java底层知识GC相关
https://www.cnblogs.com/baihuitestsoftware/articles/6483690.html
java内存模型是什么?
- Java内存模型规定和指引Java程序在不同的内存架构、CPU和操作系统间有确定性地行为。它在多线程的情况下尤其重要。Java内存模型对一个线程所做的变动能被其他线程可见提供了保证,它们之间是先行发生关系。这个关系定义了一些规则让程序员在并发编程时思路更清晰。比如,先行发生关系确保了:
- 线程内的代码能够按先后顺序执行,这被称为程序次序规则。
- 对于同一个锁,一个解锁操作一定要发生在时间上后发生的另一个锁定操作之前,也叫做管程规定规则。
- 当一条线程修改了这个变量的值,新值对于其他线程来说是可以立即得知的,也叫volatile变量规则。
- 一个线程内的任何操作必需在这个线程的start()调用之后,也叫线程启动规则。
- 一个线程的所有操作都会在线程终止之前,线程终止规则。
- 一个对象的终结操作必需在这个对象构造完成之后,也叫对象终结规则。
- 可传递性
GC简单的了解
GC:Garbage Collection 字面意思是垃圾回收器,释放垃圾占用的内存空间。让创建的对象不需要像c、c++那样delete、free掉。对于c、c++的开发人员分配的,也就是说还要对内存进行维护和释放。对于java程序员来说,一个对象的内存分配是在虚拟机的自动分配机制的帮助下,不再需要为每一个new操作去写配对的delete/free代码,而且不容易出现内存泄漏和内存溢出的问题,但是,如果出现了内存泄漏和内存溢出问题,而开发者又不了解虚拟机怎么分配内存的话,那么定位错误和排除错误将是一件很痛苦的事。
jvm内存管理结构,如图
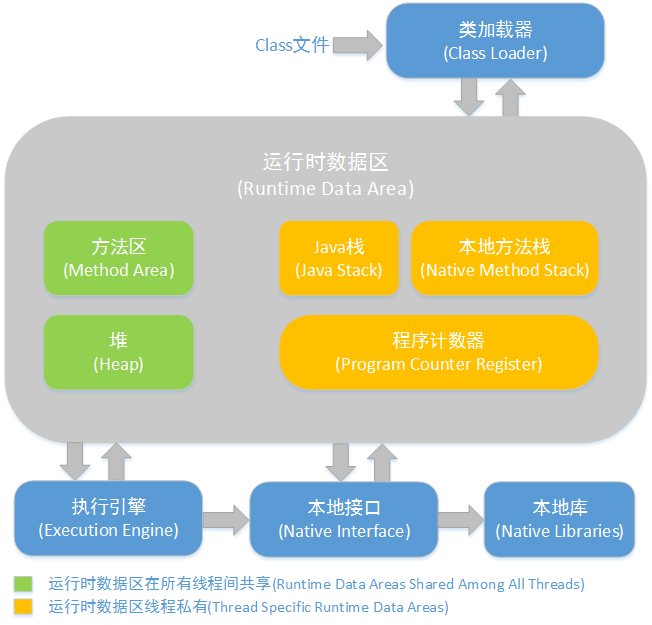
JVM运行时数据区
- 程序计数器(Program Counter Register):程序计数器是用于存储每个线程下一步执行的JVM指令,分支、循环、跳转、异常处理、线程恢复等基础功能都需要依赖这个计数器来完成。每条线程都需要有一个独立的程序计数器,各条线程之间的计数器互不影响,独立存储,故称该区域为“线程私有内存”
- JVM栈(JVM stack):与程序计数器一样,Java虚拟机栈也是线程私有的,它的生命周期与线程相同。虚拟机栈描述的是Java方法执行的内存模型;每个方法被执行的时候都会同时创建一个栈帧用于存储局部变量表,操作栈,动态链接,方法出口等信息。每个方法被调用直至执行完成的过程,就对应着一个栈帧在虚拟机栈中从入栈到出栈的过程。
局部变量表存放了编译期可知的各种基本数据类型(boolean、byte、char、short、int、float、long、double)、非基本类型的对象在JVM栈上仅存放一个指向堆上的地址。 - Java堆(Head):对于大多数应用来说,Java堆是Java虚拟机所管理的内存中最大的一块。Java堆是被所有线程共享的一块内存区域,在虚拟机启动时创建。此区域的唯一目的就是存放对象的实例,几乎所有的对象实例都在这里分配内存。
Java堆是垃圾收集器管理的主要区域,因此很多时候也被称作“GC堆”。如果从内存回收的角度看,由于现在收集器基本上都采用分代收集算法,所以Java堆中还可以细分为 :新生代和老年代;再细分一点新生代有Eden空间、From Survivor空间、To Survivor空间等。
根据Java虚拟机规范规定,Java堆可以处于物理上不连续的内存空间中,只要逻辑上是连续的即可,就像我们的磁盘空间一样,在实现时,既可以实现成固定大小的,也可以是可扩展的,不过当前主流的虚拟机都是按照可扩展来实现的(通过-Xmx和-Xms控制)。一般设置成同样大小,以避免每次垃圾回收完成后JVM重新分配内存,引起性能问题。如果在堆中没有内存完成实例分配,并且无法再扩展时,将会抛出OutOfMemoryError异常 - 方法区(Method Area):方法区与Java堆一样,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。虽然Java虚拟机规范把方法区描述为堆的一个逻辑部分,但是它却有一个别名叫做Non-Heap(非堆),目的应该是与Java堆区分开来。对于习惯在HotSpot虚拟机上开发和部署程序的开发者来说,很多人愿意把方法区称为“永久代”(Permanent Generation),本质上两者并不等价,仅仅是因为HotSpot虚拟机的设计团队选择吧GC分代收集扩展至方法区,或者说使用永久代来实现方法区而已。
此区域内存不够时我们会得到:java.lang.OutOfMemoryError: PermGen错误。而在JDK8中发生了明显的变化,就是一般情况下不会得到这个错误,原因是在于JDK8中把存放元数据中的永久代从堆内存中移到了本地内存。这样永久代就不再占用堆内存,当然JDK8也提供了一个新的设置Matespace内存大小的参数,通过这个参数可以设置Matespace内存大小,这样我们可以根据自己项目的实际情况,避免过度浪费本地内存,达到有效利用。-XX:MaxMetaspaceSize=128m 设置最大的元内存空间128兆
对象被判定为垃圾的标准
1、没有被其他对象引用
判定对象是否为垃圾的算法
1、引用计数算法
判断对象的引用数量
1)、通过判断对象的引用数量来决定对象是否可以被回收
2)、每个对象实例都有一个引用计数器,被引用则+1,完成引用-1
3)、任何引用数为0的对象实例可以被当做垃圾收集
优点:执行效率高,程序执行受影响较小
缺点:无法检测出循环引用的情况,导致内存泄漏
2、可达性分析算法
通过判断对象的引用链是否可达来决定对象是否可以被回收
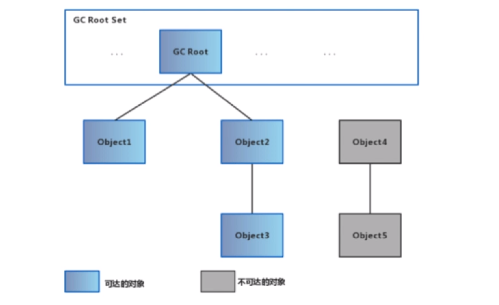
可以作为GC ROOT的对象:
1)、虚拟机栈中引用的对象(栈帧中的本地变量表)
2)、方法区中的常量引用的对象
3)、方法区中的类静态属性引用的对象
4)、本地方法栈中JNI(native方法)的引用对象
5)、活跃线程的引用对象
垃圾回收算法
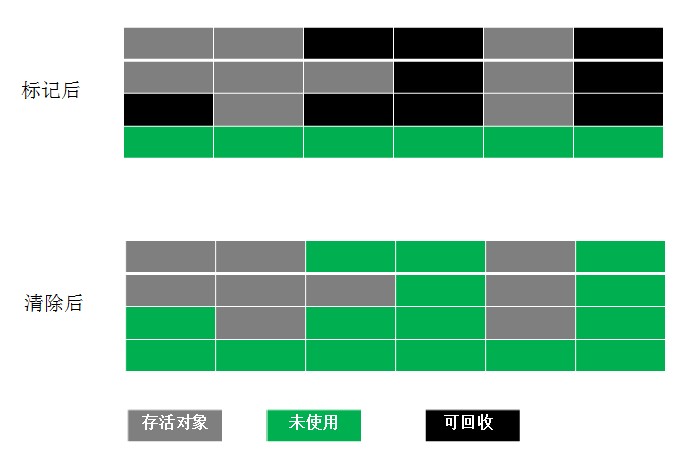
1、标记-清除算法
最基础的收集算法,算法分为“标记”和“清除”两个阶段:首先标记出所有需要回收的对象,在标记完成后统计回收所有被被标记的对象。
缺点:
- 标记和清除两个过程效率都不高。
- 空间问题,标记清除后会产生大量不连续的内存碎片,碎片太多可能会导致以后在程序运行过程中需要分配大对象时,无法找到足够的连续内存而不得不提前触发另一次垃圾收集动作。
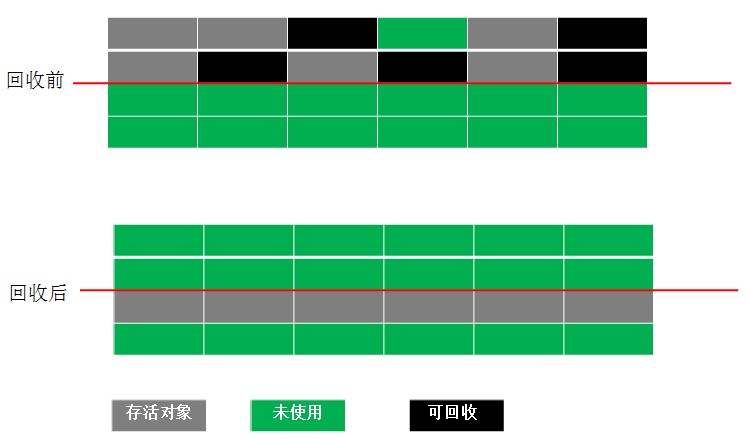
2、复制算法
为了解决效率问题,一种称为“复制”(Copying)的收集算法出现了,它将可用的内存按容量划分为大小相等的两块,每次只使用其中的一块,当这块内存用完了,就将还存活着的对象复制到另一块上面,然后再把已使用过的内存空间一次清理掉。这样使得每次都是对整个半区进行内存回收,内存分配时也就不用考虑内存碎片等复杂情况,只要移动堆顶指针,按顺序分配内存即可,实现简单,运行高效。只是这种算法的代价是将内存缩小为原来的一半,未免太高了一点。新生代GC算法采用的就是这种算法。Hotspot虚拟机默认为Eden和Survivor的比例是8:1:1。
3、标记-整理算法
复制收集算法在对象存活率较高时就要进行较多的复制操作,效率将会变低。更关键的是,如果不想浪费50%的空间,就需要有额外的空间进行分配担保,以应对被使用的内存中所有对象都100%存活的极端情况,所以在老年代一般不能直接使用这种算法。
根据老年代的特点,有人提出了另外一种“标记-整理”(Mark-Compact)算法,标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存,“标记-整理”算法如图
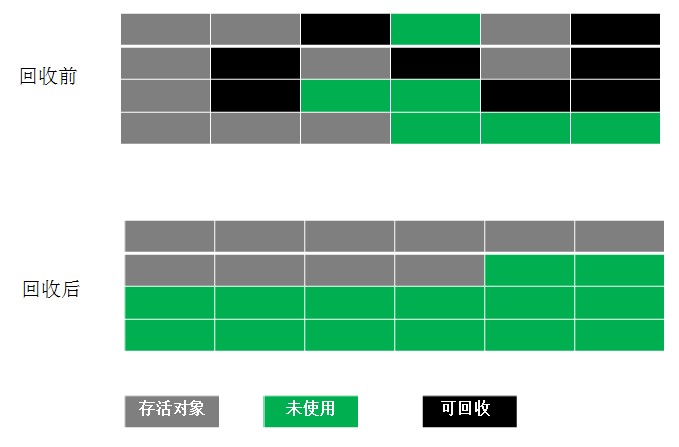
4、分代收集算法
当前商业虚拟机的垃圾收集都采用“分代收集”算法,这种算法并没有什么新的思想,只是根据对象存活周期的不同将内存划分为几块,一般是把Java堆分为新生代和老年代,这样就可以根据各个年代的特点采用最适当的收集算法。在新生代中,每次垃圾收集时都发现有大批对象死去,只有少量存活,那就选用复制算法,只需要付出少量存活对象的复制成本就可以完成收集。而老年代中因为对象存活率高,没有额外空间对它进行分配担保,就必须使用“标记-清理”或者“标记-整理”算法来进行回收。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号