【转载】分布式系统理论之CAP定理
什么是CAP定理
CAP定理指的是在一个分布式系统中, Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),三者不可兼得。在分布式系统中,分区容错性是必须需要实现的。所以只能在一致性和可用性之间进行权衡(AP或者CP)
单机RDBMS是CA系统
单机的Oracle或MySQL之类的传统RDBMS数据库没有分区容错,是CA系统,可以达到强一致性和可用性。
CAP在MySQL主从复制中的应用
MySQL主从复制实现了分区容错性(P),主从复制分为异步复制和半同步复制。
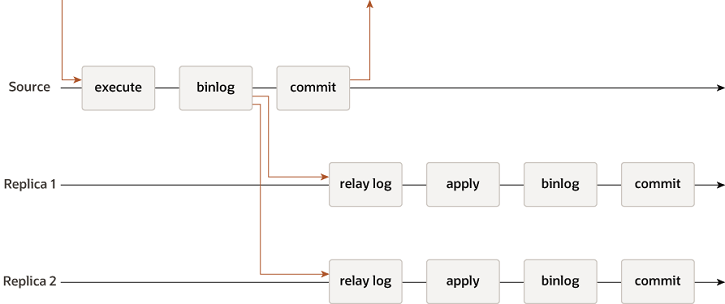
- 异步复制 异步复制操作时序图:
![]()
异步复制在master写binlog成功之后立即提交,不等待slave的同步结果。这种方式有很高的性能,但是牺牲了数据一致性。如果slave同步不成功就会造成master和slave数据不一致。异步复制虽然性能高(A),但是数据有可能不一致(C),所以异步复制是AP系统。 - 半同步复制 半同步复制操作时序图:
![]()
半同步复制在master写binlog成功之后不立即提交,而是等待其中一个slave同步成功,只要有一个slave同步成功,立即提交。这种方式比异步复制性能稍差(需要等待至少一个slave同步成功才提交),但是在一定程度上保证了数据一致性(依然不是CP系统:如果同步slave2失败,master和slave1在commit之后挂了,slave2对外提供服务,从slave2中无法查询到刚才提交的数据)。
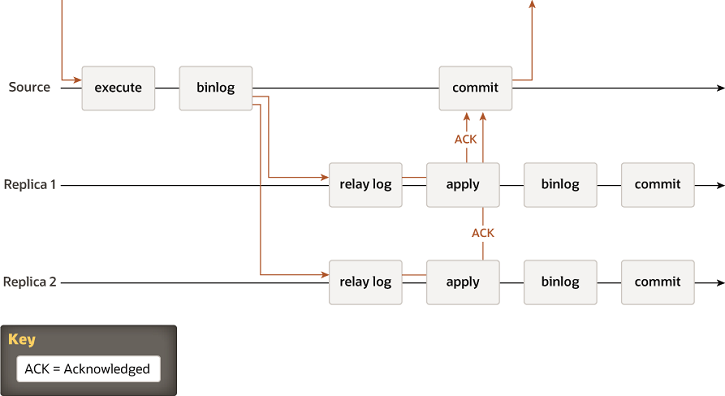
从MySQL两种主从复制实现来看,在保证分区容错(P)的情况下,必须在性能(A)和数据一致性上(C)做出取舍。
CAP在MySQL组复制中的应用
组复制操作时序图: 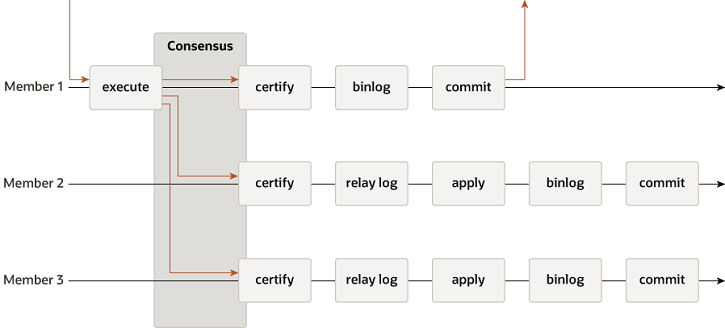 组复制使用paxos协议广播执行状态,由于paxos协议的限制,必须多数master达成一致,写入操作才算成功,可以实现在多个master之间保持数据一致。如果在两个或多个master上并发更新同一条数据,在certify阶段进行操作校验,只有第一个更新操作能成功,其他更新操作返回失败。 此系统在一致性方面(C)做了妥协(强一致->弱一致,有短暂数据不一致窗口),在性能方面(A)也做了妥协(比单机多了消息广播和certify阶段,性能略低),从而达到分区容错(P)。
组复制使用paxos协议广播执行状态,由于paxos协议的限制,必须多数master达成一致,写入操作才算成功,可以实现在多个master之间保持数据一致。如果在两个或多个master上并发更新同一条数据,在certify阶段进行操作校验,只有第一个更新操作能成功,其他更新操作返回失败。 此系统在一致性方面(C)做了妥协(强一致->弱一致,有短暂数据不一致窗口),在性能方面(A)也做了妥协(比单机多了消息广播和certify阶段,性能略低),从而达到分区容错(P)。
zookeeper集群
zookeeper集群在对外提供服务和写入数据时,必须半数以上主机可用并且数据写入成功,才返回成功。虽然有短暂的数据不一致窗口,但是因为有超过半数成功的限制条件,即使leader挂掉,选举出来的新leader也肯定会有所有完整的数据(有最新数据日志的节点才有可能被选为leader),所以最终数据会在集群中的所有机器上保持一致(单调弱一致性:两次读取操作,后发起的不会读取到比前一次读取到的数据更老的数据)。因此zookeeper集群是CP系统。
zookeeper集群设计为CP系统的原因:zookeeper作为分布式协调系统,可以在性能上做出妥协,但是必须要求数据是一致的,否则无法作为协调工具存在。
redis集群
redis集群在写入数据时,master写入成功即返回成功,数据异步复制到slave上。如果在master写入成功,但是在同步数据到slave时master挂掉,slave被选为新的master,此时刚才写入成功但没有同步到slave的数据会丢失。所以redis集群是AP系统。 redis集群设计为AP系统的原因:redis作为内存数据库,目的是为了提高数据存取的性能,缓存是其最常见的使用场景,性能高是redis的最大特点,所以只能在数据一致性上做出妥协。
分布式锁的选择
zookeeper和redis都可以实现分布式锁(MySQL和其他RDBMS也可以,但是性能较低),也都有现成的第三方库。选择zookeeper还是redis实现分布式锁,一般参照以下标准:
- 对安全性要求高,不允许出现锁失效的场景,比如和用户金钱道具相关的操作,选择zookeeper实现分布式锁。
- 对安全性要求不高,可以允许偶尔出现锁失效的场景,比如分布式系统执行定时任务做一些类似于归档数据的操作,如果多个实例并发执行会影响性能,但是不会造成其他负面影响。
总结
CAP定理作为分布式系统的基础,在系统架构方面起引导作用。由于CAP定理的限制,需要根据不同使用场景,在性能和一致性之间做出选择(参照zookeeper和redis)。
转载自:https://my.oschina.net/lhztt/blog/915533

 浙公网安备 33010602011771号
浙公网安备 33010602011771号