使用RAML描述API文档信息的一些用法整理
RAML是Restful API Modeling Language的缩写,是用来描述API信息的文档。
创建一个.raml后缀的文件,用Atom打开。
基本用法
#%RAML 0.8 title: Book API baseUri: http://api.book.com/{version} version: v1 /users: /authors: /{authorname}: /books: get: queryParameters: author: displayName: Author type: string description: An author's full name example: Mary required: false publicationYear: displayName: Pub Year type: number description: The year released for the first time example: 1984 required: false rating: displayName: Rating type: number description: Average rating required: false isBn: displayName: ISBN type: string minLength: 10 example: 0321736079 put: queryParameters: access_token: displayName: Access Token type: string description: Token giving you permission to make call required: true post: /{bookTitle}: get: description: Retrieve a specific book title responses: 200: body: application/json: example: | { "data":{ "id": "SbBGk", "title": "its the title", "descritpion": null }, "success": true, "status": 200 } put: delete: /author: get: /publiser: get:
以上,
● 类型/users:看作是resource,也就是以/开始,:结尾,而且resource是嵌套存在的
● queryParameters描述查询字符串
接下来把.raml转换成html格式,有一个开源的项目。
→ 参考:https://github.com/raml2html/raml2html
→ 全局安装:npm i -g raml2html
→ .raml文件所在文件夹内打开命令窗口,输入:raml2html example.raml > example.html
就是这么个效果:
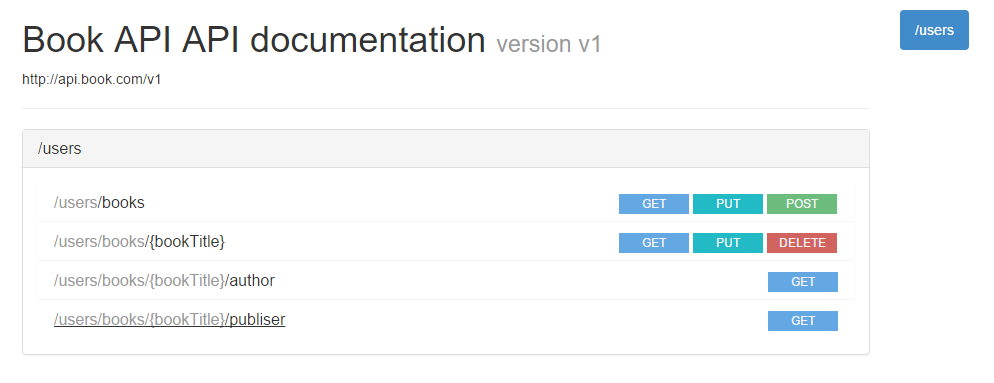
Body Parameters
POST请求,通常把参数放到body中传递,在RAML中如何描述呢?
在Body中的参数传递有很多方式,需要在Headers下的Content-Type中设置。Content-Type这个key可能的值包括:multipart/form-data, application/json, application/x-www-form-urlencoded等等。
1、通过multipart/form-data
/file-content: description: The file to be reproduced by the client get: description: Get the file content responses: 200: body: binary/octet-stream: example: !include heybulldog.mp3 post: description: | Enters the file content for an existing song entity. Use the "binary/octet-stream" content type to specify the content from any consumer (excepting web-browsers). Use the "multipart-form/data" content type to upload a file which content will become the file-content body: binary/octet-stream: multipart/form-data: formParameters: file: description: The file to be uploaded required: true type: file
以上,
● Content-Type能接受的类型是binary/octet-stream或multipart/form-data
● 对于multipart/form-data类型,键值数据放在了formParameters中
● !include heybulldog.mp3表示把heybulldog.mp3文件引入进来
2、通过JSON Shema
JSON Shema用来描述JSON格式。
为什么需要JSON Schema呢?
举个例子:
{ "id":1, "name":"a green door", "price":12.50, "tags":["home", "green"] }
我们可能会问:
● 什么是id
● name字段必须吗
● price的值可以是0吗
● tags所代表的数组元素是string类型吗?
JSON Schema就是解决这些问题的。
{ "$schema": "http://json-schema.org/draft-04/schema#", "title": "Product", "description": "A product from Acme's catalog", "type": "object" }
以上,
● $schema表示当前JSON Shema所采用的版本
● type字段是必须的,是object类型
接着,对id字段约束。
{ "$schema": "http://json-schema.org/draft-04/schema#", "title": "Product", "description": "A product from Acme's catalog", "type": "object", "properties": { "id": { "description": "The unique identifier for a product", "type": "integer" } }, "required": ["id"] }
对name字段约束。
{ "$schema": "http://json-schema.org/draft-04/schema#", "title": "Product", "description": "A product from Acme's catalog", "type": "object", "properties": { "id": { "description": "The unique identifier for a product", "type": "integer" }, "name": { "description": "Name of the product", "type": "string" } }, "required": ["id", "name"] }
对price字段约束。
{ "$schema": "http://json-schema.org/draft-04/schema#", "title": "Product", "description": "A product from Acme's catalog", "type": "object", "properties": { "id": { "description": "The unique identifier for a product", "type": "integer" }, "name": { "description": "Name of the product", "type": "string" }, "price": { "type": "number", "minimum": 0, "exclusiveMinimum": true } }, "required": ["id", "name", "price"] }
对tags字段约束。
{ "$schema": "http://json-schema.org/draft-04/schema#", "title": "Product", "description": "A product from Acme's catalog", "type": "object", "properties": { "id": { "description": "The unique identifier for a product", "type": "integer" }, "name": { "description": "Name of the product", "type": "string" }, "price": { "type": "number", "minimum": 0, "exclusiveMinimum": true }, "tags": { "type": "array", "items": { "type": "string" }, "minItems": 1, "uniqueItems": true } }, "required": ["id", "name", "price"] }
数组如何用JSON Schema描述呢?
[ { "id": 2, "name": "An ice sculpture", "price": 12.50, "tags": ["cold", "ice"], "dimensions": { "length": 7.0, "width": 12.0, "height": 9.5 }, "warehouseLocation": { "latitude": -78.75, "longitude": 20.4 } }, { "id": 3, "name": "A blue mouse", "price": 25.50, "dimensions": { "length": 3.1, "width": 1.0, "height": 1.0 }, "warehouseLocation": { "latitude": 54.4, "longitude": -32.7 } } ]
用JSON Shema描述就是这样:
{ "$schema": "http://json-schema.org/draft-04/schema#", "title": "Product set", "type": "array", "items": { "title": "Product", "type": "object", "properties": { "id": { "description": "The unique identifier for a product", "type": "number" }, "name": { "type": "string" }, "price": { "type": "number", "minimum": 0, "exclusiveMinimum": true }, "tags": { "type": "array", "items": { "type": "string" }, "minItems": 1, "uniqueItems": true }, "dimensions": { "type": "object", "properties": { "length": {"type": "number"}, "width": {"type": "number"}, "height": {"type": "number"} }, "required": ["length", "width", "height"] }, "warehouseLocation": { "description": "Coordinates of the warehouse with the product", "$ref": "http://json-schema.org/geo" } }, "required": ["id", "name", "price"] } }
RAML也用到了JSON Shema,就像这样:
body: application/json: schema: | { "type": "object", "$schema": "http://json-schema.org/draft-03/schema", "id": "http://jsonschema.net", "required": true, "properties": { "songTitle": { "type": "string", "required": true }, "albumId": { "type": "string", "required": true, "minLength": 36, "maxLength": 36 } } } example: | { "songId": "550e8400-e29b-41d4-a716-446655440000", "songTitle": "Get Lucky", "albumId": "183100e3-0e2b-4404-a716-66104d440550" }
schemas
每个资源都有自己的schema,是否可以把所有资源的schema合并到同一个地方呢?
RAML提供了schemas字段。
schemas: - song: | { "type": "object", "$schema": "http://json-schema.org/draft-03/schema", "id": "http://jsonschema.net", "required": true, "properties": { "songTitle": { "type": "string", "required": true }, "albumId": { "type": "string", "required": true, "minLength": 36, "maxLength": 36 } } }
按如下引用:
body: application/json: schema: song example: | { "songId": "550e8400-e29b-41d4-a716-446655440000", "songTitle": "Get Lucky", "albumId": "183100e3-0e2b-4404-a716-66104d440550" }
Resource Types资源类型
每个资源通有相似的部分,能否把这些相似的部分提取抽象出来呢?
假设有2个资源:/resources和/{resourceId}
#%RAML 0.8 title: /resources: get: post: /{resourceId}: get: put: delete:
以上,resource大致可以分成针对集合和针对个体的,所以,在RAML中通过resourceTypes对资源进行分类,有这样的表达方式:
resourceTypes: - collection: get: post: - collection-item: get:
于是collection类型可以写成这样:
resourceTypes: - collection: description: Collection of available <<resourcePathName>> in Jukebox. get: description: Get a list of <<resourcePathName>>. responses: 200: body: application/json: post: description: | Add a new <<resourcePathName|!singularize>> to Jukebox. queryParameters: access_token: description: "The access token provided by the authentication application" example: AABBCCDD required: true type: string body: application/json: schema: <<resourcePathName|!singularize>> responses: 200: body: application/json: example: | { "message": "The <<resourcePathName|!singularize>> has been properly entered" }
以上,
● <<resourcePathName>>是占位符,类似表示songs
● 另外<<resourcePath>>是占位符,类似表示/songs
● <<resourcePathName|!singularize>>是占位符,类似表示song
● <<resourcePathName|!pluralize>>是占位符,类似表示songs
然后这样使用:
/songs: type: collection get: queryParameters: songTitle: description: "The title of the song to search (it is case insensitive and doesn't need to match the whole title)" required: true minLength: 3 type: string example: "Get L" responses: 200: body: application/json: example: | "songs": [ { "songId": "550e8400-e29b-41d4-a716-446655440000", "songTitle": "Get Lucky" }, { "songId": "550e8400-e29b-41d4-a716-446655440111", "songTitle": "Loose yourself to dance" }, { "songId": "550e8400-e29b-41d4-a716-446655440222", "songTitle": "Gio sorgio by Moroder" } ] post: body: application/json: example: | { "songId": "550e8400-e29b-41d4-a716-446655440000", "songTitle": "Get Lucky", "albumId": "183100e3-0e2b-4404-a716-66104d440550" }
collection-item类型可以写成这样:
resourceTypes: - collection: ... - collection-item: description: Entity representing a <<resourcePathName|!singularize>> get: description: | Get the <<resourcePathName|!singularize>> with <<resourcePathName|!singularize>>Id = {<<resourcePathName|!singularize>>Id} responses: 200: body: application/json: 404: body: application/json: example: | {"message": "<<resourcePathName|!singularize>> not found" }
然后这样使用:
/songs: ... /{songId}: type: collection-item get: responses: 200: body: application/json: example: | { "songId": "550e8400-e29b-41d4-a716-446655440000", "songTitle": "Get Lucky", "duration": "6:07", "artist": { "artistId": "110e8300-e32b-41d4-a716-664400445500" "artistName": "Daft Punk", "imageURL": "http://travelhymns.com/wp-content/uploads/2013/06/random-access-memories1.jpg" }, "album": { "albumId": "183100e3-0e2b-4404-a716-66104d440550", "albumName": "Random Access Memories", "imageURL": "http://upload.wikimedia.org/wikipedia/en/a/a7/Random_Access_Memories.jpg" } }
以上,
● 在resourceTypes中的谓词get,post等,可以在具体的resource中进行重新定义
● 在resrouce级别,通过type: collection-item或type: collection与resourceTypes对应
Parameters
以上,resourceTypes字段所代表的是一个对集合和个体类型相同操作的一个封装,在这些操作中,在这些请求响应中,有时需要通过example字段来举例,通常这样写:
example: | { ... } 或者 example: | [ { }, { } ]
但在RAML中,为我们提供了<<exampleCollection>>和<<exampleItem>>占位符分别表示集合和个体。
resourceTypes: - collection: description: Collection of available <<resourcePathName>> in Jukebox. get: description: Get a list of <<resourcePathName>>. responses: 200: body: application/json: example: | <<exampleCollection>> post: description: | Add a new <<resourcePathName|!singularize>> to Jukebox. queryParameters: access_token: description: "The access token provided by the authentication application" example: AABBCCDD required: true type: string body: application/json: schema: <<resourcePathName|!singularize>> example: | <<exampleItem>> responses: 200: body: application/json: example: | { "message": "The <<resourcePathName|!singularize>> has been properly entered" } - collection-item: description: Entity representing a <<resourcePathName|!singularize>> get: description: | Get the <<resourcePathName|!singularize>> with <<resourcePathName|!singularize>>Id = {<<resourcePathName|!singularize>>Id} responses: 200: body: application/json: example: | <<exampleItem>> 404: body: application/json: example: | {"message": "<<resourcePathName|!singularize>> not found" }
在资源resource部分通常这样调用:
/songs: type: collection: exampleCollection: | [ ... ] /{songId}: type: collection-item: exampleItem: | { ... }
具体来说,类似这样:
/songs: type: collection: exampleCollection: | [ { "songId": "550e8400-e29b-41d4-a716-446655440000", "songTitle": "Get Lucky" }, { "songId": "550e8400-e29b-41d4-a716-446655440111", "songTitle": "Loose yourself to dance" }, { "songId": "550e8400-e29b-41d4-a716-446655440222", "songTitle": "Gio sorgio by Morodera" } ] exampleItem: | { "songId": "550e8400-e29b-41d4-a716-446655440000", "songTitle": "Get Lucky", "albumId": "183100e3-0e2b-4404-a716-66104d440550" } get: queryParameters: songTitle: description: "The title of the song to search (it is case insensitive and doesn't need to match the whole title)" required: true minLength: 3 type: string example: "Get L" /{songId}: type: collection-item: exampleItem: | { "songId": "550e8400-e29b-41d4-a716-446655440000", "songTitle": "Get Lucky", "duration": "6:07", "artist": { "artistId": "110e8300-e32b-41d4-a716-664400445500" "artistName": "Daft Punk", "imageURL": "http://travelhymns.com/wp-content/uploads/2013/06/random-access-memories1.jpg" }, "album": { "albumId": "183100e3-0e2b-4404-a716-66104d440550", "albumName": "Random Access Memories", "imageURL": "http://upload.wikimedia.org/wikipedia/en/a/a7/Random_Access_Memories.jpg" } }
Includes
可以把一些example放到单独的文件,然后通过!include关键字来引用这些文件。
/songs: type: collection: exampleCollection: !include jukebox-include-songs.sample exampleItem: !include jukebox-include-song-new.sample /{songId}: type: collection-item: exampleItem: !include jukebox-include-song-retrieve.sample
traits
如何描述查询、排序、分页呢?
traits: - searchable: queryParameters: query: description: | JSON array [{"field1","value1","operator1"},{"field2","value2","operator2"},...,{"fieldN","valueN","operatorN"}] <<description>> example: | <<example>>aml - orderable: queryParameters: orderBy: description: | Order by field: <<fieldsList>> type: string required: false order: description: Order enum: [desc, asc] default: desc required: false - pageable: queryParameters: offset: description: Skip over a number of elements by specifying an offset value for the query type: integer required: false example: 20 default: 0 limit: description: Limit the number of elements on the response type: integer required: false example: 80 default: 10
按如下使用这些trait。
/songs: type: collection: exampleCollection: !include jukebox-include-songs.sample exampleItem: !include jukebox-include-song-new.sample get: is: [ searchable: {description: "with valid searchable fields: songTitle", example: "[\"songTitle\", \"Get L\", \"like\"]"}, orderable: {fieldsList: "songTitle"}, pageable ]
另外,schema也可以放到单独的文件中,然后通过!include引用。
schemas: - song: !include jukebox-include-song.schema - artist: !include jukebox-include-artist.schema - album: !include jukebox-include-album.schema
resourceTypes也可以放到单独的文件中:
resourceTypes: !include jukebox-includes-resourceTypes.inc

 浙公网安备 33010602011771号
浙公网安备 33010602011771号