(原)人脸姿态时别HYBRID COARSE-FINE CLASSIFICATION FOR HEAD POSE ESTIMATION
转载请注明出处:
https://www.cnblogs.com/darkknightzh/p/12150128.html
论文:
HYBRID COARSE-FINE CLASSIFICATION FOR HEAD POSE ESTIMATION
论文网址:
https://arxiv.org/abs/1901.06778
官方pytorch代码:
https://github.com/haofanwang/accurate-head-pose
该论文提出了coarse-fine的分类方式。
1. 网络结构
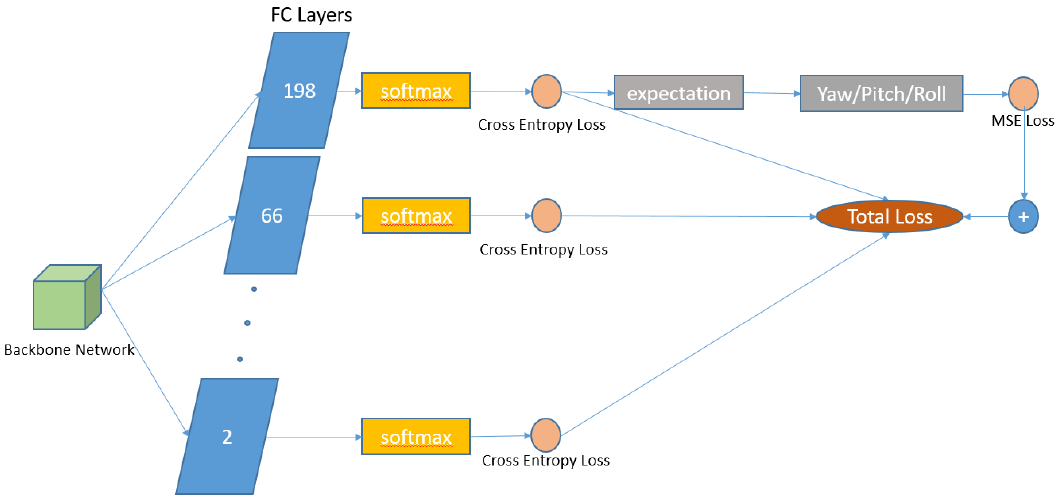
论文网络结构如下图所示。输入图像通过骨干网络得到特征后,分别连接到不同的fc层。这些fc层将输入特征映射到-99度至102度之内不同间隔的角度区间(间隔分别为1,3,11,33,99),而后通过softmax得到归一化特征,并分2支,一方面计算期望及期望与真值的MSE loss,另一方面计算交叉熵损失。而后求和,得到最终的损失。
1) MSE loss和deep head pose中接近(区别是此处使用198个类别的分类结果计算期望,deep head pose使用66个类别)。
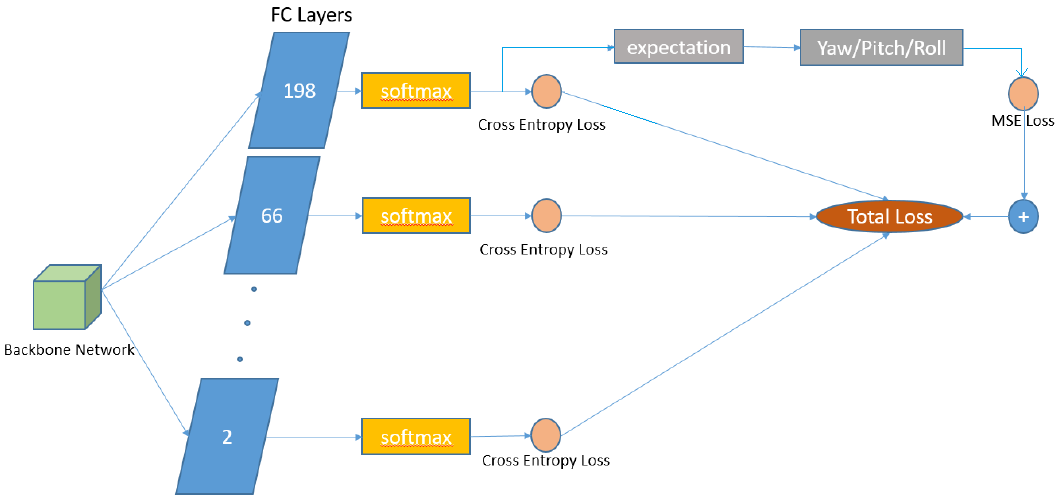
2) 其他角度区间(除198个类别的角度区间之外)只用于计算交叉熵损失(如下图所示)。
3) 不同角度区间的交叉熵损失权重不同。
4) 本文MSE损失的权重较大(为2)
5) 训练时使用softmax计算概率。测试时使用带temperature的softmax计算概率(由于代码中T=1,实际上等效于softmax)。
6) 从https://arxiv.org/abs/1503.02531可知,给定输入logit ${{z}_{i}}$,其softmax temperature的输出${{q}_{i}}$计算如下:
${{q}_{i}}=\frac{\exp ({{z}_{i}}/T)}{\sum\nolimits_{j}{\exp ({{z}_{j}}/T)}}$
其中T为temperature。通常设置为1(即为softmax)。T越大,输出概率的差异性越小;T越小(越接近0),输出概率的差异性越大。
因而,感觉上图变成下面这样,会更容易理解:
本文损失函数如下:
$Loss=\alpha \centerdot MSE(y,{{y}^{*}})+\sum\limits_{i=1}^{num}{{{\beta }_{i}}\centerdot H({{y}_{i}},y_{i}^{*})}$
其中H代表交叉熵损失。${{\beta }_{i}}$为不同角度区间时交叉熵损失的权重(具体权重可参见代码)。
2. 代码
2.1 网络结构


1 class Multinet(nn.Module): 2 # Hopenet with 3 output layers for yaw, pitch and roll 3 # Predicts Euler angles by binning and regression with the expected value 4 def __init__(self, block, layers, num_bins): 5 self.inplanes = 64 6 super(Multinet, self).__init__() 7 self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False) 8 self.bn1 = nn.BatchNorm2d(64) 9 self.relu = nn.ReLU(inplace=True) 10 self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) 11 self.layer1 = self._make_layer(block, 64, layers[0]) 12 self.layer2 = self._make_layer(block, 128, layers[1], stride=2) 13 self.layer3 = self._make_layer(block, 256, layers[2], stride=2) 14 self.layer4 = self._make_layer(block, 512, layers[3], stride=2) 15 self.avgpool = nn.AvgPool2d(7) # 至此为Resnet的骨干网络 16 self.fc_yaw = nn.Linear(512 * block.expansion, num_bins) # 和hopenet类似,只是num_bins=198 17 self.fc_pitch = nn.Linear(512 * block.expansion, num_bins) # 和hopenet类似,只是num_bins=198 18 self.fc_roll = nn.Linear(512 * block.expansion, num_bins) # 和hopenet类似,只是num_bins=198 19 20 self.fc_yaw_1 = nn.Linear(512 * block.expansion, 66) # 66和deep head pose一致 21 self.fc_yaw_2 = nn.Linear(512 * block.expansion, 18) # 其他为新的fc层 22 self.fc_yaw_3 = nn.Linear(512 * block.expansion, 6) 23 self.fc_yaw_4 = nn.Linear(512 * block.expansion, 2) 24 25 self.fc_pitch_1 = nn.Linear(512 * block.expansion, 66) 26 self.fc_pitch_2 = nn.Linear(512 * block.expansion, 18) 27 self.fc_pitch_3 = nn.Linear(512 * block.expansion, 6) 28 self.fc_pitch_4 = nn.Linear(512 * block.expansion, 2) 29 30 self.fc_roll_1 = nn.Linear(512 * block.expansion, 66) 31 self.fc_roll_2 = nn.Linear(512 * block.expansion, 18) 32 self.fc_roll_3 = nn.Linear(512 * block.expansion, 6) 33 self.fc_roll_4 = nn.Linear(512 * block.expansion, 2) 34 35 # Vestigial layer from previous experiments 36 self.fc_finetune = nn.Linear(512 * block.expansion + 3, 3) # 未使用 37 38 for m in self.modules(): 39 if isinstance(m, nn.Conv2d): 40 n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels 41 m.weight.data.normal_(0, math.sqrt(2. / n)) 42 elif isinstance(m, nn.BatchNorm2d): 43 m.weight.data.fill_(1) 44 m.bias.data.zero_() 45 46 def _make_layer(self, block, planes, blocks, stride=1): 47 downsample = None 48 if stride != 1 or self.inplanes != planes * block.expansion: 49 downsample = nn.Sequential( 50 nn.Conv2d(self.inplanes, planes * block.expansion, 51 kernel_size=1, stride=stride, bias=False), 52 nn.BatchNorm2d(planes * block.expansion), 53 ) 54 55 layers = [] 56 layers.append(block(self.inplanes, planes, stride, downsample)) 57 self.inplanes = planes * block.expansion 58 for i in range(1, blocks): 59 layers.append(block(self.inplanes, planes)) 60 61 return nn.Sequential(*layers) 62 63 def forward(self, x): 64 x = self.conv1(x) 65 x = self.bn1(x) 66 x = self.relu(x) 67 x = self.maxpool(x) 68 69 x = self.layer1(x) 70 x = self.layer2(x) 71 x = self.layer3(x) 72 x = self.layer4(x) 73 74 x = self.avgpool(x) 75 x = x.view(x.size(0), -1) # 得到骨干网络的特征 76 pre_yaw = self.fc_yaw(x) # 以下得到yaw、pitch、roll等的其他特征 77 pre_pitch = self.fc_pitch(x) 78 pre_roll = self.fc_roll(x) 79 80 pre_yaw_1 = self.fc_yaw_1(x) 81 pre_pitch_1 = self.fc_pitch_1(x) 82 pre_roll_1 = self.fc_roll_1(x) 83 84 pre_yaw_2 = self.fc_yaw_2(x) 85 pre_pitch_2 = self.fc_pitch_2(x) 86 pre_roll_2 = self.fc_roll_2(x) 87 88 pre_yaw_3 = self.fc_yaw_3(x) 89 pre_pitch_3 = self.fc_pitch_3(x) 90 pre_roll_3 = self.fc_roll_3(x) 91 92 pre_yaw_4 = self.fc_yaw_4(x) 93 pre_pitch_4 = self.fc_pitch_4(x) 94 pre_roll_4 = self.fc_roll_4(x) 95 96 return pre_yaw,pre_yaw_1,pre_yaw_2,pre_yaw_3,pre_yaw_4, pre_pitch,pre_pitch_1,pre_pitch_2,pre_pitch_3,pre_pitch_4, pre_roll,pre_roll_1,pre_roll_2,pre_roll_3,pre_roll_4
2.2 训练代码
1 def parse_args(): 2 """Parse input arguments.""" 3 parser = argparse.ArgumentParser(description='Head pose estimation using the Hopenet network.') 4 parser.add_argument('--gpu', dest='gpu_id', help='GPU device id to use [0]', default=0, type=int) 5 parser.add_argument('--num_epochs', dest='num_epochs', help='Maximum number of training epochs.', default=25, type=int) 6 parser.add_argument('--batch_size', dest='batch_size', help='Batch size.', default=32, type=int) 7 parser.add_argument('--lr', dest='lr', help='Base learning rate.', default=0.000001, type=float) 8 parser.add_argument('--dataset', dest='dataset', help='Dataset type.', default='AFLW_multi', type=str) 9 parser.add_argument('--data_dir', dest='data_dir', help='Directory path for data.', default='', type=str) 10 parser.add_argument('--filename_list', dest='filename_list', help='Path to text file containing relative paths for every example.', default='/tools/AFLW_train.txt', type=str) 11 parser.add_argument('--output_string', dest='output_string', help='String appended to output snapshots.', default = '', type=str) 12 parser.add_argument('--alpha', dest='alpha', help='Regression loss coefficient.', default=2, type=float) 13 parser.add_argument('--snapshot', dest='snapshot', help='Path of model snapshot.', default='', type=str) 14 15 args = parser.parse_args() 16 return args 17 18 def get_ignored_params(model): 19 # Generator function that yields ignored params. 20 b = [model.conv1, model.bn1, model.fc_finetune] 21 for i in range(len(b)): 22 for module_name, module in b[i].named_modules(): 23 if 'bn' in module_name: 24 module.eval() 25 for name, param in module.named_parameters(): 26 yield param 27 28 def get_non_ignored_params(model): 29 # Generator function that yields params that will be optimized. 30 b = [model.layer1, model.layer2, model.layer3, model.layer4] 31 for i in range(len(b)): 32 for module_name, module in b[i].named_modules(): 33 if 'bn' in module_name: 34 module.eval() 35 for name, param in module.named_parameters(): 36 yield param 37 38 def get_fc_params(model): 39 # Generator function that yields fc layer params. 40 b = [model.fc_yaw, model.fc_pitch, model.fc_roll, 41 model.fc_yaw_1, model.fc_pitch_1, model.fc_roll_1, 42 model.fc_yaw_2, model.fc_pitch_2, model.fc_roll_2, 43 model.fc_yaw_3, model.fc_pitch_3, model.fc_roll_3] 44 for i in range(len(b)): 45 for module_name, module in b[i].named_modules(): 46 for name, param in module.named_parameters(): 47 yield param 48 49 def load_filtered_state_dict(model, snapshot): 50 # By user apaszke from discuss.pytorch.org 51 model_dict = model.state_dict() 52 snapshot = {k: v for k, v in snapshot.items() if k in model_dict} 53 model_dict.update(snapshot) 54 model.load_state_dict(model_dict) 55 56 if __name__ == '__main__': 57 args = parse_args() 58 59 cudnn.enabled = True 60 num_epochs = args.num_epochs 61 batch_size = args.batch_size 62 gpu = args.gpu_id 63 64 if not os.path.exists('output/snapshots'): 65 os.makedirs('output/snapshots') 66 67 # ResNet50 structure 68 model = hopenet.Multinet(torchvision.models.resnet.Bottleneck, [3, 4, 6, 3], 198) # 载入模型 69 70 if args.snapshot == '': 71 load_filtered_state_dict(model, model_zoo.load_url('https://download.pytorch.org/models/resnet50-19c8e357.pth')) 72 else: 73 saved_state_dict = torch.load(args.snapshot) 74 model.load_state_dict(saved_state_dict) 75 76 print('Loading data.') 77 78 transformations = transforms.Compose([transforms.Resize(240), 79 transforms.RandomCrop(224), transforms.ToTensor(), 80 transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])]) 81 82 if args.dataset == 'Pose_300W_LP': 83 pose_dataset = datasets.Pose_300W_LP(args.data_dir, args.filename_list, transformations) 84 elif args.dataset == 'Pose_300W_LP_multi': 85 pose_dataset = datasets.Pose_300W_LP_multi(args.data_dir, args.filename_list, transformations) 86 elif args.dataset == 'Pose_300W_LP_random_ds': 87 pose_dataset = datasets.Pose_300W_LP_random_ds(args.data_dir, args.filename_list, transformations) 88 elif args.dataset == 'Synhead': 89 pose_dataset = datasets.Synhead(args.data_dir, args.filename_list, transformations) 90 elif args.dataset == 'AFLW2000': 91 pose_dataset = datasets.AFLW2000(args.data_dir, args.filename_list, transformations) 92 elif args.dataset == 'BIWI': 93 pose_dataset = datasets.BIWI(args.data_dir, args.filename_list, transformations) 94 elif args.dataset == 'BIWI_multi': 95 pose_dataset = datasets.BIWI_multi(args.data_dir, args.filename_list, transformations) 96 elif args.dataset == 'AFLW': 97 pose_dataset = datasets.AFLW(args.data_dir, args.filename_list, transformations) 98 elif args.dataset == 'AFLW_multi': # 载入数据的dataset 99 pose_dataset = datasets.AFLW_multi(args.data_dir, args.filename_list, transformations) 100 elif args.dataset == 'AFLW_aug': 101 pose_dataset = datasets.AFLW_aug(args.data_dir, args.filename_list, transformations) 102 elif args.dataset == 'AFW': 103 pose_dataset = datasets.AFW(args.data_dir, args.filename_list, transformations) 104 else: 105 print('Error: not a valid dataset name') 106 sys.exit() 107 108 train_loader = torch.utils.data.DataLoader(dataset=pose_dataset, batch_size=batch_size, shuffle=True, num_workers=2) 109 110 model.cuda(gpu) 111 criterion = nn.CrossEntropyLoss().cuda(gpu) 112 reg_criterion = nn.MSELoss().cuda(gpu) 113 # Regression loss coefficient 114 alpha = args.alpha 115 116 softmax = nn.Softmax(dim=1).cuda(gpu) 117 idx_tensor = [idx for idx in range(198)] 118 idx_tensor = Variable(torch.FloatTensor(idx_tensor)).cuda(gpu) 119 120 optimizer = torch.optim.Adam([{'params': get_ignored_params(model), 'lr': 0}, 121 {'params': get_non_ignored_params(model), 'lr': args.lr}, 122 {'params': get_fc_params(model), 'lr': args.lr * 5}], 123 lr = args.lr) 124 125 print('Ready to train network.') 126 for epoch in range(num_epochs): 127 for i, (images, labels, labels_0, labels_1, labels_2, labels_3, cont_labels, name) in enumerate(train_loader): 128 images = Variable(images).cuda(gpu) 129 130 # Binned labels 131 label_yaw = Variable(labels[:,0]).cuda(gpu) 132 label_pitch = Variable(labels[:,1]).cuda(gpu) 133 label_roll = Variable(labels[:,2]).cuda(gpu) 134 135 label_yaw_1 = Variable(labels_0[:,0]).cuda(gpu) 136 label_pitch_1 = Variable(labels_0[:,1]).cuda(gpu) 137 label_roll_1 = Variable(labels_0[:,2]).cuda(gpu) 138 139 label_yaw_2 = Variable(labels_1[:,0]).cuda(gpu) 140 label_pitch_2 = Variable(labels_1[:,1]).cuda(gpu) 141 label_roll_2 = Variable(labels_1[:,2]).cuda(gpu) 142 143 label_yaw_3 = Variable(labels_2[:,0]).cuda(gpu) 144 label_pitch_3 = Variable(labels_2[:,1]).cuda(gpu) 145 label_roll_3 = Variable(labels_2[:,2]).cuda(gpu) 146 147 label_yaw_4 = Variable(labels_3[:,0]).cuda(gpu) 148 label_pitch_4 = Variable(labels_3[:,1]).cuda(gpu) 149 label_roll_4 = Variable(labels_3[:,2]).cuda(gpu) 150 151 # Continuous labels 152 label_yaw_cont = Variable(cont_labels[:,0]).cuda(gpu) 153 label_pitch_cont = Variable(cont_labels[:,1]).cuda(gpu) 154 label_roll_cont = Variable(cont_labels[:,2]).cuda(gpu) 155 156 # Forward pass 157 yaw,yaw_1,yaw_2,yaw_3,yaw_4, pitch,pitch_1,pitch_2,pitch_3,pitch_4, roll,roll_1,roll_2,roll_3,roll_4 = model(images) # 得到各个特征 158 159 # Cross entropy loss # 各个交叉熵损失 160 loss_yaw,loss_yaw_1,loss_yaw_2,loss_yaw_3,loss_yaw_4 = criterion(yaw, label_yaw),criterion(yaw_1, label_yaw_1),criterion(yaw_2, label_yaw_2),criterion(yaw_3, label_yaw_3),criterion(yaw_4, label_yaw_4) 161 loss_pitch,loss_pitch_1,loss_pitch_2,loss_pitch_3,loss_pitch_4 = criterion(pitch, label_pitch),criterion(pitch_1, label_pitch_1),criterion(pitch_2, label_pitch_2),criterion(pitch_3, label_pitch_3),criterion(pitch_4, label_pitch_4) 162 loss_roll,loss_roll_1,loss_roll_2,loss_roll_3,loss_roll_4 = criterion(roll, label_roll),criterion(roll_1, label_roll_1),criterion(roll_2, label_roll_2),criterion(roll_3, label_roll_3),criterion(roll_4, label_roll_4) 163 164 # MSE loss # 归一化特征 165 yaw_predicted = softmax(yaw) 166 pitch_predicted = softmax(pitch) 167 roll_predicted = softmax(roll) 168 169 yaw_predicted = torch.sum(yaw_predicted * idx_tensor, 1) - 99 # 此部分和deep head pose计算一致 170 pitch_predicted = torch.sum(pitch_predicted * idx_tensor, 1) - 99 171 roll_predicted = torch.sum(roll_predicted * idx_tensor, 1) - 99 172 173 loss_reg_yaw = reg_criterion(yaw_predicted, label_yaw_cont) # 此部分和deep head pose计算一致 174 loss_reg_pitch = reg_criterion(pitch_predicted, label_pitch_cont) 175 loss_reg_roll = reg_criterion(roll_predicted, label_roll_cont) 176 177 # Total loss 178 total_loss_yaw = alpha * loss_reg_yaw + 7*loss_yaw + 5*loss_yaw_1 + 3*loss_yaw_2 + 1*loss_yaw_3 + 1*loss_yaw_4 # 各个角度区间的加权总损失 179 total_loss_pitch = alpha * loss_reg_pitch + 7*loss_pitch + 5*loss_pitch_1 + 3*loss_pitch_2 + 1*loss_pitch_3 + 1*loss_pitch_4 180 total_loss_roll = alpha * loss_reg_roll + 7*loss_roll + 5*loss_roll_1 + 3*loss_roll_2 + 1*loss_roll_3 + 1*loss_pitch_4 181 182 loss_seq = [total_loss_yaw, total_loss_pitch, total_loss_roll] 183 grad_seq = [torch.tensor(1.0).cuda(gpu) for _ in range(len(loss_seq))] 184 optimizer.zero_grad() 185 torch.autograd.backward(loss_seq, grad_seq) 186 optimizer.step() 187 188 if (i+1) % 100 == 0: 189 print ('Epoch [%d/%d], Iter [%d/%d] Losses: Yaw %.4f, Pitch %.4f, Roll %.4f' 190 %(epoch+1, num_epochs, i+1, len(pose_dataset)//batch_size, total_loss_yaw.item(), total_loss_pitch.item(), total_loss_roll.item())) 191 # Save models at numbered epochs. 192 if epoch % 1 == 0 and epoch < num_epochs: 193 print('Taking snapshot...') 194 torch.save(model.state_dict(), 195 'output/snapshots/' + args.output_string + '_epoch_'+ str(epoch+1) + '.pkl')
2.3 测试代码
1 def parse_args(): 2 """Parse input arguments.""" 3 parser = argparse.ArgumentParser(description='Head pose estimation using the Hopenet network.') 4 parser.add_argument('--gpu', dest='gpu_id', help='GPU device id to use [0]', default=0, type=int) 5 parser.add_argument('--data_dir', dest='data_dir', help='Directory path for data.', default='/AFLW2000/', type=str) 6 parser.add_argument('--filename_list', dest='filename_list', help='Path to text file containing relative paths for every example.', 7 default='/tools/AFLW2000_filename_filtered.txt', type=str) 8 parser.add_argument('--snapshot', dest='snapshot', help='Name of model snapshot.', 9 default='/output/snapshots/AFLW2000/_epoch_9.pkl', type=str) 10 parser.add_argument('--batch_size', dest='batch_size', help='Batch size.', default=1, type=int) 11 parser.add_argument('--save_viz', dest='save_viz', help='Save images with pose cube.', default=False, type=bool) 12 parser.add_argument('--dataset', dest='dataset', help='Dataset type.', default='AFLW2000', type=str) 13 14 args = parser.parse_args() 15 16 return args 17 18 if __name__ == '__main__': 19 args = parse_args() 20 21 cudnn.enabled = True 22 gpu = args.gpu_id 23 snapshot_path = args.snapshot 24 25 # ResNet50 structure 26 model = hopenet.Multinet(torchvision.models.resnet.Bottleneck, [3, 4, 6, 3], 198) 27 28 print('Loading snapshot.') 29 # Load snapshot 30 saved_state_dict = torch.load(snapshot_path) 31 model.load_state_dict(saved_state_dict) 32 33 print('Loading data.') 34 35 transformations = transforms.Compose([transforms.Resize(224), 36 transforms.CenterCrop(224), transforms.ToTensor(), 37 transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])]) 38 39 if args.dataset == 'Pose_300W_LP': 40 pose_dataset = datasets.Pose_300W_LP(args.data_dir, args.filename_list, transformations) 41 elif args.dataset == 'Pose_300W_LP_multi': 42 pose_dataset = datasets.Pose_300W_LP_multi(args.data_dir, args.filename_list, transformations) 43 elif args.dataset == 'Pose_300W_LP_random_ds': 44 pose_dataset = datasets.Pose_300W_LP_random_ds(args.data_dir, args.filename_list, transformations) 45 elif args.dataset == 'Synhead': 46 pose_dataset = datasets.Synhead(args.data_dir, args.filename_list, transformations) 47 elif args.dataset == 'AFLW2000': 48 pose_dataset = datasets.AFLW2000(args.data_dir, args.filename_list, transformations) 49 elif args.dataset == 'BIWI': 50 pose_dataset = datasets.BIWI(args.data_dir, args.filename_list, transformations) 51 elif args.dataset == 'BIWI_multi': 52 pose_dataset = datasets.BIWI_multi(args.data_dir, args.filename_list, transformations) 53 elif args.dataset == 'AFLW': 54 pose_dataset = datasets.AFLW(args.data_dir, args.filename_list, transformations) 55 elif args.dataset == 'AFLW_multi': 56 pose_dataset = datasets.AFLW_multi(args.data_dir, args.filename_list, transformations) 57 elif args.dataset == 'AFLW_aug': 58 pose_dataset = datasets.AFLW_aug(args.data_dir, args.filename_list, transformations) 59 elif args.dataset == 'AFW': 60 pose_dataset = datasets.AFW(args.data_dir, args.filename_list, transformations) 61 else: 62 print('Error: not a valid dataset name') 63 sys.exit() 64 test_loader = torch.utils.data.DataLoader(dataset=pose_dataset, 65 batch_size=args.batch_size, 66 num_workers=2) 67 68 model.cuda(gpu) 69 70 print('Ready to test network.') 71 72 # Test the Model 73 model.eval() # Change model to 'eval' mode (BN uses moving mean/var). 74 total = 0 75 76 idx_tensor = [idx for idx in range(198)] 77 idx_tensor = torch.FloatTensor(idx_tensor).cuda(gpu) 78 79 yaw_error = .0 80 pitch_error = .0 81 roll_error = .0 82 83 l1loss = torch.nn.L1Loss(size_average=False) 84 for i, (images, labels, cont_labels, name) in enumerate(test_loader): 85 #for i, (images, labels, labels_0, labels_1, labels_2, labels_3, cont_labels, name) in enumerate(test_loader): 86 images = Variable(images).cuda(gpu) 87 total += cont_labels.size(0) 88 89 label_yaw = cont_labels[:,0].float() 90 label_pitch = cont_labels[:,1].float() 91 label_roll = cont_labels[:,2].float() 92 93 yaw,yaw_1,yaw_2,yaw_3,yaw_4, pitch,pitch_1,pitch_2,pitch_3,pitch_4, roll,roll_1,roll_2,roll_3,roll_4 = model(images) # 得到特征 94 95 # Binned predictions 96 _, yaw_bpred = torch.max(yaw.data, 1) 97 _, pitch_bpred = torch.max(pitch.data, 1) 98 _, roll_bpred = torch.max(roll.data, 1) 99 100 # Continuous predictions 101 yaw_predicted = utils.softmax_temperature(yaw.data, 1) # 带temperature的softmax 102 pitch_predicted = utils.softmax_temperature(pitch.data, 1) 103 roll_predicted = utils.softmax_temperature(roll.data, 1) 104 105 yaw_predicted = torch.sum(yaw_predicted * idx_tensor, 1).cpu() - 99 # 计算期望 106 pitch_predicted = torch.sum(pitch_predicted * idx_tensor, 1).cpu() - 99 107 roll_predicted = torch.sum(roll_predicted * idx_tensor, 1).cpu() - 99 108 109 # Mean absolute error 110 yaw_error += torch.sum(torch.abs(yaw_predicted - label_yaw)) 111 pitch_error += torch.sum(torch.abs(pitch_predicted - label_pitch)) 112 roll_error += torch.sum(torch.abs(roll_predicted - label_roll)) 113 114 # Save first image in batch with pose cube or axis. 115 if args.save_viz: 116 name = name[0] 117 if args.dataset == 'BIWI': 118 cv2_img = cv2.imread(os.path.join(args.data_dir, name + '_rgb.png')) 119 else: 120 cv2_img = cv2.imread(os.path.join(args.data_dir, name + '.jpg')) 121 if args.batch_size == 1: 122 error_string = 'y %.2f, p %.2f, r %.2f' % (torch.sum(torch.abs(yaw_predicted - label_yaw)), torch.sum(torch.abs(pitch_predicted - label_pitch)), torch.sum(torch.abs(roll_predicted - label_roll))) 123 cv2.putText(cv2_img, error_string, (30, cv2_img.shape[0]- 30), fontFace=1, fontScale=1, color=(0,0,255), thickness=2) 124 # utils.plot_pose_cube(cv2_img, yaw_predicted[0], pitch_predicted[0], roll_predicted[0], size=100) 125 utils.draw_axis(cv2_img, yaw_predicted[0], pitch_predicted[0], roll_predicted[0], tdx = 200, tdy= 200, size=100) 126 cv2.imwrite(os.path.join('output/images', name + '.jpg'), cv2_img) 127 128 print('Test error in degrees of the model on the ' + str(total) + 129 ' test images. Yaw: %.4f, Pitch: %.4f, Roll: %.4f, MAE: %.4f' % (yaw_error / total, 130 pitch_error / total, roll_error / total, (yaw_error+pitch_error+roll_error)/(3.0*total)))
2.4 softmax_temperature代码
1 def softmax_temperature(tensor, temperature): 2 result = torch.exp(tensor / temperature) 3 result = torch.div(result, torch.sum(result, 1).unsqueeze(1).expand_as(result)) # 带temperature的softmax 4 return result
posted on 2020-01-04 19:36 darkknightzh 阅读(989) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号