实现nlp文本生成中的beam search解码器
自然语言处理任务,比如caption generation(图片描述文本生成)、机器翻译中,都需要进行词或者字符序列的生成。常见于seq2seq模型或者RNNLM模型中。
这篇博文主要介绍文本生成解码过程中用的greedy search 和beam search算法实现。其中,greedy search 比较简单,着重介绍beam search算法的实现。
我们在文本生成解码时,实际上是想找对最有的文本序列,或者说是概率,可能性最大的文本序列。而要在全局搜索这个最有解空间,往往是不可能的(因为词典太大),建设生成序列长度为N,词典大小为V, 则复杂度为 V^N次方。这实际上是一个NP难题。退而求其次,我们使用启发式算法,来找到可能的最优解,或者说足够好的解。
假设序列数据(假设每个位置词的概率都已经给出):
data = [[0.1, 0.2, 0.3, 0.4, 0.5], [0.5, 0.4, 0.3, 0.2, 0.1], [0.1, 0.2, 0.3, 0.4, 0.5], [0.5, 0.4, 0.3, 0.2, 0.1], [0.1, 0.2, 0.3, 0.4, 0.5], [0.5, 0.4, 0.3, 0.2, 0.1], [0.1, 0.2, 0.3, 0.4, 0.5], [0.5, 0.4, 0.3, 0.2, 0.1], [0.1, 0.2, 0.3, 0.4, 0.5], [0.5, 0.4, 0.3, 0.2, 0.1]] data = array(data)
1、greedy search decoder
非常简单,我们用argmax就可以实现
# greedy decoder def greedy_decoder(data): # 每一行最大概率词的索引 return [argmax(s) for s in data]
完整代码
from numpy import array from numpy import argmax # greedy decoder def greedy_decoder(data): # 每一行最大概率词的索引 return [argmax(s) for s in data] # 定义一个句子,长度为10,词典大小为5 data = [[0.1, 0.2, 0.3, 0.4, 0.5], [0.5, 0.4, 0.3, 0.2, 0.1], [0.1, 0.2, 0.3, 0.4, 0.5], [0.5, 0.4, 0.3, 0.2, 0.1], [0.1, 0.2, 0.3, 0.4, 0.5], [0.5, 0.4, 0.3, 0.2, 0.1], [0.1, 0.2, 0.3, 0.4, 0.5], [0.5, 0.4, 0.3, 0.2, 0.1], [0.1, 0.2, 0.3, 0.4, 0.5], [0.5, 0.4, 0.3, 0.2, 0.1]] data = array(data) # 使用greedy search解码 result = greedy_decoder(data) print(result)
2. beam search
与greedy search不同,beam search返回多个最有可能的解码结果(具体多少个,由参数k执行)。
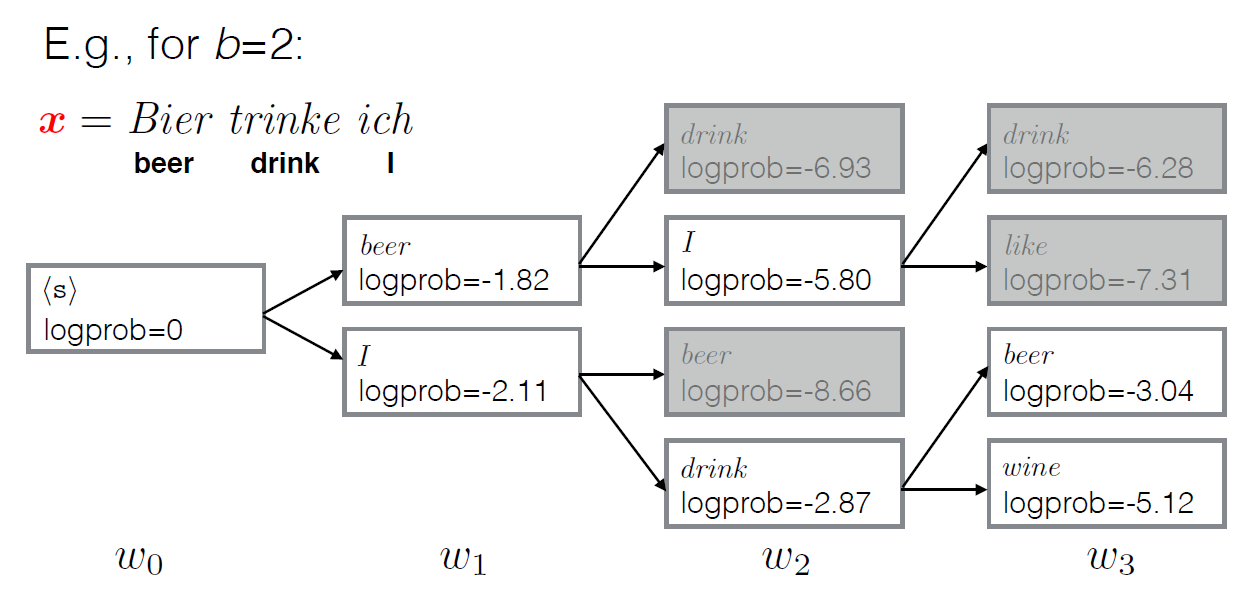
greedy search每一步都都采用最大概率的词,而beam search每一步都保留k个最有可能的结果,在每一步,基于之前的k个可能最优结果,继续搜索下一步。(参考下面示意图理解)
示例图(设置返回解码结果为2个):
from math import log from numpy import array from numpy import argmax # beam search def beam_search_decoder(data, k): sequences = [[list(), 1.0]] for row in data: all_candidates = list() for i in range(len(sequences)): seq, score = sequences[i] for j in range(len(row)): candidate = [seq + [j], score * -log(row[j])] all_candidates.append(candidate) # 所有候选根据分值排序 ordered = sorted(all_candidates, key=lambda tup:tup[1]) # 选择前k个 sequences = ordered[:k] return sequences # 定义一个句子,长度为10,词典大小为5 data = [[0.1, 0.2, 0.3, 0.4, 0.5], [0.5, 0.4, 0.3, 0.2, 0.1], [0.1, 0.2, 0.3, 0.4, 0.5], [0.5, 0.4, 0.3, 0.2, 0.1], [0.1, 0.2, 0.3, 0.4, 0.5], [0.5, 0.4, 0.3, 0.2, 0.1], [0.1, 0.2, 0.3, 0.4, 0.5], [0.5, 0.4, 0.3, 0.2, 0.1], [0.1, 0.2, 0.3, 0.4, 0.5], [0.5, 0.4, 0.3, 0.2, 0.1]] data = array(data) # 解码 result = beam_search_decoder(data, 3) # print result for seq in result: print(seq)
相关资料:
- Argmax on Wikipedia
- Numpy argmax API
- Beam search on Wikipedia
- Beam Search Strategies for Neural Machine Translation, 2017.
- Artificial Intelligence: A Modern Approach (3rd Edition), 2009.
- Neural Network Methods in Natural Language Processing, 2017.
- Handbook of Natural Language Processing and Machine Translation, 2011.
- Pharaoh: a beam search decoder for phrase-based statistical machine translation models, 2004.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号