
特性快闪:使用 Databend 玩转 Iceberg
作者:尚卓燃(PsiACE)澳门科技大学在读硕士,Databend 研发工程师实习生
Apache OpenDAL(Incubating) Committer
几周前,Databricks 和 Snowflake 召开了各自的年度大会,除了今年一路持续走红的 AI ,数据湖/数据仓库技术的发展仍然值得关注,毕竟数据才是基本盘。Apache Iceberg 无疑是数据湖方案的大赢家,Databricks 新推出的 UniForm 为以 Apache Iceberg 和 Hudi 表格式读取 Delta 中的数据提供了进一步的支持。而 Snowflake 也适时推出了 Iceberg Tables 更新,宣称要进一步打破数据孤岛。
Databend 最近几个月正在推动的重要新特性之一就是支持读取 Apache Iceberg 表格式的数据,尽管还没有完全落地,但已经取得了不错的进展。
今天这篇文章旨在为大家提前演示这一新特性 —— 使用 Databend 挂载并查询 Iceberg Catalog ,我们将介绍 Iceberg、表格式的一些核心概念,并且试图介绍 Databend 的解决方案(包括 Databend 的多源数据目录能力和以 Rust 从头实现的 IceLake)。当然,作为演示,我们将会提供完整的 workshop ,供大家尝鲜体验。
Apache Iceberg
时至今日,越来越多的数据进入云端,并且存储在对象存储之中,但这并不能完全适应现代分析的需求。这里有两个问题需要解决:第一个是数据以何种形式组织,也就是说,如何得到更结构化的数据存储。第二个问题还要更进一步,如何为用户提供更广泛的一致性保证以及业务中需要的模式信息,以及更多适应现代分析负载的高级特性。
数据湖往往会关注并解决第一个问题,而表格式则会致力于为第二个问题提供解决方案。
Apache Iceberg 是一种高性能的开放表格式,专为大规模分析工作负载而设计,简单而又可靠。同时支持 Spark、Trino、Flink、Presto、Hive 和 Impala 等查询引擎,并且具备模式演变(Full Schema Evolution)、时间旅行和回滚等杀手级特性。另外,Apache Iceberg 的数据分片和明确定义的数据结构还使得对数据源进行并发访问更加安全、可靠和方便。
如果你对 Iceberg 感兴趣,我们也推荐阅读像 Docker, Spark, and Iceberg: The Fastest Way to Try Iceberg! 这样的文章进行探索。
表格式初探
表格式(Table Format)是一种利用文件集合存储数据的规范。它主要包含以下三个部分的定义:
- 如何将数据存储在文件中
- 如何存储相关文件的元数据
- 如何存储有关表本身的元数据
表格式的文件通常存储在 HDFS、S3 或 GCS 这样的底层存储服务中,上层则会对接 Databend、Snowflake 等数据仓库。相比 CSV 或 Parquet ,表格式提供了表形式的标准的结构化数据定义,无需加载到数据仓库中就可以使用。
尽管表格式领域还有像 Delta Lake 和 Apache Hudi 这样的强劲对手,但这篇文章是关于 Apache Iceberg 的,所以,还是让我们把目光转向 Apache Iceberg ,一起了解一下它的底层文件组织结构。
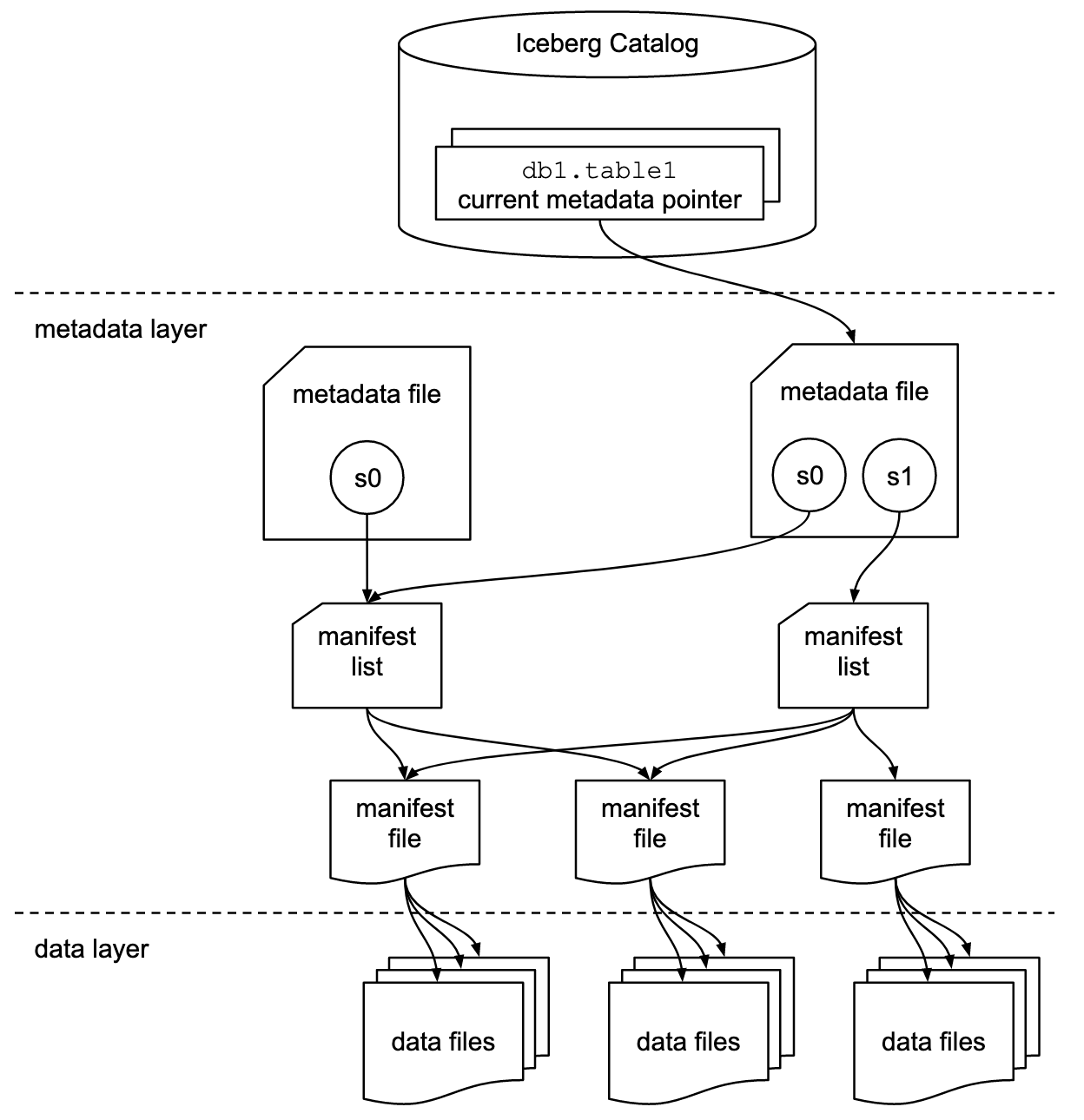
上图中的 s0 、s1 代表的是表的快照信息(snapshot),也就是表在某个时刻的状态。每次 commit 都会生成一个快照,每个快照都会对应一个清单列表(manifest list),而每个清单列表可以维护多个清单文件(manifest file)的地址与统计信息,包括路径和分区范围等。清单文件中会记录当前操作生成数据文件(data file)的地址和统计信息,比如列中的最大值最小值和数据行数等。
Databend 多源数据目录
要想在 Databend 中实现 Iceberg 集成,头一件是 Databend 的多源数据目录能力。多源数据目录将会允许将原本由其他数据分析系统所管理的数据挂载到 Databend 。
从设计之初,Databend 的目标就是成为云原生的 OLAP 数据仓库,并考虑到多源数据处理的问题。Databend 中的数据按三层进行组织:catalog -> database -> table ,catalog 作为数据最大一层,会包含所有的数据库和表。
团队在此基础上设计并实现对 Hive 和 Iceberg 数据目录的支持,提供配置文件和 CREATE CATALOG 语句多种挂载形式,从而支持对相关数据进行查询。
要想挂载数据位于 S3 中的 Iceberg Catalog,只需要执行下面的 SQL 语句:
CREATE CATALOG iceberg_ctl
TYPE=ICEBERG
CONNECTION=(
URL='s3://warehouse/path/to/db'
AWS_KEY_ID='admin'
AWS_SECRET_KEY='password'
ENDPOINT_URL='your-endpoint-url'
);
IceLake - Apache Iceberg 的纯 Rust 实现
尽管 Rust 生态中近年来涌现出不少数据库、大数据分析相关的新项目,但 Rust 生态中仍然缺乏成熟的 Apache Iceberg 绑定,这为 Databend 集成 Iceberg 制造了不少困难。
Databend Labs 支持并发起的 IceLake 旨在填补这一空白,并致力于建立一个开放生态系统:
- 用户可以从 任何 存储服务(如 s3、gcs、azblob、hdfs 等)读写 Iceberg 表。
- 任何 数据库都可以集成
icelake,以支持读写 Iceberg 表。 - 提供原生的
arrow格式互转换的能力。 - 提供多种语言绑定,使其他语言可以享有 Rust 核心带来的 Iceberg 生态支持。
当前 IceLake 已经支持读取 Apache Iceberg 存储服务中的数据(Parquet 格式)。而 Databend 的 Iceberg 数据目录能力正是由 IceLake 支撑的,其设计与实现在和 Databend 集成中得到了验证。
此外,我们还与 Iceberg 社区成员携手发起并参与 iceberg-rust 项目,旨在将 icelake 中 iceberg 相关的实现贡献给上游,目前第一个版本正紧锣密鼓的开发中,欢迎关注https://github.com/apache/iceberg-rust 。
Workshop:体验 Databend 的 Iceberg 能力
在这个 Workshop 中,我们将会展示如何准备 Iceberg 表格式的数据,并以 Catalog 的形式将其挂载到 Databend 上,并执行一些基本的查询。相关的文件和配置可以在 PsiACE/databend-workshop 中找到。
如果你本身有一些符合 Iceberg 表格式的数据存放在 OpenDAL 支持的存储服务中,我们更推荐使用 Databend Cloud ,这样你就可以跳过繁琐的服务部署和数据准备流程,轻松上手 Iceberg Catalog 。
启动服务
为了简化 Iceberg 的服务部署和数据准备问题,我们将会使用 Docker 和 Docker Compose ,你需要先安装这些组件,然后编写 docker-compose.yml 文件。
version: "3"
services:
spark-iceberg:
image: tabulario/spark-iceberg
container_name: spark-iceberg
build: spark/
networks:
iceberg_net:
depends_on:
- rest
- minio
volumes:
- ./warehouse:/home/iceberg/warehouse
- ./notebooks:/home/iceberg/notebooks/notebooks
environment:
- AWS_ACCESS_KEY_ID=admin
- AWS_SECRET_ACCESS_KEY=password
- AWS_REGION=us-east-1
ports:
- 8888:8888
- 8080:8080
- 10000:10000
- 10001:10001
rest:
image: tabulario/iceberg-rest
container_name: iceberg-rest
networks:
iceberg_net:
ports:
- 8181:8181
environment:
- AWS_ACCESS_KEY_ID=admin
- AWS_SECRET_ACCESS_KEY=password
- AWS_REGION=us-east-1
- CATALOG_WAREHOUSE=s3://warehouse/
- CATALOG_IO__IMPL=org.apache.iceberg.aws.s3.S3FileIO
- CATALOG_S3_ENDPOINT=http://minio:9000
minio:
image: minio/minio
container_name: minio
environment:
- MINIO_ROOT_USER=admin
- MINIO_ROOT_PASSWORD=password
- MINIO_DOMAIN=minio
networks:
iceberg_net:
aliases:
- warehouse.minio
ports:
- 9001:9001
- 9000:9000
command: ["server", "/data", "--console-address", ":9001"]
mc:
depends_on:
- minio
image: minio/mc
container_name: mc
networks:
iceberg_net:
environment:
- AWS_ACCESS_KEY_ID=admin
- AWS_SECRET_ACCESS_KEY=password
- AWS_REGION=us-east-1
entrypoint: >
/bin/sh -c "
until (/usr/bin/mc config host add minio http://minio:9000 admin password) do echo '...waiting...' && sleep 1; done;
/usr/bin/mc rm -r --force minio/warehouse;
/usr/bin/mc mb minio/warehouse;
/usr/bin/mc policy set public minio/warehouse;
tail -f /dev/null
"
networks:
iceberg_net:
在上述的配置文件中,我们使用 MinIO 作为底层存储,Iceberg 提供表格式能力,至于 spark-iceberg ,可以帮助我们准备一些预置数据并执行转换操作。
接下来,我们在 docker-compose.yml 文件对应的目录下启动所有服务:
docker-compose up -d
数据准备
在这个 Workshop 中,我们计划使用 NYC Taxis 数据集(纽约出租车搭乘数据),在 spark-iceberg 中已经内置了 Parquet 数据,我们只需要将其转化为 Iceberg 格式。
首先启用 pyspark-notebook :
docker exec -it spark-iceberg pyspark-notebook
接下来我们就可以在 http://localhost:8888 使用 Jupyter Notebook :
这里我们需要运行一小段程序,实施数据转换的操作:
df = spark.read.parquet("/home/iceberg/data/yellow_tripdata_2021-04.parquet")
df.write.saveAsTable("nyc.taxis", format="iceberg")
第一行将会读取 Parquet 数据,而第二行将会将其转储为 Iceberg 格式。
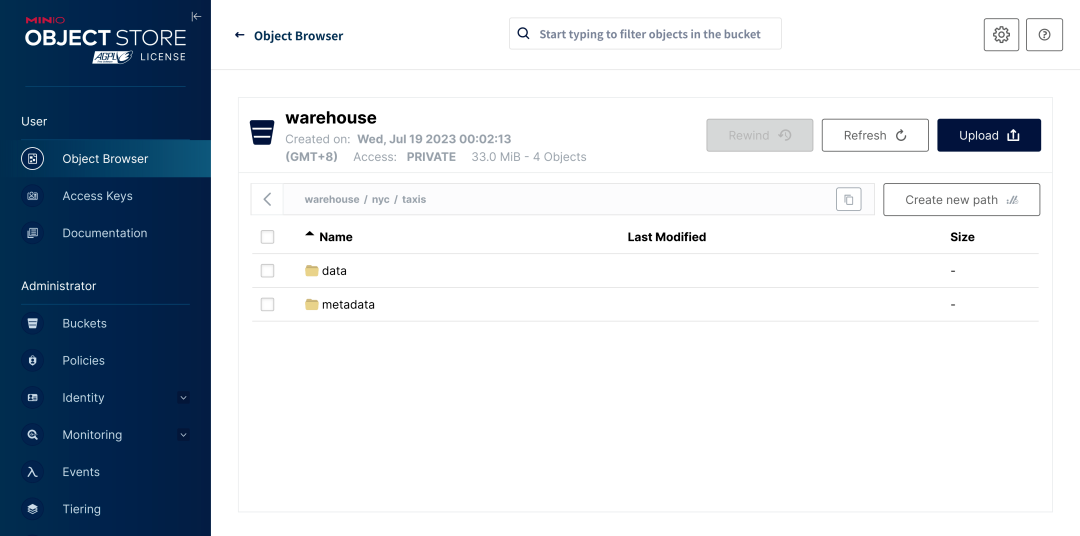
为了验证数据是否成功转换,我们可以访问位于 http://localhost:9001 的 MinIO 实例,可以看到数据是按之前描述的 Iceberg 底层文件组织形式进行管理的。
部署 Databend
这里我们使用手动部署单节点 Databend 服务的形式,总体上部署过程可以参考 Databend 官方文档 ,需要注意的一些细节如下:
-
首先是需要为日志和 Meta 数据准备相关的目录
-
sudo mkdir /var/log/databend sudo mkdir /var/lib/databend sudo chown -R $USER /var/log/databend sudo chown -R $USER /var/lib/databend
-
-
其次,因为默认的
admin_api_address已经被前面的服务占用掉,所以需要编辑databend-query.toml进行一些修改避免冲突:-
admin_api_address = "0.0.0.0:8088"
-
-
另外,我们还需要根据 Docs | Configuring Admin Users 配置管理员用户,由于只是一个 workshop ,这里选择最简单的方式,只是取消
[[query.users]]字段以及 root 用户的注释:-
[[query.users]] name = "root" auth_type = "no_password"
-
-
由于我们本地部署 MinIO ,没有设置证书加密,需要使用不安全的 HTTP 协议加载数据,所以还需要更改
databend-query.toml配置文件以允许这一行为。在生产服务中请尽可能避免开启它:-
... [storage] ... allow_insecure = true ...
-
接下来就可以正常启动 Databend :
./scripts/start.sh
我们强烈推荐你使用 BendSQL 作为客户端,当然,我们也支持像 MySQL Client 和 HTTP API 等多种访问形式。
挂载 Iceberg Catalog
根据之前的配置文件,只需要执行下述 SQL 就可以一键挂载 Iceberg Catalog 。
CREATE CATALOG iceberg_ctl
TYPE=ICEBERG
CONNECTION=(
URL='s3://warehouse/'
AWS_KEY_ID='admin'
AWS_SECRET_KEY='password'
ENDPOINT_URL='http://localhost:9000'
);
为了验证是否成功,我们可以执行 SHOW CATALOGS 查看:
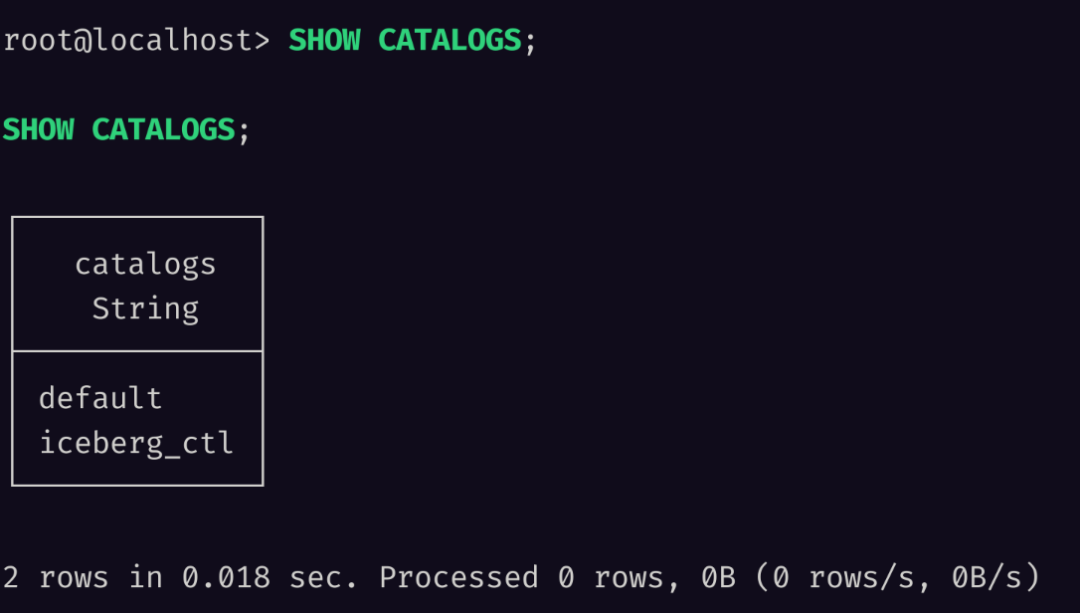
当然,我们也支持了 SHOW DATABASES 和 SHOW TABLES 语句,之前转换数据时的 nyc.taxis 对应在 MinIO 中是二级目录,而在 Databend 则会映射到数据库和表。
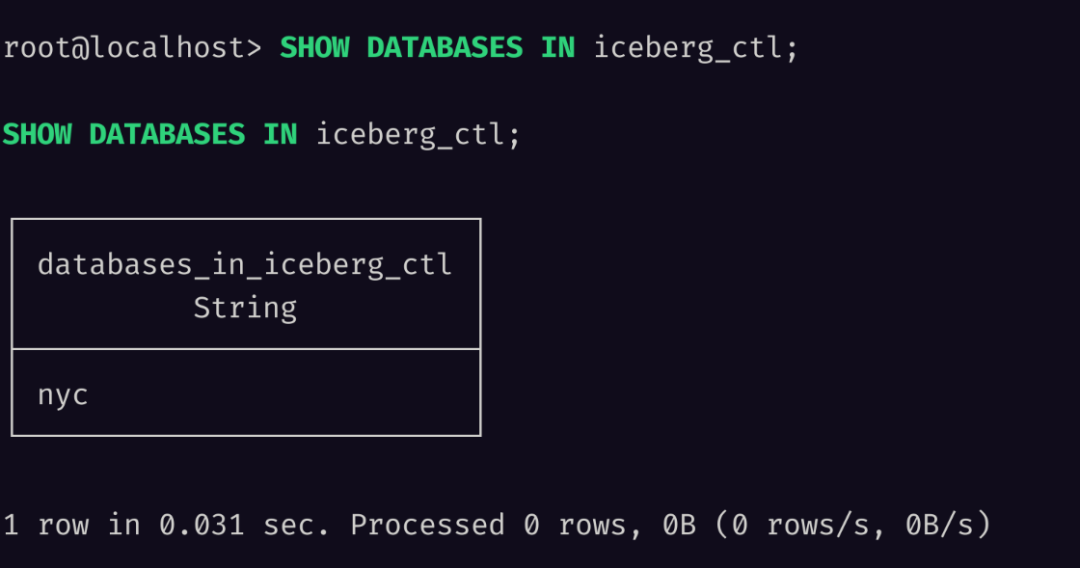
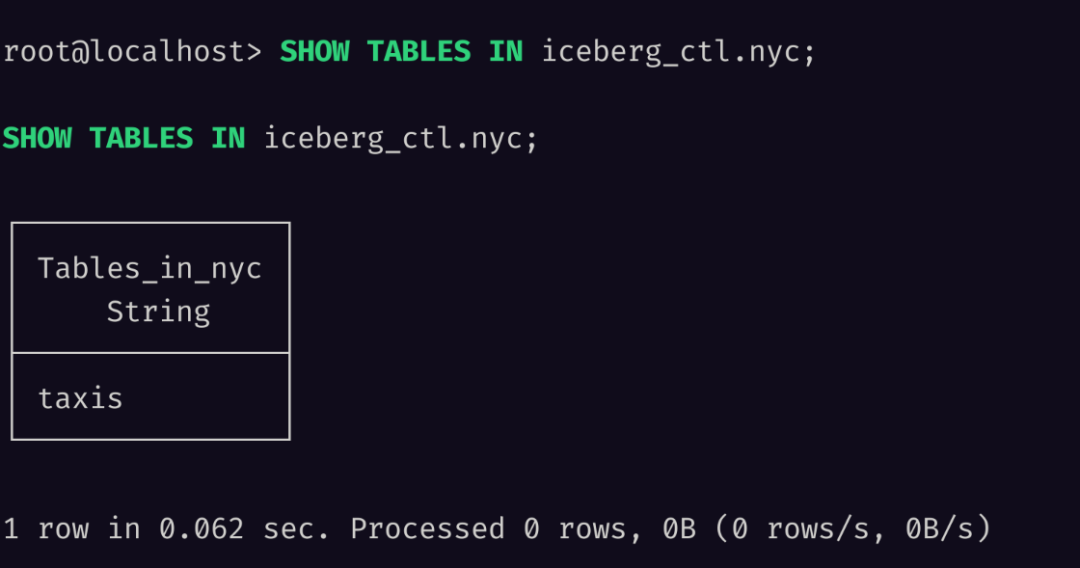
执行查询
数据已经挂载,那么就让我们执行一些简单的查询:
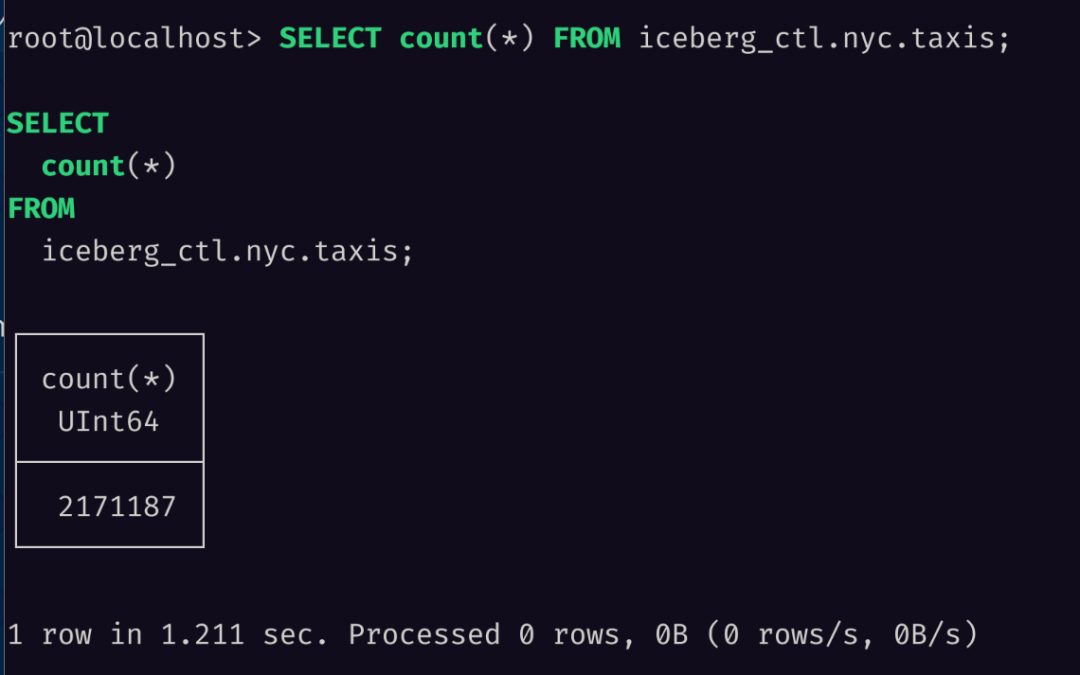
首先是对数据进行行数统计,可以看到一共挂载了 200 万行数据到 Databend:
SELECT count(*) FROM iceberg_ctl.nyc.taxis;
让我们从其中几列试着取一些数据出来:
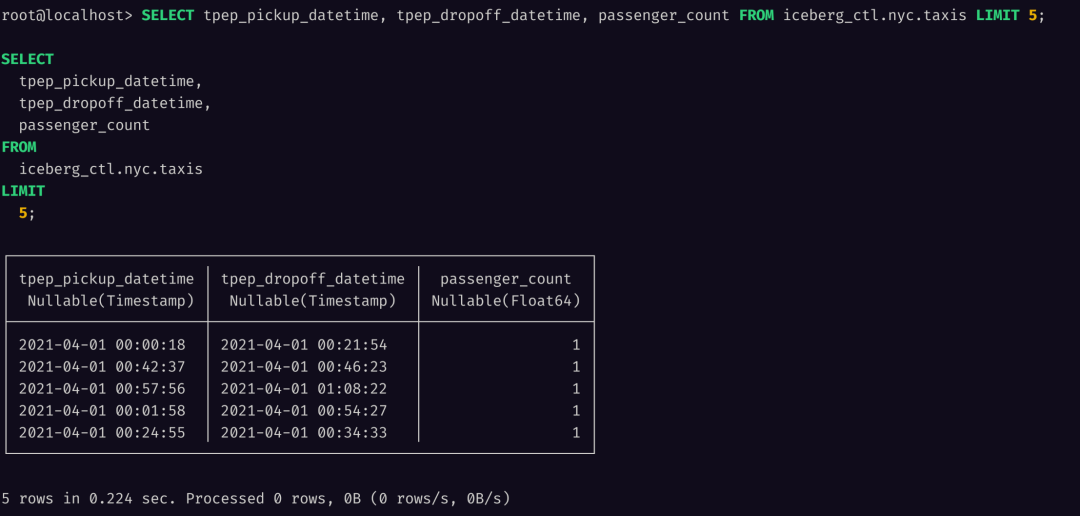
SELECT tpep_pickup_datetime, tpep_dropoff_datetime, passenger_count FROM iceberg_ctl.nyc.taxis LIMIT 5;
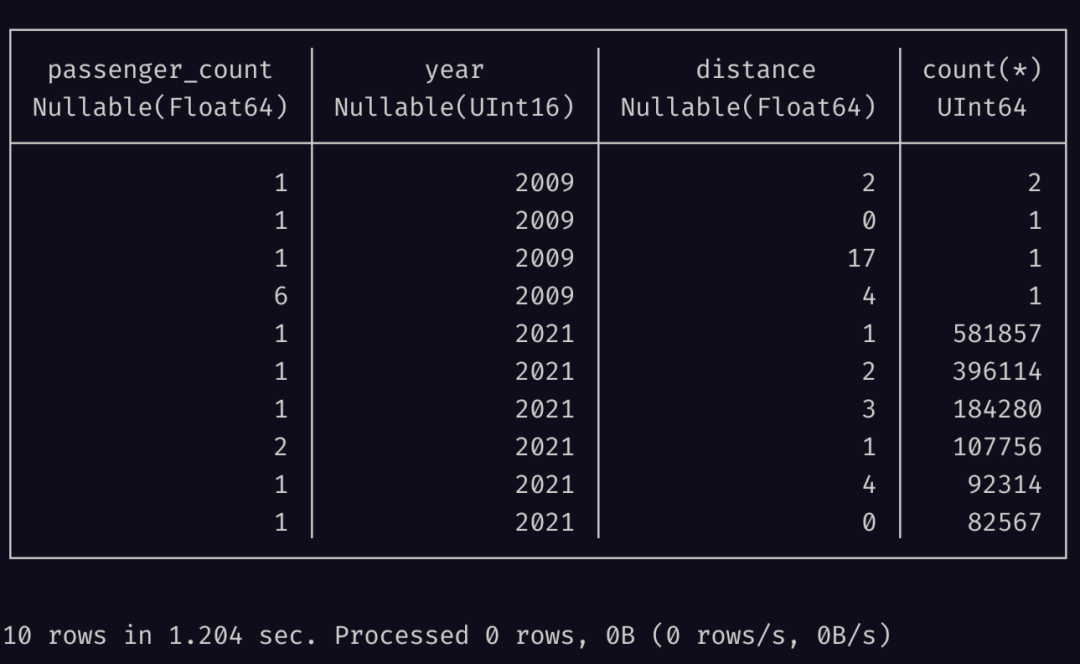
下面的查询可以帮助我们探索乘客数量和旅程距离之间的相关性,这里只取其中 10 条结果:
SELECT
passenger_count,
to_year(tpep_pickup_datetime) AS year,
round(trip_distance) AS distance,
count(*)
FROM
iceberg_ctl.nyc.taxis
GROUP BY
passenger_count,
year,
distance
ORDER BY
year,
count(*) DESC
LIMIT
10;
总结
在这篇文章中,我们介绍到 Apache Iceberg 表格式和 Databend 的相关解决方案,并且提供了一个相对完整的 workshop 供大家探索。
不难看出,尽管目前我们只为 Iceberg Catalog 提供了单机模式的目录挂载能力,但 Databend 可以胜任一些基本的查询处理任务。也欢迎大家在自己感兴趣的数据上进行尝试,并给我们提供一些反馈。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号