Hbase知识
1.海量数据存储。2.准实时查询。
上百亿行*上百亿列,实现百毫秒查询。
hbase应用于海量数据存储,只有当数据量非常大的时候,Hbase才能发挥其相应的威力。比如几百万的数据量,是完全没有必要用到Hbase的。
1、交通 2、金融 3、电商 4、移动
1、容量大
HBase单表可以有百亿行、百万列,数据矩阵横向和纵向两个纬度所支持的数据量级都非常具有弹性
2、面向列
HBase是面向列的存储和权限控制,并支持独立检索。列式存储,其数据在表中是按照某列存储的,这样在查询只需要少数几个字段的时候,能大大减少读取的数据量。
3、多版本
HBase每一个列的数据存储有多个Version
4、稀疏性
为空的列并不占用存储空间,表可以设计的非常稀疏
5、扩展性
底层依赖于HDFS
6、高可靠性
WAL机制保证了数据写入时不会因集群异常而导致写入数据丢失:Replication机制保证了在集群出现严重的问题时,数据不会发生丢失或损坏。而且HBase底层使用HDFS HDFS本身也有备份。
7、高性能
底层的LSM数据结构和Rowkey有序排列等结构上的独特设计,使得HBase具有非常高的写入性能。region切分、主键索引和缓存机制使得HBase在海量数据下具备一定的随机读取性能,该性能针对Rowkey的查询能够达到毫秒级别
官方定义:Hdoop是一个分布式的、可伸缩的大数据存储。
严格一致的读和写自动分片和可配置的分区服务器之间的表自动故障转移支持方便的基类支持Hadoop MapReduce作业与Apache HBase表易于使用Java API客户端访问块缓存和Bloom过滤器实时查询。查询谓词通过服务器端过滤器下推。Thrift gateway和一个REST-ful Web服务,支持XML、Protobuf和二进制数据编码选项Extensible JIRB -based (JIRB) she。支持通过Hadoop度量子系统将度量导出到文件或Ganglia;或通过JMX
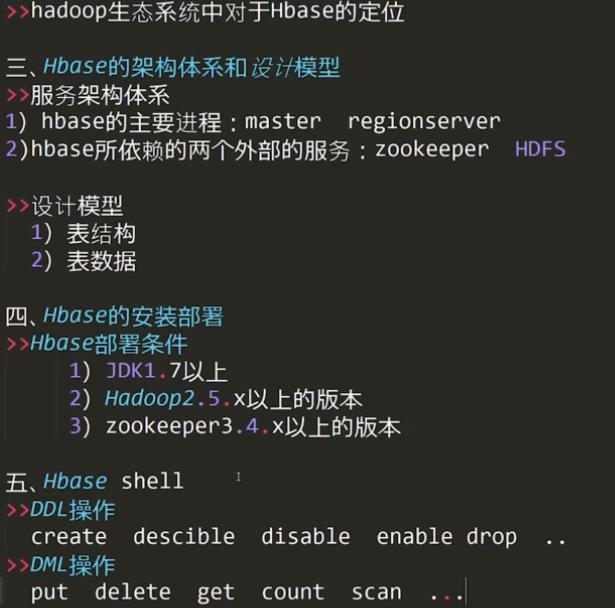
选择合适的HBase版本:
官方版本:http://archive.apache.org/dist/hbase/
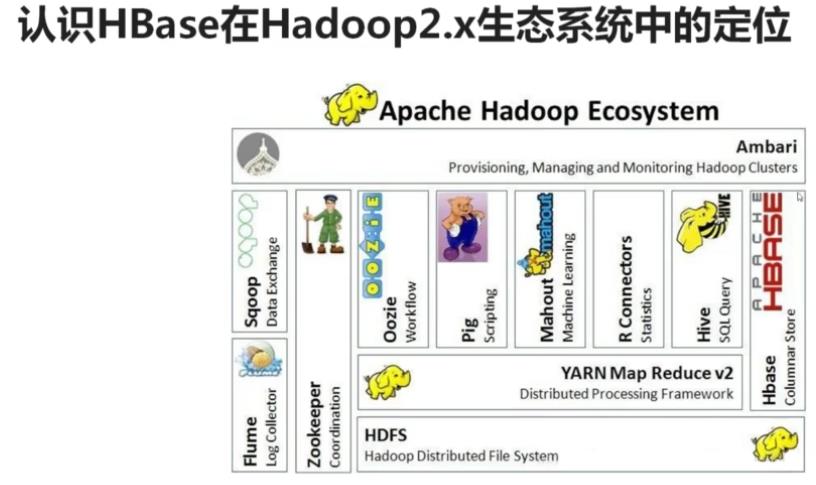
HBASE在整个HADOOP生态系统中,HBASE是唯一一个做真实的数据存储的。
Hbase基于:HDFS



 浙公网安备 33010602011771号
浙公网安备 33010602011771号