
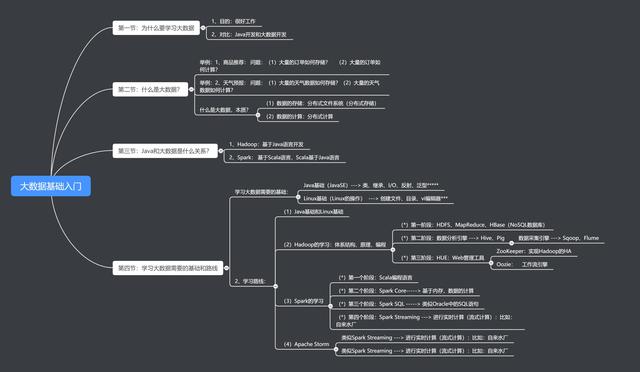
如何系统的进入大数据领域,学习路线是什么?
想要都进入大数据行业的第一步,是先搞清楚大数据究竟有哪些就业方向。
随着大数据技术在企业界如火如荼的实践,企业对组建大数据团队的迫切程度也也来越高,对与大数据相关高端人才的需求也越来越紧迫,但企业对大数据团队的组建和角色分配方面缺一直有不小的困惑,到底大数据团队里应该拥有哪些几类角色,如何设置岗位?同一类别的角色的专业方向又有哪些分化,不同专业的岗位对技能应该有哪些要求?如何管理大数据团队成员的职业发展路径?
为此,ChinaHadoop花费了一年时间调研了先进企业内部设立的大数据部门或团队的组织结构和职能划分,在此基础上,首次提出了企业大数据团队的岗位划分,专业分类及定义,以及每个岗位所需的技能及培训,技能考核对应的能力级别,我们将之统称为”企业大数据人才岗位技能认证体系“。
通过对企业大数据人才岗位进行专业细分,岗位技能认证等级与企业现有技术专业通道形成对应关系,打通员工的职业发展通道,帮助企业逐步完善大数据团队的组织结构,不断提高团队技能,为各岗位及时储备人才。
企业大数据团队的角色分类主要有三个大类别:大数据开发工程师、大数据运维工程师、大数据架构师。
总体而言,我们大数据人才划分为三个大类:
一、 大数据开发工程师:
围绕大数据系平台系统级的研发人员, 熟练Hadoop、Spark、Storm等主流大数据平台的核心框架。深入掌握如何编写MapReduce的作业及作业流的管理完成对数据的计算,并能够使用Hadoop提供的通用算法, 熟练掌握Hadoop整个生态系统的组件如: Yarn,HBase、Hive、Pig等重要组件,能够实现对平台监控、辅助运维系统的开发。
通过学习一系列面向开发者的Hadoop、Spark等大数据平台开发技术,掌握设计开发大数据系统或平台的工具和技能,能够从事分布式计算框架如Hadoop、Spark群集环境的部署、开发和管理工作,如性能改进、功能扩展、故障分析等。
二、 大数据运维工程师:
了解Hadoop、Spark、Storm等主流大数据平台的核心框架,熟悉Hadoop的核心组件:HDFS、MapReduce、Yarn;具备大数据集群环境的资源配置,如网络要求、硬件配置、系统搭建。熟悉各种大数据平台的部署方式,集群搭建,故障诊断、日常维护、性能优化,同时负责平台上的数据采集、数据清洗、数据存储,数据维护及优化。熟练使用Flume、Sqoop等工具将外部数据加载进入大数据平台,通过管理工具分配集群资源实现多用户协同使用集群资源。
三、 大数据架构师:
这一角色的要求是综合型的,对各种开源和商用的大数据系统平台和产品的特点非常熟悉,能基于Hadoop、Spark、 NoSQL、 Storm流式计算、分布式存储等主流大数据技术进行平台架构设计,负责企业选用软件产品的技术选型,具体项目中的数据库设计及实现工作,协助开发人员完成数据库部分的程序 ,能解决公司软件产品或者项目开发和运维中与数据库相关的问题; 及时解决项目开发或产品研发中的技术难题,对设计系统的最终性能和稳定性负责。
岗位能力级别定义:
1. 初级:具备基本的大数据技术的基础知识,可以将其视为大数据认证的初学或者入门等级。
2. 高级:大数据认证的高级或者熟练等级,表明该人才具备大数据某一专业方向的基本知识和熟练技能。
3. 专家:具有业界公认的专业大数据技术知识和丰富工作经验。
这里简单介绍几种我认为用的比较多的技术,因为我也仅仅是个大数据爱好者,所以有些观点可能不太标准,建议你对照着看。
一、Hadoop
可以说,hadoop几乎已经是大数据代名词。无论是是否赞成,hadoop已经是大部分企业的大数据标准。得益于Hadoop生态圈,从现在来看,还没有什么技术能够动摇hadoop的地位。
这一块可以按照一下内容来学习:
1、Hadoop产生背景 2、Hadoop在大数据、云计算中的位置和关系 3、国内外Hadoop应用案例介绍 4、国内Hadoop的就业情况分析及课程大纲介绍 5、分布式系统概述 6、Hadoop生态圈以及各组成部分的简介
二、分布式文件系统HDFS
HDFS全称 Hadoop Distributed File System ,它是一个高度容错性的系统,适合部署在廉价的机器上,同时能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。为了实现流式读取文件系统数据的目的,HDFS放宽了一部分POSIX约束。
1、分布式文件系统HDFS简介 2、HDFS的系统组成介绍 3、HDFS的组成部分详解 4、副本存放策略及路由规则 5、NameNode Federation 6、命令行接口 7、Java接口 8、客户端与HDFS的数据流讲解 9、HDFS的可用性(HA)
三、初级MapReduce
这是你成为Hadoop开发人员的基础课程。
MapReduce提供了以下的主要功能:
1)数据划分和计算任务调度:
2)数据/代码互定位:
3)系统优化:
4)出错检测和恢复:
这种编程模型主要用于大规模数据集(大于1TB)的并行运算。
1、如何理解map、reduce计算模型 2、剖析伪分布式下MapReduce作业的执行过程 3、Yarn模型 4、序列化 5、MapReduce的类型与格式 6、MapReduce开发环境搭建 7、MapReduce应用开发 8、熟悉MapReduce算法原理
四、高级MapReduce
这一块主要是高级Hadoop开发的技能,都是MapReduce为什么我要分开写呢?因为我真的不觉得谁能直接上手就把MapReduce搞得清清楚楚。
1、使用压缩分隔减少输入规模 2、利用Combiner减少中间数据 3、编写Partitioner优化负载均衡 4、如何自定义排序规则 5、如何自定义分组规则 6、MapReduce优化
五、Hadoop集群与管理
这里会涉及到一些比较高级的数据库管理知识,乍看之下都是操作性的内容,但是做成容易,做好非常难。
1、Hadoop集群的搭建 2、Hadoop集群的监控 3、Hadoop集群的管理 4、集群下运行MapReduce程序
六、ZooKeeper基础知识
ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
1、ZooKeeper体现结构 2、ZooKeeper集群的安装 3、操作ZooKeeper
七、HBase基础知识
HBase – Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。
与FUJITSU Cliq等商用大数据产品不同,HBase是Google Bigtable的开源实现,类似Google Bigtable利用GFS作为其文件存储系统,HBase利用Hadoop HDFS作为其文件存储系统;Google运行MapReduce来处理Bigtable中的海量数据,HBase同样利用Hadoop MapReduce来处理HBase中的海量数据;Google Bigtable利用 Chubby作为协同服务,HBase利用Zookeeper作为对应。
1、HBase定义 2、HBase与RDBMS的对比 3、数据模型 4、系统架构 5、HBase上的MapReduce 6、表的设计
八、HBase集群及其管理
1、集群的搭建过程 2、集群的监控 3、集群的管理
十、Pig基础知识
Pig是进行Hadoop计算的另一种框架,是一个高级过程语言,适合于使用 Hadoop 和 MapReduce 平台来查询大型半结构化数据集。通过允许对分布式数据集进行类似 SQL 的查询,Pig 可以简化 Hadoop 的使用。
1、Pig概述 2、安装Pig 3、使用Pig完成手机流量统计业务
十一、Hive
hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用。
1、数据仓库基础知识 2、Hive定义 3、Hive体系结构简介 4、Hive集群 5、客户端简介 6、HiveQL定义 7、HiveQL与SQL的比较 8、数据类型 9、表与表分区概念 10、表的操作与CLI客户端 11、数据导入与CLI客户端 12、查询数据与CLI客户端 13、数据的连接与CLI客户端 14、用户自定义函数(UDF)
十二、Sqoop
Sqoop(发音:skup)是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql...)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
1、配置Sqoop 2、使用Sqoop把数据从MySQL导入到HDFS中 3、使用Sqoop把数据从HDFS导出到MySQL中
十三、Storm
Storm为分布式实时计算提供了一组通用原语,可被用于“流处理”之中,实时处理消息并更新数据库。这是管理队列及工作者集群的另一种方式。 Storm也可被用于“连续计算”(continuous computation),对数据流做连续查询,在计算时就将结果以流的形式输出给用户。它还可被用于“分布式RPC”,以并行的方式运行昂贵的运算。
1、Storm基础知识:包括Storm的基本概念和Storm应用 场景,体系结构与基本原理,Storm和Hadoop的对比 2、Storm集群搭建:详细讲述Storm集群的安装和安装时常见问题 3、Storm组件介绍: spout、bolt、stream groupings等 4、Storm消息可靠性:消息失败的重发 5、Hadoop 2.0和Storm的整合:Storm on YARN 6、Storm编程实战
虽然写了这么多,但是仍然知识大数据的知识海洋的一角,希望题主加油!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号