
Windows 环境搭建 PostgreSQL 物理复制高可用架构数据库服务
PostgreSQL 高可用数据库的常见搭建方式主要有两种,逻辑复制和物理复制,上周已经写过了关于在Windows环境搭建PostgreSQL逻辑复制的教程,这周来记录一下 物理复制的搭建方法。
首先介绍一下逻辑复制和物理复制的一些基本区别:
- 物理复制要求多个实例之间大版本一致,并且操作系统平台一致,如主实例是 Windows环境下的 PostgreSQL15 则 从实例也必须是这个环境和版本,逻辑复制则没有要求。
- 物理复制是直接传递 WAL归档 文件,在从实例进行重放执行,可以理解为实时的 WAL归档恢复,所以延迟低,性能高。,
- 逻辑复制可以简单理解为解析了WAL归档文件中的信息,处理成为 标准的SQL语句,传递给存库进行执行,相对于直接传递WAL性能较低,延迟高。
- 物理复制不需要像逻辑复制一些去手动的建立数据库,数据表,因为物理复制是直接恢复WAL所以包含了DDL操作,逻辑复制则需要自己进行DDL操作。
- 逻辑复制更加灵活,可以自己指定需要复制的库,从实例,还可以建立其他库用于其他业务,而物理复制则是面向整个实例进行的,从实例和主实例100%一致最多只能进行只读操作。
关于 Windows 系统 PostgreSQL 的安装方法可以直接看之前的博客 Windows 系统 PostgreSQL 手工安装配置方法
如果追求高性能,高一致性的数据库复制备份方案建议采用物理复制的方式。
搭建物理复制模式的主从订阅首先要调整主实例的 postgresql.conf 文件
wal_level = replica
synchronous_commit = remote_apply

因为我们采用的 synchronous_commit = remote_apply 是同步复制的模式,该模式可以理解为同步复制,当客户端像主实例提交事务之后,需要等 synchronous_standby_names 总配置的节点全部完成 remote_apply 收到数据之后,主实例才会给备库返回事务成功提交的状态,创建好名为 s 的订阅创建之后,我们再次打开 主实例的 postgresql.conf 文件进行调整设置
synchronous_standby_names = 's'

当有多个从实例从主实例同步的时候synchronous_standby_names 还可以采用以下配置模式
- synchronous_standby_names='s1' 代表s1备机返回就可以提交。
- synchronous_standby_names='FIRST 2 (s1,s2,s3)' 代表s1,s2,s3三个备机中前两个s1和s2返回主实例就可以提交。
- synchronous_standby_names='ANY 2 (s1,s2,s3)' 代表s1,s2,s3三个备机中任意两个备机返回主实例就可以提交。
- synchronous_standby_names='ANY 2 (*)' 代表所有备机中任意两个备机返回主实例就可以提交。
- synchronous_standby_names='*' 代表匹配任意主机,也就是任意主机返回就可以提交。
这里有一点需要注意,这是 PostgreSQL 在同步复制时的一个已知问题,假设 一个主实例,一个备库 s1,采用同步模式,然后 synchronous_standby_names 配置为 synchronous_standby_names='s1',虽然从配置上来看似乎数据必须要提交到s1并且s1成功响应之后,主实例才会为客户端返回事务操作成功的响应,但是实际情况下,当备库挂掉的情况下,主实例在收到一个事务操作时,在等待 s1 备库的返回时因为 s1库已经挂掉了所以这个操作肯定会超时,当主备节点通信超时之后,主节点还是会像客户端返回事务成功提交的命令,客户端的操作还是会成功,同时因为每个事务操作都要经历这个超时的流程,所以客户端的所有事务操作都会相对很卡。
比如每个 insert 都会经过主实例和备库的这个通信超时过程,所以每个 insert 动作都变成了大约30秒次才能完成,就会导致应用程序很卡。这时候就相当于主实例在以(很卡的)独立模式运行,这个情况在备库重新上线之后就会恢复正常(如果备库短期之内无法恢复,可以调整主实例的 synchronous_standby_names设置 移除对于s1备库的事务等待验证,变为单库运行模式重启实例之后也就不会卡了),但是要注意当主实例脱离备库独立运行时,如果这个时候主实例发生灾难比如硬盘坏掉,则就会产生数据丢失。所以建议至少有2个从实例来提升保障级别。
然后还需要调整主实例的 pg_hba.conf,添加 replication 模式的连接白名单配置。
host replication all 0.0.0.0/0 scram-sha-256
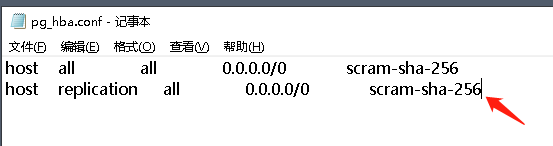
调整配置文件之后记得重启主实例。
主实例重启之后,我们还需要连接到主实例创建复制槽,默认情况下WAL归档文件是循环滚动清理,这就会导致一个问题如果我们的从实例挂机之后离线的时间较长,就有可能因为主实例的WAL文件已经循环滚动删除了,这种情况下就算从实例修复好之后重新上线,因为主实例的部分WAL归档文件已经清理了,也无法再追赶上我们主实例的数据进度,从实例会直接报错。因为有这种场景的存在所以 PostgreSQL 里面出现了一个复制槽的概念,主实例可以创建多个复制槽,一个复制槽绑定给一个从实例使用,复制槽的好处在于会确保从实例获取到WAL文件之后才会进行清理,不会有前面说的滚动循环自动清理的问题。
复制槽的维护都在主实例进行:创建,查询,删除的语句如下
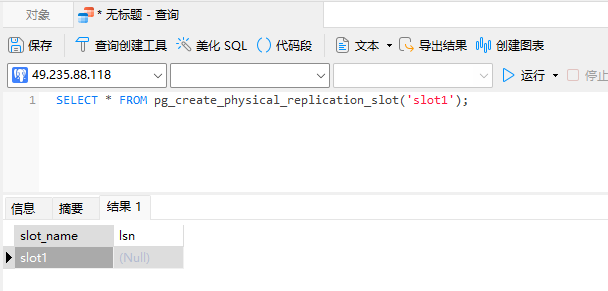
创建复制槽
SELECT * FROM pg_create_physical_replication_slot('slot1');
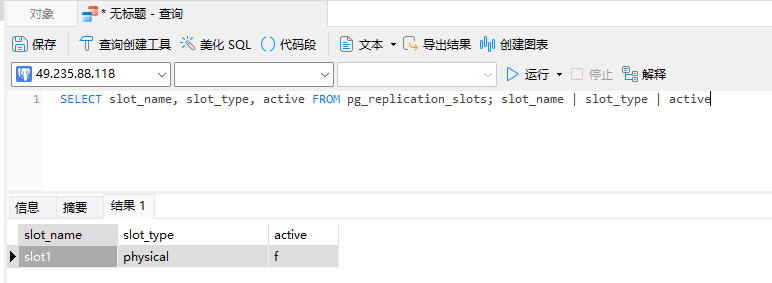
查询全部的复制槽
SELECT slot_name, slot_type, active FROM pg_replication_slots; slot_name | slot_type | active
删除复制槽
SELECT * FROM pg_drop_replication_slot('slot1')
至此主实例的配置就都完成了,接下来就是准备我们的从实例,可以直接停止主实例的运行,然后把PostgreSQL文件夹和Data整体打包压缩复制一份到新的服务器上启动起来作为从实例。
我这里选择直接把云服务器上的 PostgreSQL 打包压缩然后复制到本地解压,作为从实例
在本地解压之后,做为 从实例 需要做如下的调整,postgresql.conf
primary_conninfo = 'host=x.x.x.x port=5432 user=postgres password=xxxxxx application_name=s'
primary_slot_name = 'slot1'
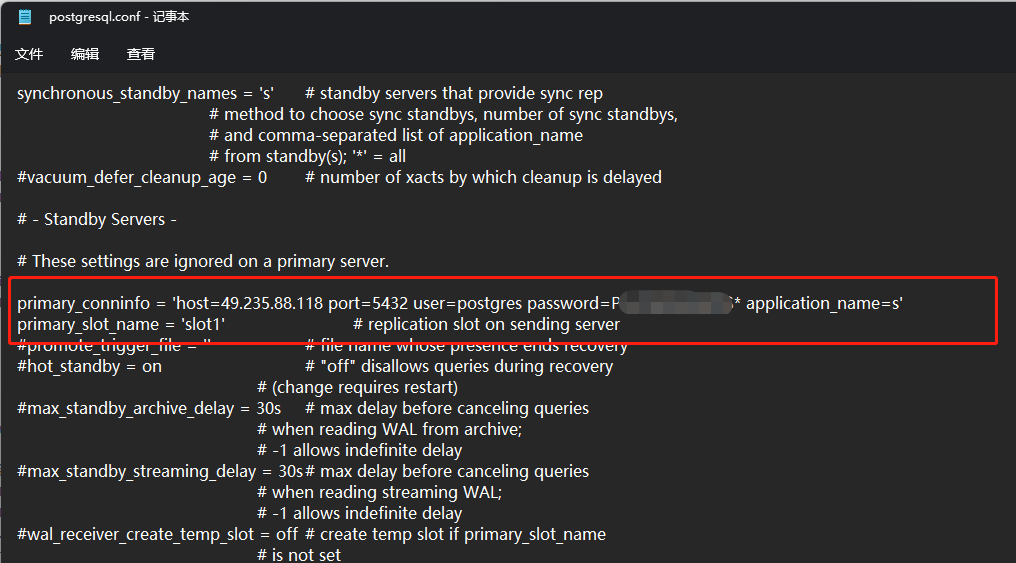
primary_conninfo 主要内容就是我们主实例的连接字符串信息然后加一个 application_name ,application_name 和我们前面在主实例上配置的 synchronous_standby_names 关联,前面我们配置了主实例的所有事务操作都需要同步等待 名字为 s 的备库执行完成
primary_slot_name 则是复制槽的名称我们前面创建了一个 slot1 的复制槽,给我们的这个从实例使用。
这里需要注意一点,在配置的时候如果有多个从实例,则一个从实例对应一个复制槽,绑定一个 application_name。
然后在 data 目录下新建一个空文件
standby.signal
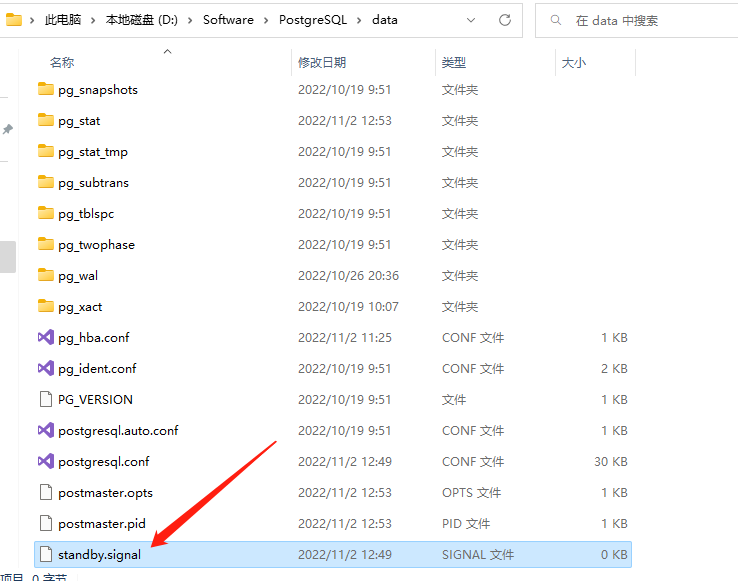
这个文件的其实一个信号标记,标识我们当前的实例时一个只读实例,不可以用于数据插入。
然后启动备库就可以了,正常情况会看到如下界面
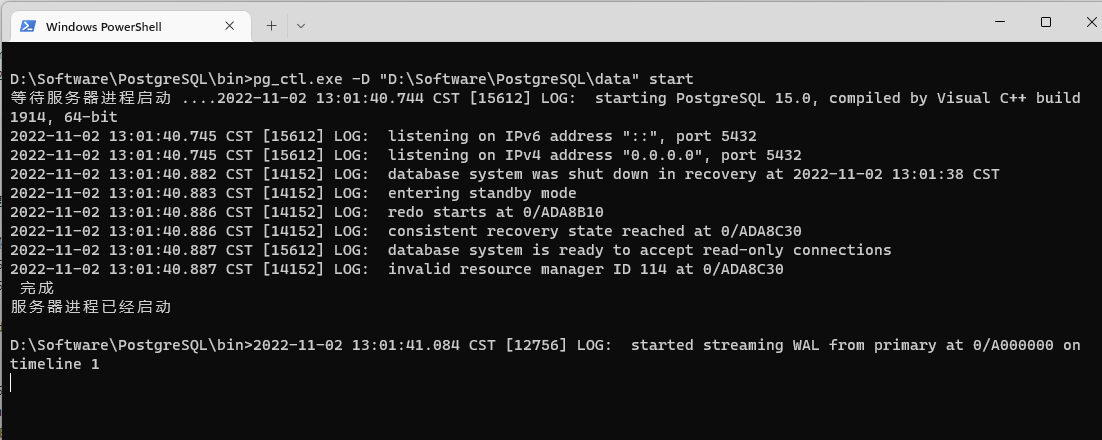
这时候我们可以尝试去主实例创建一个数据库做一些操作,然后连接从实例,就会发现两边都是互相同步的。
如果要解除从实例和主实例的关联,操作如下:
从主实例的 postgresql.conf 找到 synchronous_standby_names 删除 s 节点的配置
#synchronous_standby_names='s'
如果只有一个从节点的,则直接添加 # 对 synchronous_standby_names 进行注释即可
调整之后重启主实例。
然后打开从实例的 postgresql.conf,注释
#primary_conninfo
#primary_slot_name
配置节点的信息,然后删除 data 目录下的 standby.signal 文件,重新启动从实例即可。
至此 Windows 环境搭建 PostgreSQL 物理复制高可用架构数据库服务 就讲解完了,有任何不明白的,可以在文章下面评论或者私信我,欢迎大家积极的讨论交流,有兴趣的朋友可以关注我目前在维护的一个 .NET 基础框架项目,项目地址如下
https://github.com/dashiell-zhang/NetEngine.git


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异
· 三行代码完成国际化适配,妙~啊~