

坐标下降法(Coordinate Descent)
[转载自]: https://zhuanlan.zhihu.com/p/59734411?from_voters_page=true
目录
坐标下降法(Coordinate Descent)是一个简单但却高效的非梯度优化算法。与梯度优化算法沿着梯度最速下降的方向寻找最小值不同,坐标下降法依次沿着坐标轴的方向最小化目标函数值。
1. 坐标下降法的概念
坐标下降法的核心思想是将一个复杂的优化问题分解为一系列简单的优化问题以进行求解。我们知道,对高维的损失函数
求解最小值并不是一件容易的事情,而坐标下降法就是迭代地通过将大多数自变量
固定,即看作已知常量,而只针对剩余的自变量
求极值的过程。这样,一个高维的优化问题就被分解成了多个一维的优化问题,从而大大降低了问题的复杂性。
2. 坐标下降法的原理
下面直接通过一个简单的例子来演示坐标下降法是如何工作的:
假设我们有目标函数
其等高线图如下所示,求\((x,y)\)以使得目标函数在该点的值最小。
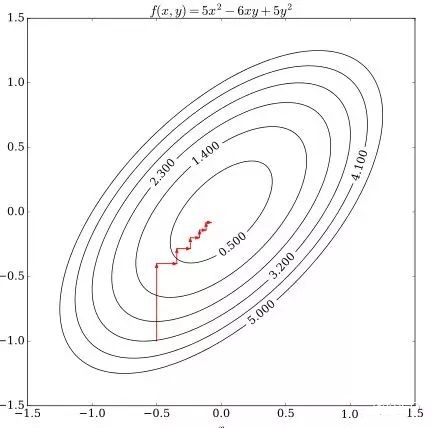
图1 等高线图(图片来源:https://en.wikipedia.org/wiki/Coordinate_descent)
图中红色十字标示的是起始点\((-0.5,-1.0)\),此时\(f=3.25\)。现在我们固定\(x\),将\(f\)看成关于\(y\)的一元二次方程并求当\(f\)最小时\(y\)的值:
代入\(x\)的值
通过令导数为零,求极值,得到新的\(y\)值
即,现在自变量的取值就更新成了\((-0.5,-0.3)\),\(f=0.8\)。如图2所示
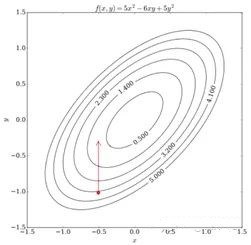
图2 第一轮迭代
下一步,将新得到的\(y\)值固定,将\(f\)看成关于\(x\)的一元二次方程并求当\(f\)最小时\(x\)的值。计算过程与上一步相似,由于计算比较简单,我们直接绘制出经过多轮如上迭代后自变量\((x,y)\)的运动轨迹,如图3所示:

图3 多轮迭代坐标变化轨迹
可见,随着\((x,y)\)依次在相应坐标轴上移动,目标函数逐渐接近其极小值点,直至在某次迭代中函数得不到优化,即达到某一驻点后停止。这就是一次完整的优化过程。我们将这个过程一般化:
对于\(f(x_0,x_1,\dots,x_n)\),求\(x\)以得到
假设\(x^{(k)}\)表示第\(k\)轮迭代,那么从初始值开始循环\(k=1,2,3....\):
直至收敛。
注意:每次得到的新的\(x_i^{(k)}\)的值会立即使用到后续的计算中。
以上便是坐标下降法的算法原理。
3. 坐标下降法与全局最小值
那么问题来了,假如我们寻找到了一个点\(x\)使得在所有单个坐标轴上\(f(x)\)都最小,是否证明我们找到了全局最小值点?
这个问题要分情况来看:
a. 若\(f(x)\)是可微的凸函数,答案是Yes,因为\(f(x)\)在任何坐标方向上求偏导都是0,并且对于凸函数来说,局部极小值就是全局最小值,如图4所示:
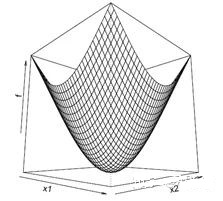
图4 可微的凸函数
b. 若\(f(x)\)是不可微的凸函数,答案是No,我们可以很容易举出反例,比如图5中算法会在不可微点(右图中红色虚线交叉点)停止迭代,因为在任意坐标方向上\(f(x)\)都找不到的更小值了。
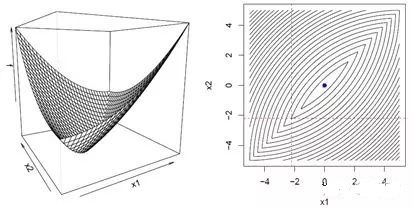
图5 不可微的凸函数
c. 若\(f(x)=g(x) + \sum_{i=0}^nh_i(x_i)\),其中\(g(x)\)是可微的凸函数,而每一个\(h_i\)都是凸函数,答案是Yes,证明如下:
假设\(x_0\)是通过坐标下降法得到的坐标点,那么,对于任意一点\(y\)来说,

图6
以上,就是坐标下降法的理论依据。
坐标下降法的几点注意事项
- 坐标轴的顺序可以是任意的,可以使用\(\{1,2,\dots,n\}\)的任何排列
- 之前我们介绍的是严格的坐标下降法,即每次进沿着单个坐标轴的方向寻找函数极小值。与之对应的是块坐标下降法,即每次沿着多个坐标轴的方向(超平面)取极值
- 将新的\(x_i^{(k)}\)的值立马代入后续的\((x_{i+1}^{(k)},\dots,x_n^{(k)})\)的计算很重要,否则有可能导致不收敛
- 当多个变量之间有较强的关联性时,坐标下降不是一个很好的方法。比如函数\(f(x)=(x_1-x_2)^2+\alpha(x_1^2+x_2^2)\),其中\(\alpha\)是正值常数。为了使\(f(x)\)最小,\((x_1-x_2)^2\)鼓励两个变量有相似值,而\((x_1^2+x_2^2)\)鼓励它们趋近于零。最终解是两者都为零,但当\(\alpha\)很小的时候,坐标下降法会使得优化过程异常缓慢,因为\((x_1-x_2)^2\)不允许单个变量变为和另一个变量当前值显著不同的值。所以在应用坐标下降法之前可以先使用主成分分析法(Principle Components Analysis,PCA)使各变量之间尽可能相互独立。
4. 总结
至此,坐标下降法就介绍完了。坐标下降法的优点是非常简单高效,但与此同时,很多的研究人员也正因为它过于简单而忽视了它。不过近几年情况有所好转,越来越多的人意识到了它的强大竞争力并扩展出了一些变形,逐渐更广泛地将其应用在实际问题中。
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号