
除了redis,还可以使用另外一个神器----Celery。Celery是一个异步任务的调度工具。
Celery是Distributed Task Queue,分布式任务队列,分布式决定了可以有多个worker的存在,列表表示其是异步操作,即存在一个产生任务提出需求的工头,和一群等着被分配工作的码农。
在python中定义Celery的时候,我们要引入Broker,中文翻译过来就是"中间人"的意思,在这里Broker起到一个中间人的角色,在工头提出任务的时候,把所有的任务放到Broker里面,在Broker的另一头,一群码农等着取出一个个任务准备着手做。
这种模式注定了整个系统会是个开环系统,工头对于码农们把任务做的怎样是不知情的,所以我们要引入Backend来保存每次任务的结果。这个Backend有点像我们的Broker,也是存储信息用的,只不过这里存的是那些任务的返回结果。我们可以选择只让错误执行的任务返回结果到Backend,这样我们取回结果,便可以知道有多少任务执行失败了。
Celery 介绍
在Celery中几个基本的概念,需要先了解下,不然不知道为什么要安装下面的东西。概念:Broker,Backend。
Broker:
broker是一个消息传输的中间件,可以理解为一个邮箱。每当应用程序调用celery的异步任务的时候,会向broker传递消息,而后celery的worker将会取到消息,进行程序执行,好吧,这个邮箱可以看成是一个消息队列,其中Broker的中文意思是经纪人,其实就是一开始说的消息队列,用来发送和接受信息。这个broker有几个方案可供选择:RabbitMQ(消息队列),Redis(缓存数据库),数据库(不推荐),等等
什么是backend?
通常程序发送的消息,发完就完了,可能都不知道对方什么时候接受了,为此,celery实现了一个backend,用于存储这些消息以及celery执行的一些消息和结果,Backend是在Celery的配置中的一个配置项CELERY_RESULT_BACKEND,作用是保存结果和状态,如果你需要跟踪任务的状态,那么需要设置这一项,可以是Database backend,也可以是Cache backend.
对于brokers,官方推荐是rabbitmq和redis,至于backend,就是数据库,为了简单可以都使用redis。

Celery的架构由三部分组成,消息中间件(message broker),任务执行单元(worker)和任务执行结果存储(task result store)组成。
消息中间件
Celery本身不提供消息服务,但是可以方便的和第三方提供的消息中间件集成,包括,RabbitMQ,Redis,MongoDB..............
任务执行单元
Worker是celery提供的任务执行的单元,worker并发的运行在分布式的系统节点中。
任务结果存储
Task result store用来存储Worker执行的任务的结果,Celery支持以不同方式存储任务的结果,包括AMQP,redis,memcached,mongodb,SQLAlchemy,Django
安装Redis,它的安装比较简单:

然后进行配置,一般都在项目的config.py文件里配置:

URL的格式为:
redis://:password@hostname:port/db_number
URL Scheme后的所有字段都是可选的,并且默认为localhost的6479端口,使用数据库0。我的配置是:
redis://:password@ubuntu:6379/5
安装Celery,我是用标准的Python工具pip安装的,如下:

使用Celery
使用celery包含三个方面:1,定义任务函数 2,运行celery服务 3,客户应用程序的调用
创建一个文件tasks.py输入下列代码:
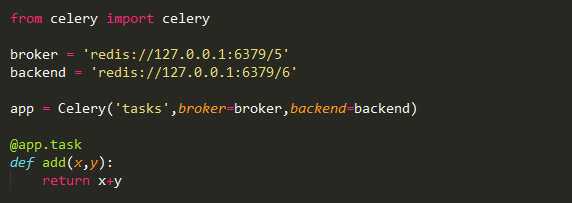
上述代码导入了celery,然后创建了celery实例app,实例化的过程中指定了任务名tasks(和文件名一致),传入了broker和backend。然后创建了一个任务函数add。下面启动
celery服务,在当前命令行终端运行:

目录结构(celery -A tasks worker --loglevel=info这条命令当前工作目录必须和tasks.py所在的目录相同,即进入tasks.py所在目录执行这条命令)
调用delay函数即可启动add这个任务,这个函数的效果是发送一条消息到broker中去,这个消息包括要执行的函数,函数的参数以及其他消息,具体的可以看Celery官方文档。这个时候worker会等待broker中的消息,一旦收到消息就会立刻执行消息。
注意:如果把返回值赋值给一个变量,那么原来的应用程序也会被阻塞,需要等待异步任务返回的结果,因此,实际使用中,不需要把结果赋值。
使用配置文件
Celery的配置比较多,可以在官方配置文档:http://docs.celeryproject.org/en/latest/userguide/configuration.html 查询每个配置项的含义。
上述的使用是简单的配置,下面介绍一个更健壮的方式来使用celery。首先创建一个python包,celery服务,姑且命名为proj。目录文件如下:

首先是celery.py
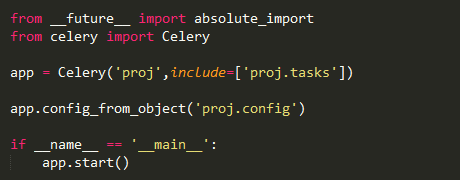
这一次创建app,并没有直接指定broker和backend。而是在配置文件中。
config.py

剩下的就是tasks.py

使用方法也很简单,在proj的同一级目录执行celery:
celery -A proj worker -l info
现在使用任务也很简单,直接在客户端代码调用proj.tasks里的函数即可。
Scheduler(定时任务,周期性任务)
一种常见的需求是每隔一段时间执行一个任务
在celery中执行定时任务非常简单,只需要设置celery对象的CELERYBEAT_SCHEDULE属性即可。
配置如下
config.py
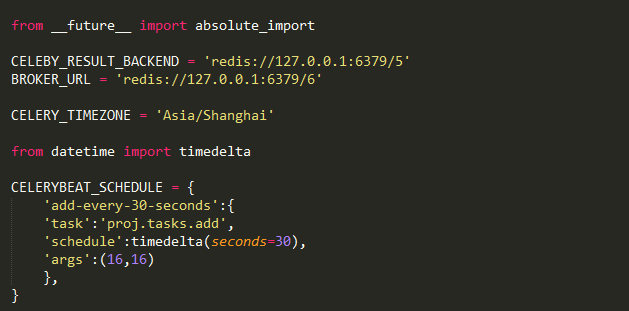
注意配置文件需要指定时区,这段代码表示每隔30秒执行add函数,一旦使用了scheduler,启动celery需要加上-B参数。
celery -A proj worker -B -l info
参考链接:https://blog.csdn.net/freeking101/article/details/74707619

 浙公网安备 33010602011771号
浙公网安备 33010602011771号