

OS_lab1实验报告
lab1实验报告
一.实验思考题
Thinking 1.1
请查阅并给出前述objdump 中使用的参数的含义。使用其它体系结构的编译器(如课程平台的MIPS交叉编译器)重复上述各步编译过程,观察并在实验报告中提交相应结果。
我们观察一下objdump的各种参数的含义和用法:
--disassemble
-d
从objfile中反汇编那些特定指令机器码的section。
-D
--disassemble-all
与 -d 类似,但反汇编所有section.
-s
--full-contents
显示指定section的完整内容。默认所有的非空section都会被显示。
-S
--source
尽可能反汇编出源代码,尤其当编译的时候指定了-g这种调试参数时,效果比较明显。隐含了-d参数。
因此我们可以发现objdump -DS指的是反汇编所有section,并反汇编出源代码。
现在我们利用平台的交叉编译器,对一个简单的hello.c文件进行实验要求的操作。
int a = 3;
char b;
int main() {
int c = 12;
char* s = "hello,world";
return 0;
}
先对其进行编译但不链接,并进行反汇编:
/OSLAB/compiler/usr/bin/mips_4KC-gcc -c hello.c
/OSLAB/compiler/usr/bin/mips_4KC-objdump -DS hello.o > temp1.txt
我们观察tmp1.txt内容:
Disassembly of section .text:
00000000 <main>:
0: 3c1c0000 lui gp,0x0
4: 279c0000 addiu gp,gp,0
8: 0399e021 addu gp,gp,t9
c: 27bdffe8 addiu sp,sp,-24
10: afbe0010 sw s8,16(sp)
14: 03a0f021 move s8,sp
18: 2402000c li v0,12
1c: afc2000c sw v0,12(s8)
20: 8f820000 lw v0,0(gp)
24: 24420000 addiu v0,v0,0
28: afc20008 sw v0,8(s8)
2c: 00001021 move v0,zero
30: 03c0e821 move sp,s8
34: 8fbe0010 lw s8,16(sp)
38: 27bd0018 addiu sp,sp,24
3c: 03e00008 jr ra
40: 00000000 nop
...
然后进行链接,并反汇编hello
/OSLAB/compiler/usr/bin/mips_4KC-ld hello.o -o hello
/OSLAB/compiler/usr/bin/mips_4KC-objdump -DS hello > temp2.txt
观察temp2.txt的内容
004000b0 <main>:
4000b0: 3c1c0fc0 lui gp,0xfc0
4000b4: 279c7f50 addiu gp,gp,32592
4000b8: 0399e021 addu gp,gp,t9
4000bc: 27bdffe8 addiu sp,sp,-24
4000c0: afbe0010 sw s8,16(sp)
4000c4: 03a0f021 move s8,sp
4000c8: 2402000c li v0,12
4000cc: afc2000c sw v0,12(s8)
4000d0: 8f828018 lw v0,-32744(gp)
4000d4: 24420100 addiu v0,v0,256
4000d8: afc20008 sw v0,8(s8)
4000dc: 00001021 move v0,zero
4000e0: 03c0e821 move sp,s8
4000e4: 8fbe0010 lw s8,16(sp)
4000e8: 27bd0018 addiu sp,sp,24
4000ec: 03e00008 jr ra
4000f0: 00000000
我们发现main的入口已经被设置为Default值004000b0。
Thinking 1.2
也许你会发现我们的readelf程序是不能解析之前生成的内核文件(内核文件是可执行文件)的,而我们之后将要介绍的工具readelf则可以解析,这是为什么呢?(提示:尝试使用readelf -h,观察不同)
我们分别用我们生成的readelf可执行文件和readelf工具先对testELF进行分析
./readelf testELF
0:0x0
1:0x8048154
2:0x8048168
3:0x8048188
4:0x80481ac
5:0x80481cc
6:0x804828c
7:0x804830e
8:0x8048328
9:0x8048358
10:0x8048360
11:0x80483b0
12:0x80483e0
13:0x8048490
14:0x804888c
15:0x80488a8
16:0x80488fc
17:0x8048940
18:0x8049f14
19:0x8049f1c
20:0x8049f24
21:0x8049f28
22:0x8049ff0
23:0x8049ff4
24:0x804a028
25:0x804a030
26:0x0
27:0x0
28:0x0
29:0x0
发现可以解析。然后:
readelf -h testELF
ELF Header:
Magic: 7f 45 4c 46 01 01 01 00 00 00 00 00 00 00 00 00
Class: ELF32
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: EXEC (Executable file)
Machine: Intel 80386
Version: 0x1
Entry point address: 0x8048490
Start of program headers: 52 (bytes into file)
Start of section headers: 4440 (bytes into file)
Flags: 0x0
Size of this header: 52 (bytes)
Size of program headers: 32 (bytes)
Number of program headers: 9
Size of section headers: 40 (bytes)
Number of section headers: 30
Section header string table index: 27
现在我们对../gxemul/vmlinux 同样采取上述操作:
./readelf ../gxemul/vmlinux
却发现以下问题:
Segmentation fault (core dumped)
然后我们调用:
readelf -h ../gxemul/vmlinux
ELF Header:
Magic: 7f 45 4c 46 01 02 01 00 00 00 00 00 00 00 00 00
Class: ELF32
Data: 2's complement, big endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: EXEC (Executable file)
Machine: MIPS R3000
Version: 0x1
Entry point address: 0x80010000
Start of program headers: 52 (bytes into file)
Start of section headers: 37116 (bytes into file)
Flags: 0x1001, noreorder, o32, mips1
Size of this header: 52 (bytes)
Size of program headers: 32 (bytes)
Number of program headers: 2
Size of section headers: 40 (bytes)
Number of section headers: 14
Section header string table index: 11
我们观察到../gxemul/vmlinux 的文件采用大端存储,testELF的文件采用小端存储,也许我是实现的readelf现在并不支持解析大端存储,因为大端存储的数据传入程序中时会显示数组溢出,无法解析。
我们现在进行调整,让其支持大端储存的ELF格式文件解析:
#ifndef EI_DATA
#define EI_DATA 5
#endif
#define REVERSE_32bits(Data) \
( (((Data) & 0xff) << 24) | (((Data) & 0xff00) << 8) | (((Data) >> 8) & 0xff00) | (((Data) >> 24) & 0xff) )
#define REVERSE_16bits(Data) \
( (((Data) & 0xff) << 8) | (((Data) >> 8) & 0xff) )
先定义一些宏帮助我们进行大小端转换,然后通过判断e_ident[EI_DATA]就可以对大小端ELF文件进行处理了。
这里给出大端处理的代码:
ptr_sh_table = binary + REVERSE_32bits(ehdr->e_shoff);
sh_entry_count = REVERSE_16bits(ehdr->e_shnum);
sh_entry_size = REVERSE_16bits(ehdr->e_shentsize);
for (Nr = 0;Nr < sh_entry_count;Nr++){
shdr = (Elf32_Shdr *)(ptr_sh_table + Nr * sh_entry_size);
printf("%d:0x%x\n",Nr,REVERSE_32bits(shdr->sh_addr));
}
从代码的处理上,我们可以发现大小端的区别:
- 数据的存储方式不同:
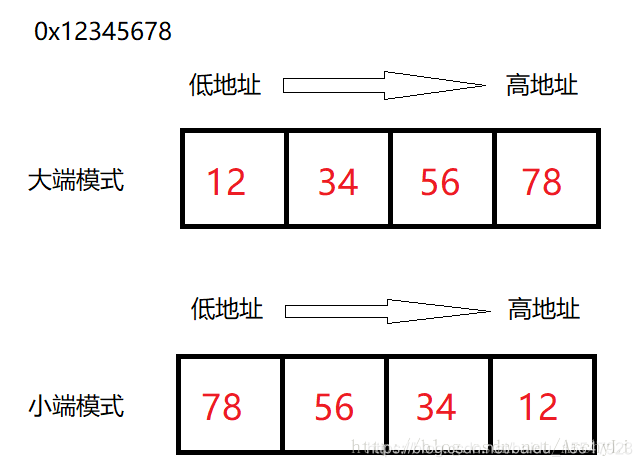
- 数据在存储空间内的存储位置不发生变化。所以我们在处理大端文件时,取出数据的位置与小端无异,只是需要将取出的数据进行大小端转换进行。
Thinking 1.3
在理论课上我们了解到,MIPS 体系结构上电时,启动入口地址为0xBFC00000(其实启动入口地址是根据具体型号而定的,由硬件逻辑确定,也有可能不是这个地址,但一定是一个确定的地址),但实验操作系统的内核入口并没有放在上电启动地址,而是按照内存布局图放置。思考为什么这样放置内核还能保证内核入口被正确跳转到?
(提示:思考实验中启动过程的两阶段分别由谁执行。)
我写的是bootloader将内核可执行文件拷贝到内存中,之后将控制权交给操作系统,只需要启动入口地址为bootloader的入口地址。
我们的实验次采用GXemul。GXemul支持加载ELF格式内核,所以启动流程被简化为加载内核到内存,之后跳转到内核的入口。
- 由Linker Script(控制加载地址)完成。Linker Script可以控制各节的加载地址。我们在tools/sese0_3.lds中设置了程序各个生成地址:
SECTIONS
{
. = 0x80010000;
.text : { *(.text) }
.data : { *(.data) }
.bss : { *(.bss) }
}
通过这个控制,生成的程序各个section的位置就被调整到了我们所指定的地址上。 segment是由section组合而成的,section的地址被调整了,那么最终segment的地址也会相应地被调整。 至此,我们通过lds文件控制各段(包括内核)被加载到我们预期的位置。与此同时tools/sese0_3.lds规定了ENTRY(_start) ,即把内核入口定为 _start 这个函数。
- 我们通过对start.S中_start函数的设置,就可以正确的跳转至main函数。
lui $sp 0x8040
jal main
Thinking 1.4
va(加载起始地址) va+i
| | |
|_ _ _|___|___BY2PG___|___BY2PG___|___BY2PG__|____|____|___BY2PG___|___|_ _ _|
offset| | |
|<--- .text & .data --->|<--- .bss --->|
|<--- bin_size --->| |
|<--- sg_size --->|
sg_size 和bin_size 的区别它的开始加载位置并非页对齐,同时bin_size的结束位置(va+i)也并非页对齐,最终整个段加载完毕的sg_size 末尾的位置也并非页对齐,请思考,为了保证页面不冲突(不重复为同一地址申请多个页,以及页上数据尽可能减少冲突),这样一个程序段应该怎样加载内存空间中。
在加载程序时,避免发生共享页面和冲突页面现象。有以下处理方式:
-
首先,不同程序段的占用空间不能够有重合,然后,尽量避免一个页面同时被多个程序段所占用。即若前面的程序段末地址所占用的页面地址为vi,则后续的程序段首地址应从下一页面vi+1开始占用
-
减少页面共享,为每一个程序段头强制页对齐,虽然增加了内碎片,但是减少了冲突。
-
我们也可以采用段式存储,将每一段分布在不同的内存空间内(不冲突),每一个段划分不同的页,这样访问时可以减少冲突。
Thinking 1.5
内核入口在什么地方?main 函数在什么地方?我们是怎么让内核进入到想要的 main 函数的呢?又是怎么进行跨文件调用函数的呢?
内核入口在 ./boot/start.S(0x80000000), main函数在 ./readelf/main.c(0x80010000)
从内核入口jal跳转到到main函数
gcc编译链接的时候,会把跨文件的函数所在的相应位置更新到jal指令上,从而实现跨文件调用
每个函数都有自己的地址,在跨文件调用函数时先将原来的变量存入栈中,返回位置同样堆栈,再跳转到调用函数的地址,函数调用结束后从栈中取出返回的位置,返回原函数,相关变量从栈中恢复。
Thinking 1.6
查阅《See MIPS Run Linux》一书相关章节,解释boot/start.S 中下面几行对CP0 协处理器寄存器进行读写的意义。具体而言,它们分别读/写了哪些寄存器的哪些特定位,从而达到什么目的?
/* Disable interrupts */
mtc0 zero, CP0_STATUS
......
/* disable kernel mode cache */
mfc0 t0, CP0_CONFIG
and t0, ~0x7
ori t0, 0x2
mtc0 t0, CP0_CONFIG
我们先查询CP0_STATUS代替的是那个寄存器
include/asm-mips3k/cp0regdef.h:#define CP0_STATUS $12
include/asm-mips3k/cp0regdef.h:#define CP0_CONFIG $16
| 12 | Status | 处理器状态和控制寄存器 |
|---|---|---|
| 16 | Config | 配置寄存器,用来设置CPU的参数 |
mtc0 zero, CP0_STATUS
上电后,需要设置SR寄存器来使CPU进入工作状态,而硬件通常都是复位后让许多寄存器的位为未定义。如此设置SR寄存器是为了屏蔽中断(IRQ和FIQ,uboot启动是一个完整的过程,没有必要也不能被打断);
mfc0 t0, CP0_CONFIG
and t0, ~0x7
ori t0, 0x2
mtc0 t0, CP0_CONFIG
Config寄存器的后三位为可写的,用来决定固定的kseg0区是否经过高速缓存和其确切的行为如何。此操作就是将Config寄存器的第二位和第零位置0,第一位置1。
我们经查询可知,Config寄存器用于CPU资源信息和配置,我们现观察一下Config寄存器的主要结构如下:


然后我们去观察K0部分的实际作用,K0有三个部分,分别为D、V、G位,我们再次查询可知:


于是我们发现,设置如上值是为了禁用内核模式缓存。
二、实验难点
exercise1.2
-
对于readelf.c我们首先需要根据魔数判断一个文件是否是ELF格式文件。readelf.c已经通过int is_elf_format(u_char *binary)帮助我们实现了。
-
根据ELF表中的有效信息,获取各个section的地址。
我们先分析一下ELF表的具体格式:

其中ELF header包含了section header table的偏移、每个节的大小、节的数目;section header table包含各个节的具体信息,基于数组实现。通过这些信息,我们可以快速定位节头表(存储着每一个节头的基本信息),并对节头表中每一项使用table[i] -> Addr即可获取每个节头的地址了,基本操作如图:
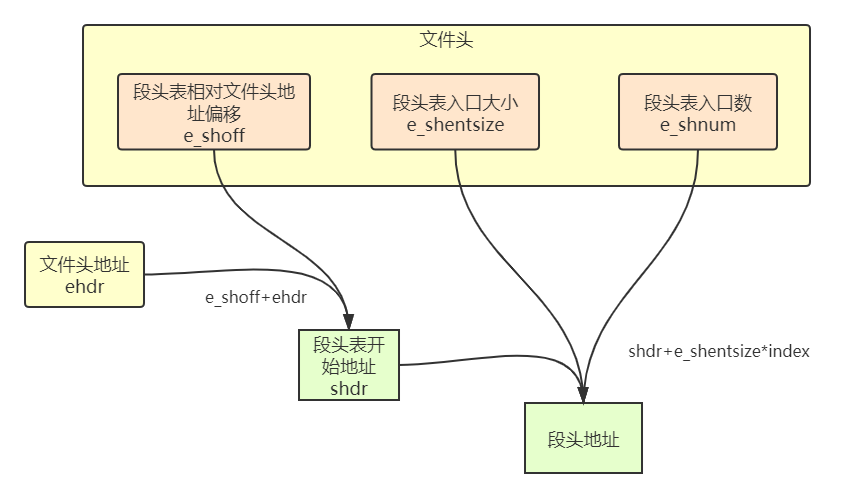
感觉较为难以理解的是弄懂各个参数和具体含义,实际操作与访问结构体数组无异。
exercise1.5
经过思考,我认为lp_print基本思路如下:

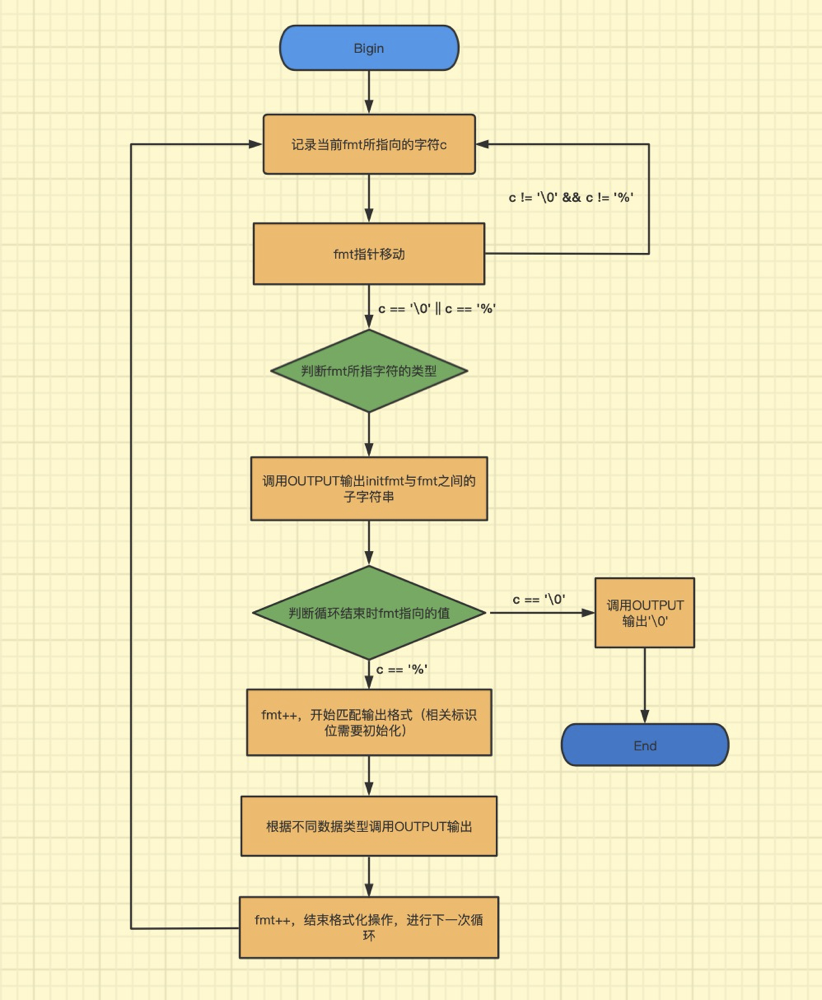
具体实验时有一定细节需要注意:
-
fmt每次完成匹配后需要自增使其指向下一个待检查的字符
-
对于flag的匹配注意'-'和'0'可以同时出现
flag 描述 - 在给定的宽度(width)上左对齐输出,默认为右对齐 0 当输出宽度和指定宽度不同的时候,在空白位置填充0 -
每一次循环时,需要对所有标志位进行初始化
-
printNUM传入的数字默认为无符号数,对于%d和%D数据处理我们需要预先判断正负
三、体会与感想
lab1花费10小时,由于实验平台仍不太熟悉,补充代码前依旧迟迟不敢开始。在实现printf时需要阅读三个文件的代码,切换起来有些不方便,导致浪费了较多时间,对tmux的使用也不够熟悉,想分屏看代码但仍觉得很不顺手。
阅读发现,文件的每一个代码段,都大量使用宏定义和一些全局变量,需要手动grep去查找,虽然说这样是为了代码的可移植性,容错性更高,但是在实际阅读时仍然对于很多宏理解不清楚甚至混淆。
以为Makefile可以实现只要依赖文件发生改动,make就会自动执行,这次作业后才发现原来还是需要在修改代码后手动make。忘记执行make导致我看着printf执行失败的界面不知所措。
给出的代码一般都预先定义好了变量,但由于不能理解变量名称(比如不知道带ptr的变量是指针),我在面对一块待补充的部分时有些茫然,在学习了一些变量命名规范后发现给出的变量名已经暗中提示了相关的操作,甚至提示了变量的数据类型。
填补代码不仅仅意味着会填所缺陷的代码就完工了,往往先要学习了解较多的预置知识,并且弄清楚其他的文件、宏定义、函数,了解各个文件、函数之间的层次关系,相较于以前一个C程序就可以解决的问题,我们还是需要明晰多文件是如何划分的,它们又是怎么协同完成操作系统的启动的。
四、遗留难点/指导书反馈
难点一:
1.2练习中,出现了很多强制转换指针的地方:
Elf32_Ehdr *ehdr = (Elf32_Ehdr *)binary;
**********
phdr = (Elf32_Phdr *)(ptr_sh_table + Nr * sh_entry_size);
本来疑惑的是,怎么可以随意的进行指针转换?后来查询得知,c语言的指针就是指向一个特定的空间地址,而空间内的信息都是以二进制形式存储,因此可以强制转换为任何类型的指针,对应的存储空间内的信息也会“转换”成指针类型对应偏移的数据类型,给出下面一个例子:
//code
#include <stdio.h>
struct test{
int a;
char b;
short c;
}new_test;
int main(int argc, char *argv[]) {
char s[100] = "BUAA,OS YYDS!";
struct test* ptr = s;
printf("%d %c %hd\n",ptr->a,ptr->b,ptr->c);
}
//output
1094800706 , 8275
//1094800706就是”BUAA“ASCLL码对应二进制转十进制数,8275也正是”OS“ASCLL码对应二进制转十进制数
难点二:
1.3练习中,源代码里的 end = . ;有什么作用吗?
难点三:
1.5练习中,判断文件是否时ELF格式的对与判断size < 4这一条件不太理解。
难点四:
求偏移使用的宏定义中为什么直接将地址0强制转化为type*?
#define offsetof(type, member) ((size_t)(&((type *)0)->member))
后来查询资料发现该可以分解为以下几个部分:


在C语言中,ANSI C标准允许值为0的常量被强制转换成任何一种类型的指针,而且转换结果是一个空指针,即NULL指针,因此对0取指针的操作((type*)0)的结果就是一个类型为type*的NULL指针。 但是如果利用这个NULL指针来访问type类型的成员当然是非法的。
因为&(((type*)0)->member)的意图只不过是计算member字段的地址,C语言编译器根本不生成访问member成员的代码,而仅仅是根据type的内容布局和结构体实例地址在编译期计算这个常量地址,这样就完全避免了通过NULL指针访问内存可能出现的问题。同时又因为结构体地址是0,所以字段地址的值就是字段相对于结构体基址的偏移。
难点五:
对于汇编语言和c程序如何相互联系,(调用函数,传入参数)等不太理解,也不理解它们链接到一起的流程和原理,教程中也没有给出,lab1-2中就出现了相关问题,着实难以完成。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通