

如何用python做一个exe程序快速爬取文章?
我用了99藏书网作为例子
注:本程序主要用于快速复制99藏书网中的小说,有些参数我要在开头先解释清楚

一、导入库
import tkinter as tk from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.common.action_chains import ActionChains from selenium.webdriver.common.keys import Keys from selenium.webdriver.chrome.options import Options
二、做一个背景函数
这个背景函数主要是用于GUI可视化背景的设置
def set_background_image(window, image_path): # 创建一个PhotoImage对象 background_image = tk.PhotoImage(file=image_path) # 将PhotoImage对象设置为窗口的背景 background_label = tk.Label(window, image=background_image) background_label.place(x=0, y=0, relwidth=1, relheight=1) # 保存PhotoImage对象到窗口属性中,避免被垃圾回收 window.background = background_image
三、做GUI主页面
app = tk.Tk() app.title("九九藏书网") app.geometry('1920x1080') set_background_image(app,"哆唻A梦.png") # 添加一个Text组件用于显示爬取的内容 text = tk.Text(app, width=50, height=40, font=('Arial', 12), wrap=tk.WORD) text.place(x=10, y=10) lb = tk.Label(app, text='欢迎来到“九九藏书网”书籍采集获取系统', width=40, height=1, fg='black', font=('Arial', 18)) lb.pack() bt = tk.Button(app, text="开始", width=10, command=main, activebackground='red') bt.pack() app.mainloop()
四、做GUI次级界面
def main(): input_window = tk.Toplevel(app) input_window.geometry(app.geometry()) set_background_image(input_window, "哆唻A梦.png") lb1 = tk.Label(input_window, text='请输入书本号', width=40, height=10, fg='black', font=8) lb1.place(x=1, y=1) entry1 = tk.Entry(input_window) entry1.place(x=130, y=220) lb2 = tk.Label(input_window, text='请输入前言的章节号', width=40, height=10, fg='black', font=8) lb2.place(x=1, y=250) entry2 = tk.Entry(input_window) entry2.place(x=130, y=470) lb3 = tk.Label(input_window, text='请输入最后一个章节的章节号', width=40, height=10, fg='black', font=8) lb3.place(x=1, y=500) entry3 = tk.Entry(input_window) entry3.place(x=130, y=720) confirm_button = tk.Button(input_window, text="确认", command=lambda: process_input1(entry1.get(), entry2.get(), entry3.get())) confirm_button.place(x=180, y=750)
五、写一个爬虫函数
先找到存储正文的模块
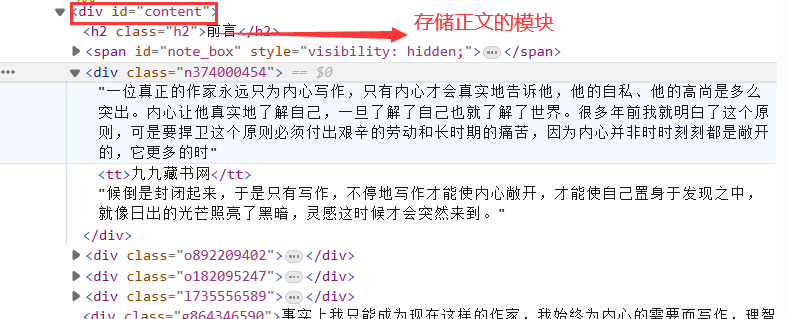
def process_input1(a, b, c): passage = 0 start_chapter = int(b) end_chapter = int(c) for i in range(start_chapter, end_chapter + 1): driver = webdriver.Chrome() url = f'https://www.99csw.com/book/{a}/{i}.htm' driver.get(url) content_element = driver.find_element(By.XPATH, '//div[@id="content"]') content = content_element.text print(content) text.insert(tk.END, content + '\n') filename = f"./活着第{i}章.txt" if passage == 0: with open('./活着前言.txt', "w", encoding='utf-8') as f: f.write(content) passage += 1 continue else: with open(filename, "w", encoding="utf-8") as f: f.write(content) continue
六、完整代码
import tkinter as tk from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.common.action_chains import ActionChains from selenium.webdriver.common.keys import Keys from selenium.webdriver.chrome.options import Options # 一个背景函数 def set_background_image(window, image_path): # 创建一个PhotoImage对象 background_image = tk.PhotoImage(file=image_path) # 将PhotoImage对象设置为窗口的背景 background_label = tk.Label(window, image=background_image) background_label.place(x=0, y=0, relwidth=1, relheight=1) # 保存PhotoImage对象到窗口属性中,避免被垃圾回收 window.background = background_image def main(): input_window = tk.Toplevel(app) input_window.geometry(app.geometry()) set_background_image(input_window, "哆唻A梦.png") lb1 = tk.Label(input_window, text='请输入书本号', width=40, height=10, fg='black', font=8) lb1.place(x=1, y=1) entry1 = tk.Entry(input_window) entry1.place(x=130, y=220) lb2 = tk.Label(input_window, text='请输入前言的章节号', width=40, height=10, fg='black', font=8) lb2.place(x=1, y=250) entry2 = tk.Entry(input_window) entry2.place(x=130, y=470) lb3 = tk.Label(input_window, text='请输入最后一个章节的章节号', width=40, height=10, fg='black', font=8) lb3.place(x=1, y=500) entry3 = tk.Entry(input_window) entry3.place(x=130, y=720) confirm_button = tk.Button(input_window, text="确认", command=lambda: process_input1(entry1.get(), entry2.get(), entry3.get())) confirm_button.place(x=180, y=750) def process_input1(a, b, c): passage = 0 start_chapter = int(b) end_chapter = int(c) for i in range(start_chapter, end_chapter + 1): driver = webdriver.Chrome() url = f'https://www.99csw.com/book/{a}/{i}.htm' driver.get(url) content_element = driver.find_element(By.XPATH, '//div[@id="content"]') content = content_element.text print(content) text.insert(tk.END, content + '\n') filename = f"./活着第{i}章.txt" if passage == 0: with open('./活着前言.txt', "w", encoding='utf-8') as f: f.write(content) passage += 1 continue else: with open(filename, "w", encoding="utf-8") as f: f.write(content) continue app = tk.Tk() app.title("九九藏书网") app.geometry('1920x1080') set_background_image(app,"哆唻A梦.png") # 添加一个Text组件用于显示爬取的内容 text = tk.Text(app, width=50, height=40, font=('Arial', 12), wrap=tk.WORD) text.place(x=10, y=10) lb = tk.Label(app, text='欢迎来到“九九藏书网”书籍采集获取系统', width=40, height=1, fg='black', font=('Arial', 18)) lb.pack() bt = tk.Button(app, text="开始", width=10, command=main, activebackground='red') bt.pack() app.mainloop()
七、打包python程序
1、下载打包python程序用的pyinstaller
在终端输入
pip install pyinstaller
2、打包python程序
pyinstall -F python文件名
这时候就生成了一个exe文件
3、找到exe文件位置,点击即可运行程序(如果运行不成功,检查exe文件包里面是否含有python程序中用到的一些图片字体等文件,若没有,自行加入)
现在给大家看一下运行结果

爬取的内容存储在了左侧text框中

