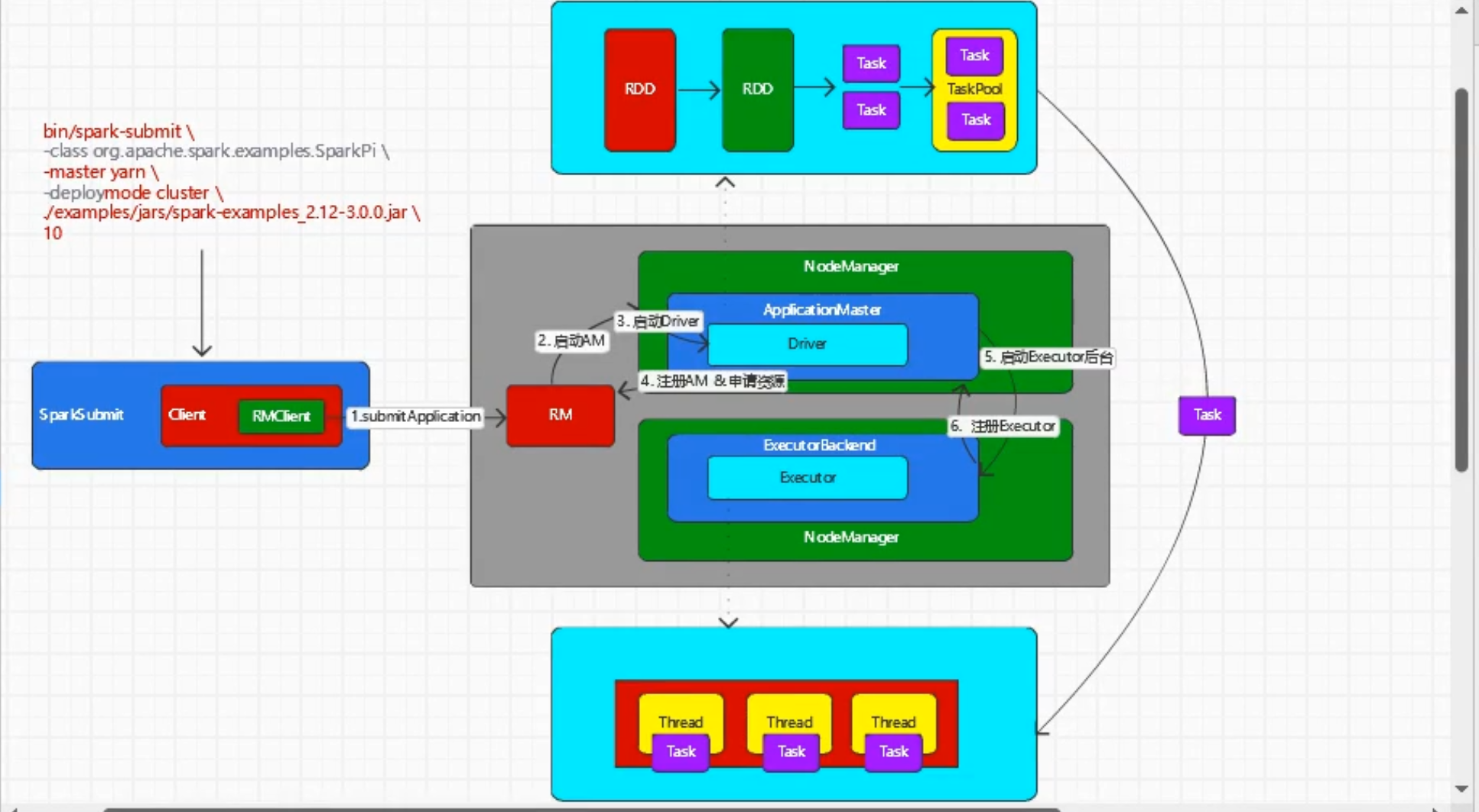
099-Spark-源码-SparkSubmit源码和任务执行流程
SparkSubmit
-- main
-- doSubmit
// 解析参数
-- parseArguments
// master => --master => yarn
// mainClass => --class => SparkPi(WordCount)
-- parse
-- submit
-- doRunMain
-- runMain
// (childArgs, childClasspath, sparkConf, childMainClass)
// 【Cluster】childMainClass => org.apache.spark.deploy.yarn.YarnClusterApplication
// 【Client 】childMainClass => SparkPi(WordCount)
-- prepareSubmitEnvironment
// Class.forName("xxxxxxx")
-- mainClass : Class = Utils.classForName(childMainClass)
// classOf[SparkApplication].isAssignableFrom(mainClass)
-- 【Cluster】a). mainClass.getConstructor().newInstance().asInstanceOf[SparkApplication]
-- 【Client 】b). new JavaMainApplication(mainClass)
-- app.start
YarnClusterApplication
-- start
// new ClientArguments
// --class => userClass => SparkPI(WordCount)
-- new Client
-- client.run
-- submitApplication
// 【Cluster】 org.apache.spark.deploy.yarn.ApplicationMaster
// 【Client 】 org.apache.spark.deploy.yarn.ExecutorLauncher
--createContainerLaunchContext
--createApplicationSubmissionContext
启动ApplicationMaster和Driver
-- main
// --class => userClass => SparkPi(WordCount)
-- new ApplicationMasterArguments
-- master = new ApplicationMaster
-- master.run()
-- 【Client 】runExecutorLauncher
-- 【Cluster】runDriver
-- userClassThread = startUserApplication()
-- ClassLoader.loadClass(args.userClass)
getMethod("main")
-- new Thread().start()
-- run
-- mainMethod.invoke(null, userArgs.toArray)
-- WordCount
-- new SparkContext() // 创建Spark的环境
-- 【blocking....................】
// Blocking -----------------------------------------
-- val sc = ThreadUtils.awaitResult
// 注册
-- registerAM
// 资源分配
-- createAllocator
-- allocator.allocateResources
-- handleAllocatedContainers
-- runAllocatedContainers
// bin/java org.apache.spark.executor.YarnCoarseGrainedExecutorBackend
-- prepareCommand
-- resumeDriver // 执行Spark作业
-- userClassThread.join()
启动ExecutorBacked,创建计算对象、任务的调度和执行
YarnCoarseGrainedExecutorBackend
-- main
-- CoarseGrainedExecutorBackend.run
-- val env = SparkEnv.createExecutorEnv
-- env.rpcEnv.setupEndpoint("Executor")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号