
[大牛翻译系列]Hadoop(12)MapReduce 性能调优:诊断硬件性能瓶颈
6.2.5 硬件性能问题
尽管单独的硬件的MTTF(平均失效前时间)都数以年记,然而在集群中就完全不是这么一回事了。整个集群的MTTF就要小得多。这一节要介绍如何确定CPU,内存,磁盘和网络是否过度利用了,以及如何将它们的利用率调节到一个合理的水平。
技术39 查找硬件的失效
节点失效可能有如下原因:磁盘控制器失效,磁盘空间事故,其他硬件事故,以及Hadoop自身的缺陷(可能性较低)。节点失效将会导致MapReduce作业执行时间变长。在较小的集群上的影响要更为明显。接下来就要介绍如何确定集群中的节点是否失效。
问题
需要确定是否是由于硬件故障导致作业运行缓慢,并查看节点的黑名单和灰名单。
方案
使用JobTracker UI来检查黑名单或灰名单中的节点。
讨论
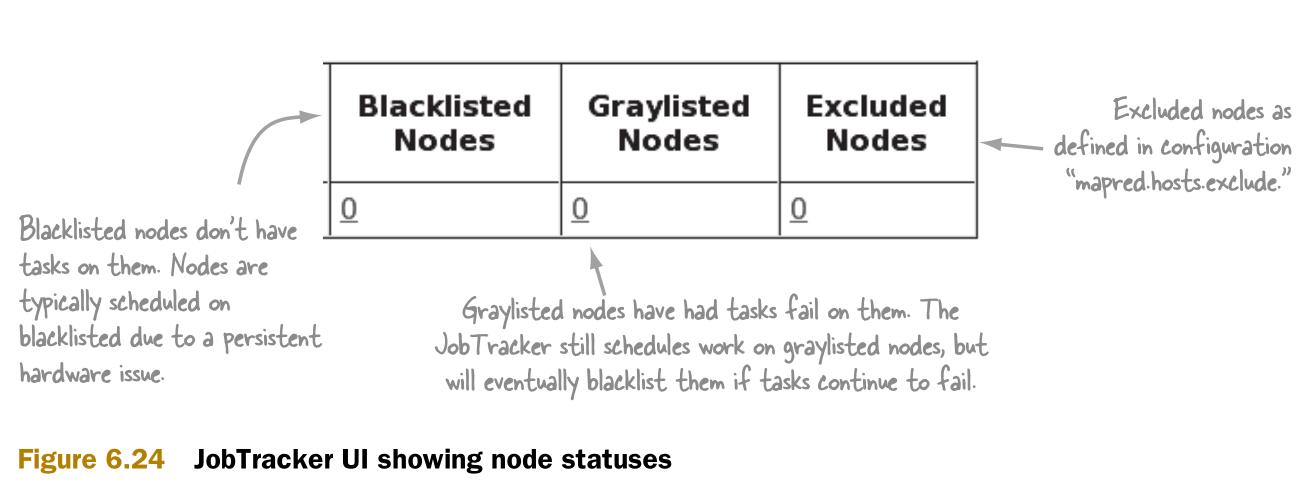
图6.24介绍了在哪里可以看到黑名单和灰名单。
小结
在集群中,特别是较小的集群是不希望看到有节点在黑名单或灰名单里的。灰名单中的节点会时不时地失效。这些节点会导致部分任务失败,拉长作业执行时间。黑名单中的节点根本不会有任何作用,这样使作业的性能远远小于预期。
如果需要了解节点进入黑名单或灰名单的原因,则需要查看任务,任务跟踪器(TaskTracker),或数据节点的日志。一旦出现了这种情况,则需要调查那些失效的节点。
比较好的一个方法是设置对黑名单和灰名单中节点的监控,这样就可以在它们失效时快速反应。通过Nagios监视器(http://goo.gl/R6deM)可以达到这个目的。它的原理是使用curl从JobTracker上通过http://127.0.0.1:50030/machines.jsp?type=blacklisted下载黑名单网页,并检查其中是否有节点。
技术40 CPU竞争
如果节点过度利用了CPU,那么会导致大量的时间被消耗在上下文切换,进而减少作业获得的计算能力。
问题
需要确定是否由于CPU过度利用导致了作业运行缓慢。
方案
使用Linux工具vmstat来观测CPU的上下文切换。
讨论
从vmstat中可以得到CPU利用率,IO等待,上下文切换等信息。通过这些信息可以快速评估主机的繁忙程度。图6.25说明了vmstat的执行方法和执行选项。(图的对齐有问题,这个暂时没有修正。请谅解。)
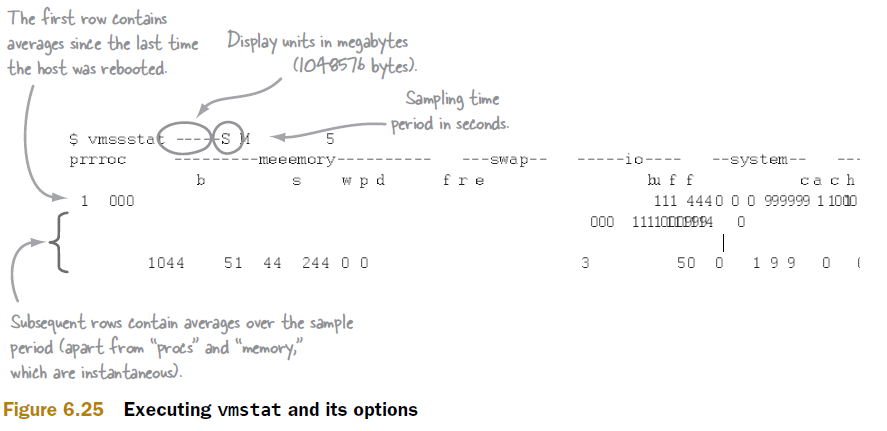
图6.26指出了需要观察的项目

小结
Linux的运行队列越长,Linux内核的进程间上下文切换的时间就越多。上写文切换是昂贵的。它需要CPU保存当前进程的状态,读入下一个进程的状态。也就是说,只要观察到了过度的上下文切换,很可能的原因就是主机上运行的任务太多了。有两个配置项mapred.tasktracker.map.tasks.maximum和mapred.tasktracker.reduce.tasks.maximum。它们的总和应当大约在主机的逻辑内核个数的120%左右。
有时候任务跟踪器会和CPU挂钩,并导致CPU利用率过高。这需要用top查看任务跟踪器是否是CPU绑定的,并考虑是否解绑。
还有如下工具可以参考:
- procinfo。查看是否有设备导致了过高的中断数量。
- sar。采集并将系统数据保存到文件。
- mpstat。给出基于单个CPU的统计数据,而不是所有CPU的。
技术41 内存交换
当内存使用量超过了物理内存上限,操作系统机会根据内存溢出机制使用磁盘作为。(我们一般叫这个虚拟内存。)这样就会产生内存交换。
磁盘的读写速度是远远小于内存的。内存交换也就会使节点的性能大为降低。
问题
需要是否由于内存交换导致作业运行缓慢。
方案
使用Linux工具vmstat来观察是否存在内存和磁盘间的交换。
讨论
图6.27介绍如何使用执行vmstat和它的执行选项。(图的对齐有问题,这个暂时没有修正。请谅解。)
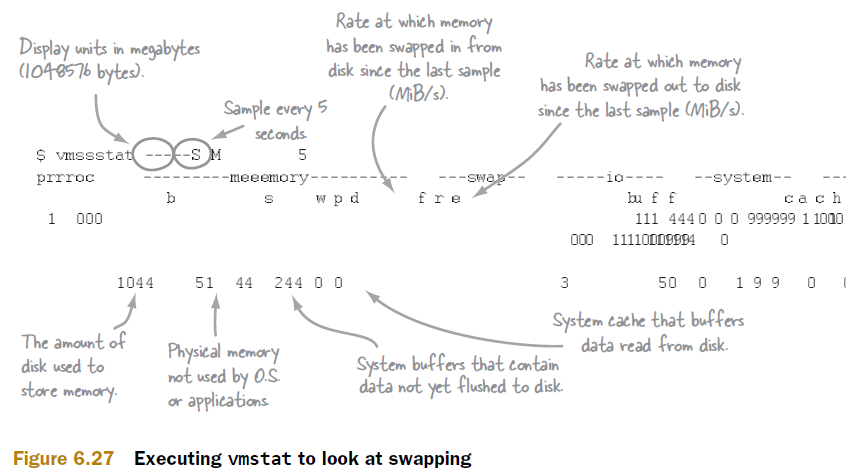
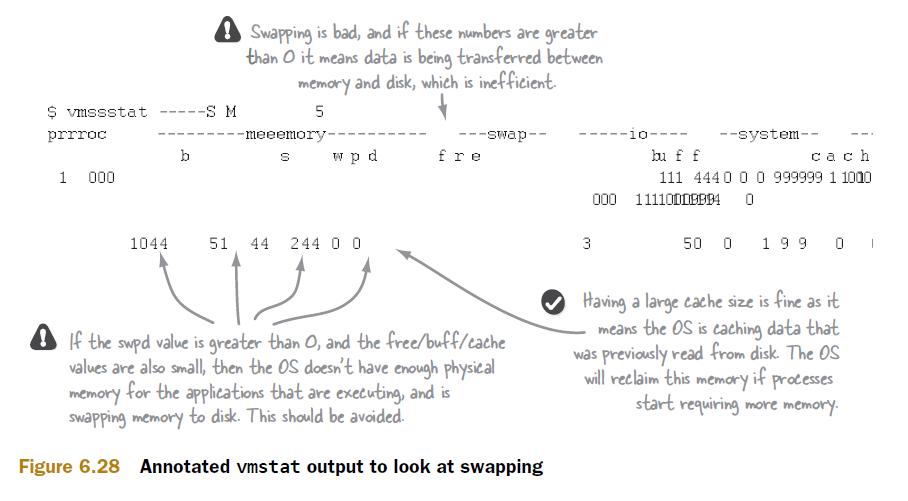
图6.28标注了需要观察的项目。(图的对齐有问题,这个暂时没有修正。请谅解。)
小结
如果存在内存交换,就需要考虑增加这个节点上的内存或减少这个节点上的map和reduce任务的并发数了(mapred.tasktracker.map.tasks.maximum and mapred.tasktracker.reduce.tasks.maximum)。
技术42 磁盘健康
即便是不过载的集群也对磁盘和磁盘控制器有很大的压力。这一节中将介绍如何评估磁盘的健康程度。此外,还将介绍如何诊断由磁盘只读装载所带来的IO错误。
问题
需要确定磁盘是否在降级运行或只读状态。
方案
使用Linux工具iostat得到磁盘的请求队列和IO等待时间。使用Linux工具dmesg得到磁盘的只读状态。
讨论
在Linux工具中,iostat是非常复杂的一个。图6.29介绍了如何执行iostat和它的执行选项。(图的对齐有问题,这个暂时没有修正。请谅解。)

图6.30标注了iostat的输出中需要注意的项目。(图的对齐有问题,这个暂时没有修正。请谅解。)
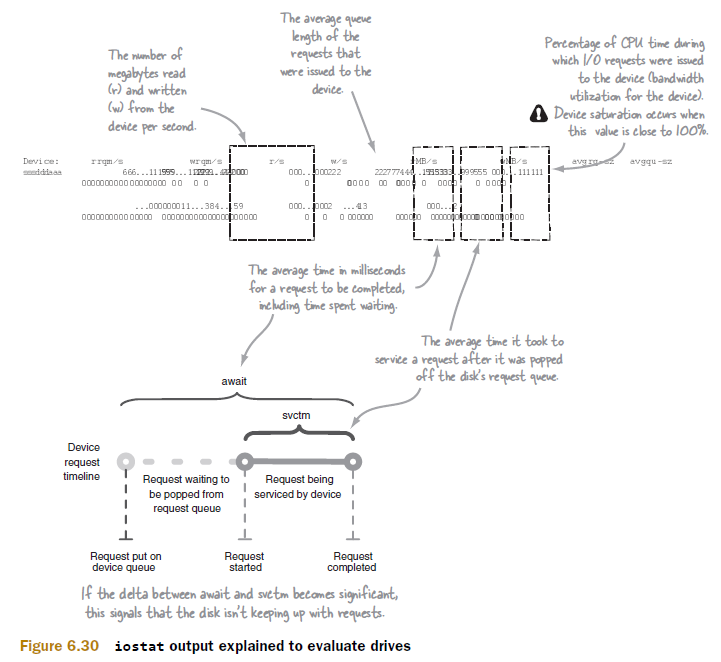
另外一个需要观察的重要事项是:文件系统是否处于只读状态。这会由Linux的磁盘或RAID控制器的缺陷引发,并可能使节点出问题。在这种情况下任务追踪器和数据节点日志中会记录:无法向磁盘写入数据。另外,可以用dmesg检查/var/log/messages中的消息。查看其中是否标识:文件系统被转换成只读状态。命令如下。
$ dmesg | grep read-only
小结
磁盘过载导致的读写缓慢以及文件系统只读带来的IO错误都会导致节点变残(cripple)。
You can use hdparm to measure the sequential read rate of your hard disk. Replace
/dev/md1 with the name of your disk device (consult /etc/fstab for device names):
可以使用hdparm来测量硬盘的序列读取速率。使用下面的命令,需要将/dev/md1换成真实的磁盘设备。
$ cat /etc/fstab
...
/dev/md1 /usr ext3 defaults 1 2
...
$ sudo /sbin/hdparm -t /dev/md1
/dev/md1:
Timing cached reads: 30656 MB in 1.99 seconds = 15405.72 MB/sec
Timing buffered disk reads: 108 MB in 3.03 seconds = 35.63 MB/sec
如果数据节点有IO等待问题,可以通过在各个节点上加装硬盘,并配置dfs.data.dir使用它们,来提高读写速率。
技术43 网络
由于MapReduce和HDFS对网络重度依赖,如数据传输等,如果网络问题,将会产生重大影响。这个技术将介绍如何正确配置节点,以及如何测试节点间的网络吞吐量。
问题
需要诊断是否是由于网络原因导致作业运行缓慢。
方案
使用Linux工具ethtool和sar的输出可以帮助诊断网络的配置问题。
讨论
首先检查以太网卡是否在正确的速度上以全双工运行。图6.31介绍了如何用ethtool获得相应信息。
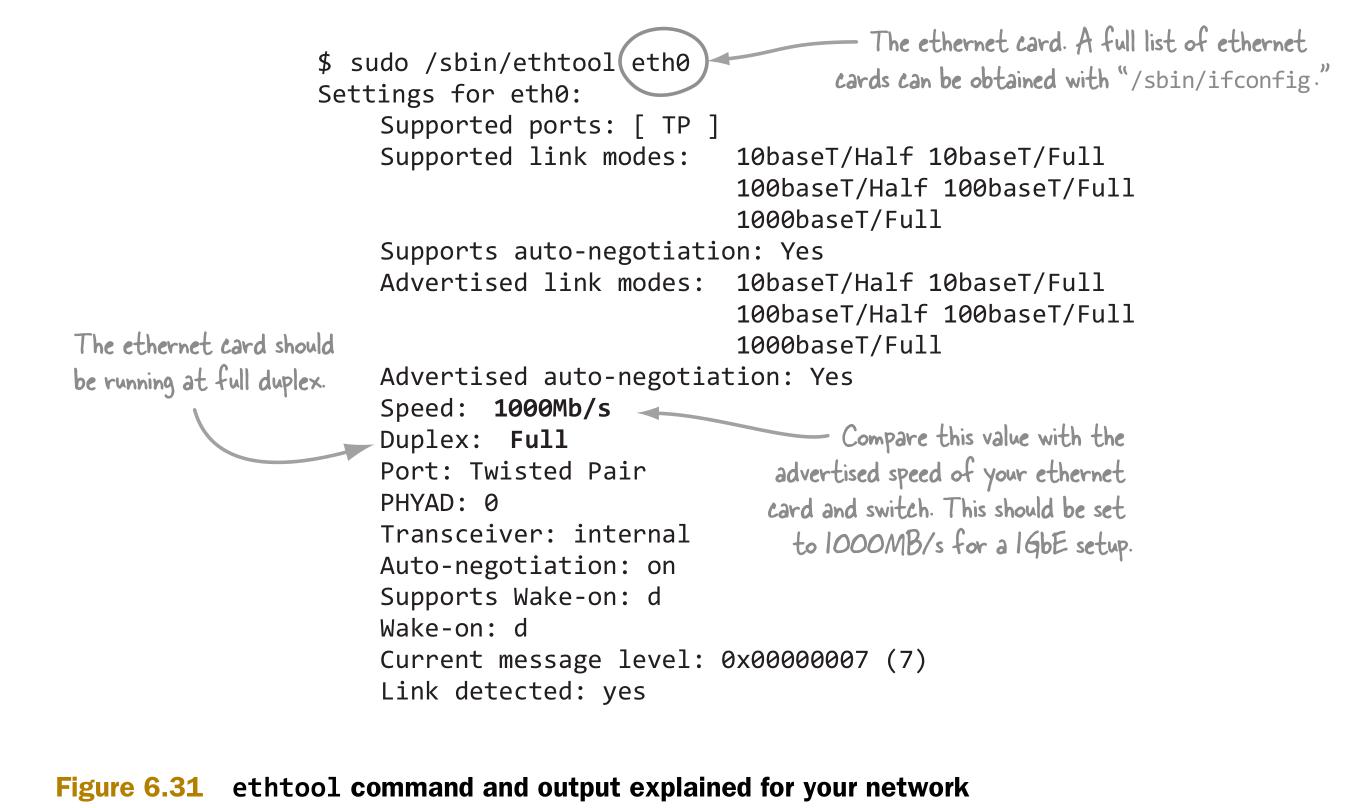
Linux工具etchtool命令可以提供各项目的小计,如已传输的字节数等。
通过sar工具可以比较网卡性能指标之间的不同,如图6.32。
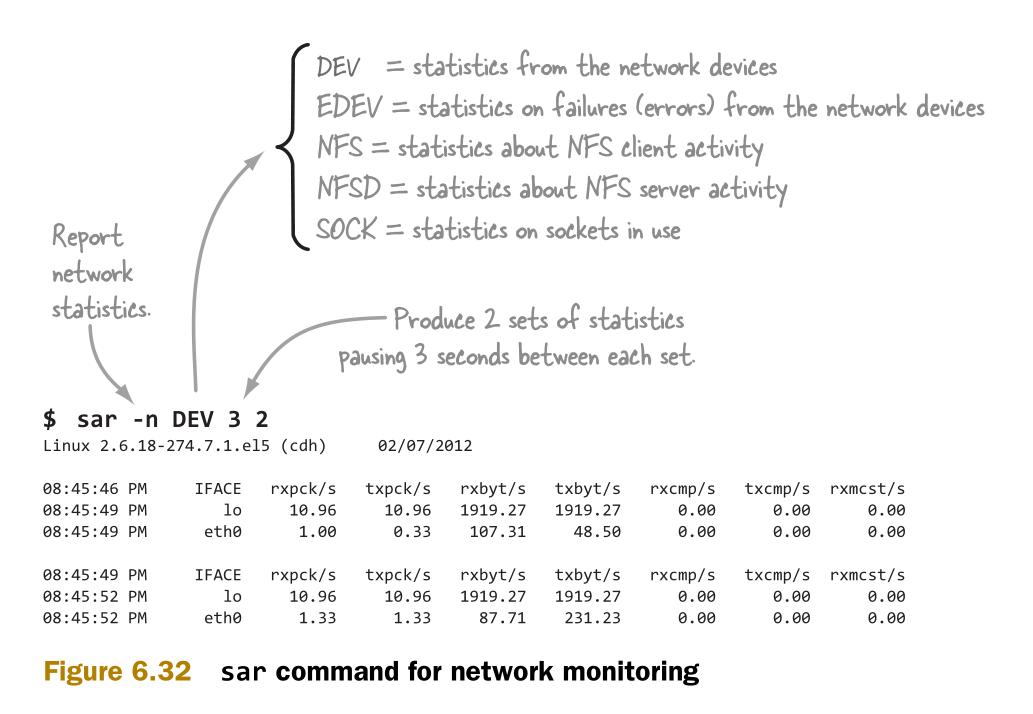
图6.33介绍sar的输出,并标记出其中指示了网络问题的指标。
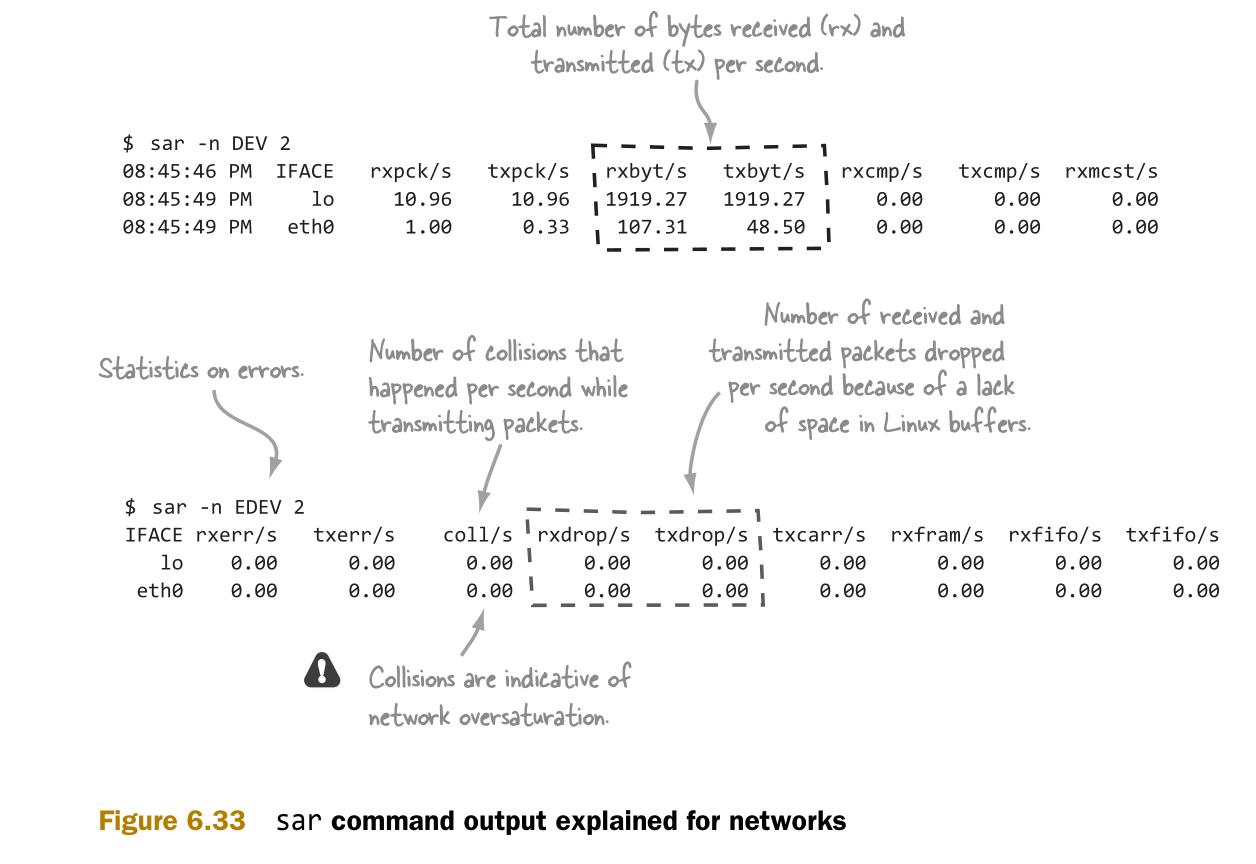
使用iperf(http://openmaniak.com/iperf.php)可以测试主机间的网络带宽,如图6.34所示。
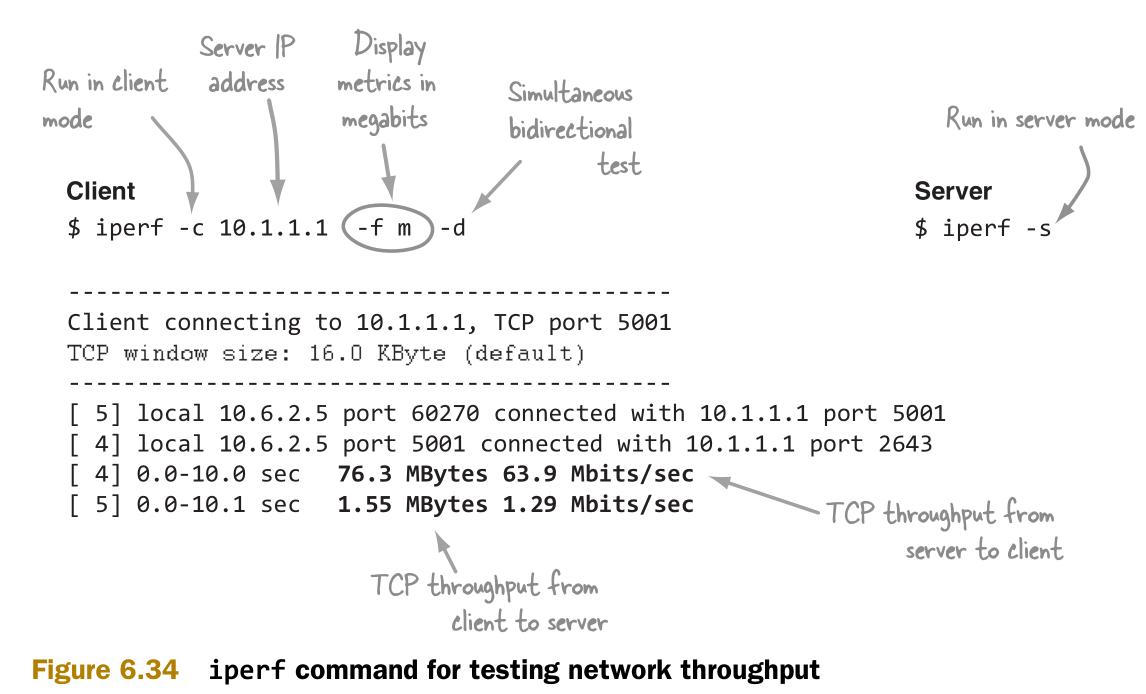
小结
这个技术中介绍了如何检查网卡的配置,如何使用工具获得网络性能指标,以及如何测量网卡和交换器之间的带宽。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号