

拉勾网数据分析师职位分析
项目背景:
2018年11月份开始学习数据分析相关课程,目前学到不少知识,准备开始找工作。在这之前想自己做一个实战,一是能够证明自己确实做了准备,初步具备数据分析师岗位的能力,二是通过实战复习自己所学知识,熟悉数据分析流程。三是,从自己想从事的数据分析职位入手分析,也能够借此了解数据分析师的收入情况?自己的学历、工作经验是否符合数据分析师的要求? 哪些公司招聘需求高? 哪个城市、哪个领域较为需要数据分析师?
收集数据
利用“八爪鱼”抓取2018年6月26日拉勾网站内搜索“数据分析”关键词下的435条职位信息。通过这些职位信息的分析和建模来进一步了解这一职位。
数据集中相关字段说明:
'positionName':职位名称
'salary':工资水平
'address':地区
'workYear':工作年限
'education':学历要求
'companyName':公司名称
'industryField':行业领域
'financeStage':融资情况
'companySize':公司规模
明确分析目标对于自己关心的这些问题,下面会从多维度(城市、工作年限、学历、领域、公司规模几个维度)进行分析:
1、分析数据分析职位的分布情况
2、分析数据分析职位的薪酬情况
数据清洗及预处理
首先进行数据清洗前的准备工作
导入所需要的库以及文件
1 import pandas as pd
2 import numpy as np
3 import re
4 #导入数据
5 df=pd.DataFrame(pd.read_excel(r'E:\siren\找工作互联网招聘求职网拉勾网1.xlsx'))
1、对领域(行业所处的领域)字段进行清洗
查看数据,清晰看到industryField字段中有的只有一个行业名称,有的有2级行业名称。保留领域字段第一部分的信息,对有2部分行业名称的字段取前一个。
1 #查看数据
2 df.head()
3 #查看数据各字段的名称
4 df.columns
5 #查看数据维度
6 df.shape

df['industryField']

可以看到行业名称之间有顿号分割,有的是逗号分隔,所以先将所有的分隔符统一为逗号,然后对数据进行分列,并将分列后的数据重新拼接回原数据表中:
1 1 industry=[]
2 2 #将顿号分隔符替换为逗号
3 3 for x in df['industryField']:
4 4 a=x.replace("、",",")
5 5 industry.append(a)
6 6 #将替换后的行业数据设置为DataFrame格式
7 7 industry=pd.DataFrame(industry,columns=['industry'])
8 8 #对行业数据进行分列
9 9 industry_s=pd.DataFrame((x.split(',') for x in industry['industry']),columns=['industry_1','industry_2'])
10 10 df=pd.merge(df,industry_s,right_index=True,left_index=True)
11 11 df['industry_1']=df['industry_1'].map(str.strip)
12 12
13 13 #将industry_1数据保留并赋值给industryField字段
14 14 df['industryField']=df['industry_1']
15 15 df=df.drop(['industry_1','industry_2'],axis=1)
2、对薪资范围字段清洗及处理
因为抓取的薪资数据是一个区间值,比较分散,无法直接使用。现在去掉无关信息,只保留薪资上限和下限,利用这两个数字计算平均值。
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
1 #去除字段中'k'或'K'字符
2 salary=[]
3 for x in df['salary']:
4 k=re.sub('[k|K]','',x)
5 salary.append(k)
6 #将salary数据转换为DataFrame格式
7 salary=pd.DataFrame(salary,columns=['salary'])
8 salary_s=pd.DataFrame((x.split('-') for x in salary['salary']),columns=['bottomSalary','topSalary'])
9 #更改字段格式
10 salary_s['bottomSalary']=salary_s['bottomSalary'].astype(np.int)
11 salary_s['topSalary']=salary_s['topSalary'].astype(np.int)
12 #计算平均值
13 avg=[]
14 for i in range(len(salary_s)):
15 avg.append((salary_s['bottomSalary'][i]+salary_s['topSalary'][i])/2)
16 salary_s['avgSalary']=avg
17 #将salary_s表与原表进行拼接
18 df=pd.merge(df,salary_s,right_index=True,left_index=True)
分析
数据分析职位需求分布
首先从数据分析职位的行业和城市两个维度来分析数据分析职位的需求分布情况。哪个行业、哪个城市最需要数据分析人才?
不同行业数据分析职位需求情况

由图可以看出:在16个细分领域中数据分析职位需求最高的是移动互联网行业,其次是金融和电子商务行业。需求最少的是生活服务和文化娱乐行业。下面是具体的数据处理和可视化过程。
1 #首先对industryField字段进行汇总统计
2 df['industryField'].value_counts()
3
4 #可以看到行业领域共分为16个细分行业,具体分析过程
5 industry_count=df['industryField'].value_counts()
6 plt.rc('font', family='STXihei', size=10)
7 a=np.arange(16)
8 plt.figure(figsize=(8,6))
9 plt.barh(range(16),industry_count,color='skyblue')
10 plt.xlabel('职位数量')
11 plt.ylabel('职位名称')
12 plt.title('不同行业领域数据分析职位数量')
13 plt.legend(['职位数量'],loc='upper right')
14 plt.grid(color='#95a5a6',linestyle='--',linewidth=1,axis='x',alpha=0.4)
15 plt.yticks(range(16),('移动互联网','金融','电子商务','数据服务','企业服务','O2O','教育','医疗健康','游戏','其他','信息安全','旅游','社交网络','硬件','文化娱乐','生活服务'))
不同城市数据分析职位需求情况

从城市维度来看,北京数据分析职位的需求量为最多,其次其次是上海,杭州,深圳的数量不如杭州多。在TOP10城市中,对数据分析人才需求最大少的是郑州、合肥,职位数量仅仅4个。所以想要从事数据分析一职,基本上要选择留在北上广深,或者杭州,才能拥有更好的发展。下面是具体的数据处理过程。
1 city_count=df['city'].value_counts()
2 plt.rc('font', family='STXihei', size=10)
3 a=np.arange(10)
4 plt.figure(figsize=(8,6))
5 plt.bar(range(10),city_count[:10],color='skyblue')
6 plt.xlabel('城市')
7 plt.ylabel('职位数量')
8 plt.title('不同城市数据分析职位数量')
9 plt.legend(['职位数量'],loc='upper right')
10 plt.grid(color='#95a5a6',linestyle='--',linewidth=1,axis='y',alpha=0.4)
11 plt.xticks(a,('北京','上海','杭州','深圳','广州','武汉','长沙','南京','郑州','合肥'))
其次,从公司规模和融资阶段两个维度进行分析,了解数据分析职位的需求状况。大公司还是小公司更需要数据分析人才?
不同公司规模数据分析职位需求分布
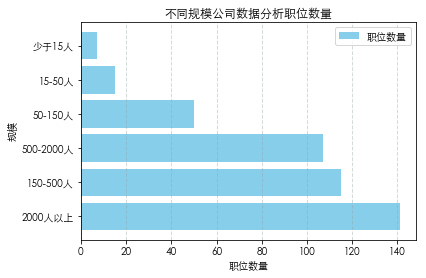
从公司规模维度分析,公司规模越大对数据分析人才的需求也就越大。从结果发现少于15人的公司需求量最少。可以猜测到,当公司规模较小时,公司的配置不健全,没有独立的数据部门,对数据分析职位当然不会有较大需求。但是大公司会有自己的数据团队对决策进行数据支持。下面是数据处理过程:
1 df['companySize']=df['companySize'].map(str.strip)
2 company_count=df['companySize'].value_counts()
3 plt.rc('font', family='STXihei', size=10)
4 a=np.arange(6)
5 plt.figure(figsize=(6,4))
6 plt.barh(range(6),company_count,color='skyblue')
7 plt.xlabel('职位数量')
8 plt.ylabel('规模')
9 plt.title('不同规模公司数据分析职位数量')
10 plt.legend(['职位数量'],loc='upper right')
11 plt.grid(color='#95a5a6',linestyle='--',linewidth=1,axis='x',alpha=0.4)
12 plt.yticks(a,company_count.index)
不同融资阶段数据分析职位需求分布

天使轮需求最少,上市公司和不需要融资的公司需求量最多。结合前面公司规模的分析,可以理解,天使轮人少钱也少,数据分析人才需求不大,但是上市公司规模较大,数据分析需求也就大。从A轮到D轮,数据分析需求较天使轮,数据分析需求有明显增长。
1 finance_count=df['financeStage'].value_counts()
2
3 plt.rc('font', family='STXihei', size=10)
4 a=np.arange(8)
5 plt.figure(figsize=(6,4))
6 plt.barh(range(8),finance_count,color='skyblue')
7 plt.xlabel('职位数量')
8 plt.ylabel('融资阶段')
9 plt.title('不同融资公司数据分析职位数量')
10 plt.legend(['职位数量'],loc='upper right')
11 plt.grid(color='#95a5a6',linestyle='--',linewidth=1,axis='x',alpha=0.4)
12 plt.yticks(a,finance_count.index)
数据分析职位对个人能力的要求
从工作年限和学历两个维度来分析数据分析职位的需求分布。
数据分析对工作年限的要求
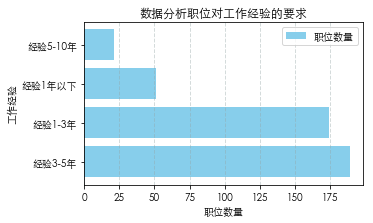
从工作年限来看,大部分公司的需求都在1-3年和3-5年这两个阶段。这两个阶段的人较工作5-10年的人年轻,精力旺盛,对工资要求不是特别高,学习能力也较强。
1 df['workYear']=df['workYear'].map(str.strip)
2 #将经验不限、经验一年以下、经验应届毕业生合并
3 for i in range(len(df['workYear'])):
4 if df['workYear'][i] in ['经验应届毕业生','经验不限']:
5 df['workYear'][i]='经验1年以下'
6 work_count=df['workYear'].value_counts()
7
8 plt.rc('font', family='STXihei', size=10)
9 a=np.arange(4)
10 plt.figure(figsize=(6,4))
11 plt.barh(range(4),work_count,color='skyblue')
12 plt.xlabel('职位数量')
13 plt.ylabel('工作经验')
14 plt.title('数据分析职位对工作经验的要求')
15 plt.legend(['职位数量'],loc='upper right')
16 plt.grid(color='#95a5a6',linestyle='--',linewidth=1,axis='x',alpha=0.4)
17 plt.yticks(a,work_count.index)
数据分析对学历的要求

从学历维度看,本科学历的数据分析人才需求量最高,占比85.3%,也就是说大多数数据分析职位对学历要求不是很高,仅仅3.7%的公司要求学历在硕士以上。
1 education_count=df['education'].value_counts()
2
3 plt.rc('font', family='STXihei', size=10)
4 labels='本科及以上','大专及以上','学历不限','硕士及以上'
5 colors=[ 'lightskyblue', 'gold','yellowgreen', 'lightcoral']
6 explode=(0.1,0.1,0.1,0.1)
7 plt.axis('equal')
8 plt.title('数据分析对学历的要求')
9 plt.pie(education_count,explode=explode,labels=labels,colors=colors,autopct='%1.1f%%',shadow=True,startangle=60,radius=1.2)
数据分析薪资范围分布
首先利用直方图观察薪资的大概分布情况

从图中看出,数据分析职位的工资大部分集中在8K-22K左右,整体呈左偏分布。少数人工资的人较低(在5000以下),极少数人能够拿到超高的薪资(35K以上)。整体来看数据分析一职,薪资待遇情况还是不错的。
1 plt.rc('font', family='STXihei', size=10)
2 plt.figure(figsize=(8,6))
3 plt.hist(df['avgSalary'],bins=30,color='skyblue')
4 plt.grid(color='#95a5a6',linestyle='--',linewidth=0.8,axis='y',alpha=0.4)
5 plt.axis('tight')
6 plt.title('薪酬分布')
7 plt.xlabel('每月薪酬(单位:K/月)')
8 plt.legend(loc=0)
行业对平均薪资的影响
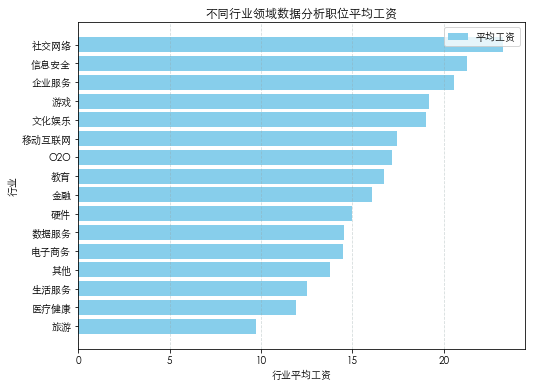
从行业平均工资来看,社交网络、信息安全、企业服务领域工资最高,旅游、医疗健康、生活服务行业工资最低。
1 industry_avg=df.groupby(by=['industryField'])['avgSalary'].mean().sort_values()
2
3 plt.rc('font', family='STXihei', size=10)
4 a=np.arange(16)
5 plt.figure(figsize=(8,6))
6 plt.barh(range(16),industry_avg,color='skyblue')
7 plt.xlabel('行业平均工资')
8 plt.ylabel('行业')
9 plt.title('不同行业领域数据分析职位平均工资')
10 plt.legend(['平均工资'],loc='upper right')
11 plt.grid(color='#95a5a6',linestyle='--',linewidth=0.8,axis='x',alpha=0.4)
12 plt.yticks(a,industry_avg.index)
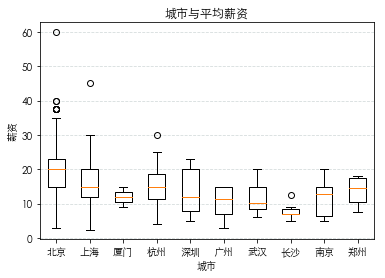
城市对平均薪资的影响
从城市角度来看,北京、杭州、上海的数据分析职位工资位列前三名,长沙、武汉的工资最低。其中北京的工资极差最大从3K~35K。![]()
在提取筛选数据时,发现因为city字段数据中有空格的存在,总是匹配不到数据,因此先对city字段进行处理,清除数据中的空格符
1 #取岗位需求前10名的城市
2 df.groupby(['city'])['avgSalary'].count().sort_values()
3
4 #先利用语句判断出字段数据中是否有空格符的存在
5 df['city'].values #发现数据中存在空格符
6 #进行处理空格符
7 df['city']=df['city'].map(str.strip)
8
9 #提取数据
10 city1=df.loc[df['city']=='北京',['city','avgSalary']]
11 city2=df.loc[df['city']=='上海',['city','avgSalary']]
12 city3=df.loc[df['city']=='成都',['city','avgSalary']]
13 city4=df.loc[df['city']=='杭州',['city','avgSalary']]
14 city5=df.loc[df['city']=='深圳',['city','avgSalary']]
15 city6=df.loc[df['city']=='广州',['city','avgSalary']]
16 city7=df.loc[df['city']=='武汉',['city','avgSalary']]
17 city8=df.loc[df['city']=='长沙',['city','avgSalary']]
18 city9=df.loc[df['city']=='南京',['city','avgSalary']]
19 city10=df.loc[df['city']=='郑州',['city','avgSalary']]
20
21 #绘图
22 plt.rc('font', family='STXihei', size=10)
23 plt.xlabel('城市')
24 plt.ylabel('薪资')
25 plt.title('城市与平均薪资')
26 plt.grid(color='#95a5a6',linestyle='--',linewidth=0.8,axis='x',alpha=0.4)
27
28 plt.boxplot((city1['avgSalary'],city2['avgSalary'],city3['avgSalary'],city4['avgSalary'],city5['avgSalary'],city6['avgSalary'],city7['avgSalary'],city8['avgSalary'],city9['avgSalary'],city10['avgSalary']),labels=('北京','上海','成都','杭州','深圳','广州','武汉','长沙','南京','郑州'))
公司规模对平均薪资的影响
找工作时总是纠结于去大公司、小公司还是初创公司?
那么下面就从公司规模维度进行分析图中,清晰地看到,随着公司规模的增大,数据分析职位的工资也随之增高。高工资更多存在于公司规模大一些的公司。

1 df['companySize']=df['companySize'].map(str.strip)
2 df.groupby(['companySize']).count()
3
4 size1=df.loc[df['companySize']=='少于15人',['companySize','avgSalary']]
5 size2=df.loc[df['companySize']=='15-50人',['companySize','avgSalary']]
6 size3=df.loc[df['companySize']=='50-150人',['companySize','avgSalary']]
7 size4=df.loc[df['companySize']=='150-500人',['companySize','avgSalary']]
8 size5=df.loc[df['companySize']=='500-2000人',['companySize','avgSalary']]
9 size6=df.loc[df['companySize']=='2000人以上',['companySize','avgSalary']]
10
11 plt.rc('font', family='STXihei', size=10)
12 plt.figure(figsize=(6,4))
13 plt.xlabel('规模')
14 plt.ylabel('薪资')
15 plt.title('公司规模与平均薪资')
16 plt.boxplot((size1['avgSalary'],size2['avgSalary'],size3['avgSalary'],size4['avgSalary'],size5['avgSalary'],size6['avgSalary']),labels=('少于15人','15-50人','50-150人','150-500人','500-2000人','2000人以上'))
17 plt.grid(color='#95a5a6',linestyle='--',linewidth=0.8,axis='y',alpha=0.4)
融资规模对平均薪资的影响
从未融资到D轮融资,融资次数越多的公司工资水平也慢慢增加,也可以想到公司多次吸引到投资,资金也会较为充足,会投入更多的资金来吸引人才。但是高工资存在于上市公司和不需要融资的公司,赚多少取决于在公司的职位情况。
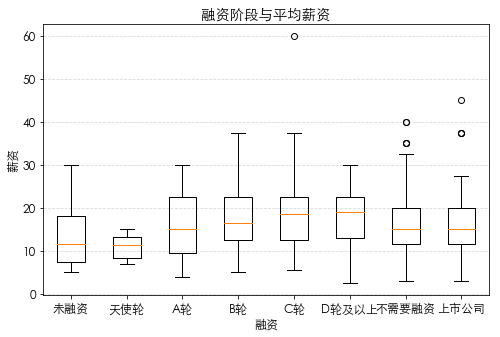
1 df['financeStage']=df['financeStage'].map(str.strip)
2
3 finance1=df.loc[df['financeStage']=='未融资',['financeStage','avgSalary']]
4 finance2=df.loc[df['financeStage']=='天使轮',['financeStage','avgSalary']]
5 finance3=df.loc[df['financeStage']=='A轮',['financeStage','avgSalary']]
6 finance4=df.loc[df['financeStage']=='B轮',['financeStage','avgSalary']]
7 finance5=df.loc[df['financeStage']=='C轮',['financeStage','avgSalary']]
8 finance6=df.loc[df['financeStage']=='D轮及以上',['financeStage','avgSalary']]
9 finance7=df.loc[df['financeStage']=='不需要融资',['financeStage','avgSalary']]
10 finance8=df.loc[df['financeStage']=='上市公司',['financeStage','avgSalary']]
11
12 plt.rc('font', family='STXihei', size=12)
13 plt.figure(figsize=(8,5))
14 plt.xlabel('融资')
15 plt.ylabel('薪资')
16 plt.title('融资阶段与平均薪资')
17 plt.grid(color='#95a5a6',linestyle='--',linewidth=0.8,axis='y',alpha=0.4)
18 plt.boxplot((finance1['avgSalary'],finance2['avgSalary'],finance3['avgSalary'],finance4['avgSalary'],finance5['avgSalary'],finance6['avgSalary'],finance7['avgSalary'],finance8['avgSalary']),labels=('未融资','天使轮','A轮','B轮','C轮','D轮及以上','不需要融资','上市公司'))
工作年限对平均薪资的影响
从工作年限来分析,工作经验的增加有助于提升工资。可以看到工作5-10年的工资极差最大。
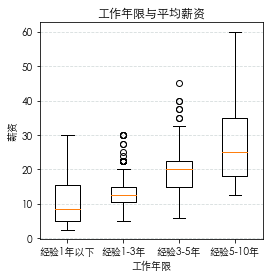
1 df['workYear']=df['workYear'].map(str.strip)
2
3 for i in range(len(df['workYear'])):
4 if df['workYear'][i] in ['经验应届毕业生','经验不限']:
5 df['workYear'][i]='经验1年以下'
6 df['workYear']=df['workYear']
7 df['workYear']
8
9 year1=df.loc[df['workYear']=='经验1年以下',['workYear','avgSalary']]
10 year2=df.loc[df['workYear']=='经验1-3年',['workYear','avgSalary']]
11 year3=df.loc[df['workYear']=='经验3-5年',['workYear','avgSalary']]
12 year4=df.loc[df['workYear']=='经验5-10年',['workYear','avgSalary']]
13
14 plt.rc('font', family='STXihei', size=10)
15 plt.figure(figsize=(4,4))
16 plt.xlabel('工作年限')
17 plt.ylabel('薪资')
18 plt.title('工作年限与平均薪资')
19 plt.grid(color='#95a5a6',linestyle='--',linewidth=0.8,axis='y',alpha=0.4)
20 plt.boxplot((year1['avgSalary'],year2['avgSalary'],year3['avgSalary'],year4['avgSalary']),labels=('经验1年以下','经验1-3年','经验3-5年','经验5-10年'))
学历对平均薪资的影响
从学历方面来说,学历的提升还是有助于工资水平的增长。可以看到本科生的薪资极差最大,即使本科学历也可以获得高薪。

1 df['education']=df['education'].map(str.strip)
2
3 edu1=df.loc[df['education']=='大专及以上',['education','avgSalary']]
4 edu2=df.loc[df['education']=='学历不限',['education','avgSalary']]
5 edu3=df.loc[df['education']=='本科及以上',['education','avgSalary']]
6 edu4=df.loc[df['education']=='硕士及以上',['education','avgSalary']]
7
8 plt.rc('font', family='STXihei', size=10)
9 plt.figure(figsize=(6,6))
10 plt.xlabel('学历')
11 plt.ylabel('薪资')
12 plt.title('学历与平均薪资')
13 plt.grid(color='#95a5a6',linestyle='--',linewidth=0.8,axis='y',alpha=0.4)
14 plt.boxplot((edu1['avgSalary'],edu2['avgSalary'],edu3['avgSalary'],edu4['avgSalary']),labels=('大专及以上','学历不限','本科及以上','硕士及以上'))
结论:
1、行业维度
需求情况:在16个细分领域中数据分析职位需求最高的是移动互联网行业,其次是金融和电子商务行业。 需求最少的是生活服务和文化娱乐行业。
薪资:可以选择社交网络、信息安全、企业服务领域,这三个领域的工资最高。
2、城市维度
需求情况:从城市维度来看,北京数据分析职位的需求量为最多,其次是上海,杭州,深圳的数量不如杭州多。
薪资:数据分析职位的工资大部分集中在8K-22K左右,整体呈左偏分布。
从城市角度来看,北京、杭州、上海的数据分析职位工资位列前三名。
3、公司规模
需求情况:从公司规模维度分析,公司规模越大对数据分析人才的需求也就越大。从结果发现少于15人的公司需求量最少。
薪资:随着公司规模的增大,数据分析职位的工资也随之增高。高工资更多存在于公司规模大一些的公司。
4、融资阶段
需求情况:可以选择融资A轮以上的公司,尤其是上市公司和不需要融资的公司,这样的公司需求量较高。
薪资:从未融资到D轮融资,融资次数越多的公司工资水平也缓慢增加。
5、工作年限
需求情况:从工作年限来看,大部分公司的需求都在1-3年和3-5年这两个阶段。
薪资:从工作年限来分析,工作经验的增加有助于提升工资。
6、学历
需求情况:从学历维度看,本科学历的数据分析人才需求量最高,占比85.3%。
薪资:从学历方面来说,学历的提升还是有助于工资水平的增长。
思考:
只是针对单一维度进行分析,练习了Python的基础使用,但是数据分析更重要的是数学、统计知识已经对业务的理解。后续会增加这方面的学习,进行更加深入的分析。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号