(原)torch和caffe中的BatchNorm层
转载请注明出处:
http://www.cnblogs.com/darkknightzh/p/6015990.html
BatchNorm具体网上搜索。
caffe中batchNorm层是通过BatchNorm+Scale实现的,但是默认没有bias。torch中的BatchNorm层使用函数SpatialBatchNormalization实现,该函数中有weight和bias。
如下代码:
local net = nn.Sequential() net:add(nn.SpatialBatchNormalization(64)) net:add(nn.SpatialBatchNormalization(64, 1e-5, 0.1, false)) print(net.modules)
输出如下:
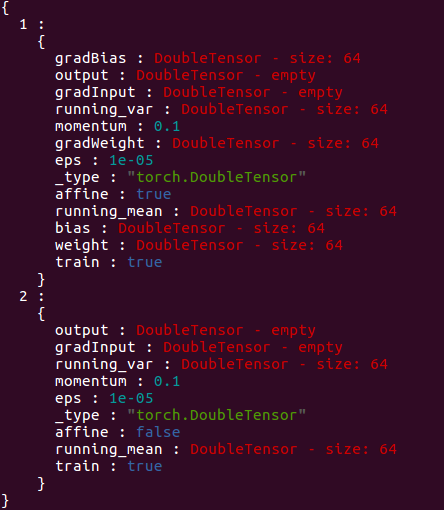
其中第一个为nn.SpatialBatchNormalization(64),第二个为nn.SpatialBatchNormalization(64, 1e-5, 0.1, false)。
SpatialBatchNormalization 参数如下:
nn.SpatialBatchNormalization(N [,eps] [, momentum] [,affine])
默认情况下,eps=1e-5,momentum =0.1,affine=true。因而若要和caffe中的BatchNorm一样,均没有weight和bias,则需要将affine设置为false。若affine为默认值,有如下两种方法可以使torch和caffe参数一致(不太确定):
1. 手动将bias设置为0,此时能和caffe中BatchNorm+Scale(默认的)一样。
2. caffe中ScaleParameter的bias_term(equivalent to a ScaleLayer+BiasLayer)设置为true(该值默认为false)。
========================================================================
161110更新(可能有不对的地方):
对于Caffe:
在使用BatchNorm时,Batch层共3个参数,1个存储均值向量,一个存储方差向量,第三个存储缩放的值。最终的均值向量=均值向量/缩放;最终的方差向量=方差向量/缩放。
Scale层共2个参数,一个存储的是γ向量,一个存储的是β向量。
假设caffe中BatchNorm层输入为1(batch size)*64(channel)*128(height)*128(width)(输出和输入一样),则BatchNorm层共3个参数:mean(64维的向量),variance(64维的向量),scalefactor(1维的向量)。其中mean存储了每一channel的均值,variance存储了每一channel的方差,scalefactor看着caffe的参数,好像都是999.982361(没有过多测试,不太确定)。
在TEST阶段,当输入一个数,如0.001932,对应的mean= -5122.504395,variance=385844.062500,scale= 999.982361时,
缩放后的mean:-5122.504395/999.982361=-5.1225947524488384450613324368429
缩放后的variance:385844.062500/999.982361=385.85086852346988548531007538442
标准差:(385.85086852346988548531007538442+1e(-5))^0.5=
19.643087296132191385983152758013
缩放后的值:
(0.001932-(-5.1225947524488384450613324368429))/ 19.643087296132191385983152758013= 0.26088194158042966422836995726056
实际上得到的为0.260882。在精度范围内一致。
总结起来就是,对每个维度使用对应的均值和方差。不同batch使用对应的参数。
在TRAIN阶段,则是首先计算每个batch不同channel的均值及方差,而后通过论文中公式得到对应的输出。
${{\hat{x_i}}}=\frac{{{x}_{i}}-{{\mu }_{B}}}{\sqrt{\sigma _{B}^{2}+\varepsilon }}$
$E\left[ x \right]={{E}_{B}}\left[ {{\mu }_{B}} \right]$
$Var\left[ x \right]=\frac{m}{m-1}{{E}_{B}}\left[ \sigma _{B}^{2} \right]$
实际中感觉caffe中,即便在训练阶段,依旧使用上面的var来计算方差。
caffe中scale层,得到的scale_param包括weight和bias,均为channel维的向量(如64)。之后对于输入,通过下式计算输出。注意的是,不同channel使用各自的weight和bias,同一个channel的weight和bias都一样。
${{y}_{i}}=\gamma {{\hat{x_i}}}+\beta $
对于torch:
torch中SpatialBatchNormalization是跟在conv层之后,其输入为4D数据(应该是batch_size*channel*height*width),另一个BatchNormalization层是跟在一般的层后面(这样说不太准确吧),其输入为2D数据(应该是batch_size*channel)。SpatialBatchNormalization继承自BatchNormalization。
SpatialBatchNormalization和BatchNormalization的第一个参数N代表特征的维数(channel)。
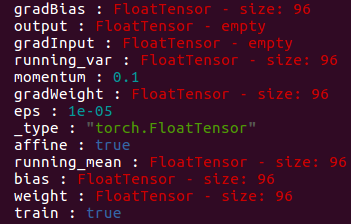
当affine=true时,SpatialBatchNormalization中结构:
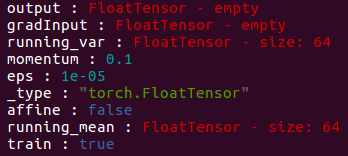
当affine=false时,SpatialBatchNormalization中结构:
当net:evaluate()时,上两图中最后一个参数train为false。
其中,running_mean存储的是特征的mean(对应于caffe中最终的均指向量),running_var存储的是特征的方差(对应于caffe中最终的方差向量)。weight存储的是缩放时特征的γ,bias存储的是缩放时特征的β。
BatchNorm的论文为:Batch Normalization Accelerating Deep Network Training by Reducing Internal Covariate Shift。
161110更新结束
161121更新
今天使用cudnn的BatchNormalization时,提示Only CUDA tensors are supported for cudnn.BatchNormalization,而后程序崩溃。网上搜索了一下,https://github.com/soumith/cudnn.torch/issues/219遇到了类似的问题。具体原因可能不太一样吧。我这边是使用BatchNormalization(或者SpatialBatchNormalization)的问题。该层affine=true时,会使用仿射(有weight和bias),affine=false时,无weight和bias。而cudnn实际上只支持affine=true的情况(目前是这样),我这边程序有affine=false的时候,此时使用cudnn的BatchNormalization(SpatialBatchNormalization继承自BatchNormalization,下面不在说明SpatialBatchNormalization)就会直接assert错误了。
cudnn的BatchNormalization的部分初始化代码如下(位置:/home/XXX/torch/install/share/lua/5.1/cudnn/BatchNormalization.lua):
function BatchNormalization:__init(nFeature, eps, momentum, affine) parent.__init(self) assert(nFeature and type(nFeature) == 'number', 'Missing argument #1: Number of feature planes. ') assert(nFeature ~= 0, 'To set affine=false call BatchNormalization' .. '(nFeature, eps, momentum, false) ') assert(affine == true or affine == nil, 'only affine supported')
实际上assert错误的地方是下面代码的最后一行:
function BatchNormalization:createIODescriptors(input) assert(input:dim() == self.nDim) assert(torch.typename(self.weight) == 'torch.CudaTensor' and torch.typename(self.bias) == 'torch.CudaTensor', 'Only CUDA tensors are supported for cudnn.BatchNormalization!')
从初始化代码可以看出,cudnn的BatchNormalization只支持affine=true的情况。
该网页也提供了解决方法:byronwwang在第5层的回复中注释的代码就是解决方法。在使用cudnn.convert时,可以通过第三个参数,不转换某些层。https://github.com/soumith/cudnn.torch里面也给出了不转换层时的代码(Conversion between cudnn and nn这部分):
cudnn.convert(net, cudnn, function(module) return torch.type(module):find('BatchNormalization') end)
此时BatchNormalization会使用nn模块中的BatchNormalization。
161121更新结束
========================================================================
posted on 2016-10-31 15:19 darkknightzh 阅读(20951) 评论(9) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号