift都可以用来处理小文件。但是缺乏相应的InputFormat来配合它们。
另外一个方法是将文件打包成zip文件。但其中的问题是,必须自定义InputFormat来处理zip文件。同时zip文件无法分块。不过分块问题可以通过打包成多个大小和HDFS块相近的zip文件。
Hadoop还提供了CombineFileInputFormat。它能够让一个单独的map任务处理来自多个文件的多个输入块,以极大地减少需要运行的map任务个数。
在类似的方法中,也可以在Hadoop中配置,使map任务的JVM可以处理多个任务,来减少JVM循环的开支。配置项mapred.job.reuse.jvm.num.tasks默认为1.这说明一个JVM只能处理一个任务。当它被配置为更大的数字的时候,一个JVM可以处理多个任务。-1则代表着处理的任务数量无上限。
此外,也可以创建一个tarball文件来装载所有的文件,然后生成一个文本文件描述HDFS中的tarball文件的位置信息。文本文件将会被作为MapReduce作业的输入源。Map任务将会直接打开tarball。但是这种方法将会损害MapReduce的本地性。也就是说,map任务需要在包含那个文本文件的节点上运行,然而包含tarball文件的HDFS很可能在另外一个节点上,这就增加了网络IO的成本。
Hadoop打包文件(HAR)是Hadoop专用于解决小文件问题的文件。它是基于HDFS的虚拟文件系统。HAR的缺陷在于无法优化MapReduce的本地磁盘访问性能,而且无法被压缩。
Hadoop 2.x版本支持HDFS联合机制。在HDFS联合机制中,HDFS被分区成多个不同的名字空间,由不同的NameNode分别管理。然后,NameNode的快信息缓存的内存压力可以由多个NameNode共同承担。最终支持了更大数量的小文件。Hortonworks有一片关于HDFS联合机制的博客:http://hortonworks.com/an-introduction-to-hdfs-federation/。
最后一个方法是MapR。MapR拥有自己的分布式文件系统,支持大量的小文件。但是,应用MapR作为分布式存储系统将会带来很大的系统变更。也就是说,几乎不可能通过应用MapR来解决HDFS中的小文件问题。
在Hadoop中有可能多次碰到小文件的问题。直接使用小文件将会使NameNode的内存消耗迅速增大,并拖累MapReduce的运行时间。这个技术可以帮助缓解这个问题,通过将小文件打包到更大的容器文件中。选择Avro的原因是,它支持可分块文件,压缩。Avro的结构模式语言有利于版本控制。
假定需要处理的不是小文件,而是超大文件。那么应当如何有效地存储数据?如何在Hadoop中压缩数据?MapReduce中应当如何处理?这将是下一节的内容。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号