python 使用xpath获取网页标签内容
获取指定html的标签内容
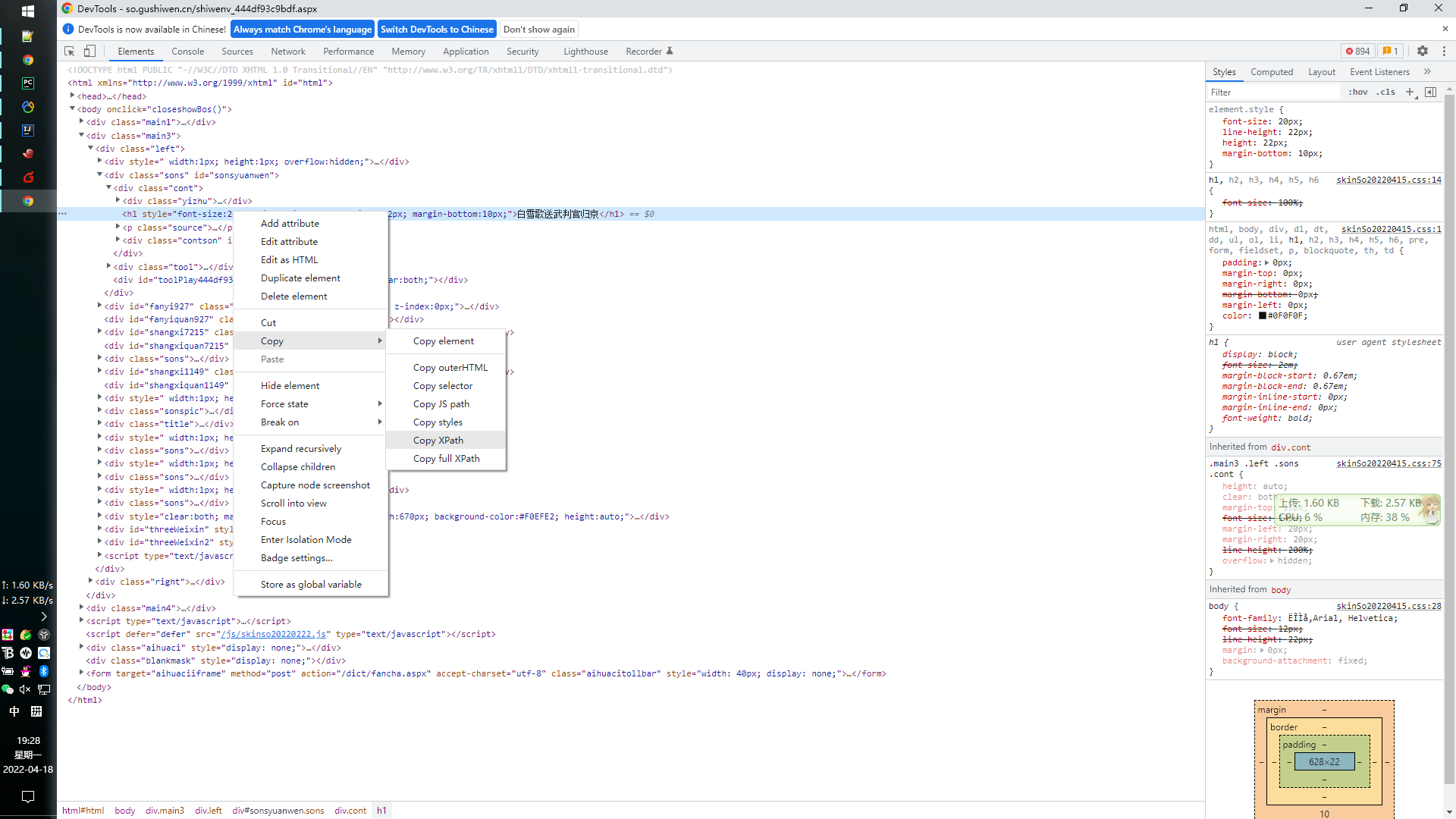
打开网页的开发者模式,得到路径标签,然后加上/text() 即可得到标签的文本内容
//*[@id="sonsyuanwen"]/div[1]/h1
对于网页爬取来说,还是很方便的
# -*- ecoding: utf-8 -*-
# @ModuleName: test005
# @Function:
# @Author: darling
# @Time: 2022-04-18 13:58
import requests
from lxml import etree
def get_url():
resource = requests.get('https://so.gushiwen.cn/shiwenv_444df93c9bdf.aspx')
html = etree.HTML(resource.text)
title = html.xpath('//*[@id="sonsyuanwen"]/div[1]/h1/text()')
neir=html.xpath('//*[@id="contson444df93c9bdf"]/text()')
print(title,neir)
return resource
if __name__ == "__main__":
res = get_url()
print(res)
惜秦皇汉武,略输文采;唐宗宋祖,稍逊风骚。
一代天骄,成吉思汗,只识弯弓射大雕。
俱往矣,数风流人物,还看今朝

 浙公网安备 33010602011771号
浙公网安备 33010602011771号