
[大牛翻译系列]Hadoop(15)MapReduce 性能调优:优化MapReduce的用户JAVA代码
6.4.5 优化MapReduce用户JAVA代码
MapReduce执行代码的方式和普通JAVA应用不同。这是由于MapReduce框架为了能够高效地处理海量数据,需要成百万次调用map和reduce函数。每次调用仅用较少时间。那么就不能用普通的经验来预测常见库(含JDK)的性能表现。
|
进一步阅读 Joshua Bloch的《Effective Java》中有很多如何调优JAVA代码的方法 |
在技术45中介绍如何用分析器(profiler)查找MapReduce代码中消耗时间的地方。这里要用同样的技术来确定一下代码中的潜在问题。
1 public void map(LongWritable key, Text value, 2 OutputCollector<LongWritable, Text> output, 3 Reporter reporter) throws IOException { 4 5 String[] parts = value.toString().split("\\."); 6 Text outputValue = new Text(parts[0]); 7 output.collect(key, outputValue); 8 }
在这部分中将介绍前面章节介绍过的两个影响代码性能的问题(正则表达式和缺乏代码重用),以及一些常见的方法。
正则表达式
正则表达式有非常丰富灵活的特性。然而灵活性意味着性能下降。有的时候,性能会降低到不可接受的地步。那么,作为一般准则,就应该在MapReduce中避免使用正则表达式。如果非用不可,也应该尽量寻找替代方法。
字符串令牌化(TOKENIZATION)
JAVA的文档推荐使用String.split和Scanner类来实现字符串令牌化。实际上,它们都是基于正则表达式,在MapReduce中会很慢。然后,就要考虑用JAVA文档不推荐的StringTokenizer。但是,StringTokenizer的算法性能也不是最优。Apache commons中的StringUtils类效率要更好。如图6.42所示。
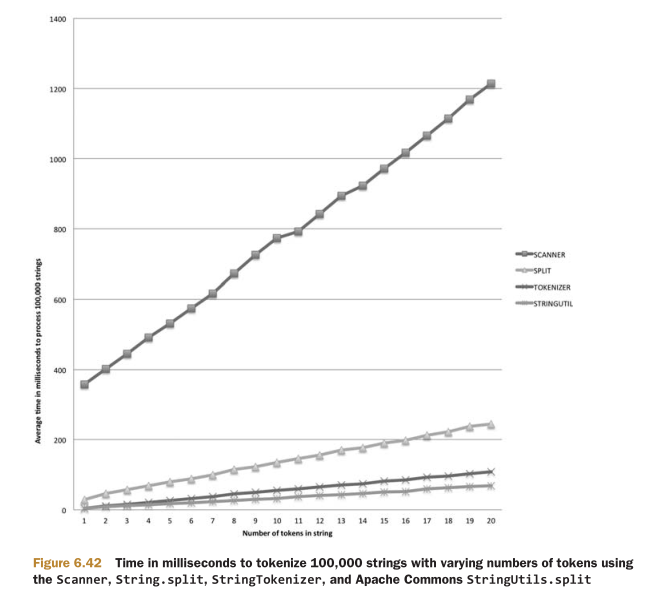
这个性能测试是在如下环境中完成:JDK 1.6.0_29,OS X,四核2.7GHz CPU。
对象重用
第二个消耗CPU时间的是类似如下的代码:
Text outputValue = new Text(parts[0]);
由于这段代码在每个键值对都要执行一次,就要执行成千上万次。代码就会在对象分配上浪费大量的时间。对象分配在JAVA中是非常昂贵的,包含创建时调用CPU,销毁时调用垃圾收集器。如果能够重用,将节约大量的时间。以下代码介绍如何达到最大重用率:
1 Text outputValue = new Text(); 2 3 public void map(LongWritable key, Text value, 4 OutputCollector<LongWritable, Text> output, 5 Reporter reporter) throws IOException { 6 String[] parts = StringUtils.split(value.toString(), ".")); 7 outputValue.set(parts[0]); 8 output.collect(key, outputValue); 9 }
在Hadoop中,当reduce将数据填充到值迭代器的时候,应用了对象重用。这个特性对缓存机制有潜在影响。在reduce中缓存值对象的数据的时候,需要克隆这个对象。实现代码如下:
1 public static class Reduce extends Reducer<Text, Text, Text, Text> { 2 3 @Override 4 public void reduce(Text key, Iterable<Text> values, Context context) 5 throws IOException, InterruptedException { 6 7 List<Text> cached = new ArrayList<Text>(); 8 for (Text value : values) { 9 cached.add(WritableUtils.clone(value, context.getConfiguration())); 10 } 11 } 12 }
字符串连接
JAVA中有一个非常古老的规则,就是应当避免使用加号来进行字符串连接。代码如下:
1 String results = a + b;
用加号连接字符串需要调用StringBuffer类。StringBuffer类是同步类,会降低执行的效能。近来,加号连接字符串有的情况下会调用StringBuilder类,一个非同步类。但这并不代表加号可以放心使用。当字符串长度大于16的时候,就很难说。具体参考http://goo.gl/9NGe8。最安全的方法就是使用StringBuilder类,并预先分配足够的空间,以防空间不足导致的空间再分配。
对象的内存资源消耗
在map和reduce任务中,常常需要缓存数据,例如第4章中的map端连接技术。然而,在JAVA中缓存数据成本高昂。首先来了解一下字符类和数组的内存资源消耗情况。预估一下下面这段代码的资源消耗。
1 ArrayList<String> strings = new ArrayList<String>(); 2 strings.add("a"); 3 string.add("b");
以下是对字符串数组列表的内存资源消耗的计算:
- 每个JAVA对象占用8字节作为基础开支。数组列表对象最开始申请8个字节。
- 数组列表对象包括一个整形原始字段占用4个字节。
- 数组列表使用对象数组存储数据。每个引用字段占用4字节。
- 每个对象占用内存字节数必须是8的倍数。以上内存占用总计为16字节。不需要凑整。
在没有存储任何数据的时候,数组列表已经占用了24字节。
接下来看数组列表中的对象数组的内存占用。
- 一个数组需要12字节作为基础开支。在8个字节外,它还需要4字节来存储数组的大小。
- 数组中的每个元素需要4字节来存储对象引用。两个元素一共8字节。
- 因为每个对象的内存字节数必须是8的倍数。上述字节数之和为20,凑整得到24。
那么现在数组列表占24字节,对象数组站24字节。最后需要理解字符串的内存占用,如下所示:
字符串内存占用字节数=(字符个数x2)+38
同样需要去整得到8的倍数。那么每个字符串占用40字节。最后存储了两个字符串的数组列表的内存占用是128字节。
这里进行这么详细计算的目的是建立对在JAVA中缓存数据的敏感性。在MapReduce中也一样,能够精确计算需要缓存数据的内存消耗是非常有益的。JAVA的内存使用详情可见:http://goo.gl/V8sZi。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号