
负载均衡的Hash策略引发的session丢失
文章目录
负载均衡后添加机器后,发现数据库的压力迅速上升,越来越多的用户说刚登陆后没多久,操作着就退出了,接着登陆,又退出了。
这些问题背后都是由于一个「Session 丢失」问题导致的。
一、什么是 Session 丢失
相信 Session 对大部分 Coder 来说应该都知道。它是为了将同一个用户的多次访问在系统中被识别为“同一个用户”而产生的概念。
除此之外,还可以基于它来减少重复往 DB 或者远程服务处获取与该用户相关的信息,以起到提升性能的作用。
在我们做了负载均衡的场景中,如果选择的负载策略是 Hash 策略,那么会使得 Session 产生一个副作用。
这个副作用就如上面举的案例那样,用户一旦由于某种原因从原先访问服务器 A 变成访问服务器 B,就会出现“登陆状态丢失”、“缓存穿透”等问题。
为什么 Hash 策略会出现这个问题呢?首先有必要先了解一下 Hash 是如何进行的。
Hash 策略就是下图这样的一个散列函数。在函数不变的情况下,A 永远对应 01,B 对应 04,C 对应 08。
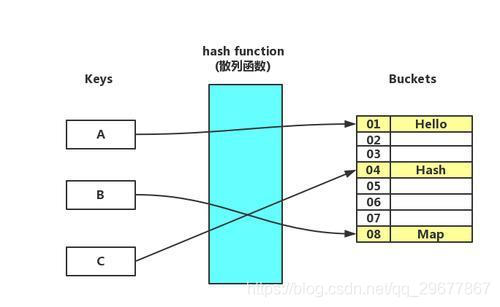
以 Nginx 中的 ip_hash 策略来举个例子:因为我们认为正常情况下用户的 ip 不会在短时间内发生变化。
所以当我们选择使用 ip_hash 策略进行负载均衡时,意味着期望同一个用户能够一直访问到同一台服务器上,就像下图这样:
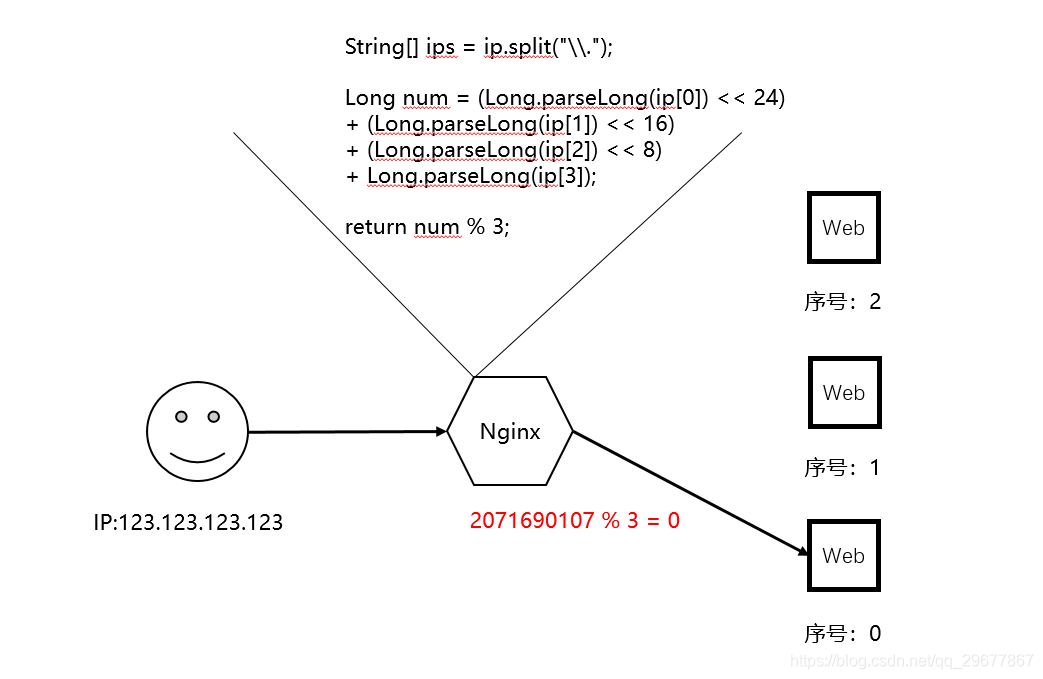
如此一来,我们只需要在这一台服务器上将这个用户相关的信息缓存在进程内,就能起到非常高性价比的提升性能的效果。
这时,客户端与服务端之间就相当于建立了一个信任,相互认识。这个信任就是「Session」。
但是,当我们加了一台服务器之后,事情就发生变化了。
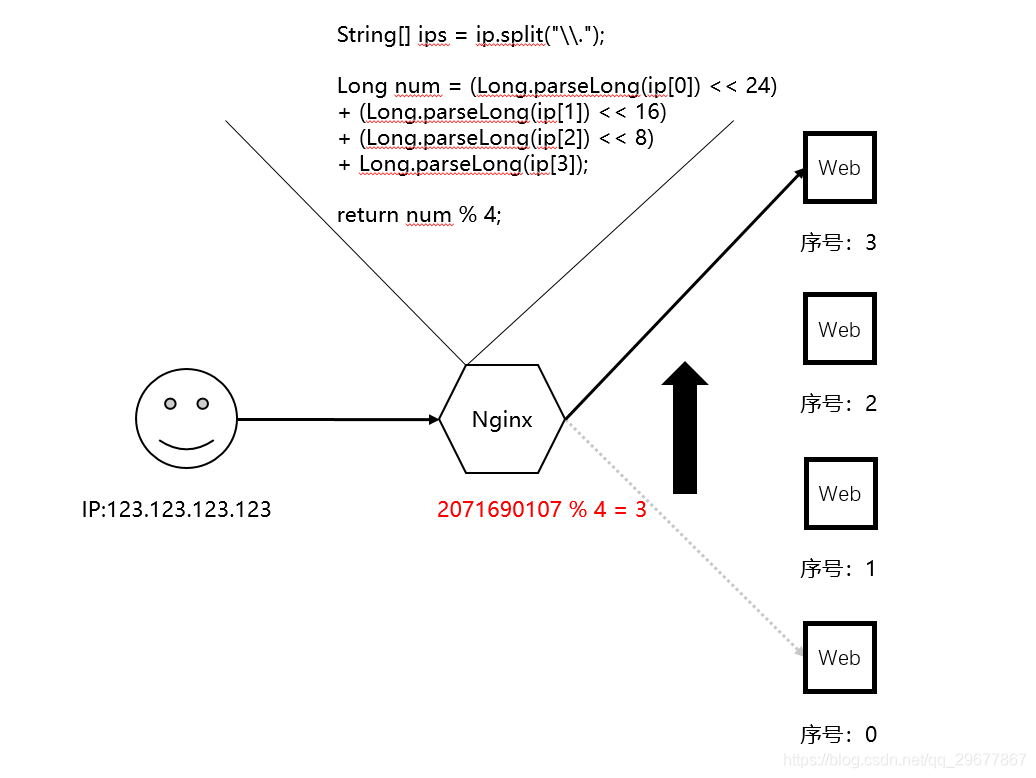
这个时候我们原先的预期就被破坏了。因为用户与序号 0 节点的链接变成了与序号 3 的链接,所以产生了前面提到的「Session丢失」问题。
与此同时,在序号 0 节点上做的进程内缓存都无效了,而在序号 3 节点上又没有用户相关的任何缓存,导致大量数据需要从下游的 DB 或者远程服务处获取。
你要知道,一旦涉及到网络通信,性能必然明显下降,I/O、序列化都是耗时的工作。
更重要的是,一旦同时有大量用户产生这个情况,由于后端的 DB 和远程服务瞬时无法承载激增的高密度请求,可能会导致它挂起。
这还没完,如果当前程序没有一些故障隔离或者降级策略,还会进一步产生蝴蝶效应,导致整个大系统响应缓慢。可谓“一颗老鼠屎坏了一锅粥”。
二、Nginx 如何来解决这个问题
2.1 Session 保持
既然以 Nginx 举例,还是从 Nginx 开始聊。通过在 Nginx 中引入 nginx-sticky-module 模块可以来解决这个问题。
解决的整个过程如下:

可以看到,当 Client 第一次进入到 Nginx 匹配节点的时候,在给它分配一个节点的同时,会将这个节点的唯一标识进行 MD5 后写入到 Cookie 中一并返回。
如果下次再发起请求的时候发现带有这个 Cookie 值,就直接转发到该值所对应的节点上去。这个机制被专业的称之为「Session 保持」。
虽然可以利用 Cookie 来解决这个问题,但是 Cookie 也有一个潜在的问题,如果客户端未开启 Cookie 功能,这个机制就失效了。不过好在目前主流浏览器都是默认打开 Cookie 的。
**题外话:**Nginx 是 2004 年发布的,在 nginx-sticky-module 出现之前的 7 年间也是 Nginx 相比竞品 HAProxy 最大的一个短板,因为 HAProxy 支持 Session 保持。
三、Session 保持的其他方案
除了 Cookie 之外,还有 2 种方式也可以最终达到类似的效果,分别被称为「Session 复制」、「Session 共享」。
3.1 Session 复制
这是最简单粗暴的方式。根据第一节的案例来看,导致问题的原因是节点 3 没有用户的 Session。
那么很容易想到,在节点 3 运行之前把 Session 相关的 Cache 数据复制过去呗。
并且在多个节点之间持续保证数据的同步,也就是说,每一台节点上都存在每个用户的 Session 数据。
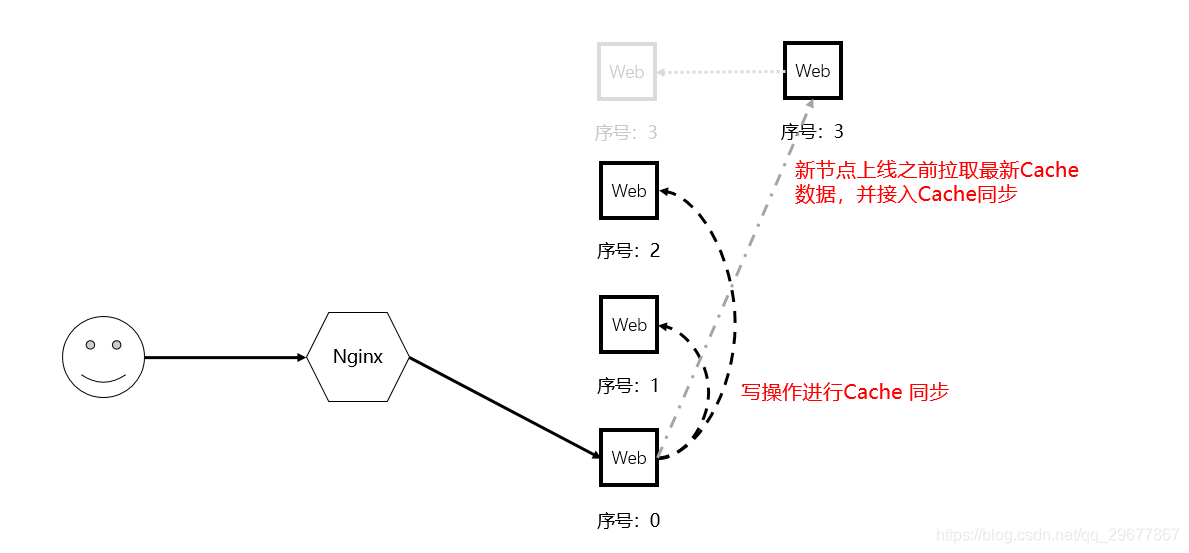
实现的方案有很多,特别是不同的宿主程序都或多或少提供了一些切入点,甚至是拿来即用的方案,如 Tomcat 的 Delta Manager 和 Backup Manager、Tomcat 和 IIS 的 Filter 机制等等,这里就不展开了。
此类方案的特点是:
-
**优点:**天然高可用,一部分节点宕机没事。因为每一个节点上都存放着所有已连接用户的会话信息。
-
**缺点:**因为每台计算机的内存是有上限的,仅适用于会话相关的数据大小较小的场景。
并且,由于多个节点之间需要同步数据,所以需要额外解决数据一致性问题。与此同时,随着节点越多,损耗越大(延迟、带宽等),有广播风暴风险。
3.1 Session 共享
我们还可以通过将 Session 信息存放到全局共享的存储介质中来达到一样的效果,如数据库、远程缓存等,这是一种中心化思想的解决方案。
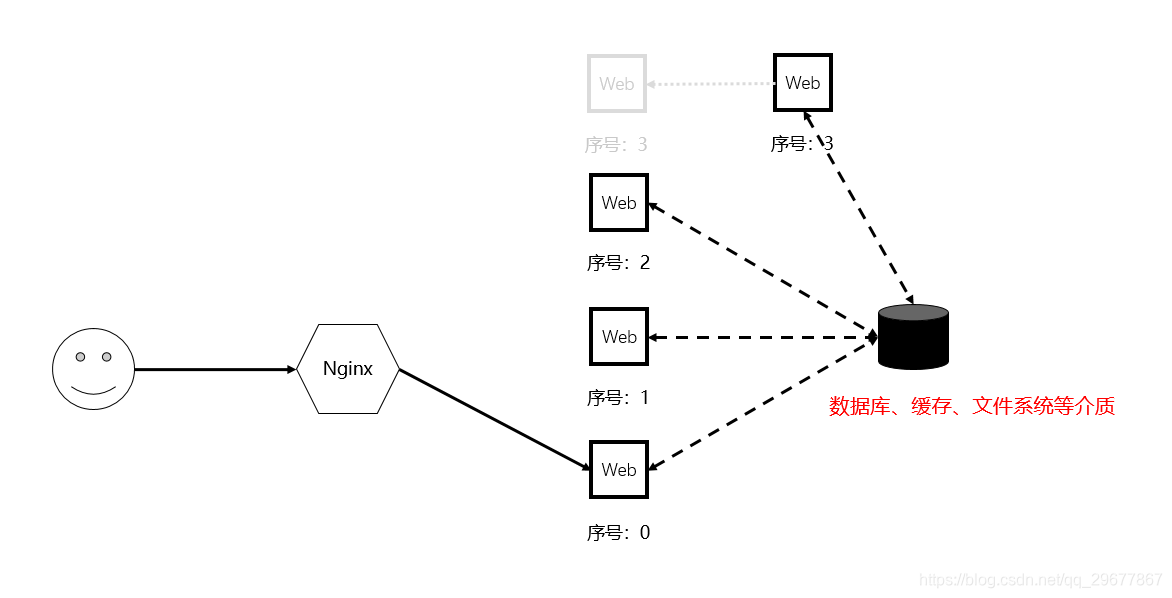
此类方案的特点是:
-
优点:不管节点怎么增加和减少,100% 不会产生会话丢失。
-
缺点:每次读写请求都需要增加额外共享存储调用,增加了网络 I/O、序列化等操作,性能明显下降。
另外,用作共享的存储介质除了增加了额外的维护成本外,还需要解决单点问题,以免产生系统性风险。
四、各个方案的适用场景
同之前 Session 保持 方案一起对比下各自的优缺点和适用场景:

分别用一句话概括一下这 3 个方案:
- Session 保持:原来在哪还是去哪。
- Session 复制:不管在哪都有一样的数据。
- Session 共享:所有节点共用一份数据。
越大型的系统,最终都会往「Session 共享」这个方案上走,因为只要再对这个共享存储做横向扩展,理论上就可以支撑无穷大的用户了。
如 Redis、一系列的 NoSQL 以及 NewSQL 等。就可以集 规模大、高可用、效果好 于一身。
结语
现在你应该清楚了 Session 丢失问题,也知道了如何去应对它。但是,我们还需要明白一个事实:严格来说「Session 保持」本质上是破坏了做「负载均衡」的初衷。
举个极端点的场景:一共有 10 个会话连在了节点 A 上,并且都是活动中状态。
那么这个时候哪怕增加一个节点 B 上线,只要没有新的会话进来,节点 B 上的活动连接数永远是 0,并没有起到分担压力的作用。但是,在系统的起步时期,其实用这样简单的方案也是极好的。

