混合云案例:利用 Databend Cloud 高效加速私有 Databend 的策略与实施

背景
Databend 是一款基于对象存储的存算分离湖仓产品,已成为云上大数据分析中高效且低成本的首选解决方案。目前,Databend 在多个用户场景中得到广泛应用,包括:
- 新媒体行业数据分析及大屏数据展示
- 云上 CDH 替代以减少本地磁盘和资源占用
- 性能明显提升的云上 Greenplum 替代方案
- 降低用户管理复杂度的云上 Clickhouse 替代方案
- ...
Databend 将数据持久化存储在对象存储中,计算层无状态且可随意扩展。同时,Databend 还充分利用云上对象存储的无需虚拟专用网络(VPC)的特性,实现了一个统一化的湖仓解决方案。
在云上构建大数据环境时,有两个昂贵的成本需要考虑:
- 本地磁盘成本,包括大量的闲置存储空间和冗余副本。
- 流量成本,跨 VPC 通信的带宽费用,通常 1G 带宽的成本都超过 0.5 元。
越来越多的云上用户选择利用 Databend 结合对象存储构建湖仓,以节省本地磁盘成本。由于对象存储无需 VPC,全球写入无需费用,内网请求无带宽费用,从而降低了云上大数据相关费用。
本文将介绍如何通过私有化部署 Databend 和结合公有云上的 Databend Cloud,将核心业务部署在私有环境中,然后借助 Databend Cloud 进行大规模计算和挖掘,用户可以减少 IT 建设成本,并实现强大的云端计算能力。
客户案例:
我们以一家位于阿里云杭州区的短视频内容产业客户为例。其核心业务涉及多平台内容投放,如抖音、快手、微信视频号等。客户在现有系统中部署了 Databend 服务,用于收集多个平台的数据投放情况和订单数据,并在数据平台上展示。这不仅让管理层直观地看到业务数据,也为营销策略提供了数据支持。
业务特征:
- 多个平台的数据投放:可能出现多个平台回来的订单数据,以及多个 API 的数据回传
- 数据全网打通:分析用户群体的活跃情况和投放效果
- 投放的留存分析及转化分析
- 挖倔分析及数据整理
挑战与解决方案:
该客户面临的主要挑战包括数据去重、多平台数据整合、投放留存分析和数据挖掘。
- 数据去重:由于多平台数据回传,可能存在重复数据。客户目前采用创建临时表的方式,接收传输的数据,并通过 SQL 与已入库数据进行比较,入库不重复数据,丢弃重复数据。
- 全网数据打通:需要对来自多个平台的用户进行匹配,计算用户活跃度和投放情况。由于业务只有 3 台 Databend 机器,有时会面临资源瓶颈。
- 投放留存和转化分析:可利用 Databend 的 bitmap 和漏斗函数进行方便的分析。
- 数据挖掘分析:利用 Databend 的索引特性,通过各种 SQL 查询实现高效的数据挖掘分析。
客户目前的挑战是处理大型 SQL 请求对现有资源造成较大压力,但又不希望扩大环境规模(受限于 IT 成本)。因此,结合 Databend Cloud 的使用,可以优化私有化 Databend 部署的成本。
接下来以 TPCH 中的表举例
基本架构如下
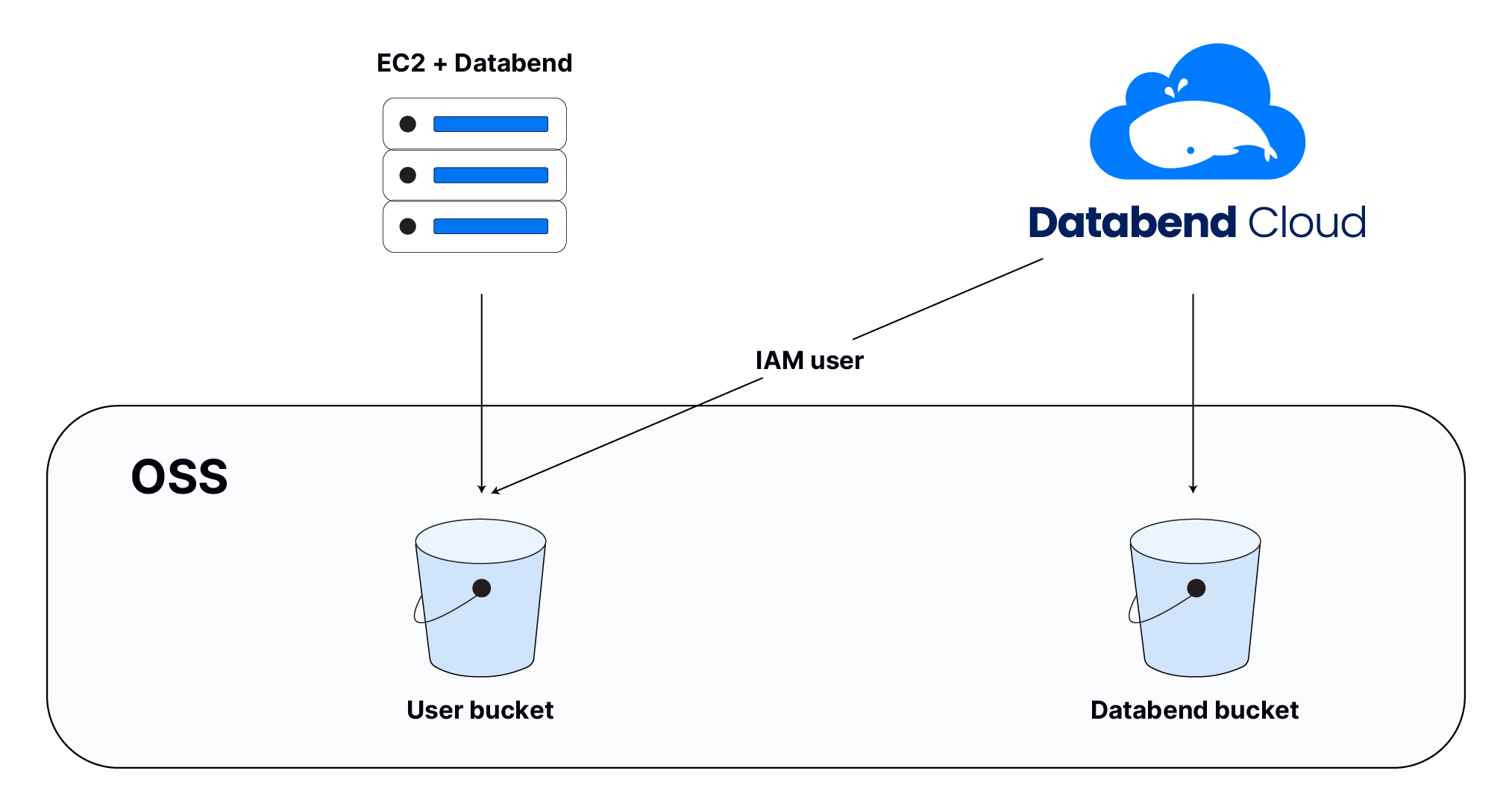
- 从阿里云市场关联 Databend Cloud
- 用户所在的区有对应的 Databend Cloud,计算和存储不要跨区
- 私有化环境表对应的 URI
- 在 Databend Cloud 中创建 attach 只读表
获取原表在存储上的位置
具体操作如下:
- 获取用户对应表的 URI
例如这里需要找到 tpch_100.lineitem 对应的 uri ,首先
SELECT
regexp_substr(snapshot_location, '^\d+/\d+/') AS table_path FROM
fuse_snapshot('tpch_100', 'lineitem')
LIMIT 1;
┌──────────────────┐
│ table_path │
│ Nullable(String) │
├──────────────────┤
│ 28/33/ │
└──────────────────┘
1 row read in 0.013 sec. Processed 1 row, 227 B (79.57 row/s, 17.64 KiB/s)
其中 snapshot_location 是对应的 bucket 下的 root 下指定的位置,默认 root 为:空。
例如我的 oss 配为:
SELECT * FROM system.configs WHERE name LIKE '%bucket' OR name LIKE '%root';
┌───────────────────────────────────────────────────┐
│ group │ name │ value │ description │
│ String │ String │ String │ String │
├─────────┼──────────────┼────────────┼─────────────┤
│ storage │ gcs.bucket │ │ │
│ storage │ gcs.root │ │ │
│ storage │ s3.bucket │ │ │
│ storage │ s3.root │ │ │
│ storage │ azblob.root │ │ │
│ storage │ hdfs.root │ │ │
│ storage │ obs.bucket │ │ │
│ storage │ obs.root │ │ │
│ storage │ oss.bucket │ wubx-bj01 │ │
│ storage │ oss.root │ wubx202310 │ │
│ storage │ webhdfs.root │ │ │
│ storage │ cos.bucket │ │ │
│ storage │ cos.root │ │ │
└───────────────────────────────────────────────────┘
13 rows read in 0.009 sec. Processed 155 rows, 9.21 KiB (16.51 thousand rows/s, 981.20 KiB/s)
针对这个环境的 URI 为:
语法: [oss://bucket[/root]/table_path/]
oss://wubx-bj01/wubx202310/28/33/
- 创建只读表
- 登录 app.databend.cn
- 进入 worksheet
- 创建或是切换到指定库下创建表
attach table lineitem 'oss://wubx-bj01/wubx202310/28/33/' connection=(
endpoint_url='https://oss-cn-beijing-internal.aliyuncs.com'
access_key_id='x'
access_key_secret='x'
) READ_ONLY;
- 通过 show tables; 确认表存在
show tables;
select count(*) from lineietm;
测试 SQL
把 tpch100sf 中 lineitem 挂载到 Databend Cloud 中,测试 Q1 效果为:
SELECT
l_returnflag,
l_linestatus,
sum(l_quantity) AS sum_qty,
sum(l_extendedprice) AS sum_base_price,
sum(l_extendedprice * (1 - l_discount)) AS sum_disc_price,
sum(l_extendedprice * (1 - l_discount) * (1 + l_tax)) AS sum_charge,
avg(l_quantity) AS avg_qty,
avg(l_extendedprice) AS avg_price,
avg(l_discount) AS avg_disc,
count(*) AS count_order
FROM
lineitem
WHERE
l_shipdate <= add_days(to_date('1998-12-01'), -90)
GROUP BY
l_returnflag,
l_linestatus
ORDER BY
l_returnflag,
l_linestatus;
成果展示
| 规格 | TPCH-100 Q1 响应时间 |
|---|---|
| 阿里云 S6-8C32G | 38.956s |
| Databend Cloud(medium) | 10.1s |
| Databend Cloud(xlarge) | 2.6s |
总结
通过 Databend Cloud,用户可以实现私有化大数据处理与公有云平台的一致性,充分利用 Databend Cloud 的弹性计算能力,快速完成大规模的分析 SQL 计算,使用后即可以释放。这种方法不仅提高了效率,还在成本控制方面提供了显著优势,为用户在数据驱动决策方面提供了强有力的支持。
Connect With Us
Databend 是一款开源、弹性、低成本,基于对象存储也可以做实时分析的新式数仓。期待您的关注,一起探索云原生数仓解决方案,打造新一代开源 Data Cloud。
👨💻 Databend Cloud:databend.cn
📖 Databend 文档:databend.rs/
💻 WeChat:Databend
✨ GitHub:github.com/datafuselab…

 浙公网安备 33010602011771号
浙公网安备 33010602011771号