【Kill Thread Part.2-1】Java内存模型——底层原理
【Kill Thread Part.2-1】Java内存模型——底层原理
一、什么是“底层原理”?本章研究的内容?
1、从Java代码到CPU指令
- 从.java文件到.class文件,然后JVM翻译成对应操作系统平台的机器指令。
- JVM实现会带来不同的“翻译”,不同的CPU平台的机器指令又千差万别,无法保证并发安全的效果一致。
- 重点开始向下转移:转化过程的规范、原则
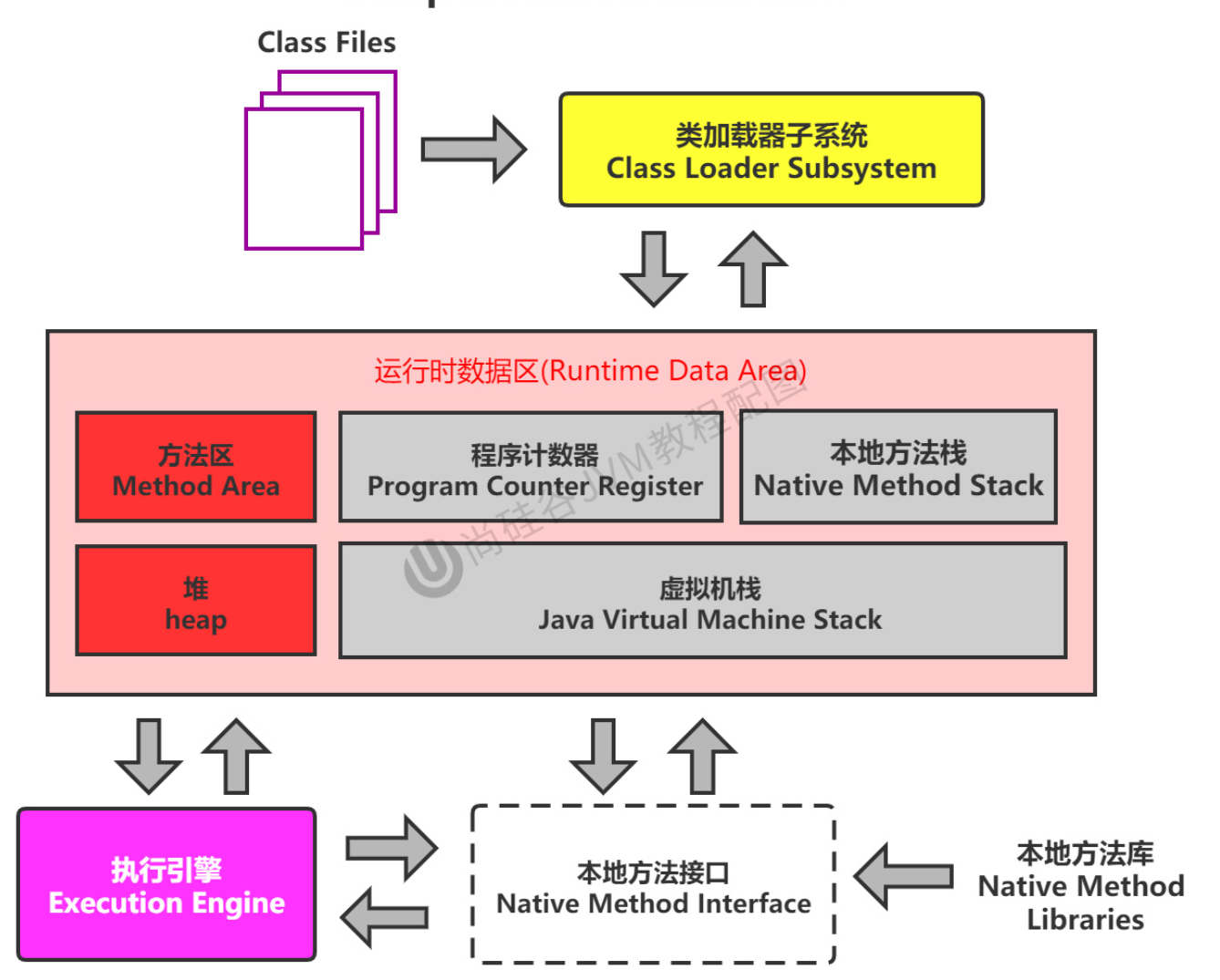
2、JVM内存结构 VS Java内存模型 VS Java对象模型
①整体方向
- JVM内存结构:和Java虚拟机的运行时区域有关
- Java内存模型:和Java的并发编程有关
- Java对象模型:和Java对象在虚拟机中的表现形式有关
②JVM内存结构
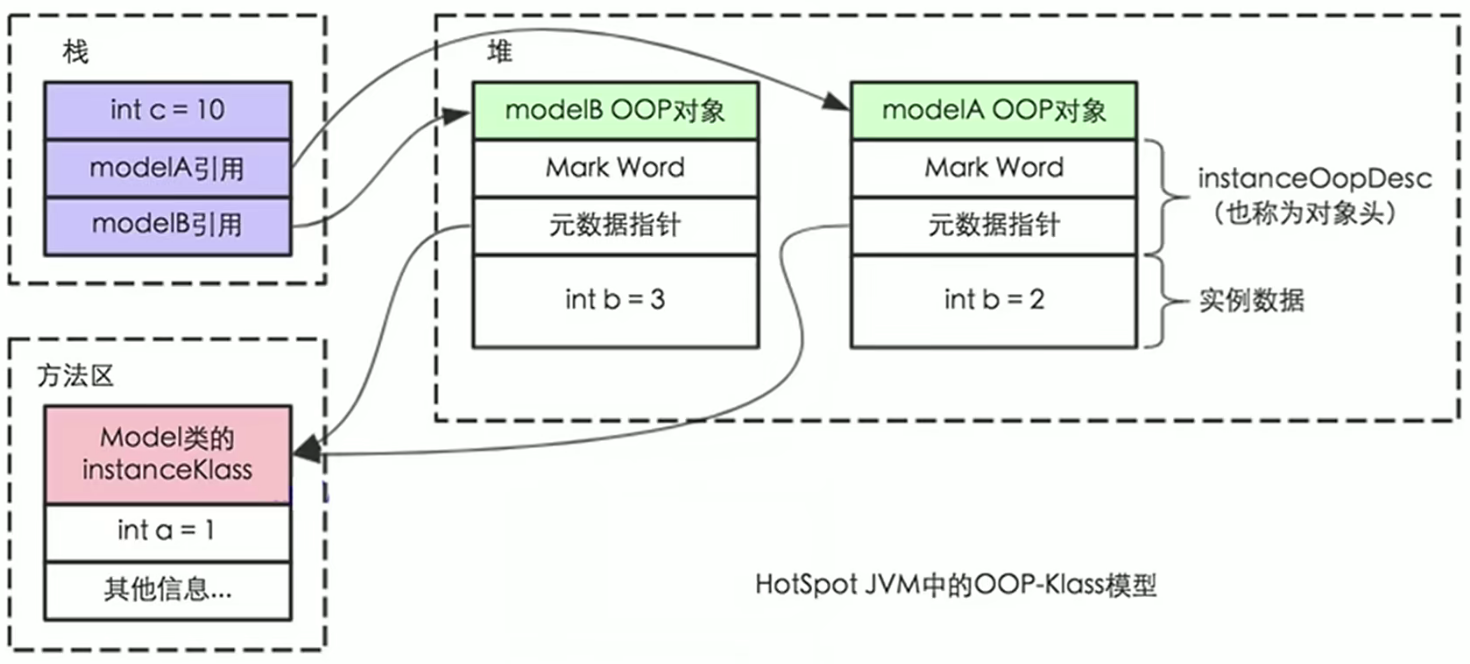
③Java对象模型
Java是面向对象的语言,每一个Java对象在JVM中存储是有一定的结构的。
-
Java对象自身的存储模型
-
JVM会给这个类创建一个instanceKlass,保存在方法区,用来在JVM层展示该Java类。
-
当我们在Java代码中,使用new创建一个对象的时候,JVM会创建一个instanceOopDesc对象,这个对象中包含了对象头以及实例数据。
④Jav内存模型是什么?
下面详细介绍
二、JMM是什么(Java Memory Model)
- 是规范
- C语言不存在内存模型的概念
- 依赖处理器,不同处理器结果不一样
- 无法保证并发安全
- 需要一个标准,让多线程运行的结果可预期
- 是一组规范,需要各个JVM的实现来遵守JMM的规范,以便于开发者可以利用这些规范,更方便地开发多线程程序。
- 如果没有这样一个内存模型来规范,那么很可能经过了JVM的不同规则的重排序之后,导致不同的虚拟机上运行的结果不一样,造成很大的问题。
- C语言不存在内存模型的概念
- 是工具类和关键字的原理
- volatile、synchronized、Lock等的原理都是JMM
- 如果没有JMM,那就需要我们自己指定什么时候用内存栅栏等,那是相当麻烦的,幸好有了JMM,让我们只需要用同步工具和关键字就可以开发并发程序。
- 最重要的三点内容:重排序、可见性、原子性
三、重排序
1、案例演示:什么是重排序?
①测试代码
/**
* 描述: 演示重排序的现象“直到达到某个条件才停止”,测试小概率事件
*/
public class OutOfOrderExecution {
private static int x = 0, y = 0;
private static int a = 0, b = 0;
public static void main(String[] args) throws InterruptedException {
Thread one = new Thread(new Runnable() {
@Override
public void run() {
a = 1;
x = b;
}
});
Thread two = new Thread(new Runnable() {
@Override
public void run() {
b = 1;
y = a;
}
});
one.start();
two.start();
one.join();
two.join();
System.out.println("x = " + x + "," + "y = " + y);
}
}
运行结果:

②重排序分析
这4行代码的执行顺序决定了 最终x和y的结果,一共有3种情况:

-
虽然代码执行顺序可能有多种情况,但是在线程1的内部,也就是:a = 1; x = b;
- 这两行代码的额执行顺序,是不会改变的,也就是a = 1,会在x = b,前执行;同理,线程2的b = 1会在y = a前执行。
-
出现(0, 0)的诡异情况
-
测试代码:
-
/** * 描述: 演示重排序的现象 “直到达到某个条件才停止”,测试小概率事件 */ public class OutOfOrderExecution { private static int x = 0, y = 0; private static int a = 0, b = 0; public static void main(String[] args) throws InterruptedException { int i = 0; for (; ; ) { i++; x = 0; y = 0; a = 0; b = 0; CountDownLatch latch = new CountDownLatch(3); Thread one = new Thread(new Runnable() { @Override public void run() { try { latch.countDown(); latch.await(); } catch (InterruptedException e) { e.printStackTrace(); } a = 1; x = b; } }); Thread two = new Thread(new Runnable() { @Override public void run() { try { latch.countDown(); latch.await(); } catch (InterruptedException e) { e.printStackTrace(); } b = 1; y = a; } }); two.start(); one.start(); latch.countDown(); one.join(); two.join(); String result = "第" + i + "次(" + x + "," + y + ")"; if (x == 0 && y == 0) { System.out.println(result); break; } else { System.out.println(result); } } } } -

-
-
③为什么会出现(0, 0)的情况?
会出现x = 0,y =0?那是因为重排序发生了,四行代码的执行顺序的其中一种可能。
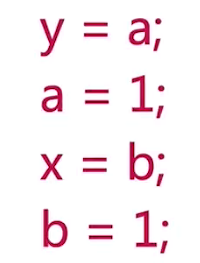
什么是重排序:
在线程1内部的两行代码的实际执行顺序和代码在Java文件中的顺序不一致,代码指令并不是严格的按照代码语句顺序执行的,它们的顺序被改变了,这就是重排序,这里被颠倒的时y = a和b = 1这两行语句。
2、重排序的好处:提高处理速度
①重排序前的指令

②重排序后的指令

可以看到指令数变少了,这样执行速度就会变快。
3、重排序的优化
编译器优化:包括JVM,JIT编译器等
CPU指令重排:就算编译器不发生重排,CPU也可能对指令进行重排
内存的“重排序”:线程A的修改线程B却看不到,引出可见性问题(主存和缓存的问题)
四、可见性
1、案例演示:什么是可见性问题
①测试代码
/**
* 描述: 演示可见性带来的问题
*/
public class FieldVisibility {
int a = 1;
int b = 2;
private void change() {
a = 3;
b = a;
}
private void print() {
System.out.println("b=" + b + ";a=" + a);
}
public static void main(String[] args) {
while (true) {
FieldVisibility test = new FieldVisibility();
new Thread(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
test.change();
}
}).start();
new Thread(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
test.print();
}
}).start();
}
}
}
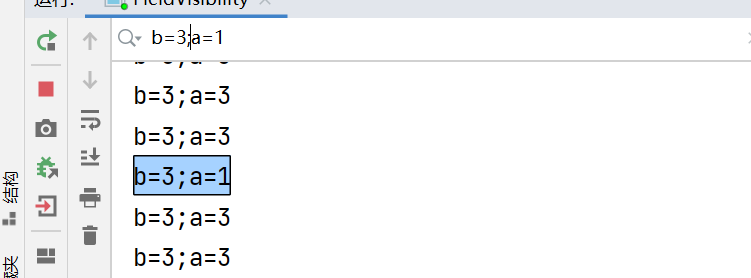
②可能出现的结果
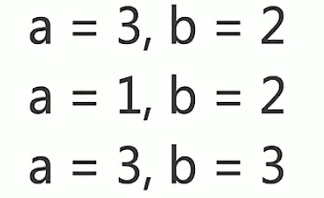
这三种情况可能是多线程执行顺序导致的,
但是,还有一种情况,是内存的可见性问题导致的。

③详细分析
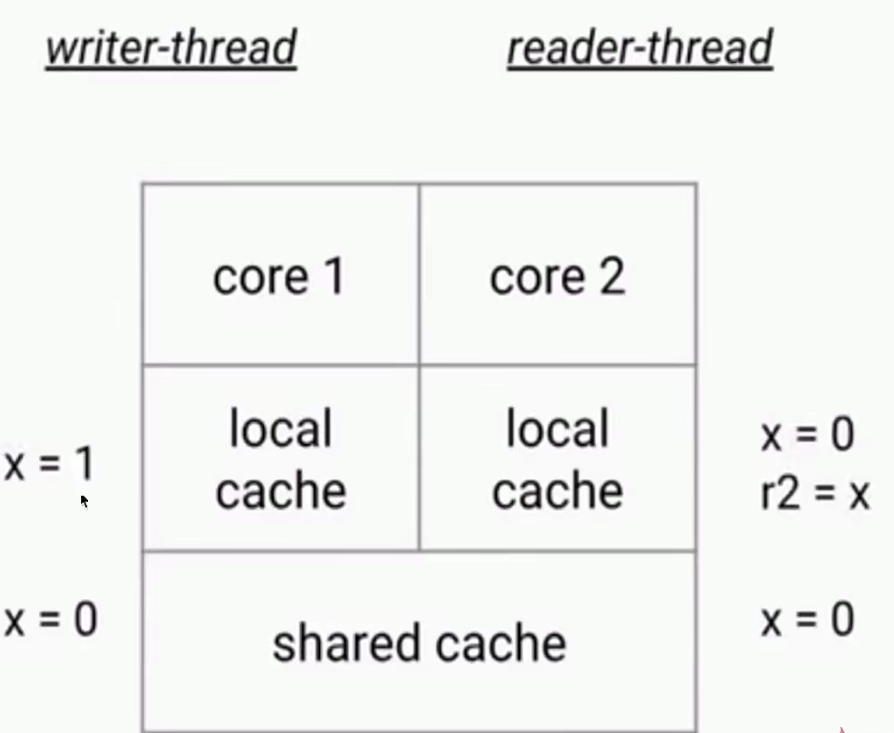
两个线程是不能直接通信的,只有通过访问主存。一个写,一个读。
2、用volatile解决问题
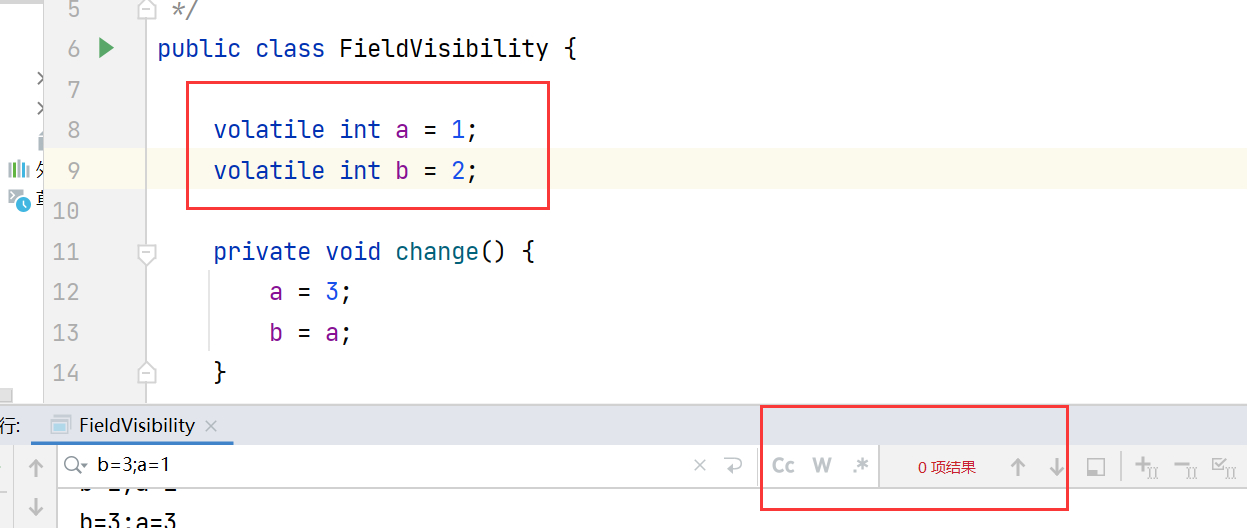
将上述案例演示代码的a, b的值前面加上volatile,就不会出现可见性的问题了。
原理
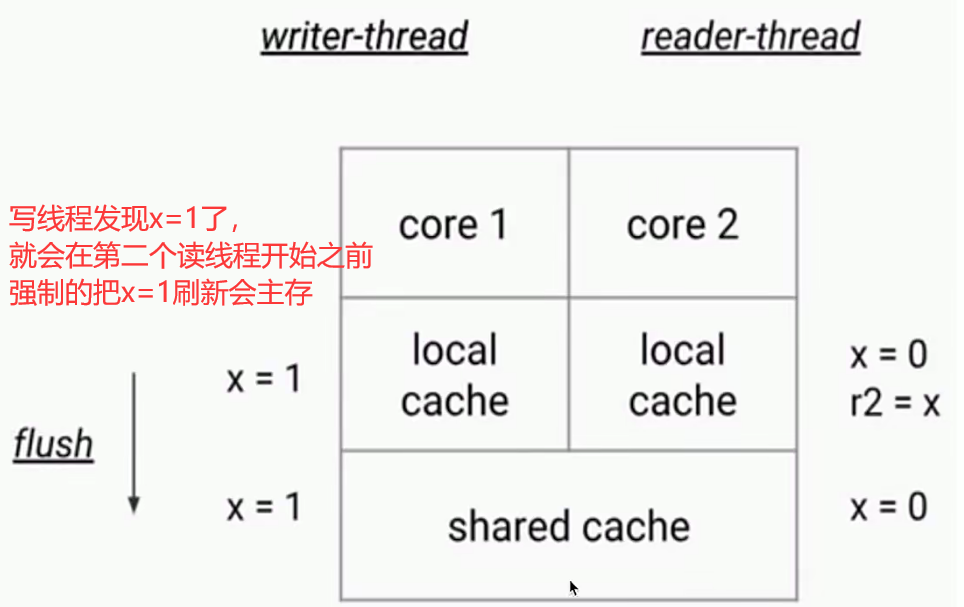
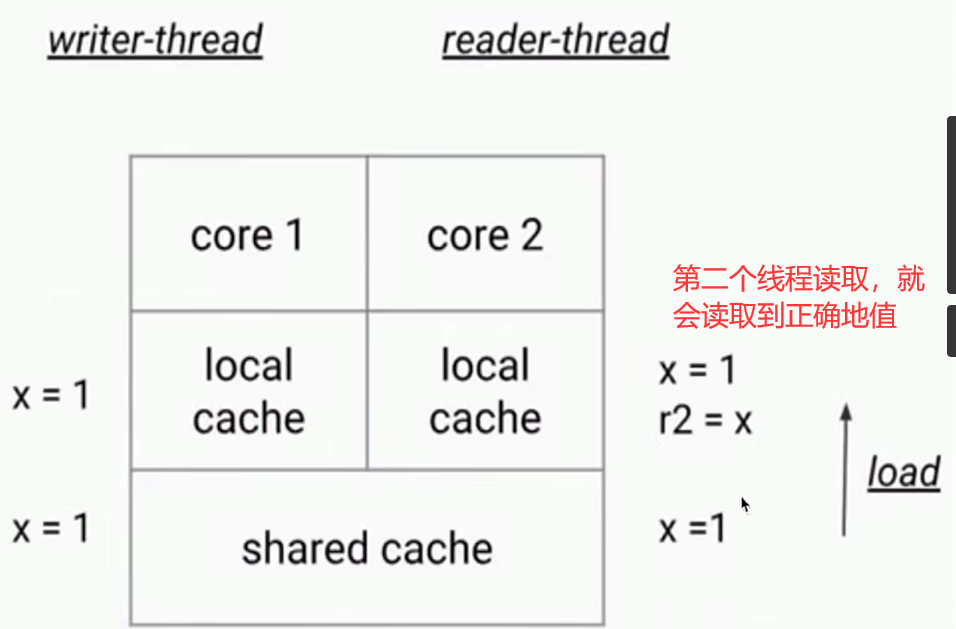
3、为什么会有可见性问题
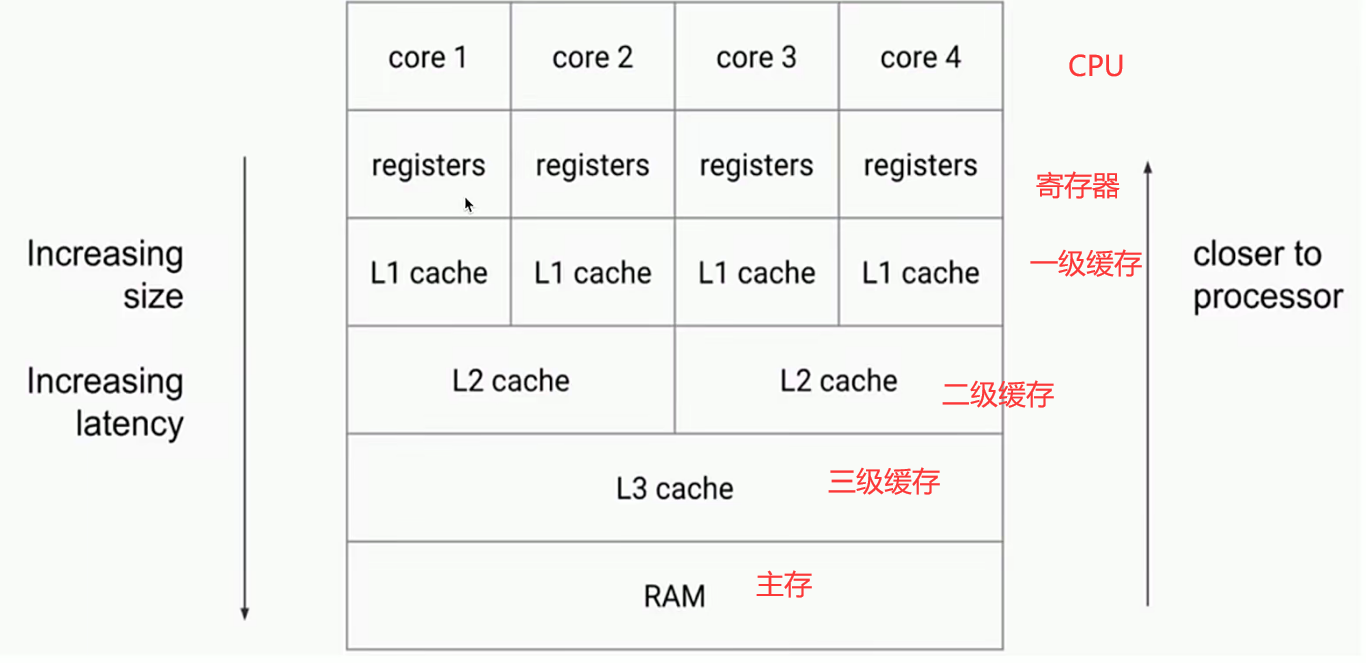
- CPU有多级缓存,导致读的数据过期
- 高速缓存的容量比内存小,但是速度仅次于寄存器,所以在CPU和主存之间就多了Cache层
- 线程间的对于共享变量的可见性问题不是直接由多核引起的,而是由多缓存引起的。
- 如果所有的核心都只用一个缓存,那么也就不存在内存可见性问题了。
- 通常情况下,每个核心都会将自己需要的数据读到独占缓存中,数据修改后也是写入到缓存中,然后等待刷入到主存中。所以会导致有些核心读取的值是一个过期的值。
4、JMM的抽象:主内存和本地内存
Java作为高级语言,屏蔽了这些底层细节,用JMM定义了一套读写内存数据的规范,虽然我们不再需要关心一级缓存和二级缓存的问题,但是,JMM抽象了主内存和本地内存的概念。
这里说的本地内存并不是真的是一块给每个线程分配的内存,而是JMM的一个抽象,是对于寄存器、一级缓存、二级缓存等的抽象。
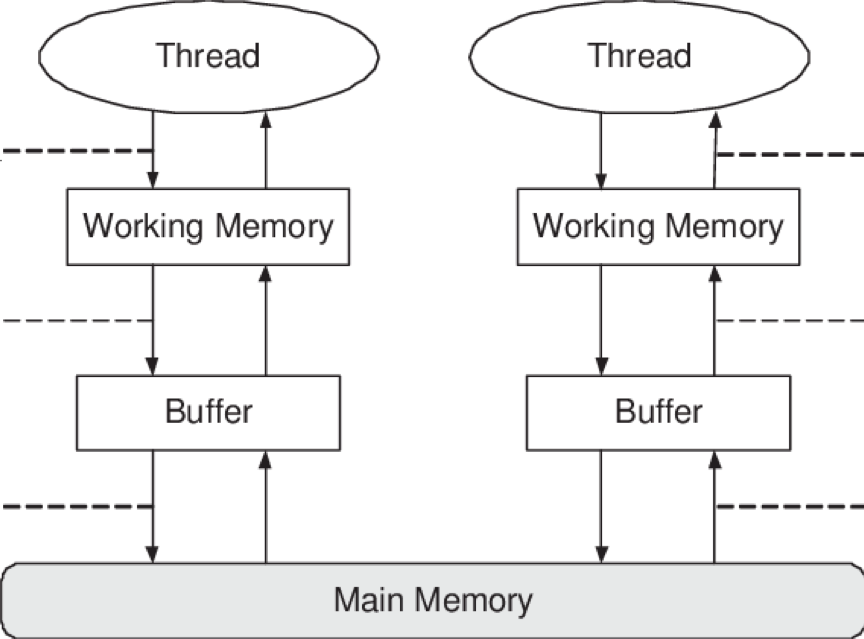
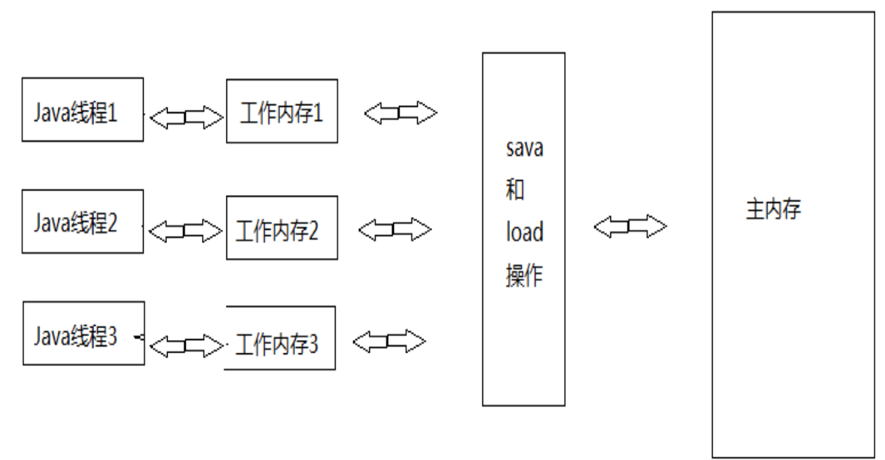
主内存和本地内存的关系
JMM有以下规定:
- 所有的变量都存储在主存当中,同时每个线程也有自己独立地工作内存,工作内存中的变量内容是主内存中的拷贝。
- 线程不能直接读写主内存中的变量,而是只能操作自己工作内存中的变量,然后再同步到主内存中。
- 主内存是多个线程共享的,但是线程之间不共享工作内存,如果线程间需要通信,必须借助主内存中转来完成。
所有的共享变量存在于内存中,每个线程有自己的本地内存,而且线程读写共享数据也是通过本地内存交换的,所以才导致了可见性问题。
五、Happens-Before原则
1、什么是happens-before
- happens-before规则是用来解决可见性问题的:
- 在时间上,动作A发生在动作B之前,B保证能看见A,这就是happens-before.
- 两个操作可以用happens-before来确定它们的执行顺序:
- 如果一个操作happens-before于另一个操作,那么我们说第一个操作对于第二个操作是可见的
2、什么不是happens-before
- 两个线程没有相互配合的机制,所以代码X和Y的执行结果并不能保证总被对方看到的,这就不具备happens-before。
3、原则有哪些?
- 单线程规则
- 如果是单线程,后面的代码一定可以看见前面代码的操作。
- 因为每个线程都有自己的工作内存
- 但是有可能发生重排序。
- 如果是单线程,后面的代码一定可以看见前面代码的操作。
- 锁操作
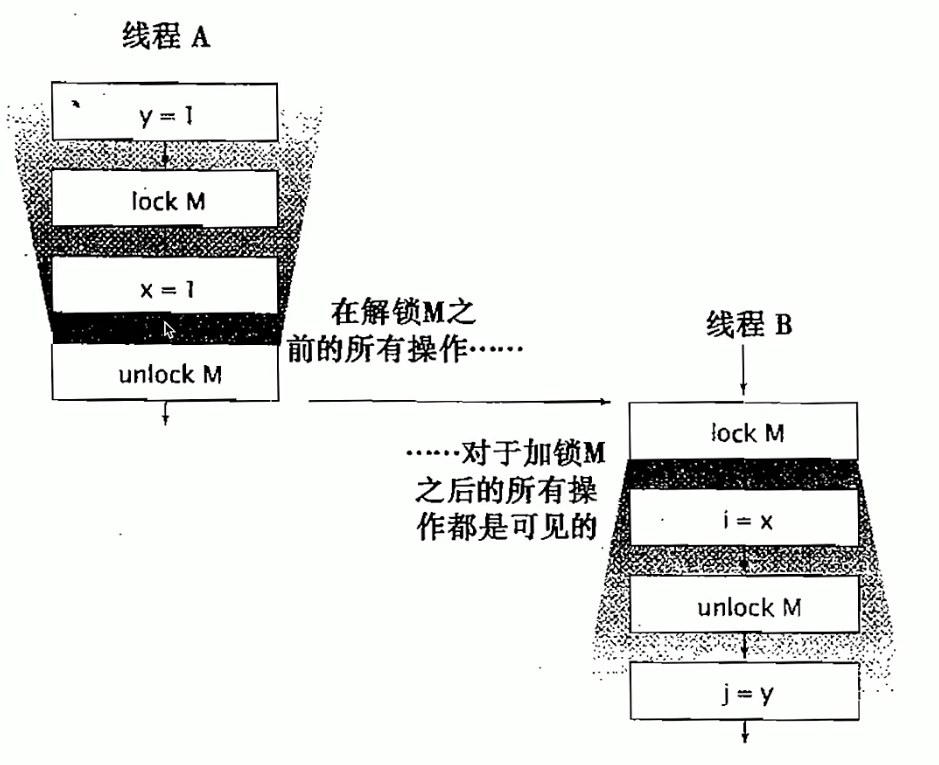
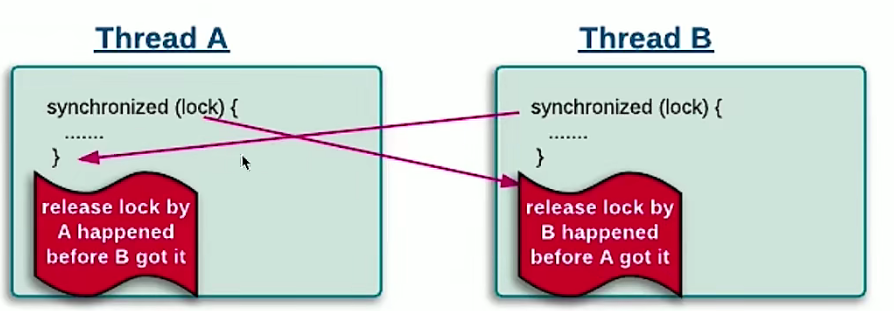
- 假设A拿到了锁,执行完ynchronized代码块之后释放锁,然后B拿到锁,是可以看到A的所有操作的。
- volatile变量
- 只要写入了,读取的线程一定可以读取到volatile修饰的变量。
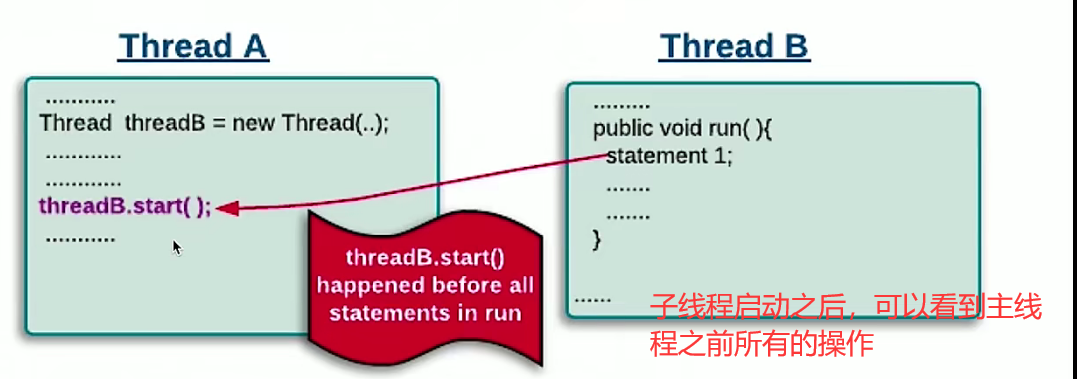
- 线程启动
- 线程join
- 子线程join,主线程join下面的语句都能看到join的子线程的所有操作。
- 传递性
- 如果hb(A, B)而且hb(B,C),那么可以推出hb(A,C)
- 中断
- 一个线程被其他线程interrupt,那么检测中断isInterrupted或者抛出InterruptedException一定能看到
- 构造方法
- 对象构造方法的最后一行指令happedns-before与finalize()方法的第一行指令
- 工具类的happens-before原则
- 线程安全的容器get一定能看到再次之前的put等存入动作
- CountDownLatch
- Semaphore
- Future
- 线程池
- CyclicBarrier

 浙公网安备 33010602011771号
浙公网安备 33010602011771号