
一、什么是集合?
1、问题:为什么要使用数组?
在编程时,可以使用数组保存多个对象或数据,但数组长度在声明时已经决定了长度,一旦指定了数组的长度,那么这个数组长度就是不可变的;
但是,在编程过程中,往往会出现数量变化的数据,那么此时使用数组就有点乏力了,而且数组无法保存具有一定映射关系的数据,例如:隔壁——小王,花花——小红...;
这种数据看上去就像两个不同的数组,但是这两个数组之间的元素具有一定的关联关系;
因此,为了保存数量不确定,并且具有一定关联的映射的数据,Java提供了集合类供我们使用;
2、集合的作用?
主要负责保存,存放其他数据,因此集合类也可以被称为一类数据的容器类;
3、集合的分类:
所有集合都来源于
java.util包下,该包包含了对集合的一些定义和API工具,常用于日常的编码工作;
集合主要分为两类:Collection 和 Map;
以下为主要关系图:
参考博客:https://www.cnblogs.com/xiaoxi/p/6089984.html

简化图:
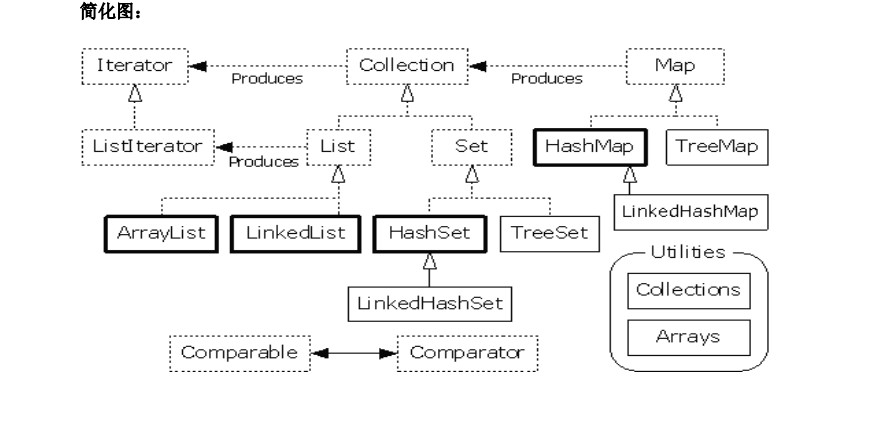
4、Stream 操作 Colletion 集合:
有上述分析可知,
Stream 可以操作基本集合类中,除了 Map 及其 派生对象以外的 所有集合对象;
二、Stream 的介绍:
参考博客:https://www.cnblogs.com/andywithu/p/7404101.html
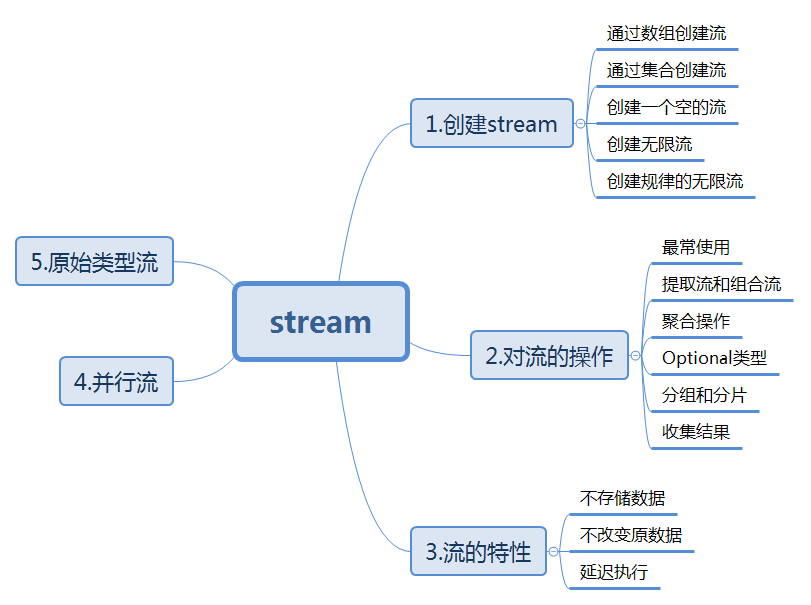
1、使用 Stream 的前提条件,会使用 Lambda表达式:
Java8 在原来面向对象的基础上,增加了函数式编程的能力,于是就出现了在 Java 中使用 Lambda 表达式;
其中 Java8 中提供的 Stream 就是一个使用函数式编程的对象,通过使用 Stream API 可以提高日常 编程 Java 程序员的生产力,让程序员写出高效、简洁、干净的代码;但对于不懂 Lambda 表达式的程序员,可读性就不太友好了;
例子:
public class Student {
private String name;
private String number;
private Integer score;
public Student() {
}
public Student(String name, String number, Integer score) {
this.name = name;
this.number = number;
this.score = score;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getNumber() {
return number;
}
public void setNumber(String number) {
this.number = number;
}
public Integer getScore() {
return score;
}
public void setScore(Integer score) {
this.score = score;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", number='" + number + '\'' +
", score=" + score +
'}';
}
}
@Test
public void TestString() {
List<Student> studentList = new ArrayList<Student>() {
{
add(new Student("小王", "dca", 78));
add(new Student("小红", "eca", 60));
add(new Student("小绿", "aca", 90));
}
};
System.out.println("------按学号进行排序(倒序)--------");
// 根据学号进行倒排
List<Student> studentList1 = studentList.stream()
.sorted(Comparator.comparing(Student::getNumber).reversed())
.collect(Collectors.toList());
for (Student student : studentList1) {
System.out.println(student.toString());
}
System.out.println("------按学号进行排序(正序序)并过滤出分数超过70分的人--------");
List<Student> studentList2 = studentList.stream()
.sorted(Comparator.comparing(Student::getNumber))
.filter(x -> x.getScore() > 70)
.collect(Collectors.toList());
for (Student student : studentList2) {
System.out.println(student.toString());
}
System.out.println("------对字符串进行排序--------");
List<String> strList = new ArrayList<>();
strList.add("ec");
strList.add("ce");
strList.add("fa");
strList.add("bh");
List<String> sortStrList = strList.stream().sorted(String::compareToIgnoreCase).collect(Collectors.toList());
for (String s : sortStrList) {
System.out.println(s);
}
}
执行以上 test 方法,控制台打印的结果为:
------按学号进行排序(倒序)--------
Student{name='小红', number='eca', score=60}
Student{name='小王', number='dca', score=78}
Student{name='小绿', number='aca', score=90}
------按学号进行排序(正序序)并过滤出分数超过70分的人--------
Student{name='小绿', number='aca', score=90}
Student{name='小王', number='dca', score=78}
------对字符串进行排序--------
bh
ce
ec
fa
创建 学生的集合,并放入三位学生的数据:
- 根据学生的学号进行排序(倒序);
- 根据学生的学号进行排序(正序序)并过滤出分数超过70分的人;
创建 字符串集合,并放入数条不同字符串;
对字符串集合中的字符串,按照字符串首字母,进行正序的排序,并把排好序的结果放到一个新的集合中;
2、Stream 的特性
不存储数据,不改变元数据,延迟执行特性
日常工作中一般我们都会在数组或集合的基础上创建 Stream,Stream 并不会专门存储数据;我们对 数组或集合上的 Stream 操作也不会影响 数组或集合上的数据;对于 Stream 的中间函数的操作,只能进行一次,如果重复进行多次操作函数,会在第二次重复操作时报错;
示例:
@Test
public void TestLambdaPrintTwo() {
List<String> stringList = new ArrayList<String>() {
{
add("cd");
add("ab");
add("ef");
}
};
Stream<String> stream = stringList.stream();
stream.forEach(System.out::println);
List <String> sortStrings = stream.sorted(String::compareToIgnoreCase).collect(Collectors.toList());
stream.forEach(System.out::println);
}
控制台打印结果为:
cd
ab
ef
java.lang.IllegalStateException: stream has already been operated upon or closed
可知程序在正常打印一次工作后,再次进行打印时报错;
Stream 的操作时延迟执行的,只有在 collect 执行后,才会执行之前的 filte、sorted、map等方法;
也就是说,在 collect 方法执行之前,Stream 的中间方法和末端方法都不会触发执行;
示例:
public Student map (Student s) {
System.out.println("----begin map 让每位学生分数给加10-----");
s.setScore(s.getScore() + 10);
return s;
}
@Test
public void TestSetTimeout() {
List<Student> studentList = new ArrayList<Student>() {
{
add(new Student("小王", "dca", 78));
add(new Student("小红", "eca", 60));
add(new Student("小绿", "aca", 90));
}
};
Stream<Student> studentStream = studentList.stream().map(this::map);
System.out.println("----end map 让每位学生分数给加10-----");
List<Student> studentList1 = studentStream.collect(Collectors.toList());
for (Student student : studentList1) {
System.out.println(student.toString());
}
}
打印的日志为:
----end map 让每位学生分数给加10-----
----begin map 让每位学生分数给加10-----
----begin map 让每位学生分数给加10-----
----begin map 让每位学生分数给加10-----
Student{name='小王', number='dca', score=88}
Student{name='小红', number='eca', score=70}
Student{name='小绿', number='aca', score=100}
Process finished with exit code 0
可知,原本
end字符串在studentStream后的,但是它被先打印了,之后studentStream调用了collect方法后,才开始执行map 中调用的方法;
总结得知:stream 是延迟执行的
当我们在操作一个流的时候,并不会修改流底层的集合(即是集合时线程安全的);
如果想要修改原有的集合,就无法定义流操作的输出;
由于 Stream 的延迟执行特性,在聚合操作前修改数据源是允许的;
示例:
@Test
public void operateStringList() {
List<String> strList = new ArrayList<String>(){
{
add("a");
add("b");
add("c");
add("d");
add("e");
add("f");
add("g");
add("h");
}
};
Stream<String> stringStream = strList.stream();
strList.add("i");
strList.add("j");
strList.add("k");
strList.add("k");
strList.add("k");
long num = stringStream.distinct().count();
System.out.println(num);
}
控制台打印日志为
11
Process finished with exit code 0
最后打印的结果为 8;此处我考虑应该是 集合 是引用类型,所以在调用聚合操作之前,修改都会被同步到 Stream 中
三、Strean 创建的几种方式:
1、通过数组创建:
两种方式:Arrays.stream(arr) 和 Stream.of(arr)
@Test
public void operateStringList() {
/**
* 1、通过 Arrays.stream
*/
// 1.1、基本类型
int[] arr = new int[]{1, 22, 333, 4444, 5};
IntStream intStream = Arrays.stream(arr);
// 1.2、引用类型
Student[] students = new Student[]{
new Student("a", "num1", 67),
new Student("c", "num3", 67),
new Student("b", "num2", 67)
};
/**
* 2、通过 Stream.of
*/
// 生成 Integer 流
Stream<Integer> stream1 = Stream.of(1, 22, 333, 4444, 5);
// 生成 int[] 流
Stream<int[]> stream2 = Stream.of(arr, arr, arr);
stream2.map(x -> {
for (int i = 0; i < x.length; i++) {
System.out.println(x[i]);
}
return x;
})
// .collect(Collectors.toList());
.forEach(x -> System.out.println(x));
}
控制台打印为:
1
22
333
4444
5
[I@5b1d2887
1
22
333
4444
5
[I@5b1d2887
1
22
333
4444
5
[I@5b1d2887
Process finished with exit code 0
2、通过集合创建流:
两种方式: 直接调用 stream()(普通流) 或 parallelStream()(并行流)方法;
@Test
public void arrayStream() {
List<String> strs = Arrays.asList("111", "aba", "2323", "dfd");
// 创建普通流
Stream<String> stream = strs.stream();
// 创建并行流
Stream<String> stream1 = strs.parallelStream();
}
3、创建空的流:
@Test
public void nullStream() { // 创建空的流
// 穿件一个空的 Stream
Stream<Integer> stream = Stream.empty();
}
4、创建无限流
@Test
public void testUnlimitStream() { // 创建一个无限流
// 创建无限流,通过 Limit 提取指定大小
Stream.generate(() -> "number" + new Random().nextInt()).limit(100).forEach(System.out::println);
Stream.generate(() -> new Student("name", "1", 1)).limit(20).forEach( x -> x.toString());
}
控制台打印为:
number-1381339958
number-1028888960
...... 此处省略98跳结果,number后面的数字是随机的,不考虑正负
Student{name='name', number='1', score=1}
Student{name='name', number='1', score=1}
...... 此处省略18条,相同的数据
5、创建规律的无限流:
@Test
public void testRegularUnlimitStream() { // 创建规律的无限流
Stream.iterate(0, x -> x+1).limit(10).forEach(System.out::println);
Stream.iterate(0, x -> x).limit(10).forEach(System.out::println);
// 等同于
Stream.iterate(0, UnaryOperator.identity()).limit(10).forEach(System.out::println);
}
控制台打印的日志为:
0
1
...... 自加到9
0
0
...... 此处省略重复打印 0 ,8次
0
0
...... 此处省略重复打印 0 ,8次
四、对Stream的操作:
1、常用的中间方法:
1)、map:转换流,将一种类型的流转换为另外一种流
@Test
public void testMap() { // 转换流,将一种类型的流转换为另外一种类型的流
// 给每个字母加上 "yes" 后,并转换为大写
String[] arr = new String[]{"a", "b", "c"};
Arrays.stream(arr).map(x -> {x=x+"yes"; return x.toUpperCase();}).forEach(System.out::println);
}
控制台打印的日志为:
AYES
BYES
CYES
2)、filter:过滤流,过滤流中的元素
@Test
public void testFilter() { // 过滤流:过滤流中的元素
// 过滤集合中,元素 > 5 元素
Integer[] integers = new Integer[]{10, 4, 8, 3};
Arrays.stream(integers).filter(x -> x>5).forEach(System.out::println);
}
控制台打印的日志为:
10
8
3)、flapMap:拆解流,将流中每个元素拆解成一个流
@Test
public void testFlapMap() { // 拆解流:将流中每个元素拆解成一个流
String[] arr1 = {"a", "b", "c", "d"};
String[] arr2 = {"e", "f", "c", "d"};
String[] arr3 = {"h", "j", "c", "d"};
String[][] arr4 = {arr1, arr2, arr3};
Arrays.stream(arr4).flatMap(x -> Arrays.stream(x)).forEach(System.out::println);
}
控制台打印的日志为:
a
b
c
...... 一直打印到 d
4)、sorted:对流进行排序:
@Test
public void testSorted() { // 对流进行排序
String[] arr1 = {"abc", "ghi", "de", "f"};
// 按照字符串长度进行排序
System.out.println("*******按照字符串长度进行排序********");
System.out.println("*******正序********");
Arrays.stream(arr1).sorted((x, y) -> x.length()-y.length()).forEach(System.out::println);
// 等同于
//Arrays.stream(arr1).sorted(Comparator.comparing(String::length)).forEach(System.out::println);
System.out.println("*******倒序********");
/**
* reversed(),java8泛型推导的问题,所以如果comparing里面是非方法引用的lambda表达式就没办法直接使用reversed()
* Comparator.reverseOrder():也是用于翻转顺序,用于比较对象(Stream里面的类型必须是可比较的)
* Comparator. naturalOrder():返回一个自然排序比较器,用于比较对象(Stream里面的类型必须是可比较的)
*/
Arrays.stream(arr1).sorted(Comparator.comparing(String::length).reversed()).forEach(System.out::println);
//Arrays.stream(arr1).sorted(Comparator.reverseOrder()).forEach(System.out::println);
//Arrays.stream(arr1).sorted(Comparator.naturalOrder()).forEach(System.out::println);
System.out.println("*******按照字符串首字符进行排序********");
Arrays.stream(arr1).sorted(Comparator.comparing(this::getFirstChar)).forEach(System.out::println);
System.out.println("*******按照字符串 先首字符进行排序,之后按照 String 的长度排序********");
Arrays.stream(arr1).sorted(Comparator.comparing(this::getFirstChar).thenComparing(String::length)).forEach(System.out::println);
}
public char getFirstChar(String x) {
return x.charAt(0);
}
控制台打印的日志为:
*******按照字符串长度进行排序********
*******正序********
f
de
abc
ghi
*******倒序********
abc
ghi
de
f
*******按照字符串首字符进行排序********
abc
de
f
ghi
*******按照字符串 先首字符进行排序,之后按照 String 的长度排序********
abc
de
f
ghi
2、提取流和组合流:
1):提取流:
@Test
public void testExtract() { // 提取流
/**
* limit,限制从流中获取前 n 个数据
*/
System.out.println("*******limit********");
java.util.stream.Stream.iterate(1, x->x+1).limit(5).forEach(System.out::println);
/**
* skip,跳过前 n 个数据
*/
System.out.println("*******skip在前********");
java.util.stream.Stream.iterate(1, x->x+1).skip(2).limit(5).forEach(System.out::println);
System.out.println("*******skip在前后********");
java.util.stream.Stream.iterate(1, x->x+1).limit(5).skip(2).forEach(System.out::println);
}
控制台打印的日志为:
*******limit********
1
2
3
4
5
*******skip在前********
3
4
5
6
7
*******skip在前后********
3
4
5
2):组合流:
@Test
public void testCombination() { // 组合流
String[] arr1 = new String[]{"a","b","c","d"};
String[] arr2 = new String[]{"d","e","f","g"};
String[] arr3 = new String[]{"i","j","k","l"};
java.util.stream.Stream<String> stream1 = Arrays.stream(arr1);
java.util.stream.Stream<String> stream2 = java.util.stream.Stream.of(arr2);
/**
* 可以把两个 stream 合并成一个 stream(合并的 stream 类型必须相同)
* 只能两两合并
*/
java.util.stream.Stream.concat(stream1,stream2).distinct().forEach(System.out::println);
}
控制台打印的日志为:
a
b
c
d
e
f
g
3、聚合操作:(末端操作)
1)max、min:最大最小值
@Test
public void testMaxMin() { // 获取流中最大最小的值
String[] arr = new String[]{"b","ab","abc","abcd","abcde"};
System.out.println("******字符串长度最大值*******");
java.util.stream.Stream.of(arr).max(Comparator.comparing(String::length)).ifPresent(System.out::println);
System.out.println("******字符串长度最小值*******");
java.util.stream.Stream.of(arr).min(Comparator.comparing(String::length)).ifPresent(System.out::println);
}
控制台打印的日志为:
******字符串长度最大值*******
abcde
******字符串长度最小值*******
b
2)、count:计算数量;
@Test
public void testCount() { // 获取流中数据的总数或者满足条件的总数
String[] arr = new String[]{"b","ab","abc","abcd","abcde"};
System.out.println("******获取集合中元素的数量*******");
System.out.println(Arrays.stream(arr).count());
System.out.println("******获取集合中元素符合 指定长度 的数量*******");
System.out.println(Arrays.stream(arr).filter(x -> x.length() > 3).count());
}
控制台打印的日志为:
******获取集合中元素的数量*******
5
******获取集合中元素符合 指定长度 的数量*******
2
3)、findFirst:查询流中第一个元素
@Test
public void testFindFirst() { // 查询流中的第一个元素
String[] arr = new String[]{"b","ab","abc","abcd","abcde"};
String str = Arrays.stream(arr).map(x -> x+"test").findFirst().orElse("nothing");
System.out.println(str);
}
控制台打印的日志为:
btest
4)、findAny:找到所有匹配的元素
找到所有匹配的元素;
对并行流十分有效;(后续待验证)
只要发现了第一个匹配的元素就会结束整个运算;
@Test
public void testFindAny() { // 找到所有匹配的元素
/**
* 只要在任何片段发现了第一个匹配的元素就会结束整个运算
*/
String[] arr = new String[]{"b","ab","abc","abcd","abcde"};
Optional<String> optional = java.util.stream.Stream.of(arr).filter(x -> x.length()>4).findAny();
System.out.println(optional);
}
控制台打印的日志为:
Optional[abcde]
5)、anyMath:是否含有匹配元素
@Test
public void testAnyMatch() { // 是否含有匹配的额元素
String[] arr = new String[]{"b","ab","abc","abcd","abcde"};
System.out.println("*****是否含有以 b 开头的字符串******");
Boolean isIncluded1 = Arrays.stream(arr).anyMatch(x -> x.startsWith("a"));
System.out.println(isIncluded1);
System.out.println("*****是否含有以 g 字符的字符串******");
Boolean isIncluded2 = Arrays.stream(arr).anyMatch(x -> x.indexOf("g")!=-1);
System.out.println(isIncluded2);
}
控制台打印的日志为:
*****是否含有以 b 开头的字符串******
true
*****是否含有以 b 开头的字符串******
false
6)、allMatch:是否流中的元素都匹配
@Test
public void testAllMatch() { // 是否流中的元素全匹配
String[] arr = new String[]{"a","ab","abc","abcd","abcde"};
System.out.println("*****是否都含有以 a 开头的字符串******");
Boolean isIncluded1 = Arrays.stream(arr).allMatch(x -> x.startsWith("a"));
System.out.println(isIncluded1);
System.out.println("*****是否都含有 b 字符的字符串******");
Boolean isIncluded2 = Arrays.stream(arr).allMatch(x -> x.indexOf("b")!=-1);
System.out.println(isIncluded2);
}
控制台打印的日志为:
*****是否都含有以 a 开头的字符串******
true
*****是否都含有 b 字符的字符串******
false
4、Optional 类型:
一般,聚合操作或返回
Optional类型,Optional表示一个安全的指定结果类型,所谓的安全指的是避免直接调用返回类型的null值二造成空指针异常:
1、调用optional.ifPresent()可以判断返回值是否为空;
2、或者直接调用ifPresent(Consumer <? super T> consumer)在结果不为空时,进行消费操作,调用optional.get()获取返回值;
一般的使用方式如下:
@Test
public void testOptional() { // 获取optional的值
List<String> list = new ArrayList<String>(){
{
add("one");
add("two");
}
};
Optional<String> opt = Optional.of("new String");
opt.ifPresent(list::add);
list.forEach(System.out::println);
}
控制台打印日志为:
one
two
new String
使用
Optional可以在没有值时指定一个返回值,例:
@Test
public void testOptionalConst() { // Optional 没有值时返回一个指定的值
Integer[] arr = new Integer[]{3, 4, 5, 6, 7};
System.out.println("*****先从流中过滤出大于7的集合,然后在按小到大排序,如果该集合为空,则返回指定的 -1****");
Integer result = java.util.stream.Stream.of(arr).filter(x -> x>7).max(Comparator.naturalOrder()).orElse(-1);
System.out.println(result);
System.out.println("*****先从流中过滤出大于7的集合,然后在按小到大排序,如果该集合为空,则返回指定的 -1****");
Integer result2 = java.util.stream.Stream.of(arr).filter(x -> x>7).max(Comparator.naturalOrder()).orElseGet(() ->-1);
System.out.println(result2);
System.out.println("*****先从流中过滤出大于7的集合,然后在按小到大排序,如果该集合为空,则抛出 RuntimeException 的错误****");
Integer result3 = java.util.stream.Stream.of(arr).filter(x -> x>7).max(Comparator.naturalOrder()).orElseThrow(RuntimeException::new);
System.out.println(result3);
}
控制台打印的日志为:
*****先从流中过滤出大于7的集合,然后在按小到大排序,如果该集合为空,则返回指定的 -1****
-1
*****先从流中过滤出大于7的集合,然后在按小到大排序,如果该集合为空,则返回指定的 -1****
-1
*****先从流中过滤出大于7的集合,然后在按小到大排序,如果该集合为空,则返回指定的 -1****
java.lang.RuntimeException
Optional的创建:
1、Optional.empty(): 创建一个空的 Optional;
2、Optional.of():创建指定值的 Optional;
3、可以调用Optional对象的map方法进行Optional的转换,调用flatMap方法进行Optional的迭代;
@Test
public void testInitOptional() { // 创建 Optional
Optional<Student> studentOptional = Optional.of(new Student("user1", "num1",21));
Optional<String> optionalStr = studentOptional.map(Student::getName);
System.out.println(optionalStr.get());
}
public static Optional<Double> inverse(Double x) {
return x == 0 ? Optional.empty() : Optional.of(1 / x);
}
public static Optional<Double> squareRoot(Double x) {
return x < 0 ? Optional.empty() : Optional.of(Math.sqrt(x));
}
控制台打印的日志为:
user1
5、收集结果:
结果的类型有:
List、Set、数组、或指定生成的类型;
Student[] students;
@Before
public void init(){
students = new Student[100];
for (int i=0;i<30;i++){
Student student = new Student("user", "num1", i);
students[i] = student;
}
for (int i=30;i<60;i++){
Student student = new Student("user"+i, "num2", i);
students[i] = student;
}
for (int i=60;i<100;i++){
Student student = new Student("user"+i, "num3", i);
students[i] = student;
}
}
@Test
public void testCollect1(){
/**
* 生成List
*/
List<Student> list = Arrays.stream(students).collect(Collectors.toList());
list.forEach((x)-> System.out.println(x));
/**
* 生成Set
*/
Set<Student> set = Arrays.stream(students).collect(Collectors.toSet());
set.forEach((x)-> System.out.println(x));
/**
* 如果包含相同的key,则需要提供第三个参数,否则报错
*/
Map<String,Integer> map = Arrays.stream(students).collect(Collectors.toMap(Student::getName,Student::getScore,(s,a)->s+a));
map.forEach((x,y)-> System.out.println(x+"->"+y));
}
/**
* 生成数组
*/
@Test
public void testCollect2(){
Student[] s = Arrays.stream(students).toArray(Student[]::new);
for (int i=0;i<s.length;i++)
System.out.println(s[i]);
}
/**
* 指定生成的类型
*/
@Test
public void testCollect3(){
HashSet<Student> s = Arrays.stream(students).collect(Collectors.toCollection(HashSet::new));
s.forEach(System.out::println);
}
/**
* 统计
*/
@Test
public void testCollect4(){
IntSummaryStatistics summaryStatistics = Arrays.stream(students).collect(Collectors.summarizingInt(Student::getScore));
System.out.println("getAverage->"+summaryStatistics.getAverage());
System.out.println("getMax->"+summaryStatistics.getMax());
System.out.println("getMin->"+summaryStatistics.getMin());
System.out.println("getCount->"+summaryStatistics.getCount());
System.out.println("getSum->"+summaryStatistics.getSum());
}
6、分组和分片:
分组和分片的意义是:
将collec的结果集展示为 Map<key,val>的形式,通常的用法如下:
1)、使用 groupBy 进行分类:
public Student[] init2(){
Student[] students = new Student[100];
for (int i=0;i<30;i++){
Student student = new Student("user1", "num1", i);
students[i] = student;
}
for (int i=30;i<60;i++){
Student student = new Student("user2", "num2", i);
students[i] = student;
}
for (int i=60;i<100;i++){
Student student = new Student("user3", "num3", i);
students[i] = student;
}
return students;
}
@Test
public void groupByName() {
Student[] students = this.init2();
System.out.println("*********根据名称分类*******");
Map<String, List<Student>> stuMap = Arrays.stream(students).collect(Collectors.groupingBy(Student::getName));
for (String s : stuMap.keySet()) {
System.out.println(s);
System.out.println(stuMap.get(s).size());
}
System.out.println("*********根据分数是否超过50进行分类*******");
Map<Boolean, List<Student>> stuMap2 = Arrays.stream(students).collect(Collectors.groupingBy(x -> x.getScore() > 50));
for (Boolean aBoolean : stuMap2.keySet()) {
System.out.println(aBoolean);
System.out.println(stuMap2.get(aBoolean).size());
}
}
控制台打印的日志为:
*********根据名称分类*******
user1
30
user2
30
user3
40
*********根据分数是否超过50进行分类*******
false
51
true
49
2)、partitionBy:
如果只有两类的情况,使用partitionBy 会比 groupBy 更有效率:
public Student[] init2(){
Student[] students = new Student[100];
for (int i=0;i<30;i++){
Student student = new Student("user1", "num1", i);
students[i] = student;
}
for (int i=30;i<60;i++){
Student student = new Student("user2", "num2", i);
students[i] = student;
}
for (int i=60;i<100;i++){
Student student = new Student("user3", "num3", i);
students[i] = student;
}
return students;
}
/**
* 如果只有两类,那么 partitioningBy 比 groupBy 更有效率
*/
@Test
public void testPartitionBy() {
Student[] students = this.init2();
Map<Boolean, List<Student>> stuMap = Arrays.stream(students).collect(Collectors.partitioningBy(x -> x.getScore() > 60));
for (Boolean aBoolean : stuMap.keySet()) {
System.out.println(aBoolean);
System.out.println(stuMap.get(aBoolean).size());
}
}
控制台打印的日志为:
false
61
true
39
3)、downstream 指定类型:
进行分类时,
groupBy的第二个参数指定分类集合的类型:


public Student[] init2(){
Student[] students = new Student[100];
for (int i=0;i<30;i++){
Student student = new Student("user1", "num1", i);
students[i] = student;
}
for (int i=30;i<60;i++){
Student student = new Student("user2", "num2", i);
students[i] = student;
}
for (int i=60;i<100;i++){
Student student = new Student("user3", "num3", i);
students[i] = student;
}
return students;
}
/**
* 指定分类类型化
*/
@Test
public void testGroupBy2() {
Student[] students = this.init2();
Map<String, Set<Student>> setMap1 = Arrays.stream(students).collect(Collectors.groupingBy(Student::getName, Collectors.toSet()));
for (String s : setMap1.keySet()) {
System.out.println(s);
System.out.println(setMap1.get(s).size());
}
Map<Boolean, Set<Student>> setMap2 = Arrays.stream(students).collect(Collectors.partitioningBy(x -> x.getScore() > 60, Collectors.toSet()));
for (boolean s : setMap2.keySet()) {
System.out.println(s);
System.out.println(setMap2.get(s).size());
}
}
控制台打印的日志为:
user1
30
user2
30
user3
40
false
61
true
39
4)、聚合操作:将分类,指定类型,比较放在一起使用
主要因为是,
downstream的类型是Collector,所以可以做到再次进行比较和指定类型;
public Student[] init2(){
Student[] students = new Student[100];
for (int i=0;i<30;i++){
Student student = new Student("user1", "num1", i);
students[i] = student;
}
for (int i=30;i<60;i++){
Student student = new Student("user2", "num2", i);
students[i] = student;
}
for (int i=60;i<100;i++){
Student student = new Student("user3", "num3", i);
students[i] = student;
}
return students;
}
@Test
public void testGroupBy3() {
Student[] students = this.init2();
/**
* counting
*/
Map<String,Long> map1 = Arrays.stream(students).collect(Collectors.groupingBy(Student::getName,Collectors.counting()));
map1.forEach((x,y)-> System.out.println(x+"->"+y));
/**
* summingInt
*/
Map<String,Integer> map2 = Arrays.stream(students).collect(Collectors.groupingBy(Student::getName,Collectors.summingInt(Student::getScore)));
map2.forEach((x,y)-> System.out.println(x+"->"+y));
/**
* maxBy
*/
Map<String,Optional<Student>> map3 = Arrays.stream(students).collect(Collectors.groupingBy(Student::getName,Collectors.maxBy(Comparator.comparing(Student::getScore))));
map3.forEach((x,y)-> System.out.println(x+"->"+y));
/**
* mapping
*/
Map<String,Set<Integer>> map4 = Arrays.stream(students).collect(Collectors.groupingBy(Student::getName,Collectors.mapping(Student::getScore,toSet())));
map4.forEach((x,y)-> System.out.println(x+"->"+y));
}
控制台打印的日志为:
user1->30
user2->30
user3->40
user1->435
user2->1335
user3->3180
user1->Optional[Student{name='user1', number='num1', score=29}]
user2->Optional[Student{name='user2', number='num2', score=59}]
user3->Optional[Student{name='user3', number='num3', score=99}]
user1->[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29]
user2->[30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59]
user3->[64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 60, 61, 62, 63]
Process finished with exit code 0
参考博客:
https://www.cnblogs.com/andywithu/p/7404101.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号