
\(k\)均值聚类
目录
\(k\)均值(k-means)算法是最为经典的基于划分的聚簇方法,是十大经典数据挖掘算法之一。简单的说\(k\)均值就是在没有任何监督信号的情况下将数据分为\(k\)份的一种方法。聚类算法是无监督学习中最常见的一种,给定一组数据,需要聚类算法去挖掘数据中的隐含信息。聚类算法的应用很广:顾客行为聚类,google新闻聚类等。
\(k\)值是聚类结果中类别的数量。简单的说就是我们希望将数据划分的类别数。
1. \(k\)均值算法基本思想
在数据集中根据一定策略选择\(k\)个点作为每个簇的初始中心,然后观察剩余的数据,将数据划分到距离这\(k\)个点最近的簇中,也就是说将数据划分成\(k\)个簇完成一次划分,但形成的新簇并不一定是最好的划分,因此生成的新簇中,重新计算每个簇的中心点,然后在重新进行划分,直到每次划分的结果保持不变。
给定样本集\(D=\{\pmb x_1, \pmb x_2, \dots, \pmb x_m\}\),每个样本由一个特征向量表示,特征向量的维数是\(d\)。\(k\)均值聚类的目标是将\(m\)个样本分到\(k\)个不同的类或簇中。这里假设\(k \lt m\)。\(k\)个类形成了对样本集\(D\)的划分,用\(C\)表示划分\(C=\{C_1, C_2,\dots,C_k\}\),一个划分对应着一个聚类结果。
\(k\)均值聚类的策略是针对所得簇划分\(C\)最小化平方误差,即
其中,\(\pmb \mu_i = \frac{1}{|C_i|}\sum_{\pmb x \in C_i} \pmb x\)是第\(i\)个簇的均值向量或者中心。直观来看,式\((1)\)在一定程度上刻画了簇内样本围绕簇均值向量的紧密程度,\(E\)值越小则簇内样本相似度越高。
相似的样本被聚到同类时,平方误差值最小,使得式\((1)\)最小化能够达到聚类的目的。但是,这是一个组合优化问题,\(m\)个样本分到\(k\)类,所有可能分法的数目是:
这个数字是指数级的。事实上,\(k\)均值聚类的最优解求解问题是NP难问题。因此,\(k\)均值算法采用了贪心策略,通过迭代优化来近似求解。在实际应用中往往经过很多次迭代仍然达不到每次划分结果保持不变,甚至因为数据的关系,根本就达不到这个终止条件,所以往往采用变通的方法设置一个最大迭代次数,当达到最大迭代次数时,终止计算。
2. \(k\)均值算法
\(k\)均值聚类的算法是一个迭代的过程,每次迭代包含两个步骤。首先选择\(k\)个类的中心,将样本逐个分配到与其最近的中心的类中,得到一个聚类结果;然后更新每个类的样本的均值,作为类的新的中心;重复以上步骤,直到收敛为止。
首先,对于给定的中心值\((\mu_1, \mu_2, \dots,\mu_k)\),\(\mu\)表示均值向量。求一个划分\(C\),使得目标函数极小化:
就是说在类中心确定的情况下,将每一个样本分到一个类中,使样本和其所属类的中心之间的距离总和最小。求解结果,将每个样本分配到与其最近的中心\(\mu_i\)的类\(C_i\)中。
然后,对于给定的划分\(C\)(上一步求解得到的),再求各个类的中心\((\mu_1, \mu_2, \dots,\mu_k)\),使得目标函数极小化。就是说在划分确定的情况下,使样本和其所属类的中心之间的距离总和最小。求解结果,对于每个类\(C_i\),更新其均值\(\mu_i\):
其中,\(|C_i|\)表示类\(C_i\)中的样本数量。重复以上两个步骤,直到划分不再改变,得到聚类结果。现将\(k\)均值算法叙述如下:
输入:样本集\(D=\{\pmb x_1, \pmb x_2, \dots, \pmb x_m\}\)和聚类簇数\(k\)。
1)从\(D\)中随机选择\(k\)个样本作为初始均值向量\((\mu_1, \mu_2, \dots,\mu_k)\);
2)计算样本\(x_j(j=1,2,\dots,m)\)与各均值向量\(\mu_i(1\le i \le k)\)的距离:\(d_{ji}=\parallel{\pmb x - \pmb \mu_i}\parallel_2\);
3)根据距离最近的均值向量确定\(x_j\)的簇标记:\(\lambda_j = argmin_{i \in \{1,2,\dots,k\}}d_{ji}\);
4)将样本\(x_j\)划入相应的簇:\(C_{\lambda_j} = C_{\lambda_j} \bigcup \{x_j\}\);
5)计算新的均值向量:\(\mu_i^{'}=\frac{1}{|C_i|}\sum_{x \in C_i} x , i=1,2,\dots,k\);
6)如果当前均指向量\(\mu_i\)与\(\mu_i^{'}\)相等,保持当前均值向量不变,否则将当前均值向量更新为\(\mu_i^{'}\);
7)重复步骤\(2-6\)直到当前的均值向量均不再更新。
输出:簇划分\(C=\{C_1, C_2,\dots,C_k\}\)。
一个直观的例子
以下面的西瓜数据集为例来演示\(k\)均值算法的实现过程。
| 编号 | 密度 | 含糖率 | 编号 | 密度 | 含糖率 | 编号 | 密度 | 含糖率 |
|---|---|---|---|---|---|---|---|---|
| 1 | 0.697 | 0.460 | 11 | 0.245 | 0.057 | 21 | 0.748 | 0.232 |
| 2 | 0.774 | 0.376 | 12 | 0.343 | 0.099 | 22 | 0.714 | 0.346 |
| 3 | 0.634 | 0.264 | 13 | 0.639 | 0.161 | 23 | 0.483 | 0.312 |
| 4 | 0.608 | 0.318 | 14 | 0.657 | 0.198 | 24 | 0.478 | 0.437 |
| 5 | 0.556 | 0.215 | 15 | 0.360 | 0.370 | 25 | 0.525 | 0.369 |
| 6 | 0.403 | 0.237 | 16 | 0.593 | 0.042 | 26 | 0.751 | 0.489 |
| 7 | 0.481 | 0.149 | 17 | 0.719 | 0.103 | 27 | 0.532 | 0.472 |
| 8 | 0.437 | 0.211 | 18 | 0.359 | 0.188 | 28 | 0.473 | 0.376 |
| 9 | 0.666 | 0.091 | 19 | 0.339 | 0.241 | 29 | 0.725 | 0.445 |
| 10 | 0.243 | 0.267 | 20 | 0.282 | 0.257 | 30 | 0.446 | 0.459 |
假定聚类数\(k=3\),算法开始随机选取三个样本\(x_6,x_{12},x_{27}\)作为初始均值向量,即
考察样本\(x_1=(0.697,0.460)\),它与当前均值向量\(\mu_1,\mu_2,\mu_3\)的(欧氏)距离分别为0.369、0.506、0.166,因此\(x_1\)将被划入簇\(C_3\)中。类似的,对数据集中的所有样本考察一遍后,可得当前簇划分为
于是,可以从\(C_1,C_2,C_3\)分别求出新的均值向量
更新当前均值向量后,不断重复上述过程,第五轮迭代产生的结果与第四轮迭代相同,于是算法停止,得到最终的簇划分。
3. \(k\)均值算法特性
\(k\)均值算法试图找到使平方误差准则函数最小的簇。当潜在的簇形状是凸面的,簇与簇之间区别较明显,且簇大小相近时,其聚类结果较理想。对于处理大数据集合,该算法非常高效,且伸缩性较好。
\(k\)均值聚类属于启发式方法,能够保证收敛,但不能保证收敛到全局最优,经常以局部最优结束,除了对初始聚类中心敏感外,同时对“噪声”和孤立点敏感,并且该方法不适于发现非凸面形状的簇或大小差别很大的簇。
\(k\)均值聚类在选择不同的初始中心时,通常会得到不同的聚类结果。初始中心的选择,选择彼此距离尽可能远的那些点作为中心点或者可以使用层次聚类对样本进行聚类,得到\(k\)个类时停止。然后从每个类中选取一个与中心距离最近的点。
\(k\)均值聚类中的\(k\)值需要预先指定,而在实际应用中最优的\(k\)值是不知道的。解决这个问题的一个方法是尝试用不同的\(k\)值聚类,检验各自得到的聚类结果的质量(聚类结果质量度量可以查看《机器学习-周志华》第9章9.2节),推测最优的\(k\)值。
4. 一个简单的\(k\)均值聚类实例
下面我们使用sklearn库中的\(k\)均值聚类算法对鸢尾花数据集进行聚类分析。我们知道鸢尾花数据集中的数据是有标签的,我们可以用来直观的感受一下\(k\)均值聚类的效果。
# python 3.6
# sklearn 0.20.3
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
# 直接从sklearn中加载鸢尾花数据集
data = load_iris()
X = data.data
y = data.target
# 只选用其中的两个特征进行聚类分析,并可视化
# 已知鸢尾花数据集中只有3个分类,所以我们k值设置为3
km = KMeans(n_clusters=3)
km.fit(X[:,[2,3]])
# 得到聚类簇
label_pred = km.labels_
# 将结果进行可视化
fig, ax = plt.subplots(1,2, figsize=(12, 6))
ax[0].scatter(X[:,2], X[:,3], c=y)
ax[0].set_title("原始鸢尾花类别")
z = X[:,[2,3]]
x0 = z[y == 0]
x1 = z[y == 1]
x2 = z[y == 2]
ax[1].scatter(x0[:, 0], x0[:, 1], c = "gray", marker='o', s=110, label='label0')
ax[1].scatter(x1[:, 0], x1[:, 1], c = "gray", marker='*', s=110, label='label1')
ax[1].scatter(x2[:, 0], x2[:, 1], c = "gray", marker='+', s=110,label='label2')
ax[1].scatter(X[:,2], X[:,3], s=10, c=label_pred)
ax[1].set_title("聚类生成的鸢尾花类别")
ax[1].legend()
plt.show()
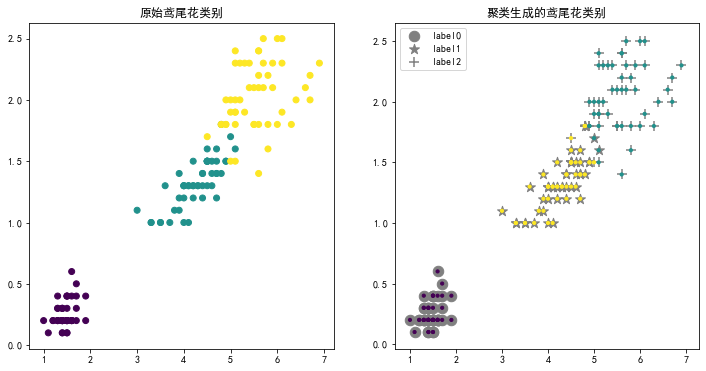
图1 鸢尾花数据k均值聚类
如图1所示,左侧展示了鸢尾花数据集中对鸢尾花类别的标记,右侧我们将\(k\)均值聚类的结果和原始的标记绘制在了一起,使用不同的颜色的小圆点表示聚类结果,灰色不同形状表示原始类别。能够看出当选取鸢尾花最后两个特征作为聚类数据时,聚类的效果还不错。
参考来源:
1)机器学习-周志华
2)统计学习方法-李航
3)https://www.cnblogs.com/nxld/p/6376496.html
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号