01 2022 档案
摘要:Windows平台下IDEA+Spark本地开发环境搭建过程 1.安装Java,配置Java环境变量 2.安装Scala,配置Scala环境变量 3.安装Maven,配置Maven环境变量 4.IDEA下载与配置 5.在IDEA启动之前,安装scala插件(Configure->Plugins) 6
阅读全文
摘要:第1章 程序员都在因为什么而焦虑 1.1 最主要的来源:迷茫 解决这一问题,就在于先定好目标,再上路。路上的芝麻再多,你想想自己终点要摘的那个大西瓜,就忍住了。 1.2 一个客观的来源:技术更新 一小步一小步地往前走,也好过原地打转。 1.3 人性的弱点:攀比 1.4 不得不考虑的现实因素:生活 对
阅读全文
摘要:SparkSubmit -- main -- doSubmit // 解析参数 -- parseArguments // master => --master => yarn // mainClass => --class => SparkPi(WordCount) -- parse -- subm
阅读全文
摘要:1、https://blog.csdn.net/qq_30089191/article/details/73742425?utm_medium=distribute.pc_relevant.none-task-blog-2defaultOPENSEARCHdefault-3.control&dist
阅读全文
摘要:
阅读全文
摘要:累加器用来把Executor端变量信息聚合到Driver端。在Driver程序中定义的变量,在Executor端的每个Task都会得到这个变量的一份新的副本,每个task更新这些副本的值后,传回Driver端进行merge。
阅读全文
摘要: 
阅读全文
摘要:Spark目前支持Hash分区和Range分区,和用户自定义分区。Hash分区为当前的默认分区。分区器直接决定了RDD中分区的个数、RDD中每条数据经过Shuffle后进入哪个分区,进而决定了Reduce的个数。
阅读全文
摘要:所谓的检查点其实就是通过将RDD中间结果写入磁盘 由于血缘依赖过长会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果检查点之后有节点出现问题,可以从检查点开始重做血缘,减少了开销。 对RDD进行checkpoint操作并不会马上被执行,必须执行Action操作才能触发。 缓存和检查点区别
阅读全文
摘要:1、RDD Cache缓存 RDD通过Cache或者Persist方法将前面的计算结果缓存,默认情况下会把数据以缓存在JVM的堆内存中。但是并不是这两个方法被调用时立即缓存,而是触发后面的action算子时,该RDD将会被缓存在计算节点的内存中,并供后面重用。 缓存有可能丢失,或者存储于内存的数据由
阅读全文
摘要:RDD任务切分中间分为:Application、Job、Stage和Task Application:初始化一个SparkContext即生成一个Application; Job:一个Action算子就会生成一个Job; Stage:Stage等于宽依赖(ShuffleDependency)的
阅读全文
摘要: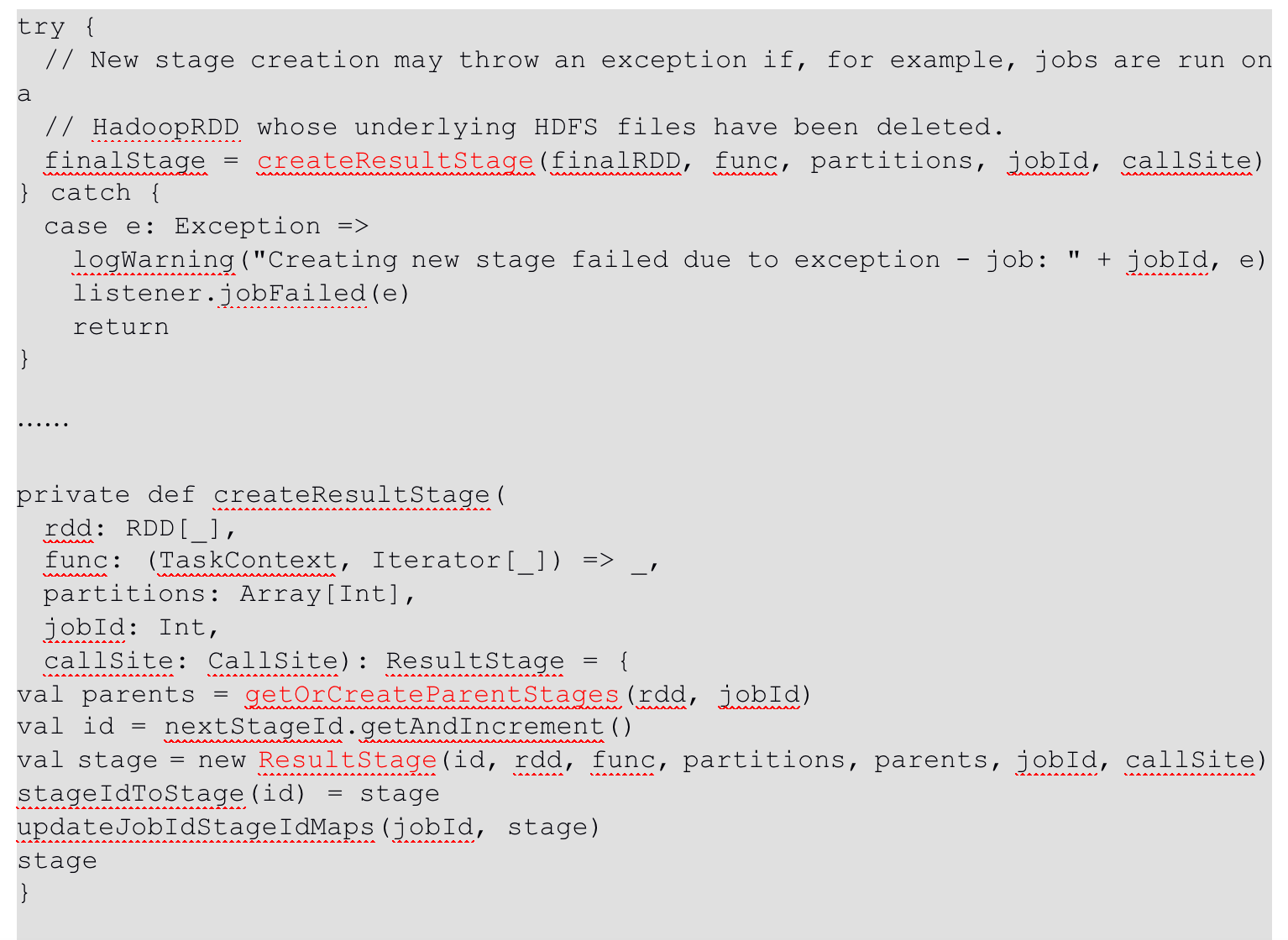 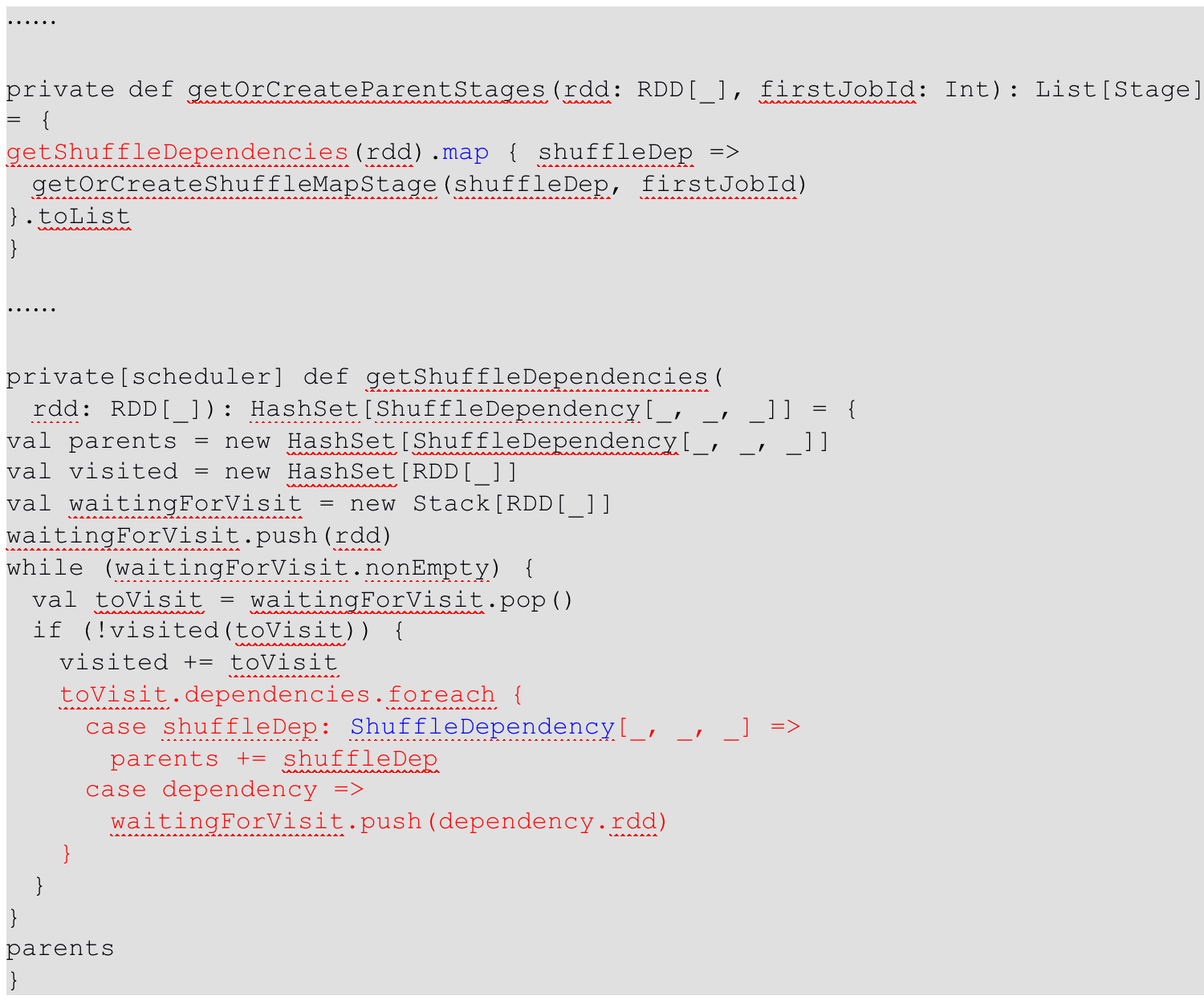
阅读全文
摘要:这里所谓的依赖关系,其实就是两个相邻RDD之间的关系 1、窄依赖表示每一个父(上游)RDD的Partition最多被子(下游)RDD的一个Partition使用,窄依赖我们形象的比喻为独生子女。 2、宽依赖表示同一个父(上游)RDD的Partition被多个子(下游)RDD的Partition依赖,
阅读全文
摘要:1.RDD只支持粗粒度转换,即在大量记录上执行的单个操作。将创建RDD的一系列Lineage(血统)记录下来,以便恢复丢失的分区。RDD的Lineage会记录RDD的元数据信息和转换行为,当该RDD的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。
阅读全文
摘要:1.从计算的角度, 算子以外的代码都是在Driver端执行, 算子里面的代码都是在Executor端执行。那么在scala的函数式编程中,就会导致算子内经常会用到算子外的数据,这样就形成了闭包的效果,如果使用的算子外的数据无法序列化,就意味着无法传值给Executor端执行,就会发生错误,所以需要在
阅读全文
 浙公网安备 33010602011771号
浙公网安备 33010602011771号