
hadoop2.6虚拟机搭建和应用到win平台下eclipse开发
历程是艰辛,无脑的苦力活~
首先我的平台是搭建在cenos7虚拟机上的,使用hadoop2.6,部署计划:
| 主机 | 角色 |
| namenode1:192.168.80.101 | namenode,resourcemanager |
| datanode1:192.168.80.102 | datanode,nodemanager |
| datanode2:192.168.80.103 | datanode,nodemanager |
0.需要 hadoop2.6 ,jdk1.7,hadoop-eclipse-plugin-2.6.0.jar,出错时候用的一些文件
1.关于虚拟机的网络设置,使用nat模式:文件/etc/sysconfig/network-scripts/ifcfg-eno*
lo网卡设置关掉,把 ONBOOT=yes 改成 no即可
TYPE=Ethernet
HWADDR=00:0C:29:9E:66:9c
#BOOTPROTO=dhcp
BOOTPROTO=static
DEFROUTE=yes
PEERDNS=yes
PEERROUTES=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_PEERDNS=yes
IPV6_PEERROUTES=yes
IPV6_FAILURE_FATAL=no
NAME=eno16777736
UUID=98f69bcb-c555-40a4-ac50-d6cf6a2fab73
DEVICE=eno16777736
#ONBOOT=no
ONBOOT=yes
IPADDR0=192.168.80.101
PREFIX0=24
GATEWAY0=192.168.80.1
sudo service network restart
2.关于SSH免密登录,可参考其他资料,或上一个随笔。其实免密登录不是搭建hadoop平台必须的,只是可以方便开启结点
3.jdk的配置也很简单,解压后,写入配置文件路径 sudo vi /etc/profile
(export JAVA_HOME=
export PATH=$PATH:$JAVA_HOME)
更新 source vi /etc/profile
成功后,在命令台输入 java运行成功即可。
4. 配置hadoop
4.1把hadoop路径写入系统文件
4.2改配置文件 hadoop_home\etc\hadoop\core-site.xml
关于缓存文件的dir需要事先创建出来,
要记好 这里的hdfs端口号,
<property> <name>fs.defaultFS</name> <value>hdfs://namenode1:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/boy/hadoop/hadoop-2.6.0/tem</value> </property> <property> <name>hadoop.proxyuser.root.hosts</name> <value>namenode1</value> </property> <property> <name>hadoop.proxyuser.root.groups</name> <value>*</value> </property>
前提:在所有机器上主机和网址的映射都有,文件 /etc/hosts
127.0.0.1 localhost www # localhost.localdomain localhost4 localhost4.localdomain4
#::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.80.101 namenode1
192.168.80.102 datanode1
192.168.80.103 datanode2
配置文件 应该根据自己的平台做相应变化,关于解释,请查阅其他的。网上有很多资料
4.3配置文件 hdfs-site.xml
<property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> <property> <name>dfs.name.dir</name> <value>/home/boy/hadoop/hadoop-2.6.0/tem/name1</value> #hadoop的name目录路径 <description> </description> </property> <property> <name>dfs.data.dir</name> <value>/home/boy/hadoop/hadoop-2.6.0/tem/data1</value> <description> </description> </property>
dfs.replication:数据副本个数,在该集群中是有两个数据节点,默认是3个,个数不能多于数据节点个数
dfs.permissions:是否验证访问者权限
后面两个是数据文件存放的位置,可以不用事先创建
4.4yarn-site.xml
这里的 resourcemanager端口号 8032也很重要,后面eclipse会用到
端口8088是hadoop marreduce的web访问端口
<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>namenode1:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>namenode1:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>namenode1:8031</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>namenode1:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>namenode1:8088</value> </property>
4.5mapred-sit.xml
<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobtracker.http.address</name> <value>namenode1:50030</value> </property> <property><name>mapreduce.jobhistory.address</name><value>namenode1:10020</value> </property> <property><name>mapreduce.jobhistory.webapp.address</name><value>namenode1:19888</value> </property> <property><name>mapreduce.jobhistory.intermediate-done-dir</name><value>/mr-history/tmp</value> </property> <property><name>mapreduce.jobhistory.done-dir</name><value>/mr-history/done</value> </property>
4.6 修改hadoop-env.sh文件 中的java_home,为机器的java_home
4.7到这里配置完成,把所有配置文件发送或拷贝到其他主机,一定要一样,不一样的话 mast节点会报错,或者数据节点会启动不起来,但是如果是数据节点报错,报错信息可以通过控制台看到日志文件的位置,可以查看异常。
4.8 在主节点 格式化节点 进入hadoop安装目录,执行:bin/hdfs namenode -format 格式化节点
如果配置文件出错,窗口会提示,大多为配置文件错误,如果有其他错误,可查阅其他资料。
最后提示格式化成功,然后再节点执行:
mast:
sbin/hadoop-deamon.sh start namenode
sbin/yarn-deamon.sh start resourcemanager
slave:
sbin/hadoop-deamon.sh start datanode
sbin/yarn-deamon.sh start nodemanager
hadoop2.X引入了yarn,将原来的job和task从资源管理中脱离出来,减轻集群负担。分为资源管理和任务管理,也就是resourcemanager管理nodemanager,通过任务管理进程applicationmaster
成功启动个节点后,使用jps命令查看当前节点状态
master:
ResourceManager
Jps
Namenode
slave:
NodeManager
Jps
DataNode
在主节点,运行:bin/hadoop dfsadmin -report
可以查看个节点状态
另外启动成功并不代表可以执行程序:
在集群中创建目录:bin/hdfs dfs -mkdir /user/boy/input(路径随意,我的用户是boy所以这样用,主意这里和本机没有关系)
将本机文件上传到HDFS:bin/hdfs dfs -put s.txt /user/boy/input (本地文件可以是相对路径或绝对路径)
感想:其实搭建过程很简单,hadoop的配置文件不能搞错,这些也都是繁琐工作。由于不了解配置文件具体的哪个属性的用途,我走了很多弯路。学知识和技术不能太着急。多尝试,如果时间允许的话
5.连接eclipse
网上有很多教程连接eclipse的,但是很多介绍不明确。首先我先提出想法:
编写HDFS存储操作程序或MapReduce程序,在win平台下使用eclipse执行,远程连接虚拟机中的hadoop集群,实现分布式程序开发。
eclipse连接虚拟机中的hadoop需要插件,网上介绍很多插件编译方法,我虽然尽量避开这些繁琐的地方,试过hadoop2.5,最终是在朋友帮助下使用了hadoop2.6,因为朋友有插件包等一些必须文件。不过我最终使用的还是自己用ant自己编译的,编译过程不难,出现卡住的错误,可以在网上查资料找到解决方法,本文也给出查到的解决方法。
5.1插件准备 hadoop-eclipse-plugin-2.6.0.jar
5.2放到eclipse安装目录的plugin插件文件夹中,重启eclipse,如果没有反应,试一下清理缓存,命令行中 放入eclipse.exe 后面跟 -clean 启动,我就是这里在eclipse window-preference 怎么不出来hadoop配置的相关
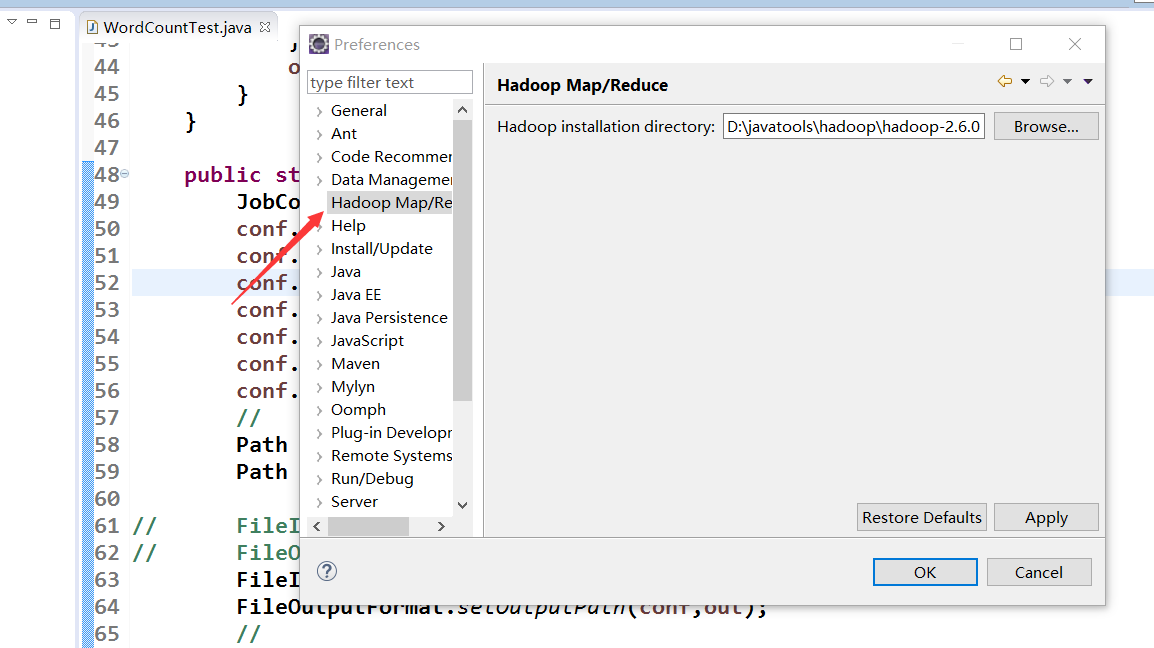
5.3 win平台也需要hadoop,把虚拟机中的配置好的hadoop 压缩拷贝出来,解压到win平台中,在系统环境变量中配置hadoop_home,加入到path中。然后配置到上图中的hadoop 文件路径中。
eclipse下面状态栏中会有小象的窗口,在这里建立与虚拟机hadoop的链接,右键 Location 出现编辑 新建 删除,选择新建
配置远程的 hadoop mast机地址,还有mapreduce端口号,和HDFS端口号,即 resourcemanager端口号8032和defalueFS端口号9000,用户名处写hadoop中的用户名
在扩展参数advance parameters 选项框中,可以不管,有很多运行的历史文件存到本地,不方便一一介绍,日后可以统一修改
5.4下面终于可以 开始编程了,创建mapreduce程序,默认eclipse会导进来很多包,需要去重,我去重后还有108个包,百度编写wordcount程序吧。
package shmtu.hadoop.test; import java.io.IOException; import java.util.Iterator; import java.util.StringTokenizer; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapred.FileInputFormat; import org.apache.hadoop.mapred.FileOutputFormat; import org.apache.hadoop.mapred.JobClient; import org.apache.hadoop.mapred.JobConf; import org.apache.hadoop.mapred.MapReduceBase; import org.apache.hadoop.mapred.Mapper; import org.apache.hadoop.mapred.OutputCollector; import org.apache.hadoop.mapred.Reducer; import org.apache.hadoop.mapred.Reporter; import org.apache.hadoop.mapred.TextInputFormat; import org.apache.hadoop.mapred.TextOutputFormat; public class WordCountTest { public static class MyMap extends MapReduceBase implements Mapper<LongWritable,Text,Text,IntWritable>{ private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(LongWritable key,Text value,OutputCollector<Text,IntWritable> output,Reporter repoter) throws IOException{ String line = value.toString(); StringTokenizer tokenizer = new StringTokenizer(line); while(tokenizer.hasMoreTokens()){ word.set(tokenizer.nextToken()); output.collect(word, one); } } } public static class MyReduce extends MapReduceBase implements Reducer<Text,IntWritable,Text,IntWritable>{ public void reduce(Text key,Iterator<IntWritable> values,OutputCollector<Text,IntWritable> output,Reporter reporter) throws IOException{ int sum = 0; while(values.hasNext()){ sum += values.next().get(); } output.collect(key, new IntWritable(sum)); } } public static void main(String[]args) throws Exception{ JobConf conf = new JobConf(WordCountTest.class); conf.setJobName("wordcount"); conf.setOutputKeyClass(Text.class); conf.setOutputValueClass(IntWritable.class); conf.setMapperClass(MyMap.class); conf.setReducerClass(MyReduce.class); conf.setInputFormat(TextInputFormat.class); conf.setOutputFormat(TextOutputFormat.class); // Path in = new Path("hdfs://192.168.80.101:9000/user/boy/input"); Path out = new Path("hdfs://192.168.80.101:9000/user/boy/output2"); // FileInputFormat.setInputPaths(conf,new Path(args[0])); // FileOutputFormat.setOutputPath(conf,new Path(args[1])); FileInputFormat.setInputPaths(conf,in); FileOutputFormat.setOutputPath(conf,out); // JobClient.runJob(conf); } }
5.5 运行过程中 会出现各种奇怪错误,就是这么周折:
http://my.oschina.net/muou/blog/408543#OSC_h2_9
--------------------
http://www.tuicool.com/articles/qY7F3q
命令行在ivy-resolve-common处卡了
原因是找不到几个依赖包,那几个依赖包可能是换路径了,其实不需要这几个依赖包也可以
解决方案:
修改"H2EP_HOME"\src\contrib\eclipse-plugin\build.xml
找到:
<target name="compile" depends="init, ivy-retrieve-common" unless="skip.contrib">
去掉depends修改为
<target name="compile" unless="skip.contrib">
-------------------
插件包没反应
http://www.aboutyun.com/thread-11288-1-1.html
是其他的,已经做好了,解决办法是: 启动eclipse的时候清理一下缓存。 eclipse.exe -clean。 就可以解决我那个插件不存在的问题。谢谢。哥们。
---------------------------------------
问题一.An internal error occurred during: "Map/Reducelocation status updater".java.lang.NullPointerException
我们hadoop-eclipse-plugin-2.6.0.jar放到Eclipse的plugins目录下,我们的Eclipse目录是F:\tool\eclipse-jee-juno-SR2\eclipse-jee-juno-SR2\plugins,重启一下Eclipse,然后,打开Window-->Preferens,可以看到Hadoop Map/Reduc选项,然后点击出现了An internal error occurredduring: "Map/Reduce location status updater".java.lang.NullPointerException,如图所示:
解决:
我们发现刚配置部署的Hadoop2还没创建输入和输出目录,先在hdfs上建个文件夹 。
#bin/hdfs dfs -mkdir –p /user/root/input
#bin/hdfs dfs -mkdir -p /user/root/output
我们在Eclipse的DFS Locations目录下看到我们这两个目录,如图所示:
------------------------------
http://book.2cto.com/201408/45667.html
---------------------------
------------------
org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z
分析:
C:\Windows\System32下缺少hadoop.dll,把这个文件拷贝到C:\Windows\System32下面即可。
解决:
将压缩包中的hadoop.dll放到C:\Windows\System32下,然后重启电脑,也许还没那么简单,还是出现这样的问题。如果这个还是没解决,最好在%HADOOP_HOME%/bin目录下面也复制一份。
-------------------
请多百度,查看资料,上面给出一部分错误。注意到 成功运行还需要另外一些文件
如果需要,我可以上传。hadoop2.6的
