(原)人体姿态识别HRNet
转载请注明出处:
https://www.cnblogs.com/darkknightzh/p/12150637.html
论文
HRNet:Deep High-Resolution Representation Learning for Human Pose Estimation
https://arxiv.org/abs/1902.09212
HRNetV2:High-Resolution Representations for Labeling Pixels and Regions
https://arxiv.org/abs/1904.04514
官方代码:
包括如下内容
1 简介
论文指出,有两种主要的计算高分辨率特征的方式:1 从ResNet等网络输出的低分辨率特征恢复高分辨率特征,同时可以得到中分辨率特征,如Hourglass、SegNet、DeconvNet、U-Net、encoder-decoder等。此时,可以使用上采样网络得到高分辨率特征,上采样网络应当和下采样网络互为对称网络(也有不对称的上采样过程,如RefineNet等)。2 通过高分辨率特征及并行的低分辨率特征来保持高分辨率特征。另一方面,空洞卷积可以用于计算中分辨率的特征。
HRNet能够保持高分辨率的特征,而不是从低分辨率的特征恢复高分辨率的特征。
2 网络结构
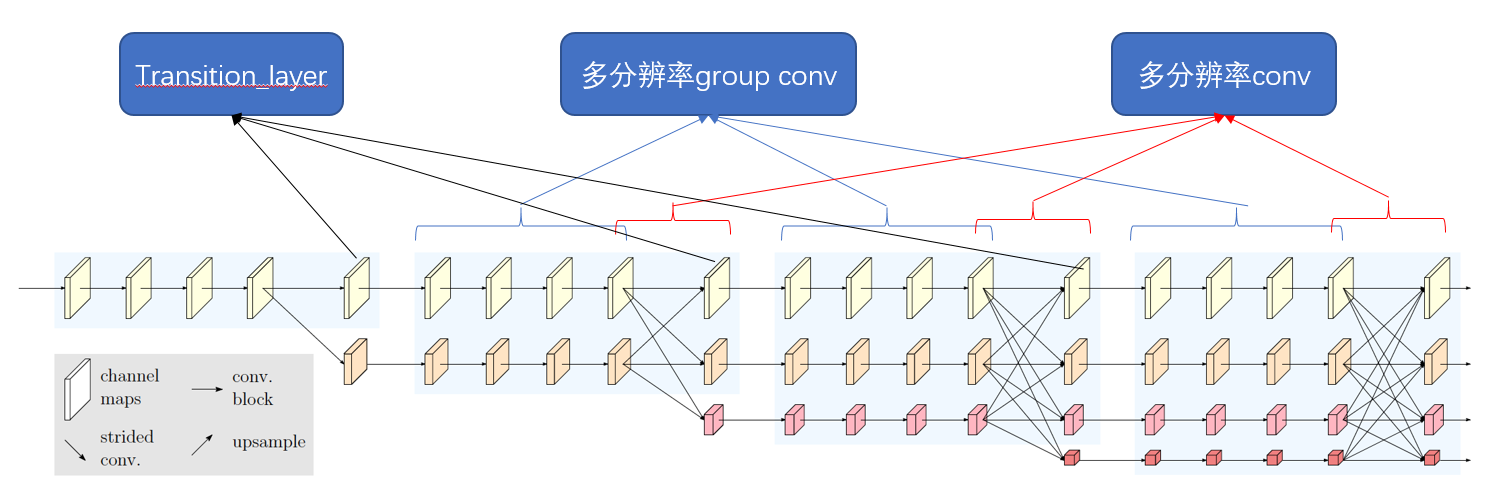
2.1 总体结构
论文的网络结构如下图所示,该图有4个阶段,第2、3、4阶段均为重复的多分辨率模块(modularized multi-resolution blocks)。在每个多分辨率模块之前,有一个交换层(Translation layer),该层才会出现额外的特征图。而多分辨率模块(多分辨率分组卷积+多分辨率卷积)没有额外的特征图出现。
注意:论文中的网络结构和代码中的稍有差异,但是本质上是一样的。如下面网址:
https://github.com/HRNet/HRNet-Object-Detection/issues/3
问题:

作者回答:
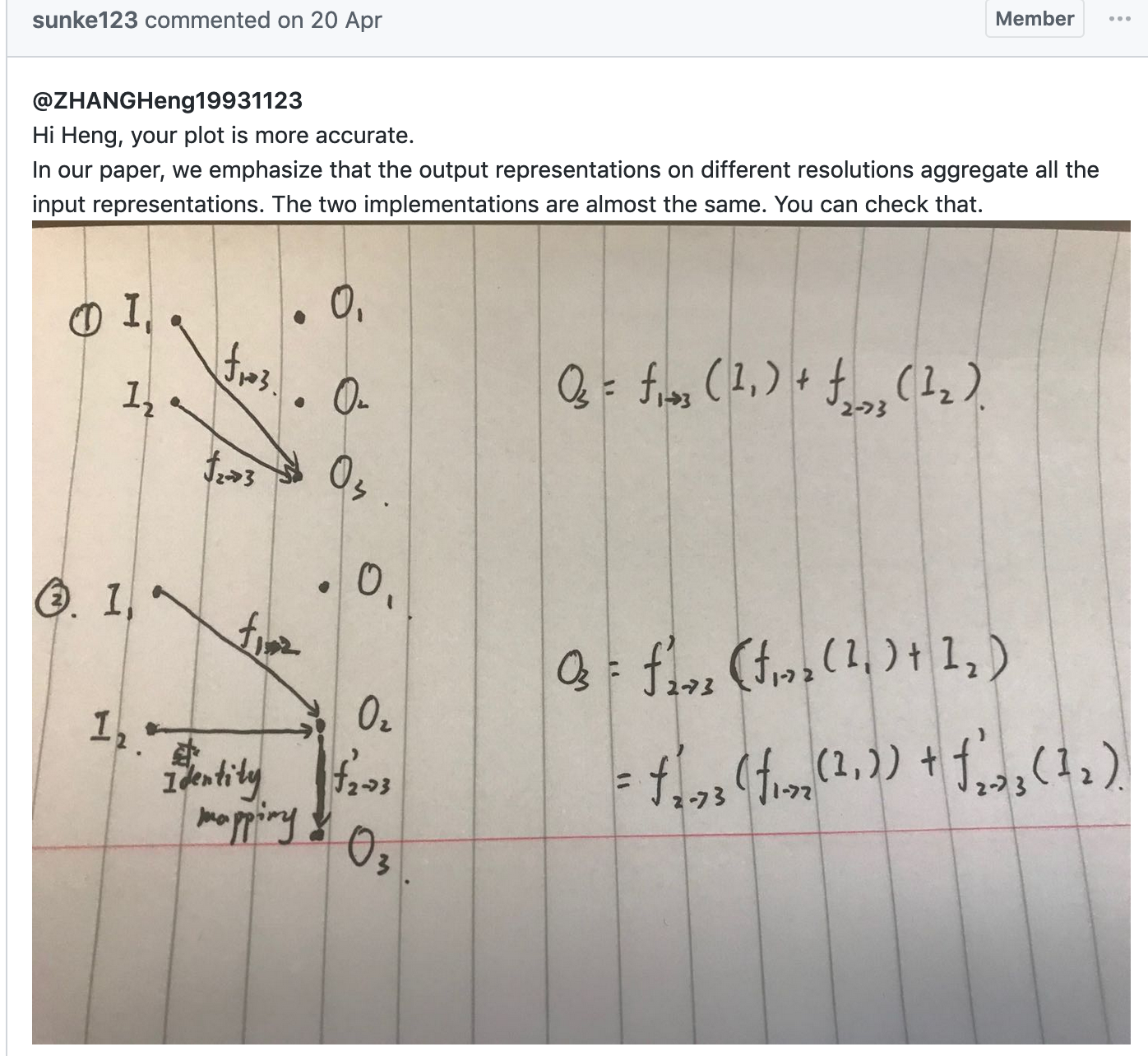
如下所示,左侧的论文结构实际上等效于右侧的代码实现。d2为c2的下采样,但是由于c2是a2和b2的全连接,因而也可以认为d2是a2和b2的全连接。

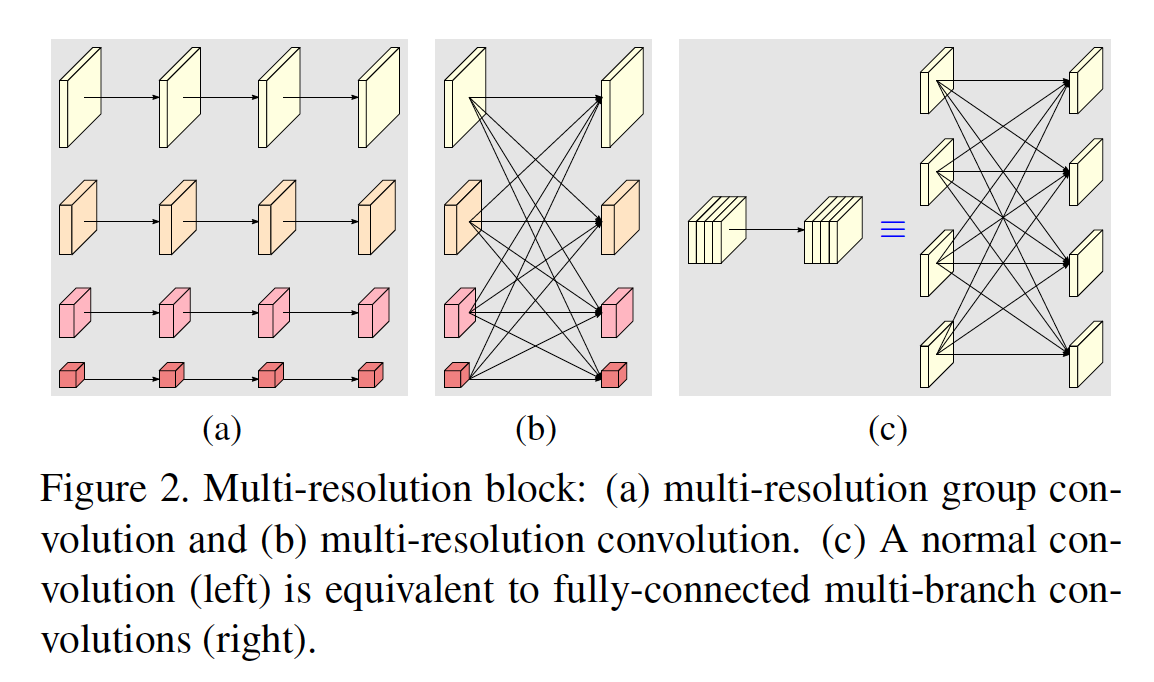
2.2 多分辨率模块
多分辨率模块包括多分辨率分组卷积(multi-resolution group convolution)和多分辨率卷积(multi-resolution convolution)。多分辨率分组卷积如下图a所示,其是分组卷积的扩展,将输入的通道分成了不同的子通道,每个子通道使用常规的卷积。多分辨率卷积如下图b所示,输入和输出子集使用类似全连接的方式,实现上是常见的卷积。为了保持分辨率匹配,降低分辨率时使用的是多个stride=2的3*3conv,增加分辨率时使用的是上采样(bilinear或者nearest neighbor)。下图c左侧为常规卷积,等效于右侧的全连接多分支卷积。
==================================================
以下内容出自HRNetV1:
假设某阶段输入特征为$\left\{ {{\mathbf{X}}_{1}},{{\mathbf{X}}_{2}},\cdots ,{{\mathbf{X}}_{s}} \right\}$,输出特征为$\left\{ {{\mathbf{Y}}_{1}},{{\mathbf{Y}}_{2}},\cdots ,{{\mathbf{Y}}_{s}} \right\}$,输出特征的分辨率和宽高都和输入的对应相等。每个输出均为输入的加权和${{\mathbf{Y}}_{k}}=\sum\nolimits_{i=1}^{s}{a\left( {{\mathbf{X}}_{i}},k \right)}$。Translation layer还有一个额外的特征${{\mathbf{Y}}_{s+1}}$:${{\mathbf{Y}}_{s+1}}=a\left( {{\mathbf{Y}}_{s}},s+1 \right)$,即为2.1中注意的地方。
$a\left( {{\mathbf{X}}_{i}},k \right)$包含从第i分辨率到第k分辨率的上采样(使用最近邻差值进行上采样,并使用1*1conv保证通道一致)或者下采样(1个3*3,stride=2的conv得到2x的下采样,2个3*3,stride=2的conv得到4x的下采样)操作。当i=k时,$a\left( \cdot ,\cdot \right)$为恒等连接(identify connection),即$a\left( {{\mathbf{X}}_{i}},k \right)={{\mathbf{X}}_{i}}$。
==================================================
2.3 HRNetV2和HRNetV1的区别
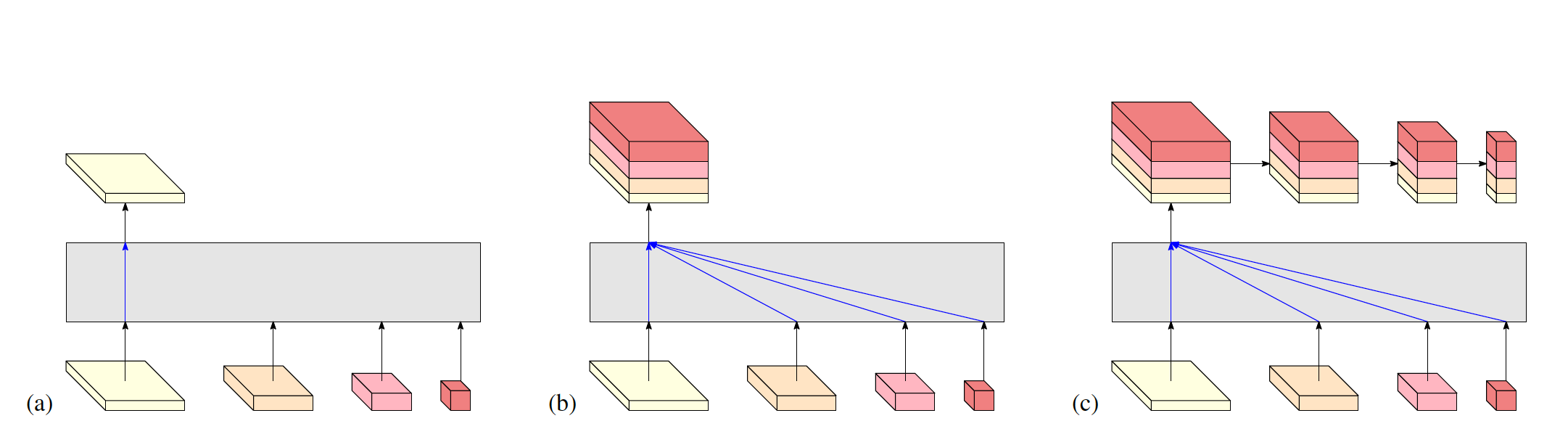
HRNetV1的最后一个阶段,只有最高分辨率的特征作为输出,如下图a所示,这意味着最后一个阶段只有高分辨率的特征会被利用,其他的低分辨率特征会被丢弃。HRNetV2最后一个阶段,使用bilinear插值将低分辨率的特征上采样到高分辨率,并拼接后作为最终的高分辨率特征,如下图b所示。b的方式直接用于分割、人脸关键点定位。多于目标检测,则将最后一个阶段的高分辨率特征使用平均池化下采样,得到多尺度特征,如下图c所示,简记为HRNet2p。
3 代码
HighResolutionNet代码如下:


1 blocks_dict = { 2 'BASIC': BasicBlock, 3 'BOTTLENECK': Bottleneck 4 } 5 6 7 class HighResolutionNet(nn.Module): 8 9 def __init__(self, config, **kwargs): 10 self.inplanes = 64 11 extra = config.MODEL.EXTRA 12 super(HighResolutionNet, self).__init__() 13 14 # stem net 15 self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=2, padding=1, bias=False) # 2个3*3的conv 16 self.bn1 = BatchNorm2d(64, momentum=BN_MOMENTUM) 17 self.conv2 = nn.Conv2d(64, 64, kernel_size=3, stride=2, padding=1, bias=False) 18 self.bn2 = BatchNorm2d(64, momentum=BN_MOMENTUM) 19 self.relu = nn.ReLU(inplace=True) 20 self.sf = nn.Softmax(dim=1) 21 22 self.layer1 = self._make_layer(Bottleneck, 64, 64, 4) # ResNet的第一个layer # 输入64,输出256维度 23 24 self.stage2_cfg = extra['STAGE2'] 25 num_channels = self.stage2_cfg['NUM_CHANNELS'] # 每个分辨率分支特征维数 26 block = blocks_dict[self.stage2_cfg['BLOCK']] # BasicBlock还是Bottleneck 27 num_channels = [num_channels[i] * block.expansion for i in range(len(num_channels))] # 每个分辨率分支特征维数 28 self.transition1 = self._make_transition_layer([256], num_channels) # self.layer1输出为256维,因而此处为[256] 29 self.stage2, pre_stage_channels = self._make_stage(self.stage2_cfg, num_channels) 30 31 self.stage3_cfg = extra['STAGE3'] 32 num_channels = self.stage3_cfg['NUM_CHANNELS'] 33 block = blocks_dict[self.stage3_cfg['BLOCK']] 34 num_channels = [num_channels[i] * block.expansion for i in range(len(num_channels))] 35 self.transition2 = self._make_transition_layer(pre_stage_channels, num_channels) 36 self.stage3, pre_stage_channels = self._make_stage(self.stage3_cfg, num_channels) 37 38 self.stage4_cfg = extra['STAGE4'] 39 num_channels = self.stage4_cfg['NUM_CHANNELS'] 40 block = blocks_dict[self.stage4_cfg['BLOCK']] 41 num_channels = [num_channels[i] * block.expansion for i in range(len(num_channels))] 42 self.transition3 = self._make_transition_layer(pre_stage_channels, num_channels) 43 self.stage4, pre_stage_channels = self._make_stage(self.stage4_cfg, num_channels, multi_scale_output=True) 44 45 final_inp_channels = sum(pre_stage_channels) # 拼接后最终的特征维数 46 47 self.head = nn.Sequential( # 1*1 conv(维度不变) + BN + ReLU + 1*1 conv(降维)用于得到面部关键点数量的热图 48 nn.Conv2d(in_channels=final_inp_channels, out_channels=final_inp_channels, kernel_size=1, 49 stride=1, padding=1 if extra.FINAL_CONV_KERNEL == 3 else 0), 50 BatchNorm2d(final_inp_channels, momentum=BN_MOMENTUM), 51 nn.ReLU(inplace=True), 52 nn.Conv2d(in_channels=final_inp_channels, out_channels=config.MODEL.NUM_JOINTS, 53 kernel_size=extra.FINAL_CONV_KERNEL, stride=1, padding=1 if extra.FINAL_CONV_KERNEL == 3 else 0) 54 ) 55 56 def _make_transition_layer(self, num_channels_pre_layer, num_channels_cur_layer): 57 num_branches_cur = len(num_channels_cur_layer) # 当前层的分辨率个数 num_channels_pre_layer, num_channels_cur_layer均为list 58 num_branches_pre = len(num_channels_pre_layer) # 之前层的分辨率个数 num_channels_pre_layer, num_channels_cur_layer均为list 59 60 transition_layers = [] 61 for i in range(num_branches_cur): # 依次遍历当前层的每个分辨率 62 if i < num_branches_pre: # 之前层有当前子层的分辨率 63 if num_channels_cur_layer[i] != num_channels_pre_layer[i]: # 当前子层的通道数量和之前子层的通道数量不同,stage2的transition1为16!=256 64 transition_layers.append(nn.Sequential( # 3*3 conv + BN + ReLU 用于维度匹配 65 nn.Conv2d(num_channels_pre_layer[i], num_channels_cur_layer[i], 3, 1, 1, bias=False), 66 BatchNorm2d(num_channels_cur_layer[i], momentum=BN_MOMENTUM), 67 nn.ReLU(inplace=True))) 68 else: 69 transition_layers.append(None) # 当前子层的通道数量和之前子层的通道数量相同,给出的模型均这样 70 else: 71 conv3x3s = [] 72 # 如果num_branches_cur=num_branches_pre+1,则一个[conv(num_channels_pre_layer[-1], num_channels_cur_layer[-1])_stride_2] 73 # 如果num_branches_cur=num_branches_pre+2,则(目前下面的情况均不存在): 74 # [ conv(pre[-1],cur[-1])_stride_2, ,会出现当前分辨率宽高降低的情况 75 # conv(pre[-1],pre[-1])_stride_2 + conv(pre[-1],cur[-1])_stride_2, ] 会出现当前分辨率宽高降低的情况 76 # 如果num_branches_cur=num_branches_pre+3,则: 77 # [ conv(pre[-1],cur[-1])_stride_2, ,会出现当前分辨率宽高降低的情况 78 # conv(pre[-1],pre[-1])_stride_2 + conv(pre[-1],cur[-1])_stride_2 ,会出现当前分辨率宽高降低的情况 79 # conv(pre[-1],pre[-1])_stride_2 + conv(pre[-1],pre[-1])_stride_2 + conv(pre[-1],cur[-1])_stride_2, ] 会出现当前分辨率宽高降低的情况 80 for j in range(i + 1 - num_branches_pre): # stride=2的降维卷积 81 inchannels = num_channels_pre_layer[-1] 82 outchannels = num_channels_cur_layer[i] if j == i - num_branches_pre else inchannels 83 conv3x3s.append(nn.Sequential( 84 nn.Conv2d(inchannels, outchannels, 3, 2, 1, bias=False), 85 BatchNorm2d(outchannels, momentum=BN_MOMENTUM), 86 nn.ReLU(inplace=True))) 87 transition_layers.append(nn.Sequential(*conv3x3s)) 88 89 return nn.ModuleList(transition_layers) 90 91 def _make_layer(self, block, inplanes, planes, blocks, stride=1): # 输入64,输出256维度 92 downsample = None 93 if stride != 1 or inplanes != planes * block.expansion: 94 downsample = nn.Sequential( # 64==》64*4的1*1卷积,用于维度变换 95 nn.Conv2d(inplanes, planes * block.expansion, kernel_size=1, stride=stride, bias=False), 96 BatchNorm2d(planes * block.expansion, momentum=BN_MOMENTUM), 97 ) 98 99 layers = [] 100 layers.append(block(inplanes, planes, stride, downsample)) # 只有一个_make_layer,(64=>64)=>(64=>64)=>(64=>64*4)的1个Bottleneck 101 inplanes = planes * block.expansion 102 for i in range(1, blocks): 103 layers.append(block(inplanes, planes)) # (64*4=>64)=>(64=>64)=>(64=>64*4)的3个Bottleneck 104 105 return nn.Sequential(*layers) 106 107 def _make_stage(self, layer_config, num_inchannels, multi_scale_output=True): 108 num_modules = layer_config['NUM_MODULES'] # 当前层重复次数 109 num_branches = layer_config['NUM_BRANCHES'] # 当前层的分辨率分支数 110 num_blocks = layer_config['NUM_BLOCKS'] # 每个分辨率重复block的个数 111 num_channels = layer_config['NUM_CHANNELS'] # 当前层各分辨率通道个数 112 block = blocks_dict[layer_config['BLOCK']] # BasicBlock还是Bottleneck 113 fuse_method = layer_config['FUSE_METHOD'] # SUM 114 115 modules = [] 116 for i in range(num_modules): # 重复当前多分辨率分支的次数 117 # multi_scale_output is only used last module 118 if not multi_scale_output and i == num_modules - 1: # multi_scale_output==True,HRNet V2中此处永远不会执行 119 reset_multi_scale_output = False 120 else: 121 reset_multi_scale_output = True # HRNet V2中此处恒为True 122 modules.append( # [num_inchannels] = [num_channels*block.expansion] 123 HighResolutionModule(num_branches, block, num_blocks, num_inchannels, 124 num_channels, fuse_method, reset_multi_scale_output)) 125 num_inchannels = modules[-1].get_num_inchannels() 126 127 return nn.Sequential(*modules), num_inchannels 128 129 def forward(self, x): 130 # h, w = x.size(2), x.size(3) 131 x = self.conv1(x) 132 x = self.bn1(x) 133 x = self.relu(x) 134 x = self.conv2(x) 135 x = self.bn2(x) 136 x = self.relu(x) 137 x = self.layer1(x) 138 139 x_list = [] 140 for i in range(self.stage2_cfg['NUM_BRANCHES']): # NUM_BRANCHES为当前层的分辨率分支数 141 if self.transition1[i] is not None: # stage2的transition1的两个分辨率分支都不为None(一个维度匹配,一个降分辨率) 142 x_list.append(self.transition1[i](x)) 143 else: 144 x_list.append(x) 145 y_list = self.stage2(x_list) # 在对应stage中会重复NUM_MODULES个HighResolutionModule 146 147 x_list = [] 148 for i in range(self.stage3_cfg['NUM_BRANCHES']): # NUM_BRANCHES为当前层的分辨率分支数 149 if self.transition2[i] is not None: 150 x_list.append(self.transition2[i](y_list[-1])) # 将前一个分辨率的最后一个分支输入当前transition_layer 151 else: 152 x_list.append(y_list[i]) # 前一个分辨率的其他分支直接输入当前分辨率对应分支 153 y_list = self.stage3(x_list) # 在对应stage中会重复NUM_MODULES个HighResolutionModule 154 155 x_list = [] 156 for i in range(self.stage4_cfg['NUM_BRANCHES']): # NUM_BRANCHES为当前层的分辨率分支数 157 if self.transition3[i] is not None: 158 x_list.append(self.transition3[i](y_list[-1])) # 将前一个分辨率的最后一个分支输入当前transition_layer 159 else: 160 x_list.append(y_list[i]) # 前一个分辨率的其他分支直接输入当前分辨率对应分支 161 x = self.stage4(x_list) # 在对应stage中会重复NUM_MODULES个HighResolutionModule 162 163 # Head Part 164 height, width = x[0].size(2), x[0].size(3) # 得到宽高 165 x1 = F.interpolate(x[1], size=(height, width), mode='bilinear', align_corners=False) # 其他分辨率差值到x[0]宽高 166 x2 = F.interpolate(x[2], size=(height, width), mode='bilinear', align_corners=False) # 其他分辨率差值到x[0]宽高 167 x3 = F.interpolate(x[3], size=(height, width), mode='bilinear', align_corners=False) # 其他分辨率差值到x[0]宽高 168 x = torch.cat([x[0], x1, x2, x3], 1) # 拼接特征 169 x = self.head(x) # 1*1 conv(维度不变) + BN + ReLU + 1*1 conv(降维)用于得到面部关键点数量的热图 170 171 return x 172 173 def init_weights(self, pretrained=''): 174 logger.info('=> init weights from normal distribution') 175 for m in self.modules(): 176 if isinstance(m, nn.Conv2d): 177 # nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu') 178 nn.init.normal_(m.weight, std=0.001) 179 # nn.init.constant_(m.bias, 0) 180 elif isinstance(m, nn.BatchNorm2d): 181 nn.init.constant_(m.weight, 1) 182 nn.init.constant_(m.bias, 0) 183 if os.path.isfile(pretrained): 184 pretrained_dict = torch.load(pretrained) 185 logger.info('=> loading pretrained model {}'.format(pretrained)) 186 model_dict = self.state_dict() 187 pretrained_dict = {k: v for k, v in pretrained_dict.items() if k in model_dict.keys()} 188 for k, _ in pretrained_dict.items(): 189 logger.info('=> loading {} pretrained model {}'.format(k, pretrained)) 190 model_dict.update(pretrained_dict) 191 self.load_state_dict(model_dict)
上面extra = config.MODEL.EXTRA位于experiments/alfw(300w,cofw,wflw)/face_alignment_aflw_hrnet_w18.yaml中,如下:
1 EXTRA: 2 FINAL_CONV_KERNEL: 1 3 STAGE2: 4 NUM_MODULES: 1 5 NUM_BRANCHES: 2 6 BLOCK: BASIC 7 NUM_BLOCKS: 8 - 4 9 - 4 10 NUM_CHANNELS: 11 - 18 12 - 36 13 FUSE_METHOD: SUM 14 STAGE3: 15 NUM_MODULES: 4 16 NUM_BRANCHES: 3 17 BLOCK: BASIC 18 NUM_BLOCKS: 19 - 4 20 - 4 21 - 4 22 NUM_CHANNELS: 23 - 18 24 - 36 25 - 72 26 FUSE_METHOD: SUM 27 STAGE4: 28 NUM_MODULES: 3 29 NUM_BRANCHES: 4 30 BLOCK: BASIC 31 NUM_BLOCKS: 32 - 4 33 - 4 34 - 4 35 - 4 36 NUM_CHANNELS: 37 - 18 38 - 36 39 - 72 40 - 144 41 FUSE_METHOD: SUM
_make_layer实际上和ResNet的layer一致。
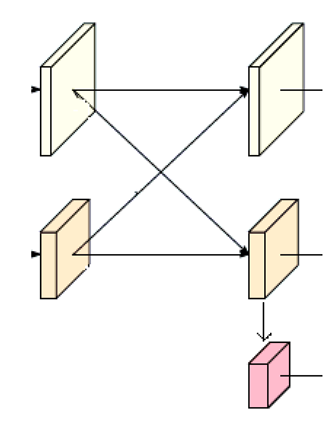
_make_transition_layer结构如下:
HighResolutionModule如下:
1 class HighResolutionModule(nn.Module): 2 def __init__(self, num_branches, blocks, num_blocks, num_inchannels, 3 num_channels, fuse_method, multi_scale_output=True): 4 ''' num_branches 分辨率分支个数 5 block BasicBlock还是Bottleneck 6 num_blocks 重复block的个数 7 num_inchannels [输入通道个数] # [num_inchannels] = [num_channels*block.expansion] 8 num_channels [当前通道个数] # num_channels=layer_config['NUM_CHANNELS'] 9 fuse_method SUM 10 reset_multi_scale_output multi_scale_output==True''' 11 super(HighResolutionModule, self).__init__() 12 self._check_branches(num_branches, blocks, num_blocks, num_inchannels, num_channels) 13 14 self.num_inchannels = num_inchannels # [self.num_inchannels] = [num_channels*block.expansion] 15 self.fuse_method = fuse_method 16 self.num_branches = num_branches 17 self.multi_scale_output = multi_scale_output # 恒为True 18 19 self.branches = self._make_branches(num_branches, blocks, num_blocks, num_channels) 20 self.fuse_layers = self._make_fuse_layers() 21 self.relu = nn.ReLU(inplace=True) 22 23 def _check_branches(self, num_branches, blocks, num_blocks, num_inchannels, num_channels): 24 if num_branches != len(num_blocks): 25 error_msg = 'NUM_BRANCHES({}) <> NUM_BLOCKS({})'.format(num_branches, len(num_blocks)) 26 logger.error(error_msg) 27 raise ValueError(error_msg) 28 29 if num_branches != len(num_channels): 30 error_msg = 'NUM_BRANCHES({}) <> NUM_CHANNELS({})'.format(num_branches, len(num_channels)) 31 logger.error(error_msg) 32 raise ValueError(error_msg) 33 34 if num_branches != len(num_inchannels): 35 error_msg = 'NUM_BRANCHES({}) <> NUM_INCHANNELS({})'.format(num_branches, len(num_inchannels)) 36 logger.error(error_msg) 37 raise ValueError(error_msg) 38 39 def _make_one_branch(self, branch_index, block, num_blocks, num_channels, stride=1): 40 downsample = None # BasicBlock时downsample=None Bottleneck时进行维度匹配 41 if stride != 1 or self.num_inchannels[branch_index] != num_channels[branch_index] * block.expansion: # stride == 1 42 downsample = nn.Sequential( # [self.num_inchannels] = [num_channels*block.expansion] 1*1 conv维度匹配 43 nn.Conv2d(self.num_inchannels[branch_index], num_channels[branch_index] * block.expansion, 44 kernel_size=1, stride=stride, bias=False), 45 BatchNorm2d(num_channels[branch_index] * block.expansion, momentum=BN_MOMENTUM), 46 ) 47 48 layers = [] 49 # BasicBlock:(num_channels*block.expansion=>num_channels) => (num_channels=>num_channels*block.expansion) # block.expansion=1 50 # Bottleneck:(num_channels*block.expansion=>num_channels) => (num_channels=>num_channels) => 51 # (num_channels=>num_channels*block.expansion) # block.expansion=4 52 layers.append(block(self.num_inchannels[branch_index], num_channels[branch_index], stride, downsample)) # 1个维度匹配的block 53 # 经过上面block,输出维度可能变化了,因而此处更新接下来block的输入维度 54 self.num_inchannels[branch_index] = num_channels[branch_index] * block.expansion 55 for i in range(1, num_blocks[branch_index]): # 3个维度不变的block 56 layers.append(block(self.num_inchannels[branch_index], num_channels[branch_index])) # 此处输入维度和输出维度一样 57 58 return nn.Sequential(*layers) 59 60 def _make_branches(self, num_branches, block, num_blocks, num_channels): 61 branches = [] 62 for i in range(num_branches): # 依次将不同分辨率分支append到branches中 63 branches.append(self._make_one_branch(i, block, num_blocks, num_channels)) # 依次增加一个分辨率分支 64 65 return nn.ModuleList(branches) 66 67 def _make_fuse_layers(self): 68 # stage 3,3个branch,BasicBlock时,num_inchannels=[18, 36, 72] 69 # i j k fuse_layer 70 # 71 # 0 0 x None 72 # 0 1 x 1*1_conv(36, 18) + BN # M1 73 # 0 2 x 1*1_conv(72, 18) + BN # M2 74 # 75 # 1 0 0 3*3_conv(18, 36)_stride_2 + BN # M3 76 # 1 1 x None 77 # 1 2 x 1*1_conv(72, 36) + BN # M4 78 # 79 # 2 0 0 3*3_conv(18, 72)_stride_2 + BN + ReLU # M5 80 # 2 0 1 3*3_conv(18, 72)_stride_2 + BN # M6 81 # 2 1 0 3*3_conv(36, 72)_stride_2 + BN # M7 82 # 2 2 x None 83 84 if self.num_branches == 1: # 分辨率分支个数,目前不会出现1,此处不执行 85 return None 86 87 num_branches = self.num_branches # 分辨率分支个数 88 num_inchannels = self.num_inchannels # [输入通道个数] # [self.num_inchannels] = [num_channels*block.expansion] 89 fuse_layers = [] 90 for i in range(num_branches if self.multi_scale_output else 1): # self.multi_scale_output==True,for i in range(num_branches) 91 fuse_layer = [] 92 for j in range(num_branches): 93 if j > i: 94 fuse_layer.append(nn.Sequential( 95 nn.Conv2d(num_inchannels[j], num_inchannels[i], 1, 1, 0, bias=False), 96 BatchNorm2d(num_inchannels[i], momentum=BN_MOMENTUM))) 97 # nn.Upsample(scale_factor=2**(j-i), mode='nearest'))) 98 elif j == i: 99 fuse_layer.append(None) 100 else: 101 conv3x3s = [] 102 for k in range(i - j): 103 if k == i - j - 1: 104 num_outchannels_conv3x3 = num_inchannels[i] 105 conv3x3s.append(nn.Sequential( 106 nn.Conv2d(num_inchannels[j], num_outchannels_conv3x3, 3, 2, 1, bias=False), 107 BatchNorm2d(num_outchannels_conv3x3, momentum=BN_MOMENTUM))) 108 else: 109 num_outchannels_conv3x3 = num_inchannels[j] 110 conv3x3s.append(nn.Sequential( 111 nn.Conv2d(num_inchannels[j], num_outchannels_conv3x3, 3, 2, 1, bias=False), 112 BatchNorm2d(num_outchannels_conv3x3, momentum=BN_MOMENTUM), 113 nn.ReLU(inplace=True))) 114 fuse_layer.append(nn.Sequential(*conv3x3s)) 115 fuse_layers.append(nn.ModuleList(fuse_layer)) 116 117 return nn.ModuleList(fuse_layers) 118 119 def get_num_inchannels(self): 120 return self.num_inchannels # 最终输出的维度就是这个 121 122 def forward(self, x): 123 if self.num_branches == 1: # 分辨率分支个数,目前不会出现1,此处不执行 124 return [self.branches[0](x[0])] # self.branches和x均为list,因而此处取self.branches[0]和x[0] 125 126 for i in range(self.num_branches): # 将x[i]输入self.branches[i],得到第i个分辨率分支的输出x[i] 127 x[i] = self.branches[i](x[i]) 128 129 # stage 3,3个branch,BasicBlock时,num_inchannels=num_inchannels=[18, 36, 72] 130 # 下面的x[i]均为上面 第i个分辨率分支的输出x[i]。最终每个分辨率的输出,均是x[0]、x[1]、x[2]融合的结果(下面的三个输出) 131 # i y1 j y 132 # 133 # 0 x[0] 1 x[0] + interpolate(M1(x[1])) 中间 134 # 0 x[0] 2 ReLU(x[0] + interpolate(M1(x[1])) + interpolate(M2(x[2]))) 输出 135 # 136 # 1 M3(x[0]) 1 M3(x[0]) + x[1] 中间 137 # 1 M3(x[0]) 2 ReLU(M3(x[0]) + x[1] + interpolate(M4(x[2]))) 输出 138 # 139 # 2 M6(M5(x[0])) 0 M6(M5(x[0])) + M7(x[1]) 中间 140 # 2 M6(M5(x[0])) 1 ReLU(M6(M5(x[0])) + M7(x[1]) + x[2]) 输出 141 x_fuse = [] 142 for i in range(len(self.fuse_layers)): # 依次遍历每个分辨率分支,进行融合 143 y = x[0] if i == 0 else self.fuse_layers[i][0](x[0]) # y1 144 for j in range(1, self.num_branches): 145 if i == j: 146 y = y + x[j] # y 中间 147 elif j > i: 148 y = y + F.interpolate(self.fuse_layers[i][j](x[j]), # y 中间 149 size=[x[i].shape[2], x[i].shape[3]], mode='bilinear') 150 else: 151 y = y + self.fuse_layers[i][j](x[j]) # y 中间 152 x_fuse.append(self.relu(y)) # y 输出 153 154 return x_fuse
4 不同具体模型的差异
4.1 HRNet V2 facial landmark detection VS HRNet V1
__init__

forward

4.2 HRNet V2 facial landmark detection VS HRNet V2 classification
__init__

forward

4.3 HRNet V2 facial landmark detection VS HRNet V2 detection
__init__
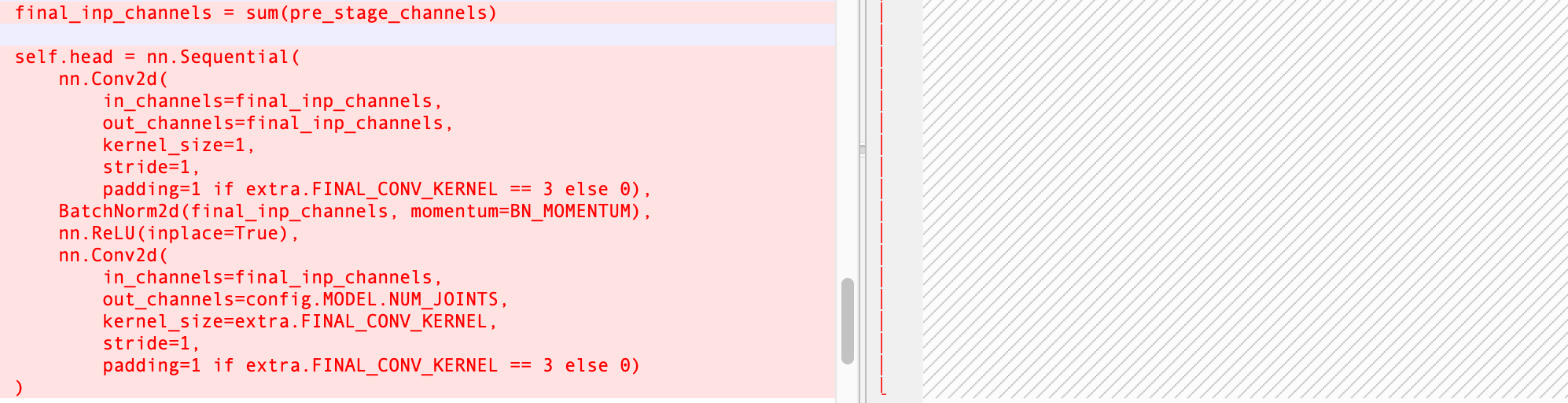
forward

4.4 HRNet V2 facial landmark detection VS HRNet V2 Semantic Segmentation
__init__

forward
(右侧为了节省显存,将BN和leaky ReLU合并。此处不包括激活函数,只是多卡同步的BN)

(upsample已被interpolate代替,此处实际一样)

posted on 2020-01-04 22:30 darkknightzh 阅读(5569) 评论(2) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号